- Speech synthesis

Содержание
- 2. Speech synthesis What is the task? Generating natural sounding speech on the fly, usually from text
- 3. Input type Concept-to-speech vs text-to-speech In CTS, content of message is determined from internal representation, not
- 4. Text-to-speech What to say: text-to-phoneme conversion is not straightforward Dr Smith lives on Marine Dr in
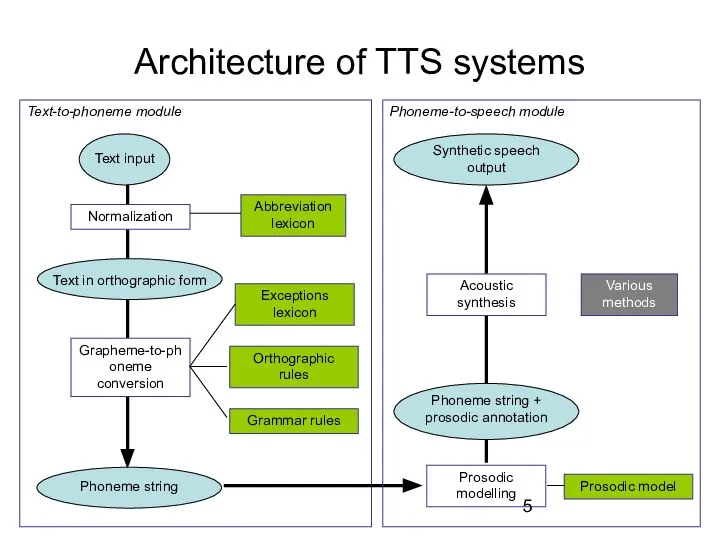
- 5. Text-to-phoneme module Architecture of TTS systems Grapheme-to-phoneme conversion Prosodic modelling Acoustic synthesis Abbreviation lexicon Exceptions lexicon
- 6. Text normalization Any text that has a special pronunciation should be stored in a lexicon Abbreviations
- 7. Grapheme-to-phoneme conversion English spelling is complex but largely regular, other languages more (or less) so Gross
- 8. Grapheme-to-phoneme conversion Much easier for some languages (Spanish, Italian, Welsh, Czech, Korean) Much harder for others
- 9. Syntactic (etc.) analysis Homograph disambiguation requires syntactic analysis He makes a record of everything they record.
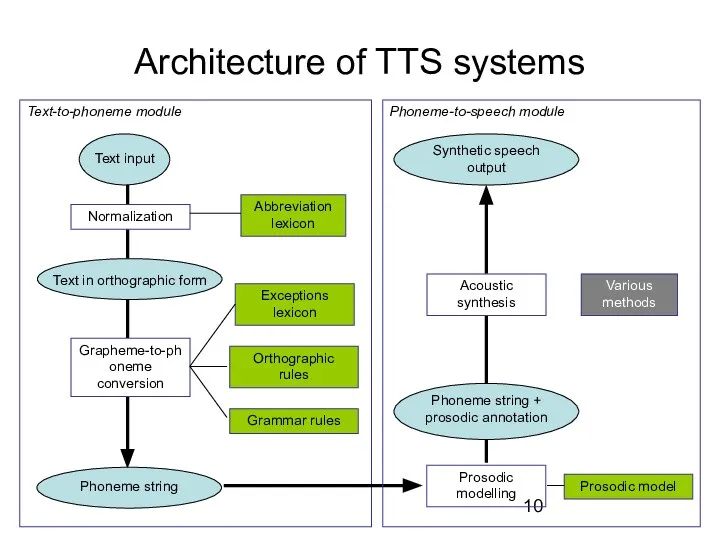
- 10. Text-to-phoneme module Architecture of TTS systems Grapheme-to-phoneme conversion Prosodic modelling Acoustic synthesis Abbreviation lexicon Exceptions lexicon
- 11. Prosody modelling Pitch, length, loudness Intonation (pitch) essential to avoid monotonous robot-like voice linked to basic
- 12. Acoustic synthesis Alternative methods: Articulatory synthesis Formant synthesis Concatenative synthesis Unit selection synthesis
- 13. Articulatory synthesis Simulation of physical processes of human articulation Wolfgang von Kempelen (1734-1804) and others used
- 14. Formant synthesis Reproduce the relevant characteristics of the acoustic signal In particular, amplitude and frequency of
- 15. Formant synthesis Demo: In control panel select “Speech” icon Type in your text and Preview voice
- 16. Concatenative synthesis Concatenate segments of pre-recorded natural human speech Requires database of previously recorded human speech
- 17. Diphone synthesis Most important for natural sounding speech is to get the transitions right (allophonic variation,
- 18. Diphone synthesis Most systems use diphones because they are Manageable in number Can be automatically extracted
- 19. Concatenative synthesis Input is phonemic representation + prosodic features Diphone segments can be digitally manipulated for
- 20. Unit selection synthesis (USS) Same idea as concatenative synthesis, but database contains bigger variety of “units”
- 21. Speech synthesis demo
- 23. Скачать презентацию

