Сравнительное исследование технологий доступа к реляционным БД на основе нестандартных моделей данных
- Сравнительное исследование технологий доступа к реляционным БД на основе нестандартных моделей данных

Содержание
- 2. Характеристики информационных систем Объем кода Сложность модели данных Масштабируемость Возможность повторного использования функциональности Конфигурируемость приложения Возможность
- 3. I. Сравнение технологий доступа и моделей данных по производительности, гибкости и простоте реализации Подходы к хранению
- 4. Реализованные подходы и технологии Дополнительные возможности Кэширование (на стороне Application-сервера) Перенесение части нагрузки на сервер БД
- 5. Субъективные тесты (1 пользователь) WEB-приложение, сценарий типа «выполнить следующие действия с данными» Формализованные нагрузочные тесты Поиск
- 6. Enterprise JavaBeans 2.0 Стандартная реализация Усовершенствование в виде кэширования метаданных на стороне Application-сервера Полное кэширование данных
- 7. Результаты
- 8. Результаты Сложность реализации
- 9. В среднем технология JPA обеспечивает несколько меньшую производительность по сравнению с EJB2.0 Однако в большинстве случаев
- 10. Модель с единственной таблицей Любой объект, тип, атрибут, бизнес-правило представлены одной записью в таблице Цель Введение
- 11. Plain DB + JDBC Data Warehouse Plain DB + JPA Social Networks Metamodels + JPA Bookstore
- 12. Разработано несколько реализаций ИС на основе EJB 2.x, JPA и JDBC Введены усовершенствования реализаций Кэширование EJB
- 14. Скачать презентацию
Слайд 2Характеристики информационных систем
Объем кода
Сложность модели данных
Масштабируемость
Возможность повторного использования функциональности
Конфигурируемость приложения
Возможность изменять логику
Характеристики информационных систем
Объем кода
Сложность модели данных
Масштабируемость
Возможность повторного использования функциональности
Конфигурируемость приложения
Возможность изменять логику

Слайд 3I. Сравнение технологий доступа и моделей данных по производительности, гибкости и простоте
I. Сравнение технологий доступа и моделей данных по производительности, гибкости и простоте

Слайд 4Реализованные подходы и технологии
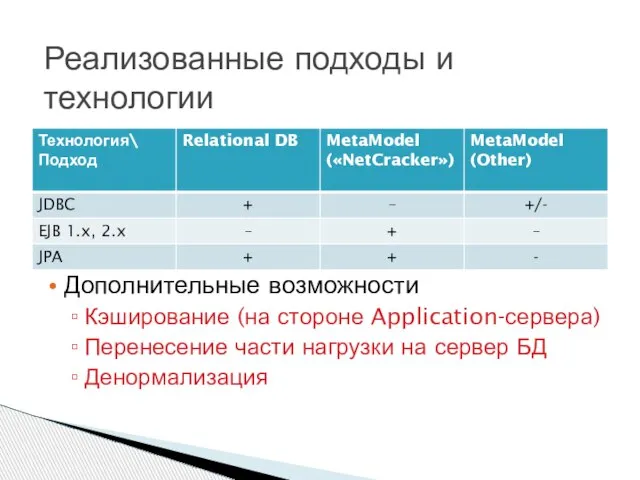
Дополнительные возможности
Кэширование (на стороне Application-сервера)
Перенесение части нагрузки на сервер
Реализованные подходы и технологии
Дополнительные возможности
Кэширование (на стороне Application-сервера)
Перенесение части нагрузки на сервер
Слайд 5Субъективные тесты (1 пользователь)
WEB-приложение, сценарий типа «выполнить следующие действия с данными»
Формализованные нагрузочные
Субъективные тесты (1 пользователь)
WEB-приложение, сценарий типа «выполнить следующие действия с данными»
Формализованные нагрузочные

Слайд 6Enterprise JavaBeans 2.0
Стандартная реализация
Усовершенствование в виде кэширования метаданных на стороне Application-сервера
Полное кэширование
Enterprise JavaBeans 2.0
Стандартная реализация
Усовершенствование в виде кэширования метаданных на стороне Application-сервера
Полное кэширование

