- Sequence to sequence. Модели и механизм внимания

Содержание
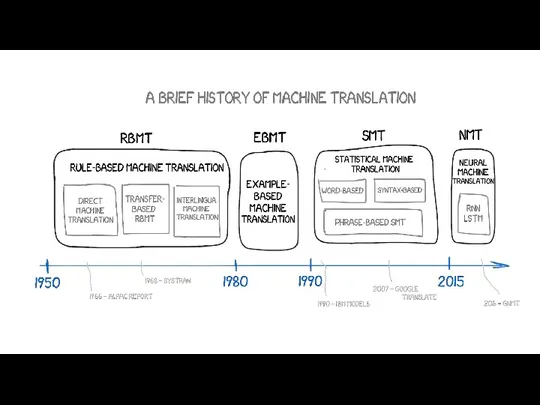
- 2. План лекции Задачи Sequence to Sequence Архитектура энкодер-декодер Механизм внимания Tips & Tricks Разбор примера Machine
- 3. RNN Recap
- 4. RNN Recap len(input) != len(output)
- 5. Задачи Sequence to Sequence Распознавание речи (spectrum -> text) Синтез речи (text -> waveform) Рукописный ввод
- 6. Speech recognition
- 7. Speech Synthesis
- 8. Рукописный ввод
- 9. Задача перевода Rosetta Stone ---> Параллельный корпус, найден в 1799 г. Позволил расшифровать египетские иероглифы
- 11. Чатботы
- 12. RNN Sequence-to-sequence model Google, Sutskever et al. 2014 Encoder Decoder https://arxiv.org/pdf/1409.3215.pdf
- 13. RNN Sequence-to-sequence model Cho et al. 2014 Encoder (same) Decoder https://www.aclweb.org/anthology/D14-1179
- 14. RNN Sequence-to-sequence model Улучшения: Deep Encoder Deep Decoder LSTM Layer 1 LSTM Layer 2 LSTM Layer
- 15. RNN Sequence-to-sequence model Улучшения: Bidirectional Encoder Forward LSTM Backward LSTM
- 16. RNN Sequence-to-sequence model Проблемы: Размер стейта фиксирован Изменения из начала последовательности затираются Не все входные токены
- 17. RNN Sequence-to-sequence model Решение: Внимание
- 18. Механизм внимания, мотивация Xu et al. 2015 Show, Attend and Tell: Neural Image Caption Generation with
- 20. Soft vs Hard Attention Hard Выбор одной/n областей Получаем сэмплингом из softmax Не дифференцируем Нужно учить
- 21. Механизм внимания, мотивация В случае машинного перевода
- 22. Механизм внимания, alignment
- 23. Механизм внимания, мотивация https://github.com/google/seq2seq
- 24. Механизм внимания https://arxiv.org/pdf/1409.0473.pdf
- 25. Механизм внимания Bahdanau et al. 2014 https://arxiv.org/pdf/1409.0473.pdf
- 26. Механизм внимания Bahdanau et al. 2014 Карта внимания или alignment слов https://arxiv.org/pdf/1409.0473.pdf
- 27. Механизм внимания Bahdanau et al. 2014 https://arxiv.org/pdf/1409.0473.pdf
