- Кластеризация текстов

Содержание
- 2. Содержание 1. Основные определения 2. Автоматическая кластеризация текстов: постановка задачи виды алгоритмов кластеризации алгоритмы и примеры
- 3. Вопрос В чем основные отличия кластеризации от классификации?
- 4. Основные определения Классификация (или рубрицирование) – отнесение объекта к заранее известным классам (рубрикам) классы: с заданными
- 5. Вопрос Какие цели может преследовать кластеризация?
- 6. Цели кластеризации Понять структуру множества объектов, разбив его на группы схожих объектов Пример: в маркетинге, выделяют
- 7. Пример: «интеллектуальная» группировка результатов при информационном поиске Сейчас кластеризация часто – один из этапов анализа данных
- 8. Формальная постановка задачи автоматической кластеризации Имеется множество объектов D = {d1, …, d|D|} Существует множество «тематических
- 9. Какими должны быть кластеры? Внутри каждого кластера должны оказаться «похожие» объекты, а объекты разных кластеров должны
- 10. Кластеризация текстов (документов) Документов представляются как вектора в пространстве признаков di = (di1, …, di|Τ|), где
- 11. Примеры мер (1) Евклидово расстояние – геометрическое расстоянием в многомерном пространстве Квадрат евклидова расстояния. Применяется для
- 12. Примеры мер (2) Расстояние Чебышева полезно для «различения» объектов, отличных в одной координате Считающее расстояние –
- 13. Задание 1 1: Карл у Клары украл кораллы 2: Клара у Карла украла кларнет 3: Клара
- 14. Задание 1. Ответ 1: Карл у Клары украл кораллы 2: Клара у Карла украла кларнет 3:
- 15. Задание 2 1: Карл у Клары украл кораллы 2: Клара у Карла украла кларнет 3: Клара
- 16. Взгляд в прошлое
- 17. Задание 2. Ответ 1: Карл у Клары украл кораллы 2: Клара у Карла украла кларнет 3:
- 18. Задание 3 1. Вычислить косинусное расстояние для w1=(1,1,1,1,0,0,0,0) и w2=(1,1,1,0,1,0,0,0) w1=(1,1,1,1,0,0,0,0) и w3=(1,1,1,1,0,0,0,0) 2. Вычислить евклидово
- 19. Задание 3. Обсуждение (1) 1: Карл у Клары украл кораллы 2: Клара у Карла украла кларнет
- 20. Задание 3. Обсуждение (2) 1: Карл у Клары украл кораллы 2: Клара у Карла украла кларнет
- 21. Виды алгоритмов кластеризации Иерархические и плоские алгоритмы иерархические строят не одно разбиение выборки на непересекающиеся кластеры,
- 22. Иерархические алгоритмы Восходящие (агломеративные): построение кластеров снизу вверх Начало: один документ – один кластер Последовательно объединяем
- 23. Восходящие алгоритмы: критерии объединения Сходство двух кластеров есть: сходство между их наиболее похожими документами (одиночная связь)
- 24. Вопросы Какой тип сходства изображен на Рисунке 1? Какой тип сходства изображен на Рисунке 2? Какие
- 25. Пример (1): тексты
- 26. Пример (1): деревья Матрица расстояний: Одиночная связь Полная связь
- 27. Пример 2 Давайте построим дерево
- 28. Пример 2: полученное дерево
- 29. Просто пример дерева Выборка из 10000 писем: дерево (дендрограмма) и график зависимости расстояния между объединяемыми кластерами
- 30. Плоский четкий алгоритм k-средних (k-means) Входные данные: количество кластеров k множество документов как векторов di =
- 31. Оптимизируемая функция Алгоритм минимизирует среднее внутрикластерное расстояние каждая точка присваивается к тому кластеру, центр которого ближе
- 32. Иллюстрация работы k-средних, k=2
- 33. Иллюстрация работы k-средних, k=2
- 34. Иллюстрация работы k-средних, k=2
- 35. Иллюстрация работы k-средних, k=2
- 36. Иллюстрация работы k-средних, k=2
- 37. Иллюстрация работы k-средних, k=2
- 38. Иллюстрация работы k-средних, k=2
- 39. Иллюстрация работы k-средних, k=2 Центроиды классов не изменились ? завершение работы
- 40. Пример использования: документы
- 41. Пример использования: применение алгоритма Итерация 1. Случайным образом инициализированы μi: μ1=[0,96 0,80 0,42 0,79 0,66 0,85]
- 42. Пример использования: уменьшение цветов изображения Охарактеризуйте рисунки с точки зрения цвета
- 43. Пример использования: уменьшение цветов изображения 64 цвета (случайно) 96615 цветов 64 цвета (K-means)
- 44. Проблемы алгоритма k-средних Не гарантируется достижение глобального минимума суммарного квадратичного отклонения e(D,C) ? Результат зависит от
- 45. Плоский нечеткий алгоритм c-средних (c-means) Является модификацией метода k-средних Входные данные: количество кластеров k степень нечеткости
- 46. Пример применения: тексты
- 47. Оценка качества кластеризации Вычисляются меры двух видов: Внешние меры: сравнение созданного разбиения с «эталонным» анализируется сходство
- 48. Сравнение алгоритмов кластеризации Решение задачи кластеризации принципиально неоднозначно: не существует однозначно наилучшего критерия качества кластеризации количество
- 49. Домашнее задание. Вариант 1 1. Взять выбранный к прошлому разу набор данных 2. Написать программу кластеризации
- 50. Домашнее задание. Вариант 2 Написать программу определения расстояния между текстами 1. Взять несколько текстов (около 10)
- 51. Домашнее задание. Вариант 3 1. Найти готовые средства визуализации многомерных векторов (текстов) 2. Рассказать про них
- 53. Скачать презентацию
Слайд 2Содержание
1. Основные определения
2. Автоматическая кластеризация текстов:
постановка задачи
виды алгоритмов кластеризации
алгоритмы и примеры применения
3.
Содержание
1. Основные определения
2. Автоматическая кластеризация текстов:
постановка задачи
виды алгоритмов кластеризации
алгоритмы и примеры применения
3.

