- Лекция №6. Данные, виды данных(3)

Содержание
- 2. Виды данных в программировании – основополагающее понятие. Классификация данных позволяет определить, где они хранятся, что собой
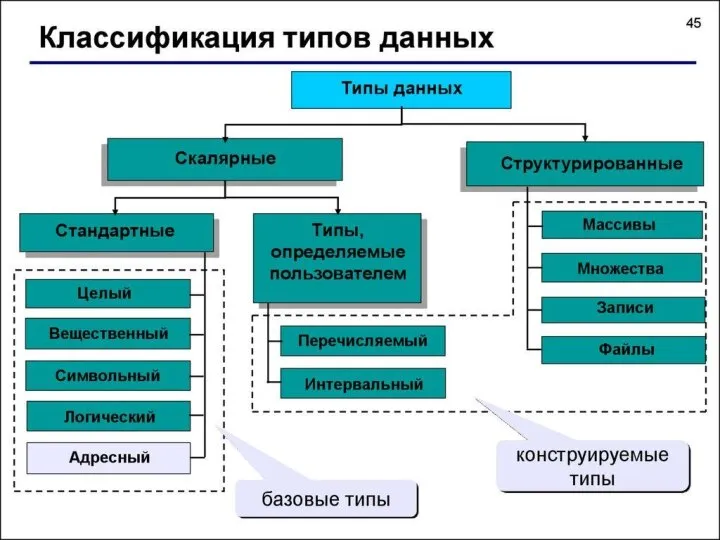
- 4. Различают базовые и производные виды данных в программировании:
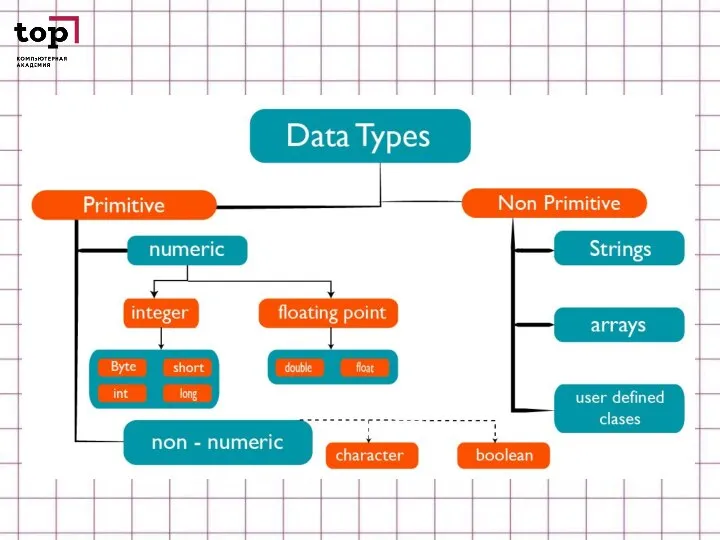
- 5. РАЗНОВИДНОСТИ БАЗОВЫХ ТИПОВ ДАННЫХ В ПРОГРАММИРОВАНИИ Числовые виды данных в программировании Целочисленные. Виды данных в программировании
- 6. Учитывая восприятие компьютерными устройствами целого значения, в ячейке памяти из n бит может храниться и 2n-1
- 8. ВЕЩЕСТВЕННЫЕ. Значения этого типа имеют плавающую запятую. Плавающая запятая — форма представления действительных чисел, в которой
- 9. Например: 14 441 544 = 1,4 441 544 ∗ 107; 0,0 004 785 = 4,785 ∗
- 10. СИМВОЛЬНЫЙ ТИП ДАННЫХ В ПРОГРАММИРОВАНИИ. В символьном типе переменная имеет только один символ, целое число. В
- 11. ПЕРЕЧИСЛИМЫЙ ВИД ДАННЫХ В ПРОГРАММИРОВАНИИ. Для внутреннего представления этот вид аналогичен целочисленному, но в нем программист
- 12. МАССИВЫ ДАННЫХ. Теперь рассмотрим сложные виды данных в программировании. И на первом месте – массив. Массив
- 13. СТРУКТУРА. До этого мы разобрали встроенные виды данных в программировании. Далее рассмотрим пользовательский тип данных. Структура
- 14. Примеры видов данных в программировании В языке Рython используются следующие типы данных программирования: int — целочисленный;
- 15. Язык программирования JavaScript содержит следующие типы данных: srting — тип данных «строка»; number — «число»; object
- 16. ТИП ДАННЫХ — «ЧИСЛО». В таком виде данных могут быть как дробные, так и целые числа.
- 17. ЛОГИЧЕСКИЕ (БУЛЕВЫЕ) ТИПЫ ДАННЫХ В ПРОГРАММИРОВАНИИ — boolean. Принимая решение, что необходимо выполнить далее, компьютер анализирует
- 18. Основой языка программирования Паскаль, как и любого другого языка, является алфавит — набор допустимых символов, которые
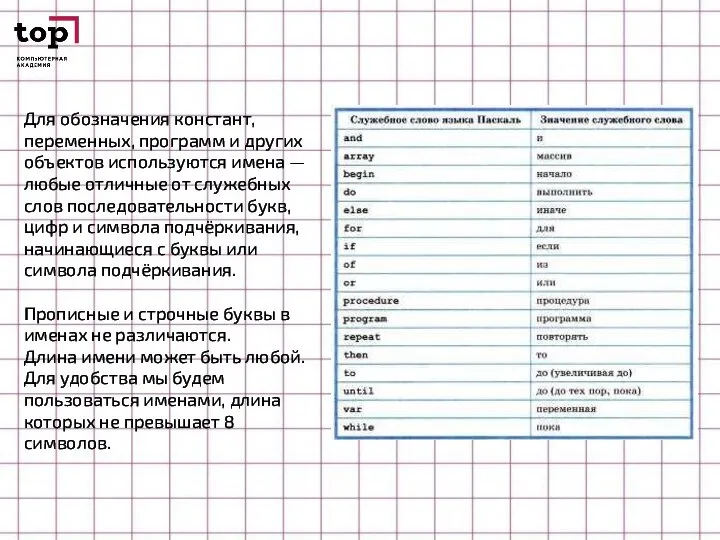
- 19. Для обозначения констант, переменных, программ и других объектов используются имена — любые отличные от служебных слов
- 20. ТИПЫ ДАННЫХ, ИСПОЛЬЗУЕМЫЕ В ЯЗЫКЕ ПАСКАЛЬ В языке Паскаль используются различные типы данных. Мы будем пользоваться
