- Графические процессоры

Содержание
- 2. Официальные спецификации GeForce 6800 16 Пиксельных процессоров, по одному текстурному блоку на каждом с произвольной фильтрацией
- 3. Общая схема чипа NV40 -многоканальный контроллер памяти. Вместо одной очень широкой 128- или 256-бит шины памяти
- 4. Вершинные процессоры и выборка данных Поддержка разных т.н. «делителей частоты» для потоков исходных данных вершин. Каждый
- 5. Блок схема вершинного процессора NV40
- 6. Параметры вершинного процессора NV40
- 7. Пиксельные процессоры и организация закраски Число TMU – теперь у нас только по одному TMU на
- 8. Параметры пиксельного процессора NV40
- 9. 2D и Видеопроцессор Процессор содержит четыре функциональных блока (целочисленное ALU, векторное целочисленное ALU с 16 компонентами,
- 10. Спецификации GeForce 7800 GTX (кодовое название G70) 24 Пиксельных процессора, по одному текстурному блоку на каждом,
- 11. Архитектура ускорителя Наличие 8 вершинных процессоров и 6 процессоров квадов (всего, таким образом, обрабатывается 4*6=24 пикселя)
- 12. Пиксельный конвейер ALU умеют выполнить MAD операцию (одновременное умножение и сложение) без какого либо пенальти Выборка
