- Методы трансляции-1 2022

Содержание
- 2. Формальные языки Алфавит — конечное множество символов. А = {0,1} — алфавит из двух символов: 0
- 3. Примеры Конечный язык можно задать явно: L = {00, 01, 10, 11}. Бесконечный язык описывается либо
- 4. Задачи Построить формальное описание языка (грамматику); по описанию языка определить, принадлежит ли ему заданная цепочка (синтаксический
- 5. Формальные грамматики (1) Формальной грамматикой называется четвёрка G = (А, V, P, s), где А —
- 6. Формальные грамматики (2) Вывод цепочек языка производится следующим образом: в правиле α → β цепочка символов
- 7. Формальные грамматики (3) Обозначения цепочки из (А U V)* обозначаются строчными греческими буквами; цепочки из А*
- 8. Формальные грамматики (4) В процессе вывода строится последовательность цепочек в соответствии с правилами грамматики: каждая следующая
- 9. Типы языков по Хомскому Тип 0 – неограниченные грамматики (рекурсивно вычислимые) Тип 1 – контекстно-зависимые и
- 10. Формальные языки: операции Формальный язык – множество терминальных цепочек. Над ними определены теоретико-множественные операции: объединение, пересечение,
- 11. Формальные языки: конкатенация Конкатенация языков L1 и L2 – множество, содержащее все цепочки, составленные из конкатенаций
- 12. Формальные языки: вывод Множество выводимых цепочек в грамматике (А, V, P, s) рекурсивно задаётся так: s
- 13. Формальные языки: определение Язык, порождаемый грамматикой G = (А, V, P, s) —это множество терминальных цепочек,
- 14. Формальные языки: нотация Существует несколько форм записи правил грамматики. Для правил с одинаковыми левыми частями их
- 15. Дерево вывода (1) Основная задача синтаксического анализа — построение вывода в заданной грамматике. Однако важен не
- 16. Дерево вывода (2) Дерево вывода — граф с вершинами, помеченными нетерминалами и терминалами. Дуги направлены к
- 17. Неоднозначный вывод (1) Рассмотрим условный оператор в языке Паскаль. oper → if b then oper |
- 18. Неоднозначный вывод (2) В теории есть понятие неоднозначной грамматики, в которой существует хотя бы одна цепочка,
- 19. Эквивалентные грамматики Грамматики, которые порождают один и тот же язык, называются эквивалентными. Пример: грамматика с правилами
- 20. Нормальные формы грамматик (1) Недостижимые нетерминалы не могут появиться ни в одной цепочке, выводимой из начального
- 21. Нормальные формы грамматик (2) Грамматика имеет нормальную форму Хомского, если все правые части состоят из двух
- 22. Регулярные грамматики и выражения (1) Грамматика называется регулярной (автоматной), если все правила имеют вид u →
- 23. Регулярные грамматики и выражения (2) Регулярный язык может порождаться и нерегулярной грамматикой. Пример – грамматика G0
- 24. Регулярные грамматики и выражения (3) Таким способом можно заменить правила, у которых перед нетерминалом стоит любое
- 25. Регулярное множество (определение) пустое множество ∅ — регулярное множество; множество из пустой цепочки {ε} — регулярное
- 26. Регулярное множество (пример) Язык L0 = {0, 1, 100, 10000, …} строится из атомарных множеств {1}
- 27. Регулярное выражение (1) С помощью операций можно составлять уравнения из констант и переменных, значения которых –регулярные
- 28. Регулярное выражение (2) Представим правила грамматики s → 1u | 1, u → 00u | 00
- 29. Конечный автомат (определение) Конечный автомат — это K = (Q, A, δ, q0, F), где Q
- 30. Конечный автомат описание (1) Конечный автомат — это частный случай машины Тьюринга, но нет записи на
- 31. Конечный автомат описание (2) Конечный автомат — абстрактная машина с лентой, разбитой на клетки, в которых
- 32. Конечный автомат конфигурация (1) В начале работы автомат находится в начальном состоянии, головка стоит на самом
- 33. Конечный автомат конфигурация (2) Цепочка считается допустимой, если существует хотя бы одна последовательность конфигураций, переводящая начальную
- 34. Конечный автомат пример (1) Автомат K1 = ({s, u, x, y, t} {0, 1}, δ, s,
- 35. Конечный автомат правила построения по грамматике состояния автомата соответствуют нетерминалам; добавлено конечное состояние t; для каждого
- 36. Конечный автомат задание функции перехода Функция перехода может быть представлена в виде таблицы переходов или в
- 37. Конечный автомат диаграмма состояний Диаграмма состояний — ориентированный граф, его вершины помечены состояниями, дуги — входными
- 38. Конечный автомат диаграмма состояний Автомат K1 можно упростить и свести к эквивалентному автомату с меньшим числом
- 39. Конечный автомат недетерминированный и детерминированный При недетерминированном автомате нужно произвести перебор вариантов в тех состояниях, где
- 40. Конечный автомат детерминированный Если в автомате K число состояний n , в автомате K' в общем
- 41. Построение ДКА по КА пример (1) Построим детерминированный автомат K'1 для автомата K1. Из s есть
- 42. Построение ДКА по КА пример (2) Диаграмма построенного детерминированного автомата.
- 44. Скачать презентацию

