- Методы интеллектуального анализа данных и некоторые их приложения

Содержание
- 2. Эволюция технологий хранения и обработки данных … — 1960-е: Файлы и файловые архивы 1960-е: Первые СУБД,
- 3. Актуальность и необходимость интеллектуального анализа данных Проблема больших объемов («Data explosion»): Средства автоматического сбора данных, повсеместное
- 4. Интеллектуальный анализ данных (Data Mining) Системы интеллектуального анализа данных (ИАД) – класс программных систем поддержки принятия
- 5. Процесс ИАД (1) Анализ предметной области: выявление и формулировка необходимых априорных знаний о предметной области, целей
- 6. Процесс ИАД (2) Выбор (или разработка) алгоритма анализа: определение ограничений и требований к алгоритму по точности,
- 7. Программные системы ИАД Типовая архитектура: Классификация систем ИАД: По типу анализируемых данных По типу решаемых задач
- 8. Типы исходных данных (1) Транзакционные базы данных и репозитории «событий» Объекты анализа – «события» различной структуры
- 9. Типы исходных данных (2) Географические и пространственные данные Привязка к пространственным координатам, учет географии объектов при
- 10. Задачи ИАД = типы выявляемых закономерностей Классификация («Обучение с учителем») Отнесение объектов к заранее определенным категориям
- 11. Методы анализа Data Mining Технологии БД Статистика и теор. вер. Другие дисциплины Теория информации Машинное обучение
- 12. Область применения систем ИАД Системы ИАД «общего назначения» По сути включают framework, библиотеку алгоритмов анализа и
- 13. ИАД в проектах лаборатории «Технологий Программирования» Компьютерная безопасность Обнаружение внешних и внутренних вторжений Моделирование и анализ
- 14. ИАД в компьютерной безопасности Цели компьютерной безопасности: обеспечение конфиденциальности, целостности и доступности данных Вторжение – действия
- 15. Традиционные средства выявления вторжений Основные концепции: Используют базах сигнатур известных атак Источники информации: системные журналы и
- 16. Методы ИАД в задачах выявления вторжений Основное предположение: активность пользователей и программ можно полностью отследить и
- 17. Обнаружение нарушений Особенности: Строится обобщенная модель атаки Основано на методах классификации Атакой считаются события или последовательности
- 18. Обнаружение аномалий Особенности : Строится обобщенная модель нормальной активности пользователей или программ (профайл) Основано на методах
- 19. Разработанные и реализованные алгоритмы Обнаружение аномалий: Оценка степени «типичности» событий и их последовательностей - нечеткая кластеризация
- 20. Система мониторинга и анализа поведения пользователей Функциональность: Сбор и консолидация данных о работе пользователей Статистический и
- 21. Архитектура системы мониторинга
- 22. Особенности реализации и результаты Подсистема консолидации исходных данных: Мульти-агентный подход Нет ограничений на источники собираемых данных
- 23. Электронный документооборот Интеллектуальная система анализа и фильтрации электронной почты масштаба предприятия Система анализа и много-темной классификации
- 24. Алгоритм классификации (на SVM): векторная форма представления письма высокая точность эффективность по скорости персональная модель классификации
- 25. Архитектура системы фильтрации Особенности реализации: Учет ресурсоемкости алгоритмов на этапе обучения Распределение и баланс нагрузки Классификация
- 26. Результаты экспериментальной реализации и апробации Почтовый сервер лаборатории «Технологий программирования» эксплуатация с весны 2004 около 1
- 27. Цели создания систем анализа и фильтрации Интернет-трафика Блокирование доступа к нелегальной (экстремистской, антисоциальной, террористической и т.п.)
- 28. Существующие системы фильтрации Традиционный подход («сигнатурные» методы): Использование при анализе Интернет-трафика специализированных, формируемых экспертами, баз знаний,
- 29. Анализ и фильтрация Интернет- трафика на основе методов ИАД Основная идея: Классификация потока гипертекстовой информации в
- 30. Преимущества Классификация в реальном времени статических и динамических интернет ресурсов; Точность выше, чем у «сигнатурных» методов;
- 31. Архитектура системы
- 32. Основные результаты Реализация системы: Формализованы требования и сценарии взаимодействия Спроектированы и реализованы базовые компоненты, их функционал,
- 33. Интеллектуальная система анализа и мониторинга электронного документооборота организации Основная задача системы: Перехват, «теневое копирование» и автоматизированное
- 34. Архитектура Драйвер ФС: определяет с какими файлами работал пользователь; Служба теневого копирования: определяет как сильно изменился
- 35. Архитектура ИАД системы анализа поведения технологических процессов Особенности реализации: выявление аномалий в характеристик ТП функционирование в
- 36. Выявление нештатных ситуаций построение модели поведения ТП (на этапе обучения) оценка отклонения текущего состояния ТП от
- 37. Анализ и прогнозирование качества ТП Какие параметры производственного процесса влияют на качество продукции? Quality = F(X1,
- 38. Результат Разработаны алгоритмы: на основе нечетких деревьев решений с поддержкой эволюционных методов оптимизации нечетких переменных и
- 39. Ситуационный центр Основная задача СЦ — строить наглядные образы ситуаций, возникающих в предметной области, на основе
- 40. Место ИАД в процессе поддержки принятия решений в СЦ ЛПР Аналитик Оператор Принятие решениий Представление результатов
- 41. Расчет и хранение индикаторов Проведение статистического анализа и вычисление индикаторов, описывающих ситуацию
- 42. Выявление аномалий в значениях индикаторов
- 43. Определение тенденций и прогнозирование значений индикаторов
- 44. Текущие результаты Проектирование и создание рабочего места аналитика ситуационного центра мониторинга и анализа ситуаций: Просмотр ситуации
- 45. Спасибо за внимание! и Вопросы? д.ф.-м.н. И.В.Машечкин ([email protected]), к.ф.-м.н. М.И. Петровский ([email protected]) лаборатория «Технологий программирования» ВМиК
- 46. Отличия ИАД систем (1) Наличие «обучения» база знаний формируются на основе анализируемых данных, а не экспертных
- 47. Отличия ИАД систем (2) Наличие большого объема данных сложной структуры зачастую скорость работы алгоритмов в ИАД
- 49. Скачать презентацию
Слайд 2Эволюция технологий хранения и обработки данных
… — 1960-е:
Файлы и файловые архивы
1960-е:
Первые
Эволюция технологий хранения и обработки данных
… — 1960-е:
Файлы и файловые архивы
1960-е:
Первые

