- Информационный поиск:модели и методы

Содержание
- 2. Информационный поиск (ИП) Цель: удовлетворить информационные потребности пользователя Обсуждаемые темы: Модели ИП Критерии оценки качества поиска
- 3. Модель ИП: Логическое представление документов Логическое представление запросов Framework моделирования представлений документов и запросов, их взаимосвязей
- 4. Классификация моделей Булева модель (теория множеств и булева алгебра) Векторная модель (векторные пространства и линейная алгебра)
- 5. Булевы модели Модель на нечетких множествах (с термом запроса ассоциировано нечеткое множество документов) Расширенная булева модель
- 6. Векторные модели Обобщенная векторная модель (учет корреляции между термами) Латентно-семантический анализ (отображение документов и запросов в
- 7. Вычисление весов термов Частота терма в документе Обратная частота термов в коллекции Вычисление весов
- 8. Нормализация весов Преимущества длинных документов: Больше различных термов Выше частоты термов Методы нормализации: по максимальной частоте
- 9. Вероятностные модели Вероятностный принцип Оценить вероятность того, что документ будет интересен пользователю Модель сетей вывода (inference
- 10. Моделирование языка Zipf’s Law Heaps’ Law Слова F V Размер текста
- 11. Предварительная обработка текста Лексический анализ Исключение стоп-слов Выделение основ слов (stemming) Выбор термов для индексирования (например
- 12. Языки запросов Запросы по ключевым словам однословные контекстные логические на естественном языке Запросы по шаблонам Протоколы
- 13. Уточнение запросов: Изменение весов термов запроса Добавление новых термов в запрос Основные подходы: Обратная связь (Relevance
- 14. Критерии оценки Точность Полнота Процент мусора A R S
- 15. Критерии оценки (2) Средняя точность Интерполяция По числу документов P@20, P@50, p@100
- 16. Критерии оценки (3) Точность на уровне обнаружения заданного числа релевантных документов Точность среди первых R возвращенных,
- 17. Критерии оценки (4) Среднее гармоническое (b = 1) (компромисс между точностью и полнотой) E-мера (учет предпочтений
- 18. Критерии оценки (5) Пользовательские критерии: Коэффициент покрытия (процент уже известного среди найденного) Коэффициент новизны (отношение нового
- 19. Особенности поиска в Интернет Огромный размер > 1 миллиарда документов (февраль 2000) > 75 миллионов узлов
- 20. Размер поисковых систем
- 21. Оценка качества индекса Не все страницы одинаково важны Метрики Суммарная значимость всех страниц Средняя значимость страниц
- 22. TREC и Web Коллекция VLC2: 100Гб, 18.5 миллионов документов Короткие запросы из TREC (2.5 слова) 5
- 23. Задачи ИП в Интернет Обнаружение дубликатов Интеллектуальные сетевые роботы Борьба с опечатками Levenshtein(survey, surgery) = 2
- 24. Классификация типов копий Повторение содержания (1) и структуры (2)
- 25. Оценка повторения структуры Построение описаний URL yahoo.com/ref/art/news.htm (yahoo,com) (ref, art, 0) (art, news, 1) (news, htm,
- 26. Оценка повторения содержания Выбор страниц для проверки Проверка на полную идентичность Вычисление оценки близости: S(A) —
- 27. Сетевые роботы Области применения: Построение индексов Сбор статистики Поиск ресурсов Исследование структуры Интернет Проверка целостности ссылок
- 28. Поиск по значимости Дополнение к оценкам близости Значимость не зависит от запроса Значимость бывает не только
- 29. Значимость из содержимого Анализ документа (PHOAKS, определение жанра текста) Анализ коллекции (Google, SCAM, PHOAKS) Информационный контекст
- 30. Значимость из действий Явные указания: Обратная связь (групповая) Триггеры на данные (почтовые фильтры) Синтезированные фильтры (пользователь
- 31. Значимость из действий (2) Неявные указания: Коллективное поведение пользователей (WebWatcher, Hotbot) Индивидуальное поведение пользователя Какие документы/коллекции
- 33. Скачать презентацию
Слайд 2Информационный поиск (ИП)
Цель: удовлетворить информационные потребности пользователя
Обсуждаемые темы:
Модели ИП
Критерии оценки качества поиска
Поиск
Информационный поиск (ИП)
Цель: удовлетворить информационные потребности пользователя
Обсуждаемые темы:
Модели ИП
Критерии оценки качества поиска
Поиск

