- Балансировка загрузки процессоров Институт математического моделирования Российской академии наук

Содержание
- 2. Задачи большого вызова (Kenneth G. Wilson, Cornell University, 1987) Вычислительная газовая динамика: Создание летательных аппаратов, эффективных
- 3. Дозвуковая аэродинамическая труба Т-104, ЦАГИ Скорость потока 10–120 м/с Диаметр сопла 7 м Длина рабочей части
- 8. Суперкомпьютеры Не просто составляют конкуренцию натурному эксперименту, но: Необходимы для его проведения Позволяют делать то, что
- 9. Суперкомпьютеры Используются неэффективно и далеко не в полной мере Необходимы: Вычислительное ядро: адаптация алгоритмов к архитектуре
- 12. НЕВЯЗКОЕ ОБТЕКАНИЕ КУЗОВА АВТОМОБИЛЯ (М = 0.12) СЕТКА: 430 949 УЗЛОВ, 2 430 306 ТЕТРАЭДРОВ
- 13. Сетка: 209 028 730 узлов, 1 244 316 672 тетраэдра (24 Гб) МВС: МВС-100К 1. Запуск
- 14. Суперкомпьютеры МСЦ РАН: процессор: Intel(R) Xeon(R) CPU X5365 @ 3.00GHz ядер на узел: 8 память узла:
- 15. Институт Математического Моделирования РАН 125047, Mиусская пл. 4а, Москва Акустика Вычислительные эксперименты по ЗПК
- 16. Институт Математического Моделирования РАН 125047, Mиусская пл. 4а, Москва Звукопоглощающие конструкции Панель ЗПК Расчетная область Резонатор
- 17. Институт Математического Моделирования РАН 125047, Mиусская пл. 4а, Москва Эксперимент 1: Модель 2D и 3D импедансной
- 18. Институт Математического Моделирования РАН 125047, Mиусская пл. 4а, Москва 3D импедансная труба Течение в отверстии резонаторной
- 19. Институт Математического Моделирования РАН 125047, Mиусская пл. 4а, Москва Эффект свиста Слой смешения Возмущения плотности Эксперимент
- 20. Институт Математического Моделирования РАН 125047, Mиусская пл. 4а, Москва Базовая численная схема (1/2) Декартова сетка Неструктурированная
- 21. Институт Математического Моделирования РАН 125047, Mиусская пл. 4а, Москва Базовая численная схема Пространственный шаблон для определения
- 22. Институт Математического Моделирования РАН 125047, Mиусская пл. 4а, Москва Канал с 5 резонаторами Уравнения Эйлера, нет
- 23. Институт Математического Моделирования РАН 125047, Mиусская пл. 4а, Москва Heat and Mass Transfer Technological Center Colom
- 24. Статическая балансировка загрузки
- 25. Равномерное распределение суммарного веса узлов/рёбер Минимизация максимального веса исходящих из домена ребер Минимизация суммарного веса разрезанных
- 26. Чему равно 25/4 ? 6.25
- 27. 25/4= 6.25
- 28. 25/4= 4 6 9 6.25
- 29. 25/4 = 4 ? 6 ? 9 Разрезать решетку 5 х 5 на 4 части
- 30. Декомпозиция сетки из 25 узлов на 4 части
- 31. 25/4 = 4 ? 6 ? 9 Дисбаланс 9/4=2.25 Декомпозиция решетки 5 х 5 на 4
- 32. 25/4 = 4 ? 6 ? 9 Дисбаланс 13/12 : 8% Декомпозиция решетки 5 х 5
- 33. 25/4 = 4 ? 6 ? 9 Дисбаланс 7/6 : 17% Декомпозиция решетки 5 х 5
- 34. 25/4 = 4 ? 6 ? 9 Дисбаланс 9/4=2.25 Декомпозиция решетки 5 х 5 на 4
- 35. 25/4 = 4 ? 6 ? 9 Дисбаланс 9/4=2.25 Декомпозиция решетки 5 х 5 на 4
- 36. Дисбаланс 9/4=2.25 25/4 = 4 ? 6 ? 9 Декомпозиция решетки 5 х 5 на 4
- 37. Декомпозиция сетки 25х25 на 7 частей
- 38. Разбиение тетраэдральной сетки, содержащей 2∙108 узлов, на 125 процессорах вычисления производились на кластере СКИФ МГу (1250
- 39. Фрагмент треугольной сетки из 75790 вершин результат геометрической декомпозиции результат перераспределения малых блоков вершин
- 40. Иерархический алгоритм Огрубление Восстановление Декомпозиция
- 41. Огрубление графа
- 42. Локальное уточнение 1 3 5 4 2 6 7 1 3 5 4 2 6 7
- 43. Связность ядер доменов
- 44. Инкрементный алгоритм декомпозиции графа
- 45. Редуцирование доменов
- 46. Инкрементный алгоритм, Dm=8
- 47. Инкрементный алгоритм, Dm=25
- 48. Результат локального разбиения сетки из 75790 вершин на 50 доменов на 5 процессорах
- 49. Результат сбора плохих групп доменов и их повторного разбиения
- 50. Адаптивные сетки Обтекание профиля NACA0012 (M=0.85, Re=104) под нулевым углом атаки: Поле продольной скорости Фрагмент сетки
- 51. Равномерная сетка Слева – ??круглое?? пятно примеси
- 52. Адаптивная сетка Слева – круглое пятно примеси
- 53. Адаптивные декартовы сетки Вначале сетка состоит из одной прямоугольной ячейки Каждая ячейка может быть разделена на
- 54. На рисунках показаны результаты решения простейшей задачи переноса на равномерной (слева) и адаптивной (справа) сетках с
- 55. Адаптивная сетка
- 56. Решение двумерной задачи фильтрации нефтеводяной смеси в области с неоднородной проницаемостью В юго-западном углу находится скважина,
- 57. Решение двумерной задачи фильтрации нефтеводяной смеси в области с неоднородной проницаемостью В юго-западном углу находится скважина,
- 58. Динамическая балансировка загрузки Перераспределение вычислительных узлов между процессорами необходимо: При изменение конфигурации сетки При изменение вычислительной
- 59. Декомпозиция пакетом Metis
- 60. Нумерация с помощью кривой Гильберта Формируется простой рекурсивной процедурой Локальное изменение сетки приводит к локальному изменению
- 61. Диффузная балансировка Декомпозиция с помощью кривой Гильберта
- 63. Стратегии балансировки загрузки Wij - вычислительная нагрузка, ассоциированная с узлом сетки i на шаге j Wij
- 64. Моделирование задач горения на многопроцессорных системах
- 66. Здесь A оператор, ρ - плотность, y(i) – массовые доли i-х компонент, u, v - скорости,
- 67. Блок схема алгоритма
- 68. Распределение времени счета
- 69. Структура и возможности алгоритма
- 70. Сотояния обрабатывающего процесса занят - если установлен соответствующий флаг. Этот флаг устанавливается перед передачей обрабатывающему процессу
- 71. Управляющий процесс 1. если - есть необработанные точки (неважно локальные или внешние) и - обрабатывающий процесс
- 72. Управляющий процесс 2. если - нет локальных необработанных точек и - нет внешних точек и -
- 73. Управляющий процесс Иначе (если не 2) 3. если - все переданные точки получены обратно обработанными и
- 74. Управляющий процесс 4. получить очередное сообщение от любого процессора или от своего обрабатывающего процесса. 5. обработать
- 75. Окончание при выполнение всех условий: нет локальных необработанных точек нет внешних точек нет обрабатываемых точек всем
- 76. Кластеры и эффективность speedup
- 77. Схема взаимодействия процессов
- 79. Скачать презентацию
Слайд 2Задачи большого вызова
(Kenneth G. Wilson, Cornell University, 1987)
Вычислительная газовая динамика:
Создание летательных
Задачи большого вызова
(Kenneth G. Wilson, Cornell University, 1987)
Вычислительная газовая динамика:
Создание летательных

Слайд 3Дозвуковая аэродинамическая труба Т-104, ЦАГИ
Скорость потока 10–120 м/с
Диаметр сопла 7 м
Длина рабочей
Дозвуковая аэродинамическая труба Т-104, ЦАГИ
Скорость потока 10–120 м/с
Диаметр сопла 7 м
Длина рабочей





Слайд 8Суперкомпьютеры
Не просто составляют конкуренцию натурному эксперименту, но:
Необходимы для его проведения
Позволяют делать то,
Суперкомпьютеры
Не просто составляют конкуренцию натурному эксперименту, но:
Необходимы для его проведения
Позволяют делать то,

Слайд 9Суперкомпьютеры
Используются неэффективно и далеко не в полной мере
Необходимы:
Вычислительное ядро: адаптация алгоритмов
к архитектуре
Суперкомпьютеры
Используются неэффективно и далеко не в полной мере
Необходимы:
Вычислительное ядро: адаптация алгоритмов
к архитектуре