Слайд 3Актуальность и необходимость интеллектуального анализа данных
Проблема больших объемов («Data explosion»):
Средства
Актуальность и необходимость интеллектуального анализа данных
Проблема больших объемов («Data explosion»):
Средства

Слайд 4Интеллектуальный анализ данных
(Data Mining)
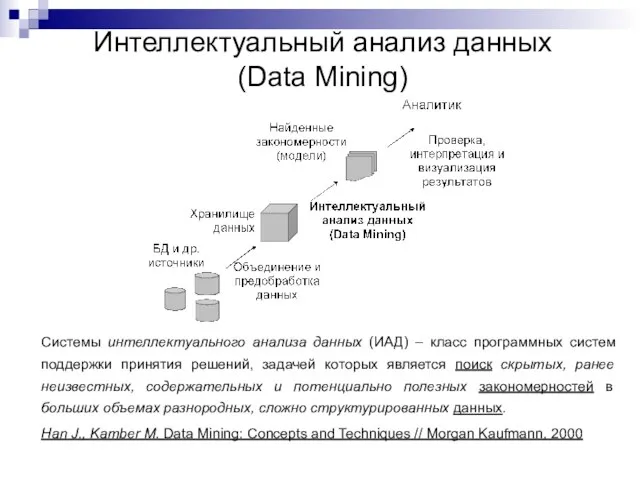
Системы интеллектуального анализа данных (ИАД) – класс программных систем
Интеллектуальный анализ данных
(Data Mining)
Системы интеллектуального анализа данных (ИАД) – класс программных систем
Слайд 5Процесс ИАД (1)
Анализ предметной области:
выявление и формулировка необходимых априорных знаний о предметной
Процесс ИАД (1)
Анализ предметной области:
выявление и формулировка необходимых априорных знаний о предметной

Слайд 6Процесс ИАД (2)
Выбор (или разработка) алгоритма анализа:
определение ограничений и требований к алгоритму
Процесс ИАД (2)
Выбор (или разработка) алгоритма анализа:
определение ограничений и требований к алгоритму

Слайд 7Программные системы ИАД
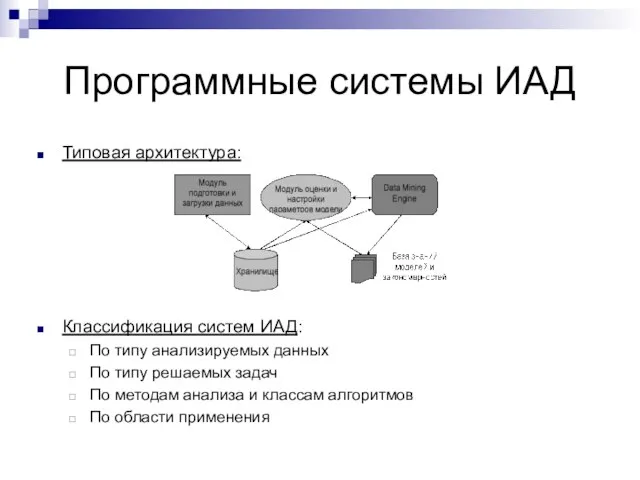
Типовая архитектура:
Классификация систем ИАД:
По типу анализируемых данных
По типу решаемых задач
По
Программные системы ИАД
Типовая архитектура:
Классификация систем ИАД:
По типу анализируемых данных
По типу решаемых задач
По
Слайд 8Типы исходных данных (1)
Транзакционные базы данных и репозитории «событий»
Объекты анализа – «события»
Типы исходных данных (1)
Транзакционные базы данных и репозитории «событий»
Объекты анализа – «события»

