- Принцип организации и преимущества колонки-ориентированной со сжатым словарем базы данных в памяти

Содержание
- 2. 1. Изменения в аппаратном обеспечении Прогресс в аппаратном обеспечении Мультиядерная архитектрура 8 х (8 – 15)
- 3. Иерархия памяти
- 4. Показатели задержки
- 5. Архитектура CPU
- 6. В связи с тенденцией перехода в современных компьютерных системах от многоядерности к многоядерным системам и продолжением
- 8. Система UMA характеризуется детерминированным временем доступа для произвольного адреса памяти, независимо от того, какой процессор делает
- 9. Системы NUMA дополнительно классифицированы на кэш-когерентную NUMA (ccNUMA) и не кэш-когерентную NUMA. Системы ccNUMA обеспечивают каждому
- 10. Чтобы в полной мере использовать потенциал NUMA, приложения должны быть осведомлены о различных местоположениях памяти и
- 11. Масштабирование основной памяти системы
- 12. Следующий рисунок показывает пример установки для масштабирования системы управления базами данных на основе основной памяти с
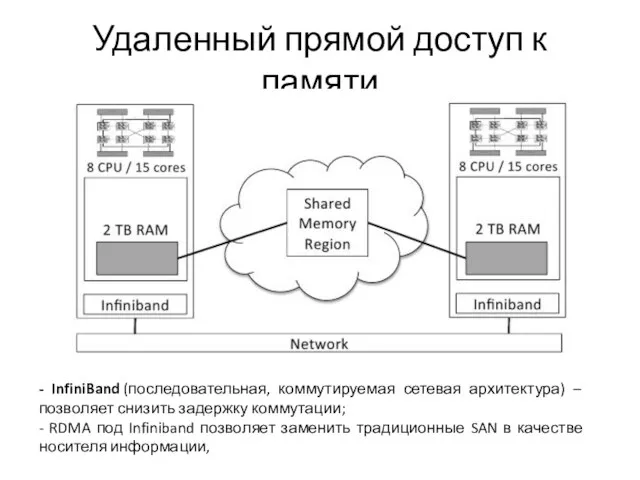
- 13. Удаленный прямой доступ к памяти Использование разделяемой памяти для прямого доступа к памяти на удаленных узлах
- 14. Удаленный прямой доступ к памяти - InfiniBand (последовательная, коммутируемая сетевая архитектура) – позволяет снизить задержку коммутации;
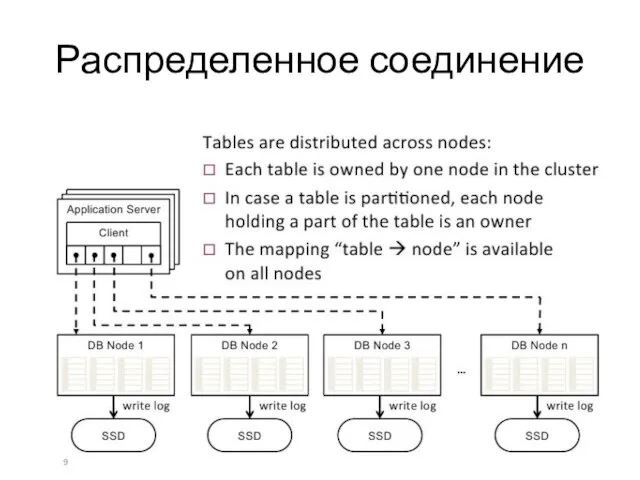
- 15. Распределенное соединение
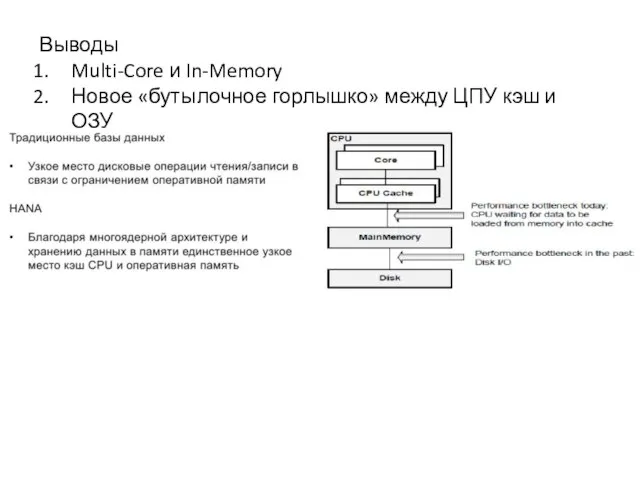
- 16. Выводы Multi-Core и In-Memory Новое «бутылочное горлышко» между ЦПУ кэш и ОЗУ
