- Конструкции для синхронизации нитей

Содержание
- 2. Москва, 2009 г. Параллельное программирование с OpenMP: Конструкции для синхронизации нитей © Бахтин В.А. из 26
- 3. из 26 #pragma omp master структурный блок /*Структурный блок будет выполнен MASTER-нитью группы. По завершении выполнения
- 4. из 26 При взаимодействии через общую память нити должны синхронизовать свое выполнение. int i=0; #pragma omp
- 5. из 26 Решение проблемы взаимного исключения должно удовлетворять требованиям: в любой момент времени только одна нить
- 6. Вычисление числа π из 26 Москва, 2009 г. Параллельное программирование с OpenMP: Конструкции для синхронизации нитей
- 7. из 26 #include int main () { int n =100000, i; double pi, h, sum, x;
- 8. из 26 #include #include int main () { int n =100000, i; double pi, h, sum,
- 9. из 26 int from_ list(float *a, int type); void work(int i, float *a); void example ()
- 10. из 26 #pragma omp atomic expression-stmt где expression-stmt: x binop= expr x++ ++x x-- --x Здесь
- 11. из 26 #include #include int main () { int n =100000, i; double pi, h, sum,
- 12. из 26 Концепцию семафоров описал Дейкстра (Dijkstra) в 1965 Семафор - неотрицательная целая переменная, которая может
- 13. из 26 Состояния семафора: uninitialized unlocked locked void omp_init_lock(omp_lock_t *lock); /* uninitialized to unlocked*/ void omp_destroy_lock(omp_lock_t
- 14. из 26 #include int main () { int n =100000, i; double pi, h, sum, x;
- 15. из 26 #include #include int main() { omp_lock_t lck; int id; omp_init_lock(&lck); #pragma omp parallel shared(lck)
- 16. из 26 #include typedef struct { int a,b; omp_lock_t lck; } pair; void incr_a(pair *p, int
- 17. из 26 #include typedef struct { int a,b; omp_nest_lock_t lck; } pair; void incr_a(pair *p, int
- 18. из 26 Точка в программе, достижимая всеми нитями группы, в которой выполнение программы приостанавливается до тех
- 19. из 26 void work(int i, int j) {} void wrong(int n) { #pragma omp parallel default(shared)
- 20. из 26 void work(int i, int j) {} void wrong(int n) { #pragma omp parallel default(shared)
- 21. из 26 void work(int i, int j) {} void wrong(int n) { #pragma omp parallel default(shared)
- 22. из 26 #pragma omp taskwait int fibonacci(int n) { int i, j; if (n return n;
- 23. из 26 #pragma omp flush [(список переменных)] По умолчанию все переменные приводятся в консистентное состояние (#pragma
- 24. из 26 Спасибо за внимание! Вопросы? Москва, 2009 г. Параллельное программирование с OpenMP: Конструкции для синхронизации
- 25. из 26 Система поддержки выполнения OpenMP-программ. Переменные окружения, управляющие выполнением OpenMP-программы. Следующая тема Москва, 2009 г.
- 27. Скачать презентацию
Слайд 2Москва, 2009 г.
Параллельное программирование с OpenMP: Конструкции для синхронизации нитей © Бахтин
Москва, 2009 г.
Параллельное программирование с OpenMP: Конструкции для синхронизации нитей © Бахтин

Слайд 3 из 26
#pragma omp master
структурный блок
/*Структурный блок будет выполнен MASTER-нитью группы.
из 26
#pragma omp master
структурный блок
/*Структурный блок будет выполнен MASTER-нитью группы.

Слайд 4 из 26
При взаимодействии через общую память нити должны синхронизовать свое выполнение.
из 26
При взаимодействии через общую память нити должны синхронизовать свое выполнение.

Слайд 5 из 26
Решение проблемы взаимного исключения должно удовлетворять требованиям:
в любой момент
из 26
Решение проблемы взаимного исключения должно удовлетворять требованиям:
в любой момент