Слайд 9Типы исходных данных (2)
Географические и пространственные данные
Привязка к пространственным координатам, учет географии
Типы исходных данных (2)
Географические и пространственные данные
Привязка к пространственным координатам, учет географии

Слайд 10Задачи ИАД = типы выявляемых закономерностей
Классификация («Обучение с учителем»)
Отнесение объектов к заранее
Задачи ИАД = типы выявляемых закономерностей
Классификация («Обучение с учителем»)
Отнесение объектов к заранее

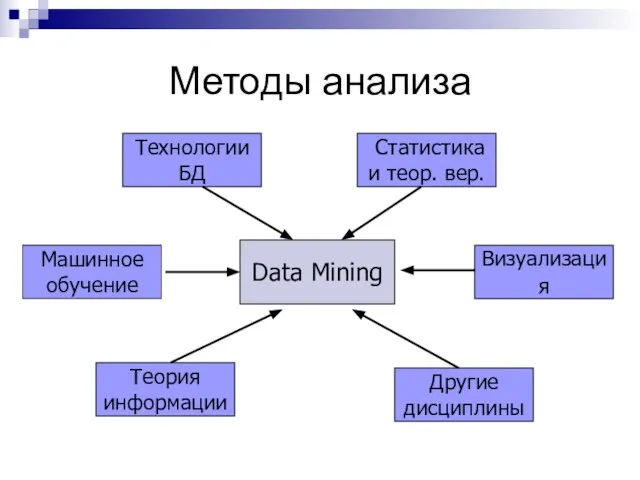
Слайд 11Методы анализа
Data Mining
Технологии
БД
Статистика
и теор. вер.
Другие
дисциплины
Теория
информации
Машинное
обучение
Визуализация
Методы анализа
Data Mining
Технологии
БД
Статистика
и теор. вер.
Другие
дисциплины
Теория
информации
Машинное
обучение
Визуализация
Слайд 12Область применения систем ИАД
Системы ИАД «общего назначения»
По сути включают framework, библиотеку алгоритмов
Область применения систем ИАД
Системы ИАД «общего назначения»
По сути включают framework, библиотеку алгоритмов

Слайд 13ИАД в проектах лаборатории «Технологий Программирования»
Компьютерная безопасность
Обнаружение внешних и внутренних вторжений
Моделирование
ИАД в проектах лаборатории «Технологий Программирования»
Компьютерная безопасность
Обнаружение внешних и внутренних вторжений
Моделирование

Слайд 14ИАД в компьютерной безопасности
Цели компьютерной безопасности: обеспечение конфиденциальности, целостности и доступности данных
Вторжение
ИАД в компьютерной безопасности
Цели компьютерной безопасности: обеспечение конфиденциальности, целостности и доступности данных
Вторжение

Слайд 15Традиционные средства выявления вторжений
Основные концепции:
Используют базах сигнатур известных атак
Источники информации:
Традиционные средства выявления вторжений
Основные концепции:
Используют базах сигнатур известных атак
Источники информации:

Слайд 16Методы ИАД в задачах выявления вторжений
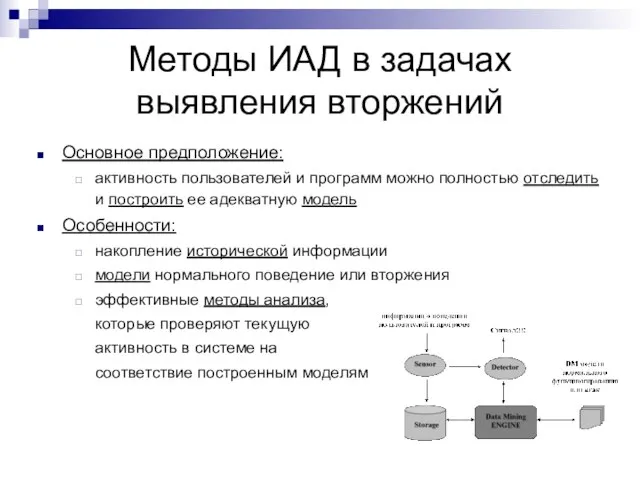
Основное предположение:
активность пользователей и программ можно
Методы ИАД в задачах выявления вторжений
Основное предположение:
активность пользователей и программ можно
Слайд 17Обнаружение нарушений
Особенности:
Строится обобщенная модель атаки
Основано на методах классификации
Атакой считаются события или
Обнаружение нарушений
Особенности:
Строится обобщенная модель атаки
Основано на методах классификации
Атакой считаются события или