- 17. 2. Кодирование словаря Так как память является новым узким местом, требуется минимизировать доступ к ней. Доступ
- 19. SanssouciDB является прототипом системы баз данных для унифицированной аналитической и транзакционной обработки. Концепция SanssouciDB построена на
- 20. В отличие от большинства других баз данных, данные SanssouciDB постоянно держит в основной памяти. Оперативная память
- 21. База данных «столбец-ориентированная» Другая концепция, используемая в SanssouciDB, была изобретена более чем два десятилетия назад: хранение
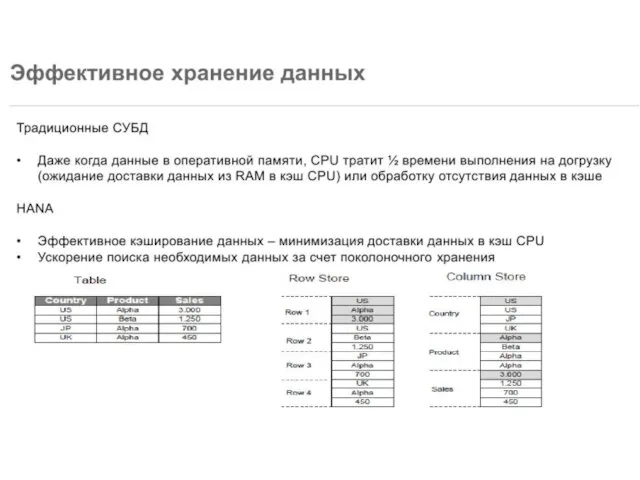
- 22. Чтобы свести к минимуму количество данных, которые должны быть переданы между местом их хранения и процессором,
- 23. Следствия столбец-ориентации Столбец-ориентированное хранение получило широкое распространение в системах баз данных, специально разработанных для OLAP, где
- 24. Кодирование словаря является относительно простым. Это означает не только то, что его легко понять, но также,
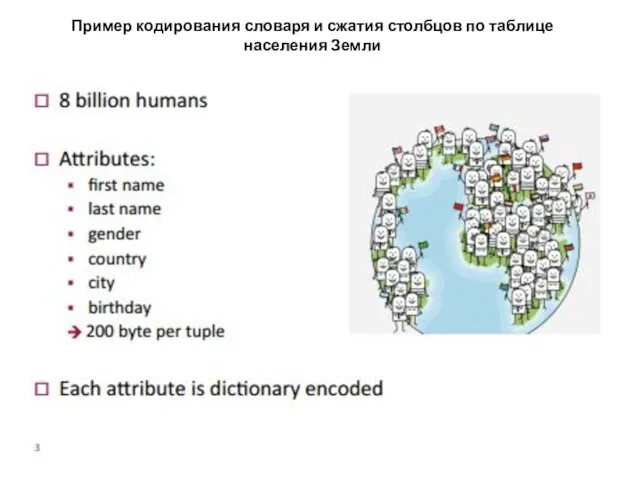
- 25. Пример кодирования словаря и сжатия столбцов по таблице населения Земли
- 27. Кодирование словаря по столбцам ¨ столбец разделен на словарь и вектор атрибутов ¨ словарь сохраняет все
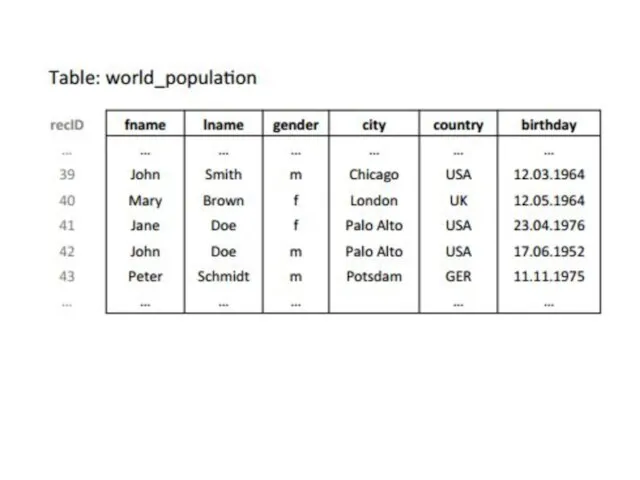
- 28. Кодирование словаря применяется к каждому столбцу таблицы отдельно. В примере, каждое отличающееся значение имени в первом
- 29. Принимая во внимание таблицу населения Земли на 8 миллиардов строк и 200 байт на строку: полный
- 30. Сколько битов потребуется для представления всех 5 миллионов различных значений первого столбца имя "имя"? Таким образом,
