- Библиотека MPI

Содержание
- 2. История MPI Стандарт MPI 1.0 1995 год, MPI 2.0 1998 год. Определяет API (варианты для Си,
- 3. «Комплект поставки» MPI Библиотека. Средства компиляции и запуска приложения.
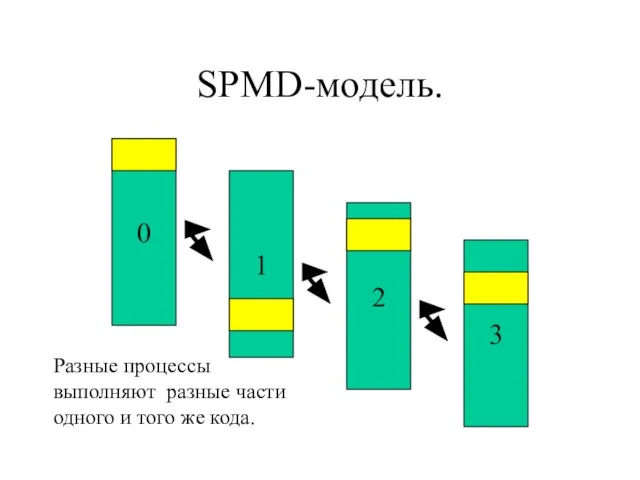
- 4. SPMD-модель. 0 1 2 3 Разные процессы выполняют разные части одного и того же кода.
- 5. Сборка MPI-приложения. Сборка MPI-приложения осуществляется с помощью специальной утилиты. В случае Си – mpicc. Пример: mpicc
- 6. MPI “Hello, World” #include #include main(int argc, char* argv[]) { MPI_Init(&argc, &argv); printf("Hello, World!\n"); MPI_Finalize(); }
- 7. Функции инициализации и завершения работы. int MPI_Init(int* argc,char*** argv) argc – указатель на счетчик аргументов командной
- 8. Тоже простая MPI-программа #include #include int main( int argc, char *argv[] ) { int rank, size;
- 9. Функции определения ранга и числа процессов. int MPI_Comm_size (MPI_Comm comm, int* size ) comm - коммуникатор
- 10. Точечные взаимодействия
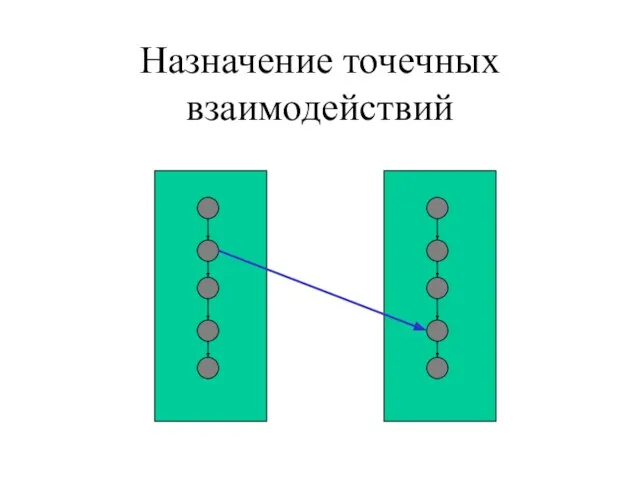
- 11. Назначение точечных взаимодействий
- 12. Пример простейшей пересылки #include #include main(int argc, char* argv[]) { int rank; MPI_Status st; char buf[64];
- 13. Функции обменов точка-точка int MPI_Send( buf, count, datatype, dest, tag, comm ) void *buf; /* in
- 14. int MPI_Recv( buf, count, datatype, source, tag, comm, status ) void *buf; /* in */ int
- 15. typedef struct { int count; int MPI_SOURCE; int MPI_TAG; int MPI_ERROR; } MPI_Status; count - число
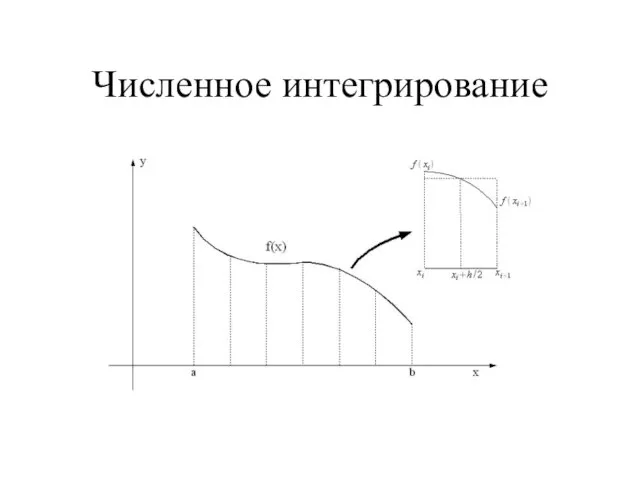
- 16. Численное интегрирование
- 17. MPI-программа численного интегрирования #include #include double f(double x) { return 4./(1 + x * x); }
- 18. MPI-программа численного интегрирования MPI_Init(&argc, &argv); MPI_Comm_rank(MPI_COMM_WORLD, &r); MPI_Comm_size(MPI_COMM_WORLD, &p); if(r == 0) t = MPI_Wtime(); MPI_Barrier(MPI_COMM_WORLD);
- 19. MPI-программа численного интегрирования if(r == 0) { double s; for(i = 0; i MPI_Recv(&s, 1, MPI_DOUBLE,
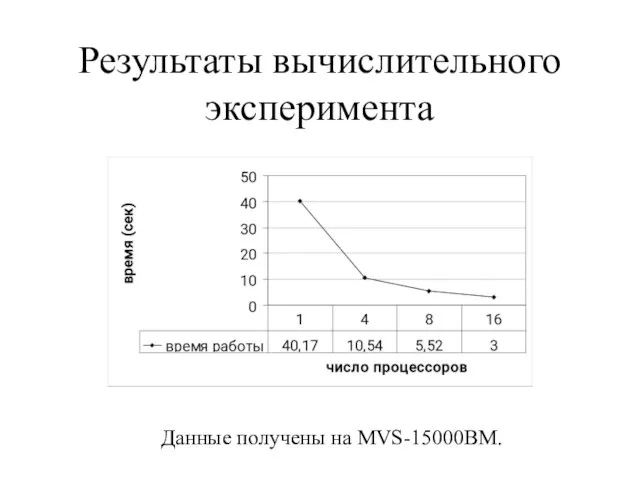
- 20. Результаты вычислительного эксперимента Данные получены на MVS-15000BM.
- 21. Семантика точечных взаимодействий
- 22. Виды точечных взаимодействий
- 24. Буферизованная пересылка Процесс-отправитель выделяет буфер и регистрирует его в системе. Функция MPI_Bsend помещает данные выделенный буфер,
- 25. Буферизованная пересылка int MPI_Bsend(void* buf, int count, MPI_Datatype datatype, int dest, int tag, MPI_Comm comm) Завершается
- 26. Функции работы с буфером обмена int MPI_Buffer_attach( buffer, size ) void *buffer; /* in */ int
- 27. Вычисление размера буфера int MPI_Pack_size(int incount, MPI_Datatype datatype, MPI_Comm comm, int *size) Вычисляет размер памяти для
- 28. Порядок организации буферизованных пересылок Вычислить необходимый объем буфера (MPI_Pack_size). Выделить память под буфер (malloc). Зарегистрировать буфер
- 29. Особенности работы с буфером Буфер всегда один. Для изменения размера буфера сначала следует отменить регистрацию, затем
- 30. MPI_Pack_size(1, MPI_INT, MPI_COMM_WORLD,&msize) blen = M * (msize + MPI_BSEND_OVERHEAD); buf = (int*) malloc(blen); MPI_Buffer_attach(buf, blen);
- 31. Неблокирующие пересылки Предназначены для перекрытия обменов и вычислений. Операция расщепляется на две: инициация и завершение.
- 32. Неблокирующая пересылка int MPI_Isend( buf, count, datatype, dest, tag, comm, request) MPI_Request *request; /* out */
- 33. Завершение: int MPI_Wait (MPI_Request * request, MPI_Status * status) int MPI_Test(MPI_Request *request, int *flag, MPI_Status *status)
- 34. Пример: кольцевой сдвиг данных
- 35. #include "mpi.h" #include int main (argc, argv) int argc; char *argv[]; { int numtasks, rank, next,
- 36. MPI_Irecv (&buf[0], 1, MPI_INT, prev, tag1, MPI_COMM_WORLD, &reqs[0]); MPI_Irecv (&buf[1], 1, MPI_INT, next, tag2, MPI_COMM_WORLD, &reqs[1]);
- 37. Прием по шаблону В качестве параметров source и tag в функции MPI_Recv могут быть использованы константы
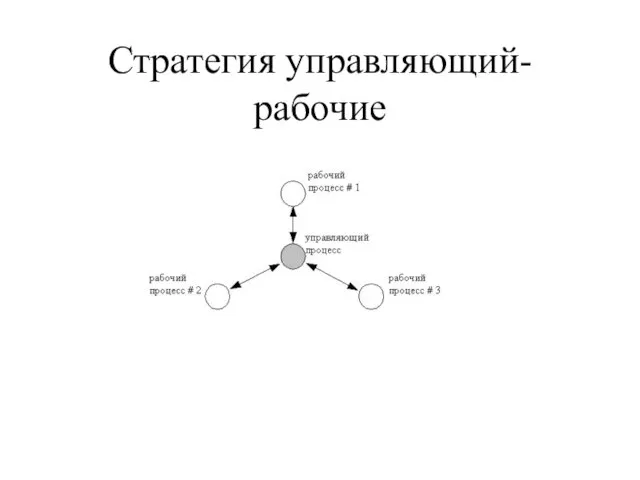
- 38. Стратегия управляющий-рабочие
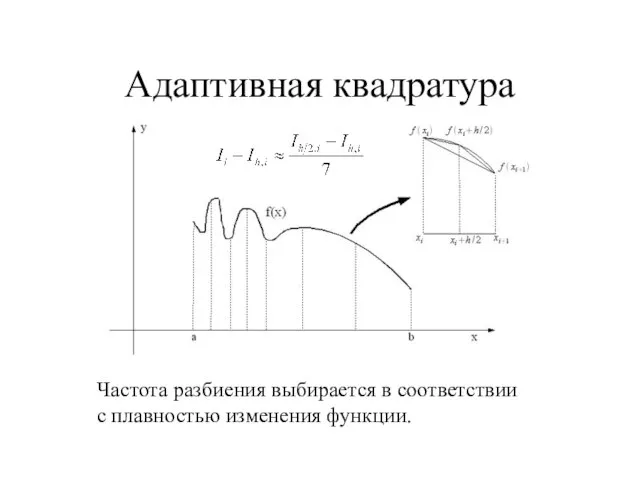
- 39. Адаптивная квадратура Частота разбиения выбирается в соответствии с плавностью изменения функции.
- 40. #include #include #define MYABS(A) (((A) double f(double x) { return sin(1. / x); } ПРИМЕР РЕАЛИЗАЦИИ
- 41. int adint(double (*f) (double), double left, double right, double eps, double *nint) { double mid; double
- 42. double recadint(double (*f)(double), double left, double right, double eps) { double I; if(adint(f, left, right, eps,
- 43. main(int argc, char* argv[]) { int r, p, n = 100000, s = 0; double a
- 44. if(r == 0) { while(s != (p-1)) { double Islave; MPI_Recv(&Islave, 1, MPI_DOUBLE, MPI_ANY_SOURCE, MPI_ANY_TAG, MPI_COMM_WORLD,
- 45. if(r == 0) { t = MPI_Wtime() - t; printf("Integral value: %lf, time = %lf\n", I,
- 46. Результаты экспериментов данные получены на MVS 15000 BM
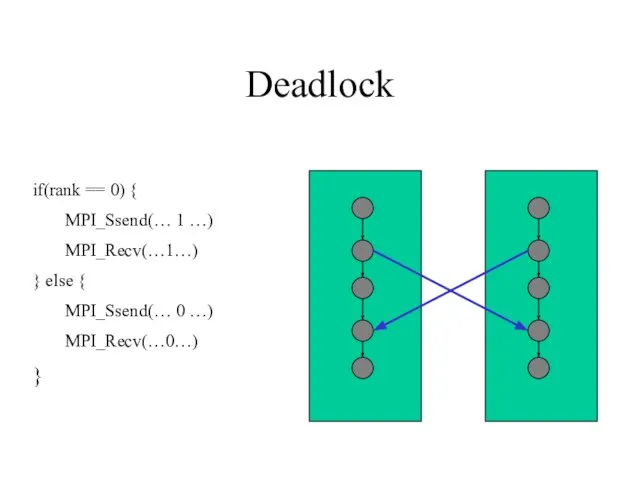
- 47. Deadlock if(rank == 0) { MPI_Ssend(… 1 …) MPI_Recv(…1…) } else { MPI_Ssend(… 0 …) MPI_Recv(…0…)
- 48. «Недетерминированный» deadlock if(rank == 0) { MPI_Send(… 1 …) MPI_Recv(…1…) } else { MPI_Send(… 0 …)
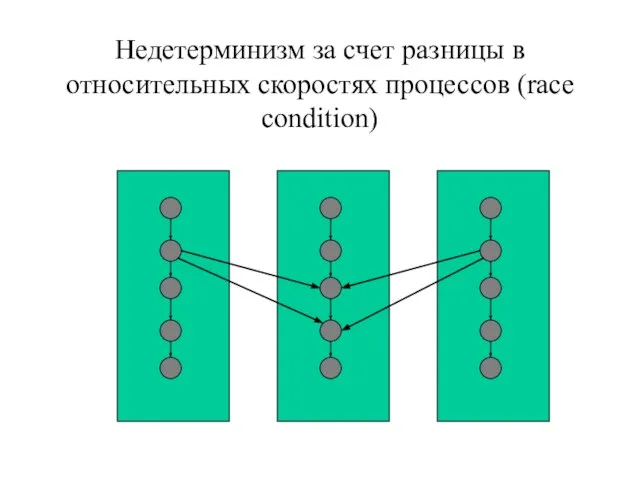
- 49. Недетерминизм за счет разницы в относительных скоростях процессов (race condition)
- 50. Коллективные взаимодействия процессов
- 51. Коллективные взаимодействия процессов MPI предоставляет ряд функций для коллективного взаимодейстия процессов. Эти функции называют коллективными, поскольку