- 28. Attention function Dot Product General Additive
- 29. Практические нюансы Wordpiece models and character-based models Pretrained embeddings Multihead Attention Teacher Forcing Beam Search
- 30. Проблемы словаря большой размер эмбеддингов и софтмакс слоя (сотни тысяч) неизвестные слова при инференсе, приходится заменять
- 31. Pretrained embeddings
- 32. Wordpiece models, BPE - byte-pair encoding
- 33. Multihead Attention
- 34. Teacher Forcing Подаем на вход декодера не прошлый выход, а верный символ из таргета
- 35. Beam Search
- 36. Beyond attention Attention позволяет построить текущее состояние с учетом всего прошлого последовательности. Одинаково хорошо учитывает данные
- 37. Transformer Attention is all you need, Vaswani et al. 2017 https://arxiv.org/abs/1706.03762 Self-attention instead of recurrence
- 38. Positional encoding Sinusoidal encoding 2. Learned positional embeddings. Position index -> embedding layer -> vector
- 40. Скачать презентацию
Слайд 2План лекции
Задачи Sequence to Sequence
Архитектура энкодер-декодер
Механизм внимания
Tips & Tricks
Разбор примера Machine Translation
План лекции
Задачи Sequence to Sequence
Архитектура энкодер-декодер
Механизм внимания
Tips & Tricks
Разбор примера Machine Translation

Слайд 3RNN Recap
RNN Recap
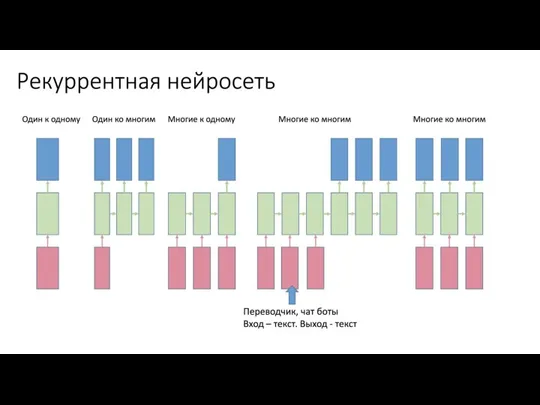
Слайд 4RNN Recap
len(input) != len(output)
RNN Recap
len(input) != len(output)
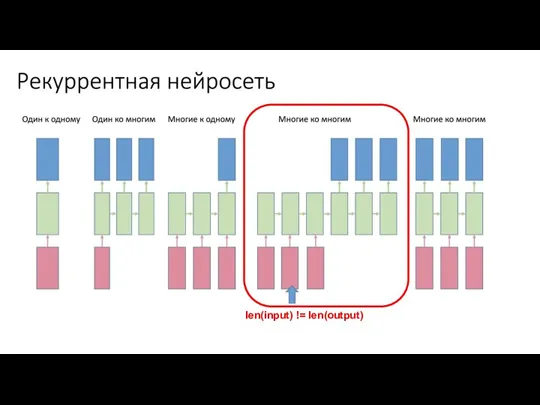
Слайд 5Задачи Sequence to Sequence
Распознавание речи (spectrum -> text)
Синтез речи (text -> waveform)
Рукописный
Задачи Sequence to Sequence
Распознавание речи (spectrum -> text)
Синтез речи (text -> waveform)
Рукописный

Слайд 6Speech recognition
Speech recognition
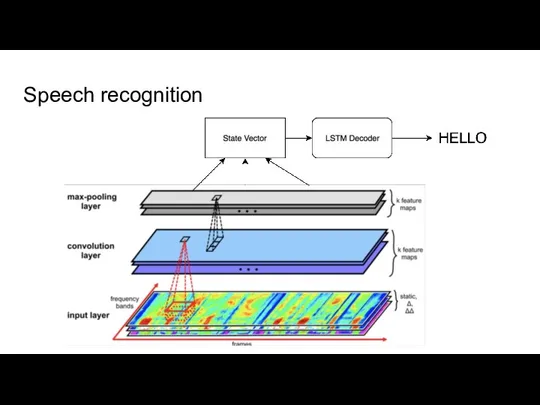
Слайд 7Speech Synthesis
Speech Synthesis
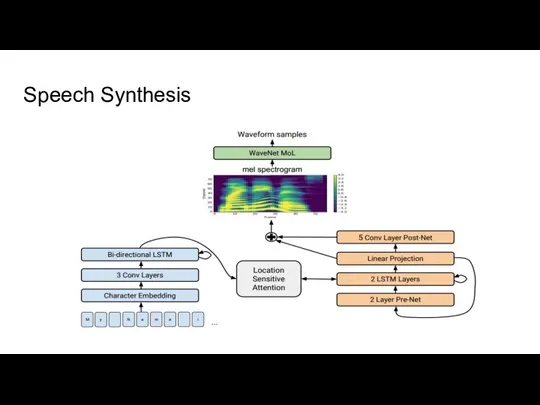
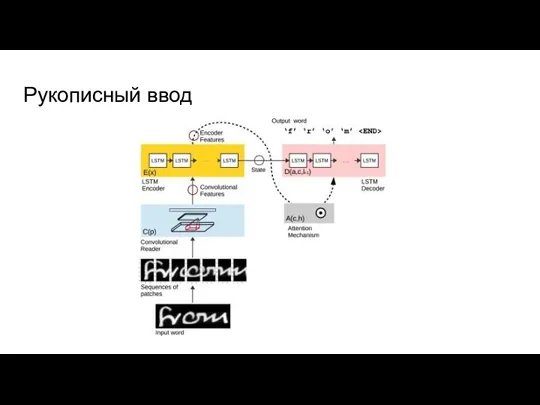
Слайд 8Рукописный ввод
Рукописный ввод
Слайд 9Задача перевода
Rosetta Stone --->
Параллельный корпус, найден в 1799 г.