- 31. Достигнутый коэффициент сжатия может быть рассчитан следующим образом: Это означает, что мы сократили размер столбца в
- 32. Пример кодирования словаря: пол Теперь, давайте посмотрим на столбец пол. Он имеет лишь 2 различных значения.
- 33. Достигнутый коэффициент сжатия может быть рассчитан следующим образом: Степень сжатия зависит от размера первоначального типа данных,
- 34. Энтропия является мерой, которая выражает, как много содержится информации в колонке (мера плотности информации). Она рассчитывается
- 36. Отсортированный словарь Записи словаря сортируются либо по их числовым значением или лексикографически сложность словаря тогда выглядит
- 37. Преимущества кодированного словаря увеличиваются, если к словарю применяется сортировка. Получение значения из отсортированного словаря ускоряет процесс
- 38. Выводы
- 40. Скачать презентацию
Слайд 21. Изменения в аппаратном обеспечении
Прогресс в аппаратном обеспечении
Мультиядерная архитектрура 8 х (8
1. Изменения в аппаратном обеспечении
Прогресс в аппаратном обеспечении
Мультиядерная архитектрура 8 х (8
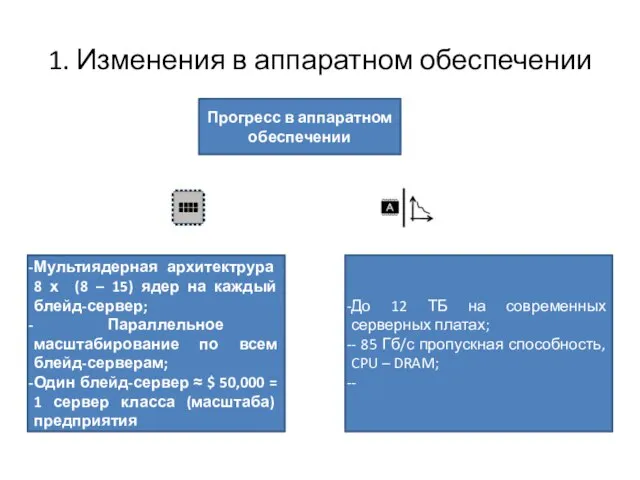
Слайд 3Иерархия памяти
Иерархия памяти
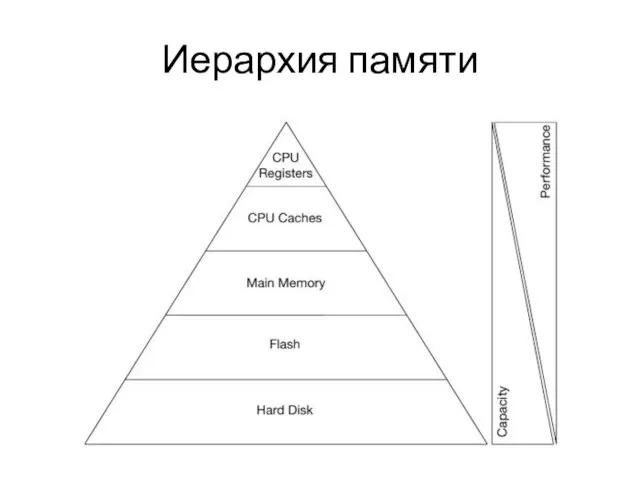
Слайд 4Показатели задержки
Показатели задержки
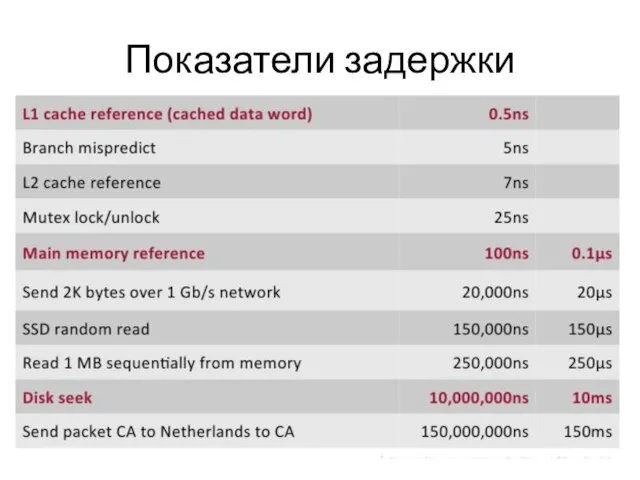
Слайд 5Архитектура CPU
Архитектура CPU
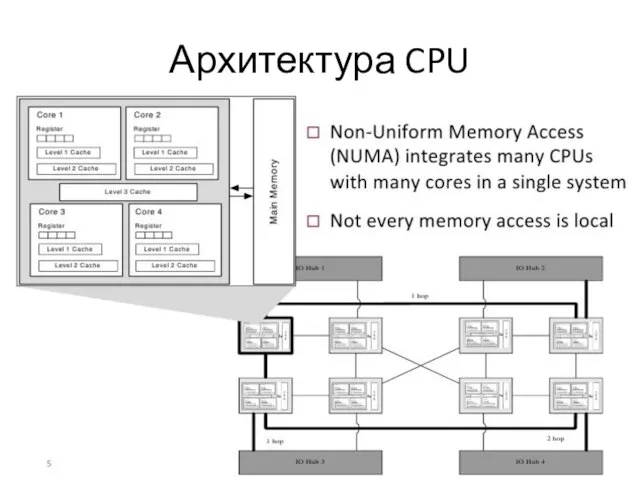
Слайд 6В связи с тенденцией перехода в современных компьютерных системах от многоядерности к
В связи с тенденцией перехода в современных компьютерных системах от многоядерности к