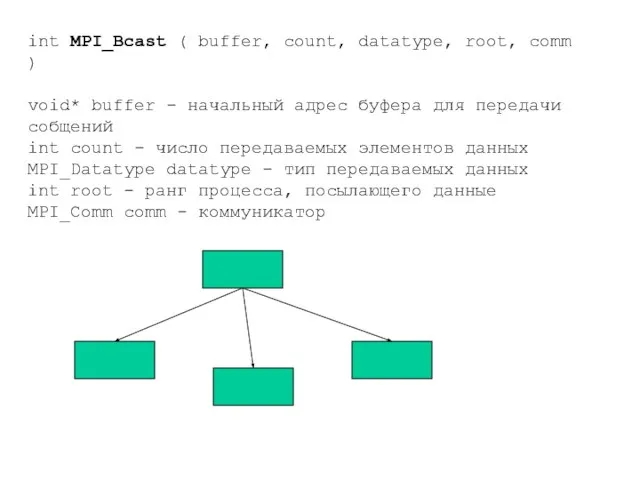
- 52. int MPI_Bcast ( buffer, count, datatype, root, comm ) void* buffer - начальный адрес буфера для
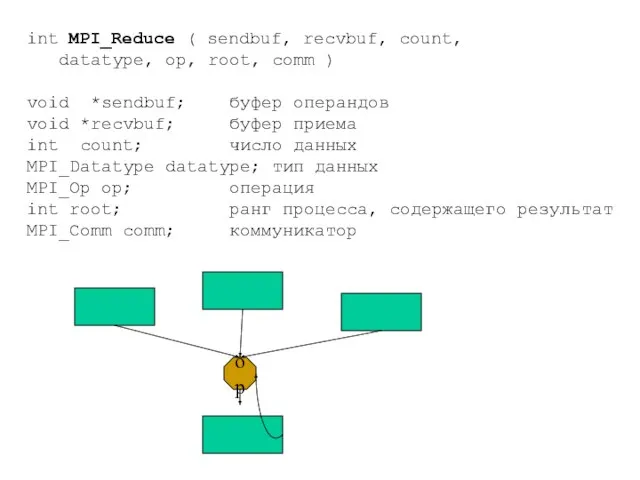
- 53. int MPI_Reduce ( sendbuf, recvbuf, count, datatype, op, root, comm ) void *sendbuf; буфер операндов void
- 54. MPI_MAX максимум MPI_MIN минимум MPI_SUM сумма MPI_PROD произведение MPI_LAND логическое "и" MPI_BAND побитовое "и" MPI_LOR логическое
- 55. Вычисление числа Пи 1 2 3 4 1 2 3 4 1 2 3 4 1
- 56. Вычисление числа Pi #include "mpi.h" #include int main(argc,argv) int argc; char *argv[]; { int n, myid,
- 57. while (1) { if (myid == 0) { printf("Enter the number of intervals: (0 quits) ");
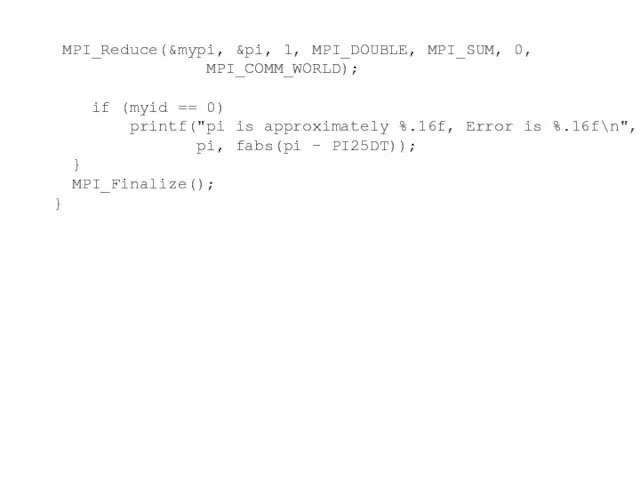
- 58. MPI_Reduce(&mypi, &pi, 1, MPI_DOUBLE, MPI_SUM, 0, MPI_COMM_WORLD); if (myid == 0) printf("pi is approximately %.16f, Error
- 59. Функция синхронизации процессов: int MPI_Barrier ( comm ) ; MPI_Comm comm; Функция синхронизации процессов: int MPI_Barrier
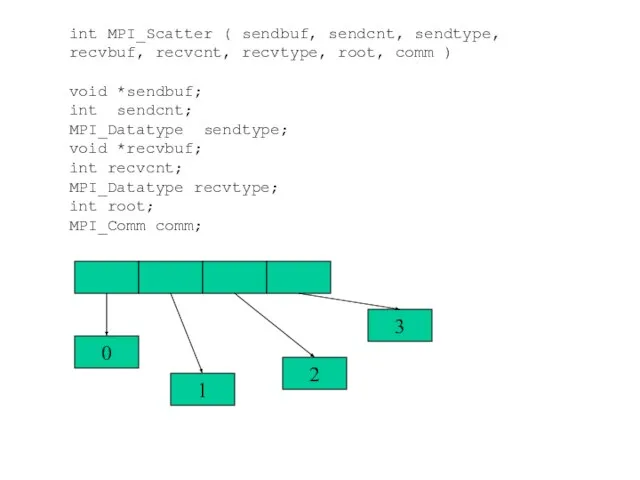
- 60. int MPI_Scatter ( sendbuf, sendcnt, sendtype, recvbuf, recvcnt, recvtype, root, comm ) void *sendbuf; int sendcnt;
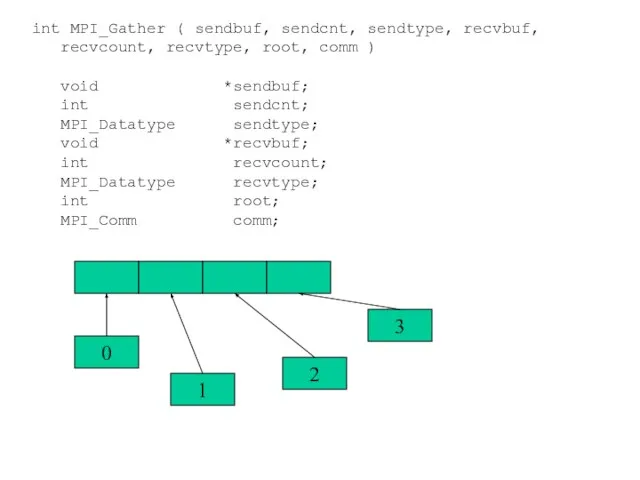
- 61. 0 1 2 3 int MPI_Gather ( sendbuf, sendcnt, sendtype, recvbuf, recvcount, recvtype, root, comm )
- 62. int MPI_Allreduce ( sendbuf, recvbuf, count, datatype, op, comm ) void *sendbuf; void *recvbuf; int count;
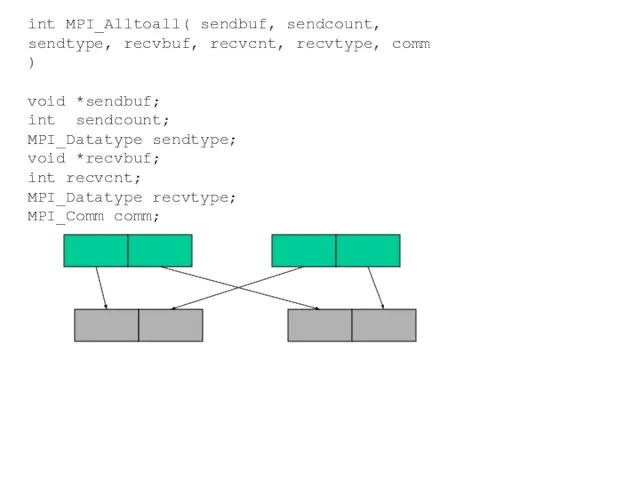
- 63. int MPI_Alltoall( sendbuf, sendcount, sendtype, recvbuf, recvcnt, recvtype, comm ) void *sendbuf; int sendcount; MPI_Datatype sendtype;
- 64. Метод Якоби решения линейных систем , -
- 65. Условие остановки:
- 66. Матричная форма записи
- 67. Условие сходимости Диагональное преобладание – достаточное условие сходимости. Пример:
- 68. Последовательный алгоритм #define MAXITERS 1000 void init(int m, double* B, double* g, double* x) { int
- 69. double evalDiff(double* u, double* v, int m) { int i; double a = 0.0; for(i =
- 70. main(int argc, char* argv[]) { int m, I = 0; double *B, *g, *x, *xold, eps,
- 71. do { int i; for(i = 0; i int j; double a = 0.; double* row
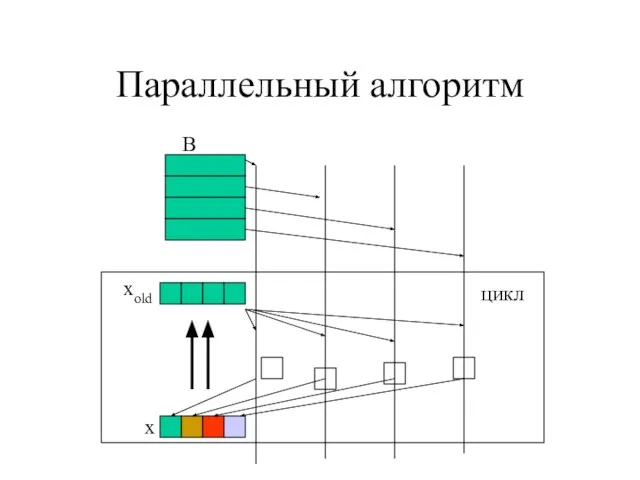
- 72. Параллельный алгоритм B xold x цикл
- 73. main(int argc, char* argv[]) { int m, np, rk, chunk, i, I = 0; double *B,
- 74. MPI_Scatter(B, m * chunk, MPI_DOUBLE, Bloc, m * chunk, MPI_DOUBLE, 0, MPI_COMM_WORLD); MPI_Bcast(g, m, MPI_DOUBLE, 0,
- 75. if(rk == 0) { t = MPI_Wtime() - t; printf("%d iterations consumed %lf sec\n", I, t);
- 76. Группы и коммуникаторы
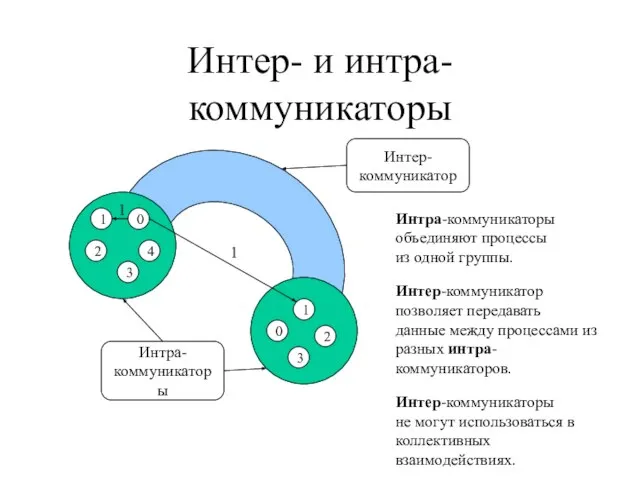
- 77. Интер- и интра-коммуникаторы Интра- коммуникаторы Интер- коммуникатор Интра-коммуникаторы объединяют процессы из одной группы. Интер-коммуникатор позволяет передавать
- 78. Назначение коммуникаторов Поддержка параллельных библиотек. Поддержка коллективных операций на части вычислительного пространства. Повышение уровня абстракции параллельных
- 79. #include "mpi.h" #include double g(double x) { return 4.0 / (1.0 + x * x); }
- 80. int main(int argc, char *argv[]) { int n, myid; double PI25DT = 3.141592653589793238462643; double pi; MPI_Init(&argc,&argv);
- 81. Создание коммуникаторов Разбиение коммуникатора на несколько: int MPI_Comm_split(MPI_Comm comm, int color, int key, MPI_Comm* newcomm) comm
- 82. int main(int argc, char **argv) { int n, myid; double PI25DT = 3.141592653589793238462643; double pi, res;
- 83. if(myid % 2) quad(n, g, comm, &pi); else quad(n, h, comm, &pi); if(myid
- 84. Группы и коммуникаторы Совокупности MPI-процессов образуют группы. Понятие ранга процесса имеет смысл только по отношению к
- 85. Информационные функции для работы с группами Определение размера группы: int MPI_Group_size(MPI_Group group, int *size) group –
- 86. Информационные функции для работы с группами Установление соответствия между номерами процессов в различных группах: int MPI_Group_translate_ranks
- 87. Информационные функции для работы с группами Сравнение двух групп процессов: int MPI_Group_compare(MPI_Group group1,MPI_Group group2, int *result)
- 88. Педопределенные группы: MPI_GROUP_EMPTY – «пустая» группа (не содержит процессов); MPI_GROUP_NULL – «нулевая группа» (не соответствует никакой
- 89. int MPI_Group_free(MPI_Group* group) group – идентификатор освобождаемой группы. Получение коммуникатора по группе: int MPI_Comm_group(MPI_Comm comm, MPI_Group
- 90. Объединение двух групп: int MPI_Group_union(MPI_Group gr1, MPI_Group g2, MPI_Group* gr3) gr1 – первая группа; gr2 –
- 91. Разность двух групп: int MPI_Group_difference(MPI_Group gr1, MPI_Group g2, MPI_Group* gr3) gr1 – первая группа; gr2 –
- 92. Переупорядочивание (с возможным удалением) процессов в существующей группе: int MPI_Group_incl(MPI_Group* group, int n, int* ranks, MPI_Group*
- 93. Удаление процессов из группы: int MPI_Group_excl(MPI_Group* group, int n, int* ranks, MPI_Group* newgroup) group – исходная
- 94. Дублирование коммуникатора Получение дубликата коммуникатора: int MPI_Comm_dup(MPI_Comm comm, MPI_Comm* newcomm) Используется для того, чтобы снабдить библиотечную
- 95. Создание коммуникатора по группе int MPI_Comm_create(MPI_Comm comm, MPI_Group group, MPI_Comm *newcomm) Требования: Конструктор вызывается на всех
- 96. Создание коммуникатора по группе Создание коммуникатора по группе процессов: int MPI_Comm_create(MPI_Comm comm,MPI_Group group, MPI_Comm *newcomm) comm