- 21. integer — основной, но не единственный тип для работы с целочисленными данными. Дополнительную информацию по этому
- 22. Имена переменных одного типа перечисляются через запятую, затем после двоеточия указывается их тип; описание каждого типа
- 23. ОПЕРАТОР ПРИСВАИВАНИЯ Основное преобразование данных, выполняемое компьютером, — присваивание переменной нового значения, что означает изменение содержимого
- 24. При выполнении оператора а:=10 в ячейку оперативной памяти компьютера с именем а заносится значение 10; при
- 25. САМОЕ ГЛАВНОЕ Паскаль — универсальный язык программирования, получивший своё название в честь выдающегося учёного Блеза Паскаля.
- 26. Общий вид программы:
- 29. ИНФОРМАЦИЯ И СУБД Появление компьютеров не сразу привело к разработке информационных систем. На заре вычислительной техники
- 30. СУБД – СИСТЕМЫ УПРАВЛЕНИЯ БАЗАМИ ДАННЫХ. Понятие согласованности данных является ключевым понятием баз данных. Если информационная
- 31. Если информационная система поддерживает два согласованных файла сотрудники и отделы и была добавлена запись файл сотрудники,
- 32. 1) В СУБД определяется искомая запись и затем для ее извлечения запрашивается диспетчер файлов. Запись –
- 33. ДИСПЕТЧЕР ДИСКОВ Диспетчер дисков является компонентом ОС. При выполнении дисковых операций необходимо знать физические адреса на
- 34. Файлом называется набор однотипных записей. Основными операциями выполняемыми диспетчером файлов являются: 1) извлечь запись R из
- 35. КЛАСТЕРИЗАЦИЯ Это процесс как можно более близкого физического размещения на диске, логически связанных между собой и
- 36. ФИЗИЧЕСКОЕ РАЗМЕЩЕНИЕ ДАННЫХ НА ДИСКЕ Логическая последовательность страниц задается с помощью указателей, то есть логически близко
- 37. Записи в пределах страницы также можно разместить в соответствии с логическим порядком. Записи идентифицируются с помощью
- 38. Индексирование Пример: Поставщики
- 39. При наличии индекса, имеется несколько стратегий доступа к данным из файла поставщики. Пример: найти поставщиков из
- 40. Использование индексов на ряду с ускорением выборки имеет недостаток , который связан с замедлением процесса обновления
