- Файловые системы

Содержание
- 2. Файлы идентифицируются именами. Пользователи дают файлам символьные имена, при этом учитываются ограничения ОС как на используемые
- 3. При переходе к длинным именам возникает проблема совместимости с ранее созданными приложениями, использующими короткие имена. Чтобы
- 4. Обычно разные файлы могут иметь одинаковые символьные имена. В этом случае файл однозначно идентифицируется так называемым
- 5. Файлы бывают разных типов: обычные файлы, специальные файлы, файлы-каталоги. Обычные файлы подразделяются на текстовые и двоичные.
- 6. Специальные файлы - это файлы, ассоциированные с устройствами ввода-вывода, которые позволяют пользователю выполнять соответствующие операции, используя
- 7. В разных файловых системах могут использоваться в качестве атрибутов разные характеристики, например: информация о разрешенном доступе;
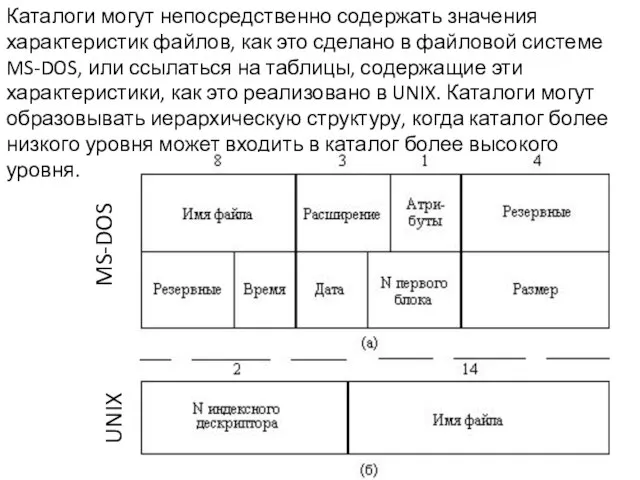
- 8. Каталоги могут непосредственно содержать значения характеристик файлов, как это сделано в файловой системе MS-DOS, или ссылаться
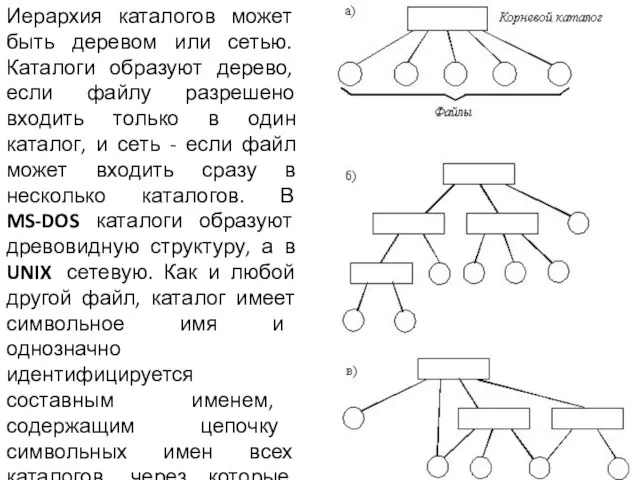
- 9. Иерархия каталогов может быть деревом или сетью. Каталоги образуют дерево, если файлу разрешено входить только в
- 10. Программист имеет дело с логической организацией файла, представляя файл в виде определенным образом организованных логических записей.
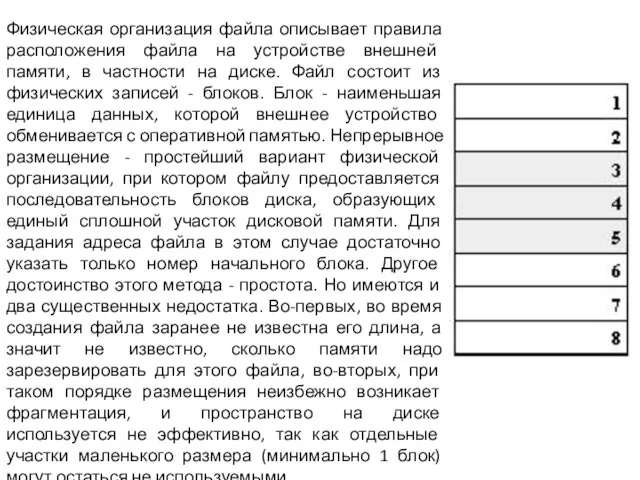
- 11. Физическая организация файла описывает правила расположения файла на устройстве внешней памяти, в частности на диске. Файл
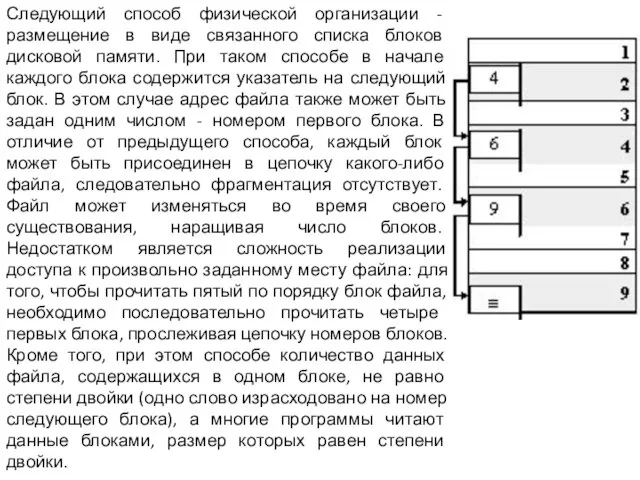
- 12. Следующий способ физической организации - размещение в виде связанного списка блоков дисковой памяти. При таком способе