Слайд 3Вопрос
В чем основные отличия кластеризации от классификации?
Вопрос
В чем основные отличия кластеризации от классификации?

Слайд 4Основные определения
Классификация (или рубрицирование) – отнесение объекта к заранее известным классам (рубрикам)
классы:
Основные определения
Классификация (или рубрицирование) – отнесение объекта к заранее известным классам (рубрикам)
классы:

Слайд 5Вопрос
Какие цели может преследовать кластеризация?
Вопрос
Какие цели может преследовать кластеризация?

Слайд 6Цели кластеризации
Понять структуру множества объектов, разбив его на группы схожих объектов
Пример: в
Цели кластеризации
Понять структуру множества объектов, разбив его на группы схожих объектов
Пример: в

Слайд 7Пример: «интеллектуальная» группировка результатов при информационном поиске
Сейчас кластеризация часто – один из
Пример: «интеллектуальная» группировка результатов при информационном поиске
Сейчас кластеризация часто – один из

Слайд 8Формальная постановка задачи автоматической кластеризации
Имеется множество объектов
D = {d1, …, d|D|}
Существует
Формальная постановка задачи автоматической кластеризации
Имеется множество объектов
D = {d1, …, d|D|}
Существует

Слайд 9Какими должны быть кластеры?
Внутри каждого кластера должны оказаться «похожие» объекты, а объекты
Какими должны быть кластеры?
Внутри каждого кластера должны оказаться «похожие» объекты, а объекты

Слайд 10Кластеризация текстов (документов)
Документов представляются как вектора в пространстве признаков
di = (di1,
Кластеризация текстов (документов)
Документов представляются как вектора в пространстве признаков
di = (di1,

Слайд 11Примеры мер (1)
Евклидово расстояние – геометрическое расстоянием в многомерном пространстве
Квадрат евклидова расстояния.
Примеры мер (1)
Евклидово расстояние – геометрическое расстоянием в многомерном пространстве
Квадрат евклидова расстояния.