Слайд 3Input type
Concept-to-speech vs text-to-speech
In CTS, content of message is determined from internal
Input type
Concept-to-speech vs text-to-speech
In CTS, content of message is determined from internal

Слайд 4Text-to-speech
What to say: text-to-phoneme conversion is not straightforward
Dr Smith lives on Marine
Text-to-speech
What to say: text-to-phoneme conversion is not straightforward
Dr Smith lives on Marine

Слайд 5Text-to-phoneme module
Architecture of TTS systems
Grapheme-to-phoneme conversion
Prosodic modelling
Acoustic synthesis
Abbreviation lexicon
Exceptions lexicon
Orthographic rules
Normalization
Grammar rules
Prosodic
Text-to-phoneme module
Architecture of TTS systems
Grapheme-to-phoneme conversion
Prosodic modelling
Acoustic synthesis
Abbreviation lexicon
Exceptions lexicon
Orthographic rules
Normalization
Grammar rules
Prosodic
Слайд 6Text normalization
Any text that has a special pronunciation should be stored in
Text normalization
Any text that has a special pronunciation should be stored in

Слайд 7Grapheme-to-phoneme conversion
English spelling is complex but largely regular, other languages more (or
Grapheme-to-phoneme conversion
English spelling is complex but largely regular, other languages more (or

Слайд 8Grapheme-to-phoneme conversion
Much easier for some languages (Spanish, Italian, Welsh, Czech, Korean)
Much harder
Grapheme-to-phoneme conversion
Much easier for some languages (Spanish, Italian, Welsh, Czech, Korean)
Much harder

Слайд 9Syntactic (etc.) analysis
Homograph disambiguation requires syntactic analysis
He makes a record of everything
Syntactic (etc.) analysis
Homograph disambiguation requires syntactic analysis
He makes a record of everything

Слайд 10Text-to-phoneme module
Architecture of TTS systems
Grapheme-to-phoneme conversion
Prosodic modelling
Acoustic synthesis
Abbreviation lexicon
Exceptions lexicon
Orthographic rules
Normalization
Grammar rules
Prosodic
Text-to-phoneme module
Architecture of TTS systems
Grapheme-to-phoneme conversion
Prosodic modelling
Acoustic synthesis
Abbreviation lexicon
Exceptions lexicon
Orthographic rules
Normalization
Grammar rules
Prosodic
Слайд 11Prosody modelling
Pitch, length, loudness
Intonation (pitch)
essential to avoid monotonous robot-like voice
linked to basic
Prosody modelling
Pitch, length, loudness
Intonation (pitch)
essential to avoid monotonous robot-like voice
linked to basic

Слайд 12Acoustic synthesis
Alternative methods:
Articulatory synthesis
Formant synthesis
Concatenative synthesis
Unit selection synthesis
Acoustic synthesis
Alternative methods:
Articulatory synthesis
Formant synthesis
Concatenative synthesis
Unit selection synthesis

Слайд 13Articulatory synthesis
Simulation of physical processes of human articulation
Wolfgang von Kempelen (1734-1804)
Articulatory synthesis
Simulation of physical processes of human articulation
Wolfgang von Kempelen (1734-1804)

Слайд 14Formant synthesis
Reproduce the relevant characteristics of the acoustic signal
In particular, amplitude and
Formant synthesis
Reproduce the relevant characteristics of the acoustic signal
In particular, amplitude and

Слайд 15Formant synthesis
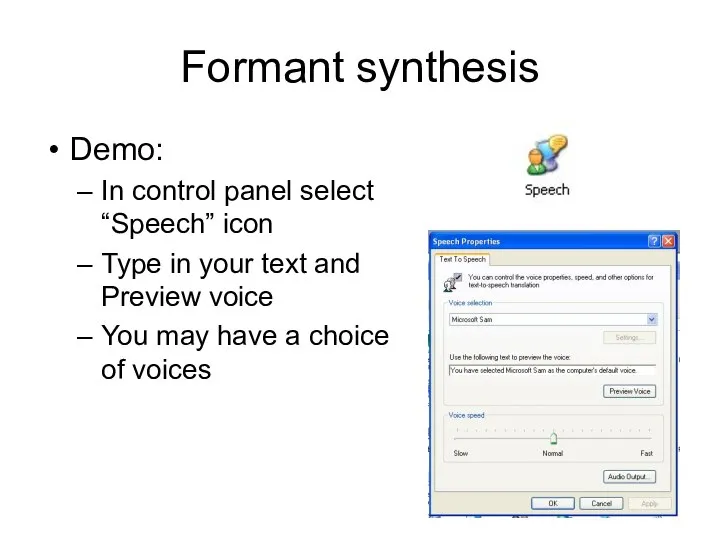
Demo:
In control panel select “Speech” icon
Type in your text and
Formant synthesis
Demo:
In control panel select “Speech” icon
Type in your text and
Слайд 16Concatenative synthesis
Concatenate segments of pre-recorded natural human speech
Requires database of previously recorded
Concatenative synthesis
Concatenate segments of pre-recorded natural human speech
Requires database of previously recorded

