- Map-Reduce и параллельные аналитические базы данных

Содержание
- 2. 23 апреля 2010 г. Корпоративные базы данных 2010 Введение (1) Клермонтский отчет: ... сбор, интеграция и
- 3. 23 апреля 2010 г. Корпоративные базы данных 2010 Введение (2) К концу прошлого века аналитические средства
- 4. 23 апреля 2010 г. Корпоративные базы данных 2010 Введение (3) C начала 2000-х активизировалось направление Data
- 5. 23 апреля 2010 г. Корпоративные базы данных 2010 Введение (4) Аналитические параллельные СУБД (1) Направление DWAA
- 6. 23 апреля 2010 г. Корпоративные базы данных 2010 Введение (5) Аналитические параллельные СУБД (2) Аппаратно-программное решение,
- 7. 23 апреля 2010 г. Корпоративные базы данных 2010 Введение (6) Аналитические параллельные СУБД (3) Возрождение направления
- 8. 23 апреля 2010 г. Корпоративные базы данных 2010 Введение (7) Аналитические параллельные СУБД (4) Эффективное DWAA-решение
- 9. 23 апреля 2010 г. Корпоративные базы данных 2010 Введение (8) Аналитические параллельные СУБД (5) С тех
- 10. 23 апреля 2010 г. Корпоративные базы данных 2010 Введение (9) Аналитические параллельные СУБД (6) DATAllegro Inc.
- 11. 23 апреля 2010 г. Корпоративные базы данных 2010 Введение (10) Аналитические параллельные СУБД (7) Greenplum MPP
- 12. 23 апреля 2010 г. Корпоративные базы данных 2010 Введение (11) Аналитические параллельные СУБД (8) EXASOL AG
- 13. 23 апреля 2010 г. Корпоративные базы данных 2010 Введение (12) Аналитические параллельные СУБД (9) Infobright поколоночное
- 14. 23 апреля 2010 г. Корпоративные базы данных 2010 Введение (13) Аналитические параллельные СУБД (10) Подход DWAA
- 15. 23 апреля 2010 г. Корпоративные базы данных 2010 Введение (14) Аналитические параллельные СУБД (11) У разных
- 16. 23 апреля 2010 г. Корпоративные базы данных 2010 Введение (15) При чем здесь MapReduce? (1) Сосредоточимся
- 17. 23 апреля 2010 г. Корпоративные базы данных 2010 Введение (16) При чем здесь MapReduce? (2) Появление
- 18. 23 апреля 2010 г. Корпоративные базы данных 2010 Введение (17) При чем здесь MapReduce? (3) Потом
- 19. 23 апреля 2010 г. Корпоративные базы данных 2010 Введение (18) При чем здесь MapReduce? (4) Однако
- 20. 23 апреля 2010 г. Корпоративные базы данных 2010 Введение (19) При чем здесь MapReduce? (5) На
- 21. 23 апреля 2010 г. Корпоративные базы данных 2010 Введение (20) При чем здесь MapReduce? (6) Рассмотрим
- 22. 23 апреля 2010 г. Корпоративные базы данных 2010 Введение (21) При чем здесь MapReduce? (7) Первый
- 23. 23 апреля 2010 г. Корпоративные базы данных 2010 MapReduce: модель и реализации (1) Программная модель MapReduce
- 24. 23 апреля 2010 г. Корпоративные базы данных 2010 MapReduce: модель и реализации (2) Свободно доступная реализация
- 25. 23 апреля 2010 г. Корпоративные базы данных 2010 MapReduce: модель и реализации (3) Однако реализация Hadoop
- 26. 23 апреля 2010 г. Корпоративные базы данных 2010 MapReduce: модель и реализации (3) Общая модель программирования
- 27. 23 апреля 2010 г. Корпоративные базы данных 2010 MapReduce: модель и реализации (4) Общая модель программирования
- 28. 23 апреля 2010 г. Корпоративные базы данных 2010 MapReduce: модель и реализации (5) Реализация в распределенной
- 29. 23 апреля 2010 г. Корпоративные базы данных 2010 MapReduce: модель и реализации (6) Реализация в распределенной
- 30. 23 апреля 2010 г. Корпоративные базы данных 2010 MapReduce: модель и реализации (7) Реализация в распределенной
- 31. 23 апреля 2010 г. Корпоративные базы данных 2010 MapReduce: модель и реализации (8) Реализация в распределенной
- 32. 23 апреля 2010 г. Корпоративные базы данных 2010 MapReduce: модель и реализации (9) Реализация в распределенной
- 33. 23 апреля 2010 г. Корпоративные базы данных 2010 MapReduce: модель и реализации (10) Реализация в распределенной
- 34. 23 апреля 2010 г. Корпоративные базы данных 2010 MapReduce: модель и реализации (11) Реализация в распределенной
- 35. 23 апреля 2010 г. Корпоративные базы данных 2010 MapReduce: модель и реализации (12) Реализация в распределенной
- 36. 23 апреля 2010 г. Корпоративные базы данных 2010 MapReduce: модель и реализации (13) Реализация в распределенной
- 37. 23 апреля 2010 г. Корпоративные базы данных 2010 MapReduce: модель и реализации (14) Реализация в распределенной
- 38. 23 апреля 2010 г. Корпоративные базы данных 2010 MapReduce: модель и реализации (15) Реализация в распределенной
- 39. 23 апреля 2010 г. Корпоративные базы данных 2010 MapReduce: модель и реализации (16) Реализация в распределенной
- 40. 23 апреля 2010 г. Корпоративные базы данных 2010 MapReduce: модель и реализации (17) Реализация в распределенной
- 41. 23 апреля 2010 г. Корпоративные базы данных 2010 MapReduce: модель и реализации (18) Реализация в распределенной
- 42. 23 апреля 2010 г. Корпоративные базы данных 2010 MapReduce: модель и реализации (19) Реализация в распределенной
- 43. 23 апреля 2010 г. Корпоративные базы данных 2010 MapReduce: модель и реализации (20) Реализация в распределенной
- 44. 23 апреля 2010 г. Корпоративные базы данных 2010 MapReduce: модель и реализации (21) Расширенные возможности (1)
- 45. 23 апреля 2010 г. Корпоративные базы данных 2010 MapReduce: модель и реализации (22) Расширенные возможности (2)
- 46. 23 апреля 2010 г. Корпоративные базы данных 2010 MapReduce: модель и реализации (23) Расширенные возможности (3)