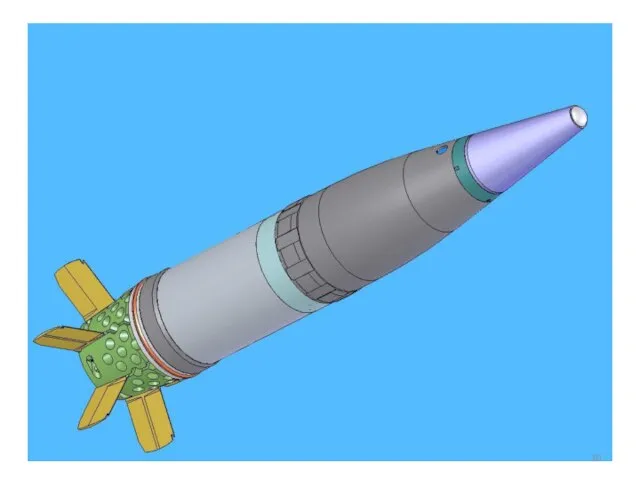
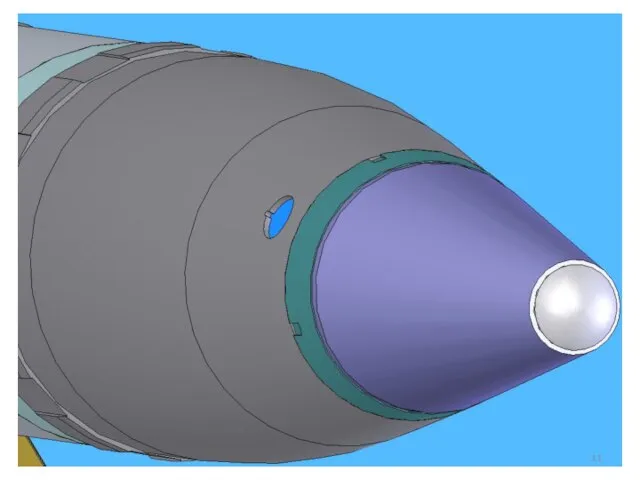
Слайд 12НЕВЯЗКОЕ ОБТЕКАНИЕ КУЗОВА АВТОМОБИЛЯ
(М = 0.12)
СЕТКА: 430 949 УЗЛОВ, 2 430 306
НЕВЯЗКОЕ ОБТЕКАНИЕ КУЗОВА АВТОМОБИЛЯ
(М = 0.12)
СЕТКА: 430 949 УЗЛОВ, 2 430 306

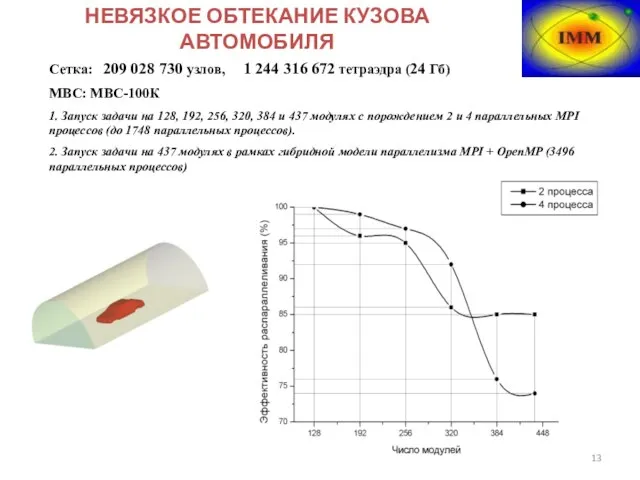
Слайд 13Сетка: 209 028 730 узлов, 1 244 316 672 тетраэдра (24 Гб)
МВС:
Сетка: 209 028 730 узлов, 1 244 316 672 тетраэдра (24 Гб)
МВС:
Слайд 14Суперкомпьютеры
МСЦ РАН: процессор: Intel(R) Xeon(R) CPU X5365 @ 3.00GHz
ядер на узел:
Суперкомпьютеры
МСЦ РАН: процессор: Intel(R) Xeon(R) CPU X5365 @ 3.00GHz
ядер на узел:

Слайд 15Институт Математического Моделирования РАН 125047, Mиусская пл. 4а, Москва
Акустика
Вычислительные эксперименты по ЗПК
Институт Математического Моделирования РАН 125047, Mиусская пл. 4а, Москва
Акустика
Вычислительные эксперименты по ЗПК

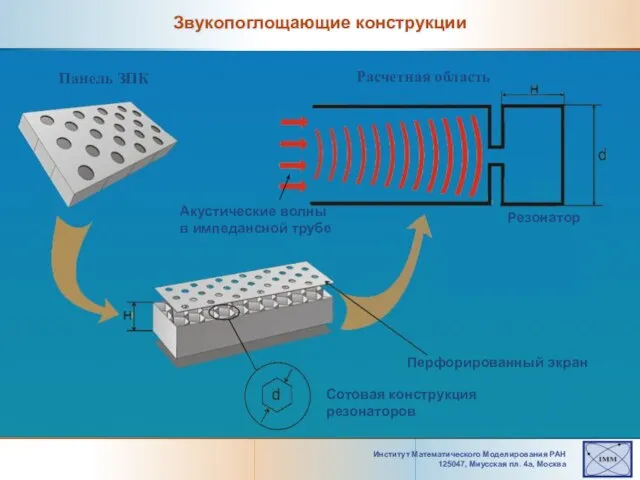
Слайд 16Институт Математического Моделирования РАН 125047, Mиусская пл. 4а, Москва
Звукопоглощающие конструкции
Панель ЗПК
Расчетная область
Резонатор
Акустические
Институт Математического Моделирования РАН 125047, Mиусская пл. 4а, Москва
Звукопоглощающие конструкции
Панель ЗПК
Расчетная область
Резонатор
Акустические
Слайд 17Институт Математического Моделирования РАН 125047, Mиусская пл. 4а, Москва
Эксперимент 1: Модель
Институт Математического Моделирования РАН 125047, Mиусская пл. 4а, Москва
Эксперимент 1: Модель
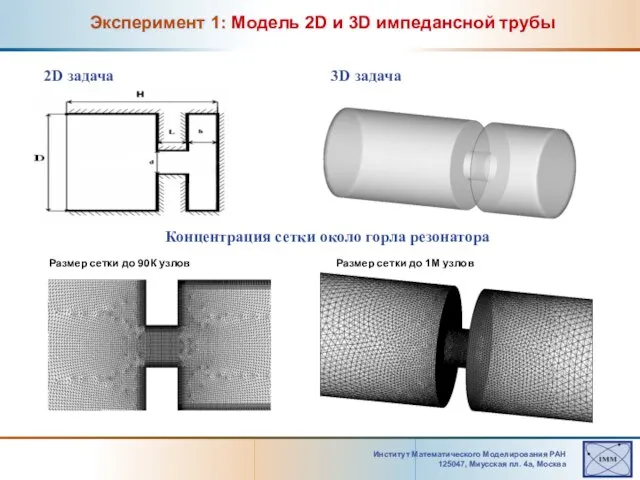
Слайд 18Институт Математического Моделирования РАН 125047, Mиусская пл. 4а, Москва
3D импедансная труба
Институт Математического Моделирования РАН 125047, Mиусская пл. 4а, Москва
3D импедансная труба
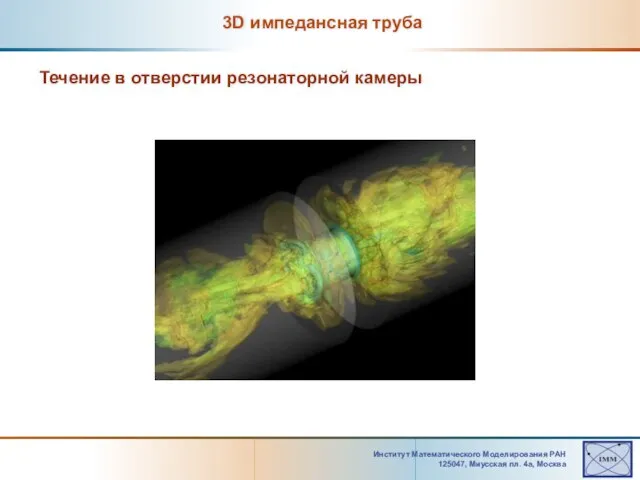
Слайд 19Институт Математического Моделирования РАН 125047, Mиусская пл. 4а, Москва
Эффект свиста
Слой смешения
Возмущения
Институт Математического Моделирования РАН 125047, Mиусская пл. 4а, Москва
Эффект свиста
Слой смешения
Возмущения

