- Создание легко обновляемых текстовых индексов

Содержание
- 2. Задача Поиск слов и фраз в большой текстовой коллекции
- 3. Инвертированные файлы Часто используются для поиска Сложно добавлять новые данные
- 4. Инвертированные файлы Для каждой словоформы сохраняется информация о том, в каких документах и где в документах
- 5. Пример информации о вхождении 1) Номер (ID) файла 2) Позиция словоформы в файле (порядковый номер словоформы,
- 6. Задача Нужно сделать индекс, который бы позволял легко добавлять в него новые данные
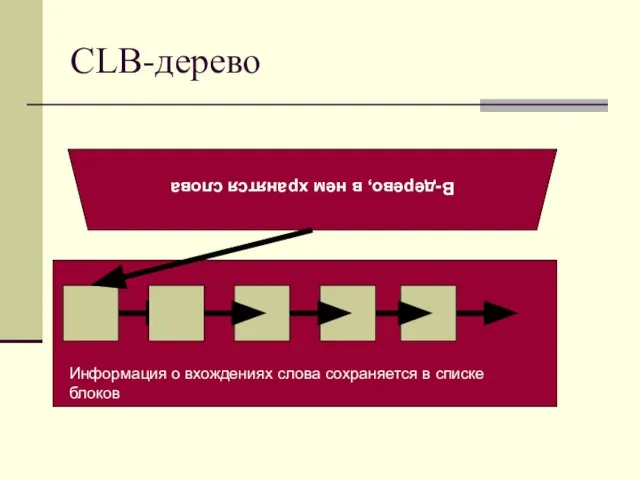
- 7. CLB-дерево B-дерево, в нем хранятся слова Информация о вхождениях слова сохраняется в списке блоков
- 8. Морфология Морфологический анализатор Для каждой словоформы из словаря выдается набор базовых форм. Базовых форм ~ 200
- 9. Кэширование Храним в B-дереве не словоформы, а базовые формы. Можем хранить в памяти последний блок для
- 10. Плюсы Можно быстро добавлять новые данные. Информация о новых вхождениях слова добавляется в последний блок списка.
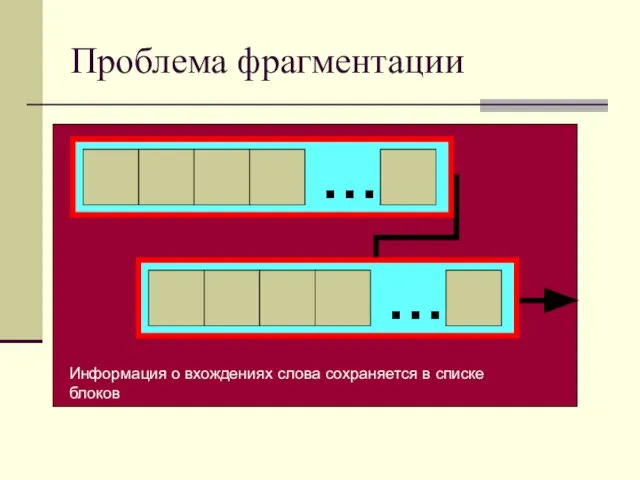
- 11. Минусы 1) Фрагментация – блоки могут располагаться в разных местах 2) Неэффективное использование дисковой памяти, блоки
- 12. Проблема фрагментации Пусть в списке блоков k блоков. Выберем число m = 2C Разделим весь список
- 13. Пример У нас есть 25 блоков и m = 8. Разбиваем 25 блоков на группы следующих
- 14. Проблема фрагментации Информация о вхождениях слова сохраняется в списке блоков
- 15. Алгоритм Пусть есть k заполненных подряд расположенных блоков B1, …, Bk, в частности последний блок также
- 16. k = 2x, x ищем 2k подряд располагающихся блоков N1, … N2k. Затем копируем информацию из
- 17. k = 2x, x = c Заканчиваем текущую группу блоков, в ней уже есть m =
- 18. Остальные случаи Используем зарезервированные ранее блоки (в случае k = 2x, x
- 19. Эффективное использование дисковой памяти B-дерево, в нем хранятся слова Информация о вхождениях слова сохраняется в списке
- 20. Эффективное использование памяти Все базовые формы разделяются на n групп. Используем n временных файлов. Вначале читаем
- 21. Сравнение с существующими разработками Общий объем 35,2 гб, 191 074 файла Все файлы были в кодировке
- 22. Описание конфигурации оборудования Процессор: Intel Core 2 Duo E6700, 2.66 GHz, кэш: L1 Data – 2
- 23. Создание индекса Создание инвертированного файла: время 9 часов, размер 40 гб. Создание CLB индекса: время 3
- 24. Добавление в индекс одного файла среднего размера Время добавления одного документа 1,2 мб. для CLB индекса:
- 25. Добавление в индекс одного файла малого размера Время добавления одного документа размером 534 байта для CLB
- 26. Время поиска Время поиска в инвертированном файле и CLB-индексе практически совпадают.
- 27. Выводы Проведенные эксперименты показывают высокую эффективность CLB индекса при добавлении в него данных небольшого размера.
- 28. Сравнение с существующими разработками Процессор: Intel Pentium 4, 3.0 GHz, кэш: L1 Data – 16 кб,
- 29. Создание CLB индекса Размер индекса 26,2 гб. Время создания 5 часов 49 мин. Использовался размер блока
- 30. SearchInform Desktop (http://www.searchinform.com) Размер индекса 16,15 гб. Время создания 9 часов.
- 31. Архивариус 3000 http://www.likasoft.com/ Размер индекса 24,83 гб. Время создания 6 часов 46 мин.
- 32. Google Desktop Размер индекса ~ 5 гб Время создания 31 час 25 минуты
- 33. Выводы Эксперименты показывают высокую скорость создания CLB индекса.
- 34. Эксперименты Общий объем 86 гб, 400 049 файла Все файлы были в кодировке Windows-1251 (CP1251). Язык
- 35. Описание конфигурации оборудования Процессор: Intel Core 2 Duo E6700, 2.66 GHz, кэш: L1 Data – 2
- 36. Создание CLB индекса Размер индекса 56,5 гб. Время создания 4 часа 28 минут. Использовался размер блока
- 37. Инвертированные файлы Размер индекса 117,7 гб. Время создания 20 часов 6 минут.
- 38. Архивариус 3000 http://www.likasoft.com/ Размер индекса 62,65 гб. Время создания 6 часов 10 минут.
- 39. Инструментарий Автором разработана библиотека для создания индексов и поиска в текстах, в которой реализована описанная структура
- 40. Форматы файлов Библиотека может индексировать файлы в различных форматах, например RTF, PDF, CHM, HTML, DJVU и
- 41. Архивы Поддерживается обработка архивов форматов ZIP, CAB, RAR, 7Z, ARJ, TAR, и др.
- 42. Архитектура Библиотека реализована в виде COM сервера для операционных систем Windows Написана на C++.
- 43. Архитектура Ядро, осуществляет создание индекса и поиск. Модуль поддержки морфологии Модуль распознавания кодировки. При распознавании кодировки
- 44. Форматы файлов Модуль поддержки форматов файлов. Поддержка форматов файлов и архивов реализована с помощью подключаемых дополнительных
- 45. Архитектура Модуль атрибутов документов, для сохранения описания документов. Модуль репозитария, для сохранения текстов документов. Создается для
- 46. Архитектура Модуль COM осуществляет доступ к остальным модулям извне с помощью COM, что позволяет использовать библиотеку
- 47. Системные требования Реализованные алгоритмы достаточно нетребовательные к ресурсам компьютера. Для создания индекса достаточно иметь 300–400 мегабайт
- 48. SSD Эффективность описанных в данном алгоритмов значительно возрастет с применением дисков SSD (Solid-state drive), за счет
- 50. Скачать презентацию