Слайд 12Примеры мер (2)
Расстояние Чебышева полезно для «различения» объектов, отличных в одной координате
Считающее
Примеры мер (2)
Расстояние Чебышева полезно для «различения» объектов, отличных в одной координате
Считающее

Слайд 13Задание 1
1: Карл у Клары украл кораллы
2: Клара у Карла
Задание 1
1: Карл у Клары украл кораллы
2: Клара у Карла

Слайд 14Задание 1. Ответ
1: Карл у Клары украл кораллы
2: Клара у
Задание 1. Ответ
1: Карл у Клары украл кораллы
2: Клара у

Слайд 15Задание 2
1: Карл у Клары украл кораллы
2: Клара у Карла украла
Задание 2
1: Карл у Клары украл кораллы
2: Клара у Карла украла

Слайд 16Взгляд в прошлое
Взгляд в прошлое

Слайд 17Задание 2. Ответ
1: Карл у Клары украл кораллы
2: Клара у Карла
Задание 2. Ответ
1: Карл у Клары украл кораллы
2: Клара у Карла

Слайд 18Задание 3
1. Вычислить косинусное расстояние для
w1=(1,1,1,1,0,0,0,0) и w2=(1,1,1,0,1,0,0,0)
w1=(1,1,1,1,0,0,0,0) и w3=(1,1,1,1,0,0,0,0)
2. Вычислить
Задание 3
1. Вычислить косинусное расстояние для
w1=(1,1,1,1,0,0,0,0) и w2=(1,1,1,0,1,0,0,0)
w1=(1,1,1,1,0,0,0,0) и w3=(1,1,1,1,0,0,0,0)
2. Вычислить

Слайд 19Задание 3. Обсуждение (1)
1: Карл у Клары украл кораллы
2: Клара у
Задание 3. Обсуждение (1)
1: Карл у Клары украл кораллы
2: Клара у

Слайд 20Задание 3. Обсуждение (2)
1: Карл у Клары украл кораллы
2: Клара у
Задание 3. Обсуждение (2)
1: Карл у Клары украл кораллы
2: Клара у

Слайд 21Виды алгоритмов кластеризации
Иерархические и плоские алгоритмы
иерархические строят не одно разбиение выборки на
Виды алгоритмов кластеризации
Иерархические и плоские алгоритмы
иерархические строят не одно разбиение выборки на

Слайд 22Иерархические алгоритмы
Восходящие (агломеративные): построение кластеров снизу вверх
Начало: один документ – один
Иерархические алгоритмы
Восходящие (агломеративные): построение кластеров снизу вверх
Начало: один документ – один

Слайд 23Восходящие алгоритмы: критерии объединения
Сходство двух кластеров есть:
сходство между их наиболее похожими документами
Восходящие алгоритмы: критерии объединения
Сходство двух кластеров есть:
сходство между их наиболее похожими документами

