- Semantic Web и продукционная модель знаний

Содержание
- 4. OWL RDF OWL RDF
- 5. RDF Horst, H. J. Combining RDF and Part of OWL with Rules: Semantics, Decidability, Complexity. etc
- 6. RDF Horst, H. J. Combining RDF and Part of OWL with Rules: Semantics, Decidability, Complexity. etc
- 7. Логическая модель
- 8. Логическая модель Pallet Hawk Racer Fact
- 9. Логическое программирование Логическое программирование – общее название для языков программирования, программы которых состоят из продукций. Prolog
- 10. Стратегии вычисления продукций Forward-chaining, (bottom-up) Последовательное применение продукций к фактам, а затем и к комбинациям фактов
- 11. Что еще можно делать с продукциями? Мы используем комбинированную стратегию. При этом применяются продукции к фактам,
- 12. Граф зависимости продукций Запрос: ?a(x) Продукции: R1: a(x) :- p(x), q(x) R2: p(y) :- p1(y) R3:
- 13. Генерация SQL Предикат p(x) опрделеляет множество : Select * from F where F.s like “P” Join
- 14. Генерация продукций Продукции => SQL + Совмещение SQL запросов с семантическими к реляционной СУБД
- 15. Генерация продукций Продукции => SQL + Совмещение SQL запросов с семантическими к реляционной СУБД SPARQL =>
- 16. Генерация продукций Продукции => SQL + Совмещение SQL запросов с семантическими к реляционной СУБД SPARQL =>
- 18. Скачать презентацию


Слайд 4OWL
RDF
OWL
RDF
OWL
RDF
OWL
RDF
Слайд 5RDF
Horst, H. J. Combining RDF and Part of OWL with Rules:
RDF
Horst, H. J. Combining RDF and Part of OWL with Rules:

Слайд 6RDF
Horst, H. J. Combining RDF and Part of OWL with Rules:
RDF
Horst, H. J. Combining RDF and Part of OWL with Rules:

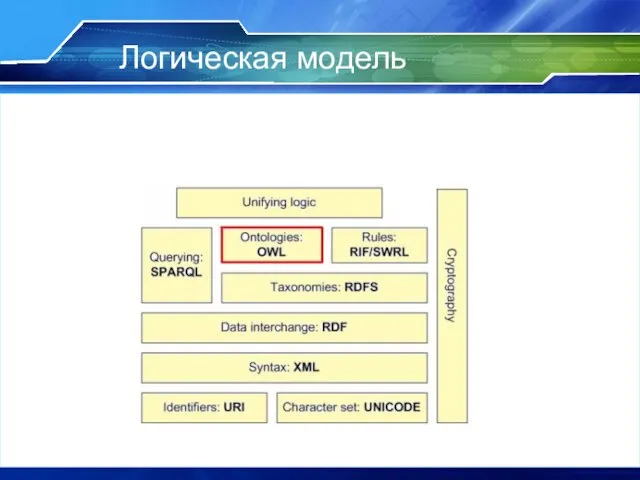
Слайд 7Логическая модель
Логическая модель
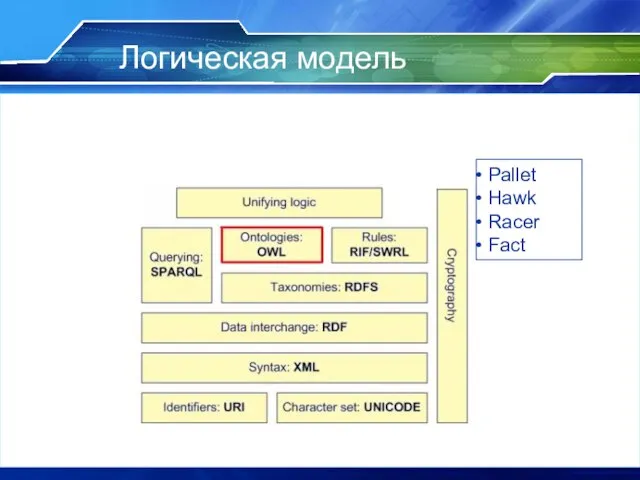
Слайд 8Логическая модель
Pallet
Hawk
Racer
Fact
Логическая модель
Pallet
Hawk
Racer
Fact
Слайд 9Логическое программирование
Логическое программирование – общее название для языков программирования, программы которых состоят
Логическое программирование
Логическое программирование – общее название для языков программирования, программы которых состоят

Слайд 10Стратегии вычисления продукций
Forward-chaining, (bottom-up)
Последовательное применение продукций к фактам, а
Стратегии вычисления продукций
Forward-chaining, (bottom-up)
Последовательное применение продукций к фактам, а

Слайд 11Что еще можно делать с продукциями?
Мы используем комбинированную стратегию. При этом применяются
Что еще можно делать с продукциями?
Мы используем комбинированную стратегию. При этом применяются