Слайд 3Модель ИП:
Логическое представление документов
Логическое представление запросов
Framework моделирования представлений документов и запросов, их
Модель ИП:
Логическое представление документов
Логическое представление запросов
Framework моделирования представлений документов и запросов, их

Слайд 4Классификация моделей
Булева модель
(теория множеств и булева алгебра)
Векторная модель
(векторные пространства и
Классификация моделей
Булева модель
(теория множеств и булева алгебра)
Векторная модель
(векторные пространства и

Слайд 5Булевы модели
Модель на нечетких множествах
(с термом запроса ассоциировано нечеткое множество документов)
Расширенная булева
Булевы модели
Модель на нечетких множествах
(с термом запроса ассоциировано нечеткое множество документов)
Расширенная булева

Слайд 6Векторные модели
Обобщенная векторная модель
(учет корреляции между термами)
Латентно-семантический анализ
(отображение документов и запросов
Векторные модели
Обобщенная векторная модель
(учет корреляции между термами)
Латентно-семантический анализ
(отображение документов и запросов

Слайд 7Вычисление весов термов
Частота терма в документе
Обратная частота термов в коллекции
Вычисление весов
Вычисление весов термов
Частота терма в документе
Обратная частота термов в коллекции
Вычисление весов

Слайд 8Нормализация весов
Преимущества длинных документов:
Больше различных термов
Выше частоты термов
Методы нормализации:
по максимальной частоте
по длине
Нормализация весов
Преимущества длинных документов:
Больше различных термов
Выше частоты термов
Методы нормализации:
по максимальной частоте
по длине

Слайд 9Вероятностные модели
Вероятностный принцип
Оценить вероятность того, что документ будет интересен пользователю
Модель сетей
Вероятностные модели
Вероятностный принцип
Оценить вероятность того, что документ будет интересен пользователю
Модель сетей

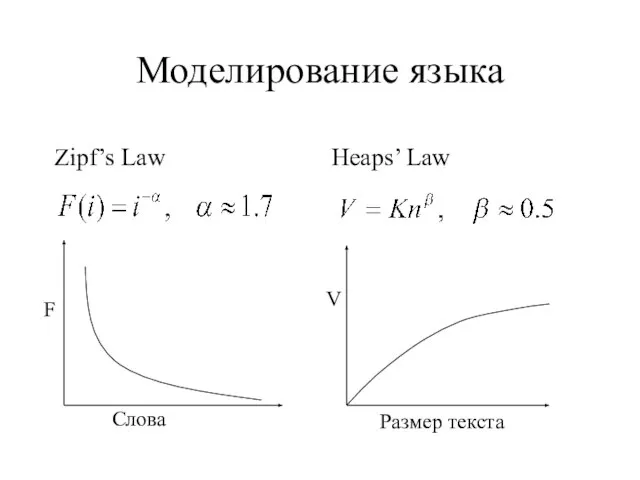
Слайд 10Моделирование языка
Zipf’s Law
Heaps’ Law
Слова
F
V
Размер текста
Моделирование языка
Zipf’s Law
Heaps’ Law
Слова
F
V
Размер текста
Слайд 11Предварительная обработка текста
Лексический анализ
Исключение стоп-слов
Выделение основ слов (stemming)
Выбор термов для индексирования
(например
Предварительная обработка текста
Лексический анализ
Исключение стоп-слов
Выделение основ слов (stemming)
Выбор термов для индексирования
(например

Слайд 12Языки запросов
Запросы по ключевым словам
однословные
контекстные
логические
на естественном языке
Запросы по шаблонам
Протоколы запросов (Z39.50, WAIS)
Языки запросов
Запросы по ключевым словам
однословные
контекстные
логические
на естественном языке
Запросы по шаблонам
Протоколы запросов (Z39.50, WAIS)

Слайд 13Уточнение запросов:
Изменение весов термов запроса
Добавление новых термов в запрос
Основные подходы:
Обратная связь (Relevance
Уточнение запросов:
Изменение весов термов запроса
Добавление новых термов в запрос
Основные подходы:
Обратная связь (Relevance