- 97. Удаление коммуникатора Освобождение коммуникатора: int MPI_Comm_free(MPI_Comm *comm) При освобождении коммуникатора все незавершенные операции будут завершены, только
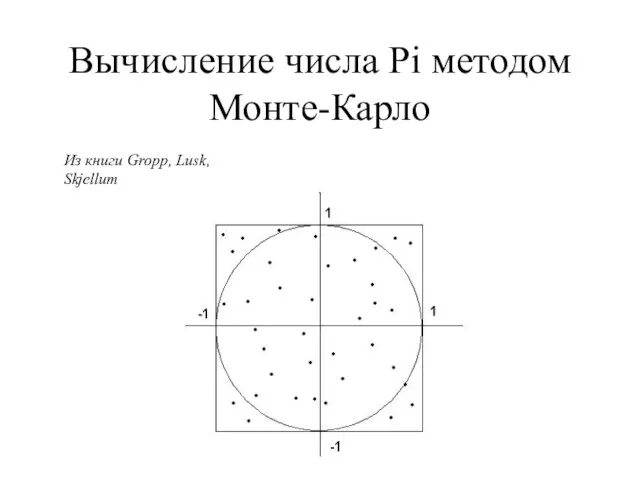
- 98. Вычисление числа Pi методом Монте-Карло Из книги Gropp, Lusk, Skjellum
- 99. Схема вычислений server worker processes коммуникатор workers коммуникатор world
- 100. /* compute pi using Monte Carlo method */ #include #include "mpi.h" #define CHUNKSIZE 1000 #define INT_MAX
- 101. server = numprocs-1; if (myid == 0) sscanf( argv[1], "%lf", &epsilon ); MPI_Bcast( &epsilon, 1, MPI_DOUBLE,
- 102. else { /* I am a worker process */ request = 1; done = in =
- 103. MPI_Allreduce(&in, &totalin, 1, MPI_INT, MPI_SUM, workers); MPI_Allreduce(&out, &totalout, 1, MPI_INT, MPI_SUM, workers); Pi = (4.0*totalin)/(totalin +
- 104. if (myid == 0) { printf( "\npoints: %d\nin: %d, out: %d, to exit\n", totalin+totalout, totalin, totalout
- 105. Система типов сообщений MPI
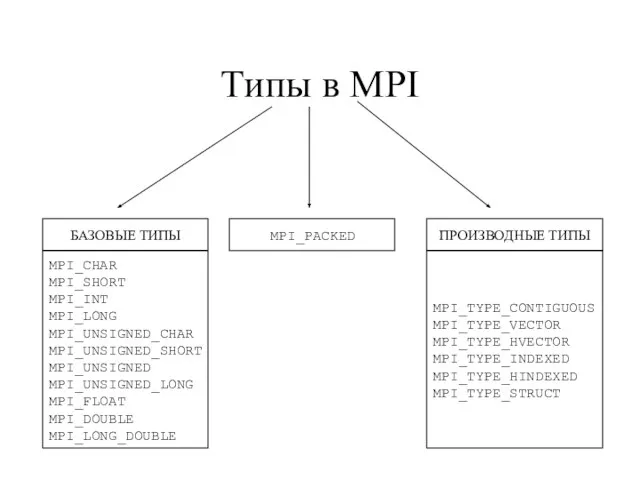
- 106. Типы в MPI БАЗОВЫЕ ТИПЫ MPI_CHAR MPI_SHORT MPI_INT MPI_LONG MPI_UNSIGNED_CHAR MPI_UNSIGNED_SHORT MPI_UNSIGNED MPI_UNSIGNED_LONG MPI_FLOAT MPI_DOUBLE MPI_LONG_DOUBLE
- 107. БАЗОВЫЕ ТИПЫ
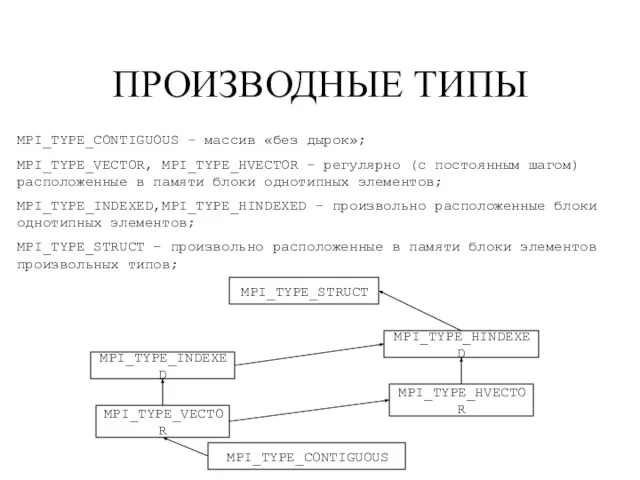
- 108. ПРОИЗВОДНЫЕ ТИПЫ MPI_TYPE_CONTIGUOUS – массив «без дырок»; MPI_TYPE_VECTOR, MPI_TYPE_HVECTOR – регулярно (с постоянным шагом) расположенные в
- 109. Назначение производных типов пересылка данных, расположенных в несмежных областях памяти в одном сообщении; пересылка разнотипных данных
- 110. MPI_TYPE_CONTIGUOUS MPI_Type_contiguous(int count, MPI_Datatype oldtype, MPI_Datatype *newtype) oldtype oldtype oldtype oldtype ... count
- 111. MPI_TYPE_VECTOR MPI_Type_vector(int count, int blocksize, int stride, MPI_Datatype oldtype, MPI_Datatype *newtype) oldtype oldtype oldtype oldtype ...
- 112. Отрицательный шаг oldtype oldtype oldtype oldtype stride = -4 oldtype oldtype oldtype oldtype stride = 4
- 113. MPI_TYPE_INDEXED MPI_Type_indexed(int count, int* blocksizes, int* displacements, MPI_Datatype oldtype, MPI_Datatype *newtype) oldtype oldtype oldtype count (число
- 114. MPI_TYPE_HVECTOR MPI_TYPE_HINDEXED основное отличие: смещение задается в байтах – необходимо знать точные значения размеров и требований
- 115. MPI_TYPE_STRUCT MPI_Type_struct(int count, int* blocksizes, int* displacements, MPI_Datatype *types, MPI_Datatype *newtype) types[0] types[1] count (число блоков)
- 116. РЕГИСТРАЦИЯ ТИПА Регистрация типа: int MPI_Type_commit(MPI_Datatype *datatype) Освобождение памяти: int MPI_Type_free(MPI_Datatype *datatype) типы, которые строились на
- 117. ПОРЯДОК РАБОТЫ С ПРОИЗВОДНЫМИ ТИПАМИ Создание типа с помощью конструктора. Регистрация. Использование. Освобождение памяти.
- 118. КАРТА И СИГНАТУРА ТИПА Карта типа - набор пар (базовый тип, смещение): ((type1, disp1), (type2, disp2),
- 119. СООТВЕТСТВИЕ ТИПОВ Соответствие типов отправителя и получателя: Сигнатура типа пришедшего сообщения является начальной подпоследовательностью сигнатуры типа,
- 120. ПРИМЕРЫ send: MPI_TYPE_VECTOR(3, 1, 2, MPI_DOUBLE) recv: MPI_TYPE_CONTIGUOUS(3, MPI_DOUBLE) double double double double double double send:MPI_TYPE_CONTIGUOUS(6,
- 121. ПРИМЕРЫ send: MPI_TYPE_VECTOR(3, 1, 2, MPI_DOUBLE) recv: MPI_TYPE_CONTIGUOUS(6, MPI_DOUBLE) double double double double double double double
- 122. ПРИМЕРЫ MPI_TYPE_HVECTOR(3, 1, 2, MPI_DOUBLE) MPI_TYPE_VECTOR(3, 1, 2, MPI_DOUBLE) double double double double double double MPI_TYPE_VECTOR(3,
- 123. ТРАНСПОНИРОВАНИЕ МАТРИЦЫ A AT Процесс #1 Процесс #2
- 124. #include #include #define N 3 int A[N][N]; void fill_matrix() { int i,j; for(i = 0; i
- 125. main(int argc, char* argv[]) { int r, i; MPI_Status st; MPI_Datatype typ; MPI_Init(&argc, &argv); MPI_Comm_rank(MPI_COMM_WORLD, &r);
- 126. else if(r == 1){ MPI_Type_vector(N, 1, N, MPI_INT, &typ); MPI_Type_commit(&typ); MPI_Barrier(MPI_COMM_WORLD); for(i = 0; i MPI_Recv(&(A[0][i]),
- 127. РЕЗУЛЬТАТ РАБОТЫ Transposed: 0 3 6 1 4 7 2 5 8 Source: 0 1 2
- 128. if(r == 0) { fill_matrix(); printf("\n Source:\n"); print_matrix(); MPI_Type_contiguous(N * N, MPI_INT, &typ); MPI_Type_commit(&typ); MPI_Barrier(MPI_COMM_WORLD); MPI_Send(&(A[0][0]),
- 129. УПАКОВКА СООБЩЕНИЙ дает возможность пересылать разнородные данные в одном сообщении; отделяет операцию формирования сообщения от операции
- 130. MPI_PACK int MPI_Pack(void* inbuf, int incount, MPI_Datatype datatype, void *outbuf, int outcount, int *position,, MPI_Comm comm)
- 131. MPI_UNPACK int MPI_Unpack(void* inbuf, int insize, int *position, void *outbuf, int outcount, MPI_Datatype datatype, MPI_Comm comm)
- 132. ОПРЕДЕЛЕНИЕ РАЗМЕРА СООБЩЕНИЯ int MPI_Pack_size(int incount, MPI_Datatype datatype, MPI_Comm comm, int *size) incount – число элементов
- 133. ПРИМЕР #include #include #include #define N 3 main(int argc, char* argv[]) { int r; int i;
- 134. ПРИМЕР if(r == 0){ int sz; int pos = 0; int a = 1; void* buf;
- 135. ПРИМЕР else { MPI_Status st; int A[N]; MPI_Recv(A, N, MPI_INT, 0, 0, MPI_COMM_WORLD, &st); for(i =
- 136. ХАРАКТЕРНЫЕ ОШИБКИ В MPI-ПРОГРАММАХ
- 137. ВИДЫ ОШИБОК Ошибки последовательных программ. Ошибки несоответствия типов. Ошибки работы с MPI-объектами. Взаимные блокировки. Недетерминизм.
- 138. Недетерминизм за счет разницы в относительных скоростях процессов (race condition)
- 139. Deadlock if(rank == 0) { MPI_Ssend(… 1 …) MPI_Recv(…1…) } else { MPI_Ssend(… 0 …) MPI_Recv(…0…)
- 141. Скачать презентацию