Позволил расшифровать
египетские
Задача перевода
Rosetta Stone --->
Параллельный корпус, найден в 1799 г.
Позволил расшифровать
египетские

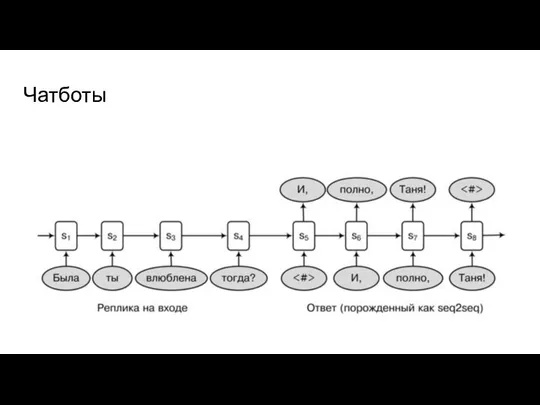
Слайд 11Чатботы
Чатботы
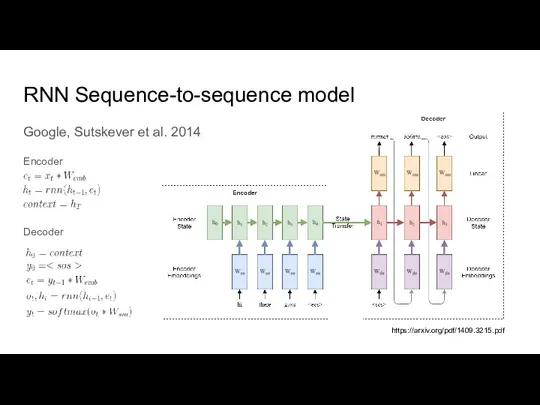
Слайд 12RNN Sequence-to-sequence model
Google, Sutskever et al. 2014
Encoder
Decoder
https://arxiv.org/pdf/1409.3215.pdf
RNN Sequence-to-sequence model
Google, Sutskever et al. 2014
Encoder
Decoder
https://arxiv.org/pdf/1409.3215.pdf
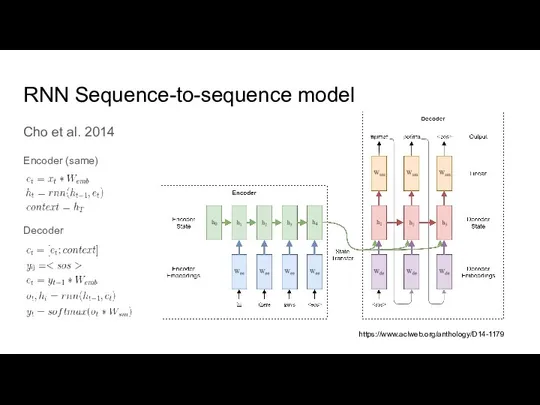
Слайд 13RNN Sequence-to-sequence model
Cho et al. 2014
Encoder (same)
Decoder
https://www.aclweb.org/anthology/D14-1179
RNN Sequence-to-sequence model
Cho et al. 2014
Encoder (same)
Decoder
https://www.aclweb.org/anthology/D14-1179
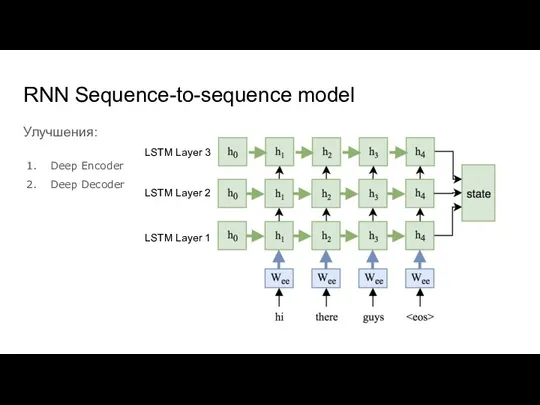
Слайд 14RNN Sequence-to-sequence model
Улучшения:
Deep Encoder
Deep Decoder
LSTM Layer 1
LSTM Layer 2
LSTM Layer 3
RNN Sequence-to-sequence model
Улучшения:
Deep Encoder
Deep Decoder
LSTM Layer 1
LSTM Layer 2
LSTM Layer 3
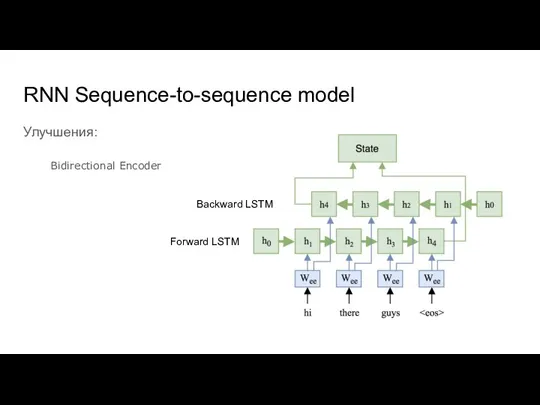
Слайд 15RNN Sequence-to-sequence model
Улучшения:
Bidirectional Encoder
Forward LSTM
Backward LSTM
RNN Sequence-to-sequence model
Улучшения:
Bidirectional Encoder
Forward LSTM
Backward LSTM