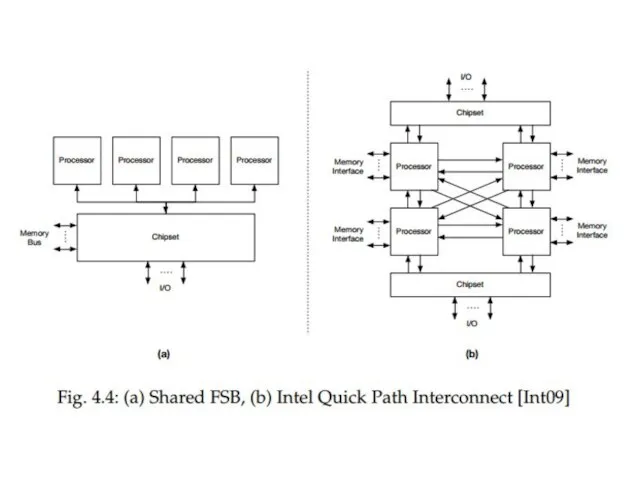
Слайд 8Система UMA характеризуется детерминированным временем доступа для произвольного адреса памяти, независимо от
Система UMA характеризуется детерминированным временем доступа для произвольного адреса памяти, независимо от

Слайд 9Системы NUMA дополнительно классифицированы на кэш-когерентную NUMA (ccNUMA) и не кэш-когерентную NUMA.
Системы NUMA дополнительно классифицированы на кэш-когерентную NUMA (ccNUMA) и не кэш-когерентную NUMA.