Слайд 20Институт Математического Моделирования РАН 125047, Mиусская пл. 4а, Москва
Базовая численная схема (1/2)
Институт Математического Моделирования РАН 125047, Mиусская пл. 4а, Москва
Базовая численная схема (1/2)
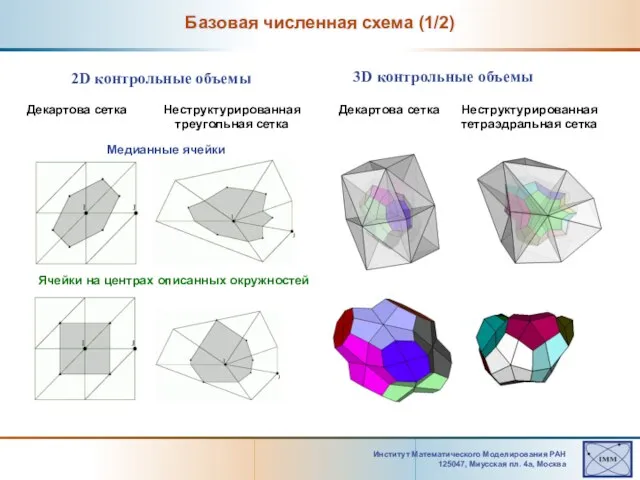
Слайд 21Институт Математического Моделирования РАН 125047, Mиусская пл. 4а, Москва
Базовая численная схема
Пространственный шаблон
Институт Математического Моделирования РАН 125047, Mиусская пл. 4а, Москва
Базовая численная схема
Пространственный шаблон
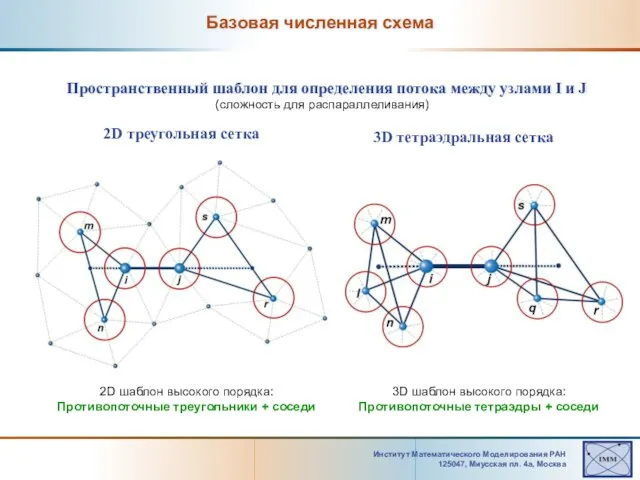
Слайд 22Институт Математического Моделирования РАН 125047, Mиусская пл. 4а, Москва
Канал с 5 резонаторами
Институт Математического Моделирования РАН 125047, Mиусская пл. 4а, Москва
Канал с 5 резонаторами

Слайд 23Институт Математического Моделирования РАН 125047, Mиусская пл. 4а, Москва
Heat and Mass Transfer
Институт Математического Моделирования РАН 125047, Mиусская пл. 4а, Москва
Heat and Mass Transfer
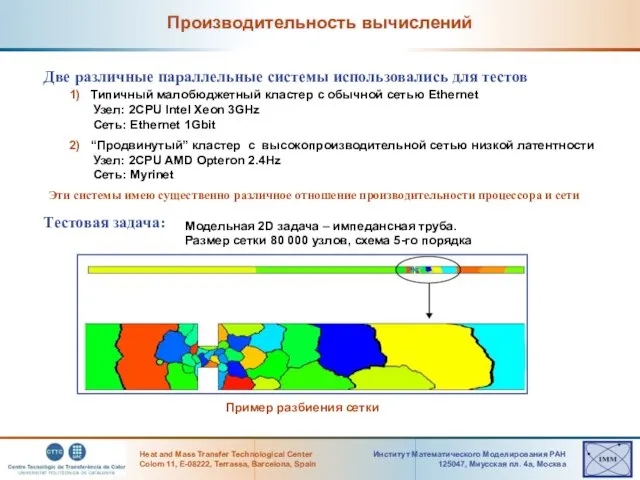
Слайд 24Статическая балансировка загрузки
Статическая балансировка загрузки

Слайд 25Равномерное
распределение суммарного веса узлов/рёбер
Минимизация
максимального веса исходящих из домена ребер
Минимизация суммарного
Равномерное
распределение суммарного веса узлов/рёбер
Минимизация
максимального веса исходящих из домена ребер
Минимизация суммарного

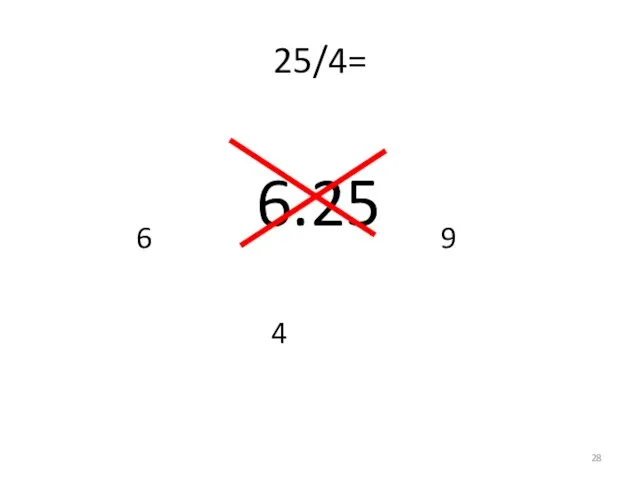
Слайд 26Чему равно 25/4 ?
6.25
Чему равно 25/4 ?
6.25