- 13. Популярным способом, используемым, например, в файловой системе FAT операционной системы MS-DOS, является использование связанного списка индексов.
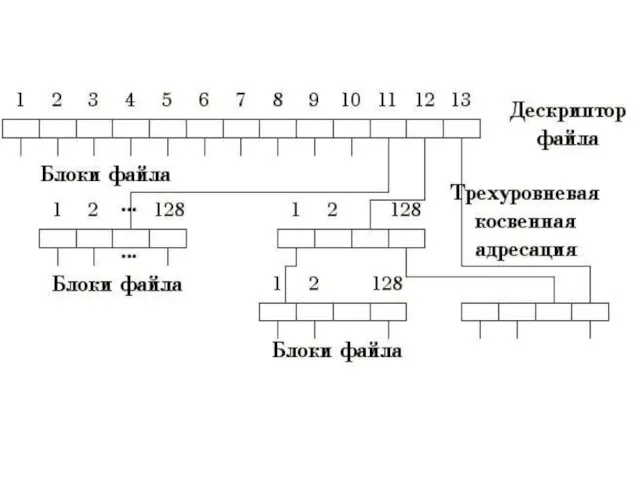
- 14. Pассмотрим задание физического расположения файла путем простого перечисления номеров блоков, занимаемых этим файлом. ОС UNIX использует
- 16. Права доступа к файлу Определить права доступа к файлу - значит определить для каждого пользователя набор
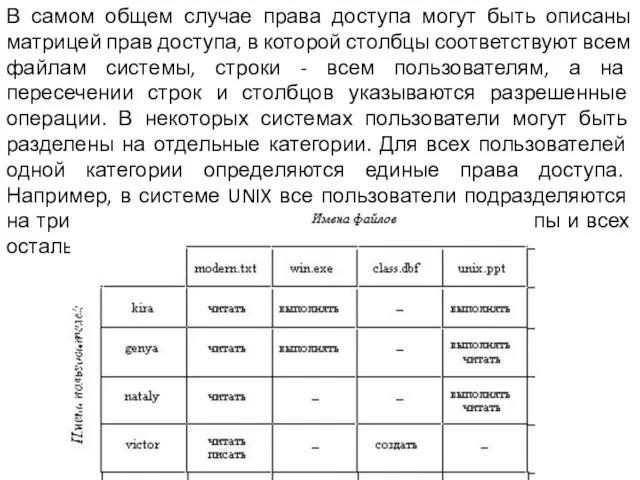
- 17. В самом общем случае права доступа могут быть описаны матрицей прав доступа, в которой столбцы соответствуют
- 18. Различают два основных подхода к определению прав доступа: избирательный доступ, когда для каждого файла и каждого
- 19. Функционирование любой файловой системы можно представить многоуровневой моделью, в которой каждый уровень предоставляет некоторый интерфейс вышележащему
- 20. Задачей символьного уровня является определение по символьному имени файла его уникального имени. В файловых системах, в
- 21. На логическом уровне определяются координаты запрашиваемой логической записи в файле, то есть требуется определить, на каком
- 22. Исходные данные: V - размер блока N - номер первого блока файла S - смещение логической
- 23. Разработчики операционных систем стремятся обеспечить пользователя возможностью работать сразу с несколькими файловыми системами. В новом понимании
- 24. Каждый компонент уровня файловых систем выполнен в виде драйвера соответствующей файловой системы и поддерживает определенную её
- 25. Большое число уровней архитектуры файловой системы обеспечивает авторам драйверов устройств большую гибкость - драйвер может получить
- 26. Распределенные файловые системы Две главные цели. Сетевая прозрачность. Самая важная цель - обеспечить те же самые