Слайд 10Чтобы в полной мере использовать потенциал NUMA, приложения должны быть осведомлены о
Чтобы в полной мере использовать потенциал NUMA, приложения должны быть осведомлены о

Слайд 11Масштабирование основной памяти системы
Масштабирование основной памяти системы
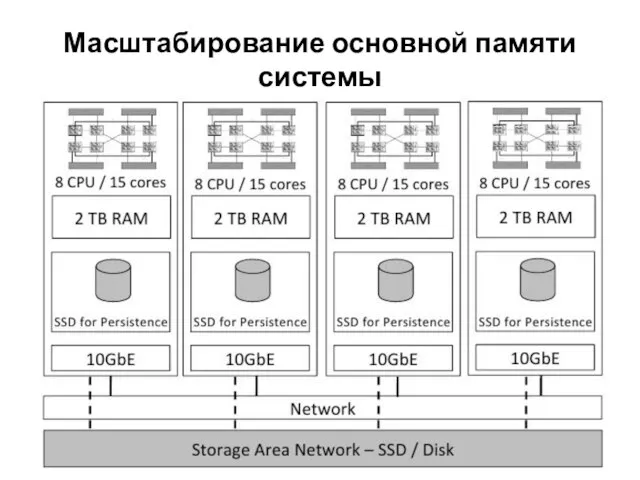
Слайд 12Следующий рисунок показывает пример установки для масштабирования системы управления базами данных на
Следующий рисунок показывает пример установки для масштабирования системы управления базами данных на

Слайд 13Удаленный прямой доступ к памяти
Использование разделяемой памяти для прямого доступа к памяти
Удаленный прямой доступ к памяти
Использование разделяемой памяти для прямого доступа к памяти

Слайд 14Удаленный прямой доступ к памяти
- InfiniBand (последовательная, коммутируемая сетевая архитектура) – позволяет снизить
Удаленный прямой доступ к памяти
- InfiniBand (последовательная, коммутируемая сетевая архитектура) – позволяет снизить
Слайд 15Распределенное соединение
Распределенное соединение
Слайд 16Выводы
Multi-Core и In-Memory
Новое «бутылочное горлышко» между ЦПУ кэш и ОЗУ
Выводы
Multi-Core и In-Memory
Новое «бутылочное горлышко» между ЦПУ кэш и ОЗУ
Слайд 172. Кодирование словаря
Так как память является новым узким местом, требуется минимизировать доступ
2. Кодирование словаря
Так как память является новым узким местом, требуется минимизировать доступ

Слайд 19SanssouciDB является прототипом системы баз данных для унифицированной аналитической и транзакционной обработки.
SanssouciDB является прототипом системы баз данных для унифицированной аналитической и транзакционной обработки.

Слайд 20В отличие от большинства других баз данных, данные SanssouciDB постоянно держит в
В отличие от большинства других баз данных, данные SanssouciDB постоянно держит в

Слайд 21База данных «столбец-ориентированная»
Другая концепция, используемая в SanssouciDB, была изобретена более чем два
База данных «столбец-ориентированная»
Другая концепция, используемая в SanssouciDB, была изобретена более чем два

Слайд 22Чтобы свести к минимуму количество данных, которые должны быть переданы между местом
Чтобы свести к минимуму количество данных, которые должны быть переданы между местом

Слайд 23Следствия столбец-ориентации
Столбец-ориентированное хранение получило широкое распространение в системах баз данных, специально разработанных
Следствия столбец-ориентации
Столбец-ориентированное хранение получило широкое распространение в системах баз данных, специально разработанных