Слайд 3Инвертированные файлы
Часто используются для поиска
Сложно добавлять новые данные
Инвертированные файлы
Часто используются для поиска
Сложно добавлять новые данные

Слайд 4Инвертированные файлы
Для каждой словоформы сохраняется информация о том, в каких документах и
Инвертированные файлы
Для каждой словоформы сохраняется информация о том, в каких документах и

Слайд 5Пример информации о вхождении
1) Номер (ID) файла
2) Позиция словоформы в файле (порядковый
Пример информации о вхождении
1) Номер (ID) файла
2) Позиция словоформы в файле (порядковый

Слайд 6Задача
Нужно сделать индекс, который бы позволял легко добавлять в него новые данные
Задача
Нужно сделать индекс, который бы позволял легко добавлять в него новые данные

Слайд 7CLB-дерево
B-дерево, в нем хранятся слова
Информация о вхождениях слова сохраняется в списке блоков
CLB-дерево
B-дерево, в нем хранятся слова
Информация о вхождениях слова сохраняется в списке блоков
Слайд 8Морфология
Морфологический анализатор
Для каждой словоформы из словаря выдается набор базовых форм.
Базовых форм ~
Морфология
Морфологический анализатор
Для каждой словоформы из словаря выдается набор базовых форм.
Базовых форм ~