- 27. Понятие файлового сервиса и файлового сервера. Файловый сервис - это то, что файловая система предоставляет своим
- 28. Архитектура распределенных файловых систем Распределенная система обычно имеет два существенно отличающихся компонента - непосредственно файловый сервис
- 29. Важный аспект файловой модели - могут ли файлы модифицироваться после создания. Обычно могут, но есть системы
- 30. Интерфейс сервера директорий Обеспечивает операции создания и удаления директорий, именования и переименования файлов, перемещение файлов из
- 31. Прозрачность именования. Две формы прозрачности именования различают - прозрачность расположения (/server/d1/f1) и прозрачность миграции (когда изменение
- 32. Двухуровневое именование. Большинство систем используют ту или иную форму двухуровневого именования. Файлы (и другие объекты) имеют
- 33. Семантика разделения файлов UNIX-семантика Естественная семантика однопроцессорной ЭВМ - если за операцией записи следует чтение, то
- 34. Семантика сессий Изменения открытого файла видны только тому процессу (или машине), который производит эти изменения, а
- 35. Реализация распределенных файловых систем Приступая к реализации очень важно понимать, как система будет использоваться. Приведем результаты
- 36. Структура системы Есть ли разница между клиентами и серверами? Имеются системы, где все машины имеют одно
- 37. В случае разделения серверов и при наличии разных серверов директорий для различных поддеревьев возникает следующая проблема.
- 38. Существует две конкурирующие точки зрения. Первая состоит в том, что сервер не должен хранить такую информацию
- 39. Серверы с состоянием. Достоинства. Короче сообщения (двоичные имена используют таблицу открытых файлов). выше эффективность (информация об