Слайд 6Вычисление числа π
из 26
Москва, 2009 г.
Параллельное программирование с OpenMP: Конструкции для
Вычисление числа π
из 26
Москва, 2009 г.
Параллельное программирование с OpenMP: Конструкции для
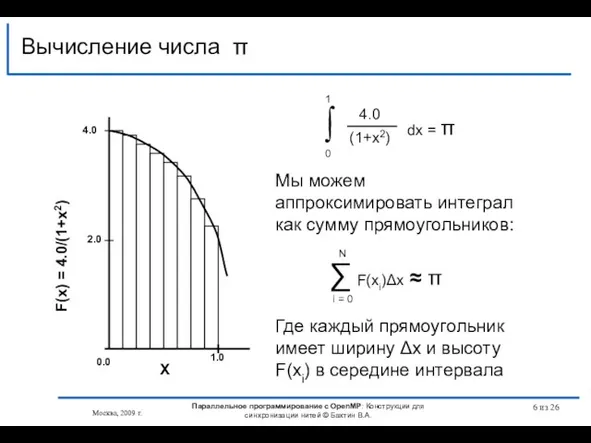
Слайд 7 из 26
#include
int main ()
{
int n =100000, i;
double pi,
из 26
#include
int main ()
{
int n =100000, i;
double pi,

Слайд 8 из 26
#include
#include
int main ()
{
int n =100000, i;
double
из 26
#include
#include
int main ()
{
int n =100000, i;
double

Слайд 9 из 26
int from_ list(float *a, int type);
void work(int i, float *a);
void
из 26
int from_ list(float *a, int type);
void work(int i, float *a);
void

Слайд 10 из 26
#pragma omp atomic
expression-stmt
где expression-stmt:
x binop= expr
x++
++x
x--
--x
Здесь х – скалярная переменная,
из 26
#pragma omp atomic
expression-stmt
где expression-stmt:
x binop= expr
x++
++x
x--
--x
Здесь х – скалярная переменная,

Слайд 11 из 26
#include
#include
int main ()
{
int n =100000, i;
double
из 26
#include
#include
int main ()
{
int n =100000, i;
double

Слайд 12 из 26
Концепцию семафоров описал Дейкстра (Dijkstra) в 1965
Семафор - неотрицательная
из 26
Концепцию семафоров описал Дейкстра (Dijkstra) в 1965
Семафор - неотрицательная

Слайд 13 из 26
Состояния семафора:
uninitialized
unlocked
locked
void omp_init_lock(omp_lock_t *lock); /* uninitialized to unlocked*/
void omp_destroy_lock(omp_lock_t *lock);
из 26
Состояния семафора:
uninitialized
unlocked
locked
void omp_init_lock(omp_lock_t *lock); /* uninitialized to unlocked*/
void omp_destroy_lock(omp_lock_t *lock);

Слайд 14 из 26
#include
int main ()
{
int n =100000, i;
double pi,
из 26
#include
int main ()
{
int n =100000, i;
double pi,

Слайд 15 из 26
#include
#include
int main()
{
omp_lock_t lck;
int id;
omp_init_lock(&lck);
#pragma
из 26
#include
#include
int main()
{
omp_lock_t lck;
int id;
omp_init_lock(&lck);
#pragma

Слайд 16 из 26
#include
typedef struct {
int a,b;
omp_lock_t lck; } pair;
void
из 26
#include
typedef struct {
int a,b;
omp_lock_t lck; } pair;
void

Слайд 17 из 26
#include
typedef struct {
int a,b;
omp_nest_lock_t lck; } pair;
void
из 26
#include
typedef struct {
int a,b;
omp_nest_lock_t lck; } pair;
void

Слайд 18 из 26
Точка в программе, достижимая всеми нитями группы, в которой выполнение
из 26
Точка в программе, достижимая всеми нитями группы, в которой выполнение

Слайд 19 из 26
void work(int i, int j) {}
void wrong(int n)
{
#pragma omp parallel
из 26
void work(int i, int j) {}
void wrong(int n)
{
#pragma omp parallel

Слайд 20 из 26
void work(int i, int j) {}
void wrong(int n)
{
#pragma omp parallel
из 26
void work(int i, int j) {}
void wrong(int n)
{
#pragma omp parallel

Слайд 21 из 26
void work(int i, int j) {}
void wrong(int n)
{
#pragma omp parallel
из 26
void work(int i, int j) {}
void wrong(int n)
{
#pragma omp parallel

Слайд 22 из 26
#pragma omp taskwait
int fibonacci(int n) {
int i, j;
if
из 26
#pragma omp taskwait
int fibonacci(int n) {
int i, j;
if

Слайд 23 из 26
#pragma omp flush [(список переменных)]
По умолчанию все переменные приводятся в
из 26
#pragma omp flush [(список переменных)]
По умолчанию все переменные приводятся в
![из 26 #pragma omp flush [(список переменных)] По умолчанию все переменные приводятся](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/397879/slide-22.jpg)
Слайд 24 из 26
Спасибо за внимание!
Вопросы?
Москва, 2009 г.
Параллельное программирование с OpenMP: Конструкции для
из 26
Спасибо за внимание!
Вопросы?
Москва, 2009 г.
Параллельное программирование с OpenMP: Конструкции для

