1 МЕТРОЛОГИЧЕСКИЕ ОЦЕНКИ НЕОПРЕДЕЛЕННОСТИ В КАЧЕСТВЕННОМ АНАЛИЗЕ В.И.Вершинин Россия, Омск, Омский государственный ун
- 1 МЕТРОЛОГИЧЕСКИЕ ОЦЕНКИ НЕОПРЕДЕЛЕННОСТИ В КАЧЕСТВЕННОМ АНАЛИЗЕ В.И.Вершинин Россия, Омск, Омский государственный ун

Содержание
- 2. Предпосылки повышенного внимания к метрологии качественного анализа на рубеже ХХ-XXI веков 1) Резкий рост числа объектов
- 3. Методы анализа, в которых применяют системы компьютерной идентификации (СКИ) Газовая хроматография Анализ бензинов, растворителей, пищевых продуктов
- 4. Пример выдачи на печать результатов работы системы компьютерной идентификации (СКИ) при хроматографическом анализе бензина по ASTM
- 5. Некоторые отечественные публикации в области метрологии качественного анализа 1955 - Комарь Н.П. Основы качественного химического анализа.
- 6. Некоторые зарубежные публикации в области метрологии качественного анализа 1973 - McLafferty F.W. Interpretation of mass-spectra. Reading
- 7. Рабочая группа Eurachem / CITAC по метрологии качественного анализа Ellison S. (Великобритания) – председатель Salit M.
- 8. Предпосылки повышенного внимания к метрологии качественного анализа на рубеже ХХ-XXI веков 4) Возникновение в метрологии концепции
- 9. Максимально допустимые уровни составляющих неопределенности для методик разного типа 9 Снижения α и β до нужной
- 10. Возможные подходы к метрологической оценке неопределенности в качественном анализе 1. Статистические оценки Используют N образцов известного
- 11. Реализация статистического подхода Считают, что FPR и FNR – случайные величины, имеющие биномиальное распределение. Тогда объем
- 12. 12 Связь неопределенности идентификации с концентрацией аналита М 1 - вероятность необнаружения М (β ), 2
- 13. Преимущества и ограничения статистических оценок неопределенности в качественном анализе Алгоритмы статистической оценки неопределенности: универсальны, объективны, просты;
- 14. Возможные подходы к метрологической оценке неопределенности в качественном анализе 2. Априорные оценки Исследуют характер распределения экспериментальных
- 15. Модель для априорной оценки неопределенности в качественном хроматографическом анализе Концентрации всех компонентов пробы (Х) выше, чем
- 16. Алгоритм расчета составляющих неопределенности в рамках данной модели Если случайный сдвиг пика X из «окна» (tx
- 17. Оптимизация критерия d при опознании веществ с разной селективностью характеристик удерживания 1 - β, 2,3,4 -
- 18. Число веществ, соответствующих единичному пику на хроматограмме, при разных режимах работы СКИ ( оптимизация критерия совпадения
- 19. Априорная оценка неопределенности идентификации индивидуальных углеводородов при хроматографическом анализе бензина с помощью СКИ α - вероятность
- 20. Алгоритм обратного поиска при работе систем компьютерной идентификации (СКИ) Ввод данных ( спектра или хроматограммы пробы
- 21. Дополнительные операции, возможные для СКИ, в которых используются алгоритмы априорной оценки неопределенности 1. Автоматическое вычисление значений
- 22. Оценка неопределенности для методик анализа, включающих n единичных испытаний (в разных условиях) Предполагается, что единичные вероятности
- 23. Оценка αn для методов, основанных на подсчете количества спектральных совпадений пробы и эталона Модель предполагает равную
- 24. Расчет критерия идентификации в спектральном анализе где tкр находят из условия Г(t) = 1-αn, где Г
- 25. Результаты компьютерного качественного анализа бинарной смеси ПАУ Расшифровка спектра низкотемпературной люминесценции пробы. N - число линий
- 26. Идентификация индивидуальных ПАУ в 12-компонентной модельной смеси в условиях спектрального фракционирования 26
- 27. Некоторые нерешенные проблемы метрологии качественного анализа В рамках статистического подхода: унификация терминологии и вычислительных алгоритмов, разработка
- 29. Скачать презентацию
Слайд 2Предпосылки повышенного внимания
к метрологии качественного анализа на рубеже ХХ-XXI веков
1) Резкий
Предпосылки повышенного внимания
к метрологии качественного анализа на рубеже ХХ-XXI веков
1) Резкий

