- Как Map/Reduce спас Яндекс.Статистику

Содержание
- 2. Background Взрывной рост объема данных, за 8 лет объем дневных данных вырос в 2000 раз с
- 3. Рождение – 2001 год Яндекс – start-up На все 1 сервер БД 400ГБ, 2ГБ данных в
- 4. Архитектура v.1
- 5. Первые шаги Рост данных, новые проекты и отчеты Из-за падения базы бывает не успеваем пересчитать отчеты
- 6. Архитектура v.2
- 7. Активный рост Рост данных и требований продолжается Вынуждены использовать NAS как хранилище для БД, появляется новое
- 8. Архитектура v.3
- 9. Старость Сеть между NAS и БД постоянно перегружена Тяжелые запросы очень плохо используют больше одной машины,
- 10. Архитектура v.4
- 11. Смерть Рост данных продолжился Большие отчетам уже не хватает ресурсов, их расчет может занимать до нескольких
- 12. Бабах
- 13. Что такое Map/Reduce? Map/Reduce это технология, упрощающая написание приложений, для параллельной обработки больших объемов данных на
- 14. Что есть в Map/Reduce? Линейное масштабирование по объему данных и скорости обработки Хранилище неструктурированных данных Простота
- 15. Чего нет в Map/Reduce? Типов данных Индексов Партицирования Проверок целостности
- 16. Map/Reduce Схема Работы
- 17. Что такое MapReduce? Данные С точки зрения пользователя данные - это таблицы. Каждая запись в таблице
- 18. Второе рождение Добавляем Map/Reduce хранилище логов Переносим все тяжелые отчеты в Map/Reduce База только для быстрых
- 19. Архитектура v.5
- 20. Резюме Что бы выдержать рост данных необходимо выносить обработку и хранение больших данных в Map/Reduce БД
- 22. Скачать презентацию

Слайд 3Рождение – 2001 год
Яндекс – start-up
На все 1 сервер
БД 400ГБ, 2ГБ данных
Рождение – 2001 год
Яндекс – start-up
На все 1 сервер
БД 400ГБ, 2ГБ данных

Слайд 4Архитектура v.1
Архитектура v.1
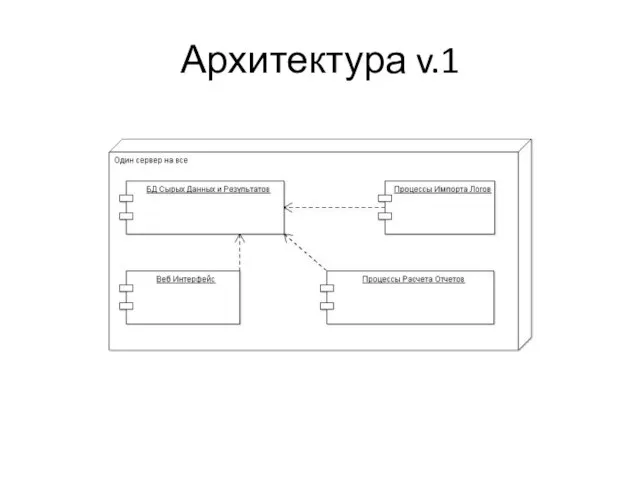
Слайд 5Первые шаги
Рост данных, новые проекты и отчеты
Из-за падения базы бывает не успеваем
Первые шаги
Рост данных, новые проекты и отчеты
Из-за падения базы бывает не успеваем

Слайд 6Архитектура v.2
Архитектура v.2
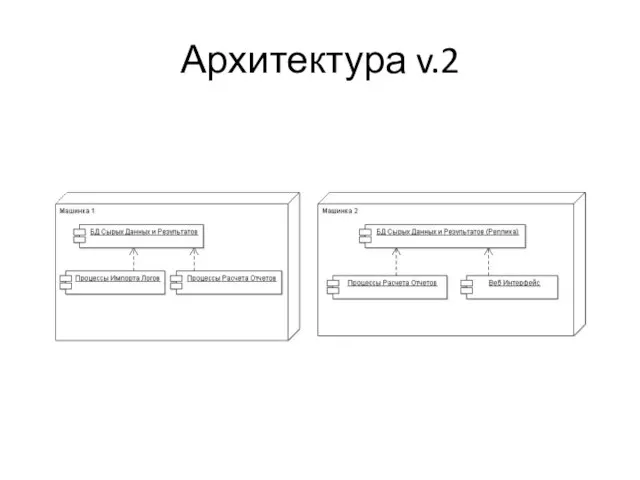
Слайд 7Активный рост
Рост данных и требований продолжается
Вынуждены использовать NAS как хранилище для БД,
Активный рост
Рост данных и требований продолжается
Вынуждены использовать NAS как хранилище для БД,