Слайд 17Diphone synthesis
Most important for natural sounding speech is to get the transitions
Diphone synthesis
Most important for natural sounding speech is to get the transitions

Слайд 18Diphone synthesis
Most systems use diphones because they are
Manageable in number
Can be automatically
Diphone synthesis
Most systems use diphones because they are
Manageable in number
Can be automatically

Слайд 19Concatenative synthesis
Input is phonemic representation + prosodic features
Diphone segments can be digitally
Concatenative synthesis
Input is phonemic representation + prosodic features
Diphone segments can be digitally

Слайд 20Unit selection synthesis (USS)
Same idea as concatenative synthesis, but database contains bigger
Unit selection synthesis (USS)
Same idea as concatenative synthesis, but database contains bigger

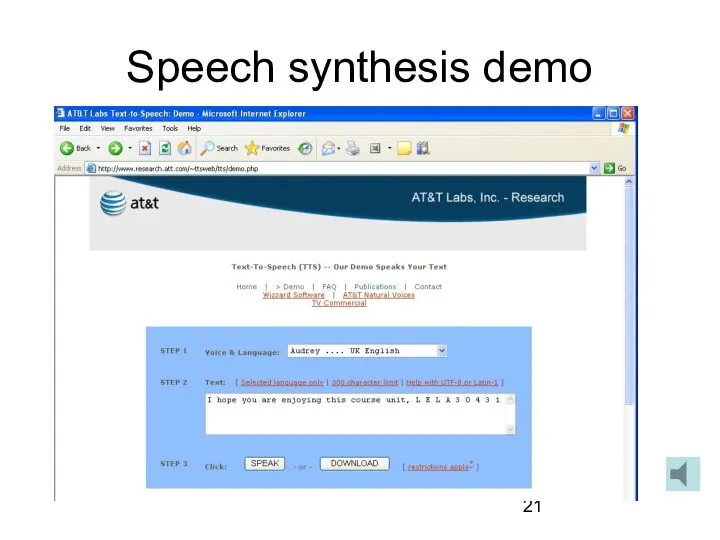
Слайд 21Speech synthesis demo
Speech synthesis demo
 Фонетическая разминка
Фонетическая разминка Фонетические особенности преподавания английского языка детям младшего школьного возраста
Фонетические особенности преподавания английского языка детям младшего школьного возраста Introduction. Good questions to ask
Introduction. Good questions to ask Rudolph visits Santa and the Elf. Elf is worried
Rudolph visits Santa and the Elf. Elf is worried Countries-nationalities
Countries-nationalities Lemuria or Mu
Lemuria or Mu Last birthday
Last birthday Hello, my dear friends! Здравствуйте, дорогие друзья! Давайте познакомимся
Hello, my dear friends! Здравствуйте, дорогие друзья! Давайте познакомимся Past simple questions
Past simple questions Petersburg. Игра
Petersburg. Игра Find continuation
Find continuation Works and professions
Works and professions English tenses
English tenses The Lincoln Lawyer
The Lincoln Lawyer What’s your name?
What’s your name? Личные местоимения
Личные местоимения Презентация на тему TRADITIONS AND HOLIDAYS OF GREAT BRITAIN
Презентация на тему TRADITIONS AND HOLIDAYS OF GREAT BRITAIN  Persona pronouns
Persona pronouns Pet animals. Flashcards
Pet animals. Flashcards Disjunctive questions. Practise your grammar
Disjunctive questions. Practise your grammar Saratov my Native Town
Saratov my Native Town Эффективные способы запоминания иностранных слов и выражений
Эффективные способы запоминания иностранных слов и выражений To what extend does the children's upbringing affect their achievements in life
To what extend does the children's upbringing affect their achievements in life Are you sleeping
Are you sleeping YPD present simple
YPD present simple Cameroon english
Cameroon english Popcorn time author James Dashner
Popcorn time author James Dashner My about self
My about self