Слайд 3Примеры
Конечный язык можно задать явно: L = {00, 01, 10, 11}. Бесконечный
Примеры
Конечный язык можно задать явно: L = {00, 01, 10, 11}. Бесконечный

Слайд 4Задачи
Построить формальное описание языка (грамматику);
по описанию языка определить, принадлежит ли ему заданная
Задачи
Построить формальное описание языка (грамматику);
по описанию языка определить, принадлежит ли ему заданная

Слайд 5Формальные грамматики (1)
Формальной грамматикой называется четвёрка G = (А, V, P, s),
Формальные грамматики (1)
Формальной грамматикой называется четвёрка G = (А, V, P, s),

Слайд 6Формальные грамматики (2)
Вывод цепочек языка производится следующим образом:
в правиле α →
Формальные грамматики (2)
Вывод цепочек языка производится следующим образом:
в правиле α →

Слайд 7Формальные грамматики (3)
Обозначения
цепочки из (А U V)* обозначаются строчными греческими буквами;
цепочки
Формальные грамматики (3)
Обозначения
цепочки из (А U V)* обозначаются строчными греческими буквами;
цепочки

Слайд 8Формальные грамматики (4)
В процессе вывода строится последовательность цепочек в соответствии с правилами
Формальные грамматики (4)
В процессе вывода строится последовательность цепочек в соответствии с правилами

Слайд 9Типы языков по Хомскому
Тип 0 – неограниченные грамматики (рекурсивно вычислимые)
Тип 1 –
Типы языков по Хомскому
Тип 0 – неограниченные грамматики (рекурсивно вычислимые)
Тип 1 –

Слайд 10Формальные языки: операции
Формальный язык – множество терминальных цепочек.
Над ними определены теоретико-множественные операции:
Формальные языки: операции
Формальный язык – множество терминальных цепочек.
Над ними определены теоретико-множественные операции:

Слайд 11Формальные языки: конкатенация
Конкатенация языков L1 и L2 – множество, содержащее все цепочки,
Формальные языки: конкатенация
Конкатенация языков L1 и L2 – множество, содержащее все цепочки,

Слайд 12Формальные языки: вывод
Множество выводимых цепочек в грамматике (А, V, P, s) рекурсивно
Формальные языки: вывод
Множество выводимых цепочек в грамматике (А, V, P, s) рекурсивно

Слайд 13Формальные языки: определение
Язык, порождаемый грамматикой G = (А, V, P, s) —это
Формальные языки: определение
Язык, порождаемый грамматикой G = (А, V, P, s) —это

Слайд 14Формальные языки: нотация
Существует несколько форм записи правил грамматики.
Для правил с одинаковыми
Формальные языки: нотация
Существует несколько форм записи правил грамматики.
Для правил с одинаковыми

Слайд 15Дерево вывода (1)
Основная задача синтаксического анализа — построение вывода в заданной грамматике.
Дерево вывода (1)
Основная задача синтаксического анализа — построение вывода в заданной грамматике.

