- Основы OpenMP

Содержание
- 2. OpenMP: Что это? Стандарт, позволяющий распараллеливать вычисления на системах с общей памятью. Преимущества: Простота использования. Переносимость.
- 3. Синтаксис Compiler directives: C/C++ #pragma omp directive [clause, …] Fortran !$OMP directive [clause, …] C$OMP directive
- 4. Параллельное исполнение Parallel Regions Основная конструкция OpenMP #pragma omp parallel #pragma omp parallel { printf( “hello
- 5. Параллельное исполнение Итак, большинство конструкций OpenMP – это дерективы компилятора Основная конструкция OpenMP это omp parallel
- 6. OpenMP подход к параллелизму OpenMP основано на модели разделяемой памяти. Вычислительная задача распределяется на потоки. –
- 7. OpenMP подход к параллелизму Модель fork-join Исполнение программы начинается в одном потоке (master thread). Далее следует
- 8. Основные конструкции OpenMP #pragma omp for Каждый поток получает свою порцию работы – data parallelism. #pragma
- 9. OpenMP sections #pragma omp sections [ clause [ clause ] ... ] new-line { [#pragma omp
- 10. OpenMP sections #pragma omp parallel #pragma omp sections nowait { thread1_work(); #pragma omp section thread2_work(); #pragma
- 11. OpenMP for directive #pragma omp for [ clause [ clause ] ... Непосредственно следующий за директивой
- 12. OpenMP for directive #pragma omp parallel private(f) { f=7; #pragma omp for for (i=0; i a[i]
- 13. OpenMP for directive Возможны следующие модификаторы: private( list ); reduction( operator: list ); schedule( type [
- 14. Переменные в OpenMP private ( list ) Будут созданы уникальные локальные копии перечисленных переменных. shared (
- 15. Пример int x; x = 0; // Initialize x to zero #pragma omp parallel for firstprivate(x)
- 16. OpenMP schedule clause Разбиение итераций цикла по потокам или «диспетчеризация» schedule( type [ , chunk ]
- 17. Loop scheduling (планирование выполнения итераций цикла)
- 18. Основные функции OpenMP int omp_get_num_threads(void); int omp_get_thread_num(void); … http://www.openmp.org/
- 19. Синхронизация в OpenMP Неявная синхронизация происходит в начале и конце любой конструкции parallel (до тех пор,
- 20. Синхронизация в OpenMP сritical – критическая секция. Не может исполняться одновременно несколькими потоками. atomic – специальная
- 21. OpenMP critical cnt = 0; f=7; #pragma omp parallel { #pragma omp for for (i=0; i
- 22. Полная информация OpenMP Homepage: http://www.openmp.org/ Introduction to OpenMP - tutorial from WOMPEI 2000 (link) Writing and
- 24. Скачать презентацию
Слайд 2OpenMP: Что это?
Стандарт, позволяющий распараллеливать вычисления на системах с общей памятью.
Преимущества:
Простота использования.
Переносимость.
Низкие
OpenMP: Что это?
Стандарт, позволяющий распараллеливать вычисления на системах с общей памятью.
Преимущества:
Простота использования.
Переносимость.
Низкие

Слайд 3Синтаксис
Compiler directives:
C/C++
#pragma omp directive [clause, …]
Fortran
!$OMP directive [clause, …]
C$OMP directive [clause, …]
*$OMP
Синтаксис
Compiler directives:
C/C++
#pragma omp directive [clause, …]
Fortran
!$OMP directive [clause, …]
C$OMP directive [clause, …]
*$OMP
![Синтаксис Compiler directives: C/C++ #pragma omp directive [clause, …] Fortran !$OMP directive](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/423764/slide-2.jpg)
Слайд 4Параллельное исполнение
Parallel Regions
Основная конструкция OpenMP
#pragma omp parallel
#pragma omp parallel
{
printf( “hello world from
Параллельное исполнение
Parallel Regions
Основная конструкция OpenMP
#pragma omp parallel
#pragma omp parallel
{
printf( “hello world from