Слайд 3
Методы анализа, в которых применяют системы компьютерной идентификации (СКИ)
Газовая хроматография Анализ
Методы анализа, в которых применяют системы компьютерной идентификации (СКИ)
Газовая хроматография Анализ

Слайд 4
Пример выдачи на печать результатов работы
системы компьютерной идентификации (СКИ)
при хроматографическом
Пример выдачи на печать результатов работы системы компьютерной идентификации (СКИ) при хроматографическом
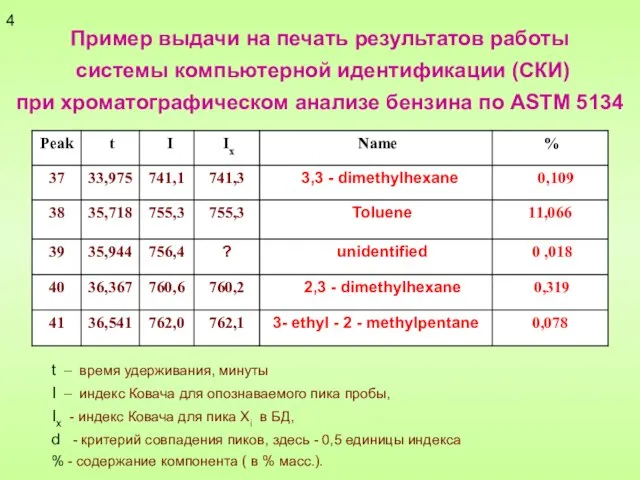
Слайд 5 Некоторые отечественные публикации
в области метрологии качественного анализа
1955 - Комарь Н.П.
Некоторые отечественные публикации
в области метрологии качественного анализа
1955 - Комарь Н.П.

Слайд 6Некоторые зарубежные публикации
в области метрологии качественного анализа
1973 - McLafferty F.W. Interpretation
Некоторые зарубежные публикации
в области метрологии качественного анализа
1973 - McLafferty F.W. Interpretation

Слайд 7Рабочая группа Eurachem / CITAC
по метрологии качественного анализа
Ellison S. (Великобритания) – председатель
Salit
Рабочая группа Eurachem / CITAC
по метрологии качественного анализа
Ellison S. (Великобритания) – председатель
Salit

Слайд 8Предпосылки повышенного внимания
к метрологии качественного анализа на рубеже ХХ-XXI веков
4)
Предпосылки повышенного внимания
к метрологии качественного анализа на рубеже ХХ-XXI веков
4)

Слайд 9Максимально допустимые уровни составляющих неопределенности для методик разного типа
9
Снижения α и β
Максимально допустимые уровни составляющих неопределенности для методик разного типа
9
Снижения α и β
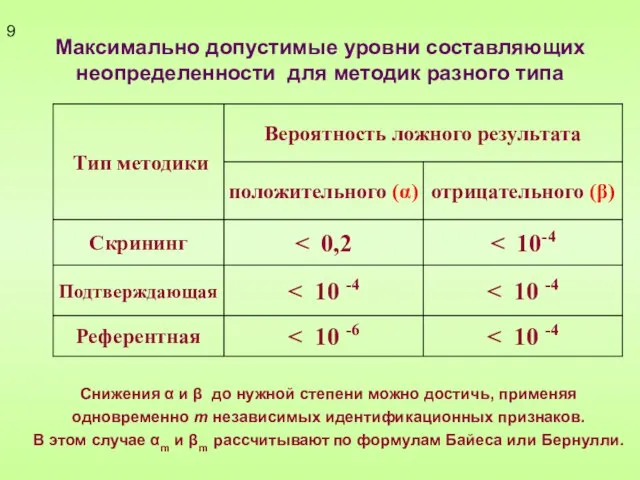
Слайд 10Возможные подходы к метрологической оценке неопределенности в качественном анализе
1. Статистические оценки
Используют
Возможные подходы к метрологической оценке неопределенности в качественном анализе
1. Статистические оценки
Используют

