- Многоуровневая Архитектура

Содержание
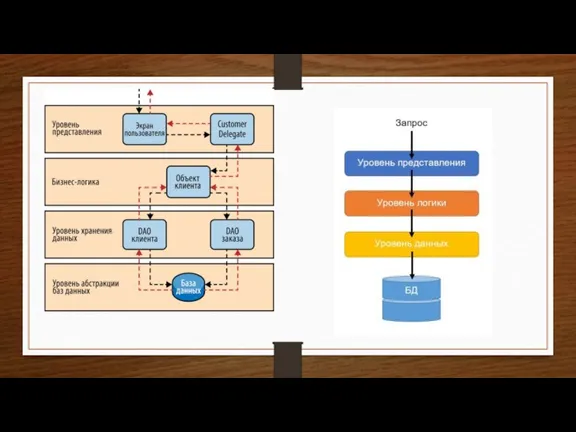
- 2. многоуровневая архитектура В программной инженерии многоуровневая архитектура или многослойная архитектура — клиент-серверная архитектура, в которой разделяются
- 3. Распространённые слои логически разделённых на слои архитектурах информационных систем наиболее часто встречаются следующие четыре слоя: Слой
- 5. Основные задачи, для решения которых применяется многоуровневый подход, обычно сводятся к следующим: повышение производительности системы за
- 6. На каждом уровне реализовывается отдельный вид обработки данных: хранилище данных (ХД) -- набор зарегистрированных баз данных,
- 8. Данная архитектура обеспечивает взаимодействие служб: публикации данных, поддержка и их аутентичности и качества; поиска и представления
- 10. Плюсы: Каждый уровень этой архитектуры выполняет строго ограниченный набор функций (которые не повторяются от слоя к
- 11. Недостатки: В программировании есть присказка, что любую проблему можно решить добавлением еще одного уровня абстракции. Однако
- 13. Скачать презентацию
Слайд 2многоуровневая архитектура
В программной инженерии многоуровневая архитектура или многослойная архитектура — клиент-серверная архитектура, в которой разделяются функции представления, обработки
многоуровневая архитектура
В программной инженерии многоуровневая архитектура или многослойная архитектура — клиент-серверная архитектура, в которой разделяются функции представления, обработки

Слайд 3Распространённые слои
логически разделённых на слои архитектурах информационных систем наиболее часто встречаются следующие
Распространённые слои
логически разделённых на слои архитектурах информационных систем наиболее часто встречаются следующие

Слайд 5Основные задачи, для решения которых применяется многоуровневый подход, обычно сводятся к следующим:
повышение
Основные задачи, для решения которых применяется многоуровневый подход, обычно сводятся к следующим:
повышение

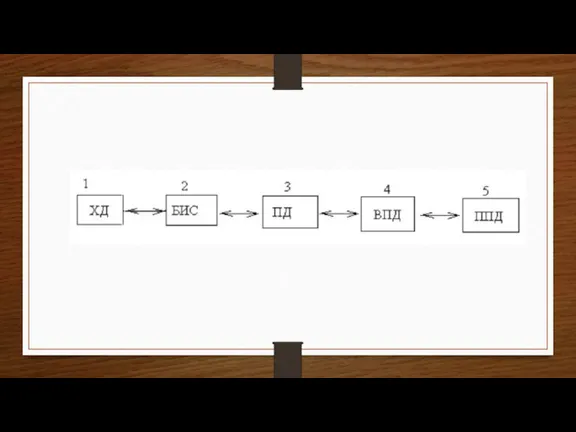
Слайд 6На каждом уровне реализовывается отдельный вид обработки данных:
хранилище данных (ХД) -- набор
На каждом уровне реализовывается отдельный вид обработки данных:
хранилище данных (ХД) -- набор