Слайд 5Параллельное исполнение
Итак, большинство конструкций OpenMP – это дерективы компилятора
Основная конструкция OpenMP это
Параллельное исполнение
Итак, большинство конструкций OpenMP – это дерективы компилятора
Основная конструкция OpenMP это

Слайд 6OpenMP подход к параллелизму
OpenMP основано на модели разделяемой памяти.
Вычислительная задача распределяется на
OpenMP подход к параллелизму
OpenMP основано на модели разделяемой памяти.
Вычислительная задача распределяется на

Слайд 7OpenMP подход к параллелизму
Модель fork-join
Исполнение программы начинается в одном потоке (master thread).
Далее
OpenMP подход к параллелизму
Модель fork-join
Исполнение программы начинается в одном потоке (master thread).
Далее

Слайд 8Основные конструкции OpenMP
#pragma omp for
Каждый поток получает свою порцию работы – data
Основные конструкции OpenMP
#pragma omp for
Каждый поток получает свою порцию работы – data

Слайд 9OpenMP sections
#pragma omp sections [ clause [ clause ] ... ] new-line
{
[#pragma
OpenMP sections
#pragma omp sections [ clause [ clause ] ... ] new-line
{
[#pragma
![OpenMP sections #pragma omp sections [ clause [ clause ] ... ]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/423764/slide-8.jpg)
Слайд 10OpenMP sections
#pragma omp parallel
#pragma omp sections nowait
{
thread1_work();
#pragma omp section
thread2_work();
#pragma omp section
thread3_work();
#pragma omp
OpenMP sections
#pragma omp parallel
#pragma omp sections nowait
{
thread1_work();
#pragma omp section
thread2_work();
#pragma omp section
thread3_work();
#pragma omp

Слайд 11OpenMP for directive
#pragma omp for [ clause [ clause ] ...
Непосредственно
OpenMP for directive
#pragma omp for [ clause [ clause ] ...
Непосредственно
![OpenMP for directive #pragma omp for [ clause [ clause ] ...](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/423764/slide-10.jpg)
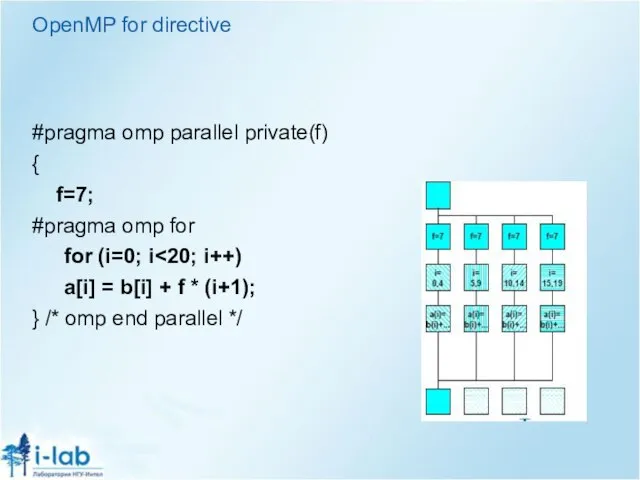
Слайд 12OpenMP for directive
#pragma omp parallel private(f)
{
f=7;
#pragma omp for
for (i=0; i<20; i++)
a[i] =
OpenMP for directive
#pragma omp parallel private(f)
{
f=7;
#pragma omp for
for (i=0; i<20; i++)
a[i] =
Слайд 13OpenMP for directive
Возможны следующие модификаторы:
private( list );
reduction( operator: list );
OpenMP for directive
Возможны следующие модификаторы:
private( list );
reduction( operator: list );

Слайд 14Переменные в OpenMP
private ( list )
Будут созданы уникальные локальные копии перечисленных переменных.
shared
Переменные в OpenMP
private ( list )
Будут созданы уникальные локальные копии перечисленных переменных.
shared