- 47. 23 апреля 2010 г. Корпоративные базы данных 2010 MapReduce: модель и реализации (24) Расширенные возможности (4)
- 48. 23 апреля 2010 г. Корпоративные базы данных 2010 MapReduce внутри параллельной СУБД (1) Очевидны преимущества клиент-серверных
- 49. 23 апреля 2010 г. Корпоративные базы данных 2010 MapReduce внутри параллельной СУБД (2) Естественно, возникает вопрос:
- 50. 23 апреля 2010 г. Корпоративные базы данных 2010 MapReduce внутри параллельной СУБД (3) Поддержка определяемых пользователями
- 51. 23 апреля 2010 г. Корпоративные базы данных 2010 MapReduce внутри параллельной СУБД (4) Тем не менее,
- 52. 23 апреля 2010 г. Корпоративные базы данных 2010 MapReduce внутри параллельной СУБД (5) Технически можно было
- 53. 23 апреля 2010 г. Корпоративные базы данных 2010 MapReduce внутри параллельной СУБД (6) С другой стороны,
- 54. 23 апреля 2010 г. Корпоративные базы данных 2010 MapReduce внутри параллельной СУБД (7) Несмотря на эти
- 55. 23 апреля 2010 г. Корпоративные базы данных 2010 MapReduce внутри параллельной СУБД (8) Речь идет о
- 56. 23 апреля 2010 г. Корпоративные базы данных 2010 MapReduce внутри параллельной СУБД (9) Greemplum – MapReduce
- 57. 23 апреля 2010 г. Корпоративные базы данных 2010 MapReduce внутри параллельной СУБД (10) Greemplum – MapReduce
- 58. 23 апреля 2010 г. Корпоративные базы данных 2010 MapReduce внутри параллельной СУБД (11) Greemplum – MapReduce
- 59. 23 апреля 2010 г. Корпоративные базы данных 2010 MapReduce внутри параллельной СУБД (12) Greemplum – MapReduce
- 60. 23 апреля 2010 г. Корпоративные базы данных 2010 MapReduce внутри параллельной СУБД (13) Greemplum – MapReduce
- 61. 23 апреля 2010 г. Корпоративные базы данных 2010 MapReduce внутри параллельной СУБД (14) Greemplum – MapReduce
- 62. 23 апреля 2010 г. Корпоративные базы данных 2010 MapReduce внутри параллельной СУБД (15) Greemplum – MapReduce
- 63. 23 апреля 2010 г. Корпоративные базы данных 2010 MapReduce внутри параллельной СУБД (16) Greemplum – MapReduce
- 64. 23 апреля 2010 г. Корпоративные базы данных 2010 MapReduce внутри параллельной СУБД (17) Greemplum – MapReduce
- 65. 23 апреля 2010 г. Корпоративные базы данных 2010 MapReduce внутри параллельной СУБД (18) Greemplum – MapReduce
- 66. 23 апреля 2010 г. Корпоративные базы данных 2010 MapReduce внутри параллельной СУБД (18) Greemplum – MapReduce
- 67. 23 апреля 2010 г. Корпоративные базы данных 2010 MapReduce внутри параллельной СУБД (19) Greemplum – MapReduce
- 68. 23 апреля 2010 г. Корпоративные базы данных 2010 MapReduce внутри параллельной СУБД (20) Greemplum – MapReduce
- 69. 23 апреля 2010 г. Корпоративные базы данных 2010 MapReduce внутри параллельной СУБД (21) Greemplum – MapReduce
- 70. 23 апреля 2010 г. Корпоративные базы данных 2010 MapReduce внутри параллельной СУБД (22) Aster Data –
- 71. 23 апреля 2010 г. Корпоративные базы данных 2010 MapReduce внутри параллельной СУБД (23) Aster Data –
- 72. 23 апреля 2010 г. Корпоративные базы данных 2010 MapReduce внутри параллельной СУБД (24) Aster Data –
- 73. 23 апреля 2010 г. Корпоративные базы данных 2010 MapReduce внутри параллельной СУБД (25) Aster Data –
- 74. 23 апреля 2010 г. Корпоративные базы данных 2010 MapReduce внутри параллельной СУБД (26) Aster Data –
- 75. 23 апреля 2010 г. Корпоративные базы данных 2010 MapReduce внутри параллельной СУБД (27) Aster Data –
- 76. 23 апреля 2010 г. Корпоративные базы данных 2010 MapReduce внутри параллельной СУБД (28) Aster Data –
- 77. 23 апреля 2010 г. Корпоративные базы данных 2010 MapReduce внутри параллельной СУБД (29) Aster Data –
- 78. 23 апреля 2010 г. Корпоративные базы данных 2010 MapReduce внутри параллельной СУБД (30) Aster Data –
- 79. 23 апреля 2010 г. Корпоративные базы данных 2010 MapReduce внутри параллельной СУБД (31) Aster Data –
- 80. 23 апреля 2010 г. Корпоративные базы данных 2010 MapReduce внутри параллельной СУБД (32) Aster Data –
- 81. 23 апреля 2010 г. Корпоративные базы данных 2010 MapReduce внутри параллельной СУБД (33) Aster Data –
- 82. 23 апреля 2010 г. Корпоративные базы данных 2010 MapReduce внутри параллельной СУБД (34) Aster Data –
- 83. 23 апреля 2010 г. Корпоративные базы данных 2010 MapReduce внутри параллельной СУБД (35) Aster Data –
- 84. 23 апреля 2010 г. Корпоративные базы данных 2010 MapReduce внутри параллельной СУБД (36) Aster Data –
- 85. 23 апреля 2010 г. Корпоративные базы данных 2010 MapReduce внутри параллельной СУБД (37) Aster Data –
- 86. 23 апреля 2010 г. Корпоративные базы данных 2010 MapReduce внутри параллельной СУБД (38) Aster Data –
- 87. 23 апреля 2010 г. Корпоративные базы данных 2010 MapReduce внутри параллельной СУБД (39) Aster Data –
- 88. 23 апреля 2010 г. Корпоративные базы данных 2010 MapReduce внутри параллельной СУБД (40) Таким образом в
- 89. 23 апреля 2010 г. Корпоративные базы данных 2010 Параллельная СУБД на основе MapReduce (1) В статье
- 90. 23 апреля 2010 г. Корпоративные базы данных 2010 Параллельная СУБД на основе MapReduce (2) Однако спустя
- 91. 23 апреля 2010 г. Корпоративные базы данных 2010 Параллельная СУБД на основе MapReduce (3) Это объясняется
- 92. 23 апреля 2010 г. Корпоративные базы данных 2010 Параллельная СУБД на основе MapReduce (4) Требуемые характеристики
- 93. 23 апреля 2010 г. Корпоративные базы данных 2010 Параллельная СУБД на основе MapReduce (5) Однако объективно
- 94. 23 апреля 2010 г. Корпоративные базы данных 2010 Параллельная СУБД на основе MapReduce (6) В проекте