Слайд 18Обнаружение аномалий
Особенности :
Строится обобщенная модель нормальной активности пользователей или программ (профайл)
Основано на
Обнаружение аномалий
Особенности :
Строится обобщенная модель нормальной активности пользователей или программ (профайл)
Основано на

Слайд 19Разработанные и реализованные алгоритмы
Обнаружение аномалий:
Оценка степени «типичности» событий и их последовательностей
Разработанные и реализованные алгоритмы
Обнаружение аномалий:
Оценка степени «типичности» событий и их последовательностей

Слайд 20Система мониторинга и анализа поведения пользователей
Функциональность:
Сбор и консолидация данных о работе пользователей
Статистический
Система мониторинга и анализа поведения пользователей
Функциональность:
Сбор и консолидация данных о работе пользователей
Статистический

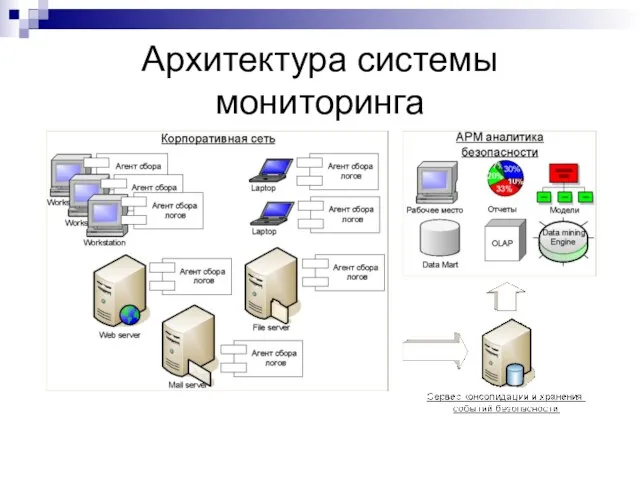
Слайд 21Архитектура системы мониторинга
Архитектура системы мониторинга
Слайд 22Особенности реализации и результаты
Подсистема консолидации исходных данных:
Мульти-агентный подход
Нет ограничений на источники собираемых
Особенности реализации и результаты
Подсистема консолидации исходных данных:
Мульти-агентный подход
Нет ограничений на источники собираемых

Слайд 23Электронный документооборот
Интеллектуальная система анализа и фильтрации электронной почты масштаба предприятия
Система анализа и
Электронный документооборот
Интеллектуальная система анализа и фильтрации электронной почты масштаба предприятия
Система анализа и

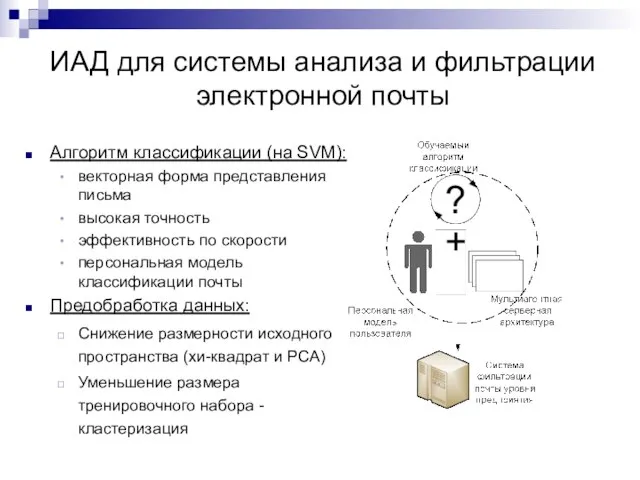
Слайд 24Алгоритм классификации (на SVM):
векторная форма представления письма
высокая точность
эффективность по скорости
персональная модель классификации
Алгоритм классификации (на SVM):
векторная форма представления письма
высокая точность
эффективность по скорости
персональная модель классификации
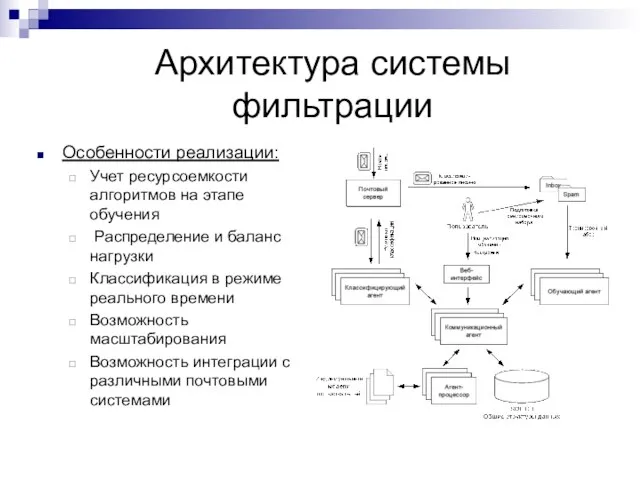
Слайд 25Архитектура системы фильтрации
Особенности реализации:
Учет ресурсоемкости алгоритмов на этапе обучения
Распределение и баланс
Архитектура системы фильтрации
Особенности реализации:
Учет ресурсоемкости алгоритмов на этапе обучения
Распределение и баланс
Слайд 26Результаты экспериментальной реализации и апробации
Почтовый сервер лаборатории «Технологий программирования»
эксплуатация с весны 2004
около
Результаты экспериментальной реализации и апробации
Почтовый сервер лаборатории «Технологий программирования»
эксплуатация с весны 2004
около