Слайд 11Реализация статистического подхода
Считают, что FPR и FNR – случайные величины, имеющие биномиальное
Реализация статистического подхода
Считают, что FPR и FNR – случайные величины, имеющие биномиальное
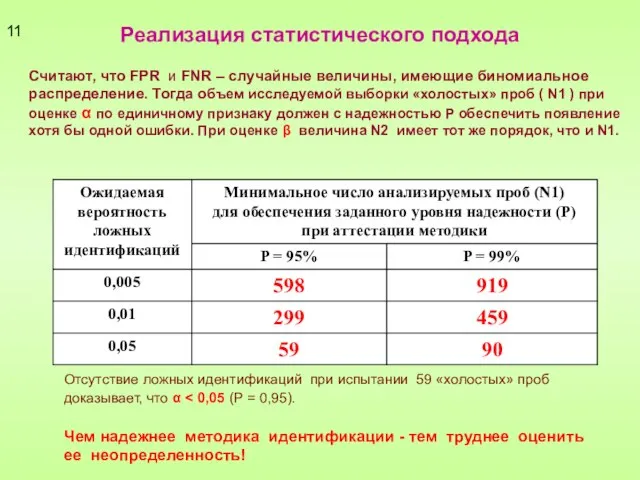
Слайд 1212
Связь неопределенности идентификации с концентрацией аналита М
1 - вероятность необнаружения М (β
12
Связь неопределенности идентификации с концентрацией аналита М
1 - вероятность необнаружения М (β
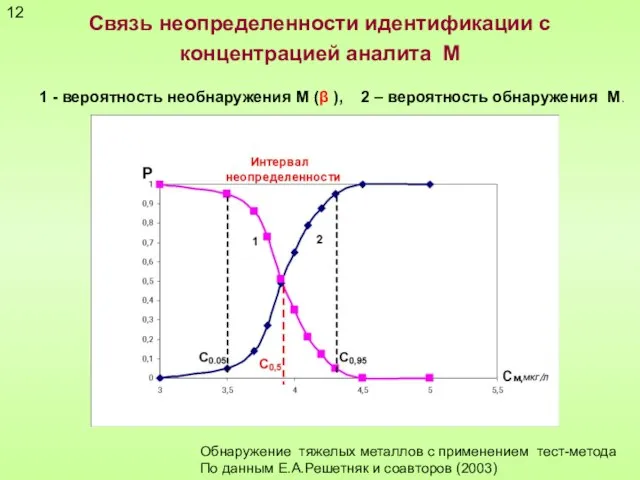
Слайд 13Преимущества и ограничения статистических оценок неопределенности в качественном анализе
Алгоритмы статистической оценки
Преимущества и ограничения статистических оценок неопределенности в качественном анализе
Алгоритмы статистической оценки

Слайд 14Возможные подходы к метрологической оценке неопределенности в качественном анализе
2. Априорные оценки
Возможные подходы к метрологической оценке неопределенности в качественном анализе
2. Априорные оценки

Слайд 15Модель для априорной оценки неопределенности в качественном хроматографическом анализе
Концентрации всех компонентов
Модель для априорной оценки неопределенности в качественном хроматографическом анализе
Концентрации всех компонентов

Слайд 16
Алгоритм расчета составляющих
неопределенности в рамках данной модели
Если случайный сдвиг пика
Алгоритм расчета составляющих
неопределенности в рамках данной модели
Если случайный сдвиг пика