Слайд 2725/4=
6.25
25/4=
6.25

Слайд 2825/4=
4
6
9
6.25
25/4=
4
6
9
6.25
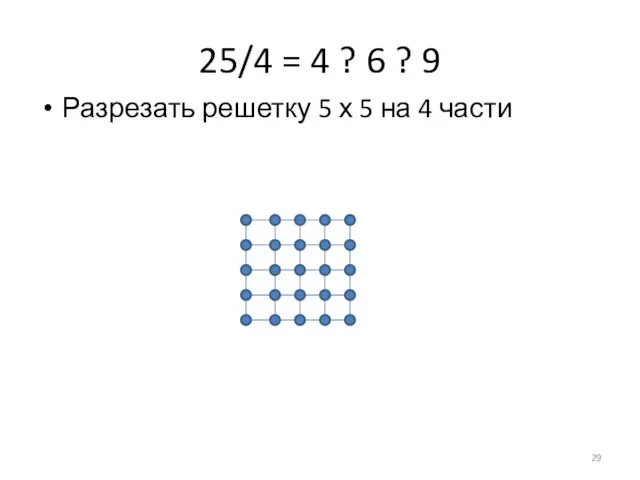
Слайд 2925/4 = 4 ? 6 ? 9
Разрезать решетку 5 х 5 на
25/4 = 4 ? 6 ? 9
Разрезать решетку 5 х 5 на
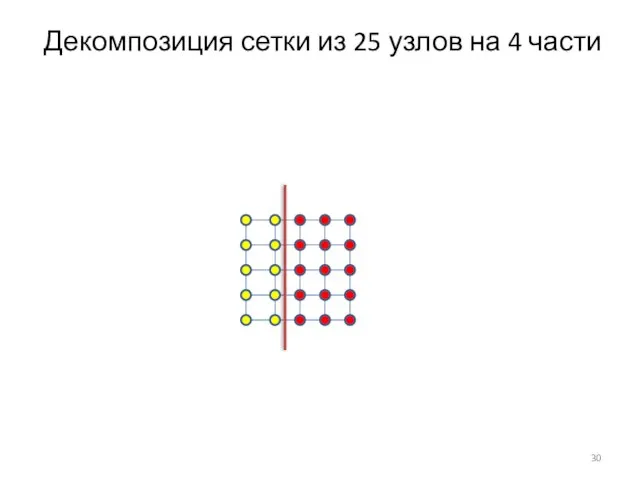
Слайд 30Декомпозиция сетки из 25 узлов на 4 части
Декомпозиция сетки из 25 узлов на 4 части
Слайд 3125/4 = 4 ? 6 ? 9
Дисбаланс 9/4=2.25
Декомпозиция решетки 5 х 5
25/4 = 4 ? 6 ? 9
Дисбаланс 9/4=2.25
Декомпозиция решетки 5 х 5
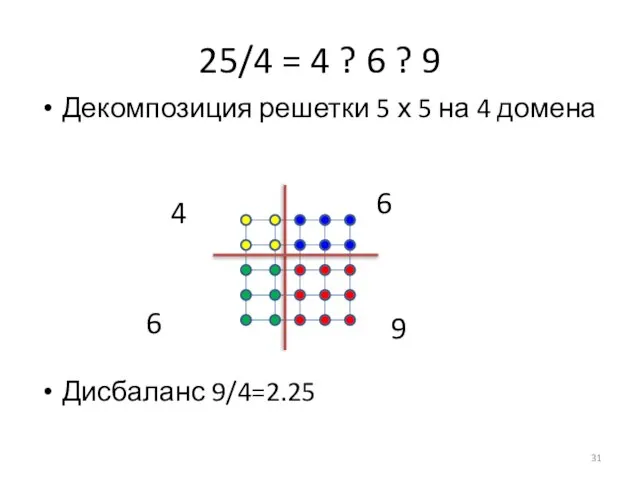
Слайд 3225/4 = 4 ? 6 ? 9
Дисбаланс 13/12 : 8%
Декомпозиция решетки 5
25/4 = 4 ? 6 ? 9
Дисбаланс 13/12 : 8%
Декомпозиция решетки 5
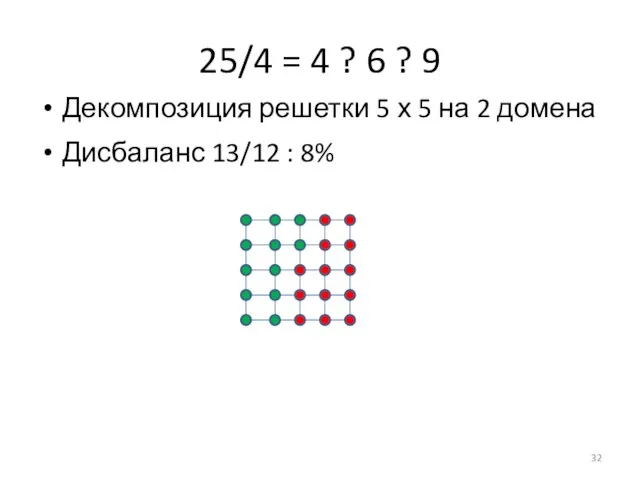
Слайд 3325/4 = 4 ? 6 ? 9
Дисбаланс 7/6 : 17%
Декомпозиция решетки 5
25/4 = 4 ? 6 ? 9
Дисбаланс 7/6 : 17%
Декомпозиция решетки 5
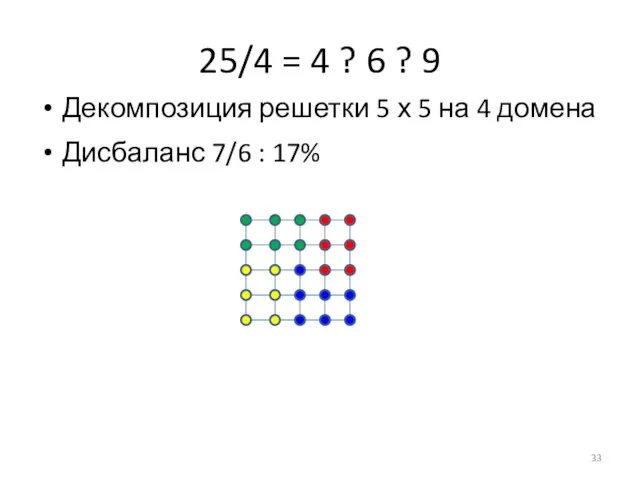
Слайд 3425/4 = 4 ? 6 ? 9
Дисбаланс 9/4=2.25
Декомпозиция решетки 5 х 5
25/4 = 4 ? 6 ? 9
Дисбаланс 9/4=2.25
Декомпозиция решетки 5 х 5
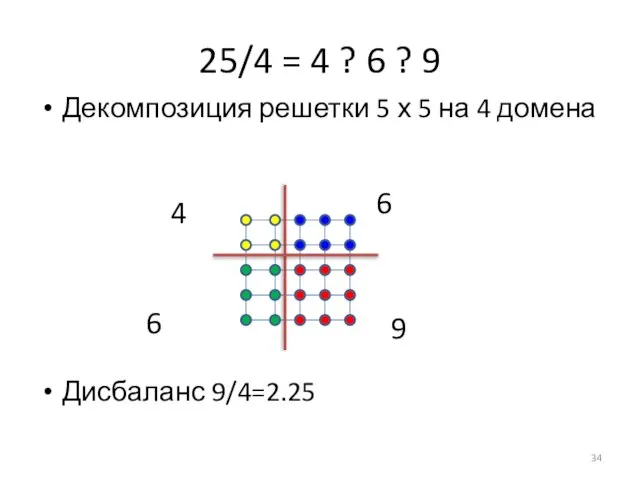
Слайд 3525/4 = 4 ? 6 ? 9
Дисбаланс 9/4=2.25
Декомпозиция решетки 5 х 5
25/4 = 4 ? 6 ? 9
Дисбаланс 9/4=2.25
Декомпозиция решетки 5 х 5
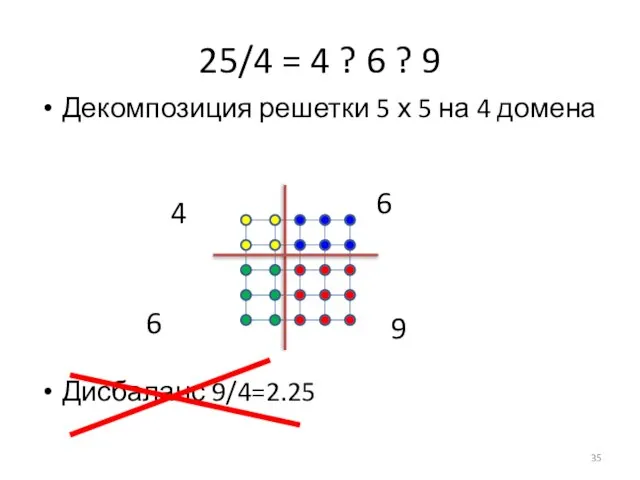
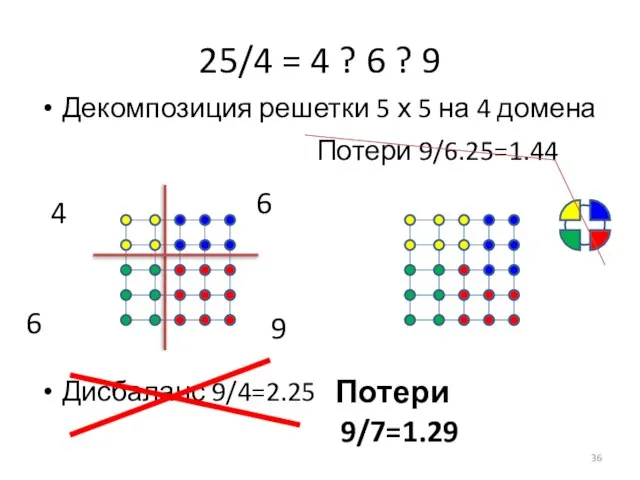
Слайд 36
Дисбаланс 9/4=2.25
25/4 = 4 ? 6 ? 9
Декомпозиция решетки 5 х 5
Дисбаланс 9/4=2.25
25/4 = 4 ? 6 ? 9
Декомпозиция решетки 5 х 5
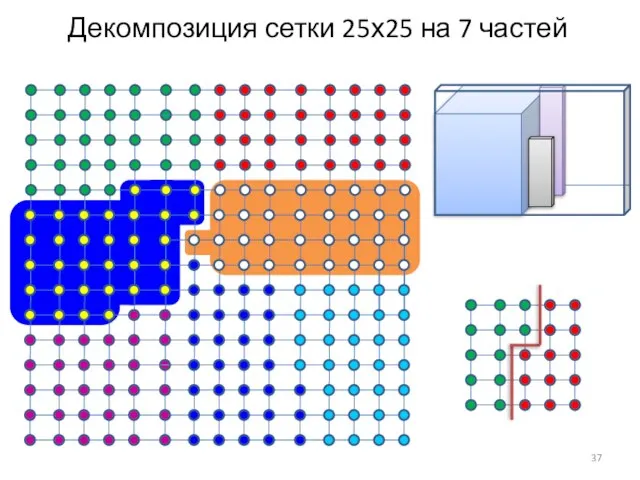
Слайд 37Декомпозиция сетки 25х25 на 7 частей
Декомпозиция сетки 25х25 на 7 частей
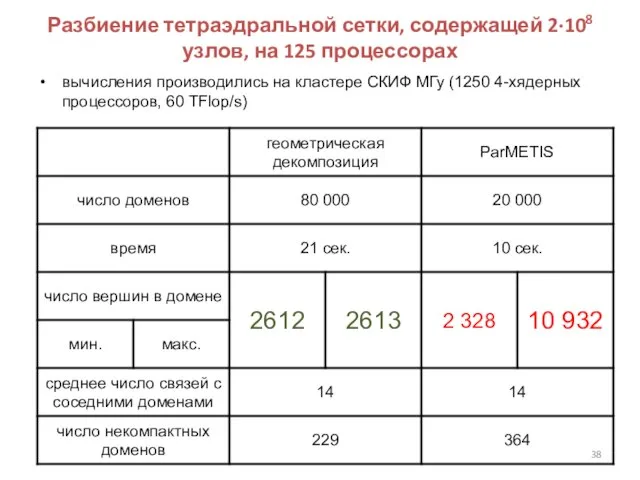
Слайд 38Разбиение тетраэдральной сетки, содержащей 2∙108 узлов, на 125 процессорах
вычисления производились на кластере
Разбиение тетраэдральной сетки, содержащей 2∙108 узлов, на 125 процессорах
вычисления производились на кластере
Слайд 39Фрагмент треугольной сетки из 75790 вершин
результат геометрической декомпозиции
результат перераспределения малых блоков вершин
Фрагмент треугольной сетки из 75790 вершин
результат геометрической декомпозиции
результат перераспределения малых блоков вершин