- 41. ПЛОТНОЕ И НЕПЛОТНОЕ ИНДЕКСИРОВАНИЕ Плотный индекс имеет вход для каждой записи индексированного файла. В индексе используются
- 42. СТРУКТУРА ТИПА B-TREE Дерево состоит из двух множеств: множество вершин и множество дуг. Корневой называется вершина
- 43. НАБОР ИНДЕКСОВ Обеспечивает быстрый непосредственный доступ к наборам последовательностей (последовательным данным). Фактически набор индексов является индексным
- 44. Для вставки нового значения V в структуру типа B-tree порядка n. Пусть V = 41. Например,
- 45. Далее этот процесс следует повторить для вставки среднего значения W в родительский элемент P на более
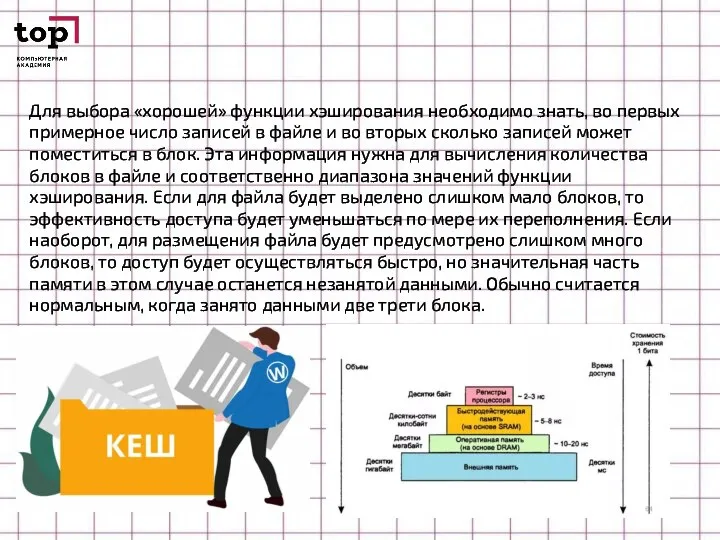
- 46. КЭШИРОВАНИЕ Стилем и порядком дерева называется максимально допустимое количество дочерних узлов для каждого родительского узла. Большие
- 47. Для выбора «хорошей» функции хэширования необходимо знать, во первых примерное число записей в файле и во
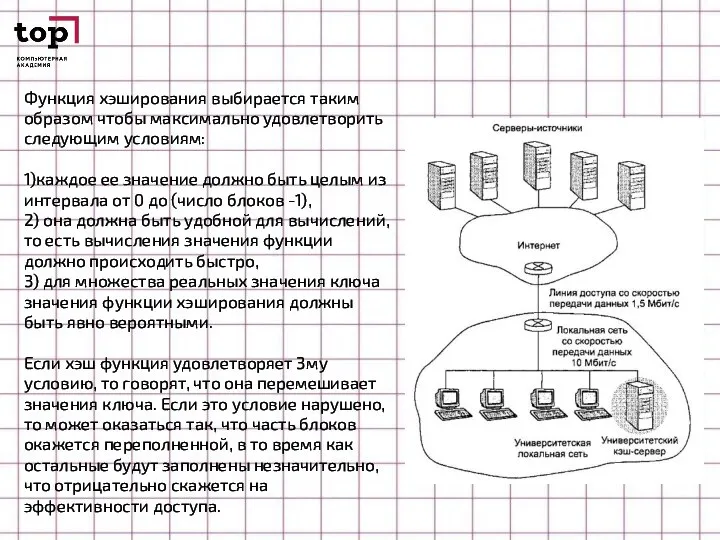
- 48. Функция хэширования выбирается таким образом чтобы максимально удовлетворить следующим условиям: 1)каждое ее значение должно быть целым
- 49. НЕПРИГОДНОСТЬ ФАЙЛОВ С ХЭШ АДРЕСАЦИЕЙ К ГРУППОВОЙ ОБРАБОТКЕ Прямой доступ имеет место, когда требуется найти одно
- 50. ЦЕПОЧКИ УКАЗАТЕЛЕЙ Для выполнения запроса типа “найти поставщиков из города N” можно применить способ хранения данных
- 51. НЕДОСТАТКИ СТРУКТУРЫ Для доступа к Nму поставщику требуется перебрать все предыдущие записи поставщиков. В худшем случае,
- 52. МЕРЫ ПО УЛУЧШЕНИЮ СТРУКТУРЫ 1) Указатели можно задать также и в обратном направлении. При этом существенно
- 53. УПРАВЛЕНИЕ ДАННЫМИ РАСПОЛОЖЕННЫМИ В ОПЕРАТИВНОЙ ПАМЯТИ Возможность размещать базу данных целиком в оперативной памяти появилась в
- 54. В традиционной СУБД узел B-tree представляет собой страницу диска и содержит максимально возможное число указателей на
- 56. Скачать презентацию
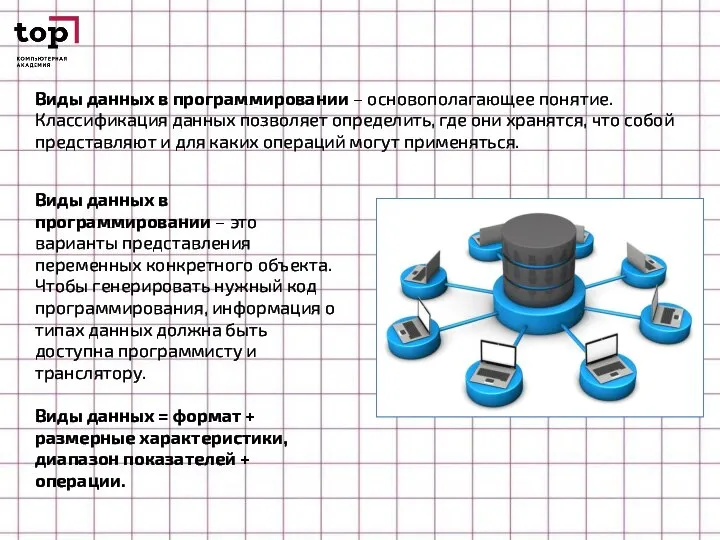
Слайд 2Виды данных в программировании – основополагающее понятие. Классификация данных позволяет определить, где
Виды данных в программировании – основополагающее понятие. Классификация данных позволяет определить, где
Слайд 4Различают базовые и производные виды данных в программировании:
Различают базовые и производные виды данных в программировании:

Слайд 5РАЗНОВИДНОСТИ БАЗОВЫХ ТИПОВ ДАННЫХ В ПРОГРАММИРОВАНИИ
Числовые виды данных в программировании
Целочисленные.
Виды данных в
РАЗНОВИДНОСТИ БАЗОВЫХ ТИПОВ ДАННЫХ В ПРОГРАММИРОВАНИИ
Числовые виды данных в программировании
Целочисленные.
Виды данных в

Слайд 6Учитывая восприятие компьютерными устройствами целого значения, в ячейке памяти из n бит
Учитывая восприятие компьютерными устройствами целого значения, в ячейке памяти из n бит

Слайд 8ВЕЩЕСТВЕННЫЕ.
Значения этого типа имеют плавающую запятую.
Плавающая запятая — форма представления действительных чисел,
ВЕЩЕСТВЕННЫЕ.
Значения этого типа имеют плавающую запятую.
Плавающая запятая — форма представления действительных чисел,

Слайд 9Например: 14 441 544 = 1,4 441 544 ∗ 107; 0,0 004 785 =
Например: 14 441 544 = 1,4 441 544 ∗ 107; 0,0 004 785 =

Слайд 10СИМВОЛЬНЫЙ ТИП ДАННЫХ В ПРОГРАММИРОВАНИИ.
В символьном типе переменная имеет только один символ,
СИМВОЛЬНЫЙ ТИП ДАННЫХ В ПРОГРАММИРОВАНИИ.
В символьном типе переменная имеет только один символ,

Слайд 11ПЕРЕЧИСЛИМЫЙ ВИД ДАННЫХ В ПРОГРАММИРОВАНИИ.
Для внутреннего представления этот вид аналогичен целочисленному, но
ПЕРЕЧИСЛИМЫЙ ВИД ДАННЫХ В ПРОГРАММИРОВАНИИ.
Для внутреннего представления этот вид аналогичен целочисленному, но