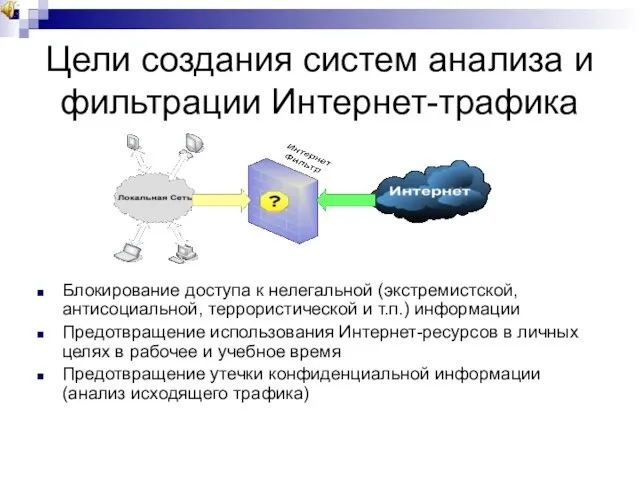
Слайд 27Цели создания систем анализа и фильтрации Интернет-трафика
Блокирование доступа к нелегальной (экстремистской, антисоциальной,
Цели создания систем анализа и фильтрации Интернет-трафика
Блокирование доступа к нелегальной (экстремистской, антисоциальной,
Слайд 28Существующие системы фильтрации
Традиционный подход («сигнатурные» методы):
Использование при анализе Интернет-трафика специализированных, формируемых экспертами,
Существующие системы фильтрации
Традиционный подход («сигнатурные» методы):
Использование при анализе Интернет-трафика специализированных, формируемых экспертами,

Слайд 29Анализ и фильтрация Интернет- трафика на основе методов ИАД
Основная идея:
Классификация потока гипертекстовой
Анализ и фильтрация Интернет- трафика на основе методов ИАД
Основная идея:
Классификация потока гипертекстовой

Слайд 30Преимущества
Классификация в реальном времени статических и динамических интернет ресурсов;
Точность выше, чем у
Преимущества
Классификация в реальном времени статических и динамических интернет ресурсов;
Точность выше, чем у

Слайд 31Архитектура системы
Архитектура системы
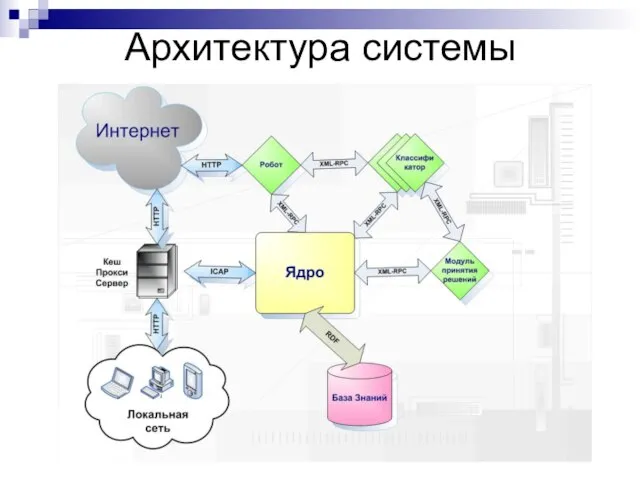
Слайд 32Основные результаты
Реализация системы:
Формализованы требования и сценарии взаимодействия
Спроектированы и реализованы базовые компоненты,
Основные результаты
Реализация системы:
Формализованы требования и сценарии взаимодействия
Спроектированы и реализованы базовые компоненты,

Слайд 33Интеллектуальная система анализа и мониторинга электронного документооборота организации
Основная задача системы:
Перехват, «теневое копирование»
Интеллектуальная система анализа и мониторинга электронного документооборота организации
Основная задача системы:
Перехват, «теневое копирование»