Слайд 24Вопросы
Какой тип сходства изображен на Рисунке 1?
Какой тип сходства изображен на Рисунке
Вопросы
Какой тип сходства изображен на Рисунке 1?
Какой тип сходства изображен на Рисунке
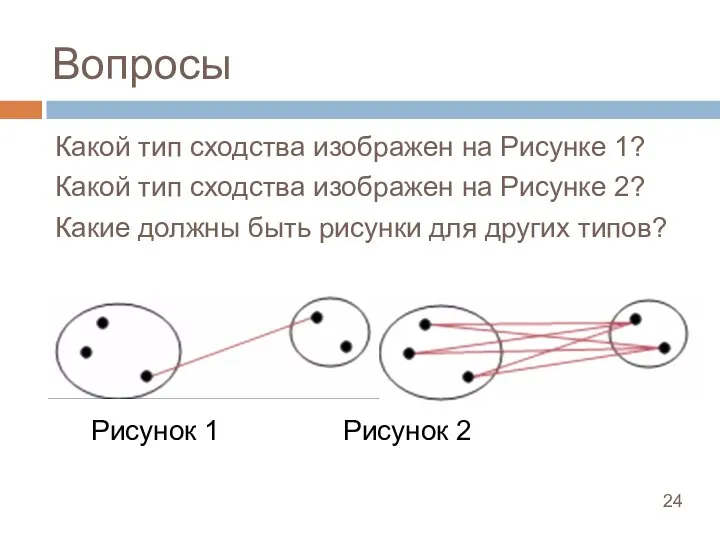
Слайд 25Пример (1): тексты
Пример (1): тексты
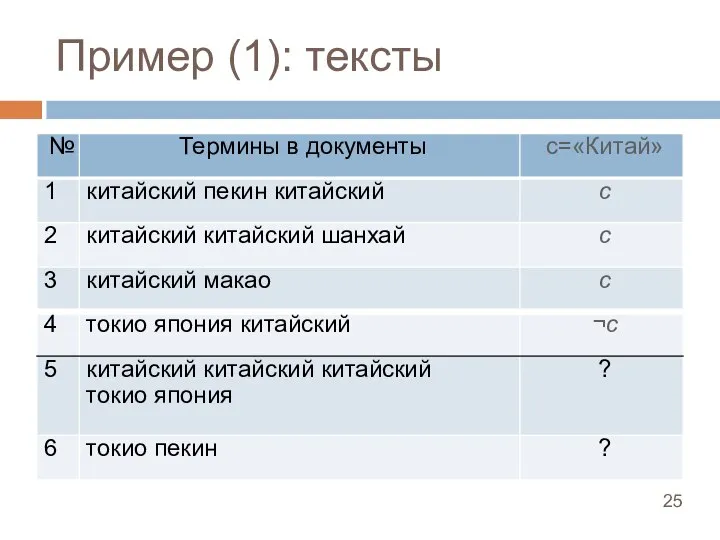
Слайд 26Пример (1): деревья
Матрица расстояний:
Одиночная связь Полная связь
Пример (1): деревья
Матрица расстояний:
Одиночная связь Полная связь
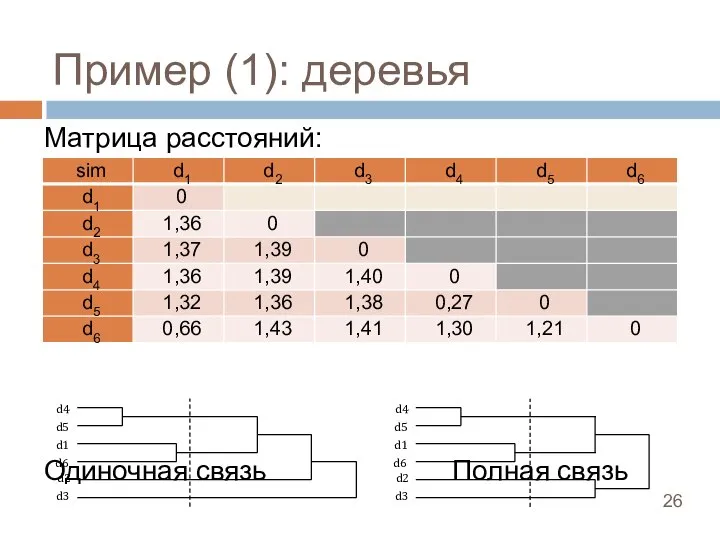
Слайд 27Пример 2
Давайте построим дерево
Пример 2
Давайте построим дерево