Слайд 15Пример
int x;
x = 0; // Initialize x to zero
#pragma omp parallel for firstprivate(x)
Пример
int x;
x = 0; // Initialize x to zero
#pragma omp parallel for firstprivate(x)

Слайд 16OpenMP schedule clause
Разбиение итераций цикла по потокам или «диспетчеризация»
schedule( type [
OpenMP schedule clause
Разбиение итераций цикла по потокам или «диспетчеризация»
schedule( type [

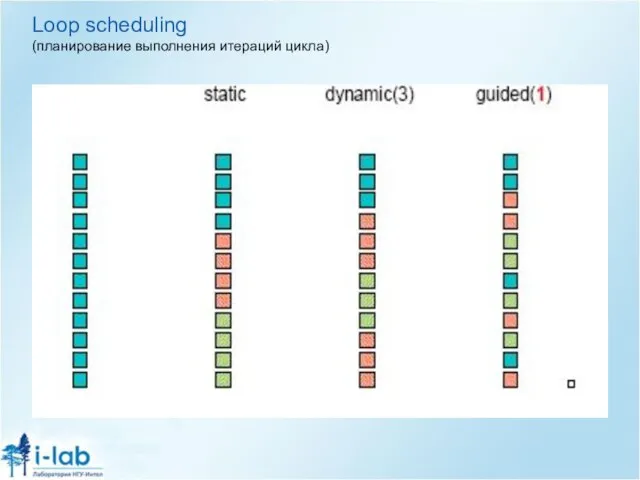
Слайд 17Loop scheduling
(планирование выполнения итераций цикла)
Loop scheduling
(планирование выполнения итераций цикла)
Слайд 18Основные функции OpenMP
int omp_get_num_threads(void);
int omp_get_thread_num(void);
…
http://www.openmp.org/
Основные функции OpenMP
int omp_get_num_threads(void);
int omp_get_thread_num(void);
…
http://www.openmp.org/

Слайд 19Синхронизация в OpenMP
Неявная синхронизация происходит в начале и конце любой конструкции
Синхронизация в OpenMP
Неявная синхронизация происходит в начале и конце любой конструкции

Слайд 20Синхронизация в OpenMP
сritical – критическая секция. Не может исполняться одновременно несколькими потоками.
atomic
Синхронизация в OpenMP
сritical – критическая секция. Не может исполняться одновременно несколькими потоками.
atomic

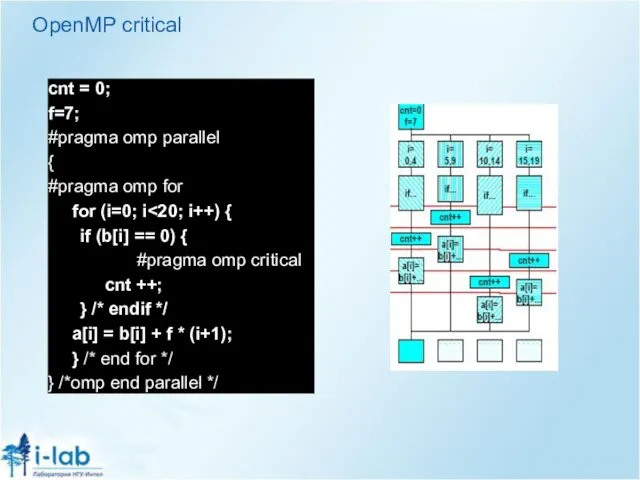
Слайд 21OpenMP critical
cnt = 0;
f=7;
#pragma omp parallel
{
#pragma omp for
for (i=0; i<20; i++) {
if
OpenMP critical
cnt = 0;
f=7;
#pragma omp parallel
{
#pragma omp for
for (i=0; i<20; i++) {
if
Слайд 22Полная информация
OpenMP Homepage: http://www.openmp.org/
Introduction to OpenMP - tutorial from WOMPEI 2000 (link)
Полная информация
OpenMP Homepage: http://www.openmp.org/
Introduction to OpenMP - tutorial from WOMPEI 2000 (link)