- 40. Кэширование В системе клиент-сервер с памятью и дисками есть четыре потенциальных места для хранения файлов или
- 41. Поэтому рассмотрим подробнее организацию кэширования в памяти клиента. кэширование в каждом процессе. По мере того, как
- 42. Кэширование в ядре. Недостатком этого варианта является то, что во всех случаях требуется выполнять системные вызовы,
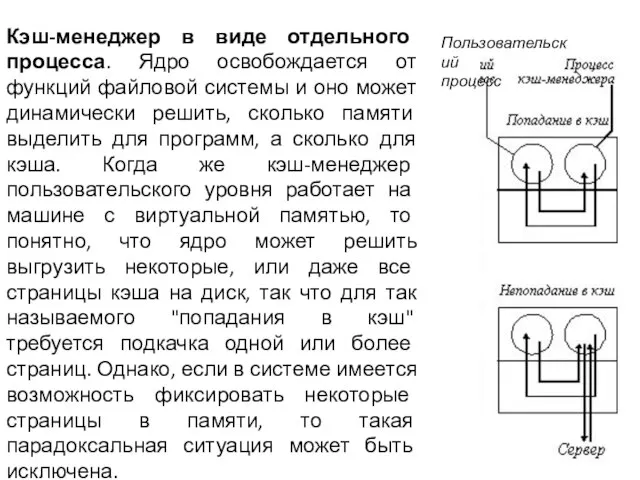
- 43. Кэш-менеджер в виде отдельного процесса. Ядро освобождается от функций файловой системы и оно может динамически решить,
- 44. Когерентность кэшей. Алгоритм со сквозной записью. Необходимость проверки, не устарела ли информация в кэше. Запись вызывает
- 45. Размножение Система может предоставлять такой сервис, как поддержание для указанных файлов нескольких копий на различных серверах.
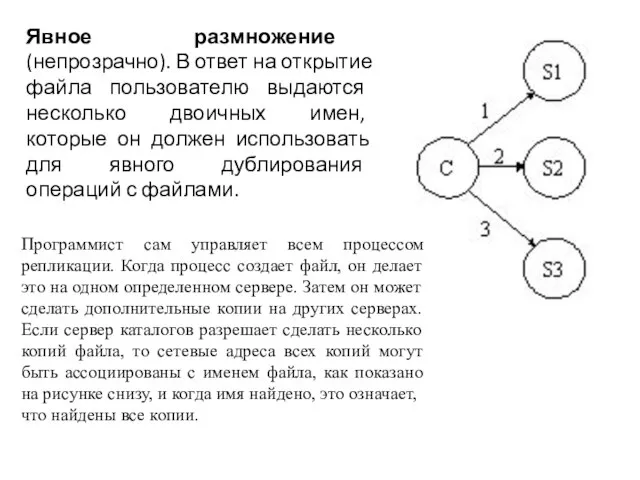
- 46. Явное размножение (непрозрачно). В ответ на открытие файла пользователю выдаются несколько двоичных имен, которые он должен
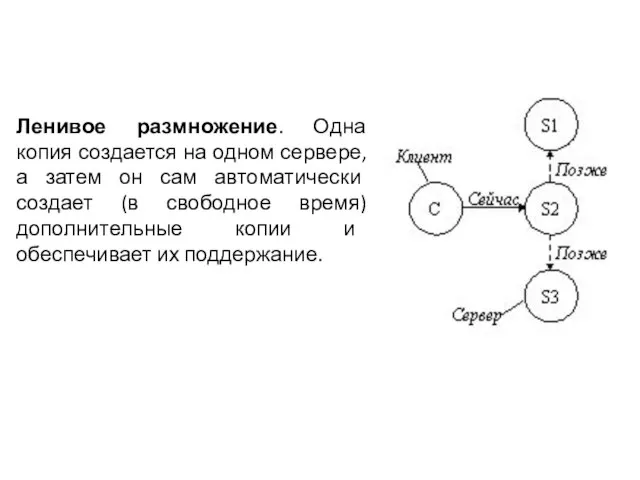
- 47. Ленивое размножение. Одна копия создается на одном сервере, а затем он сам автоматически создает (в свободное
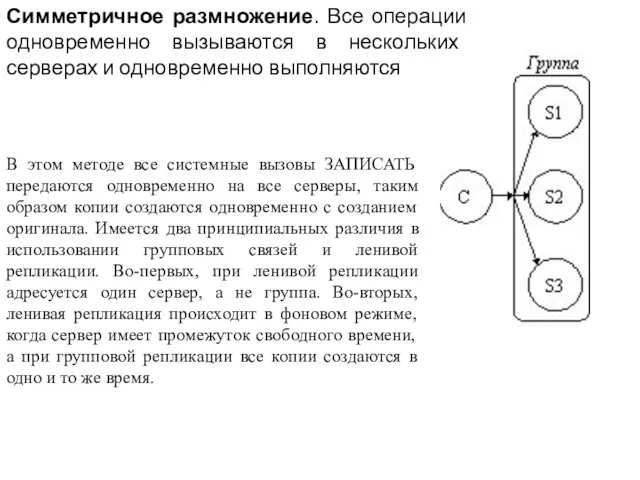
- 48. Симметричное размножение. Все операции одновременно вызываются в нескольких серверах и одновременно выполняются В этом методе все
- 49. Протоколы коррекции. Рассмотрим, как могут быть изменены существующие реплицированные файлы. Существует два хорошо известных алгоритма решения
- 51. Скачать презентацию
Слайд 2Файлы идентифицируются именами. Пользователи дают файлам символьные имена, при этом учитываются ограничения
Файлы идентифицируются именами. Пользователи дают файлам символьные имена, при этом учитываются ограничения