- 13. Вершинный конвейер Число вершинных процессоров увеличилось с 6 до 8.
- 14. Форматы данных, с которыми работает ускоритель VS 3.0 — FP32 PS 3.0 — FP16, FP32 Текстуры
- 15. Унифицированная архитектура
- 16. Графический ускоритель GeForce 8800 Унифицированная архитектура (массив общих процессоров для потоковой обработки вершин и пикселей, а
- 17. Архитектура Чип состоит из 8 универсальных вычислительных блоков (шейдерных процессоров), и хотя NVIDIA говорит о 128
- 18. Шейдерный процессор и его TMU/ALU В каждом из 8 шейдерных блоков в наличии 16 скалярных ALU.
- 19. ALU Операция выборки и фильтрации текстур не требует ресурсов ALU и может теперь производиться полностью параллельно
- 20. Параметры пиксельного процессора G80 Налицо значительные количественные и качественные перемены - все меньше и меньше ограничений
- 21. Текстурные модули(TMU) В наличии 4 модуля для адресации текстур TA (определения по координатам точного адреса для
- 22. Блоки ROP, запись в буфер кадра, сглаживание полноценная поддержка FP32 и FP16 форматов буфера кадров ВМЕСТЕ
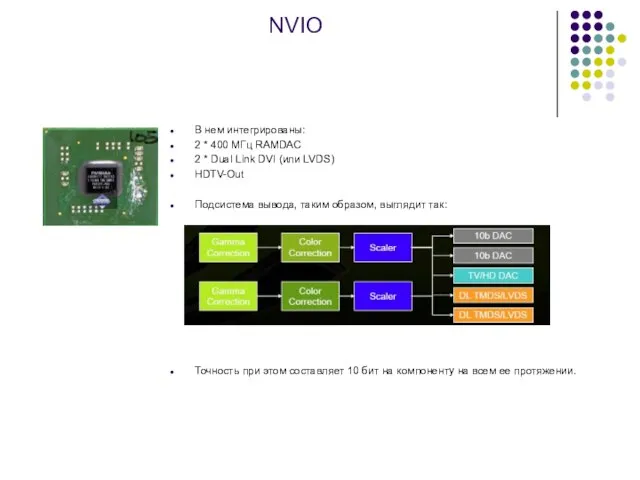
- 23. NVIO В нем интегрированы: 2 * 400 МГц RAMDAC 2 * Dual Link DVI (или LVDS)