Слайд 3«Комплект поставки» MPI
Библиотека.
Средства компиляции и запуска приложения.
«Комплект поставки» MPI
Библиотека.
Средства компиляции и запуска приложения.

Слайд 4SPMD-модель.
0
1
2
3
Разные процессы
выполняют разные части
одного и того же кода.
SPMD-модель.
0
1
2
3
Разные процессы
выполняют разные части
одного и того же кода.
Слайд 5Сборка MPI-приложения.
Сборка MPI-приложения осуществляется с помощью
специальной утилиты. В случае Си – mpicc.
Сборка MPI-приложения.
Сборка MPI-приложения осуществляется с помощью
специальной утилиты. В случае Си – mpicc.

Слайд 6MPI “Hello, World”
#include
#include
main(int argc, char* argv[])
{
MPI_Init(&argc, &argv);
printf("Hello,
MPI “Hello, World”
#include
#include
main(int argc, char* argv[])
{
MPI_Init(&argc, &argv);
printf("Hello,
![MPI “Hello, World” #include #include main(int argc, char* argv[]) { MPI_Init(&argc, &argv); printf("Hello, World!\n"); MPI_Finalize(); }](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/450558/slide-5.jpg)
Слайд 7Функции инициализации и завершения работы.
int MPI_Init(int* argc,char*** argv)
argc – указатель на
Функции инициализации и завершения работы.
int MPI_Init(int* argc,char*** argv)
argc – указатель на

Слайд 8Тоже простая MPI-программа
#include
#include
int main( int argc, char *argv[] )
{
int
Тоже простая MPI-программа
#include
#include
int main( int argc, char *argv[] )
{
int
![Тоже простая MPI-программа #include #include int main( int argc, char *argv[] )](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/450558/slide-7.jpg)
Слайд 9Функции определения ранга и числа процессов.
int MPI_Comm_size (MPI_Comm comm, int* size )
Функции определения ранга и числа процессов.
int MPI_Comm_size (MPI_Comm comm, int* size )

Слайд 10Точечные взаимодействия
Точечные взаимодействия

Слайд 11Назначение точечных взаимодействий
Назначение точечных взаимодействий
Слайд 12Пример простейшей пересылки
#include
#include
main(int argc, char* argv[])
{
int rank;
MPI_Status
Пример простейшей пересылки
#include
#include
main(int argc, char* argv[])
{
int rank;
MPI_Status
![Пример простейшей пересылки #include #include main(int argc, char* argv[]) { int rank;](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/450558/slide-11.jpg)
Слайд 13Функции обменов точка-точка
int MPI_Send( buf, count, datatype, dest, tag, comm )
void *buf;
Функции обменов точка-точка
int MPI_Send( buf, count, datatype, dest, tag, comm )
void *buf;

Слайд 14int MPI_Recv( buf, count, datatype, source, tag, comm, status )
void *buf; /*
int MPI_Recv( buf, count, datatype, source, tag, comm, status )
void *buf; /*

Слайд 15typedef struct
{
int count;
int MPI_SOURCE;
int MPI_TAG;
int MPI_ERROR;
} MPI_Status;
count
typedef struct
{
int count;
int MPI_SOURCE;
int MPI_TAG;
int MPI_ERROR;
} MPI_Status;
count

Слайд 16Численное интегрирование
Численное интегрирование
Слайд 17MPI-программа численного интегрирования
#include
#include
double f(double x)
{
return 4./(1 + x *
MPI-программа численного интегрирования
#include
#include
double f(double x)
{
return 4./(1 + x *

Слайд 18MPI-программа численного интегрирования
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &r);
MPI_Comm_size(MPI_COMM_WORLD, &p);
if(r == 0)
MPI-программа численного интегрирования
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &r);
MPI_Comm_size(MPI_COMM_WORLD, &p);
if(r == 0)

Слайд 19MPI-программа численного интегрирования
if(r == 0) {
double s;
for(i =
MPI-программа численного интегрирования
if(r == 0) {
double s;
for(i =

Слайд 20Результаты вычислительного эксперимента
Данные получены на MVS-15000BM.
Результаты вычислительного эксперимента
Данные получены на MVS-15000BM.
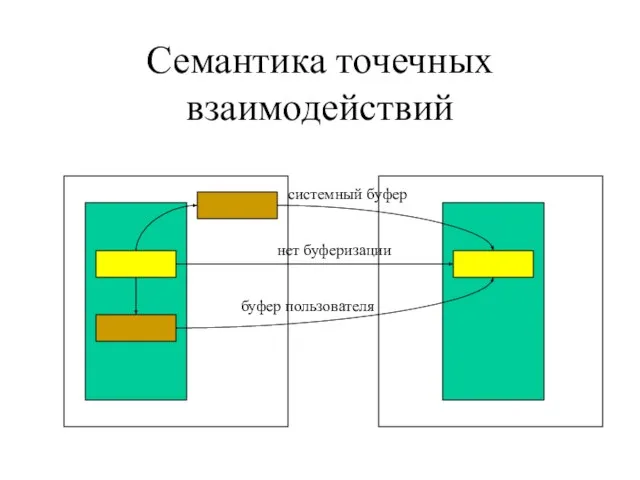
Слайд 21Семантика точечных взаимодействий
Семантика точечных взаимодействий
Слайд 22Виды точечных взаимодействий
Виды точечных взаимодействий


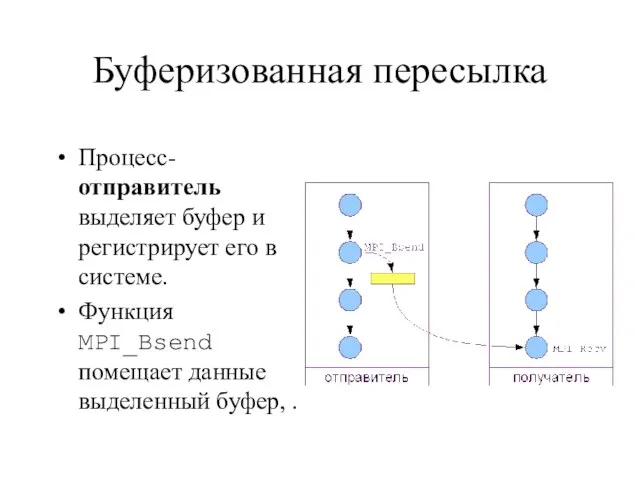
Слайд 24Буферизованная пересылка
Процесс-отправитель выделяет буфер и регистрирует его в системе.
Функция MPI_Bsend помещает данные
Буферизованная пересылка
Процесс-отправитель выделяет буфер и регистрирует его в системе.
Функция MPI_Bsend помещает данные
Слайд 25Буферизованная пересылка
int MPI_Bsend(void* buf, int count, MPI_Datatype datatype, int dest, int tag,
Буферизованная пересылка
int MPI_Bsend(void* buf, int count, MPI_Datatype datatype, int dest, int tag,

Слайд 26Функции работы с буфером обмена
int MPI_Buffer_attach( buffer, size )
void *buffer; /* in
Функции работы с буфером обмена
int MPI_Buffer_attach( buffer, size )
void *buffer; /* in

Слайд 27Вычисление размера буфера
int MPI_Pack_size(int incount, MPI_Datatype datatype, MPI_Comm comm, int *size)
Вычисляет
Вычисление размера буфера
int MPI_Pack_size(int incount, MPI_Datatype datatype, MPI_Comm comm, int *size)
Вычисляет

Слайд 28Порядок организации буферизованных пересылок
Вычислить необходимый объем буфера (MPI_Pack_size).
Выделить память под буфер (malloc).
Зарегистрировать
Порядок организации буферизованных пересылок
Вычислить необходимый объем буфера (MPI_Pack_size).
Выделить память под буфер (malloc).
Зарегистрировать

Слайд 29Особенности работы с буфером
Буфер всегда один.
Для изменения размера буфера сначала следует
Особенности работы с буфером
Буфер всегда один.
Для изменения размера буфера сначала следует

Слайд 30 MPI_Pack_size(1, MPI_INT, MPI_COMM_WORLD,&msize)
blen = M * (msize + MPI_BSEND_OVERHEAD);
buf = (int*) malloc(blen);
MPI_Buffer_attach(buf,
MPI_Pack_size(1, MPI_INT, MPI_COMM_WORLD,&msize)
blen = M * (msize + MPI_BSEND_OVERHEAD);
buf = (int*) malloc(blen);
MPI_Buffer_attach(buf,

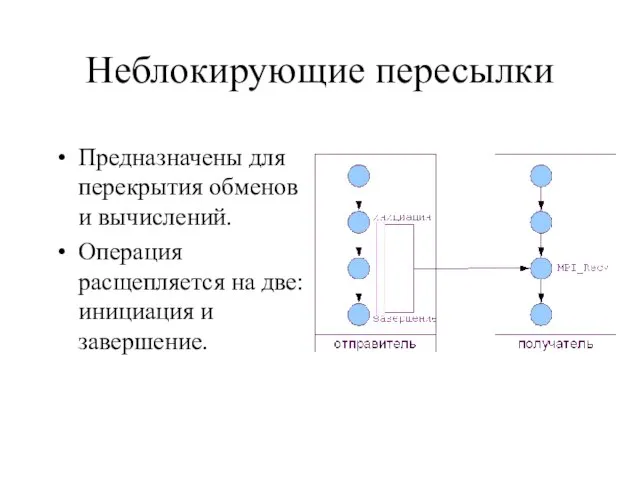
Слайд 31Неблокирующие пересылки
Предназначены для перекрытия обменов и вычислений.
Операция расщепляется на две: инициация и
Неблокирующие пересылки
Предназначены для перекрытия обменов и вычислений.
Операция расщепляется на две: инициация и
Слайд 32Неблокирующая пересылка
int MPI_Isend( buf, count, datatype, dest, tag, comm, request)
MPI_Request *request;
Неблокирующая пересылка
int MPI_Isend( buf, count, datatype, dest, tag, comm, request)
MPI_Request *request;

Слайд 33Завершение:
int MPI_Wait (MPI_Request * request, MPI_Status * status)
int MPI_Test(MPI_Request *request, int *flag,
Завершение:
int MPI_Wait (MPI_Request * request, MPI_Status * status)
int MPI_Test(MPI_Request *request, int *flag,