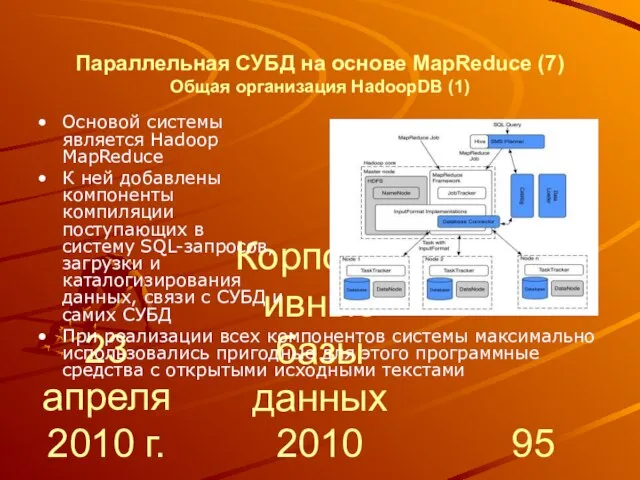
- 95. 23 апреля 2010 г. Корпоративные базы данных 2010 Параллельная СУБД на основе MapReduce (7) Общая организация
- 96. 23 апреля 2010 г. Корпоративные базы данных 2010 Параллельная СУБД на основе MapReduce (8) Общая организация
- 97. 23 апреля 2010 г. Корпоративные базы данных 2010 Параллельная СУБД на основе MapReduce (9) Общая организация
- 98. 23 апреля 2010 г. Корпоративные базы данных 2010 Параллельная СУБД на основе MapReduce (10) Общая организация
- 99. 23 апреля 2010 г. Корпоративные базы данных 2010 Параллельная СУБД на основе MapReduce (11) Общая организация
- 100. 23 апреля 2010 г. Корпоративные базы данных 2010 Параллельная СУБД на основе MapReduce (12) Общая организация
- 101. 23 апреля 2010 г. Корпоративные базы данных 2010 Параллельная СУБД на основе MapReduce (13) Общая организация
- 102. 23 апреля 2010 г. Корпоративные базы данных 2010 Параллельная СУБД на основе MapReduce (14) Общая организация
- 103. 23 апреля 2010 г. Корпоративные базы данных 2010 Параллельная СУБД на основе MapReduce (15) Общая организация
- 104. 23 апреля 2010 г. Корпоративные базы данных 2010 Параллельная СУБД на основе MapReduce (16) Общая организация
- 105. 23 апреля 2010 г. Корпоративные базы данных 2010 Параллельная СУБД на основе MapReduce (17) Общая организация
- 106. 23 апреля 2010 г. Корпоративные базы данных 2010 Параллельная СУБД на основе MapReduce (18) Общая организация
- 107. 23 апреля 2010 г. Корпоративные базы данных 2010 Параллельная СУБД на основе MapReduce (19) Общая организация
- 108. 23 апреля 2010 г. Корпоративные базы данных 2010 Параллельная СУБД на основе MapReduce (20) Общая организация
- 109. 23 апреля 2010 г. Корпоративные базы данных 2010 Параллельная СУБД на основе MapReduce (21) Общая организация
- 110. 23 апреля 2010 г. Корпоративные базы данных 2010 Параллельная СУБД на основе MapReduce (22) Общая организация
- 111. 23 апреля 2010 г. Корпоративные базы данных 2010 Параллельная СУБД на основе MapReduce (23) Общая организация
- 112. 23 апреля 2010 г. Корпоративные базы данных 2010 Параллельная СУБД на основе MapReduce (24) Общая организация
- 113. 23 апреля 2010 г. Корпоративные базы данных 2010 Параллельная СУБД на основе MapReduce (25) Общая организация
- 114. 23 апреля 2010 г. Корпоративные базы данных 2010 Параллельная СУБД на основе MapReduce (26) Общая организация
- 115. 23 апреля 2010 г. Корпоративные базы данных 2010 Параллельная СУБД на основе MapReduce (27) Общая организация
- 116. 23 апреля 2010 г. Корпоративные базы данных 2010 Параллельная СУБД на основе MapReduce (28) Характеристики HadoopDВ
- 117. 23 апреля 2010 г. Корпоративные базы данных 2010 Параллельная СУБД на основе MapReduce (29) Характеристики HadoopDВ
- 118. 23 апреля 2010 г. Корпоративные базы данных 2010 Параллельная СУБД на основе MapReduce (30) Характеристики HadoopDВ
- 119. 23 апреля 2010 г. Корпоративные базы данных 2010 Параллельная СУБД на основе MapReduce (31) Характеристики HadoopDВ
- 120. 23 апреля 2010 г. Корпоративные базы данных 2010 Параллельная СУБД на основе MapReduce (32) Характеристики HadoopDВ
- 121. 23 апреля 2010 г. Корпоративные базы данных 2010 Параллельная СУБД на основе MapReduce (33) Характеристики HadoopDВ
- 122. 23 апреля 2010 г. Корпоративные базы данных 2010 Параллельная СУБД на основе MapReduce (34) Характеристики HadoopDВ
- 123. 23 апреля 2010 г. Корпоративные базы данных 2010 Параллельная СУБД на основе MapReduce (35) Характеристики HadoopDВ
- 124. 23 апреля 2010 г. Корпоративные базы данных 2010 Параллельная СУБД на основе MapReduce (36) Проект HadoopDB
- 125. 23 апреля 2010 г. Корпоративные базы данных 2010 ETL с использованием MapReduce (1) Различных средств ETL
- 126. 23 апреля 2010 г. Корпоративные базы данных 2010 ETL с использованием MapReduce (2) Можно согласиться, что
- 127. 23 апреля 2010 г. Корпоративные базы данных 2010 ETL с использованием MapReduce (3) Итак, что мы
- 128. 23 апреля 2010 г. Корпоративные базы данных 2010 ETL с использованием MapReduce (4) MapReduce и ETL
- 129. 23 апреля 2010 г. Корпоративные базы данных 2010 ETL с использованием MapReduce (5) MapReduce и ETL
- 130. 23 апреля 2010 г. Корпоративные базы данных 2010 ETL с использованием MapReduce (6) MapReduce и ETL
- 131. 23 апреля 2010 г. Корпоративные базы данных 2010 ETL с использованием MapReduce (7) Hadoop и Vertica
- 132. 23 апреля 2010 г. Корпоративные базы данных 2010 ETL с использованием MapReduce (8) Hadoop и Vertica
- 133. 23 апреля 2010 г. Корпоративные базы данных 2010 ETL с использованием MapReduce (9) Скорее всего, мы
- 134. 23 апреля 2010 г. Корпоративные базы данных 2010 Заключение (1) Еще пару лет назад было непонятно,
- 135. 23 апреля 2010 г. Корпоративные базы данных 2010 Заключение (2) Однако вскоре стало понятно, что технология
- 136. 23 апреля 2010 г. Корпоративные базы данных 2010 Заключение (3) На сегодняшний день уже понятно, что
- 137. 23 апреля 2010 г. Корпоративные базы данных 2010 Заключение (4) Интересные работы ведутся и в направлении
- 138. 23 апреля 2010 г. Корпоративные базы данных 2010 Заключение (5) Полный текст: Сергей Кузнецов. MapReduce: внутри,
- 140. Скачать презентацию
Слайд 223 апреля 2010 г.
Корпоративные базы данных 2010
Введение (1)
Клермонтский отчет:
... сбор, интеграция и
23 апреля 2010 г.
Корпоративные базы данных 2010
Введение (1)
Клермонтский отчет:
... сбор, интеграция и