Слайд 8Архитектура v.3
Архитектура v.3
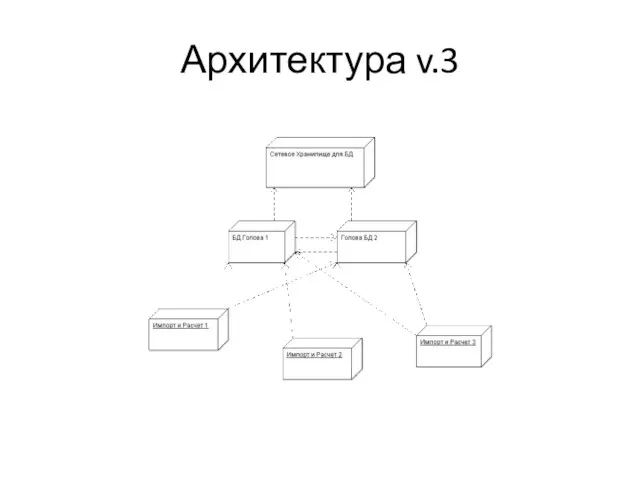
Слайд 9Старость
Сеть между NAS и БД постоянно перегружена
Тяжелые запросы очень плохо используют больше
Старость
Сеть между NAS и БД постоянно перегружена
Тяжелые запросы очень плохо используют больше

Слайд 10Архитектура v.4
Архитектура v.4
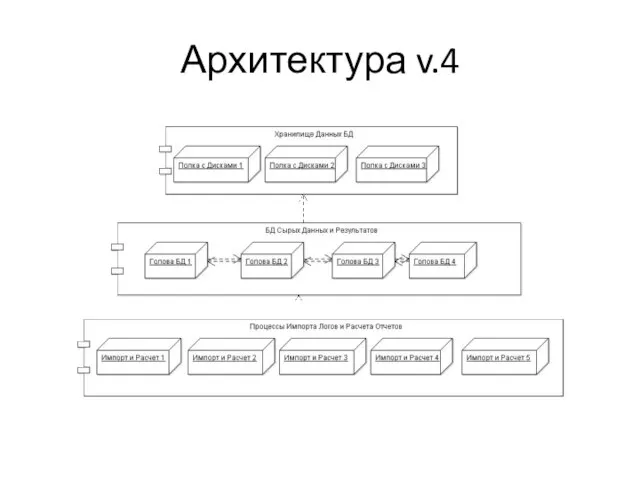
Слайд 11Смерть
Рост данных продолжился
Большие отчетам уже не хватает ресурсов, их расчет может занимать
Смерть
Рост данных продолжился
Большие отчетам уже не хватает ресурсов, их расчет может занимать

Слайд 12Бабах
Бабах
Слайд 13Что такое Map/Reduce?
Map/Reduce это технология, упрощающая написание приложений, для параллельной обработки больших объемов данных
Что такое Map/Reduce?
Map/Reduce это технология, упрощающая написание приложений, для параллельной обработки больших объемов данных

Слайд 14Что есть в Map/Reduce?
Линейное масштабирование по объему данных и скорости обработки
Хранилище неструктурированных
Что есть в Map/Reduce?
Линейное масштабирование по объему данных и скорости обработки
Хранилище неструктурированных

Слайд 15Чего нет в Map/Reduce?
Типов данных
Индексов
Партицирования
Проверок целостности
Чего нет в Map/Reduce?
Типов данных
Индексов
Партицирования
Проверок целостности

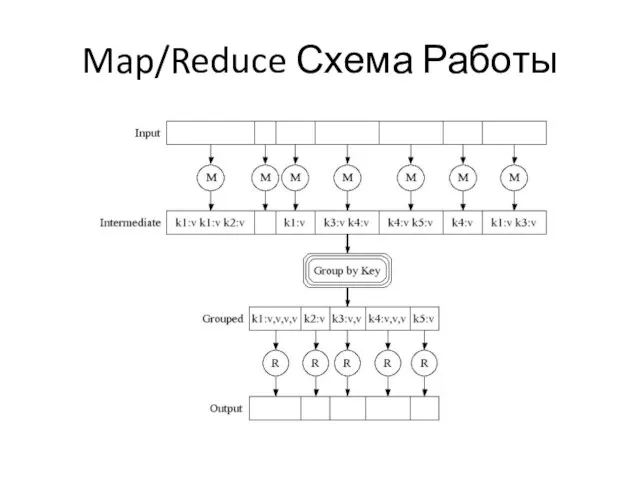
Слайд 16Map/Reduce Схема Работы
Map/Reduce Схема Работы
Слайд 17Что такое MapReduce?
Данные
С точки зрения пользователя данные - это таблицы.
Каждая запись в таблице
Что такое MapReduce?
Данные
С точки зрения пользователя данные - это таблицы.
Каждая запись в таблице