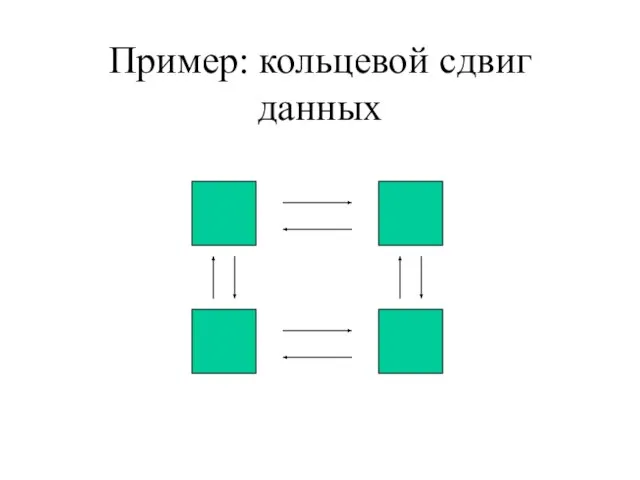
Слайд 34Пример: кольцевой сдвиг данных
Пример: кольцевой сдвиг данных
Слайд 35#include "mpi.h"
#include
int
main (argc, argv)
int argc;
char *argv[];
{
int numtasks, rank,
#include "mpi.h"
#include
int
main (argc, argv)
int argc;
char *argv[];
{
int numtasks, rank,
![#include "mpi.h" #include int main (argc, argv) int argc; char *argv[]; {](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/450558/slide-34.jpg)
Слайд 36 MPI_Irecv (&buf[0], 1, MPI_INT, prev, tag1,
MPI_COMM_WORLD, &reqs[0]);
MPI_Irecv (&buf[1], 1,
MPI_Irecv (&buf[0], 1, MPI_INT, prev, tag1,
MPI_COMM_WORLD, &reqs[0]);
MPI_Irecv (&buf[1], 1,
![MPI_Irecv (&buf[0], 1, MPI_INT, prev, tag1, MPI_COMM_WORLD, &reqs[0]); MPI_Irecv (&buf[1], 1, MPI_INT,](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/450558/slide-35.jpg)
Слайд 37Прием по шаблону
В качестве параметров source и tag в функции MPI_Recv могут
Прием по шаблону
В качестве параметров source и tag в функции MPI_Recv могут

Слайд 38Стратегия управляющий-рабочие
Стратегия управляющий-рабочие
Слайд 39Адаптивная квадратура
Частота разбиения выбирается в соответствии с плавностью изменения функции.
Адаптивная квадратура
Частота разбиения выбирается в соответствии с плавностью изменения функции.
Слайд 40#include
#include
#define MYABS(A) (((A) < 0) ? (-(A)) : (A))
double f(double
#include
double f(double

Слайд 41int adint(double (*f) (double), double left, double right, double eps, double *nint)
{
int adint(double (*f) (double), double left, double right, double eps, double *nint) {

Слайд 42double recadint(double (*f)(double), double left, double right, double eps)
{
double I;
if(adint(f,
double recadint(double (*f)(double), double left, double right, double eps) { double I; if(adint(f,

Слайд 43main(int argc, char* argv[])
{
int r, p, n = 100000, s =
main(int argc, char* argv[]) { int r, p, n = 100000, s =
![main(int argc, char* argv[]) { int r, p, n = 100000, s](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/450558/slide-42.jpg)
Слайд 44 if(r == 0) {
while(s != (p-1)) {
double Islave;
MPI_Recv(&Islave,
if(r == 0) { while(s != (p-1)) { double Islave; MPI_Recv(&Islave,

Слайд 45 if(r == 0) {
t = MPI_Wtime() - t;
printf("Integral value:
if(r == 0) { t = MPI_Wtime() - t; printf("Integral value:

Слайд 46Результаты экспериментов
данные получены на MVS 15000 BM
Результаты экспериментов
данные получены на MVS 15000 BM

Слайд 47Deadlock
if(rank == 0) {
MPI_Ssend(… 1 …)
MPI_Recv(…1…)
} else {
MPI_Ssend(… 0 …)
MPI_Recv(…0…)
}
Deadlock
if(rank == 0) {
MPI_Ssend(… 1 …)
MPI_Recv(…1…)
} else {
MPI_Ssend(… 0 …)
MPI_Recv(…0…)
}
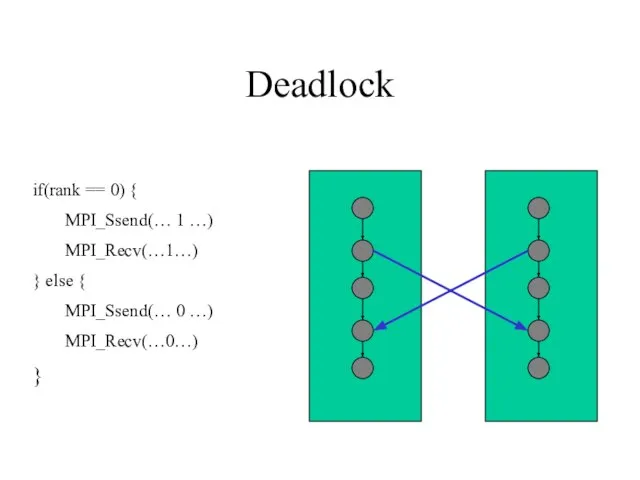
Слайд 48«Недетерминированный» deadlock
if(rank == 0) {
MPI_Send(… 1 …)
MPI_Recv(…1…)
} else {
MPI_Send(… 0 …)
MPI_Recv(…0…)
}
«Недетерминированный» deadlock
if(rank == 0) {
MPI_Send(… 1 …)
MPI_Recv(…1…)
} else {
MPI_Send(… 0 …)
MPI_Recv(…0…)
}
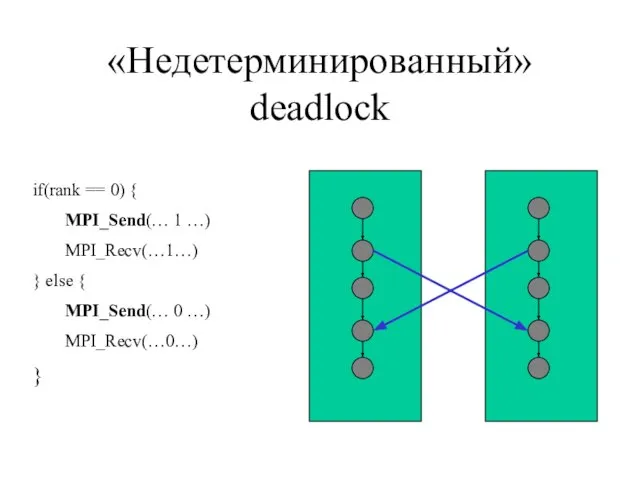
Слайд 49Недетерминизм за счет разницы в относительных скоростях процессов (race condition)
Недетерминизм за счет разницы в относительных скоростях процессов (race condition)
Слайд 50Коллективные взаимодействия процессов
Коллективные взаимодействия процессов

Слайд 51Коллективные взаимодействия процессов
MPI предоставляет ряд функций для коллективного
взаимодейстия процессов.
Эти функции
Коллективные взаимодействия процессов
MPI предоставляет ряд функций для коллективного
взаимодейстия процессов.
Эти функции

Слайд 52int MPI_Bcast ( buffer, count, datatype, root, comm )
void* buffer - начальный
int MPI_Bcast ( buffer, count, datatype, root, comm )
void* buffer - начальный
Слайд 53int MPI_Reduce ( sendbuf, recvbuf, count,
datatype, op, root, comm )
void *sendbuf;
int MPI_Reduce ( sendbuf, recvbuf, count,
datatype, op, root, comm )
void *sendbuf;
Слайд 54MPI_MAX максимум
MPI_MIN минимум
MPI_SUM сумма
MPI_PROD произведение
MPI_LAND логическое "и"
MPI_BAND побитовое "и"
MPI_LOR логическое "или"
MPI_BOR
MPI_MAX максимум
MPI_MIN минимум
MPI_SUM сумма
MPI_PROD произведение
MPI_LAND логическое "и"
MPI_BAND побитовое "и"
MPI_LOR логическое "или"
MPI_BOR

Слайд 55Вычисление числа Пи
1
2
3
4
1
2
3
4
1
2
3
4
1
Вычисление числа Пи
1
2
3
4
1
2
3
4
1
2
3
4
1
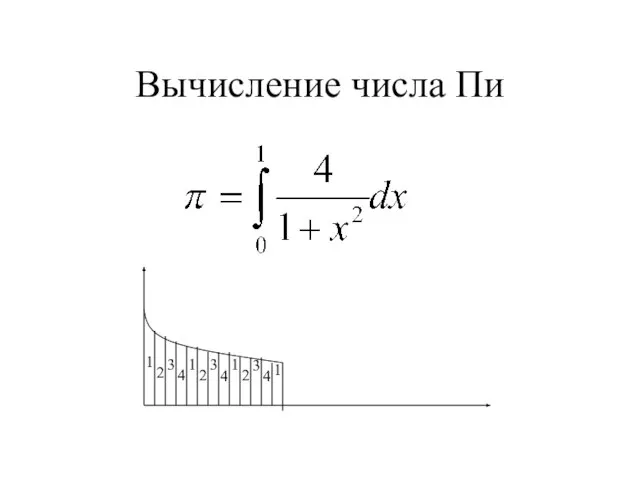
Слайд 56Вычисление числа Pi
#include "mpi.h"
#include
int main(argc,argv)
int argc;
char *argv[];
Вычисление числа Pi
#include "mpi.h"
#include
int main(argc,argv)
int argc;
char *argv[];
![Вычисление числа Pi #include "mpi.h" #include int main(argc,argv) int argc; char *argv[];](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/450558/slide-55.jpg)
Слайд 57
while (1)
{
if (myid == 0) {
while (1)
{
if (myid == 0) {

Слайд 58 MPI_Reduce(&mypi, &pi, 1, MPI_DOUBLE, MPI_SUM, 0,
MPI_COMM_WORLD);
if (myid ==
MPI_Reduce(&mypi, &pi, 1, MPI_DOUBLE, MPI_SUM, 0,
MPI_COMM_WORLD);
if (myid ==
Слайд 59Функция синхронизации процессов:
int MPI_Barrier ( comm ) ;
MPI_Comm comm;
Функция синхронизации процессов:
int
Функция синхронизации процессов:
int MPI_Barrier ( comm ) ;
MPI_Comm comm;
Функция синхронизации процессов:
int

Слайд 60int MPI_Scatter ( sendbuf, sendcnt, sendtype,
recvbuf, recvcnt, recvtype, root, comm )
void
int MPI_Scatter ( sendbuf, sendcnt, sendtype,
recvbuf, recvcnt, recvtype, root, comm )
void
Слайд 610
1
2
3
int MPI_Gather ( sendbuf, sendcnt, sendtype, recvbuf,
recvcount, recvtype, root, comm
0
1
2
3
int MPI_Gather ( sendbuf, sendcnt, sendtype, recvbuf,
recvcount, recvtype, root, comm
Слайд 62int MPI_Allreduce ( sendbuf, recvbuf, count, datatype, op,
comm )
void *sendbuf;
void *recvbuf;
int
int MPI_Allreduce ( sendbuf, recvbuf, count, datatype, op,
comm )
void *sendbuf;
void *recvbuf;
int

Слайд 63int MPI_Alltoall( sendbuf, sendcount,
sendtype, recvbuf, recvcnt, recvtype, comm )
void *sendbuf;
int sendcount;
MPI_Datatype
int MPI_Alltoall( sendbuf, sendcount,
sendtype, recvbuf, recvcnt, recvtype, comm )
void *sendbuf;
int sendcount;
MPI_Datatype
Слайд 64Метод Якоби решения линейных систем
, -
Метод Якоби решения линейных систем
, -

Слайд 65Условие остановки:
Условие остановки:
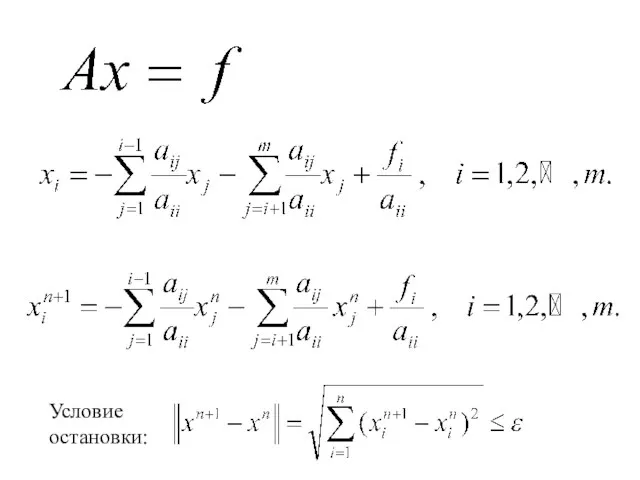
Слайд 66Матричная форма записи
Матричная форма записи