- 25. Скачать презентацию
Слайд 2Официальные спецификации GeForce 6800
16 Пиксельных процессоров, по одному текстурному блоку на
Официальные спецификации GeForce 6800
16 Пиксельных процессоров, по одному текстурному блоку на

Слайд 3Общая схема чипа NV40
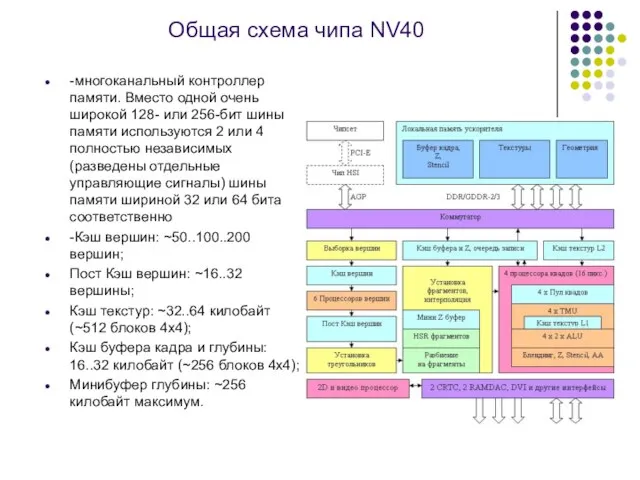
-многоканальный контроллер памяти. Вместо одной очень широкой 128- или
Общая схема чипа NV40
-многоканальный контроллер памяти. Вместо одной очень широкой 128- или
Слайд 4Вершинные процессоры и выборка данных
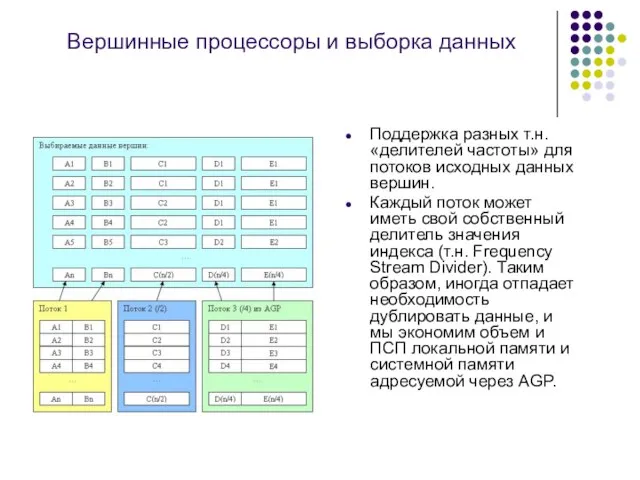
Поддержка разных т.н. «делителей частоты» для потоков
Вершинные процессоры и выборка данных
Поддержка разных т.н. «делителей частоты» для потоков
Слайд 5Блок схема вершинного процессора NV40
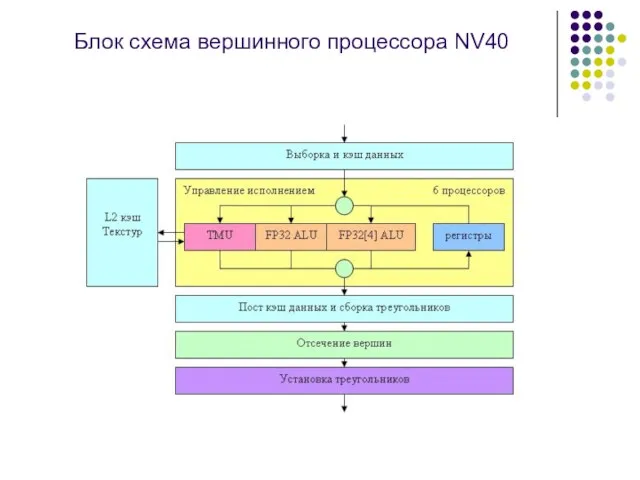
Блок схема вершинного процессора NV40
Слайд 6Параметры вершинного процессора NV40
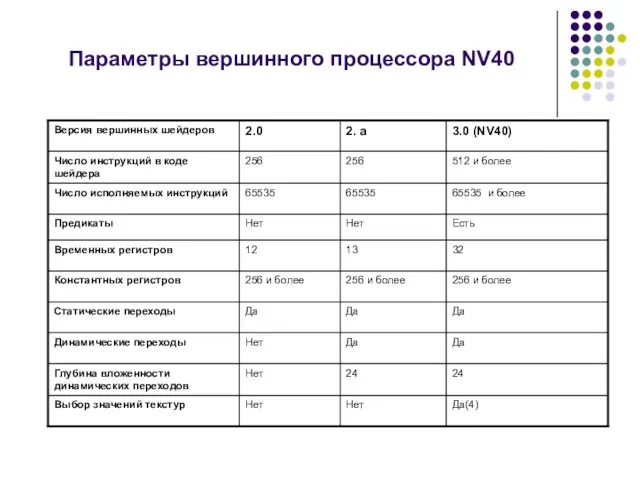
Параметры вершинного процессора NV40
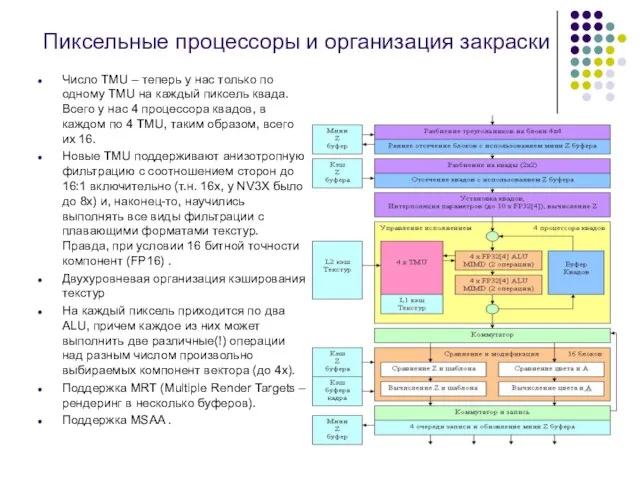
Слайд 7Пиксельные процессоры и организация закраски
Число TMU – теперь у нас только
Пиксельные процессоры и организация закраски
Число TMU – теперь у нас только
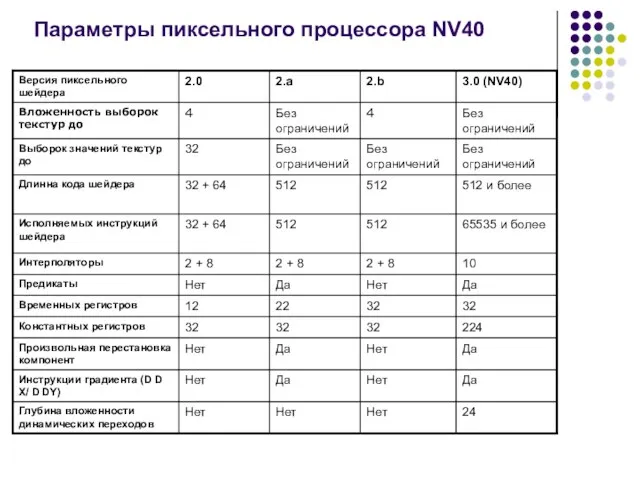