Слайд 323 апреля 2010 г.
Корпоративные базы данных 2010
Введение (2)
К концу прошлого века аналитические
23 апреля 2010 г.
Корпоративные базы данных 2010
Введение (2)
К концу прошлого века аналитические

Слайд 423 апреля 2010 г.
Корпоративные базы данных 2010
Введение (3)
C начала 2000-х активизировалось направление
23 апреля 2010 г.
Корпоративные базы данных 2010
Введение (3)
C начала 2000-х активизировалось направление

Слайд 523 апреля 2010 г.
Корпоративные базы данных 2010
Введение (4)
Аналитические параллельные СУБД (1)
Направление DWAA
23 апреля 2010 г.
Корпоративные базы данных 2010
Введение (4)
Аналитические параллельные СУБД (1)
Направление DWAA

Слайд 623 апреля 2010 г.
Корпоративные базы данных 2010
Введение (5)
Аналитические параллельные СУБД (2)
Аппаратно-программное решение,
23 апреля 2010 г.
Корпоративные базы данных 2010
Введение (5)
Аналитические параллельные СУБД (2)
Аппаратно-программное решение,

Слайд 723 апреля 2010 г.
Корпоративные базы данных 2010
Введение (6)
Аналитические параллельные СУБД (3)
Возрождение направления
23 апреля 2010 г.
Корпоративные базы данных 2010
Введение (6)
Аналитические параллельные СУБД (3)
Возрождение направления

Слайд 823 апреля 2010 г.
Корпоративные базы данных 2010
Введение (7)
Аналитические параллельные СУБД (4)
Эффективное DWAA-решение
23 апреля 2010 г.
Корпоративные базы данных 2010
Введение (7)
Аналитические параллельные СУБД (4)
Эффективное DWAA-решение

Слайд 923 апреля 2010 г.
Корпоративные базы данных 2010
Введение (8)
Аналитические параллельные СУБД (5)
С тех
23 апреля 2010 г.
Корпоративные базы данных 2010
Введение (8)
Аналитические параллельные СУБД (5)
С тех

Слайд 1023 апреля 2010 г.
Корпоративные базы данных 2010
Введение (9)
Аналитические параллельные СУБД (6)
DATAllegro Inc.
23 апреля 2010 г.
Корпоративные базы данных 2010
Введение (9)
Аналитические параллельные СУБД (6)
DATAllegro Inc.