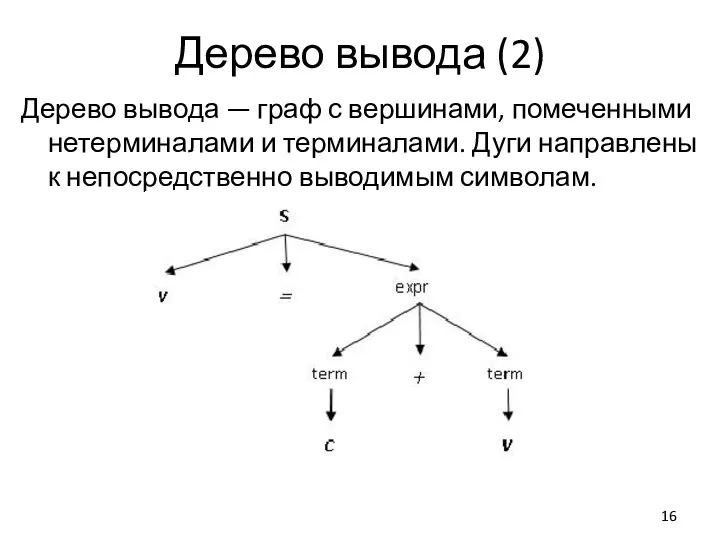
Слайд 16Дерево вывода (2)
Дерево вывода — граф с вершинами, помеченными нетерминалами и терминалами.
Дерево вывода (2)
Дерево вывода — граф с вершинами, помеченными нетерминалами и терминалами.
Слайд 17Неоднозначный вывод (1)
Рассмотрим условный оператор в языке Паскаль.
oper → if b
Неоднозначный вывод (1)
Рассмотрим условный оператор в языке Паскаль.
oper → if b

Слайд 18Неоднозначный вывод (2)
В теории есть понятие неоднозначной грамматики, в которой существует хотя
Неоднозначный вывод (2)
В теории есть понятие неоднозначной грамматики, в которой существует хотя

Слайд 19Эквивалентные грамматики
Грамматики, которые порождают один и тот же язык, называются эквивалентными.
Пример: грамматика
Эквивалентные грамматики
Грамматики, которые порождают один и тот же язык, называются эквивалентными.
Пример: грамматика

Слайд 20Нормальные формы грамматик (1)
Недостижимые нетерминалы не могут появиться ни в одной цепочке,
Нормальные формы грамматик (1)
Недостижимые нетерминалы не могут появиться ни в одной цепочке,

Слайд 21Нормальные формы грамматик (2)
Грамматика имеет нормальную форму Хомского, если все правые части
Нормальные формы грамматик (2)
Грамматика имеет нормальную форму Хомского, если все правые части

Слайд 22Регулярные грамматики и выражения (1)
Грамматика называется регулярной (автоматной), если все правила имеют
Регулярные грамматики и выражения (1)
Грамматика называется регулярной (автоматной), если все правила имеют

Слайд 23Регулярные грамматики и выражения (2)
Регулярный язык может порождаться и нерегулярной грамматикой.
Пример
Регулярные грамматики и выражения (2)
Регулярный язык может порождаться и нерегулярной грамматикой.
Пример

Слайд 24Регулярные грамматики и выражения (3)
Таким способом можно заменить правила, у которых перед
Регулярные грамматики и выражения (3)
Таким способом можно заменить правила, у которых перед

Слайд 25Регулярное множество (определение)
пустое множество ∅ — регулярное множество;
множество из пустой цепочки {ε}
Регулярное множество (определение)
пустое множество ∅ — регулярное множество;
множество из пустой цепочки {ε}

Слайд 26Регулярное множество (пример)
Язык L0 = {0, 1, 100, 10000, …} строится из
Регулярное множество (пример)
Язык L0 = {0, 1, 100, 10000, …} строится из

Слайд 27Регулярное выражение (1)
С помощью операций можно составлять уравнения из констант и переменных,
Регулярное выражение (1)
С помощью операций можно составлять уравнения из констант и переменных,