Слайд 17 Оптимизация критерия d при опознании веществ
с разной селективностью характеристик
Оптимизация критерия d при опознании веществ
с разной селективностью характеристик
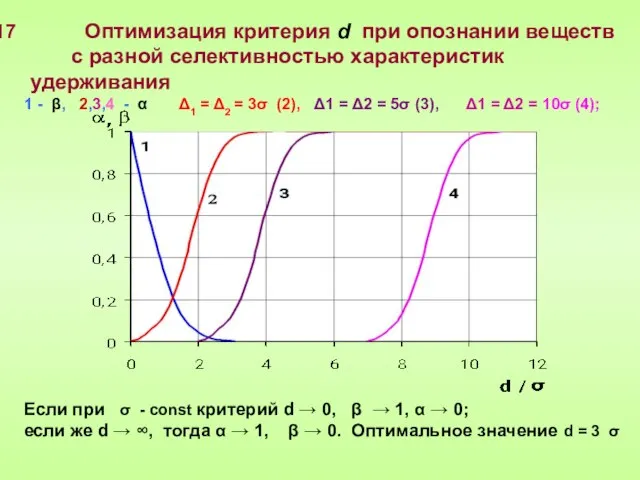
Слайд 18
Число веществ, соответствующих единичному пику
на хроматограмме, при разных
Число веществ, соответствующих единичному пику
на хроматограмме, при разных
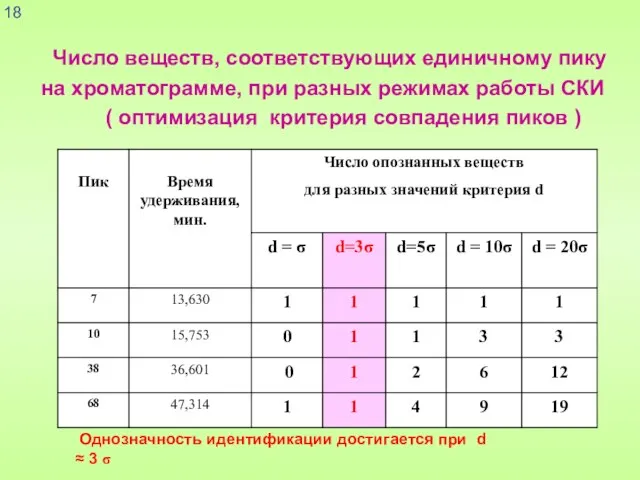
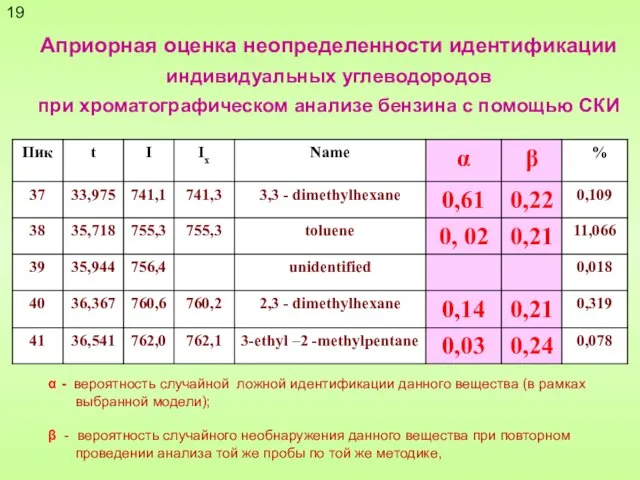
Слайд 19Априорная оценка неопределенности идентификации индивидуальных углеводородов
при хроматографическом анализе бензина с помощью
Априорная оценка неопределенности идентификации индивидуальных углеводородов при хроматографическом анализе бензина с помощью
Слайд 20
Алгоритм обратного поиска
при работе систем компьютерной идентификации (СКИ)
Ввод данных (
Алгоритм обратного поиска
при работе систем компьютерной идентификации (СКИ)
Ввод данных (

Слайд 21
Дополнительные операции,
возможные для СКИ, в которых используются алгоритмы априорной оценки
Дополнительные операции, возможные для СКИ, в которых используются алгоритмы априорной оценки

Слайд 22Оценка неопределенности для методик анализа,
включающих n единичных испытаний (в разных условиях)
Оценка неопределенности для методик анализа,
включающих n единичных испытаний (в разных условиях)

Слайд 23Оценка αn для методов, основанных на подсчете
количества спектральных совпадений пробы и
Оценка αn для методов, основанных на подсчете
количества спектральных совпадений пробы и

Слайд 24 Расчет критерия идентификации в спектральном анализе
где tкр находят из условия
Расчет критерия идентификации в спектральном анализе
где tкр находят из условия