Слайд 1123 апреля 2010 г.
Корпоративные базы данных 2010
Введение (10)
Аналитические параллельные СУБД (7)
Greenplum
MPP
система основана
23 апреля 2010 г.
Корпоративные базы данных 2010
Введение (10)
Аналитические параллельные СУБД (7)
Greenplum
MPP
система основана

Слайд 1223 апреля 2010 г.
Корпоративные базы данных 2010
Введение (11)
Аналитические параллельные СУБД (8)
EXASOL AG
MPP
поколоночное
23 апреля 2010 г.
Корпоративные базы данных 2010
Введение (11)
Аналитические параллельные СУБД (8)
EXASOL AG
MPP
поколоночное

Слайд 1323 апреля 2010 г.
Корпоративные базы данных 2010
Введение (12)
Аналитические параллельные СУБД (9)
Infobright
поколоночное хранение
23 апреля 2010 г.
Корпоративные базы данных 2010
Введение (12)
Аналитические параллельные СУБД (9)
Infobright
поколоночное хранение

Слайд 1423 апреля 2010 г.
Корпоративные базы данных 2010
Введение (13)
Аналитические параллельные СУБД (10)
Подход DWAA
23 апреля 2010 г.
Корпоративные базы данных 2010
Введение (13)
Аналитические параллельные СУБД (10)
Подход DWAA

Слайд 1523 апреля 2010 г.
Корпоративные базы данных 2010
Введение (14)
Аналитические параллельные СУБД (11)
У разных
23 апреля 2010 г.
Корпоративные базы данных 2010
Введение (14)
Аналитические параллельные СУБД (11)
У разных

Слайд 1623 апреля 2010 г.
Корпоративные базы данных 2010
Введение (15)
При чем здесь MapReduce? (1)
Сосредоточимся
23 апреля 2010 г.
Корпоративные базы данных 2010
Введение (15)
При чем здесь MapReduce? (1)
Сосредоточимся

Слайд 1723 апреля 2010 г.
Корпоративные базы данных 2010
Введение (16)
При чем здесь MapReduce? (2)
Появление
23 апреля 2010 г.
Корпоративные базы данных 2010
Введение (16)
При чем здесь MapReduce? (2)
Появление

Слайд 1823 апреля 2010 г.
Корпоративные базы данных 2010
Введение (17)
При чем здесь MapReduce? (3)
Потом
23 апреля 2010 г.
Корпоративные базы данных 2010
Введение (17)
При чем здесь MapReduce? (3)
Потом

Слайд 1923 апреля 2010 г.
Корпоративные базы данных 2010
Введение (18)
При чем здесь MapReduce? (4)
Однако
23 апреля 2010 г.
Корпоративные базы данных 2010
Введение (18)
При чем здесь MapReduce? (4)
Однако

Слайд 2023 апреля 2010 г.
Корпоративные базы данных 2010
Введение (19)
При чем здесь MapReduce? (5)
На
23 апреля 2010 г.
Корпоративные базы данных 2010
Введение (19)
При чем здесь MapReduce? (5)
На

Слайд 2123 апреля 2010 г.
Корпоративные базы данных 2010
Введение (20)
При чем здесь MapReduce? (6)
Рассмотрим
23 апреля 2010 г.
Корпоративные базы данных 2010
Введение (20)
При чем здесь MapReduce? (6)
Рассмотрим

Слайд 2223 апреля 2010 г.
Корпоративные базы данных 2010
Введение (21)
При чем здесь MapReduce? (7)
Первый
23 апреля 2010 г.
Корпоративные базы данных 2010
Введение (21)
При чем здесь MapReduce? (7)
Первый

Слайд 2323 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce: модель и реализации (1)
Программная модель
23 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce: модель и реализации (1)
Программная модель

Слайд 2423 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce: модель и реализации (2)
Свободно доступная
23 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce: модель и реализации (2)
Свободно доступная

Слайд 2523 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce: модель и реализации (3)
Однако реализация
23 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce: модель и реализации (3)
Однако реализация

Слайд 2623 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce: модель и реализации (3)
Общая модель
23 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce: модель и реализации (3) Общая модель

Слайд 2723 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce: модель и реализации (4)
Общая модель
23 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce: модель и реализации (4) Общая модель

Слайд 2823 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce: модель и реализации (5)
Реализация в
23 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce: модель и реализации (5) Реализация в

Слайд 2923 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce: модель и реализации (6)
Реализация в
23 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce: модель и реализации (6) Реализация в

Слайд 3023 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce: модель и реализации (7)
Реализация в
23 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce: модель и реализации (7) Реализация в

Слайд 3123 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce: модель и реализации (8)
Реализация в
23 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce: модель и реализации (8) Реализация в

Слайд 3223 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce: модель и реализации (9)
Реализация в
23 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce: модель и реализации (9) Реализация в

Слайд 3323 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce: модель и реализации (10)
Реализация в
23 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce: модель и реализации (10) Реализация в

Слайд 3423 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce: модель и реализации (11)
Реализация в
23 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce: модель и реализации (11) Реализация в

Слайд 3523 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce: модель и реализации (12)
Реализация в
23 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce: модель и реализации (12) Реализация в

Слайд 3623 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce: модель и реализации (13)
Реализация в
23 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce: модель и реализации (13) Реализация в

Слайд 3723 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce: модель и реализации (14)
Реализация в
23 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce: модель и реализации (14) Реализация в

Слайд 3823 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce: модель и реализации (15)
Реализация в
23 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce: модель и реализации (15) Реализация в

Слайд 3923 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce: модель и реализации (16)
Реализация в
23 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce: модель и реализации (16) Реализация в