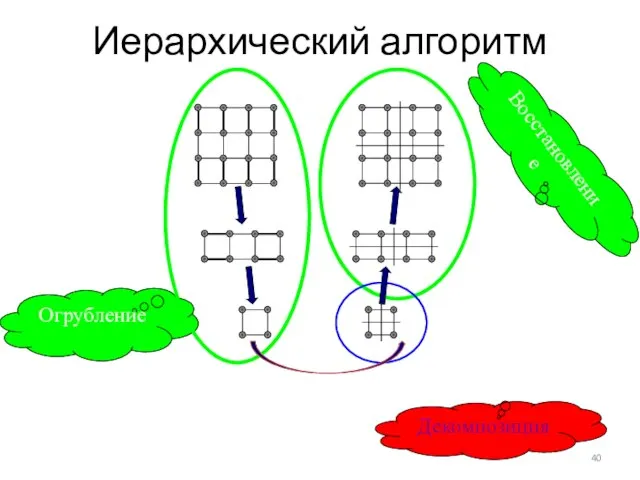
Слайд 40Иерархический алгоритм
Огрубление
Восстановление
Декомпозиция
Иерархический алгоритм
Огрубление
Восстановление
Декомпозиция
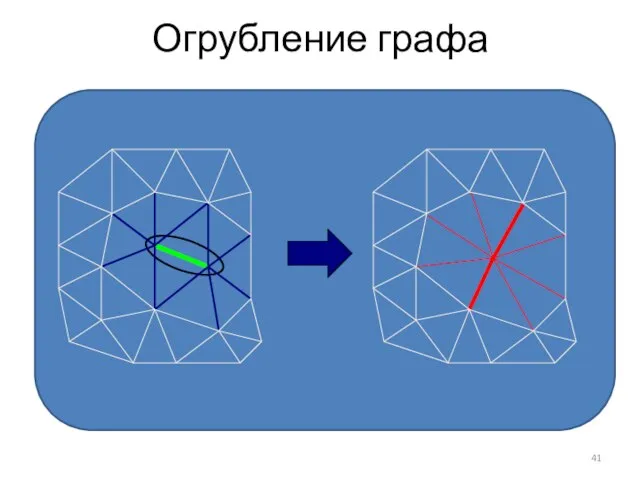
Слайд 41Огрубление графа
Огрубление графа
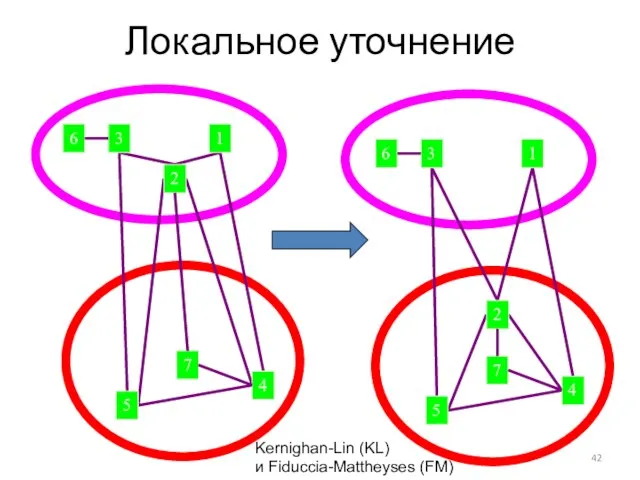
Слайд 42Локальное уточнение
1
3
5
4
2
6
7
1
3
5
4
2
6
7
Kernighan-Lin (KL)
и Fiduccia-Mattheyses (FM)
Локальное уточнение
1
3
5
4
2
6
7
1
3
5
4
2
6
7
Kernighan-Lin (KL)
и Fiduccia-Mattheyses (FM)
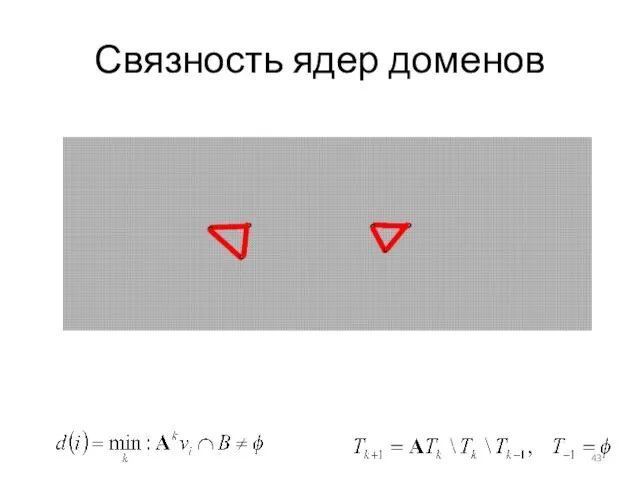
Слайд 43Связность ядер доменов
Связность ядер доменов
Слайд 44
Инкрементный алгоритм декомпозиции графа
Инкрементный алгоритм декомпозиции графа
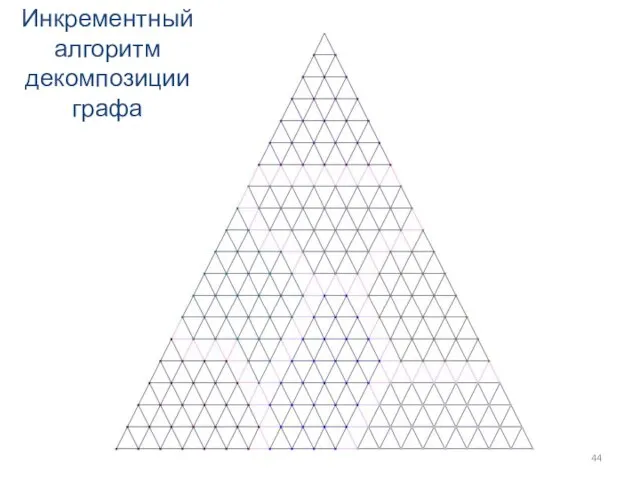
Слайд 45Редуцирование доменов
Редуцирование доменов

Слайд 46Инкрементный алгоритм, Dm=8
Инкрементный алгоритм, Dm=8
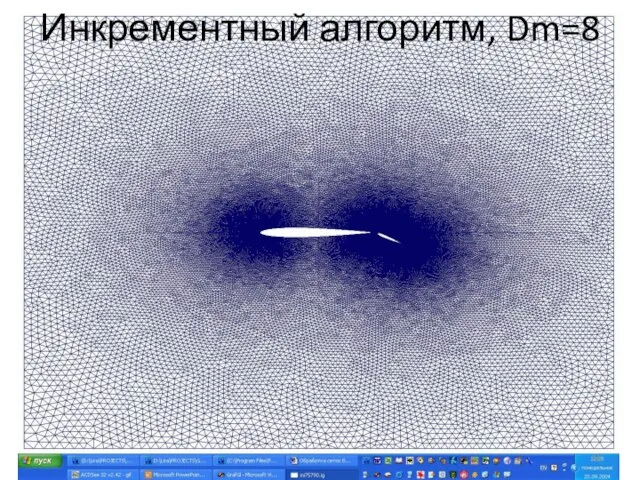
Слайд 47Инкрементный алгоритм, Dm=25
Инкрементный алгоритм, Dm=25