Слайд 18Второе рождение
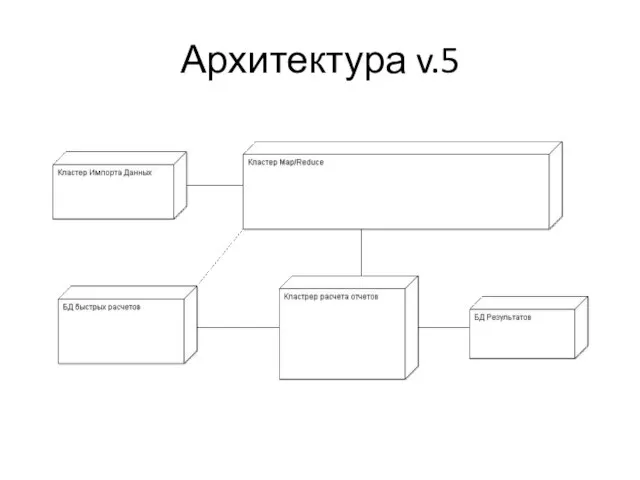
Добавляем Map/Reduce хранилище логов
Переносим все тяжелые отчеты в Map/Reduce
База только для
Второе рождение
Добавляем Map/Reduce хранилище логов
Переносим все тяжелые отчеты в Map/Reduce
База только для

Слайд 19Архитектура v.5
Архитектура v.5
Слайд 20Резюме
Что бы выдержать рост данных необходимо выносить обработку и хранение больших данных
Резюме
Что бы выдержать рост данных необходимо выносить обработку и хранение больших данных

 Международный спутниковый канал Интер+
Международный спутниковый канал Интер+ Проблемы и парадоксы введения ФГОС начального и основного общего образования
Проблемы и парадоксы введения ФГОС начального и основного общего образования Уважаемые собственники бизнеса, руководители предприятий! Мы поможем Вам провести: - логистический аудит и консультирование; - опт
Уважаемые собственники бизнеса, руководители предприятий! Мы поможем Вам провести: - логистический аудит и консультирование; - опт Презентация на тему Подготовка к сочинению-рассуждению (поле С)
Презентация на тему Подготовка к сочинению-рассуждению (поле С) Занятие № 1: Организация, вооружение и военная техника взвода
Занятие № 1: Организация, вооружение и военная техника взвода Antibiotic (Антибиотики)
Antibiotic (Антибиотики) Школьная форма
Школьная форма Портфолио студента
Портфолио студента Домашние опасности (2 класс)
Домашние опасности (2 класс) Пенсионные фонды, способы формирования и назначение
Пенсионные фонды, способы формирования и назначение Волшебная принцесса
Волшебная принцесса Distributed Version Control Systems
Distributed Version Control Systems Изображение и реальность
Изображение и реальность Возрастные особенности интеллектуального развития учащихся начальной школы
Возрастные особенности интеллектуального развития учащихся начальной школы  Проект«Создание элективного курса по географии для предпрофильной подготовки учащихся 9 классов».
Проект«Создание элективного курса по географии для предпрофильной подготовки учащихся 9 классов». Католическая церковь: путь к вершине могущества
Католическая церковь: путь к вершине могущества Рельеф Южной Америки
Рельеф Южной Америки Метод проектов: общие положения. Проектная и исследовательская деятельность: сходство и различие
Метод проектов: общие положения. Проектная и исследовательская деятельность: сходство и различие Управленческий учет (лекции)
Управленческий учет (лекции) Александр Иванович Куприн
Александр Иванович Куприн Урок на тему : «Исследование функции с помощью производной»с использованием компьютерных технологийУчитель математики Бахт
Урок на тему : «Исследование функции с помощью производной»с использованием компьютерных технологийУчитель математики Бахт Закономерности управления персоналом
Закономерности управления персоналом 1 2 На протяжении 60 лет ISKRAEMECO является одним из мировых лидеров в области производства приборов и систем учета. На сегодняшний день I
1 2 На протяжении 60 лет ISKRAEMECO является одним из мировых лидеров в области производства приборов и систем учета. На сегодняшний день I Презентация на тему Образование и философия
Презентация на тему Образование и философия  Сертификация продукции
Сертификация продукции ДО АВГУСТА 2008
ДО АВГУСТА 2008 Железнодорожные перевозки по всей России!
Железнодорожные перевозки по всей России! Микены и Троя. История Древнего мира
Микены и Троя. История Древнего мира