Слайд 4023 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce: модель и реализации (17)
Реализация в
23 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce: модель и реализации (17) Реализация в

Слайд 4123 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce: модель и реализации (18)
Реализация в
23 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce: модель и реализации (18) Реализация в

Слайд 4223 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce: модель и реализации (19)
Реализация в
23 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce: модель и реализации (19) Реализация в

Слайд 4323 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce: модель и реализации (20)
Реализация в
23 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce: модель и реализации (20) Реализация в

Слайд 4423 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce: модель и реализации (21)
Расширенные возможности
23 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce: модель и реализации (21) Расширенные возможности

Слайд 4523 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce: модель и реализации (22)
Расширенные возможности
23 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce: модель и реализации (22) Расширенные возможности

Слайд 4623 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce: модель и реализации (23)
Расширенные возможности
23 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce: модель и реализации (23) Расширенные возможности

Слайд 4723 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce: модель и реализации (24)
Расширенные возможности
23 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce: модель и реализации (24) Расширенные возможности

Слайд 4823 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce внутри параллельной СУБД (1)
Очевидны преимущества
23 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce внутри параллельной СУБД (1)
Очевидны преимущества

Слайд 4923 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce внутри параллельной СУБД (2)
Естественно, возникает
23 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce внутри параллельной СУБД (2)
Естественно, возникает

Слайд 5023 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce внутри параллельной СУБД (3)
Поддержка определяемых
23 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce внутри параллельной СУБД (3)
Поддержка определяемых

Слайд 5123 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce внутри параллельной СУБД (4)
Тем не
23 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce внутри параллельной СУБД (4)
Тем не

Слайд 5223 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce внутри параллельной СУБД (5)
Технически можно
23 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce внутри параллельной СУБД (5)
Технически можно

Слайд 5323 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce внутри параллельной СУБД (6)
С другой
23 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce внутри параллельной СУБД (6)
С другой

Слайд 5423 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce внутри параллельной СУБД (7)
Несмотря на
23 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce внутри параллельной СУБД (7)
Несмотря на

Слайд 5523 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce внутри параллельной СУБД (8)
Речь идет
23 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce внутри параллельной СУБД (8)
Речь идет

Слайд 5623 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce внутри параллельной СУБД (9)
Greemplum –
23 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce внутри параллельной СУБД (9) Greemplum –

Слайд 5723 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce внутри параллельной СУБД (10)
Greemplum –
23 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce внутри параллельной СУБД (10) Greemplum –

Слайд 5823 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce внутри параллельной СУБД (11)
Greemplum –
23 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce внутри параллельной СУБД (11) Greemplum –

Слайд 5923 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce внутри параллельной СУБД (12)
Greemplum –
23 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce внутри параллельной СУБД (12) Greemplum –

Слайд 6023 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce внутри параллельной СУБД (13)
Greemplum –
23 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce внутри параллельной СУБД (13) Greemplum –

Слайд 6123 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce внутри параллельной СУБД (14)
Greemplum –
23 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce внутри параллельной СУБД (14) Greemplum –

Слайд 6223 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce внутри параллельной СУБД (15)
Greemplum –
23 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce внутри параллельной СУБД (15) Greemplum –

Слайд 6323 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce внутри параллельной СУБД (16)
Greemplum –
23 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce внутри параллельной СУБД (16) Greemplum –

Слайд 6423 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce внутри параллельной СУБД (17)
Greemplum –
23 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce внутри параллельной СУБД (17) Greemplum –

Слайд 6523 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce внутри параллельной СУБД (18)
Greemplum –
23 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce внутри параллельной СУБД (18) Greemplum –

Слайд 6623 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce внутри параллельной СУБД (18)
Greemplum –
23 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce внутри параллельной СУБД (18) Greemplum –

Слайд 6723 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce внутри параллельной СУБД (19)
Greemplum –
23 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce внутри параллельной СУБД (19) Greemplum –

Слайд 6823 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce внутри параллельной СУБД (20)
Greemplum –
23 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce внутри параллельной СУБД (20) Greemplum –

Слайд 6923 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce внутри параллельной СУБД (21)
Greemplum –
23 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce внутри параллельной СУБД (21) Greemplum –

Слайд 7023 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce внутри параллельной СУБД (22)
Aster Data
23 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce внутри параллельной СУБД (22) Aster Data

Слайд 7123 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce внутри параллельной СУБД (23)
Aster Data
23 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce внутри параллельной СУБД (23) Aster Data

Слайд 7223 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce внутри параллельной СУБД (24)
Aster Data
23 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce внутри параллельной СУБД (24) Aster Data

Слайд 7323 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce внутри параллельной СУБД (25)
Aster Data
23 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce внутри параллельной СУБД (25) Aster Data

Слайд 7423 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce внутри параллельной СУБД (26)
Aster Data
23 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce внутри параллельной СУБД (26) Aster Data

Слайд 7523 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce внутри параллельной СУБД (27)
Aster Data
23 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce внутри параллельной СУБД (27) Aster Data

Слайд 7623 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce внутри параллельной СУБД (28)
Aster Data
23 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce внутри параллельной СУБД (28) Aster Data

Слайд 7723 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce внутри параллельной СУБД (29)
Aster Data
23 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce внутри параллельной СУБД (29) Aster Data

Слайд 7823 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce внутри параллельной СУБД (30)
Aster Data
23 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce внутри параллельной СУБД (30) Aster Data

Слайд 7923 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce внутри параллельной СУБД (31)
Aster Data
23 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce внутри параллельной СУБД (31) Aster Data