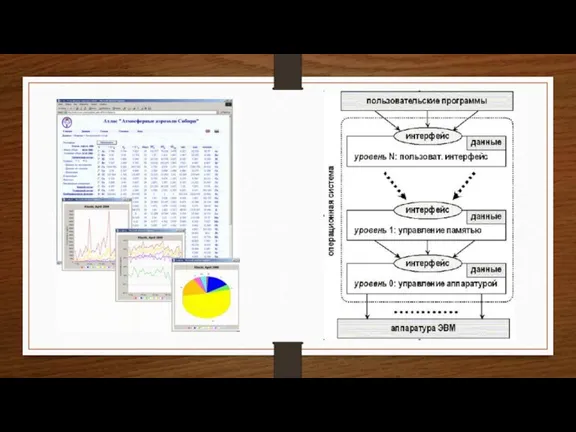
Слайд 8Данная архитектура обеспечивает взаимодействие служб:
публикации данных, поддержка и их аутентичности и качества;
поиска
Данная архитектура обеспечивает взаимодействие служб:
публикации данных, поддержка и их аутентичности и качества;
поиска

Слайд 10Плюсы:
Каждый уровень этой архитектуры выполняет строго ограниченный набор функций (которые не повторяются
Плюсы:
Каждый уровень этой архитектуры выполняет строго ограниченный набор функций (которые не повторяются

Слайд 11Недостатки:
В программировании есть присказка, что любую проблему можно решить добавлением еще одного
Недостатки:
В программировании есть присказка, что любую проблему можно решить добавлением еще одного

 Презентация на тему о ВИЧ – инфекции и СПИДе
Презентация на тему о ВИЧ – инфекции и СПИДе  Электропоезд ЭР-9. Совесткий электропоезд, выпускавшийся с 1962 года по 2002 год
Электропоезд ЭР-9. Совесткий электропоезд, выпускавшийся с 1962 года по 2002 год ВЫБОРЫ ДЕПУТАТОВ ГОСУДАРСТВЕННОЙ ДУМЫ ФЕДЕРАЛЬНОГО СОБРАНИЯ РОССИЙСКОЙ ФЕДЕРАЦИИ 4 ДЕКАБРЯ 2011 ГОДА
ВЫБОРЫ ДЕПУТАТОВ ГОСУДАРСТВЕННОЙ ДУМЫ ФЕДЕРАЛЬНОГО СОБРАНИЯ РОССИЙСКОЙ ФЕДЕРАЦИИ 4 ДЕКАБРЯ 2011 ГОДА Пневмонии
Пневмонии КоптоРУС. Продажа
КоптоРУС. Продажа Форма сделок Условия действительности сделки
Форма сделок Условия действительности сделки 3_raund
3_raund Презентация на тему Экономика Японии
Презентация на тему Экономика Японии Презентация на тему Защита от несанкционированного доступа к информации
Презентация на тему Защита от несанкционированного доступа к информации Поступление на военную службу по контракту
Поступление на военную службу по контракту Организация научных исследований
Организация научных исследований 20170209_yuzhnaya_amerika
20170209_yuzhnaya_amerika Рисуем музыку
Рисуем музыку Реставрация Тарских ворот.
Реставрация Тарских ворот. Театральные профессии
Театральные профессии Уголовный процесс: Общая часть
Уголовный процесс: Общая часть Управление SQL Server c помощью PowerShell
Управление SQL Server c помощью PowerShell Программа стимулирования продаж IdealDuo от Ideal Standard
Программа стимулирования продаж IdealDuo от Ideal Standard ГОУ ВПО Кузбасская государственная педагогическая академия Разработка учебного плана на компетентностной основе___________________
ГОУ ВПО Кузбасская государственная педагогическая академия Разработка учебного плана на компетентностной основе___________________ Арест имущества должника
Арест имущества должника Признаки объектов. Объекты с необычными признаками и действиями
Признаки объектов. Объекты с необычными признаками и действиями Предвыборная программа. Суриков А.С
Предвыборная программа. Суриков А.С Профессиональная подготовка специалистов индустрии туризма и инновационные технологии в туризме
Профессиональная подготовка специалистов индустрии туризма и инновационные технологии в туризме Презентация на тему Трудовые ресурсы и занятость населения
Презентация на тему Трудовые ресурсы и занятость населения Оценка экологического состояния деревни Шильпухово
Оценка экологического состояния деревни Шильпухово Бюджетний процес
Бюджетний процес СЕМЬЯ И ШКОЛА: ДЕТСТВО БЕЗ ЖЕСТОКОСТИ И НАСИЛИЯ
СЕМЬЯ И ШКОЛА: ДЕТСТВО БЕЗ ЖЕСТОКОСТИ И НАСИЛИЯ Универсальный иммортализм
Универсальный иммортализм