Слайд 16RNN Sequence-to-sequence model
Проблемы:
Размер стейта фиксирован
Изменения из начала последовательности затираются
Не все входные токены
RNN Sequence-to-sequence model
Проблемы:
Размер стейта фиксирован
Изменения из начала последовательности затираются
Не все входные токены

Слайд 17RNN Sequence-to-sequence model
Решение:
Внимание
RNN Sequence-to-sequence model
Решение:
Внимание

Слайд 18Механизм внимания, мотивация
Xu et al. 2015
Show, Attend and Tell:
Neural Image Caption
Механизм внимания, мотивация
Xu et al. 2015
Show, Attend and Tell:
Neural Image Caption

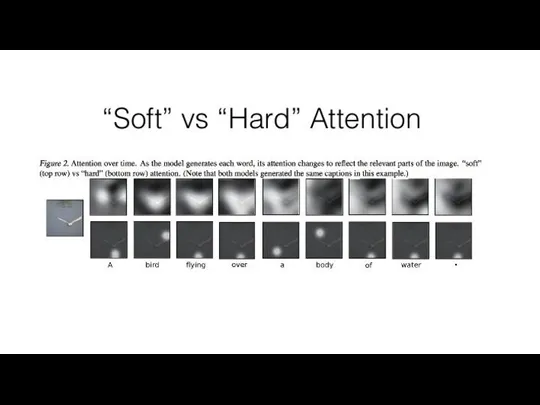
Слайд 20Soft vs Hard Attention
Hard
Выбор одной/n областей
Получаем сэмплингом из softmax
Не дифференцируем
Нужно учить с
Soft vs Hard Attention
Hard
Выбор одной/n областей
Получаем сэмплингом из softmax
Не дифференцируем
Нужно учить с

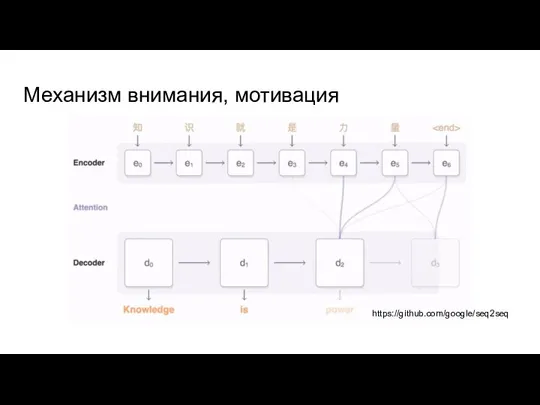
Слайд 21Механизм внимания, мотивация
В случае машинного перевода
Механизм внимания, мотивация
В случае машинного перевода

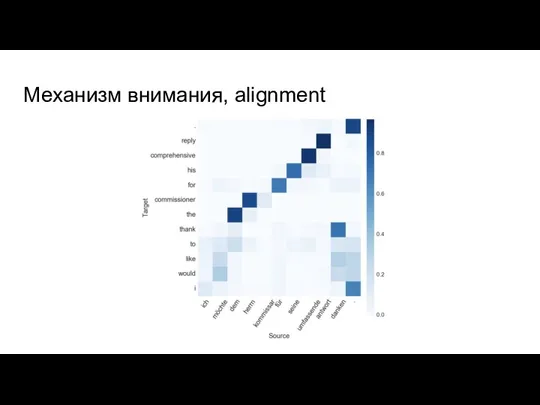
Слайд 22Механизм внимания, alignment
Механизм внимания, alignment
Слайд 23Механизм внимания, мотивация
https://github.com/google/seq2seq
Механизм внимания, мотивация
https://github.com/google/seq2seq