Слайд 28Регулярное выражение (2)
Представим правила грамматики s → 1u | 1, u →
Регулярное выражение (2)
Представим правила грамматики s → 1u | 1, u →

Слайд 29Конечный автомат
(определение)
Конечный автомат — это K = (Q, A, δ, q0, F),
Конечный автомат
(определение)
Конечный автомат — это K = (Q, A, δ, q0, F),

Слайд 30Конечный автомат
описание (1)
Конечный автомат — это частный случай машины Тьюринга, но нет
Конечный автомат
описание (1)
Конечный автомат — это частный случай машины Тьюринга, но нет

Слайд 31Конечный автомат
описание (2)
Конечный автомат — абстрактная машина с лентой, разбитой на клетки,
Конечный автомат
описание (2)
Конечный автомат — абстрактная машина с лентой, разбитой на клетки,

Слайд 32Конечный автомат
конфигурация (1)
В начале работы автомат находится в начальном состоянии, головка
Конечный автомат
конфигурация (1)
В начале работы автомат находится в начальном состоянии, головка

Слайд 33Конечный автомат
конфигурация (2)
Цепочка считается допустимой, если существует хотя бы одна последовательность конфигураций,
Конечный автомат
конфигурация (2)
Цепочка считается допустимой, если существует хотя бы одна последовательность конфигураций,

Слайд 34Конечный автомат
пример (1)
Автомат K1 = ({s, u, x, y, t} {0, 1},
Конечный автомат
пример (1)
Автомат K1 = ({s, u, x, y, t} {0, 1},

Слайд 35Конечный автомат
правила построения по грамматике
состояния автомата соответствуют нетерминалам;
добавлено конечное состояние t;
для каждого
Конечный автомат
правила построения по грамматике
состояния автомата соответствуют нетерминалам;
добавлено конечное состояние t;
для каждого

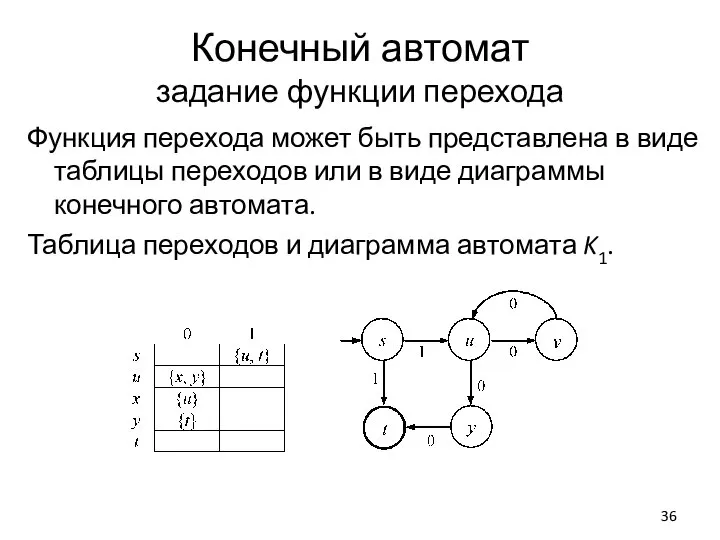
Слайд 36Конечный автомат
задание функции перехода
Функция перехода может быть представлена в виде таблицы переходов
Конечный автомат
задание функции перехода
Функция перехода может быть представлена в виде таблицы переходов
Слайд 37Конечный автомат
диаграмма состояний
Диаграмма состояний — ориентированный граф, его вершины помечены состояниями, дуги
Конечный автомат
диаграмма состояний
Диаграмма состояний — ориентированный граф, его вершины помечены состояниями, дуги