Слайд 3При переходе к длинным именам возникает проблема совместимости с ранее созданными приложениями,
При переходе к длинным именам возникает проблема совместимости с ранее созданными приложениями,

Слайд 4Обычно разные файлы могут иметь одинаковые символьные имена. В этом случае файл
Обычно разные файлы могут иметь одинаковые символьные имена. В этом случае файл

Слайд 5Файлы бывают разных типов: обычные файлы, специальные файлы, файлы-каталоги.
Обычные файлы подразделяются на
Файлы бывают разных типов: обычные файлы, специальные файлы, файлы-каталоги.
Обычные файлы подразделяются на

Слайд 6Специальные файлы - это файлы, ассоциированные с устройствами ввода-вывода, которые позволяют пользователю
Специальные файлы - это файлы, ассоциированные с устройствами ввода-вывода, которые позволяют пользователю

Слайд 7В разных файловых системах могут использоваться в качестве атрибутов разные характеристики, например:
информация
В разных файловых системах могут использоваться в качестве атрибутов разные характеристики, например:
информация

Слайд 8Каталоги могут непосредственно содержать значения характеристик файлов, как это сделано в файловой
Каталоги могут непосредственно содержать значения характеристик файлов, как это сделано в файловой
Слайд 9Иерархия каталогов может быть деревом или сетью. Каталоги образуют дерево, если файлу
Иерархия каталогов может быть деревом или сетью. Каталоги образуют дерево, если файлу
Слайд 10Программист имеет дело с логической организацией файла, представляя файл в виде определенным
Программист имеет дело с логической организацией файла, представляя файл в виде определенным

Слайд 11Физическая организация файла описывает правила расположения файла на устройстве внешней памяти, в
Физическая организация файла описывает правила расположения файла на устройстве внешней памяти, в
Слайд 12Следующий способ физической организации - размещение в виде связанного списка блоков дисковой
Следующий способ физической организации - размещение в виде связанного списка блоков дисковой
Слайд 13Популярным способом, используемым, например, в файловой системе FAT операционной системы MS-DOS, является
Популярным способом, используемым, например, в файловой системе FAT операционной системы MS-DOS, является

Слайд 14Pассмотрим задание физического расположения файла путем простого перечисления номеров блоков, занимаемых этим
Pассмотрим задание физического расположения файла путем простого перечисления номеров блоков, занимаемых этим

Слайд 16Права доступа к файлу
Определить права доступа к файлу - значит определить для
Права доступа к файлу
Определить права доступа к файлу - значит определить для

Слайд 17В самом общем случае права доступа могут быть описаны матрицей прав доступа,
В самом общем случае права доступа могут быть описаны матрицей прав доступа,
Слайд 18Различают два основных подхода к определению прав доступа:
избирательный доступ, когда для каждого
Различают два основных подхода к определению прав доступа:
избирательный доступ, когда для каждого

Слайд 19Функционирование любой файловой системы можно представить многоуровневой моделью, в которой каждый уровень
Функционирование любой файловой системы можно представить многоуровневой моделью, в которой каждый уровень
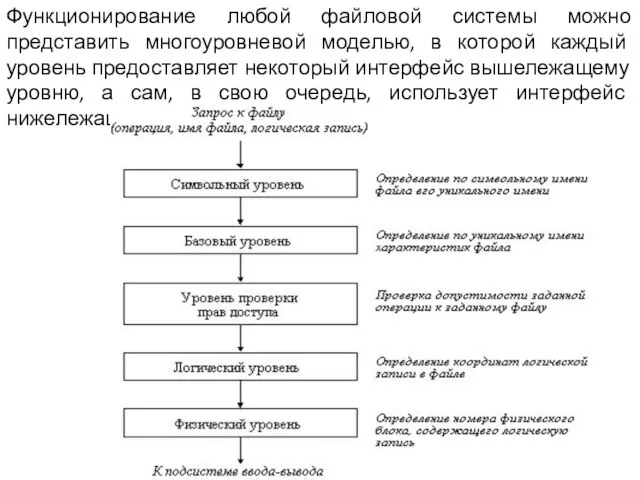
Слайд 20Задачей символьного уровня является определение по символьному имени файла его уникального имени.
Задачей символьного уровня является определение по символьному имени файла его уникального имени.