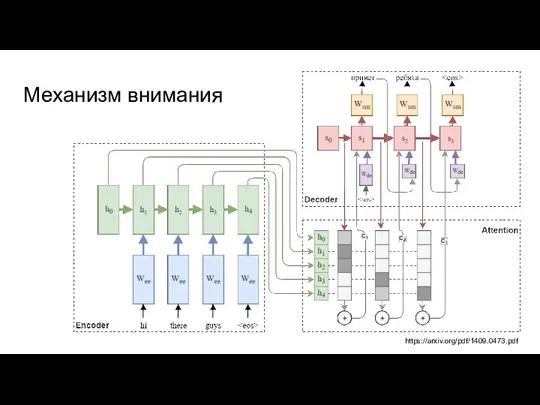
Слайд 24Механизм внимания
https://arxiv.org/pdf/1409.0473.pdf
Механизм внимания
https://arxiv.org/pdf/1409.0473.pdf
Слайд 25Механизм внимания
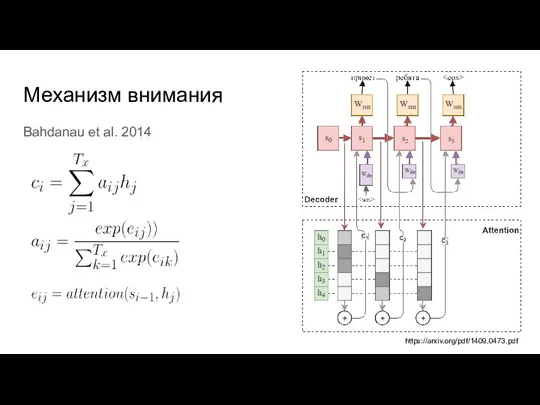
Bahdanau et al. 2014
https://arxiv.org/pdf/1409.0473.pdf
Механизм внимания
Bahdanau et al. 2014
https://arxiv.org/pdf/1409.0473.pdf
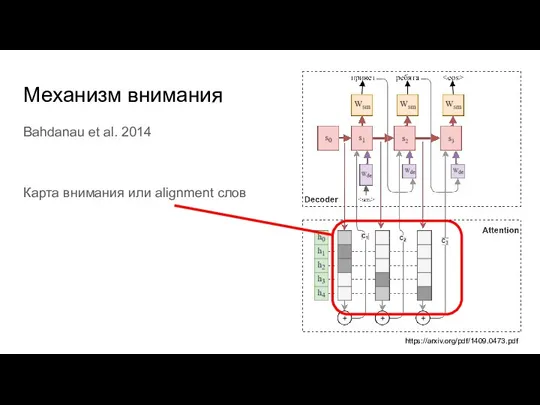
Слайд 26Механизм внимания
Bahdanau et al. 2014
Карта внимания или alignment слов
https://arxiv.org/pdf/1409.0473.pdf
Механизм внимания
Bahdanau et al. 2014
Карта внимания или alignment слов
https://arxiv.org/pdf/1409.0473.pdf
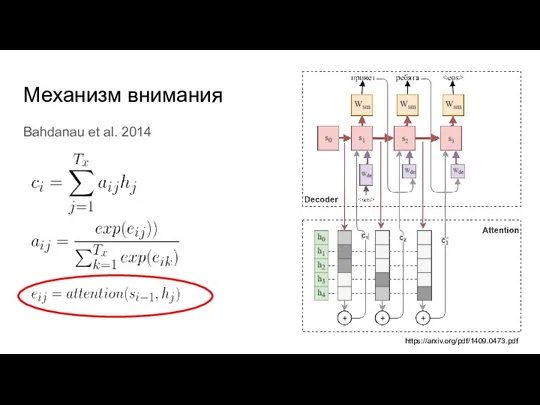
Слайд 27Механизм внимания
Bahdanau et al. 2014
https://arxiv.org/pdf/1409.0473.pdf
Механизм внимания
Bahdanau et al. 2014
https://arxiv.org/pdf/1409.0473.pdf
Слайд 28Attention function
Dot Product
General
Additive
Attention function
Dot Product
General
Additive

Слайд 29Практические нюансы
Wordpiece models and character-based models
Pretrained embeddings
Multihead Attention
Teacher Forcing
Beam Search
Практические нюансы
Wordpiece models and character-based models
Pretrained embeddings
Multihead Attention
Teacher Forcing
Beam Search

Слайд 30Проблемы словаря