Слайд 24Кодирование словаря является относительно простым. Это означает не только то, что его
Кодирование словаря является относительно простым. Это означает не только то, что его

Слайд 25Пример кодирования словаря и сжатия столбцов по таблице населения Земли
Пример кодирования словаря и сжатия столбцов по таблице населения Земли
Слайд 27Кодирование словаря по столбцам
¨ столбец разделен на словарь и вектор атрибутов
¨ словарь
Кодирование словаря по столбцам
¨ столбец разделен на словарь и вектор атрибутов
¨ словарь
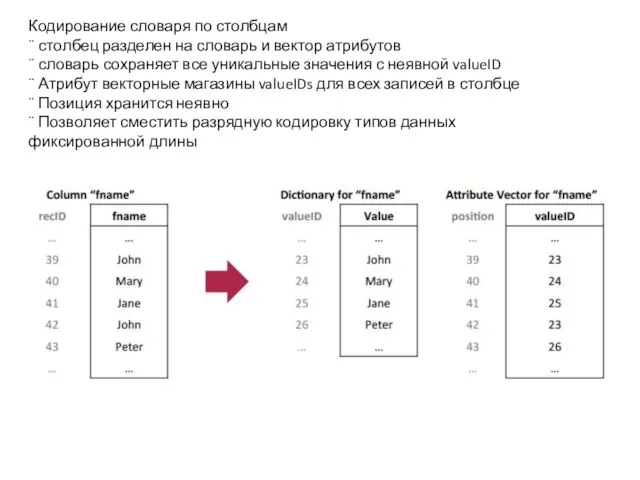
Слайд 28Кодирование словаря применяется к каждому столбцу таблицы отдельно. В примере, каждое отличающееся
Кодирование словаря применяется к каждому столбцу таблицы отдельно. В примере, каждое отличающееся

Слайд 29Принимая во внимание таблицу населения Земли на 8 миллиардов строк и 200
Принимая во внимание таблицу населения Земли на 8 миллиардов строк и 200
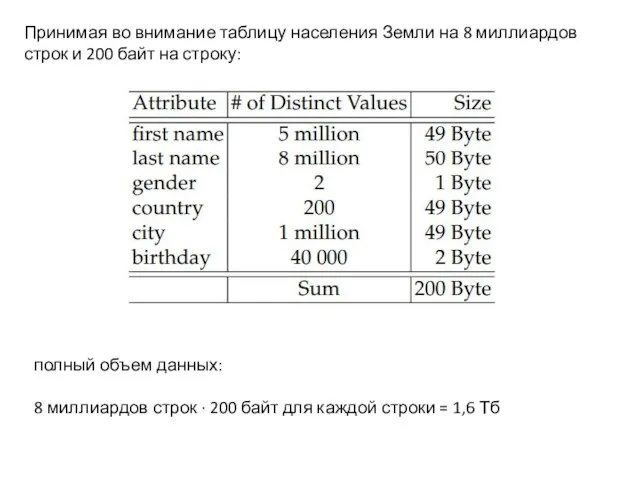
Слайд 30Сколько битов потребуется для представления всех 5 миллионов различных значений первого столбца
Сколько битов потребуется для представления всех 5 миллионов различных значений первого столбца

Слайд 31Достигнутый коэффициент сжатия может быть рассчитан следующим образом:
Это означает, что мы сократили
Достигнутый коэффициент сжатия может быть рассчитан следующим образом:
Это означает, что мы сократили

Слайд 32Пример кодирования словаря: пол
Теперь, давайте посмотрим на столбец пол. Он имеет лишь
Пример кодирования словаря: пол
Теперь, давайте посмотрим на столбец пол. Он имеет лишь

Слайд 33Достигнутый коэффициент сжатия может быть рассчитан следующим образом:
Степень сжатия зависит от размера
Достигнутый коэффициент сжатия может быть рассчитан следующим образом:
Степень сжатия зависит от размера

Слайд 34Энтропия является мерой, которая выражает, как много содержится информации в колонке (мера
Энтропия является мерой, которая выражает, как много содержится информации в колонке (мера