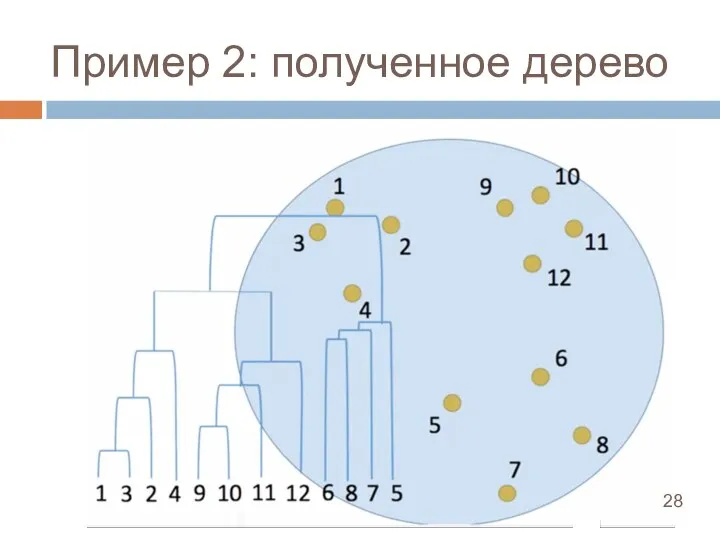
Слайд 28Пример 2: полученное дерево
Пример 2: полученное дерево
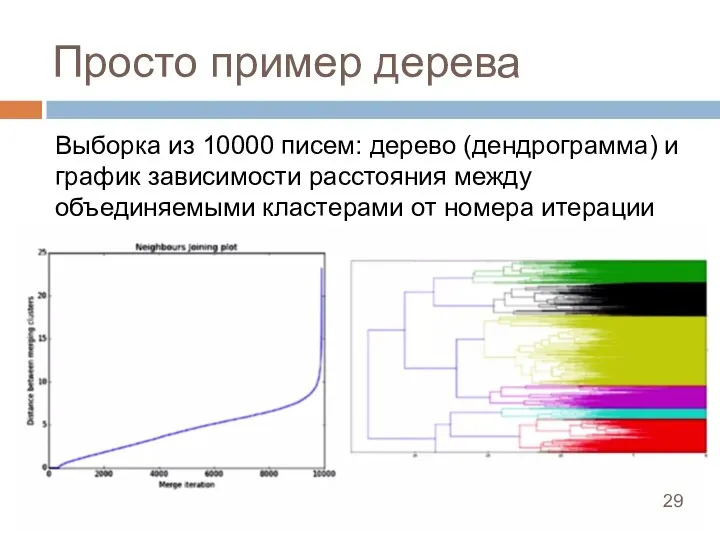
Слайд 29Просто пример дерева
Выборка из 10000 писем: дерево (дендрограмма) и график зависимости расстояния
Просто пример дерева
Выборка из 10000 писем: дерево (дендрограмма) и график зависимости расстояния
Слайд 30Плоский четкий алгоритм k-средних (k-means)
Входные данные:
количество кластеров k
множество документов как векторов
Плоский четкий алгоритм k-средних (k-means)
Входные данные:
количество кластеров k
множество документов как векторов

Слайд 31Оптимизируемая функция
Алгоритм минимизирует среднее внутрикластерное расстояние
каждая точка присваивается к тому кластеру, центр
Оптимизируемая функция
Алгоритм минимизирует среднее внутрикластерное расстояние
каждая точка присваивается к тому кластеру, центр