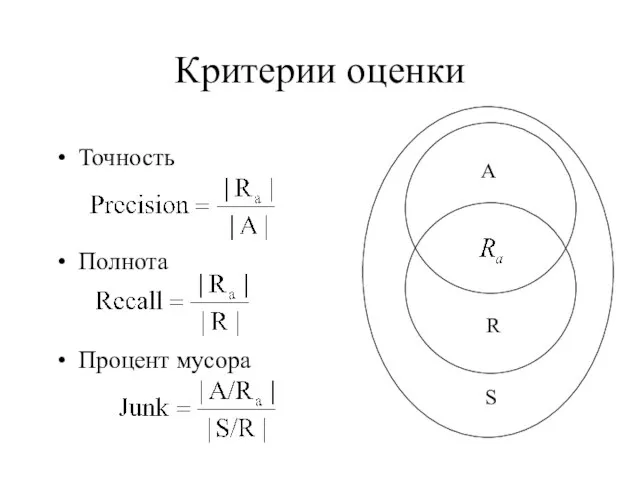
Слайд 14Критерии оценки
Точность
Полнота
Процент мусора
A
R
S
Критерии оценки
Точность
Полнота
Процент мусора
A
R
S
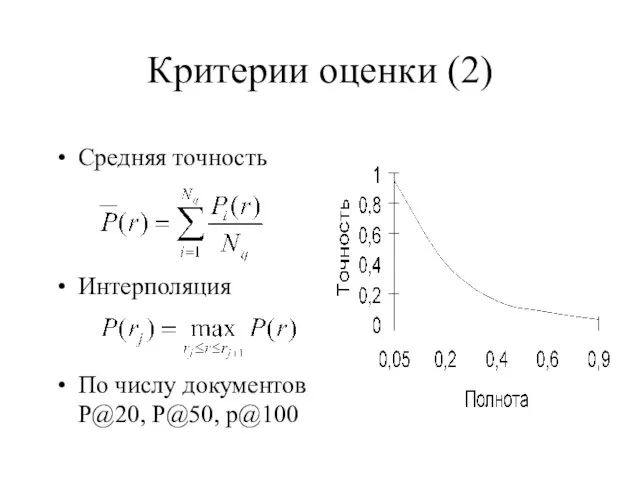
Слайд 15Критерии оценки (2)
Средняя точность
Интерполяция
По числу документов
P@20, P@50, p@100
Критерии оценки (2)
Средняя точность
Интерполяция
По числу документов
P@20, P@50, p@100
Слайд 16Критерии оценки (3)
Точность на уровне обнаружения заданного числа релевантных документов
Точность среди первых
Критерии оценки (3)
Точность на уровне обнаружения заданного числа релевантных документов
Точность среди первых

Слайд 17Критерии оценки (4)
Среднее гармоническое (b = 1)
(компромисс между точностью и полнотой)
E-мера
(учет
Критерии оценки (4)
Среднее гармоническое (b = 1)
(компромисс между точностью и полнотой)
E-мера
(учет

Слайд 18Критерии оценки (5)
Пользовательские критерии:
Коэффициент покрытия
(процент уже известного среди найденного)
Коэффициент новизны
(отношение нового к
Критерии оценки (5)
Пользовательские критерии:
Коэффициент покрытия
(процент уже известного среди найденного)
Коэффициент новизны
(отношение нового к

Слайд 19Особенности поиска в Интернет
Огромный размер
> 1 миллиарда документов (февраль 2000)
> 75 миллионов
Особенности поиска в Интернет
Огромный размер > 1 миллиарда документов (февраль 2000) > 75 миллионов

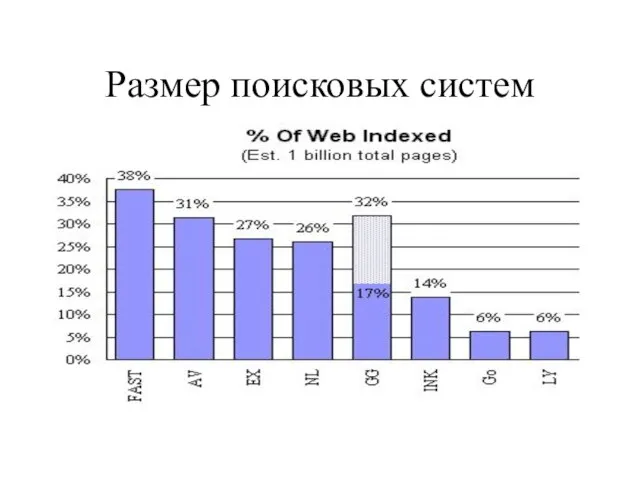
Слайд 20Размер поисковых систем
Размер поисковых систем
Слайд 21Оценка качества индекса
Не все страницы одинаково важны
Метрики
Суммарная значимость всех страниц
Средняя значимость страниц
Оценка качества индекса
Не все страницы одинаково важны
Метрики
Суммарная значимость всех страниц
Средняя значимость страниц