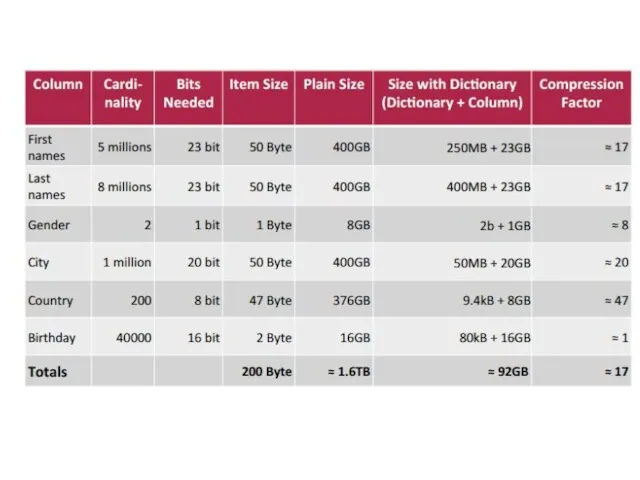
Слайд 36Отсортированный словарь
Записи словаря сортируются либо по их числовым значением или лексикографически
сложность словаря
Отсортированный словарь
Записи словаря сортируются либо по их числовым значением или лексикографически
сложность словаря

Слайд 37Преимущества кодированного словаря увеличиваются, если к словарю применяется сортировка.
Получение значения из отсортированного
Преимущества кодированного словаря увеличиваются, если к словарю применяется сортировка.
Получение значения из отсортированного

Слайд 38Выводы
Выводы

 Лекция 5 (Принципы передачи по сети)
Лекция 5 (Принципы передачи по сети) Интернет и английский язык: что нужно знать пользователю подростку
Интернет и английский язык: что нужно знать пользователю подростку Ромашки. Электронная физминутка для глаз
Ромашки. Электронная физминутка для глаз іт гр 32 урок 2
іт гр 32 урок 2 Внедрение VPN. Внедрение Web Application Proxy
Внедрение VPN. Внедрение Web Application Proxy Подготовка схемы расположения земельного участка
Подготовка схемы расположения земельного участка Презентація (1)
Презентація (1) Компьютер в жизни школьника – это целый мир
Компьютер в жизни школьника – это целый мир 8-3py_Основы программирования (Python)
8-3py_Основы программирования (Python) Циклы и комбинированные алгоритмы. Практическая работа
Циклы и комбинированные алгоритмы. Практическая работа Netiqueta
Netiqueta Лабораторная работа по компьютерной графике в графическом редакторе Gimp. Осенний коллаж
Лабораторная работа по компьютерной графике в графическом редакторе Gimp. Осенний коллаж Всемирная путина (World Wide Web)
Всемирная путина (World Wide Web) Linux. Файлы и права доступа в Linux
Linux. Файлы и права доступа в Linux Минимизация ДНФ методом Квайна
Минимизация ДНФ методом Квайна Электронные таблицы EXCEL
Электронные таблицы EXCEL Пятое занятие. Функции
Пятое занятие. Функции SE Ranking – комплекс незаменимых инструментов для SEO и онлайн-маркетинга
SE Ranking – комплекс незаменимых инструментов для SEO и онлайн-маркетинга Guarantor Registration
Guarantor Registration Решение кейса недели экологии
Решение кейса недели экологии Циклы Pascal
Циклы Pascal Валидация ParCur. Шаблон для представления результатов проекта
Валидация ParCur. Шаблон для представления результатов проекта Алгоритмизация, как условие автоматизации
Алгоритмизация, как условие автоматизации Формализация функциональных требований к системе с помощью диаграммы вариантов использования
Формализация функциональных требований к системе с помощью диаграммы вариантов использования Процесс разработки программного обеспечения
Процесс разработки программного обеспечения Концепция электронного голосования
Концепция электронного голосования Повторение Питон
Повторение Питон Системный таймер
Системный таймер