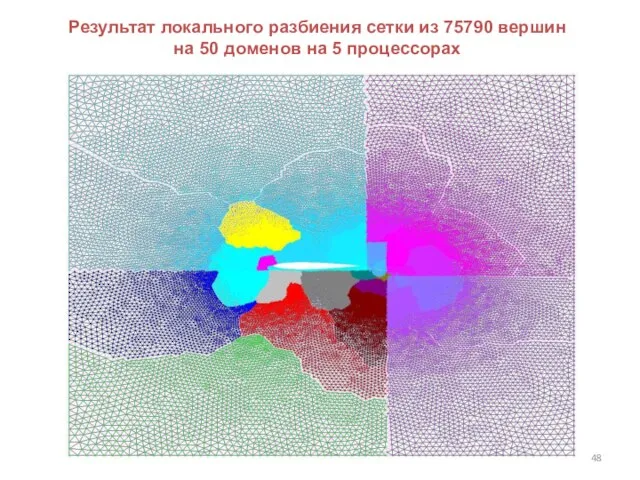
Слайд 48Результат локального разбиения сетки из 75790 вершин на 50 доменов на 5
Результат локального разбиения сетки из 75790 вершин на 50 доменов на 5
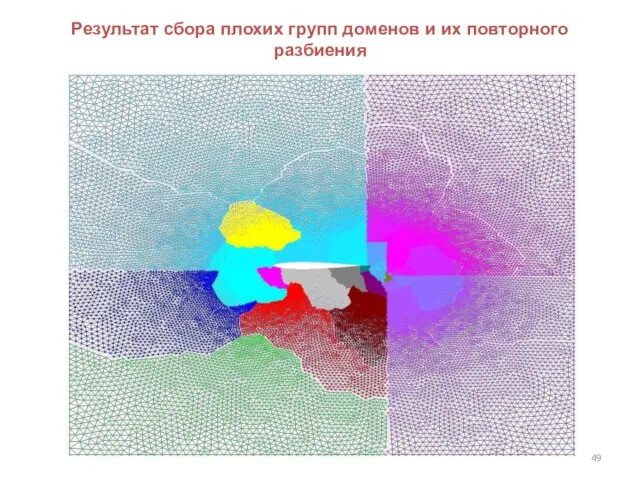
Слайд 49Результат сбора плохих групп доменов и их повторного разбиения
Результат сбора плохих групп доменов и их повторного разбиения
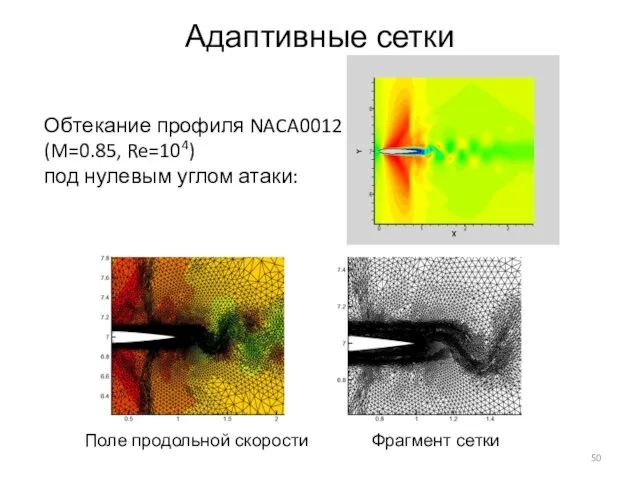
Слайд 50Адаптивные сетки
Обтекание профиля NACA0012 (M=0.85, Re=104)
под нулевым углом атаки:
Поле продольной скорости
Фрагмент сетки
Адаптивные сетки
Обтекание профиля NACA0012 (M=0.85, Re=104)
под нулевым углом атаки:
Поле продольной скорости
Фрагмент сетки
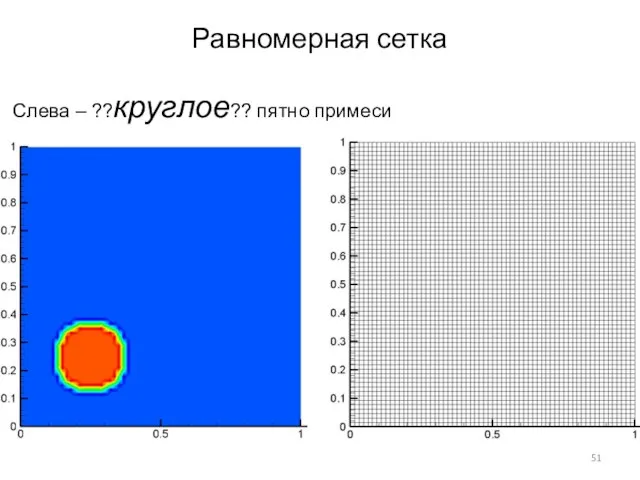
Слайд 51Равномерная сетка
Слева – ??круглое?? пятно примеси
Равномерная сетка
Слева – ??круглое?? пятно примеси
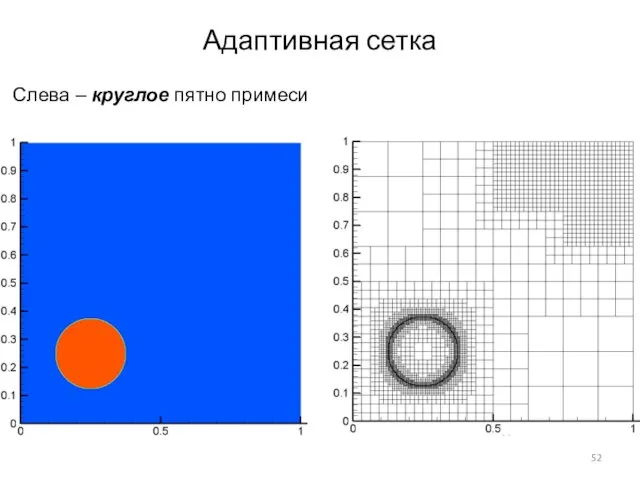
Слайд 52Адаптивная сетка
Слева – круглое пятно примеси
Адаптивная сетка
Слева – круглое пятно примеси
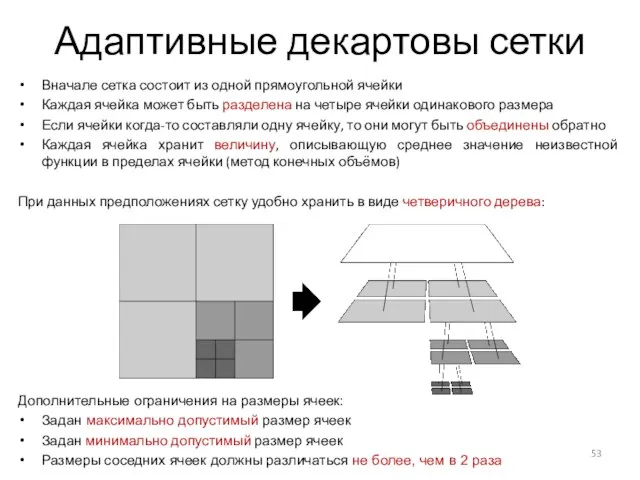
Слайд 53Адаптивные декартовы сетки
Вначале сетка состоит из одной прямоугольной ячейки
Каждая ячейка может быть
Адаптивные декартовы сетки
Вначале сетка состоит из одной прямоугольной ячейки
Каждая ячейка может быть
Слайд 54На рисунках показаны результаты решения простейшей задачи переноса на равномерной (слева) и
На рисунках показаны результаты решения простейшей задачи переноса на равномерной (слева) и
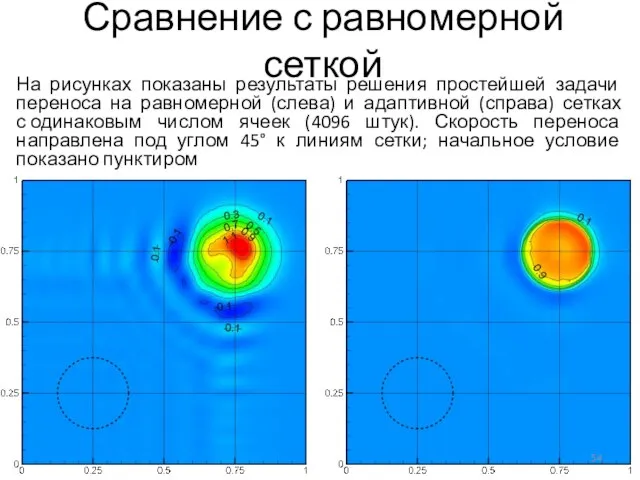
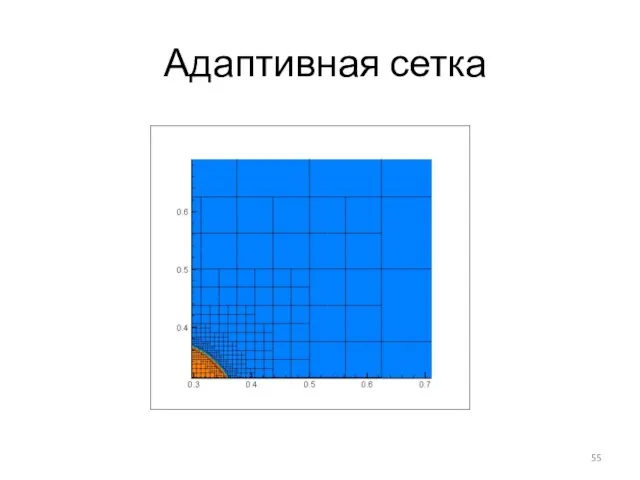
Слайд 55Адаптивная сетка
Адаптивная сетка
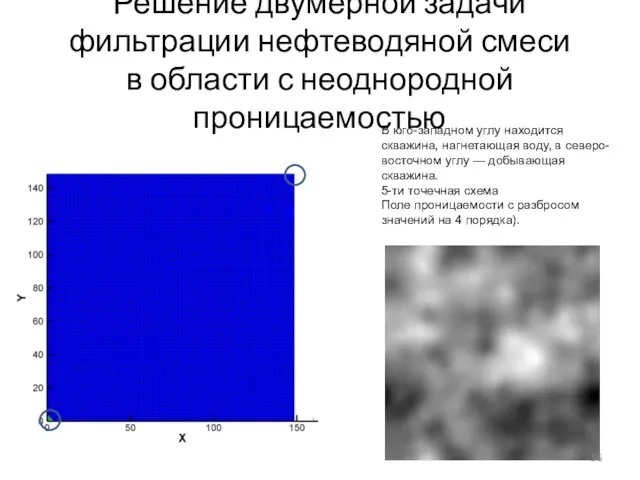
Слайд 56Решение двумерной задачи фильтрации нефтеводяной смеси в области с неоднородной проницаемостью
В юго-западном углу находится
Решение двумерной задачи фильтрации нефтеводяной смеси в области с неоднородной проницаемостью
В юго-западном углу находится
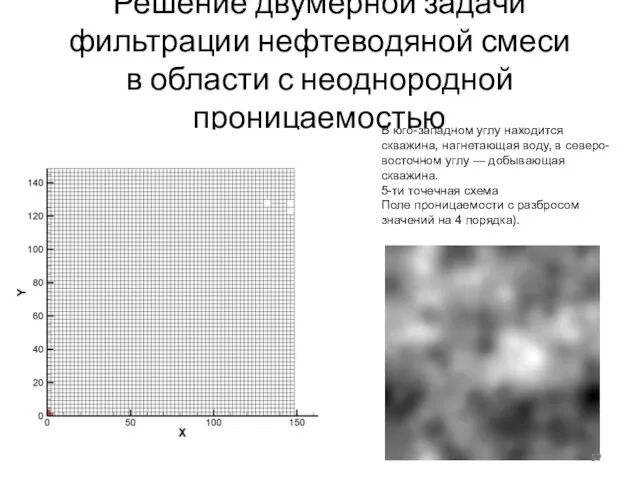
Слайд 57Решение двумерной задачи фильтрации нефтеводяной смеси в области с неоднородной проницаемостью
В юго-западном углу находится
Решение двумерной задачи фильтрации нефтеводяной смеси в области с неоднородной проницаемостью
В юго-западном углу находится
Слайд 58Динамическая балансировка загрузки
Перераспределение вычислительных узлов между процессорами необходимо:
При изменение конфигурации сетки
При изменение
Динамическая балансировка загрузки
Перераспределение вычислительных узлов между процессорами необходимо:
При изменение конфигурации сетки
При изменение