Слайд 8023 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce внутри параллельной СУБД (32)
Aster Data
23 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce внутри параллельной СУБД (32) Aster Data

Слайд 8123 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce внутри параллельной СУБД (33)
Aster Data
23 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce внутри параллельной СУБД (33) Aster Data

Слайд 8223 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce внутри параллельной СУБД (34)
Aster Data
23 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce внутри параллельной СУБД (34) Aster Data

Слайд 8323 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce внутри параллельной СУБД (35)
Aster Data
23 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce внутри параллельной СУБД (35) Aster Data

Слайд 8423 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce внутри параллельной СУБД (36)
Aster Data
23 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce внутри параллельной СУБД (36) Aster Data

Слайд 8523 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce внутри параллельной СУБД (37)
Aster Data
23 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce внутри параллельной СУБД (37) Aster Data

Слайд 8623 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce внутри параллельной СУБД (38)
Aster Data
23 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce внутри параллельной СУБД (38) Aster Data

Слайд 8723 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce внутри параллельной СУБД (39)
Aster Data
23 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce внутри параллельной СУБД (39) Aster Data

Слайд 8823 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce внутри параллельной СУБД (40)
Таким образом
23 апреля 2010 г.
Корпоративные базы данных 2010
MapReduce внутри параллельной СУБД (40)
Таким образом

Слайд 8923 апреля 2010 г.
Корпоративные базы данных 2010
Параллельная СУБД на основе MapReduce (1)
В
23 апреля 2010 г.
Корпоративные базы данных 2010
Параллельная СУБД на основе MapReduce (1)
В

Слайд 9023 апреля 2010 г.
Корпоративные базы данных 2010
Параллельная СУБД на основе MapReduce (2)
Однако
23 апреля 2010 г.
Корпоративные базы данных 2010
Параллельная СУБД на основе MapReduce (2)
Однако

Слайд 9123 апреля 2010 г.
Корпоративные базы данных 2010
Параллельная СУБД на основе MapReduce (3)
Это
23 апреля 2010 г.
Корпоративные базы данных 2010
Параллельная СУБД на основе MapReduce (3)
Это

Слайд 9223 апреля 2010 г.
Корпоративные базы данных 2010
Параллельная СУБД на основе MapReduce (4)
Требуемые
23 апреля 2010 г.
Корпоративные базы данных 2010
Параллельная СУБД на основе MapReduce (4)
Требуемые

Слайд 9323 апреля 2010 г.
Корпоративные базы данных 2010
Параллельная СУБД на основе MapReduce (5)
Однако
23 апреля 2010 г.
Корпоративные базы данных 2010
Параллельная СУБД на основе MapReduce (5)
Однако

Слайд 9423 апреля 2010 г.
Корпоративные базы данных 2010
Параллельная СУБД на основе MapReduce (6)
В
23 апреля 2010 г.
Корпоративные базы данных 2010
Параллельная СУБД на основе MapReduce (6)
В

Слайд 9523 апреля 2010 г.
Корпоративные базы данных 2010
Параллельная СУБД на основе MapReduce (7)
Общая
23 апреля 2010 г.
Корпоративные базы данных 2010
Параллельная СУБД на основе MapReduce (7) Общая
Слайд 9623 апреля 2010 г.
Корпоративные базы данных 2010
Параллельная СУБД на основе MapReduce (8)
Общая
23 апреля 2010 г.
Корпоративные базы данных 2010
Параллельная СУБД на основе MapReduce (8) Общая

Слайд 9723 апреля 2010 г.
Корпоративные базы данных 2010
Параллельная СУБД на основе MapReduce (9)
Общая
23 апреля 2010 г.
Корпоративные базы данных 2010
Параллельная СУБД на основе MapReduce (9) Общая

Слайд 9823 апреля 2010 г.
Корпоративные базы данных 2010
Параллельная СУБД на основе MapReduce (10)
Общая
23 апреля 2010 г.
Корпоративные базы данных 2010
Параллельная СУБД на основе MapReduce (10) Общая

Слайд 9923 апреля 2010 г.
Корпоративные базы данных 2010
Параллельная СУБД на основе MapReduce (11)
Общая
23 апреля 2010 г.
Корпоративные базы данных 2010
Параллельная СУБД на основе MapReduce (11) Общая

Слайд 10023 апреля 2010 г.
Корпоративные базы данных 2010
Параллельная СУБД на основе MapReduce (12)
Общая
23 апреля 2010 г.
Корпоративные базы данных 2010
Параллельная СУБД на основе MapReduce (12) Общая

Слайд 10123 апреля 2010 г.
Корпоративные базы данных 2010
Параллельная СУБД на основе MapReduce (13)
Общая
23 апреля 2010 г.
Корпоративные базы данных 2010
Параллельная СУБД на основе MapReduce (13) Общая

Слайд 10223 апреля 2010 г.
Корпоративные базы данных 2010
Параллельная СУБД на основе MapReduce (14)
Общая
23 апреля 2010 г.
Корпоративные базы данных 2010
Параллельная СУБД на основе MapReduce (14) Общая

Слайд 10323 апреля 2010 г.
Корпоративные базы данных 2010
Параллельная СУБД на основе MapReduce (15)
Общая
23 апреля 2010 г.
Корпоративные базы данных 2010
Параллельная СУБД на основе MapReduce (15) Общая

Слайд 10423 апреля 2010 г.
Корпоративные базы данных 2010
Параллельная СУБД на основе MapReduce (16)
Общая
23 апреля 2010 г.
Корпоративные базы данных 2010
Параллельная СУБД на основе MapReduce (16) Общая

Слайд 10523 апреля 2010 г.
Корпоративные базы данных 2010
Параллельная СУБД на основе MapReduce (17)
Общая
23 апреля 2010 г.
Корпоративные базы данных 2010
Параллельная СУБД на основе MapReduce (17) Общая