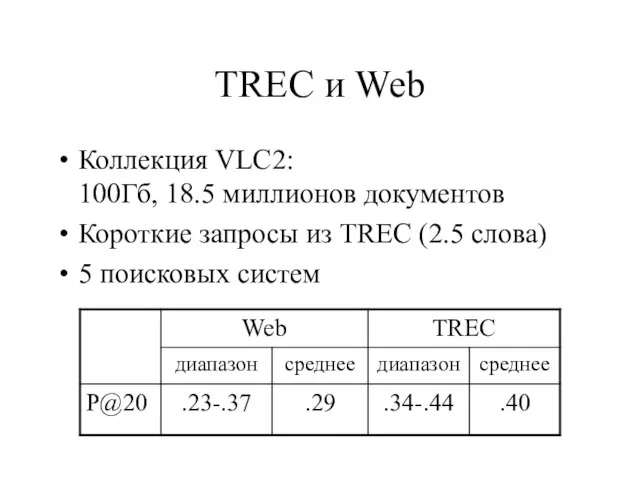
Слайд 22TREC и Web
Коллекция VLC2:
100Гб, 18.5 миллионов документов
Короткие запросы из TREC (2.5
TREC и Web
Коллекция VLC2:
100Гб, 18.5 миллионов документов
Короткие запросы из TREC (2.5
Слайд 23Задачи ИП в Интернет
Обнаружение дубликатов
Интеллектуальные сетевые роботы
Борьба с опечатками
Levenshtein(survey, surgery) = 2
LCS(survey,
Задачи ИП в Интернет
Обнаружение дубликатов
Интеллектуальные сетевые роботы
Борьба с опечатками
Levenshtein(survey, surgery) = 2
LCS(survey,

Слайд 24Классификация типов копий
Повторение содержания (1) и структуры (2)
Классификация типов копий
Повторение содержания (1) и структуры (2)

Слайд 25Оценка повторения структуры
Построение описаний URL
yahoo.com/ref/art/news.htm
(yahoo,com) (ref, art, 0) (art, news, 1) (news,
Оценка повторения структуры
Построение описаний URL yahoo.com/ref/art/news.htm (yahoo,com) (ref, art, 0) (art, news, 1) (news,

Слайд 26Оценка повторения содержания
Выбор страниц для проверки
Проверка на полную идентичность
Вычисление оценки близости:
S(A) —
Оценка повторения содержания
Выбор страниц для проверки
Проверка на полную идентичность
Вычисление оценки близости:
S(A) —

Слайд 27Сетевые роботы
Области применения:
Построение индексов
Сбор статистики
Поиск ресурсов
Исследование структуры Интернет
Проверка целостности ссылок
Стратегии обхода:
Простые
Учет структуры
Сетевые роботы
Области применения:
Построение индексов
Сбор статистики
Поиск ресурсов
Исследование структуры Интернет
Проверка целостности ссылок
Стратегии обхода:
Простые
Учет структуры

Слайд 28Поиск по значимости
Дополнение к оценкам близости
Значимость не зависит от запроса
Значимость бывает не
Поиск по значимости
Дополнение к оценкам близости
Значимость не зависит от запроса
Значимость бывает не

Слайд 29Значимость из содержимого
Анализ документа
(PHOAKS, определение жанра текста)
Анализ коллекции
(Google, SCAM, PHOAKS)
Информационный контекст
(Referral Web)
Внутренние
Значимость из содержимого
Анализ документа
(PHOAKS, определение жанра текста)
Анализ коллекции
(Google, SCAM, PHOAKS)
Информационный контекст
(Referral Web)
Внутренние