Слайд 32Иллюстрация работы k-средних, k=2
Иллюстрация работы k-средних, k=2
Слайд 33Иллюстрация работы k-средних, k=2
Иллюстрация работы k-средних, k=2
Слайд 34Иллюстрация работы k-средних, k=2
Иллюстрация работы k-средних, k=2
Слайд 35Иллюстрация работы k-средних, k=2
Иллюстрация работы k-средних, k=2
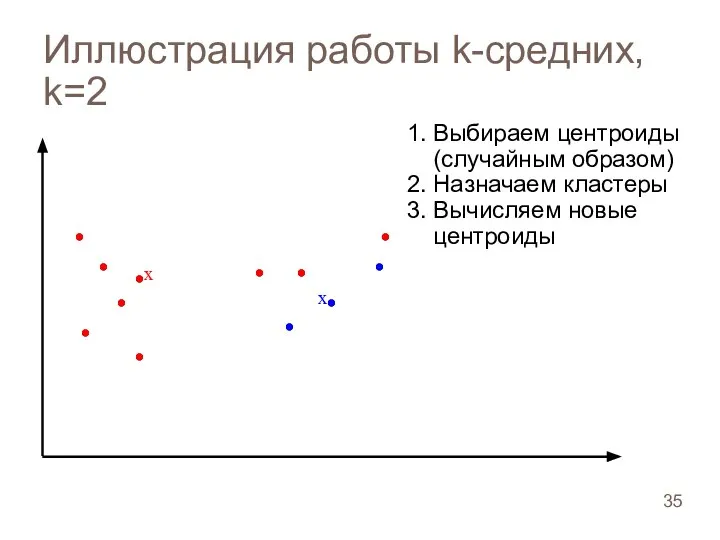
Слайд 36Иллюстрация работы k-средних, k=2
Иллюстрация работы k-средних, k=2
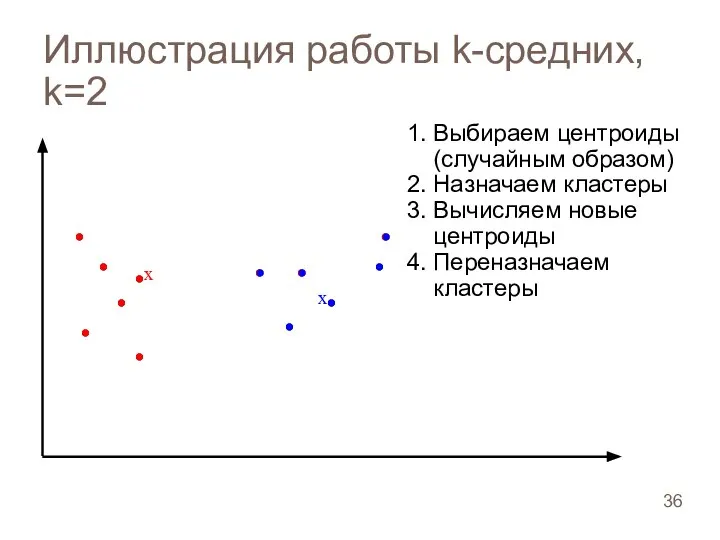
Слайд 37Иллюстрация работы k-средних, k=2
Иллюстрация работы k-средних, k=2
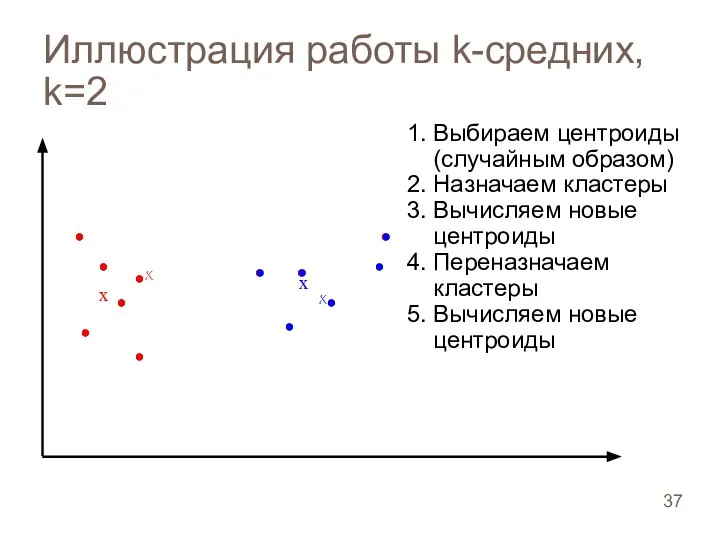
Слайд 38Иллюстрация работы k-средних, k=2