Слайд 8Параметры пиксельного процессора NV40
Параметры пиксельного процессора NV40
Слайд 92D и Видеопроцессор
Процессор содержит четыре функциональных блока (целочисленное ALU, векторное целочисленное
2D и Видеопроцессор
Процессор содержит четыре функциональных блока (целочисленное ALU, векторное целочисленное

Слайд 10Спецификации GeForce 7800 GTX (кодовое название G70)
24 Пиксельных процессора, по одному
Спецификации GeForce 7800 GTX (кодовое название G70)
24 Пиксельных процессора, по одному

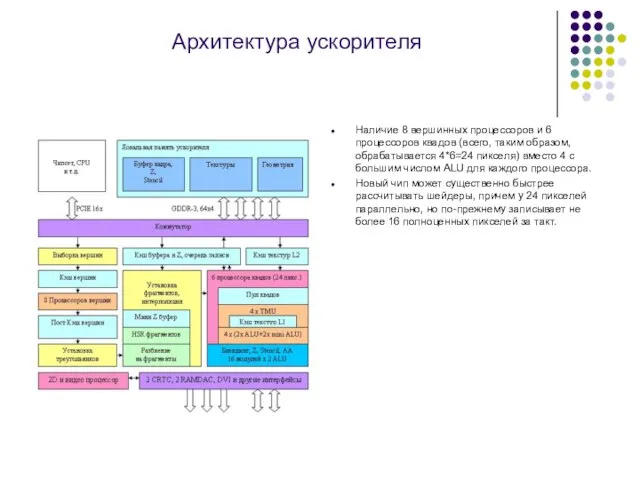
Слайд 11Архитектура ускорителя
Наличие 8 вершинных процессоров и 6 процессоров квадов (всего, таким
Архитектура ускорителя
Наличие 8 вершинных процессоров и 6 процессоров квадов (всего, таким
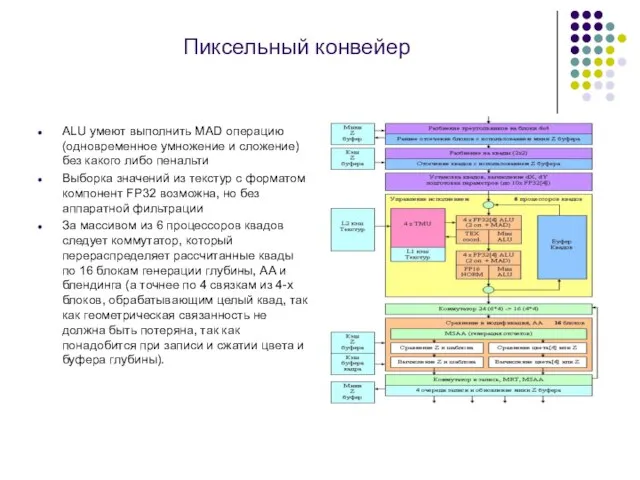
Слайд 12Пиксельный конвейер
ALU умеют выполнить MAD операцию (одновременное умножение и сложение) без
Пиксельный конвейер
ALU умеют выполнить MAD операцию (одновременное умножение и сложение) без
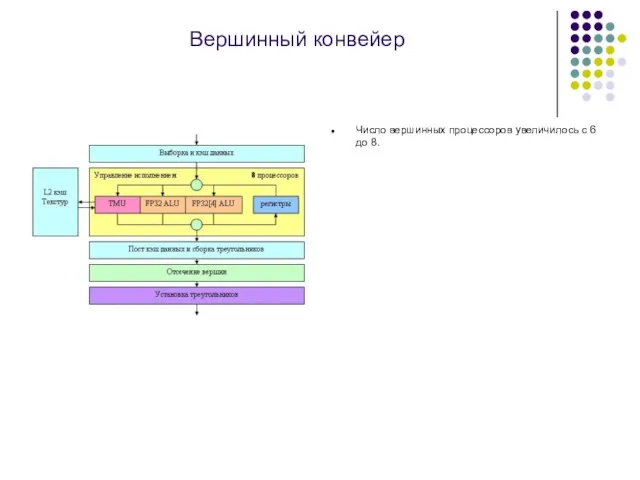
Слайд 13Вершинный конвейер
Число вершинных процессоров увеличилось с 6 до 8.
Вершинный конвейер
Число вершинных процессоров увеличилось с 6 до 8.