 Обсуждение притчи как мотивационный прием Жил-был юноша с плохим характером. Отец дал ему полный мешок гвоздей и сказал: «З
Обсуждение притчи как мотивационный прием Жил-был юноша с плохим характером. Отец дал ему полный мешок гвоздей и сказал: «З Stand design | bendix | automechanika- 2016
Stand design | bendix | automechanika- 2016 Национальная галерея искусства в Вашингтоне.
Национальная галерея искусства в Вашингтоне. Модернизация пескоразбрасывающего оборудования. Повышение сцепления абразивных частиц с поверхностью снежно-ледяных образований
Модернизация пескоразбрасывающего оборудования. Повышение сцепления абразивных частиц с поверхностью снежно-ледяных образований 111
111 Приготовление щей, борщей
Приготовление щей, борщей УСТРОЙСТВО ОРИЕНТАЦИИ БУТЫЛОК (УНИВЕРСАЛЬНОЕ)
УСТРОЙСТВО ОРИЕНТАЦИИ БУТЫЛОК (УНИВЕРСАЛЬНОЕ) Общая психология
Общая психология Бизнес-план, его назначение и структура
Бизнес-план, его назначение и структура Организация психологических служб в медицинских учреждениях
Организация психологических служб в медицинских учреждениях Организационно-правовые формы предприятия
Организационно-правовые формы предприятия Мастер света
Мастер света Кафедра физико – математических дисциплин
Кафедра физико – математических дисциплин Простые вещества - металлы и неметаллы
Простые вещества - металлы и неметаллы Мотивация оператора
Мотивация оператора Презентация на тему Гражданское право по Судебнику 1497 г
Презентация на тему Гражданское право по Судебнику 1497 г  Стенокардия
Стенокардия Сотрудники Call-центра: кто они, где их искать и чему учить.
Сотрудники Call-центра: кто они, где их искать и чему учить. Приоритетный национальный проект «Образование»
Приоритетный национальный проект «Образование» Подготовка к написанию сочинения «Описание внешности знакомого»
Подготовка к написанию сочинения «Описание внешности знакомого» Векторная графика в Word и Power Point
Векторная графика в Word и Power Point ИННОВАЦИОННЫЕ ПОДХОДЫ К КОМПЛЕКСНОЙ ТЕРАПИИ БОЛЬНЫХ ТУБЕРКУЛЕЗОМ НОВАЯ ГРУППА ЛЕКАРСТВЕННЫХ ПРЕПАРАТОВ – РЕГУЛЯТОРЫ ЗАЩИТНЫХ С
ИННОВАЦИОННЫЕ ПОДХОДЫ К КОМПЛЕКСНОЙ ТЕРАПИИ БОЛЬНЫХ ТУБЕРКУЛЕЗОМ НОВАЯ ГРУППА ЛЕКАРСТВЕННЫХ ПРЕПАРАТОВ – РЕГУЛЯТОРЫ ЗАЩИТНЫХ С «Построение маркетинговых коммуникаций с молодёжной аудиторией в соответствии с её образом жизни и моделью потребления»
«Построение маркетинговых коммуникаций с молодёжной аудиторией в соответствии с её образом жизни и моделью потребления» Презентация на тему Гималаи
Презентация на тему Гималаи Памятник Петру Великому "Медный всадник"
Памятник Петру Великому "Медный всадник" Инновационные технологии диагностики и мониторинга плоских кровель
Инновационные технологии диагностики и мониторинга плоских кровель М О Я Р О Д И Н А - Р О С С И Я
М О Я Р О Д И Н А - Р О С С И Я Родительское собрание.
Родительское собрание.