Слайд 12МАССИВЫ ДАННЫХ.
Теперь рассмотрим сложные виды данных в программировании. И на первом месте
МАССИВЫ ДАННЫХ.
Теперь рассмотрим сложные виды данных в программировании. И на первом месте

Слайд 13СТРУКТУРА.
До этого мы разобрали встроенные виды данных в программировании. Далее рассмотрим пользовательский
СТРУКТУРА.
До этого мы разобрали встроенные виды данных в программировании. Далее рассмотрим пользовательский

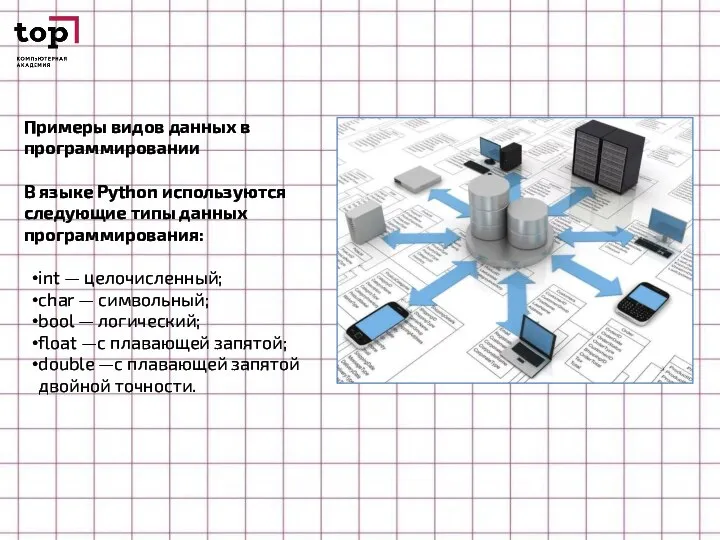
Слайд 14Примеры видов данных в программировании
В языке Рython используются следующие типы данных программирования:
int
Примеры видов данных в программировании
В языке Рython используются следующие типы данных программирования:
int
Слайд 15Язык программирования JavaScript содержит следующие типы данных:
srting — тип данных «строка»;
number —
Язык программирования JavaScript содержит следующие типы данных:
srting — тип данных «строка»;
number —

Слайд 16ТИП ДАННЫХ — «ЧИСЛО».
В таком виде данных могут быть как дробные, так
ТИП ДАННЫХ — «ЧИСЛО».
В таком виде данных могут быть как дробные, так

Слайд 17ЛОГИЧЕСКИЕ (БУЛЕВЫЕ) ТИПЫ ДАННЫХ В ПРОГРАММИРОВАНИИ — boolean.
Принимая решение, что необходимо выполнить
ЛОГИЧЕСКИЕ (БУЛЕВЫЕ) ТИПЫ ДАННЫХ В ПРОГРАММИРОВАНИИ — boolean.
Принимая решение, что необходимо выполнить

Слайд 18Основой языка программирования Паскаль, как и любого другого языка, является алфавит — набор
Основой языка программирования Паскаль, как и любого другого языка, является алфавит — набор

Слайд 19Для обозначения констант, переменных, программ и других объектов используются имена — любые
Для обозначения констант, переменных, программ и других объектов используются имена — любые
Слайд 20ТИПЫ ДАННЫХ, ИСПОЛЬЗУЕМЫЕ В ЯЗЫКЕ ПАСКАЛЬ
В языке Паскаль используются различные типы данных.
ТИПЫ ДАННЫХ, ИСПОЛЬЗУЕМЫЕ В ЯЗЫКЕ ПАСКАЛЬ
В языке Паскаль используются различные типы данных.

Слайд 21integer — основной, но не единственный тип для работы с целочисленными данными.
integer — основной, но не единственный тип для работы с целочисленными данными.