Слайд 67Условие сходимости
Диагональное преобладание – достаточное условие сходимости.
Пример:
Условие сходимости
Диагональное преобладание – достаточное условие сходимости.
Пример:

Слайд 68Последовательный алгоритм
#define MAXITERS 1000
void init(int m, double* B, double* g, double* x)
{
Последовательный алгоритм
#define MAXITERS 1000
void init(int m, double* B, double* g, double* x)
{

Слайд 69double evalDiff(double* u, double* v, int m)
{
int i;
double a =
double evalDiff(double* u, double* v, int m)
{
int i;
double a =

Слайд 70main(int argc, char* argv[])
{
int m, I = 0;
double *B, *g,
main(int argc, char* argv[])
{
int m, I = 0;
double *B, *g,
![main(int argc, char* argv[]) { int m, I = 0; double *B,](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/450558/slide-69.jpg)
Слайд 71do {
int i;
for(i = 0; i < m; i
do {
int i;
for(i = 0; i < m; i

Слайд 72Параллельный алгоритм
B
xold
x
цикл
Параллельный алгоритм
B
xold
x
цикл
Слайд 73main(int argc, char* argv[])
{
int m, np, rk, chunk, i, I =
main(int argc, char* argv[])
{
int m, np, rk, chunk, i, I =
![main(int argc, char* argv[]) { int m, np, rk, chunk, i, I](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/450558/slide-72.jpg)
Слайд 74 MPI_Scatter(B, m * chunk, MPI_DOUBLE,
Bloc, m * chunk, MPI_DOUBLE,
MPI_Scatter(B, m * chunk, MPI_DOUBLE,
Bloc, m * chunk, MPI_DOUBLE,

Слайд 75
if(rk == 0) {
t = MPI_Wtime() - t;
printf("%d
if(rk == 0) {
t = MPI_Wtime() - t;
printf("%d

Слайд 76Группы и коммуникаторы
Группы и коммуникаторы

Слайд 77Интер- и интра-коммуникаторы
Интра-
коммуникаторы
Интер-
коммуникатор
Интра-коммуникаторы
объединяют процессы
из одной группы.
Интер-коммуникатор
позволяет передавать
данные между процессами
Интер- и интра-коммуникаторы
Интра-
коммуникаторы
Интер-
коммуникатор
Интра-коммуникаторы
объединяют процессы
из одной группы.
Интер-коммуникатор
позволяет передавать
данные между процессами
Слайд 78Назначение коммуникаторов
Поддержка параллельных библиотек.
Поддержка коллективных операций на части вычислительного пространства.
Повышение уровня абстракции
Назначение коммуникаторов
Поддержка параллельных библиотек.
Поддержка коллективных операций на части вычислительного пространства.
Повышение уровня абстракции

Слайд 79#include "mpi.h"
#include
double g(double x)
{
return 4.0 / (1.0 +
#include "mpi.h"
#include

Слайд 80int main(int argc, char *argv[])
{ int n, myid; double PI25DT = 3.141592653589793238462643;
int main(int argc, char *argv[]) { int n, myid; double PI25DT = 3.141592653589793238462643;
![int main(int argc, char *argv[]) { int n, myid; double PI25DT =](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/450558/slide-79.jpg)
Слайд 81Создание коммуникаторов
Разбиение коммуникатора на несколько:
int MPI_Comm_split(MPI_Comm comm, int color, int key,
Создание коммуникаторов
Разбиение коммуникатора на несколько:
int MPI_Comm_split(MPI_Comm comm, int color, int key,

Слайд 82int main(int argc, char **argv)
{ int n, myid; double PI25DT =
int main(int argc, char **argv) { int n, myid; double PI25DT =

Слайд 83if(myid % 2)
quad(n, g, comm, &pi);
else
quad(n, h, comm, &pi);
if(myid % 2)
quad(n, g, comm, &pi);
else
quad(n, h, comm, &pi);

Слайд 84Группы и коммуникаторы
Совокупности MPI-процессов образуют группы.
Понятие ранга процесса имеет смысл только
Группы и коммуникаторы
Совокупности MPI-процессов образуют группы.
Понятие ранга процесса имеет смысл только

Слайд 85Информационные функции для работы с группами
Определение размера группы:
int MPI_Group_size(MPI_Group group, int *size)
group
Информационные функции для работы с группами
Определение размера группы:
int MPI_Group_size(MPI_Group group, int *size)
group

Слайд 86Информационные функции для работы с группами
Установление соответствия между номерами процессов в различных
Информационные функции для работы с группами
Установление соответствия между номерами процессов в различных

Слайд 87Информационные функции для работы с группами
Сравнение двух групп процессов:
int MPI_Group_compare(MPI_Group group1,MPI_Group group2,
Информационные функции для работы с группами
Сравнение двух групп процессов:
int MPI_Group_compare(MPI_Group group1,MPI_Group group2,

Слайд 88Педопределенные группы:
MPI_GROUP_EMPTY – «пустая» группа (не содержит процессов);
MPI_GROUP_NULL – «нулевая группа» (не
MPI_GROUP_EMPTY – «пустая» группа (не содержит процессов);
MPI_GROUP_NULL – «нулевая группа» (не

Слайд 89int MPI_Group_free(MPI_Group* group)
group – идентификатор освобождаемой группы.
Получение коммуникатора по группе:
int MPI_Comm_group(MPI_Comm
group – идентификатор освобождаемой группы.
Получение коммуникатора по группе:
int MPI_Comm_group(MPI_Comm

Слайд 90Объединение двух групп:
int MPI_Group_union(MPI_Group gr1, MPI_Group g2, MPI_Group* gr3)
gr1 – первая группа;
gr2
Объединение двух групп:
int MPI_Group_union(MPI_Group gr1, MPI_Group g2, MPI_Group* gr3)
gr1 – первая группа;
gr2

Слайд 91Разность двух групп:
int MPI_Group_difference(MPI_Group gr1, MPI_Group g2, MPI_Group* gr3)
gr1 – первая группа;
gr2
Разность двух групп:
int MPI_Group_difference(MPI_Group gr1, MPI_Group g2, MPI_Group* gr3)
gr1 – первая группа;
gr2

Слайд 92Переупорядочивание (с возможным удалением) процессов в существующей группе:
int MPI_Group_incl(MPI_Group* group, int n,
Переупорядочивание (с возможным удалением) процессов в существующей группе:
int MPI_Group_incl(MPI_Group* group, int n,

Слайд 93
Удаление процессов из группы:
int MPI_Group_excl(MPI_Group* group, int n, int* ranks, MPI_Group* newgroup)
group
Удаление процессов из группы:
int MPI_Group_excl(MPI_Group* group, int n, int* ranks, MPI_Group* newgroup)
group

Слайд 94Дублирование коммуникатора
Получение дубликата коммуникатора:
int MPI_Comm_dup(MPI_Comm comm, MPI_Comm* newcomm)
Используется для того, чтобы
Дублирование коммуникатора
Получение дубликата коммуникатора:
int MPI_Comm_dup(MPI_Comm comm, MPI_Comm* newcomm)
Используется для того, чтобы

Слайд 95Создание коммуникатора по группе
int MPI_Comm_create(MPI_Comm comm, MPI_Group group, MPI_Comm *newcomm)
Требования:
Конструктор
Создание коммуникатора по группе
int MPI_Comm_create(MPI_Comm comm, MPI_Group group, MPI_Comm *newcomm)
Требования:
Конструктор

Слайд 96Создание коммуникатора по группе
Создание коммуникатора по группе процессов:
int MPI_Comm_create(MPI_Comm comm,MPI_Group group, MPI_Comm
Создание коммуникатора по группе
Создание коммуникатора по группе процессов:
int MPI_Comm_create(MPI_Comm comm,MPI_Group group, MPI_Comm

Слайд 97Удаление коммуникатора
Освобождение коммуникатора:
int MPI_Comm_free(MPI_Comm *comm)
При освобождении коммуникатора все незавершенные операции
Удаление коммуникатора
Освобождение коммуникатора:
int MPI_Comm_free(MPI_Comm *comm)
При освобождении коммуникатора все незавершенные операции

Слайд 98Вычисление числа Pi методом Монте-Карло
Из книги Gropp, Lusk, Skjellum
Вычисление числа Pi методом Монте-Карло
Из книги Gropp, Lusk, Skjellum
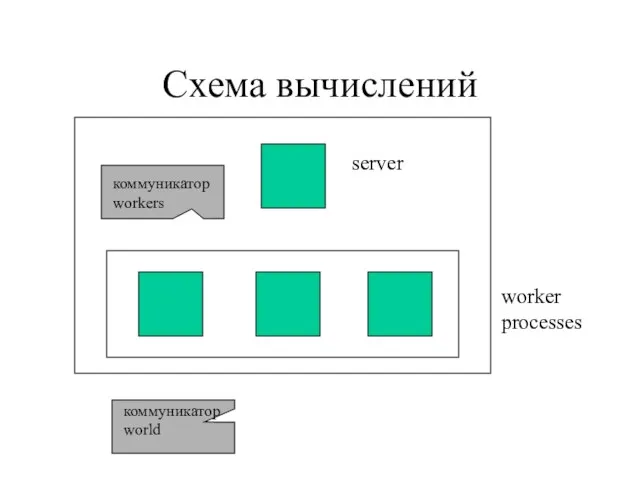
Слайд 99Схема вычислений
server
worker
processes
коммуникатор
workers
коммуникатор
world
Схема вычислений
server
worker
processes
коммуникатор
workers
коммуникатор
world
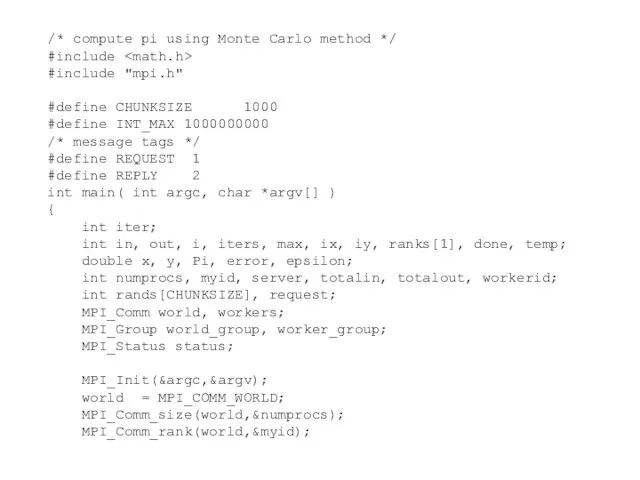
Слайд 100/* compute pi using Monte Carlo method */
#include
#include "mpi.h"
#define CHUNKSIZE 1000
#define
/* compute pi using Monte Carlo method */
#include
#include "mpi.h"
#define CHUNKSIZE 1000
#define
Слайд 101 server = numprocs-1;
if (myid == 0) sscanf( argv[1], "%lf",
server = numprocs-1;
if (myid == 0) sscanf( argv[1], "%lf",
![server = numprocs-1; if (myid == 0) sscanf( argv[1], "%lf", &epsilon );](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/450558/slide-100.jpg)
Слайд 102 else { /* I am a worker process */
request = 1;
else { /* I am a worker process */
request = 1;