Слайд 21На логическом уровне определяются координаты запрашиваемой логической записи в файле, то есть
На логическом уровне определяются координаты запрашиваемой логической записи в файле, то есть
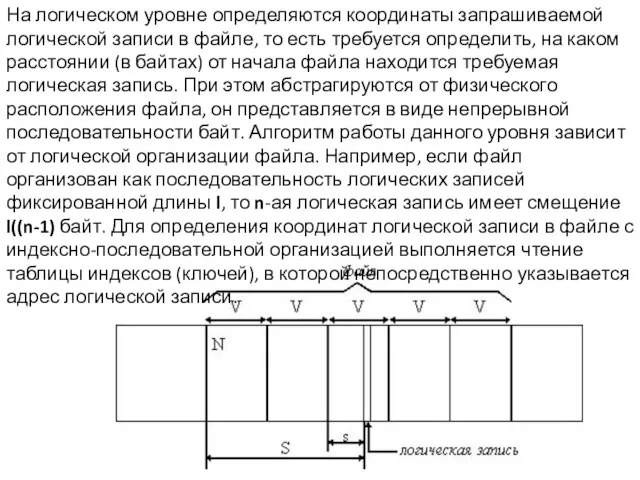
Слайд 22Исходные данные:
V - размер блока
N - номер первого блока файла
Исходные данные: V - размер блока N - номер первого блока файла
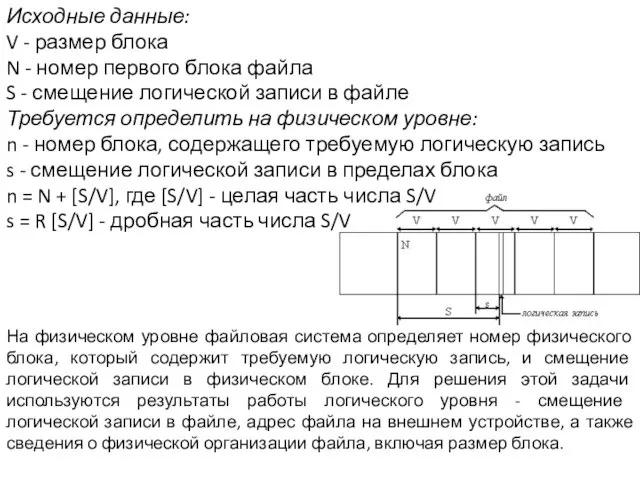
Слайд 23Разработчики операционных систем стремятся обеспечить пользователя возможностью работать сразу с несколькими файловыми
Разработчики операционных систем стремятся обеспечить пользователя возможностью работать сразу с несколькими файловыми

Слайд 24Каждый компонент уровня файловых систем выполнен в виде драйвера соответствующей файловой системы
Каждый компонент уровня файловых систем выполнен в виде драйвера соответствующей файловой системы
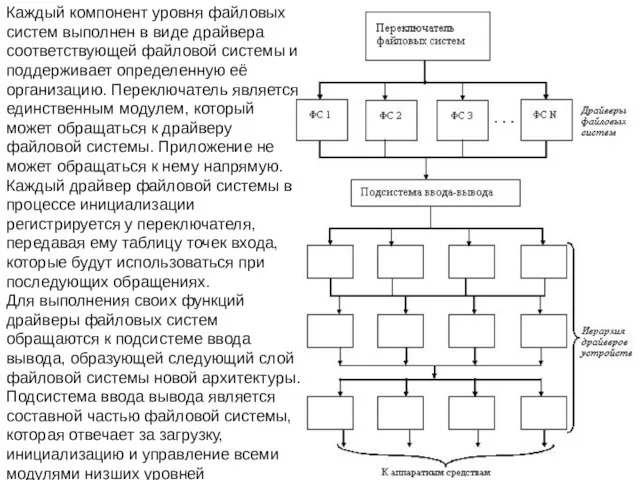
Слайд 25Большое число уровней архитектуры файловой системы обеспечивает авторам драйверов устройств большую гибкость
Большое число уровней архитектуры файловой системы обеспечивает авторам драйверов устройств большую гибкость

Слайд 26Распределенные файловые системы
Две главные цели.
Сетевая прозрачность.
Самая важная цель - обеспечить
Распределенные файловые системы
Две главные цели.
Сетевая прозрачность.
Самая важная цель - обеспечить

Слайд 27Понятие файлового сервиса и файлового сервера.
Файловый сервис - это то, что
Понятие файлового сервиса и файлового сервера.
Файловый сервис - это то, что

Слайд 28Архитектура распределенных файловых систем
Распределенная система обычно имеет два существенно отличающихся компонента -
Архитектура распределенных файловых систем
Распределенная система обычно имеет два существенно отличающихся компонента -

Слайд 29Важный аспект файловой модели - могут ли файлы модифицироваться после создания. Обычно
Важный аспект файловой модели - могут ли файлы модифицироваться после создания. Обычно

Слайд 30Интерфейс сервера директорий
Обеспечивает операции создания и удаления директорий, именования и переименования файлов,
Интерфейс сервера директорий
Обеспечивает операции создания и удаления директорий, именования и переименования файлов,