Слайд 9Кэширование
Храним в B-дереве не словоформы, а базовые формы. Можем хранить в памяти
Кэширование
Храним в B-дереве не словоформы, а базовые формы. Можем хранить в памяти

Слайд 10Плюсы
Можно быстро добавлять новые данные. Информация о новых вхождениях слова добавляется в
Плюсы
Можно быстро добавлять новые данные. Информация о новых вхождениях слова добавляется в

Слайд 11Минусы
1) Фрагментация – блоки могут располагаться в разных местах
2) Неэффективное использование дисковой
Минусы
1) Фрагментация – блоки могут располагаться в разных местах
2) Неэффективное использование дисковой

Слайд 12Проблема фрагментации
Пусть в списке блоков k блоков.
Выберем число m = 2C
Разделим весь
Проблема фрагментации
Пусть в списке блоков k блоков.
Выберем число m = 2C
Разделим весь

Слайд 13Пример
У нас есть 25 блоков и m = 8.
Разбиваем 25 блоков
Пример
У нас есть 25 блоков и m = 8.
Разбиваем 25 блоков

Слайд 14Проблема фрагментации
Информация о вхождениях слова сохраняется в списке блоков
Проблема фрагментации
Информация о вхождениях слова сохраняется в списке блоков
Слайд 15Алгоритм
Пусть есть k заполненных подряд расположенных блоков B1, …, Bk, в частности
Алгоритм
Пусть есть k заполненных подряд расположенных блоков B1, …, Bk, в частности

Слайд 16k = 2x, x < c
ищем 2k подряд располагающихся блоков N1, …
k = 2x, x < c
ищем 2k подряд располагающихся блоков N1, …

Слайд 17k = 2x, x = c
Заканчиваем текущую группу блоков, в ней уже
k = 2x, x = c
Заканчиваем текущую группу блоков, в ней уже

Слайд 18Остальные случаи
Используем зарезервированные ранее блоки (в случае k = 2x, x <
Остальные случаи
Используем зарезервированные ранее блоки (в случае k = 2x, x <

Слайд 19Эффективное использование дисковой памяти
B-дерево, в нем хранятся слова
Информация о вхождениях слова сохраняется
Эффективное использование дисковой памяти
B-дерево, в нем хранятся слова
Информация о вхождениях слова сохраняется

Слайд 20Эффективное использование памяти
Все базовые формы разделяются на n групп. Используем n временных
Эффективное использование памяти
Все базовые формы разделяются на n групп. Используем n временных

Слайд 21Сравнение с существующими
разработками
Общий объем 35,2 гб, 191 074 файла
Все файлы были
Сравнение с существующими
разработками
Общий объем 35,2 гб, 191 074 файла
Все файлы были

Слайд 22Описание конфигурации оборудования
Процессор: Intel Core 2 Duo E6700, 2.66 GHz, кэш:
Описание конфигурации оборудования
Процессор: Intel Core 2 Duo E6700, 2.66 GHz, кэш:

Слайд 23Создание индекса
Создание инвертированного файла: время 9 часов, размер 40 гб.
Создание CLB индекса:
Создание индекса
Создание инвертированного файла: время 9 часов, размер 40 гб.
Создание CLB индекса:

Слайд 24Добавление в индекс одного файла среднего размера
Время добавления одного документа 1,2
Добавление в индекс одного файла среднего размера
Время добавления одного документа 1,2

Слайд 25Добавление в индекс одного файла малого размера
Время добавления одного документа размером
Добавление в индекс одного файла малого размера
Время добавления одного документа размером

Слайд 26Время поиска
Время поиска в инвертированном файле и CLB-индексе практически совпадают.
Время поиска
Время поиска в инвертированном файле и CLB-индексе практически совпадают.

Слайд 27Выводы
Проведенные эксперименты показывают высокую эффективность CLB индекса при добавлении в него данных
Выводы
Проведенные эксперименты показывают высокую эффективность CLB индекса при добавлении в него данных

Слайд 28Сравнение с существующими
разработками
Процессор: Intel Pentium 4, 3.0 GHz, кэш: L1
Сравнение с существующими
разработками
Процессор: Intel Pentium 4, 3.0 GHz, кэш: L1

Слайд 29Создание CLB индекса
Размер индекса 26,2 гб.
Время создания 5 часов 49 мин.
Использовался
Создание CLB индекса
Размер индекса 26,2 гб.
Время создания 5 часов 49 мин.
Использовался

Слайд 30SearchInform Desktop (http://www.searchinform.com)
Размер индекса 16,15 гб.
Время создания 9 часов.
SearchInform Desktop (http://www.searchinform.com)
Размер индекса 16,15 гб.
Время создания 9 часов.