большой размер эмбеддингов и софтмакс слоя (сотни тысяч)
неизвестные слова при инференсе,
Проблемы словаря
большой размер эмбеддингов и софтмакс слоя (сотни тысяч)
неизвестные слова при инференсе,

Слайд 31Pretrained embeddings
Pretrained embeddings

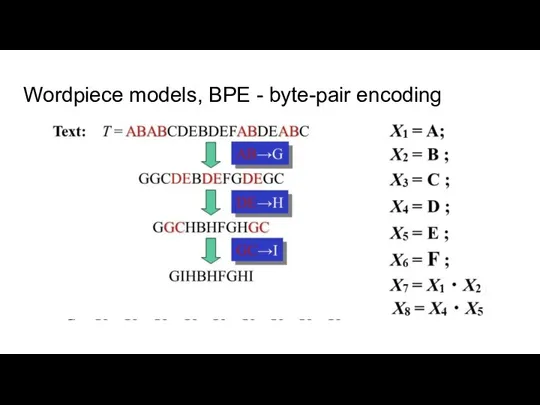
Слайд 32Wordpiece models, BPE - byte-pair encoding
Wordpiece models, BPE - byte-pair encoding
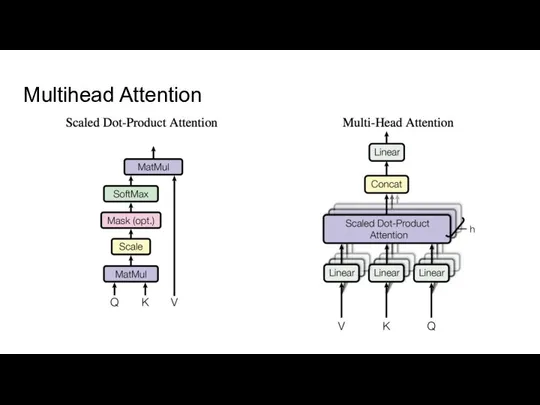
Слайд 33Multihead Attention
Multihead Attention
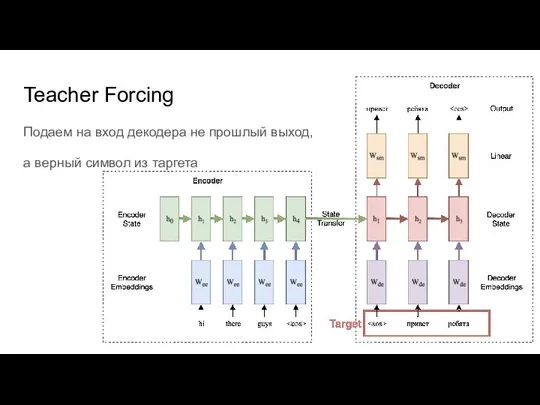
Слайд 34Teacher Forcing
Подаем на вход декодера не прошлый выход,
а верный символ из таргета
Teacher Forcing
Подаем на вход декодера не прошлый выход,
а верный символ из таргета
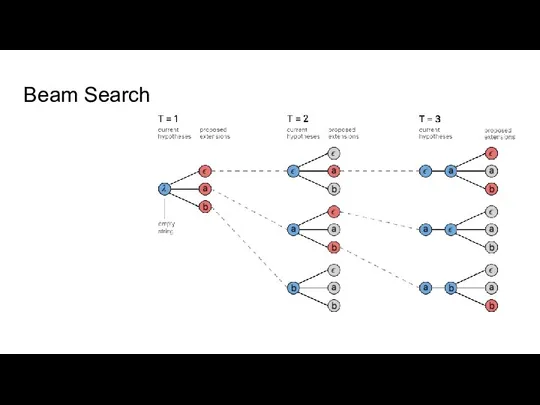
Слайд 35Beam Search
Beam Search
Слайд 36Beyond attention
Attention позволяет построить текущее состояние с учетом всего прошлого последовательности.
Одинаково
Beyond attention
Attention позволяет построить текущее состояние с учетом всего прошлого последовательности.
Одинаково

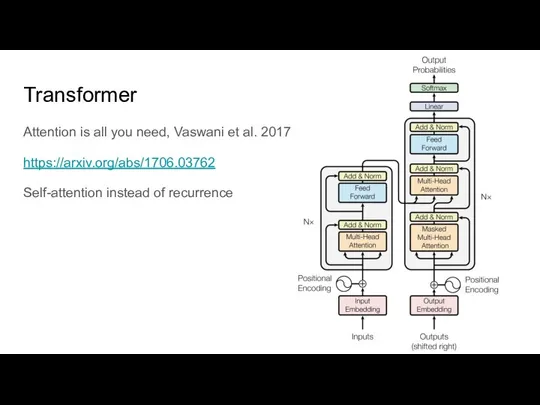
Слайд 37Transformer
Attention is all you need, Vaswani et al. 2017
https://arxiv.org/abs/1706.03762
Self-attention instead of recurrence
Transformer
Attention is all you need, Vaswani et al. 2017