Слайд 31Прозрачность именования.
Две формы прозрачности именования различают - прозрачность расположения (/server/d1/f1) и
Прозрачность именования.
Две формы прозрачности именования различают - прозрачность расположения (/server/d1/f1) и

Слайд 32Двухуровневое именование.
Большинство систем используют ту или иную форму двухуровневого именования. Файлы
Двухуровневое именование.
Большинство систем используют ту или иную форму двухуровневого именования. Файлы

Слайд 33Семантика разделения файлов
UNIX-семантика
Естественная семантика однопроцессорной ЭВМ - если за операцией записи следует
Семантика разделения файлов
UNIX-семантика
Естественная семантика однопроцессорной ЭВМ - если за операцией записи следует

Слайд 34Семантика сессий
Изменения открытого файла видны только тому процессу (или машине), который производит
Семантика сессий
Изменения открытого файла видны только тому процессу (или машине), который производит

Слайд 35Реализация распределенных файловых систем
Приступая к реализации очень важно понимать, как система будет
Реализация распределенных файловых систем
Приступая к реализации очень важно понимать, как система будет

Слайд 36Структура системы
Есть ли разница между клиентами и серверами? Имеются системы, где все
Структура системы
Есть ли разница между клиентами и серверами? Имеются системы, где все

Слайд 37В случае разделения серверов и при наличии разных серверов директорий для различных
В случае разделения серверов и при наличии разных серверов директорий для различных

Слайд 38Существует две конкурирующие точки зрения.
Первая состоит в том, что сервер не
Существует две конкурирующие точки зрения.
Первая состоит в том, что сервер не

Слайд 39Серверы с состоянием. Достоинства.
Короче сообщения (двоичные имена используют таблицу открытых файлов).
выше
Серверы с состоянием. Достоинства.
Короче сообщения (двоичные имена используют таблицу открытых файлов).
выше

Слайд 40Кэширование
В системе клиент-сервер с памятью и дисками есть четыре потенциальных места для
Кэширование
В системе клиент-сервер с памятью и дисками есть четыре потенциальных места для

Слайд 41Поэтому рассмотрим подробнее организацию кэширования в памяти клиента.
кэширование в каждом процессе.
Поэтому рассмотрим подробнее организацию кэширования в памяти клиента.
кэширование в каждом процессе.
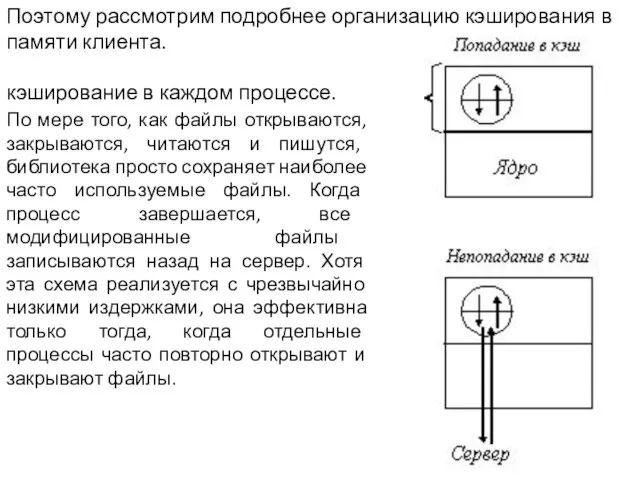
Слайд 42Кэширование в ядре. Недостатком этого варианта является то, что во всех случаях
Кэширование в ядре. Недостатком этого варианта является то, что во всех случаях
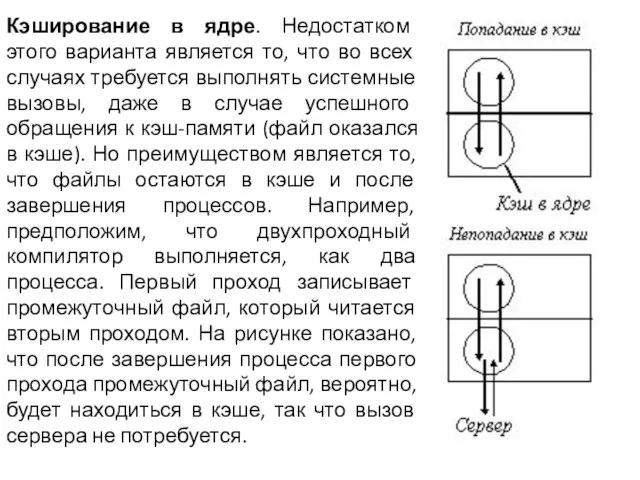
Слайд 43Кэш-менеджер в виде отдельного процесса. Ядро освобождается от функций файловой системы и
Кэш-менеджер в виде отдельного процесса. Ядро освобождается от функций файловой системы и
Слайд 44Когерентность кэшей.
Алгоритм со сквозной записью.
Необходимость проверки, не устарела ли информация в
Когерентность кэшей.
Алгоритм со сквозной записью.
Необходимость проверки, не устарела ли информация в