Слайд 25 из 26
Система поддержки выполнения OpenMP-программ. Переменные окружения, управляющие выполнением OpenMP-программы.
Следующая тема
Москва,
из 26
Система поддержки выполнения OpenMP-программ. Переменные окружения, управляющие выполнением OpenMP-программы.
Следующая тема
Москва,

 Психика человека
Психика человека ВОССТАНОВИТЕЛЬНОЕ ПРАВОСУДИЕ иЮВЕНАЛЬНЫЕ ТЕХНОЛОГИИ в РОССИИ
ВОССТАНОВИТЕЛЬНОЕ ПРАВОСУДИЕ иЮВЕНАЛЬНЫЕ ТЕХНОЛОГИИ в РОССИИ МЕЖВЕДОМСТВЕННОЕ ВЗАИМОДЕЙСТВИЕ ПРИ ОРГАНИЗАЦИИ СЕМЕЙНОГО УСТРОЙСТВА ДЕТЕЙ,ОСТАВШИХСЯБЕЗ ПОПЕЧЕНИЯ РОДИТЕЛЕЙ
МЕЖВЕДОМСТВЕННОЕ ВЗАИМОДЕЙСТВИЕ ПРИ ОРГАНИЗАЦИИ СЕМЕЙНОГО УСТРОЙСТВА ДЕТЕЙ,ОСТАВШИХСЯБЕЗ ПОПЕЧЕНИЯ РОДИТЕЛЕЙ Назначение и структура бизнес-плана
Назначение и структура бизнес-плана Тонкости продвижения интернет-магазиновв поисковых системах
Тонкости продвижения интернет-магазиновв поисковых системах Євроінтеграція України як чинник соціально-економічного розвитку держави. Роль освіти в розвитку партнерства України з іншими де
Євроінтеграція України як чинник соціально-економічного розвитку держави. Роль освіти в розвитку партнерства України з іншими де Особенности модернизации России – процесс взаимодействия инновационного и сырьевого векторов экономики Карпова Анна Владимиров
Особенности модернизации России – процесс взаимодействия инновационного и сырьевого векторов экономики Карпова Анна Владимиров Развитие психики человека
Развитие психики человека Сатиры А.Д.Кантемира
Сатиры А.Д.Кантемира Конкурсный проект смотровой площадки на вершине горы Машук
Конкурсный проект смотровой площадки на вершине горы Машук Вводный инструктаж. Формирование команды
Вводный инструктаж. Формирование команды Новая экономичная система импульсного пневмотранспорта порошкообразных сред
Новая экономичная система импульсного пневмотранспорта порошкообразных сред Подбор конфигурации и модернизация средств вычислительной техники
Подбор конфигурации и модернизация средств вычислительной техники Школьный Художественный музей
Школьный Художественный музей Прикладная геоэкология
Прикладная геоэкология Подвижная игрушка Слоненок
Подвижная игрушка Слоненок Я - мэр города Петрозаводска
Я - мэр города Петрозаводска Презентация на тему Иисус Христос – историческая личность или мифологический герой
Презентация на тему Иисус Христос – историческая личность или мифологический герой Культура Древнего Китая
Культура Древнего Китая Отраслевое административно-правовое регулирование в хозяйственно-экономических комплексах [часть 2]
Отраслевое административно-правовое регулирование в хозяйственно-экономических комплексах [часть 2] Свойства жидкостей, газов и твердых тел в пословицах
Свойства жидкостей, газов и твердых тел в пословицах Презентация на тему Богомол
Презентация на тему Богомол Временное трудоустройство. Подростки
Временное трудоустройство. Подростки Свобода. Уверенность. Выгода.
Свобода. Уверенность. Выгода. Комаров Сергей Приложения для социальных сетей. Использование приложений в качестве рекламных инструментов.
Комаров Сергей Приложения для социальных сетей. Использование приложений в качестве рекламных инструментов. Презентация "Религиозные праздники христиан" - скачать презентации по МХК
Презентация "Религиозные праздники христиан" - скачать презентации по МХК Оценка необходимости и обоснованности внедрения системы CRM в компании АБВ
Оценка необходимости и обоснованности внедрения системы CRM в компании АБВ Искусство быть здоровым.
Искусство быть здоровым.