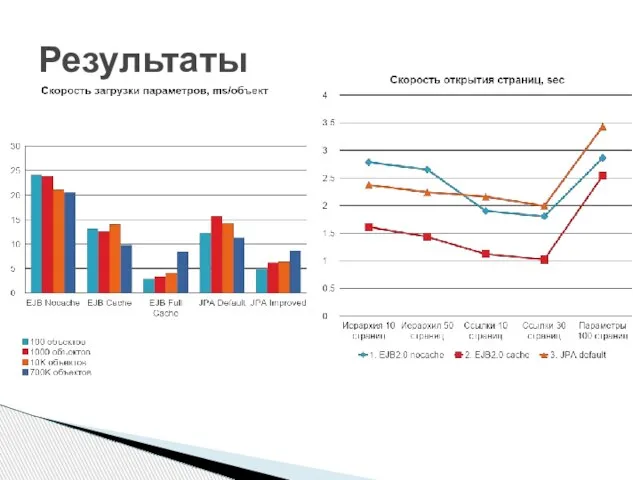
Слайд 7Результаты
Результаты
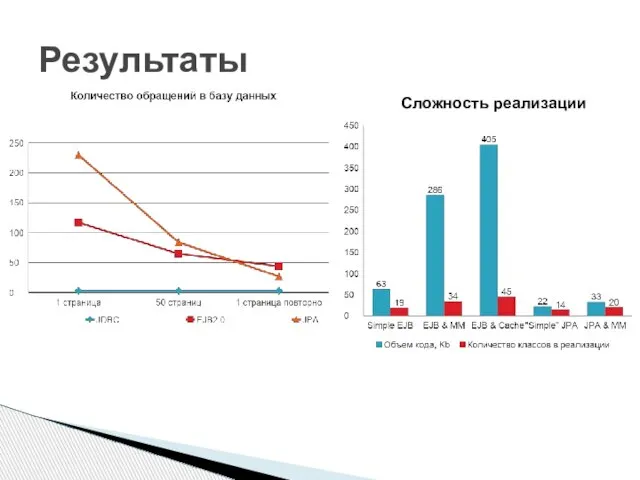
Слайд 8Результаты
Сложность реализации
Результаты
Сложность реализации
Слайд 9В среднем технология JPA обеспечивает несколько меньшую производительность по сравнению с EJB2.0
Однако
В среднем технология JPA обеспечивает несколько меньшую производительность по сравнению с EJB2.0
Однако

Слайд 10Модель с единственной таблицей
Любой объект, тип, атрибут, бизнес-правило представлены одной записью в
Модель с единственной таблицей
Любой объект, тип, атрибут, бизнес-правило представлены одной записью в

Слайд 11Plain DB + JDBC
Data Warehouse
Plain DB + JPA
Social Networks
Metamodels + JPA
Bookstore
E-Shop
Metamodels +
Plain DB + JDBC
Data Warehouse
Plain DB + JPA
Social Networks
Metamodels + JPA
Bookstore
E-Shop
Metamodels +

Слайд 12Разработано несколько реализаций ИС на основе EJB 2.x, JPA и JDBC
Введены усовершенствования
Разработано несколько реализаций ИС на основе EJB 2.x, JPA и JDBC
Введены усовершенствования

 Презентация нового продукта «Обзор заработных плат»
Презентация нового продукта «Обзор заработных плат» ПЛЮСЫ И МИНУСЫ, ПОЛОЖИТЕЛЬНОЕ И ОТРИЦАТЕЛЬНОЕ В МАТЕМАТИКЕ И В ЖИЗНИ
ПЛЮСЫ И МИНУСЫ, ПОЛОЖИТЕЛЬНОЕ И ОТРИЦАТЕЛЬНОЕ В МАТЕМАТИКЕ И В ЖИЗНИ Фриденсрайх Хундертвассер
Фриденсрайх Хундертвассер Аналоговые и цифровые сигналы
Аналоговые и цифровые сигналы Право для школьников
Право для школьников 6b8c575b324073cbf02a3d966912b4c92047c6ed — копия
6b8c575b324073cbf02a3d966912b4c92047c6ed — копия Реклама ВКонтакте
Реклама ВКонтакте В поход всей семьей – это здорово! Семейный выходной
В поход всей семьей – это здорово! Семейный выходной Акцизы с 1 января 2009 года
Акцизы с 1 января 2009 года Презентация на тему: Оценка качества предоставляемых образовательных услуг
Презентация на тему: Оценка качества предоставляемых образовательных услуг Презентация на тему Средства для борьбы с насекомыми
Презентация на тему Средства для борьбы с насекомыми Презентация на тему Классическая теория экономического риска
Презентация на тему Классическая теория экономического риска  Луна
Луна Обучающая интерактивная игра на тематику Управление проектами
Обучающая интерактивная игра на тематику Управление проектами Пришкольный лагерь "Солнышко"
Пришкольный лагерь "Солнышко" Управление комплексом маркетинговых коммуникаций
Управление комплексом маркетинговых коммуникаций Информационная безопасность
Информационная безопасность НОВОСТИ ЕГЭ
НОВОСТИ ЕГЭ О чем идет речь - Об оценке деятельности подразделения Единица оценки – подразделение Оценка работы сотрудника – не включаетс
О чем идет речь - Об оценке деятельности подразделения Единица оценки – подразделение Оценка работы сотрудника – не включаетс Физика в музыке
Физика в музыке LFood. Сэндвичи
LFood. Сэндвичи Сложение сил, действующих вдоль одной прямой. Равнодействующая
Сложение сил, действующих вдоль одной прямой. Равнодействующая «Мастерская чтения – идеи, проекты, воплощения»
«Мастерская чтения – идеи, проекты, воплощения» Использование Интернет-тренажеров при подготовке студентов к аккредитационному тестированию Сайт www.i-exam.ru
Использование Интернет-тренажеров при подготовке студентов к аккредитационному тестированию Сайт www.i-exam.ru Куликовская битва
Куликовская битва Архитектурные стили Петербурга
Архитектурные стили Петербурга Модернизация ЛВС в рамках создания регионального фрагмента единой государственной информационной системы в сфере здравоохране
Модернизация ЛВС в рамках создания регионального фрагмента единой государственной информационной системы в сфере здравоохране 3 Ховайло ВВ - Презентация проекта на открытие - СОГЛ (С) 20.10
3 Ховайло ВВ - Презентация проекта на открытие - СОГЛ (С) 20.10