Слайд 22Имена переменных одного типа перечисляются через запятую, затем после двоеточия указывается их
Имена переменных одного типа перечисляются через запятую, затем после двоеточия указывается их

Слайд 23ОПЕРАТОР ПРИСВАИВАНИЯ
Основное преобразование данных, выполняемое компьютером, — присваивание переменной нового значения, что означает
ОПЕРАТОР ПРИСВАИВАНИЯ
Основное преобразование данных, выполняемое компьютером, — присваивание переменной нового значения, что означает

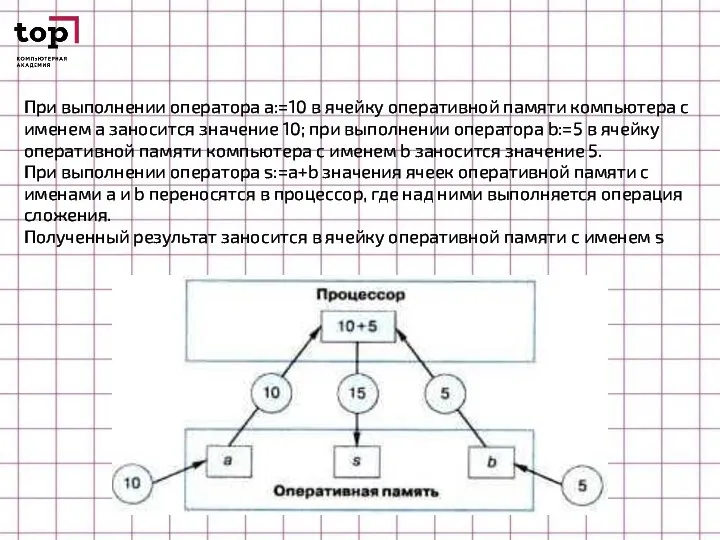
Слайд 24При выполнении оператора а:=10 в ячейку оперативной памяти компьютера с именем а
При выполнении оператора а:=10 в ячейку оперативной памяти компьютера с именем а
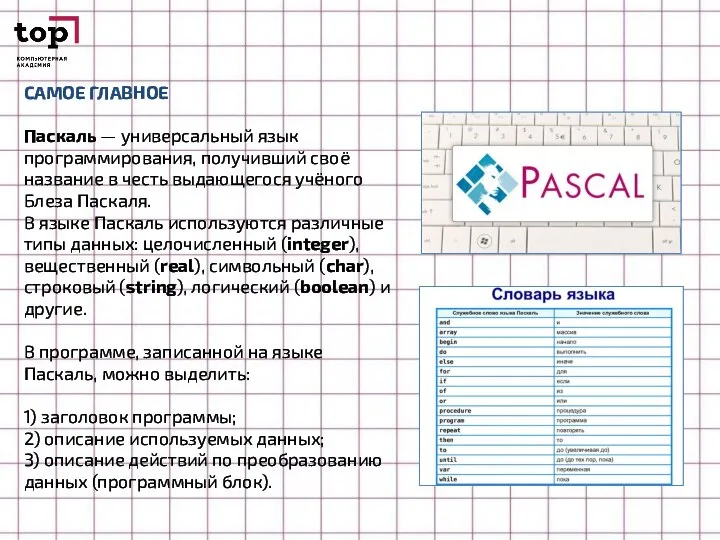
Слайд 25САМОЕ ГЛАВНОЕ
Паскаль — универсальный язык программирования, получивший своё название в честь выдающегося учёного
САМОЕ ГЛАВНОЕ
Паскаль — универсальный язык программирования, получивший своё название в честь выдающегося учёного
Слайд 26Общий вид программы:
Общий вид программы:

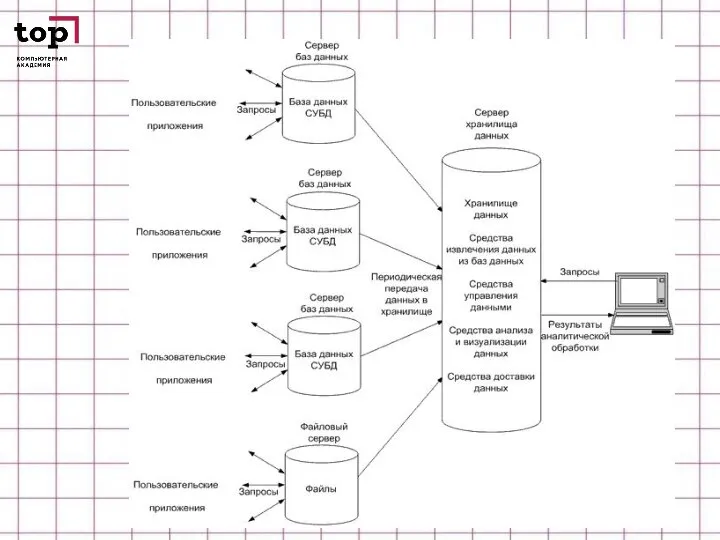
Слайд 29ИНФОРМАЦИЯ И СУБД
Появление компьютеров не сразу привело к разработке информационных систем. На
ИНФОРМАЦИЯ И СУБД
Появление компьютеров не сразу привело к разработке информационных систем. На