https://arxiv.org/abs/1706.03762
Self-attention instead of recurrence
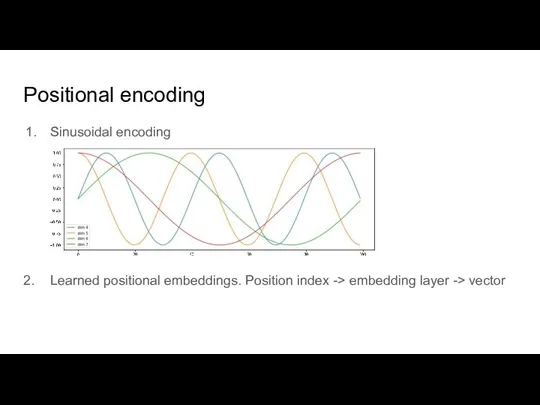
Слайд 38Positional encoding
Sinusoidal encoding
2. Learned positional embeddings. Position index -> embedding layer -> vector
Positional encoding
Sinusoidal encoding
2. Learned positional embeddings. Position index -> embedding layer -> vector
 Информационно-аналитическая деятельность как объект технологической поддержки
Информационно-аналитическая деятельность как объект технологической поддержки Компоновка
Компоновка Objektorientierte Programmierung. Bedingungen und Entscheidungen
Objektorientierte Programmierung. Bedingungen und Entscheidungen Мир науки на книжных страницах. Виртуальная выставка
Мир науки на книжных страницах. Виртуальная выставка Курсы по Blender в skullbox
Курсы по Blender в skullbox Базы данных
Базы данных Пиксель арт
Пиксель арт Информация и её свойства. 7 класс
Информация и её свойства. 7 класс Понятие физической среды передачи данных, типы линий связи
Понятие физической среды передачи данных, типы линий связи Правила общения в интернете
Правила общения в интернете Словарные методы кодирования
Словарные методы кодирования Использование графики SmartArt в работе учителя физической культуры