Слайд 14Форматы данных, с которыми работает ускоритель
VS 3.0 — FP32
PS 3.0
Форматы данных, с которыми работает ускоритель
VS 3.0 — FP32
PS 3.0

Слайд 15Унифицированная архитектура
Унифицированная архитектура

Слайд 16Графический ускоритель GeForce 8800
Унифицированная архитектура (массив общих процессоров для потоковой обработки вершин
Графический ускоритель GeForce 8800
Унифицированная архитектура (массив общих процессоров для потоковой обработки вершин

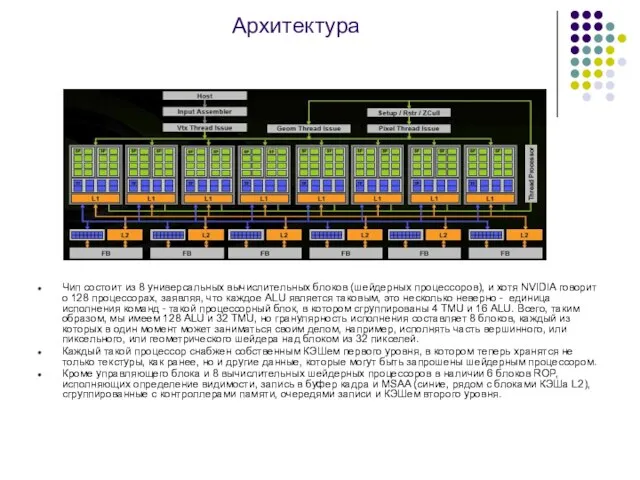
Слайд 17Архитектура
Чип состоит из 8 универсальных вычислительных блоков (шейдерных процессоров), и хотя NVIDIA
Архитектура
Чип состоит из 8 универсальных вычислительных блоков (шейдерных процессоров), и хотя NVIDIA
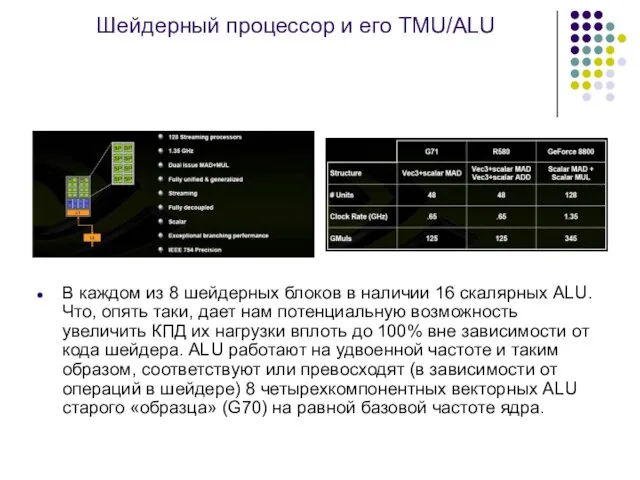
Слайд 18Шейдерный процессор и его TMU/ALU
В каждом из 8 шейдерных блоков в
Шейдерный процессор и его TMU/ALU
В каждом из 8 шейдерных блоков в
Слайд 19ALU
Операция выборки и фильтрации текстур не требует ресурсов ALU и может
ALU
Операция выборки и фильтрации текстур не требует ресурсов ALU и может

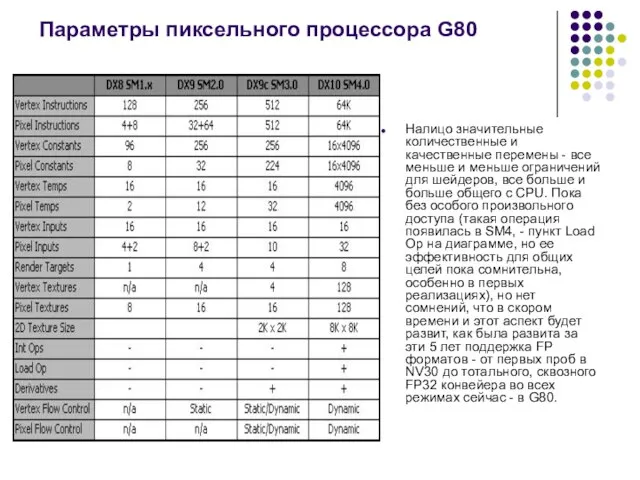
Слайд 20Параметры пиксельного процессора G80
Налицо значительные количественные и качественные перемены - все меньше
Параметры пиксельного процессора G80
Налицо значительные количественные и качественные перемены - все меньше
Слайд 21Текстурные модули(TMU)
В наличии 4 модуля для адресации текстур TA (определения по координатам
Текстурные модули(TMU)
В наличии 4 модуля для адресации текстур TA (определения по координатам

Слайд 22Блоки ROP, запись в буфер кадра, сглаживание
полноценная поддержка FP32 и FP16 форматов
Блоки ROP, запись в буфер кадра, сглаживание
полноценная поддержка FP32 и FP16 форматов

Слайд 23NVIO
В нем интегрированы:
2 * 400 МГц RAMDAC
2 * Dual Link DVI
NVIO
В нем интегрированы:
2 * 400 МГц RAMDAC
2 * Dual Link DVI
 Presentation Title
Presentation Title  Увлечение рыбалкой
Увлечение рыбалкой Презентация на тему Понятие и виды государственных служащих
Презентация на тему Понятие и виды государственных служащих  Сад камней