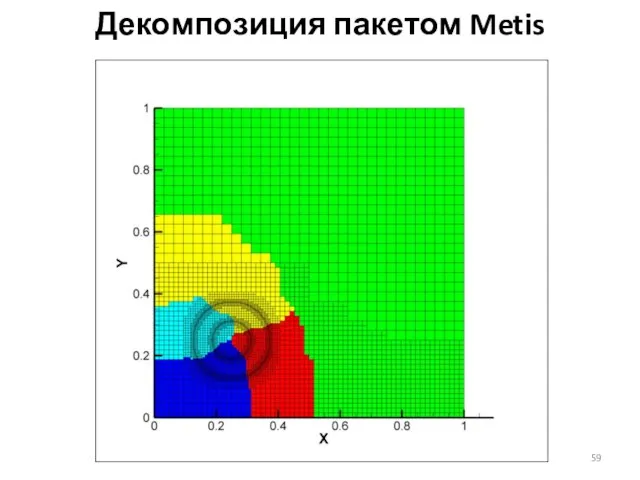
Слайд 59Декомпозиция пакетом Metis
Декомпозиция пакетом Metis
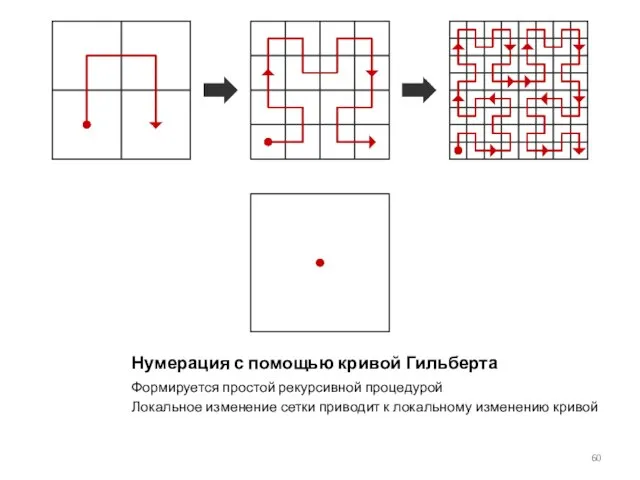
Слайд 60Нумерация с помощью кривой Гильберта
Формируется простой рекурсивной процедурой
Локальное изменение сетки приводит к
Нумерация с помощью кривой Гильберта
Формируется простой рекурсивной процедурой
Локальное изменение сетки приводит к
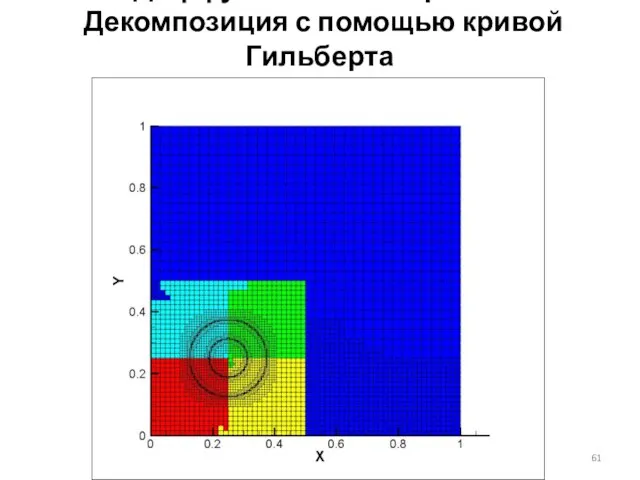
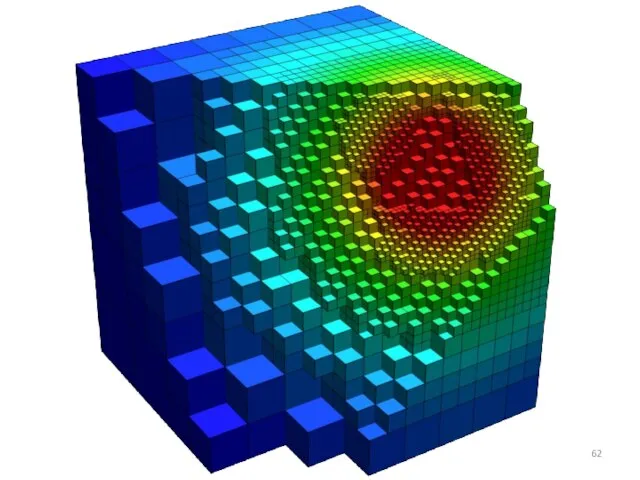
Слайд 61Диффузная балансировка
Декомпозиция с помощью кривой Гильберта
Диффузная балансировка
Декомпозиция с помощью кривой Гильберта
Слайд 63Стратегии балансировки загрузки
Wij - вычислительная нагрузка, ассоциированная с узлом сетки i на
Стратегии балансировки загрузки
Wij - вычислительная нагрузка, ассоциированная с узлом сетки i на

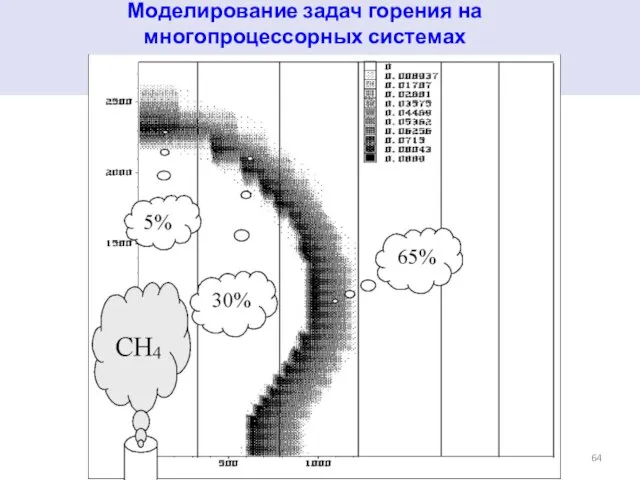
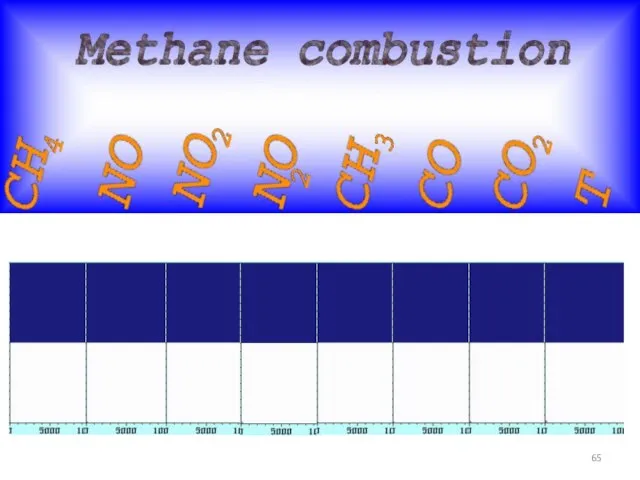
Слайд 64Моделирование задач горения на многопроцессорных системах
Моделирование задач горения на многопроцессорных системах
Слайд 66
Здесь A оператор, ρ - плотность,
y(i) – массовые доли i-х компонент,
Здесь A оператор, ρ - плотность,
y(i) – массовые доли i-х компонент,