Использование графики SmartArt в работе учителя физической культуры Кодирование звуковой информации. Звуковой сигнал
Кодирование звуковой информации. Звуковой сигнал Развитие понятия о числах. Системы счисления
Развитие понятия о числах. Системы счисления Определи вид данного суждения. 6 класс
Определи вид данного суждения. 6 класс Поместите здесь ваш текст. Шаблон
Поместите здесь ваш текст. Шаблон (1 пара)Тема 2.3. RadioButton
(1 пара)Тема 2.3. RadioButton Windows XP 2020
Windows XP 2020 Динамические структуры данных (язык Си)
Динамические структуры данных (язык Си) Представление целых чисел в компьютере. 8 класс
Представление целых чисел в компьютере. 8 класс Презентация на тему Логические основы компьютера
Презентация на тему Логические основы компьютера 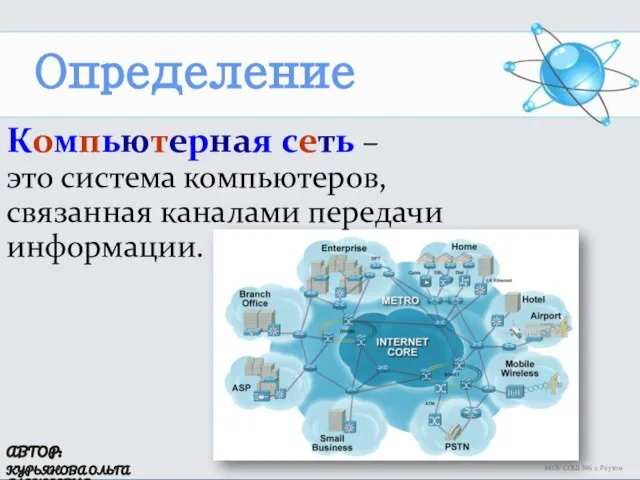 Компьютерная сеть
Компьютерная сеть Инструменты Corel
Инструменты Corel TEO-STROY Система для управления строительной фирмой/студией ремонта
TEO-STROY Система для управления строительной фирмой/студией ремонта Компьютерные презентации
Компьютерные презентации Основи програмування
Основи програмування Презентация отдела E-commerce
Презентация отдела E-commerce Создание памятного знака 75 лет Победы
Создание памятного знака 75 лет Победы