Слайд 30СУБД – СИСТЕМЫ УПРАВЛЕНИЯ БАЗАМИ ДАННЫХ.
Понятие согласованности данных является ключевым понятием баз
СУБД – СИСТЕМЫ УПРАВЛЕНИЯ БАЗАМИ ДАННЫХ.
Понятие согласованности данных является ключевым понятием баз

Слайд 31Если информационная система поддерживает два согласованных файла сотрудники и отделы и была
Если информационная система поддерживает два согласованных файла сотрудники и отделы и была

Слайд 321) В СУБД определяется искомая запись и затем для ее извлечения запрашивается
1) В СУБД определяется искомая запись и затем для ее извлечения запрашивается

Слайд 33ДИСПЕТЧЕР ДИСКОВ
Диспетчер дисков является компонентом ОС. При выполнении дисковых операций необходимо знать
ДИСПЕТЧЕР ДИСКОВ
Диспетчер дисков является компонентом ОС. При выполнении дисковых операций необходимо знать

Слайд 34Файлом называется набор однотипных записей. Основными операциями выполняемыми диспетчером файлов являются:
1) извлечь
Файлом называется набор однотипных записей. Основными операциями выполняемыми диспетчером файлов являются:
1) извлечь

Слайд 35КЛАСТЕРИЗАЦИЯ
Это процесс как можно более близкого физического размещения на диске, логически связанных
КЛАСТЕРИЗАЦИЯ
Это процесс как можно более близкого физического размещения на диске, логически связанных

Слайд 36ФИЗИЧЕСКОЕ РАЗМЕЩЕНИЕ ДАННЫХ НА ДИСКЕ
Логическая последовательность страниц задается с помощью указателей, то
ФИЗИЧЕСКОЕ РАЗМЕЩЕНИЕ ДАННЫХ НА ДИСКЕ
Логическая последовательность страниц задается с помощью указателей, то

Слайд 37Записи в пределах страницы также можно разместить в соответствии с логическим порядком.
Записи
Записи в пределах страницы также можно разместить в соответствии с логическим порядком.
Записи

Слайд 38Индексирование
Пример: Поставщики
Индексирование
Пример: Поставщики

Слайд 39При наличии индекса, имеется несколько стратегий доступа к данным из файла поставщики.
При наличии индекса, имеется несколько стратегий доступа к данным из файла поставщики.

Слайд 40Использование индексов на ряду с ускорением выборки имеет недостаток , который связан
Использование индексов на ряду с ускорением выборки имеет недостаток , который связан

Слайд 41ПЛОТНОЕ И НЕПЛОТНОЕ ИНДЕКСИРОВАНИЕ
Плотный индекс имеет вход для каждой записи индексированного файла.
ПЛОТНОЕ И НЕПЛОТНОЕ ИНДЕКСИРОВАНИЕ
Плотный индекс имеет вход для каждой записи индексированного файла.

Слайд 42СТРУКТУРА ТИПА B-TREE
Дерево состоит из двух множеств: множество вершин и множество дуг.
СТРУКТУРА ТИПА B-TREE
Дерево состоит из двух множеств: множество вершин и множество дуг.

Слайд 43НАБОР ИНДЕКСОВ
Обеспечивает быстрый непосредственный доступ к наборам последовательностей (последовательным данным). Фактически набор
НАБОР ИНДЕКСОВ
Обеспечивает быстрый непосредственный доступ к наборам последовательностей (последовательным данным). Фактически набор

Слайд 44Для вставки нового значения V в структуру типа B-tree порядка n. Пусть
Для вставки нового значения V в структуру типа B-tree порядка n. Пусть

Слайд 45Далее этот процесс следует повторить для вставки среднего значения W в родительский
Далее этот процесс следует повторить для вставки среднего значения W в родительский

Слайд 46КЭШИРОВАНИЕ
Стилем и порядком дерева называется максимально допустимое количество дочерних узлов для каждого родительского
КЭШИРОВАНИЕ
Стилем и порядком дерева называется максимально допустимое количество дочерних узлов для каждого родительского