Сад камней Имя прилагательное
Имя прилагательное Presentation Title
Presentation Title  Музыкальный клип Milka-Медленно
Музыкальный клип Milka-Медленно ТЕОРИЯ ФОТОЭФФЕКТА.ПРИМЕНЕНИЕ ФОТОЭФФЕКТА.
ТЕОРИЯ ФОТОЭФФЕКТА.ПРИМЕНЕНИЕ ФОТОЭФФЕКТА. По знаменитым местам мира
По знаменитым местам мира Бизнес-проект Б1Б2Б3 Банк Конечный спрос 111 10 111213,214,2 15,6 Сумма кредитов: 36,2 10% Сырье, материалы, условия производства 16,6.
Бизнес-проект Б1Б2Б3 Банк Конечный спрос 111 10 111213,214,2 15,6 Сумма кредитов: 36,2 10% Сырье, материалы, условия производства 16,6. Что нам стоит сайт построить?
Что нам стоит сайт построить? Задачи в жизненных ситуациях
Задачи в жизненных ситуациях Описание Фундамент: длина 12м ширина12м высота 2,7м Плита низ – ширина 30 см Плита вверх – ширина 30 см Стены по периметру – ширина 50 см
Описание Фундамент: длина 12м ширина12м высота 2,7м Плита низ – ширина 30 см Плита вверх – ширина 30 см Стены по периметру – ширина 50 см  Исследование двухэтапного алгоритма поиска навигационного сигнала
Исследование двухэтапного алгоритма поиска навигационного сигнала Портфолио учителя
Портфолио учителя Русская народная вышивка
Русская народная вышивка Презентация на тему Конфликты в школе
Презентация на тему Конфликты в школе Сегментирование рынка
Сегментирование рынка  Презентация на тему Атмосфера: значение, строение
Презентация на тему Атмосфера: значение, строение Classification of sounds
Classification of sounds Культура Руси в 10 – 13 веках
Культура Руси в 10 – 13 веках Лепка из солёного теста
Лепка из солёного теста Etron - справжня сила енергії
Etron - справжня сила енергії Доброта, красота и гармония
Доброта, красота и гармония Lektsia_3_1_opredelenie_prochnosti_kirpicha_i_metalla_ispytania_Avtosokhranennyi_774
Lektsia_3_1_opredelenie_prochnosti_kirpicha_i_metalla_ispytania_Avtosokhranennyi_774 "Петербургские повести" Н.В. Гоголя
"Петербургские повести" Н.В. Гоголя Устав. Общие положения
Устав. Общие положения Нейронные сети
Нейронные сети