Иллюстрация работы k-средних, k=2
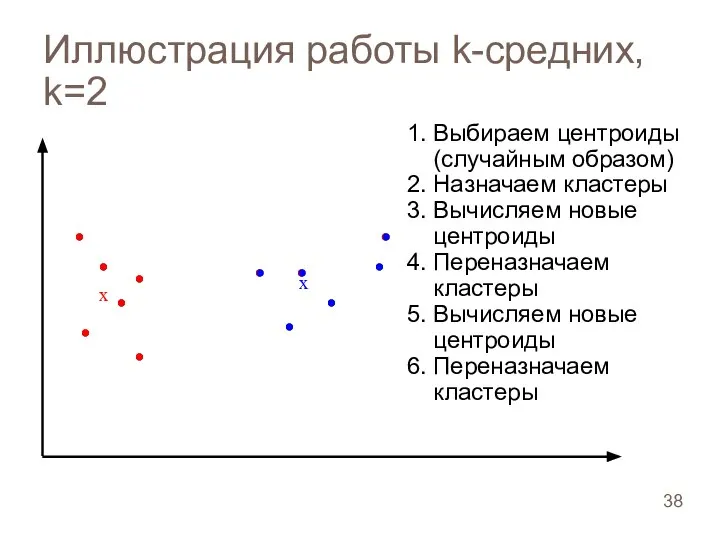
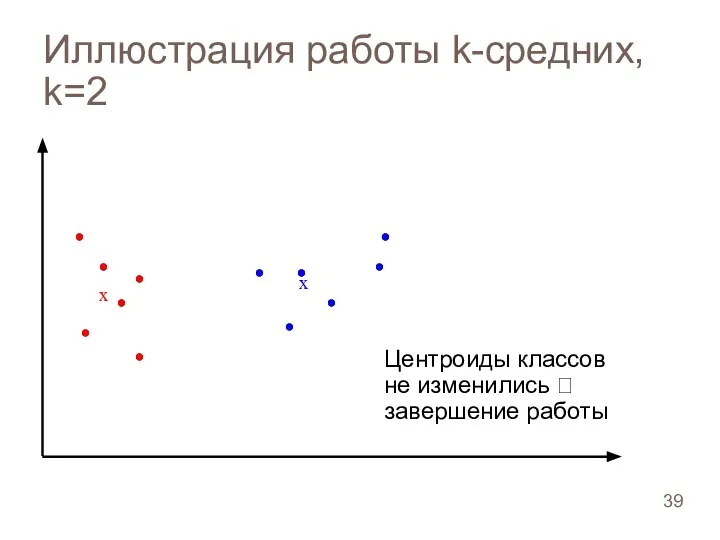
Слайд 39Иллюстрация работы k-средних, k=2
Центроиды классов
не изменились ? завершение работы
Иллюстрация работы k-средних, k=2
Центроиды классов
не изменились ? завершение работы
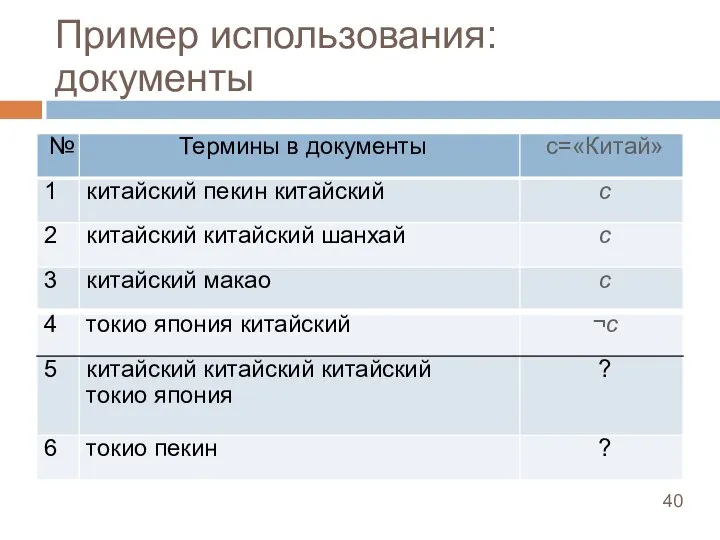
Слайд 40Пример использования: документы
Пример использования: документы
Слайд 41Пример использования: применение алгоритма
Итерация 1. Случайным образом инициализированы μi:
μ1=[0,96 0,80 0,42
Пример использования: применение алгоритма
Итерация 1. Случайным образом инициализированы μi:
μ1=[0,96 0,80 0,42