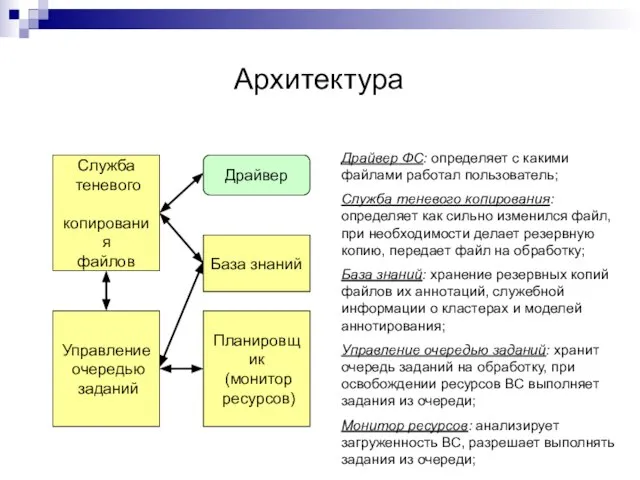
Слайд 34Архитектура
Драйвер ФС: определяет с какими файлами работал пользователь;
Служба теневого копирования: определяет как
Архитектура
Драйвер ФС: определяет с какими файлами работал пользователь;
Служба теневого копирования: определяет как
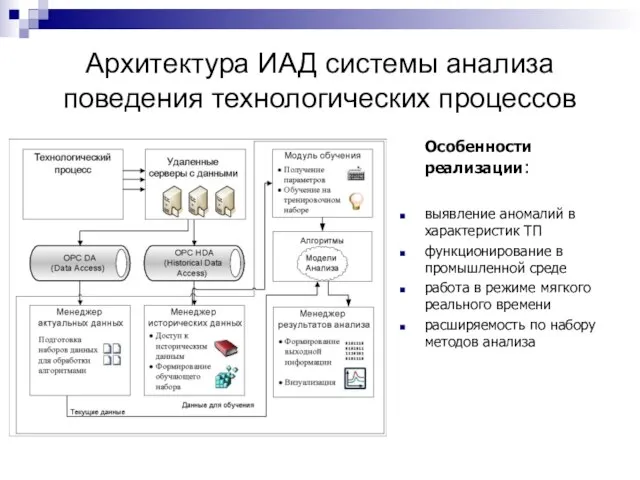
Слайд 35Архитектура ИАД системы анализа поведения технологических процессов
Особенности реализации:
выявление аномалий в характеристик ТП
функционирование
Архитектура ИАД системы анализа поведения технологических процессов
Особенности реализации:
выявление аномалий в характеристик ТП
функционирование
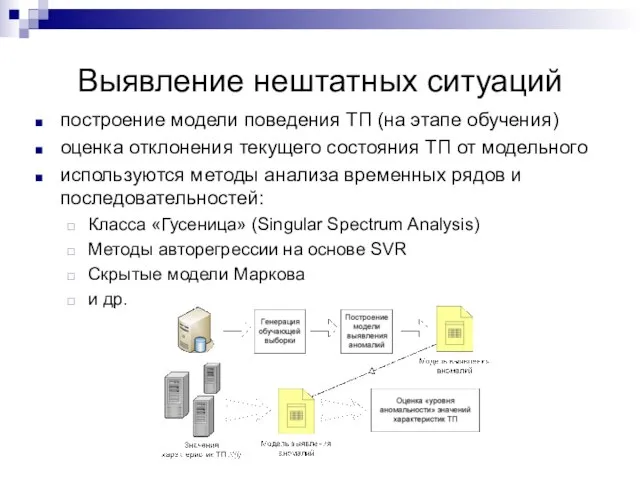
Слайд 36Выявление нештатных ситуаций
построение модели поведения ТП (на этапе обучения)
оценка отклонения текущего состояния
Выявление нештатных ситуаций
построение модели поведения ТП (на этапе обучения)
оценка отклонения текущего состояния
Слайд 37Анализ и прогнозирование качества ТП
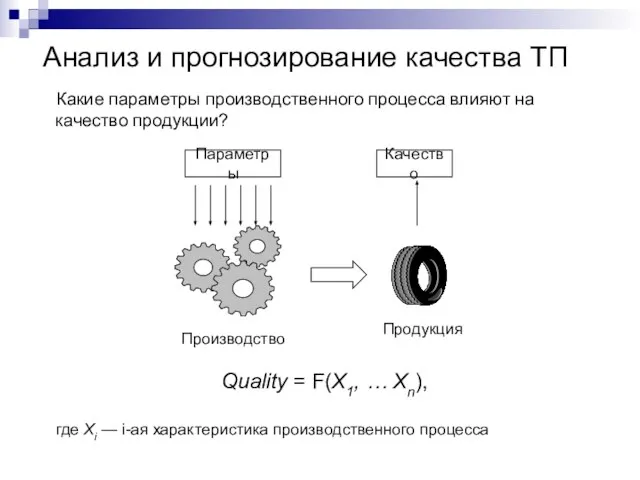
Какие параметры производственного процесса влияют на качество продукции?
Quality
Анализ и прогнозирование качества ТП
Какие параметры производственного процесса влияют на качество продукции?
Quality
Слайд 38Результат
Разработаны алгоритмы:
на основе нечетких деревьев решений
с поддержкой эволюционных методов оптимизации
Результат
Разработаны алгоритмы:
на основе нечетких деревьев решений
с поддержкой эволюционных методов оптимизации