Слайд 31Архивариус 3000
http://www.likasoft.com/
Размер индекса 24,83 гб.
Время создания 6 часов 46 мин.
Архивариус 3000
http://www.likasoft.com/
Размер индекса 24,83 гб.
Время создания 6 часов 46 мин.

Слайд 32Google Desktop
Размер индекса ~ 5 гб
Время создания 31 час 25 минуты
Google Desktop
Размер индекса ~ 5 гб
Время создания 31 час 25 минуты

Слайд 33Выводы
Эксперименты показывают высокую скорость создания CLB индекса.
Выводы
Эксперименты показывают высокую скорость создания CLB индекса.

Слайд 34Эксперименты
Общий объем 86 гб, 400 049 файла
Все файлы были в кодировке Windows-1251
Эксперименты
Общий объем 86 гб, 400 049 файла
Все файлы были в кодировке Windows-1251

Слайд 35Описание конфигурации оборудования
Процессор: Intel Core 2 Duo E6700, 2.66 GHz, кэш: L1
Описание конфигурации оборудования
Процессор: Intel Core 2 Duo E6700, 2.66 GHz, кэш: L1

Слайд 36Создание CLB индекса
Размер индекса 56,5 гб.
Время создания 4 часа 28 минут.
Использовался размер
Создание CLB индекса
Размер индекса 56,5 гб.
Время создания 4 часа 28 минут.
Использовался размер

Слайд 37Инвертированные файлы
Размер индекса 117,7 гб.
Время создания 20 часов 6 минут.
Инвертированные файлы
Размер индекса 117,7 гб.
Время создания 20 часов 6 минут.

Слайд 38Архивариус 3000
http://www.likasoft.com/
Размер индекса 62,65 гб.
Время создания 6 часов 10 минут.
Архивариус 3000
http://www.likasoft.com/
Размер индекса 62,65 гб.
Время создания 6 часов 10 минут.

Слайд 39Инструментарий
Автором разработана библиотека для создания индексов и поиска в текстах, в которой
Инструментарий
Автором разработана библиотека для создания индексов и поиска в текстах, в которой

Слайд 40Форматы файлов
Библиотека может индексировать файлы в различных форматах, например RTF, PDF, CHM,
Форматы файлов
Библиотека может индексировать файлы в различных форматах, например RTF, PDF, CHM,

Слайд 41Архивы
Поддерживается обработка архивов форматов ZIP, CAB, RAR, 7Z, ARJ, TAR, и др.
Архивы
Поддерживается обработка архивов форматов ZIP, CAB, RAR, 7Z, ARJ, TAR, и др.

Слайд 42Архитектура
Библиотека реализована в виде COM сервера для операционных систем Windows
Написана на C++.
Архитектура
Библиотека реализована в виде COM сервера для операционных систем Windows
Написана на C++.

Слайд 43Архитектура
Ядро, осуществляет создание индекса и поиск.
Модуль поддержки морфологии
Модуль распознавания кодировки. При
Архитектура
Ядро, осуществляет создание индекса и поиск.
Модуль поддержки морфологии
Модуль распознавания кодировки. При

Слайд 44Форматы файлов
Модуль поддержки форматов файлов. Поддержка форматов файлов и архивов реализована с
Форматы файлов
Модуль поддержки форматов файлов. Поддержка форматов файлов и архивов реализована с

Слайд 45Архитектура
Модуль атрибутов документов, для сохранения описания документов.
Модуль репозитария, для сохранения текстов документов.
Архитектура
Модуль атрибутов документов, для сохранения описания документов.
Модуль репозитария, для сохранения текстов документов.

Слайд 46Архитектура
Модуль COM осуществляет доступ к остальным модулям извне с помощью COM, что
Архитектура
Модуль COM осуществляет доступ к остальным модулям извне с помощью COM, что

Слайд 47Системные требования
Реализованные алгоритмы достаточно нетребовательные к ресурсам компьютера. Для создания индекса достаточно
Системные требования
Реализованные алгоритмы достаточно нетребовательные к ресурсам компьютера. Для создания индекса достаточно

Слайд 48SSD
Эффективность описанных в данном алгоритмов значительно возрастет с применением дисков SSD (Solid-state
SSD
Эффективность описанных в данном алгоритмов значительно возрастет с применением дисков SSD (Solid-state