Слайд 12Граф зависимости продукций
Запрос:
?a(x)
Продукции:
R1: a(x) :- p(x), q(x)
R2: p(y) :- p1(y)
R3: p(k) :-
Граф зависимости продукций
Запрос:
?a(x)
Продукции:
R1: a(x) :- p(x), q(x)
R2: p(y) :- p1(y)
R3: p(k) :-

Слайд 13Генерация SQL
Предикат p(x) опрделеляет множество :
Select * from F where F.s
Генерация SQL
Предикат p(x) опрделеляет множество :
Select * from F where F.s

Слайд 14Генерация продукций
Продукции => SQL
+ Совмещение SQL запросов с семантическими к реляционной СУБД
Генерация продукций
Продукции => SQL
+ Совмещение SQL запросов с семантическими к реляционной СУБД

Слайд 15Генерация продукций
Продукции => SQL
+ Совмещение SQL запросов с семантическими к реляционной СУБД
SPARQL
Генерация продукций
Продукции => SQL
+ Совмещение SQL запросов с семантическими к реляционной СУБД
SPARQL

Слайд 16Генерация продукций
Продукции => SQL
+ Совмещение SQL запросов с семантическими к реляционной СУБД
SPARQL
Генерация продукций
Продукции => SQL
+ Совмещение SQL запросов с семантическими к реляционной СУБД
SPARQL

 Химия и проблемы экологии. Кислотные дожди
Химия и проблемы экологии. Кислотные дожди Понятие, сущность и значение информационного права. Право на информацию
Понятие, сущность и значение информационного права. Право на информацию Циклоны и антициклоны
Циклоны и антициклоны Школьный спортивный комплекс настольных спортивных игр народов мира
Школьный спортивный комплекс настольных спортивных игр народов мира Африканская улитка ахатина
Африканская улитка ахатина Анализ и сопоставление концептуальных положений парциальных программ для дошкольного образования
Анализ и сопоставление концептуальных положений парциальных программ для дошкольного образования Право. Тема 6. Часть 1. ОГЭ по обществознанию
Право. Тема 6. Часть 1. ОГЭ по обществознанию Правописание безударных гласных в корне слова
Правописание безударных гласных в корне слова Об особенностях проведения ГИА-9 в 2012 году
Об особенностях проведения ГИА-9 в 2012 году Программа работы Клуба «Семейный очаг»
Программа работы Клуба «Семейный очаг» Республика Саха-Якутия
Республика Саха-Якутия Проведение государственной (итоговой) аттестации выпускников IX классов общеобразовательных учреждений, организуемой региональн
Проведение государственной (итоговой) аттестации выпускников IX классов общеобразовательных учреждений, организуемой региональн Комплексные решения в ВЭД: транспортная логистика и таможенное оформление
Комплексные решения в ВЭД: транспортная логистика и таможенное оформление Презентация на тему Дикие и домашние животные (3 класс)
Презентация на тему Дикие и домашние животные (3 класс) Coachella Style. Type of Bohemian
Coachella Style. Type of Bohemian Презентация на тему Налоговая система РФ
Презентация на тему Налоговая система РФ Программное обеспечение ИС: СИСТЕМНОЕ ПО ИС
Программное обеспечение ИС: СИСТЕМНОЕ ПО ИС Дом-музей А. Грина в Феодосии
Дом-музей А. Грина в Феодосии Александр Сергеевич Пушкин (1799-1837)
Александр Сергеевич Пушкин (1799-1837) «Анализ проблем классификации товаров в таможенных целях и пути их совершенствования на примере 13 и 14 групп товаров в ТН ВЭД » Под
«Анализ проблем классификации товаров в таможенных целях и пути их совершенствования на примере 13 и 14 групп товаров в ТН ВЭД » Под Курсовая работа. Документационное обеспечение управлением персонала
Курсовая работа. Документационное обеспечение управлением персонала Техническое обслуживание воздушных линий с напряжением до 1000 вольт
Техническое обслуживание воздушных линий с напряжением до 1000 вольт Дружок
Дружок Учебный центр Профстандарт. Порядок обучения по программам дополнительного профессионального образования
Учебный центр Профстандарт. Порядок обучения по программам дополнительного профессионального образования Швейцария. Куда инвестируют в Швейцарии?
Швейцария. Куда инвестируют в Швейцарии? Быт в 16 в
Быт в 16 в Презентация на тему Первоцветы
Презентация на тему Первоцветы РОЛЬ ПОПУЛЯЦИОННЫХ ИССЛЕДОВАНИЙ В СОВРЕМЕННОЙ ГИДРОБИОЛОГИИ
РОЛЬ ПОПУЛЯЦИОННЫХ ИССЛЕДОВАНИЙ В СОВРЕМЕННОЙ ГИДРОБИОЛОГИИ