Слайд 39Ситуационный центр
Основная задача СЦ — строить наглядные образы ситуаций, возникающих в предметной
Ситуационный центр
Основная задача СЦ — строить наглядные образы ситуаций, возникающих в предметной

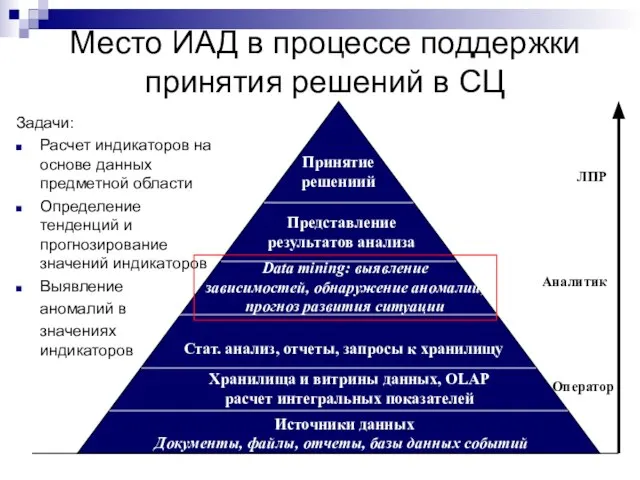
Слайд 40Место ИАД в процессе поддержки принятия решений в СЦ
ЛПР
Аналитик
Оператор
Принятие
решениий
Представление
результатов анализа
Data mining:
Место ИАД в процессе поддержки принятия решений в СЦ
ЛПР
Аналитик
Оператор
Принятие
решениий
Представление
результатов анализа
Data mining:
Слайд 41Расчет и хранение индикаторов
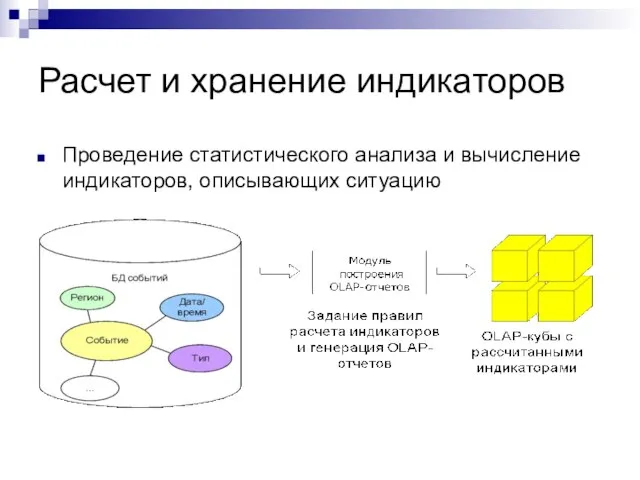
Проведение статистического анализа и вычисление индикаторов, описывающих ситуацию
Расчет и хранение индикаторов
Проведение статистического анализа и вычисление индикаторов, описывающих ситуацию
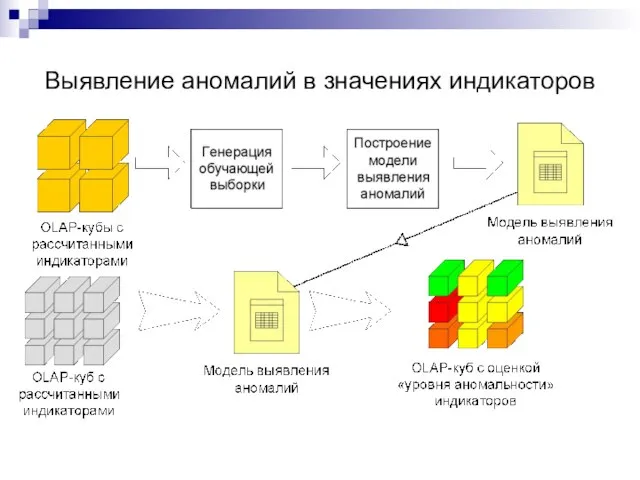
Слайд 42Выявление аномалий в значениях индикаторов
Выявление аномалий в значениях индикаторов
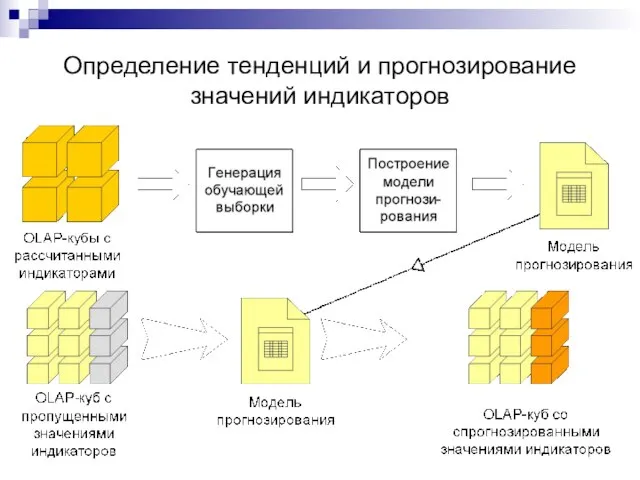
Слайд 43Определение тенденций и прогнозирование значений индикаторов
Определение тенденций и прогнозирование значений индикаторов
Слайд 44Текущие результаты
Проектирование и создание рабочего места аналитика ситуационного центра мониторинга и анализа
Текущие результаты
Проектирование и создание рабочего места аналитика ситуационного центра мониторинга и анализа