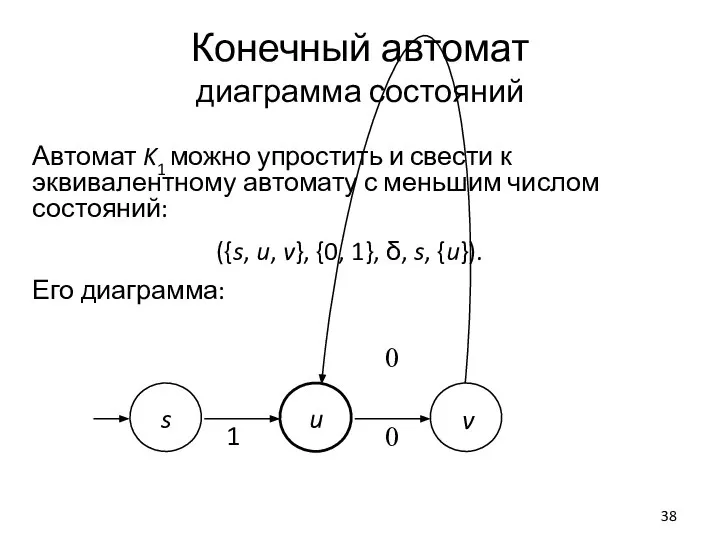
Слайд 38Конечный автомат
диаграмма состояний
Автомат K1 можно упростить и свести к эквивалентному автомату с
Конечный автомат
диаграмма состояний
Автомат K1 можно упростить и свести к эквивалентному автомату с
Слайд 39Конечный автомат
недетерминированный и детерминированный
При недетерминированном автомате нужно произвести перебор вариантов в тех
Конечный автомат
недетерминированный и детерминированный
При недетерминированном автомате нужно произвести перебор вариантов в тех

Слайд 40Конечный автомат
детерминированный
Если в автомате K число состояний n , в автомате K'
Конечный автомат
детерминированный
Если в автомате K число состояний n , в автомате K'

Слайд 41Построение ДКА по КА
пример (1)
Построим детерминированный автомат K'1 для автомата K1.
Из s
Построение ДКА по КА
пример (1)
Построим детерминированный автомат K'1 для автомата K1.
Из s