 Циклы тепловых двигателей
Циклы тепловых двигателей Александр Иванович Куприн
Александр Иванович Куприн УПРАВЛЕНИЕ R&D ПРИ ПОМОЩИ ЭКОНОМИЧЕСКОГО АНАЛИЗА ЭФФЕКТА ОТ ВНЕДРЕНИЯ
УПРАВЛЕНИЕ R&D ПРИ ПОМОЩИ ЭКОНОМИЧЕСКОГО АНАЛИЗА ЭФФЕКТА ОТ ВНЕДРЕНИЯ Информационная грамотность в начальной школе Большакова Мария Николаевна заместитель директора по информатизации гимназии № 7
Информационная грамотность в начальной школе Большакова Мария Николаевна заместитель директора по информатизации гимназии № 7 Народная одежда финнов
Народная одежда финнов Федеральный экспериментальный проект по совершенствованию питания обучающихся
Федеральный экспериментальный проект по совершенствованию питания обучающихся Эксплуатация автомобильного транспорта
Эксплуатация автомобильного транспорта Творческий проект Религиозные праздники в нашем крае
Творческий проект Религиозные праздники в нашем крае Балантидий
Балантидий Автоматизация закупок для предприятий и организаций в целях реализации Федерального закона №223-ФЗ
Автоматизация закупок для предприятий и организаций в целях реализации Федерального закона №223-ФЗ Виды проецирования. Центральное проецирование
Виды проецирования. Центральное проецирование Молодежные субкультуры
Молодежные субкультуры Презентация на тему Понятие, признаки, функции социального партнерства
Презентация на тему Понятие, признаки, функции социального партнерства  Presentation Title My name My position, contact information or project description
Presentation Title My name My position, contact information or project description  СЕКС БОЛЬШЕ, ЧЕМ ФИЗИОЛОГИЧЕСКАЯ ПОТРЕБНОСТЬ
СЕКС БОЛЬШЕ, ЧЕМ ФИЗИОЛОГИЧЕСКАЯ ПОТРЕБНОСТЬ Интерактивная игра Назови виды декоративно-прикладного искусства
Интерактивная игра Назови виды декоративно-прикладного искусства Памятка Оценка Рисков-4
Памятка Оценка Рисков-4 ДЕНЬ ЗАЩИТНИКА ОТЕЧЕСТВА.
ДЕНЬ ЗАЩИТНИКА ОТЕЧЕСТВА. ВИТАВАКС 200ФФ
ВИТАВАКС 200ФФ Их имена у всех на устах
Их имена у всех на устах Организация сопровождаемого проживания граждан с нарушениями
Организация сопровождаемого проживания граждан с нарушениями Ковалёв Юрий,
Ковалёв Юрий,  О текущем статусе реконструкции большого зала филармонии
О текущем статусе реконструкции большого зала филармонии Новые кредитные программы«ФИМ Целевой» и «ФИМ Проектный»Программы реализуются совместно с Российским Банком поддержки малог
Новые кредитные программы«ФИМ Целевой» и «ФИМ Проектный»Программы реализуются совместно с Российским Банком поддержки малог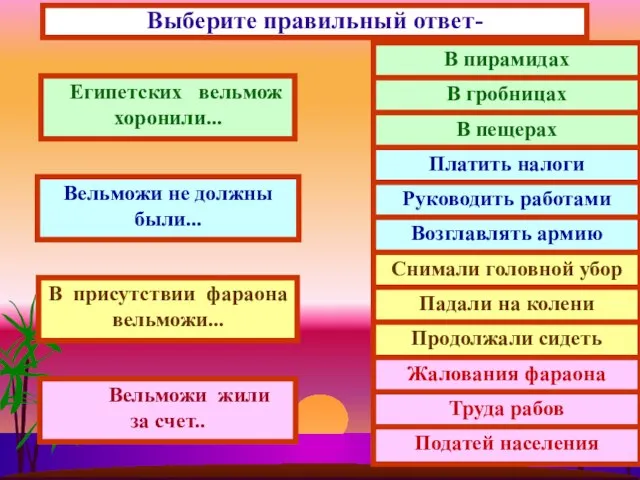 Выберите правильный ответ-
Выберите правильный ответ- Выполняем основные швы
Выполняем основные швы Бенчмаркинг как путь к повышению эффективности компании Олег ДАВИДОВИЧ, Директор по маркетингу
Бенчмаркинг как путь к повышению эффективности компании Олег ДАВИДОВИЧ, Директор по маркетингу Модель преемственности уровней дошкольного и начального общего образования в условиях ГБОУ прогимназия Радуга № 624
Модель преемственности уровней дошкольного и начального общего образования в условиях ГБОУ прогимназия Радуга № 624