Слайд 45Спасибо за внимание!
и
Вопросы?
д.ф.-м.н. И.В.Машечкин ([email protected]),
к.ф.-м.н. М.И. Петровский ([email protected])
лаборатория «Технологий программирования»
ВМиК
Спасибо за внимание!
и
Вопросы?
д.ф.-м.н. И.В.Машечкин ([email protected]),
к.ф.-м.н. М.И. Петровский ([email protected])
лаборатория «Технологий программирования»
ВМиК

Слайд 46Отличия ИАД систем (1)
Наличие «обучения»
база знаний формируются на основе анализируемых данных, а
Отличия ИАД систем (1)
Наличие «обучения»
база знаний формируются на основе анализируемых данных, а

Слайд 47Отличия ИАД систем (2)
Наличие большого объема данных сложной структуры
зачастую скорость работы алгоритмов
Отличия ИАД систем (2)
Наличие большого объема данных сложной структуры
зачастую скорость работы алгоритмов

 Прикладные виды спорта
Прикладные виды спорта Компьютерная программа FRITZ 12
Компьютерная программа FRITZ 12 Баскетбол. Совершенствование навыков ловли мяча, передачи мяча
Баскетбол. Совершенствование навыков ловли мяча, передачи мяча Международная торговля
Международная торговля Стандартизация оказания медицинской помощи и медицинский опросник для детей с муковисцидозом
Стандартизация оказания медицинской помощи и медицинский опросник для детей с муковисцидозом  «Продажи в дистрибуции» - новый мультимедийный курс для торговых компаний
«Продажи в дистрибуции» - новый мультимедийный курс для торговых компаний Основные понятия: Брак – добровольный союз мужчины и женщины с целью создания семьи. Права и обязанности родителей Права и обязан
Основные понятия: Брак – добровольный союз мужчины и женщины с целью создания семьи. Права и обязанности родителей Права и обязан Презентация на тему Античная лирика
Презентация на тему Античная лирика Презентация на тему Буква О
Презентация на тему Буква О Этап разработки конструкторской документации. Нормативная база, конструкторская документация в виде трехмерных моделей. Лекция 8
Этап разработки конструкторской документации. Нормативная база, конструкторская документация в виде трехмерных моделей. Лекция 8 Политика и власть
Политика и власть A p r o j e c t o f
A p r o j e c t o f Для чего дует ветер?
Для чего дует ветер? Презентация на тему Фламинго
Презентация на тему Фламинго  МОДЕЛЬ ТОЧКИ
МОДЕЛЬ ТОЧКИ Сущность и функции денег
Сущность и функции денег Больше. Меньше. Столько же.
Больше. Меньше. Столько же. Анализ структуры и деятельности МБУ ДО ЦДЮ Созвездие
Анализ структуры и деятельности МБУ ДО ЦДЮ Созвездие Поведение и поступок
Поведение и поступок Нижегородский филиал
Нижегородский филиал Добро и зло (9 класс)
Добро и зло (9 класс) Школьная библиотека/медиатека – навигатор детского чтения 2011
Школьная библиотека/медиатека – навигатор детского чтения 2011 rezhim_dnya
rezhim_dnya По следам теоремы Пифагора
По следам теоремы Пифагора Обувь. Рюкзаки
Обувь. Рюкзаки Международная торговля услугами
Международная торговля услугами  Презентация на тему Архитектура Древней Греции и Древнего Рима
Презентация на тему Архитектура Древней Греции и Древнего Рима Блок обучения. Для сотрудников Компании “Шин Line”
Блок обучения. Для сотрудников Компании “Шин Line”