Слайд 25 Результаты компьютерного качественного анализа бинарной смеси ПАУ
Расшифровка спектра низкотемпературной
Результаты компьютерного качественного анализа бинарной смеси ПАУ
Расшифровка спектра низкотемпературной
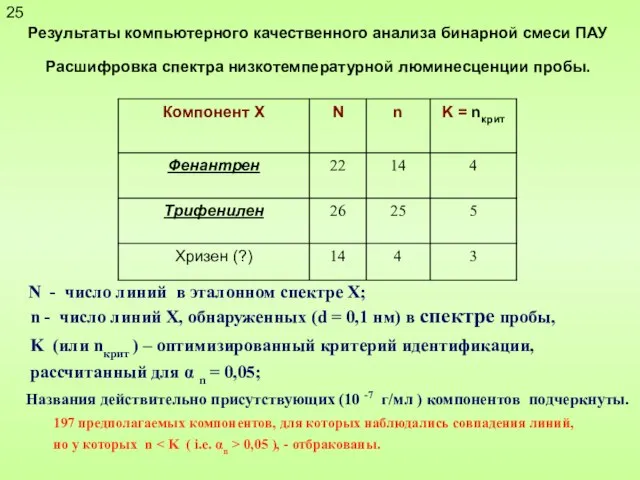
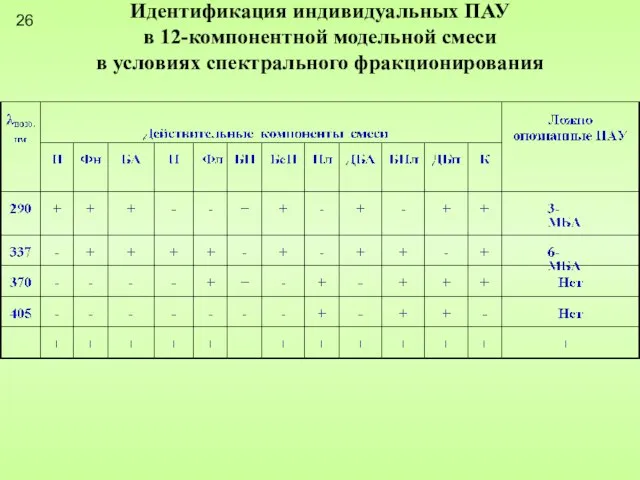
Слайд 26Идентификация индивидуальных ПАУ
в 12-компонентной модельной смеси
в условиях спектрального фракционирования
26
Идентификация индивидуальных ПАУ
в 12-компонентной модельной смеси
в условиях спектрального фракционирования
26
Слайд 27
Некоторые нерешенные проблемы
метрологии качественного анализа
В рамках статистического подхода:
унификация терминологии и
Некоторые нерешенные проблемы
метрологии качественного анализа
В рамках статистического подхода:
унификация терминологии и

 История создания романа «Тихий Дон»
История создания романа «Тихий Дон» Навчально-методичне забезпечення шкільного курсу інформатики у 2009/2010навчальному році
Навчально-методичне забезпечення шкільного курсу інформатики у 2009/2010навчальному році Молодёжка
Молодёжка Модуль числа (6 класс)
Модуль числа (6 класс) Алгоритм беседы по постановке задачи. Вебинар №7
Алгоритм беседы по постановке задачи. Вебинар №7 Организационная структура бизнес-проекта
Организационная структура бизнес-проекта Результаты анкетирования «Участие пап в воспитании детей» в рамках акции «ПАПИН АПРЕЛЬ»
Результаты анкетирования «Участие пап в воспитании детей» в рамках акции «ПАПИН АПРЕЛЬ» Система управления нормативно-технической документацией предприятия. Консорциум Кодекс
Система управления нормативно-технической документацией предприятия. Консорциум Кодекс Методические рекомендации в помощь педагогам и руководителям образовательных учреждений при написании и оформлении актуального
Методические рекомендации в помощь педагогам и руководителям образовательных учреждений при написании и оформлении актуального  Болезни почек
Болезни почек Аниме и моя жизнь
Аниме и моя жизнь Масленица
Масленица Россер Ривз (Rosser Reeves) придумал концепцию USP в 1961 году USP = Unique Selling Proposition (уникальное торговое предложение)
Россер Ривз (Rosser Reeves) придумал концепцию USP в 1961 году USP = Unique Selling Proposition (уникальное торговое предложение) Назови сказку
Назови сказку Изготовление избы
Изготовление избы Группа «Эффективные модели обновления систем повышения квалификации и аттестации педагогических работников»
Группа «Эффективные модели обновления систем повышения квалификации и аттестации педагогических работников» Компьютер и его составляющие
Компьютер и его составляющие Инструкция по созданию календаря Google. - презентация
Инструкция по созданию календаря Google. - презентация Менеджмент в здравоохранении
Менеджмент в здравоохранении Портфолио учителя как одна из форм прохождения аттестации
Портфолио учителя как одна из форм прохождения аттестации Не бойся! Ты не один!
Не бойся! Ты не один! Контрольная работа на тему: Судебно-бухгалтерская экспертиза
Контрольная работа на тему: Судебно-бухгалтерская экспертиза ПЕДСОВЕТ
ПЕДСОВЕТ Презентация на тему: Бородинская панорама
Презентация на тему: Бородинская панорама «История Развития Компьютера»
«История Развития Компьютера» Тема 6 ОТКАЗОУСТОЙЧИВОСТЬ
Тема 6 ОТКАЗОУСТОЙЧИВОСТЬ Математики шутят
Математики шутят Первая Маккавейская книга
Первая Маккавейская книга