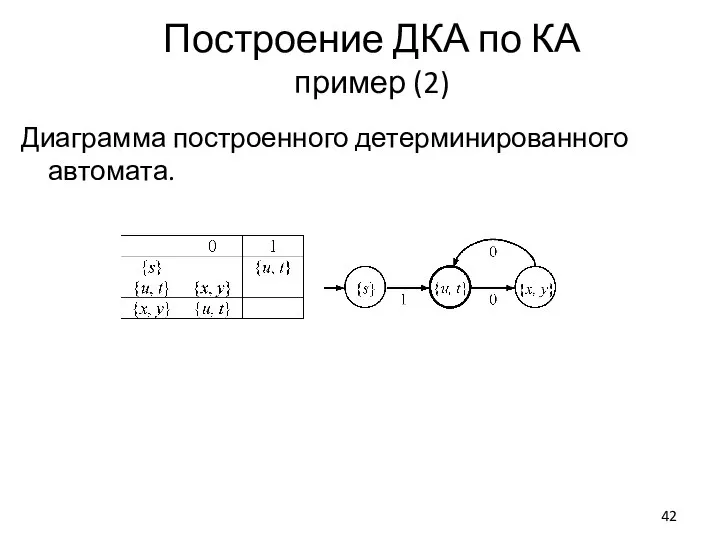
Слайд 42Построение ДКА по КА
пример (2)
Диаграмма построенного детерминированного автомата.
Построение ДКА по КА
пример (2)
Диаграмма построенного детерминированного автомата.
 1666246426895__a84q6r
1666246426895__a84q6r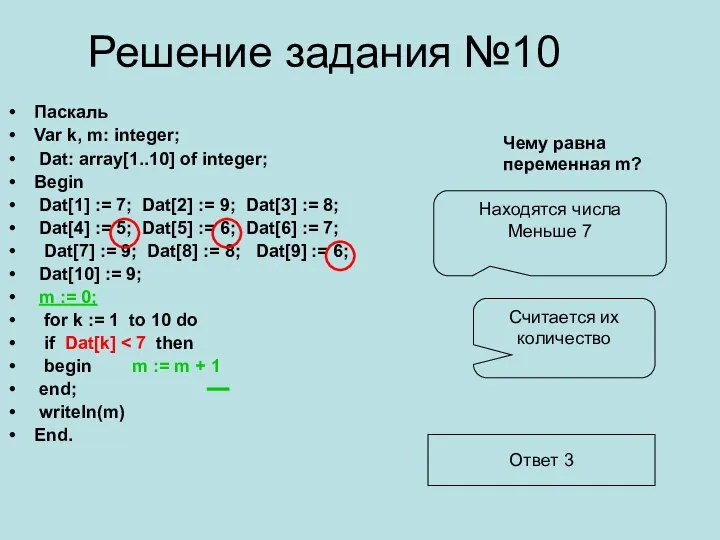 Решение задания №10. Паскаль
Решение задания №10. Паскаль Одномерные массивы. Урок информатики в 11а классе
Одномерные массивы. Урок информатики в 11а классе Презентация на тему Основы HTML
Презентация на тему Основы HTML  Инструкция по получению электроной почты студента
Инструкция по получению электроной почты студента Уроки безопасности в Интернете
Уроки безопасности в Интернете Работа в Excel
Работа в Excel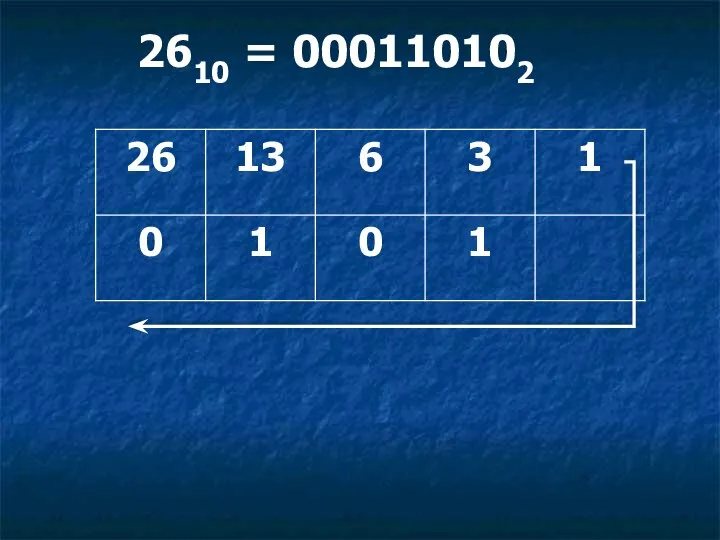 Кодирование графической информации. Флажковая азбука
Кодирование графической информации. Флажковая азбука Электронная рабочая тетрадь. Создание, понятие, структура
Электронная рабочая тетрадь. Создание, понятие, структура Базы данных
Базы данных Операционные системы: виды, назначение. Антивирусное ПО: виды назначение
Операционные системы: виды, назначение. Антивирусное ПО: виды назначение Windows 11 – операционная система 2021
Windows 11 – операционная система 2021 /Мой первый код благотворительный проект игровое программирование для школьников 8-12 лет
/Мой первый код благотворительный проект игровое программирование для школьников 8-12 лет Nodejs intro
Nodejs intro Мобильное Электронное Образование в ДОУ – доступность качественного образования
Мобильное Электронное Образование в ДОУ – доступность качественного образования Инстаграм-программа Sprechen Sie Deutsch? (Разговариваете ли вы на немецком?)
Инстаграм-программа Sprechen Sie Deutsch? (Разговариваете ли вы на немецком?) Анти - вирусы и вирусы
Анти - вирусы и вирусы Программное обеспечение
Программное обеспечение Продвижение учреждения дополнительного образования в социальных сетях
Продвижение учреждения дополнительного образования в социальных сетях Основы программирования на Python
Основы программирования на Python Информационно-технологическая архитектура ИС
Информационно-технологическая архитектура ИС Системы счисления. Непозиционные системы счисления
Системы счисления. Непозиционные системы счисления Цвет в компьютерной графики
Цвет в компьютерной графики Синтаксис оператора
Синтаксис оператора Поиск информации в Интернет. Занятие №7
Поиск информации в Интернет. Занятие №7 Разработка автоматизированной информационной системы для строительного магазина
Разработка автоматизированной информационной системы для строительного магазина Управление собой и другими людьми. 4 класс
Управление собой и другими людьми. 4 класс Информатика. Техника безопасности. Информация и знания
Информатика. Техника безопасности. Информация и знания