Слайд 30Значимость из действий
Явные указания:
Обратная связь
(групповая)
Триггеры на данные
(почтовые фильтры)
Синтезированные фильтры
(пользователь задает
Значимость из действий
Явные указания:
Обратная связь
(групповая)
Триггеры на данные
(почтовые фильтры)
Синтезированные фильтры
(пользователь задает

Слайд 31Значимость из действий (2)
Неявные указания:
Коллективное поведение пользователей
(WebWatcher, Hotbot)
Индивидуальное поведение пользователя
Какие документы/коллекции
Значимость из действий (2)
Неявные указания:
Коллективное поведение пользователей
(WebWatcher, Hotbot)
Индивидуальное поведение пользователя
Какие документы/коллекции

 Подготовка к сражению В ходе зимнего наступления Красной армии и последовавшего контрнаступления вермахта на Восточной Украине в
Подготовка к сражению В ходе зимнего наступления Красной армии и последовавшего контрнаступления вермахта на Восточной Украине в Редактирование компьютерного рисунка
Редактирование компьютерного рисунка Построение чертежа пижамных брюк
Построение чертежа пижамных брюк СИСТЕМА ДИСТАНЦИОННОГО ОБУЧЕНИЯ Руководство пользователя (для студентов РГГУ) УРР РГГУ 2011
СИСТЕМА ДИСТАНЦИОННОГО ОБУЧЕНИЯ Руководство пользователя (для студентов РГГУ) УРР РГГУ 2011 самоменеджмент Занятие 1 (1)
самоменеджмент Занятие 1 (1) Право Франции. Понятие и виды обязательств. Условия действительности договора
Право Франции. Понятие и виды обязательств. Условия действительности договора Разработка SiC автоэмиттеров
Разработка SiC автоэмиттеров Презентация на тему Цвета
Презентация на тему Цвета Тренажер для подготовки к ГИА по обществознанию. 9 класс. Задание В1
Тренажер для подготовки к ГИА по обществознанию. 9 класс. Задание В1 Презентация на тему Гражданские правоотношения (9 класс)
Презентация на тему Гражданские правоотношения (9 класс) Презентация на тему Что из чего сделано
Презентация на тему Что из чего сделано  Дарвин Чарлз Роберт
Дарвин Чарлз Роберт У Ч Е Т А Р Е Н Д Ы
У Ч Е Т А Р Е Н Д Ы Пословицы, поговорки и загадки о воде.
Пословицы, поговорки и загадки о воде. Улыбнись - 2!
Улыбнись - 2! 王磐 朝天子·咏喇叭 阿廖娜
王磐 朝天子·咏喇叭 阿廖娜 Презентация на тему Тип Иглокожие
Презентация на тему Тип Иглокожие Разработка сервиса для поддержки принятия решения при оценке производственных прототипов
Разработка сервиса для поддержки принятия решения при оценке производственных прототипов Английский в рифмах. Профессии
Английский в рифмах. Профессии Животный мир
Животный мир Let's travel
Let's travel Hummer. История фирмы
Hummer. История фирмы Светочувствительные устройства
Светочувствительные устройства Чего хочет Ваш мозг?
Чего хочет Ваш мозг? Всероссийские конкурсы
Всероссийские конкурсы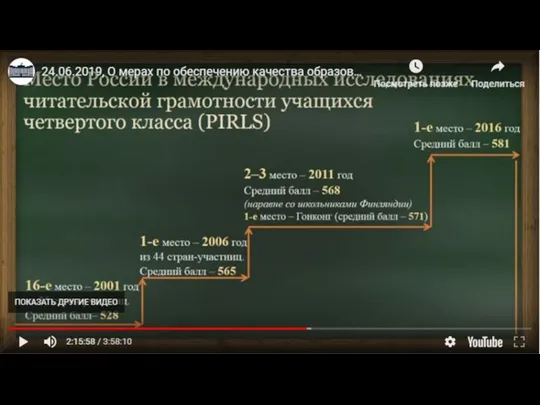 Место России в международных исследованиях читательской грамотности учащихся четвертого класса
Место России в международных исследованиях читательской грамотности учащихся четвертого класса Ауыр түсті металдар
Ауыр түсті металдар  Астафьев "Васюткино озеро": Человек и природа, или уроки мудрости и доброты
Астафьев "Васюткино озеро": Человек и природа, или уроки мудрости и доброты