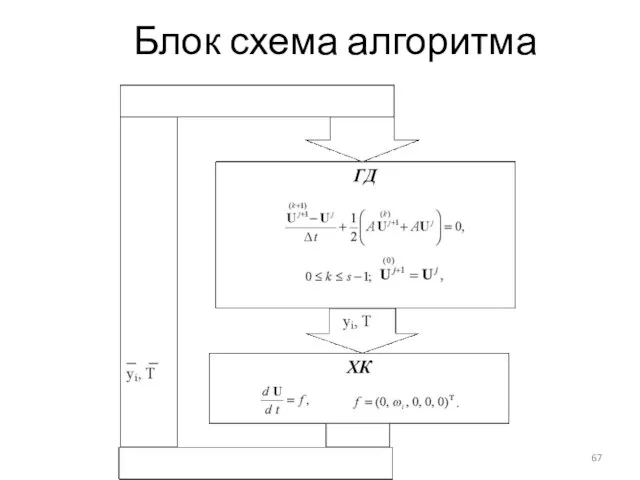
Слайд 67Блок схема алгоритма
Блок схема алгоритма
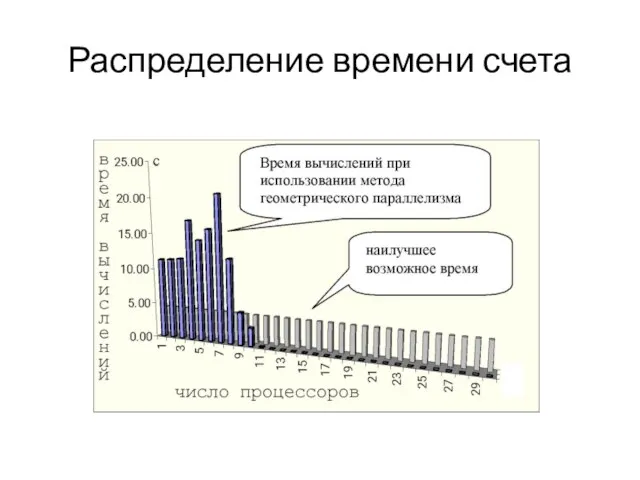
Слайд 68Распределение времени счета
Распределение времени счета
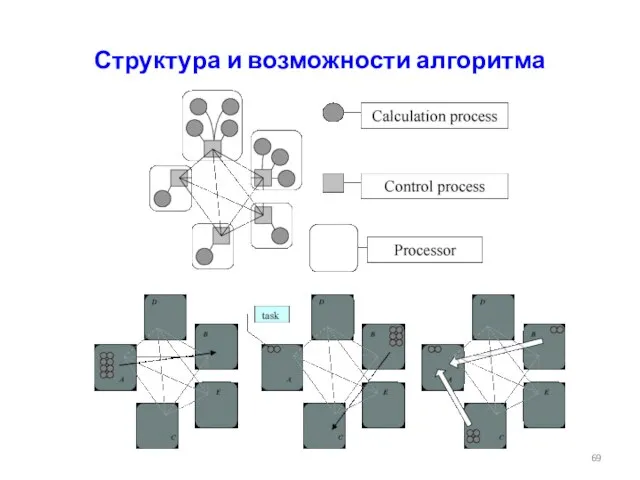
Слайд 69Структура и возможности алгоритма
Структура и возможности алгоритма
Слайд 70Сотояния обрабатывающего процесса
занят - если установлен соответствующий флаг. Этот флаг устанавливается перед
Сотояния обрабатывающего процесса
занят - если установлен соответствующий флаг. Этот флаг устанавливается перед

Слайд 71Управляющий процесс
1. если
- есть необработанные точки (неважно локальные или внешние) и
-
Управляющий процесс
1. если - есть необработанные точки (неважно локальные или внешние) и -

Слайд 72Управляющий процесс
2. если
- нет локальных необработанных точек и
- нет внешних точек и
-
Управляющий процесс
2. если - нет локальных необработанных точек и - нет внешних точек и -

Слайд 73Управляющий процесс
Иначе (если не 2)
3. если
- все переданные точки получены обратно обработанными
Управляющий процесс
Иначе (если не 2)
3. если
- все переданные точки получены обратно обработанными

Слайд 74Управляющий процесс
4. получить очередное сообщение от любого процессора или от своего обрабатывающего
Управляющий процесс
4. получить очередное сообщение от любого процессора или от своего обрабатывающего

Слайд 75Окончание при выполнение всех условий:
нет локальных необработанных точек
нет внешних точек
нет обрабатываемых точек
всем
Окончание при выполнение всех условий:
нет локальных необработанных точек
нет внешних точек
нет обрабатываемых точек
всем

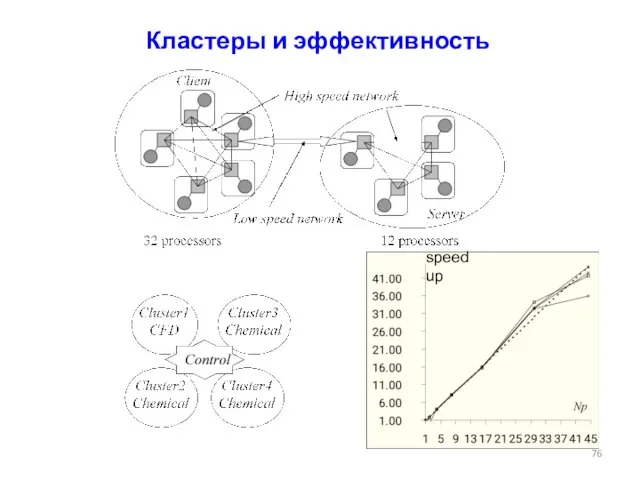
Слайд 76Кластеры и эффективность
speedup
Кластеры и эффективность
speedup
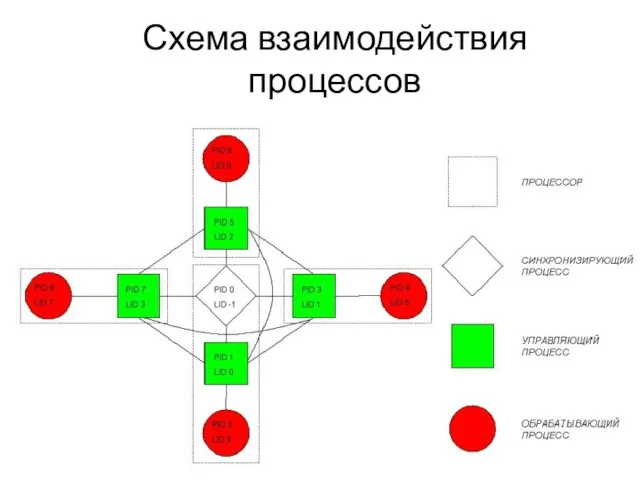
Слайд 77Схема взаимодействия процессов
Схема взаимодействия процессов
 Исламов Р.Ф., Кабак И.Н.
Исламов Р.Ф., Кабак И.Н. Реферат«Трудный путь к победе»(Великая Отечественная война 1941-1945)Выполнила:учащаяся 10 «А» классаМОУ СОШ №40Амелина М.И.Научны
Реферат«Трудный путь к победе»(Великая Отечественная война 1941-1945)Выполнила:учащаяся 10 «А» классаМОУ СОШ №40Амелина М.И.Научны Цвет в одежде и интерьере, и его влияние на окружающую среду
Цвет в одежде и интерьере, и его влияние на окружающую среду Организация проведения dungeons & dragons fallout setting
Организация проведения dungeons & dragons fallout setting Портфолио ученика начальных классов
Портфолио ученика начальных классов Экстремизм: понятие, виды, ответственность
Экстремизм: понятие, виды, ответственность Популярность кальянной индустрии
Популярность кальянной индустрии Элементы кредитной системы России. Тест
Элементы кредитной системы России. Тест Культура и мода
Культура и мода Анализ сайта
Анализ сайта Искусство и жизнь человека
Искусство и жизнь человека И.С.Тургенев: жизнь и творчество
И.С.Тургенев: жизнь и творчество Управление ассортиментом яиц, реализуемых в торговом предприятии
Управление ассортиментом яиц, реализуемых в торговом предприятии Электронный мониторинг«Наша новая школа»
Электронный мониторинг«Наша новая школа» Появление человека разумного
Появление человека разумного Использование приёма раскадровки при работе над изложением
Использование приёма раскадровки при работе над изложением Зубова Поляна
Зубова Поляна Портфолио фотоографа Алексеевой Анастасии
Портфолио фотоографа Алексеевой Анастасии Луна - спутница Земли
Луна - спутница Земли Материальное преимущество. Шахматы в школе
Материальное преимущество. Шахматы в школе Реформа электроэнергетики России: промежуточные итоги и развитие концепции
Реформа электроэнергетики России: промежуточные итоги и развитие концепции Развитие умения писать слова с разделительными твердым и мягким знаком
Развитие умения писать слова с разделительными твердым и мягким знаком Исследование деятельности научных групп Российской Федерации
Исследование деятельности научных групп Российской Федерации Заседание №1 научно-физкультурного клуба “FinFizCult”
Заседание №1 научно-физкультурного клуба “FinFizCult” Солидарная пенсия
Солидарная пенсия Спектакль и дискотека
Спектакль и дискотека Презентация на тему Первая медицинская помощь при ранениях
Презентация на тему Первая медицинская помощь при ранениях  Наш Брянск
Наш Брянск