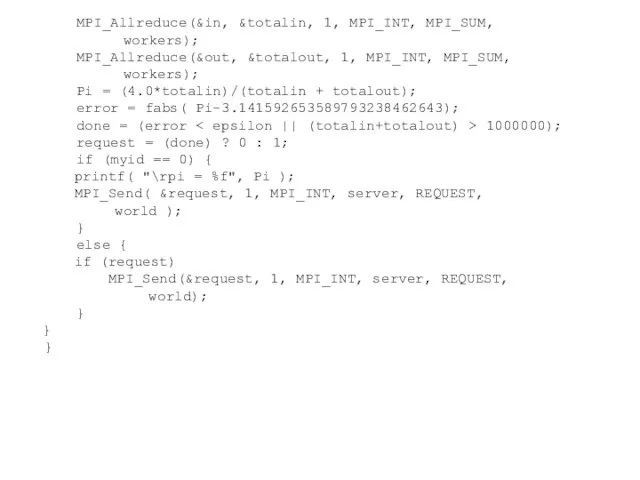
Слайд 103 MPI_Allreduce(&in, &totalin, 1, MPI_INT, MPI_SUM,
workers);
MPI_Allreduce(&out, &totalout, 1, MPI_INT, MPI_SUM,
MPI_Allreduce(&in, &totalin, 1, MPI_INT, MPI_SUM,
workers);
MPI_Allreduce(&out, &totalout, 1, MPI_INT, MPI_SUM,
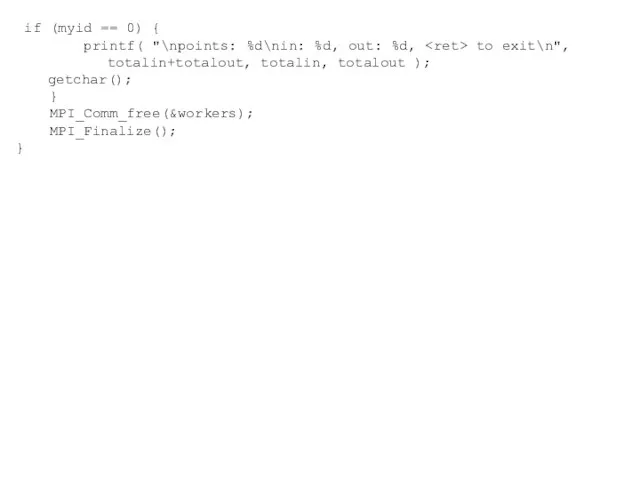
Слайд 104 if (myid == 0) {
printf( "\npoints: %d\nin: %d, out: %d,
if (myid == 0) {
printf( "\npoints: %d\nin: %d, out: %d,
Слайд 105Система типов сообщений MPI
Система типов сообщений MPI

Слайд 106Типы в MPI
БАЗОВЫЕ ТИПЫ
MPI_CHAR
MPI_SHORT
MPI_INT
MPI_LONG
MPI_UNSIGNED_CHAR
MPI_UNSIGNED_SHORT
MPI_UNSIGNED
MPI_UNSIGNED_LONG
MPI_FLOAT
Типы в MPI
БАЗОВЫЕ ТИПЫ
MPI_CHAR MPI_SHORT MPI_INT MPI_LONG MPI_UNSIGNED_CHAR MPI_UNSIGNED_SHORT MPI_UNSIGNED MPI_UNSIGNED_LONG MPI_FLOAT
Слайд 107БАЗОВЫЕ ТИПЫ
БАЗОВЫЕ ТИПЫ

Слайд 108ПРОИЗВОДНЫЕ ТИПЫ
MPI_TYPE_CONTIGUOUS – массив «без дырок»;
MPI_TYPE_VECTOR, MPI_TYPE_HVECTOR – регулярно (с постоянным шагом)
ПРОИЗВОДНЫЕ ТИПЫ
MPI_TYPE_CONTIGUOUS – массив «без дырок»;
MPI_TYPE_VECTOR, MPI_TYPE_HVECTOR – регулярно (с постоянным шагом)
Слайд 109Назначение производных типов
пересылка данных, расположенных в несмежных областях памяти в одном сообщении;
пересылка
Назначение производных типов
пересылка данных, расположенных в несмежных областях памяти в одном сообщении;
пересылка

Слайд 110MPI_TYPE_CONTIGUOUS
MPI_Type_contiguous(int count, MPI_Datatype oldtype, MPI_Datatype *newtype)
oldtype
oldtype
oldtype
oldtype
...
count
MPI_TYPE_CONTIGUOUS
MPI_Type_contiguous(int count, MPI_Datatype oldtype, MPI_Datatype *newtype)
oldtype
oldtype
oldtype
oldtype
...
count

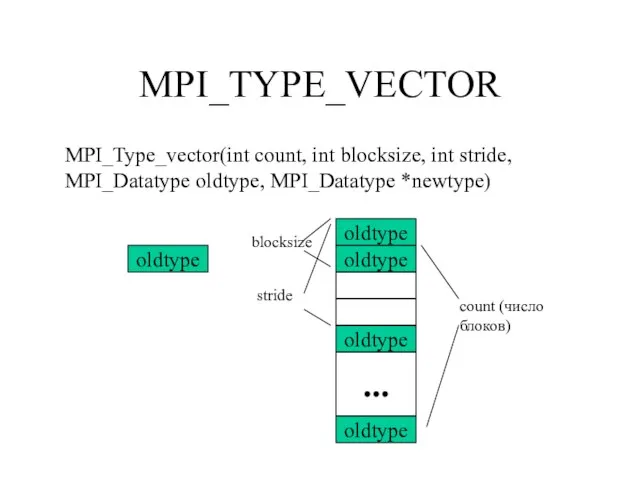
Слайд 111MPI_TYPE_VECTOR
MPI_Type_vector(int count, int blocksize, int stride, MPI_Datatype oldtype, MPI_Datatype *newtype)
oldtype
oldtype
oldtype
oldtype
...
count (число блоков)
oldtype
stride
blocksize
MPI_TYPE_VECTOR
MPI_Type_vector(int count, int blocksize, int stride, MPI_Datatype oldtype, MPI_Datatype *newtype)
oldtype
oldtype
oldtype
oldtype
...
count (число блоков)
oldtype
stride
blocksize
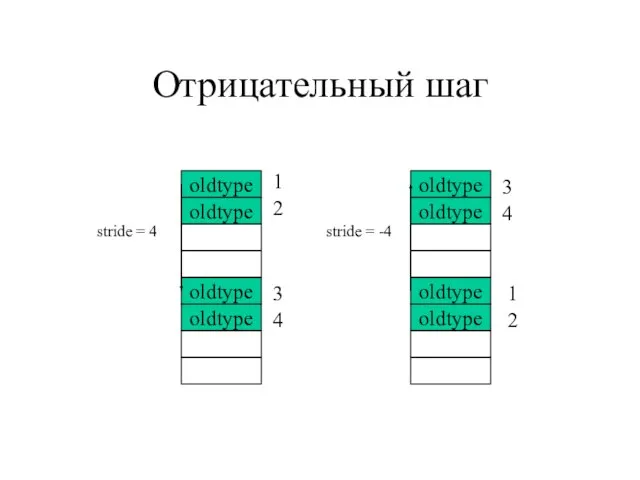
Слайд 112Отрицательный шаг
oldtype
oldtype
oldtype
oldtype
stride = -4
oldtype
oldtype
oldtype
oldtype
stride = 4
1
2
3
4
3
4
1
2
Отрицательный шаг
oldtype
oldtype
oldtype
oldtype
stride = -4
oldtype
oldtype
oldtype
oldtype
stride = 4
1
2
3
4
3
4
1
2
Слайд 113MPI_TYPE_INDEXED
MPI_Type_indexed(int count, int* blocksizes, int* displacements, MPI_Datatype oldtype, MPI_Datatype *newtype)
oldtype
oldtype
oldtype
count (число блоков)
oldtype
oldtype
oldtype
blocksizes[0]
blocksizes[1]
displacements[1]
displacements[0]
start
MPI_TYPE_INDEXED
MPI_Type_indexed(int count, int* blocksizes, int* displacements, MPI_Datatype oldtype, MPI_Datatype *newtype)
oldtype
oldtype
oldtype
count (число блоков)
oldtype
oldtype
oldtype
blocksizes[0]
blocksizes[1]
displacements[1]
displacements[0]
start
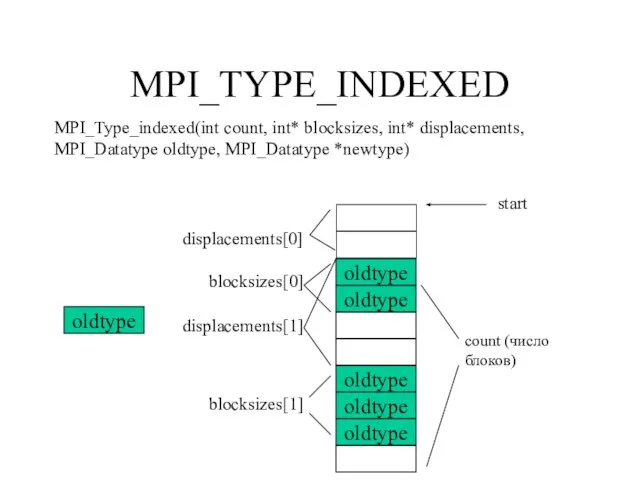
Слайд 114MPI_TYPE_HVECTOR
MPI_TYPE_HINDEXED
основное отличие: смещение задается в байтах –
необходимо знать точные значения размеров и
MPI_TYPE_HVECTOR
MPI_TYPE_HINDEXED
основное отличие: смещение задается в байтах –
необходимо знать точные значения размеров и

Слайд 115MPI_TYPE_STRUCT
MPI_Type_struct(int count, int* blocksizes, int* displacements, MPI_Datatype *types, MPI_Datatype *newtype)
types[0]
types[1]
count (число блоков)
types[0]
types[1]
types[1]
blocksizes[0]
blocksizes[1]
displacements[1]
displacements[0]
смещения
MPI_TYPE_STRUCT
MPI_Type_struct(int count, int* blocksizes, int* displacements, MPI_Datatype *types, MPI_Datatype *newtype)
types[0]
types[1]
count (число блоков)
types[0]
types[1]
types[1]
blocksizes[0]
blocksizes[1]
displacements[1]
displacements[0]
смещения
![MPI_TYPE_STRUCT MPI_Type_struct(int count, int* blocksizes, int* displacements, MPI_Datatype *types, MPI_Datatype *newtype) types[0]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/450558/slide-114.jpg)
Слайд 116РЕГИСТРАЦИЯ ТИПА
Регистрация типа:
int MPI_Type_commit(MPI_Datatype *datatype)
Освобождение памяти:
int MPI_Type_free(MPI_Datatype *datatype)
типы, которые
РЕГИСТРАЦИЯ ТИПА
Регистрация типа:
int MPI_Type_commit(MPI_Datatype *datatype)
Освобождение памяти:
int MPI_Type_free(MPI_Datatype *datatype)
типы, которые

Слайд 117ПОРЯДОК РАБОТЫ С ПРОИЗВОДНЫМИ ТИПАМИ
Создание типа с помощью конструктора.
Регистрация.
Использование.
Освобождение памяти.
ПОРЯДОК РАБОТЫ С ПРОИЗВОДНЫМИ ТИПАМИ
Создание типа с помощью конструктора.
Регистрация.
Использование.
Освобождение памяти.

Слайд 118КАРТА И СИГНАТУРА ТИПА
Карта типа - набор пар (базовый тип, смещение):
((type1,
КАРТА И СИГНАТУРА ТИПА
Карта типа - набор пар (базовый тип, смещение):
((type1,

Слайд 119СООТВЕТСТВИЕ ТИПОВ
Соответствие типов отправителя и получателя:
Сигнатура типа пришедшего сообщения является начальной подпоследовательностью
СООТВЕТСТВИЕ ТИПОВ
Соответствие типов отправителя и получателя:
Сигнатура типа пришедшего сообщения является начальной подпоследовательностью

Слайд 120ПРИМЕРЫ
send: MPI_TYPE_VECTOR(3, 1, 2, MPI_DOUBLE)
recv: MPI_TYPE_CONTIGUOUS(3, MPI_DOUBLE)
double
double
double
double
double
double
send:MPI_TYPE_CONTIGUOUS(6, MPI_DOUBLE)
recv: MPI_TYPE_VECTOR(3, 1, 2, MPI_DOUBLE)
double
double
double
double
double
double
ПРИМЕРЫ
send: MPI_TYPE_VECTOR(3, 1, 2, MPI_DOUBLE)
recv: MPI_TYPE_CONTIGUOUS(3, MPI_DOUBLE)
double
double
double
double
double
double
send:MPI_TYPE_CONTIGUOUS(6, MPI_DOUBLE)
recv: MPI_TYPE_VECTOR(3, 1, 2, MPI_DOUBLE)
double
double
double
double
double
double