Слайд 47Для выбора «хорошей» функции хэширования необходимо знать, во первых примерное число записей
Для выбора «хорошей» функции хэширования необходимо знать, во первых примерное число записей
Слайд 48Функция хэширования выбирается таким образом чтобы максимально удовлетворить следующим условиям:
1)каждое ее значение
Функция хэширования выбирается таким образом чтобы максимально удовлетворить следующим условиям:
1)каждое ее значение
Слайд 49НЕПРИГОДНОСТЬ ФАЙЛОВ С ХЭШ АДРЕСАЦИЕЙ К ГРУППОВОЙ ОБРАБОТКЕ
Прямой доступ имеет место, когда
НЕПРИГОДНОСТЬ ФАЙЛОВ С ХЭШ АДРЕСАЦИЕЙ К ГРУППОВОЙ ОБРАБОТКЕ
Прямой доступ имеет место, когда

Слайд 50ЦЕПОЧКИ УКАЗАТЕЛЕЙ
Для выполнения запроса типа “найти поставщиков из города N” можно применить
ЦЕПОЧКИ УКАЗАТЕЛЕЙ
Для выполнения запроса типа “найти поставщиков из города N” можно применить

Слайд 51НЕДОСТАТКИ СТРУКТУРЫ
Для доступа к Nму поставщику требуется перебрать все предыдущие записи поставщиков.
НЕДОСТАТКИ СТРУКТУРЫ
Для доступа к Nму поставщику требуется перебрать все предыдущие записи поставщиков.

Слайд 52МЕРЫ ПО УЛУЧШЕНИЮ СТРУКТУРЫ
1) Указатели можно задать также и в обратном направлении.
МЕРЫ ПО УЛУЧШЕНИЮ СТРУКТУРЫ
1) Указатели можно задать также и в обратном направлении.

Слайд 53УПРАВЛЕНИЕ ДАННЫМИ РАСПОЛОЖЕННЫМИ В ОПЕРАТИВНОЙ ПАМЯТИ
Возможность размещать базу данных целиком в оперативной
УПРАВЛЕНИЕ ДАННЫМИ РАСПОЛОЖЕННЫМИ В ОПЕРАТИВНОЙ ПАМЯТИ
Возможность размещать базу данных целиком в оперативной

Слайд 54В традиционной СУБД узел B-tree представляет собой страницу диска и содержит максимально
В традиционной СУБД узел B-tree представляет собой страницу диска и содержит максимально

 Бытовая швейная машина
Бытовая швейная машина КОГО Я ВИЖУ
КОГО Я ВИЖУ ООО Компьютерщик
ООО Компьютерщик ПРЕЗЕНТАЦИЯ
ПРЕЗЕНТАЦИЯ Лояльность & Сервисы
Лояльность & Сервисы Здоровьесберегающая направленность физической культуры
Здоровьесберегающая направленность физической культуры Фотоотчет. Тц Эпицентр
Фотоотчет. Тц Эпицентр Море и его обитатели
Море и его обитатели эконом-класс
эконом-класс Ультразвук в медицине
Ультразвук в медицине Назначение выборов
Назначение выборов Past tenses
Past tenses Microsoft PowerPoint
Microsoft PowerPoint Общая схема ПЭВМ
Общая схема ПЭВМ Засоби навчання
Засоби навчання Программа поддержки кадров для сельских территорий
Программа поддержки кадров для сельских территорий Презентация на тему Роман Семёнович Сеф (1931—2009)
Презентация на тему Роман Семёнович Сеф (1931—2009)  Готовы ли лидеры к построению взаимоотношений
Готовы ли лидеры к построению взаимоотношений картины 8 класс
картины 8 класс Новый маршрут уралмашевского автобуса
Новый маршрут уралмашевского автобуса Галашева Екатерина Особенности заключения и исполнения договоров с иностранными партнерами
Галашева Екатерина Особенности заключения и исполнения договоров с иностранными партнерами Как заставить ваш интернет магазин продавать
Как заставить ваш интернет магазин продавать Integral
Integral Презентация на тему Минутка биосмеха
Презентация на тему Минутка биосмеха Я – исследователь!
Я – исследователь! Формирование и эффективность функционирования местного сообщества
Формирование и эффективность функционирования местного сообщества Изображение характера животных. 2 класс
Изображение характера животных. 2 класс Останкино 7 мая. Бал Победы
Останкино 7 мая. Бал Победы