Слайд 42Пример использования: уменьшение цветов изображения
Охарактеризуйте
рисунки с точки зрения
цвета
Пример использования: уменьшение цветов изображения
Охарактеризуйте
рисунки с точки зрения
цвета

Слайд 43Пример использования: уменьшение цветов изображения
64 цвета (случайно)
96615 цветов
64 цвета (K-means)
Пример использования: уменьшение цветов изображения
64 цвета (случайно)
96615 цветов
64 цвета (K-means)

Слайд 44Проблемы алгоритма k-средних
Не гарантируется достижение глобального минимума суммарного квадратичного отклонения e(D,C) ?
Результат
Проблемы алгоритма k-средних
Не гарантируется достижение глобального минимума суммарного квадратичного отклонения e(D,C) ?
Результат

Слайд 45Плоский нечеткий алгоритм c-средних (c-means)
Является модификацией метода k-средних
Входные данные:
количество кластеров
Плоский нечеткий алгоритм c-средних (c-means)
Является модификацией метода k-средних
Входные данные:
количество кластеров

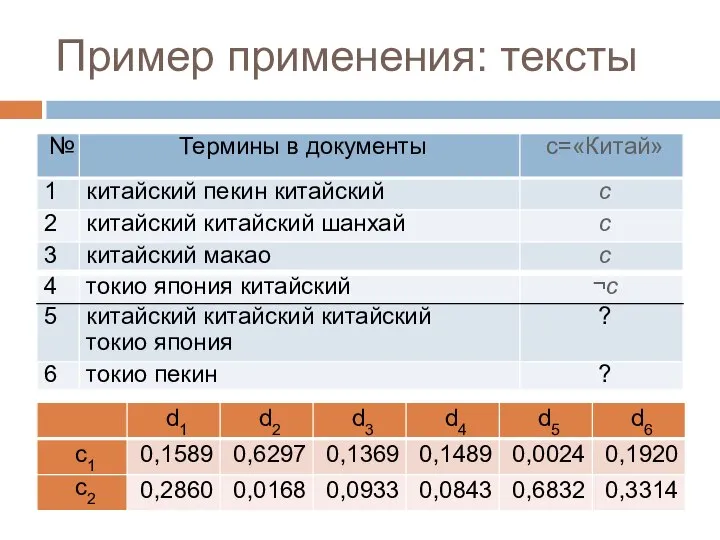
Слайд 46Пример применения: тексты
Пример применения: тексты
Слайд 47Оценка качества кластеризации
Вычисляются меры двух видов:
Внешние меры: сравнение созданного разбиения с «эталонным»
анализируется
Оценка качества кластеризации
Вычисляются меры двух видов:
Внешние меры: сравнение созданного разбиения с «эталонным»
анализируется

Слайд 48Сравнение алгоритмов кластеризации
Решение задачи кластеризации принципиально неоднозначно:
не существует однозначно наилучшего критерия качества
Сравнение алгоритмов кластеризации
Решение задачи кластеризации принципиально неоднозначно:
не существует однозначно наилучшего критерия качества

Слайд 49Домашнее задание. Вариант 1
1. Взять выбранный к прошлому разу набор данных
Домашнее задание. Вариант 1
1. Взять выбранный к прошлому разу набор данных

Слайд 50Домашнее задание. Вариант 2
Написать программу определения расстояния между текстами
1. Взять несколько
Домашнее задание. Вариант 2
Написать программу определения расстояния между текстами
1. Взять несколько

Слайд 51Домашнее задание. Вариант 3
1. Найти готовые средства визуализации многомерных векторов (текстов)
2.
Домашнее задание. Вариант 3
1. Найти готовые средства визуализации многомерных векторов (текстов)
2.

 Автоматизированная система по управлению бизнес-процессом обработки данных клиента коммерческого банка
Автоматизированная система по управлению бизнес-процессом обработки данных клиента коммерческого банка Презентация на тему Файлы и файловая система (8 класс)
Презентация на тему Файлы и файловая система (8 класс)  Основы работы в toondoo
Основы работы в toondoo Внеклассное мероприятие. Викторина Информатика и логика
Внеклассное мероприятие. Викторина Информатика и логика Создание графических изображений
Создание графических изображений Задача регистрации курсов (use case)
Задача регистрации курсов (use case) Компьютерные сети. Лекция №5. Уровень передачи данных или канальный уровень
Компьютерные сети. Лекция №5. Уровень передачи данных или канальный уровень Проект по информатике: Погода в городе
Проект по информатике: Погода в городе Внедрение и сопровождение 1С
Внедрение и сопровождение 1С Основные этапы работы над веб-сайтом
Основные этапы работы над веб-сайтом Моделирование первой сессии
Моделирование первой сессии Компьютерное проектирование
Компьютерное проектирование Мобильное программирование. Лекция 3
Мобильное программирование. Лекция 3 Платформа в информационных технологиях
Платформа в информационных технологиях Texture_mapping (1)
Texture_mapping (1) Компьютерная графика. Графический редактор
Компьютерная графика. Графический редактор Что такое Osint?
Что такое Osint? Единая система классификации и кодирования технико-экономической информации
Единая система классификации и кодирования технико-экономической информации Автоматический установщик для компьютеров, ноутбуков Msoft
Автоматический установщик для компьютеров, ноутбуков Msoft Бизнес план интернет-магазина подарков
Бизнес план интернет-магазина подарков Электронно-цифровая подпись
Электронно-цифровая подпись Безопасность в Интернете
Безопасность в Интернете Работа с Google диском
Работа с Google диском Больничное отделение. СУБД
Больничное отделение. СУБД Знакомство с python. Занятие №1
Знакомство с python. Занятие №1 EVS в Литве
EVS в Литве Правила работы в ЗУМ
Правила работы в ЗУМ Что такое алгоритм. 6 класс
Что такое алгоритм. 6 класс