Слайд 45Размножение
Система может предоставлять такой сервис, как поддержание для указанных файлов нескольких копий
Размножение
Система может предоставлять такой сервис, как поддержание для указанных файлов нескольких копий

Слайд 46Явное размножение (непрозрачно). В ответ на открытие файла пользователю выдаются несколько двоичных
Явное размножение (непрозрачно). В ответ на открытие файла пользователю выдаются несколько двоичных
Слайд 47Ленивое размножение. Одна копия создается на одном сервере, а затем он сам
Ленивое размножение. Одна копия создается на одном сервере, а затем он сам
Слайд 48Симметричное размножение. Все операции одновременно вызываются в нескольких серверах и одновременно выполняются
В
Симметричное размножение. Все операции одновременно вызываются в нескольких серверах и одновременно выполняются
В
Слайд 49Протоколы коррекции.
Рассмотрим, как могут быть изменены существующие реплицированные файлы. Существует два
Протоколы коррекции.
Рассмотрим, как могут быть изменены существующие реплицированные файлы. Существует два

 Фекальные установки compli
Фекальные установки compli Конституция РФ
Конституция РФ «Мгновение слишком яркого света»(Раннее творчество А.А. Блока)
«Мгновение слишком яркого света»(Раннее творчество А.А. Блока) Рассказ И.А. Бунина «Подснежник»
Рассказ И.А. Бунина «Подснежник» Презентация на тему Чрезвычайные ситуации техногенного характера
Презентация на тему Чрезвычайные ситуации техногенного характера Л1 мех.оборуд
Л1 мех.оборуд Презентация на тему Политическая жизнь современной России
Презентация на тему Политическая жизнь современной России  Ворота зимы. Изменения в неживой природе
Ворота зимы. Изменения в неживой природе Основа роста в бизнесе. Рабочая тетрадь. Шаблон
Основа роста в бизнесе. Рабочая тетрадь. Шаблон Притчи
Притчи Электронное строение атома
Электронное строение атома Детство, опаленное войной
Детство, опаленное войной Необычайные приключения семиклассника Вовочки.
Необычайные приключения семиклассника Вовочки. Из истории крылатых выражений. Шаблон
Из истории крылатых выражений. Шаблон Письменная литература Древней Руси. О древнерусском летописании. "Повесть временных лет"
Письменная литература Древней Руси. О древнерусском летописании. "Повесть временных лет" Методический час по использованию нетрадиционных форм работы
Методический час по использованию нетрадиционных форм работы Управление проектом по временным параметрам
Управление проектом по временным параметрам Гигиена при занятиях физической культуры
Гигиена при занятиях физической культуры Африка 7 класс
Африка 7 класс Презентация на тему Округление чисел
Презентация на тему Округление чисел  Берегись автомобиля!
Берегись автомобиля! Творческая лаборатория «Мастерская письма»для просмотра материала пройдите по ссылке http://files.mail.ru/UBJ99S
Творческая лаборатория «Мастерская письма»для просмотра материала пройдите по ссылке http://files.mail.ru/UBJ99S Свой сайт в интернете.
Свой сайт в интернете. Администрирование информационных систем
Администрирование информационных систем Предварительные итоги 3-го каталога. Орифлэйм
Предварительные итоги 3-го каталога. Орифлэйм Презентация на тему Лихтенштейн
Презентация на тему Лихтенштейн  Основные категории специальной психологии и коррекционной педагогики. Их краткая характеристика
Основные категории специальной психологии и коррекционной педагогики. Их краткая характеристика Блефариты коньюнктивиты увеиты
Блефариты коньюнктивиты увеиты