Слайд 121ПРИМЕРЫ
send: MPI_TYPE_VECTOR(3, 1, 2, MPI_DOUBLE)
recv: MPI_TYPE_CONTIGUOUS(6, MPI_DOUBLE)
double
double
double
double
double
double
double
double
double
send: MPI_TYPE_CONTIGUOUS(6, MPI_DOUBLE)
recv:MPI_TYPE_VECTOR(3, 1, 2, MPI_DOUBLE)
double
double
double
double
double
double
double
double
double
ПРИМЕРЫ
send: MPI_TYPE_VECTOR(3, 1, 2, MPI_DOUBLE)
recv: MPI_TYPE_CONTIGUOUS(6, MPI_DOUBLE)
double
double
double
double
double
double
double
double
double
send: MPI_TYPE_CONTIGUOUS(6, MPI_DOUBLE)
recv:MPI_TYPE_VECTOR(3, 1, 2, MPI_DOUBLE)
double
double
double
double
double
double
double
double
double

Слайд 122ПРИМЕРЫ
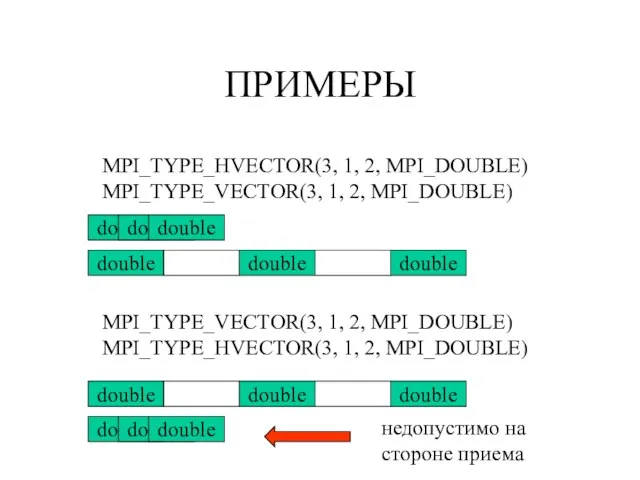
MPI_TYPE_HVECTOR(3, 1, 2, MPI_DOUBLE)
MPI_TYPE_VECTOR(3, 1, 2, MPI_DOUBLE)
double
double
double
double
double
double
MPI_TYPE_VECTOR(3, 1, 2, MPI_DOUBLE)
MPI_TYPE_HVECTOR(3, 1, 2,
ПРИМЕРЫ
MPI_TYPE_HVECTOR(3, 1, 2, MPI_DOUBLE)
MPI_TYPE_VECTOR(3, 1, 2, MPI_DOUBLE)
double
double
double
double
double
double
MPI_TYPE_VECTOR(3, 1, 2, MPI_DOUBLE) MPI_TYPE_HVECTOR(3, 1, 2,
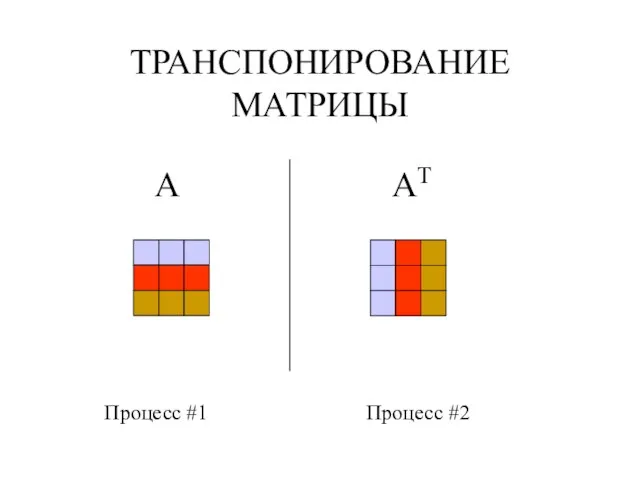
Слайд 123ТРАНСПОНИРОВАНИЕ МАТРИЦЫ
A
AT
Процесс #1
Процесс #2
ТРАНСПОНИРОВАНИЕ МАТРИЦЫ
A
AT
Процесс #1
Процесс #2
Слайд 124#include
#include
#define N 3
int A[N][N];
void fill_matrix()
{
int i,j;
for(i = 0;
#include
#include
#define N 3
int A[N][N];
void fill_matrix()
{
int i,j;
for(i = 0;
![#include #include #define N 3 int A[N][N]; void fill_matrix() { int i,j;](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/450558/slide-123.jpg)
Слайд 125main(int argc, char* argv[])
{
int r, i;
MPI_Status st;
MPI_Datatype typ;
MPI_Init(&argc, &argv);
main(int argc, char* argv[])
{
int r, i;
MPI_Status st;
MPI_Datatype typ;
MPI_Init(&argc, &argv);
![main(int argc, char* argv[]) { int r, i; MPI_Status st; MPI_Datatype typ;](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/450558/slide-124.jpg)
Слайд 126else if(r == 1){
MPI_Type_vector(N, 1, N, MPI_INT, &typ);
MPI_Type_commit(&typ);
MPI_Barrier(MPI_COMM_WORLD);
for(i
else if(r == 1){
MPI_Type_vector(N, 1, N, MPI_INT, &typ);
MPI_Type_commit(&typ);
MPI_Barrier(MPI_COMM_WORLD);
for(i

Слайд 127РЕЗУЛЬТАТ РАБОТЫ
Transposed:
0 3 6
1 4 7
2 5 8
РЕЗУЛЬТАТ РАБОТЫ
Transposed:
0 3 6
1 4 7
2 5 8

Слайд 128 if(r == 0) {
fill_matrix();
printf("\n Source:\n");
print_matrix();
MPI_Type_contiguous(N * N,
if(r == 0) {
fill_matrix();
printf("\n Source:\n");
print_matrix();
MPI_Type_contiguous(N * N,

Слайд 129УПАКОВКА СООБЩЕНИЙ
дает возможность пересылать разнородные данные в одном сообщении;
отделяет операцию формирования сообщения
УПАКОВКА СООБЩЕНИЙ
дает возможность пересылать разнородные данные в одном сообщении;
отделяет операцию формирования сообщения

Слайд 130MPI_PACK
int MPI_Pack(void* inbuf, int incount, MPI_Datatype datatype, void *outbuf, int outcount, int
MPI_PACK
int MPI_Pack(void* inbuf, int incount, MPI_Datatype datatype, void *outbuf, int outcount, int

Слайд 131MPI_UNPACK
int MPI_Unpack(void* inbuf, int insize, int *position, void *outbuf, int outcount, MPI_Datatype
MPI_UNPACK
int MPI_Unpack(void* inbuf, int insize, int *position, void *outbuf, int outcount, MPI_Datatype

Слайд 132ОПРЕДЕЛЕНИЕ РАЗМЕРА СООБЩЕНИЯ
int MPI_Pack_size(int incount, MPI_Datatype datatype, MPI_Comm comm, int *size)
incount
ОПРЕДЕЛЕНИЕ РАЗМЕРА СООБЩЕНИЯ
int MPI_Pack_size(int incount, MPI_Datatype datatype, MPI_Comm comm, int *size)
incount

Слайд 133ПРИМЕР
#include
#include
#include
#define N 3
main(int argc, char* argv[])
{
int r;
int
ПРИМЕР
#include
#include
#include
#define N 3
main(int argc, char* argv[])
{
int r;
int
![ПРИМЕР #include #include #include #define N 3 main(int argc, char* argv[]) {](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/450558/slide-132.jpg)
Слайд 134ПРИМЕР
if(r == 0){
int sz;
int pos = 0;
int a =
ПРИМЕР
if(r == 0){
int sz;
int pos = 0;
int a =

Слайд 135ПРИМЕР
else {
MPI_Status st;
int A[N];
MPI_Recv(A, N, MPI_INT, 0, 0, MPI_COMM_WORLD,
ПРИМЕР
else {
MPI_Status st;
int A[N];
MPI_Recv(A, N, MPI_INT, 0, 0, MPI_COMM_WORLD,
![ПРИМЕР else { MPI_Status st; int A[N]; MPI_Recv(A, N, MPI_INT, 0, 0,](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/450558/slide-134.jpg)
Слайд 136ХАРАКТЕРНЫЕ ОШИБКИ В MPI-ПРОГРАММАХ
ХАРАКТЕРНЫЕ ОШИБКИ В MPI-ПРОГРАММАХ

Слайд 137ВИДЫ ОШИБОК
Ошибки последовательных программ.
Ошибки несоответствия типов.
Ошибки работы с MPI-объектами.
Взаимные блокировки.
Недетерминизм.
ВИДЫ ОШИБОК
Ошибки последовательных программ.
Ошибки несоответствия типов.
Ошибки работы с MPI-объектами.
Взаимные блокировки.
Недетерминизм.

Слайд 138Недетерминизм за счет разницы в относительных скоростях процессов (race condition)
Недетерминизм за счет разницы в относительных скоростях процессов (race condition)
Слайд 139Deadlock
if(rank == 0) {
MPI_Ssend(… 1 …)
MPI_Recv(…1…)
} else {
MPI_Ssend(… 0 …)
MPI_Recv(…0…)
}
Deadlock
if(rank == 0) {
MPI_Ssend(… 1 …)
MPI_Recv(…1…)
} else {
MPI_Ssend(… 0 …)
MPI_Recv(…0…)
}
 Определение ресурсов и механизма реализации проекта
Определение ресурсов и механизма реализации проекта Архитектурный стиль в петровском Петербурге
Архитектурный стиль в петровском Петербурге Тема: Имя существительное. Цели: Обобщить и систематизировать знания о грамматических признаках существительного. Воспитывать ув
Тема: Имя существительное. Цели: Обобщить и систематизировать знания о грамматических признаках существительного. Воспитывать ув Технология разработки образовательной программы МБДОУ «ЦРР-детский сад «Теремок» в соответствии с ФГОС ДО
Технология разработки образовательной программы МБДОУ «ЦРР-детский сад «Теремок» в соответствии с ФГОС ДО Презентация на тему Значение хлеба в питании. Особенности приготовления бутербродов
Презентация на тему Значение хлеба в питании. Особенности приготовления бутербродов Региональная система ОМС
Региональная система ОМС Рorsche carrera 911
Рorsche carrera 911 Атмосферное давление
Атмосферное давление Конвенция по охране реки Дунай
Конвенция по охране реки Дунай Исследование качества жизни подростков 14-17
Исследование качества жизни подростков 14-17 «Знание только тогда знание, когда оно приобретено усилиями своей мысли, а не памятью» Л.Н.Толстой
«Знание только тогда знание, когда оно приобретено усилиями своей мысли, а не памятью» Л.Н.Толстой Иван Владимирович Мичурин
Иван Владимирович Мичурин Ja jestem Pan, Bóg wasz! (…) Nie będziecie uprawiać wróżbiarstwa. Nie będziecie uprawiać czarów
Ja jestem Pan, Bóg wasz! (…) Nie będziecie uprawiać wróżbiarstwa. Nie będziecie uprawiać czarów Победители : Ларина Ирина (35 гр.), Пустовалова Светлана (37 гр.), Злобина Людмила (41 гр.)
Победители : Ларина Ирина (35 гр.), Пустовалова Светлана (37 гр.), Злобина Людмила (41 гр.) Витаминный картель
Витаминный картель Джон Дьюи и его идеи
Джон Дьюи и его идеи Деятельность Фонда содействия кредитованию малого бизнеса в Санкт-Петербурге Санкт-Петербург 2011
Деятельность Фонда содействия кредитованию малого бизнеса в Санкт-Петербурге Санкт-Петербург 2011 ПОЗНАНИЕ (ГНОСЕОЛОГИЯ)
ПОЗНАНИЕ (ГНОСЕОЛОГИЯ) Система геометрического моделирования и программирования для станков с ЧПУ
Система геометрического моделирования и программирования для станков с ЧПУ Анализ результатов ЕГЭ-2010 по математике
Анализ результатов ЕГЭ-2010 по математике Ремонт библиотеки, Чувашская Республика
Ремонт библиотеки, Чувашская Республика Государственная служба РФ
Государственная служба РФ Поздравляем с Днем специальности САТ и АТП
Поздравляем с Днем специальности САТ и АТП Здоровый образ жизни и регулирование работоспособности человека
Здоровый образ жизни и регулирование работоспособности человека ФГОС НОО
ФГОС НОО Пора вырваться из плена клеток и перестать вести учет документов и поручений с помощью таблиц!
Пора вырваться из плена клеток и перестать вести учет документов и поручений с помощью таблиц! Композиция хохломы
Композиция хохломы Педагогический совет «Роль домашнего задания в развитии творческих способностей обучающихся и ликвидации учебных перегрузок (в
Педагогический совет «Роль домашнего задания в развитии творческих способностей обучающихся и ликвидации учебных перегрузок (в