Слайд 10623 апреля 2010 г.
Корпоративные базы данных 2010
Параллельная СУБД на основе MapReduce (18)
Общая
23 апреля 2010 г.
Корпоративные базы данных 2010
Параллельная СУБД на основе MapReduce (18) Общая

Слайд 10723 апреля 2010 г.
Корпоративные базы данных 2010
Параллельная СУБД на основе MapReduce (19)
Общая
23 апреля 2010 г.
Корпоративные базы данных 2010
Параллельная СУБД на основе MapReduce (19) Общая

Слайд 10823 апреля 2010 г.
Корпоративные базы данных 2010
Параллельная СУБД на основе MapReduce (20)
Общая
23 апреля 2010 г.
Корпоративные базы данных 2010
Параллельная СУБД на основе MapReduce (20) Общая

Слайд 10923 апреля 2010 г.
Корпоративные базы данных 2010
Параллельная СУБД на основе MapReduce (21)
Общая
23 апреля 2010 г.
Корпоративные базы данных 2010
Параллельная СУБД на основе MapReduce (21) Общая

Слайд 11023 апреля 2010 г.
Корпоративные базы данных 2010
Параллельная СУБД на основе MapReduce (22)
Общая
23 апреля 2010 г.
Корпоративные базы данных 2010
Параллельная СУБД на основе MapReduce (22) Общая

Слайд 11123 апреля 2010 г.
Корпоративные базы данных 2010
Параллельная СУБД на основе MapReduce (23)
Общая
23 апреля 2010 г.
Корпоративные базы данных 2010
Параллельная СУБД на основе MapReduce (23) Общая

Слайд 11223 апреля 2010 г.
Корпоративные базы данных 2010
Параллельная СУБД на основе MapReduce (24)
Общая
23 апреля 2010 г.
Корпоративные базы данных 2010
Параллельная СУБД на основе MapReduce (24) Общая

Слайд 11323 апреля 2010 г.
Корпоративные базы данных 2010
Параллельная СУБД на основе MapReduce (25)
Общая
23 апреля 2010 г.
Корпоративные базы данных 2010
Параллельная СУБД на основе MapReduce (25) Общая

Слайд 11423 апреля 2010 г.
Корпоративные базы данных 2010
Параллельная СУБД на основе MapReduce (26)
Общая
23 апреля 2010 г.
Корпоративные базы данных 2010
Параллельная СУБД на основе MapReduce (26) Общая

Слайд 11523 апреля 2010 г.
Корпоративные базы данных 2010
Параллельная СУБД на основе MapReduce (27)
Общая
23 апреля 2010 г.
Корпоративные базы данных 2010
Параллельная СУБД на основе MapReduce (27) Общая

Слайд 11623 апреля 2010 г.
Корпоративные базы данных 2010
Параллельная СУБД на основе MapReduce (28)
Характеристики
23 апреля 2010 г.
Корпоративные базы данных 2010
Параллельная СУБД на основе MapReduce (28) Характеристики

Слайд 11723 апреля 2010 г.
Корпоративные базы данных 2010
Параллельная СУБД на основе MapReduce (29)
Характеристики
23 апреля 2010 г.
Корпоративные базы данных 2010
Параллельная СУБД на основе MapReduce (29) Характеристики

Слайд 11823 апреля 2010 г.
Корпоративные базы данных 2010
Параллельная СУБД на основе MapReduce (30)
Характеристики
23 апреля 2010 г.
Корпоративные базы данных 2010
Параллельная СУБД на основе MapReduce (30) Характеристики

Слайд 11923 апреля 2010 г.
Корпоративные базы данных 2010
Параллельная СУБД на основе MapReduce (31)
Характеристики
23 апреля 2010 г.
Корпоративные базы данных 2010
Параллельная СУБД на основе MapReduce (31) Характеристики

Слайд 12023 апреля 2010 г.
Корпоративные базы данных 2010
Параллельная СУБД на основе MapReduce (32)
Характеристики
23 апреля 2010 г.
Корпоративные базы данных 2010
Параллельная СУБД на основе MapReduce (32) Характеристики

Слайд 12123 апреля 2010 г.
Корпоративные базы данных 2010
Параллельная СУБД на основе MapReduce (33)
Характеристики
23 апреля 2010 г.
Корпоративные базы данных 2010
Параллельная СУБД на основе MapReduce (33) Характеристики

Слайд 12223 апреля 2010 г.
Корпоративные базы данных 2010
Параллельная СУБД на основе MapReduce (34)
Характеристики
23 апреля 2010 г.
Корпоративные базы данных 2010
Параллельная СУБД на основе MapReduce (34) Характеристики

Слайд 12323 апреля 2010 г.
Корпоративные базы данных 2010
Параллельная СУБД на основе MapReduce (35)
Характеристики
23 апреля 2010 г.
Корпоративные базы данных 2010
Параллельная СУБД на основе MapReduce (35) Характеристики

Слайд 12423 апреля 2010 г.
Корпоративные базы данных 2010
Параллельная СУБД на основе MapReduce (36)
Проект
23 апреля 2010 г.
Корпоративные базы данных 2010
Параллельная СУБД на основе MapReduce (36)
Проект

Слайд 12523 апреля 2010 г.
Корпоративные базы данных 2010
ETL с использованием MapReduce (1)
Различных средств
23 апреля 2010 г.
Корпоративные базы данных 2010
ETL с использованием MapReduce (1)
Различных средств

Слайд 12623 апреля 2010 г.
Корпоративные базы данных 2010
ETL с использованием MapReduce (2)
Можно согласиться,
23 апреля 2010 г.
Корпоративные базы данных 2010
ETL с использованием MapReduce (2)
Можно согласиться,

Слайд 12723 апреля 2010 г.
Корпоративные базы данных 2010
ETL с использованием MapReduce (3)
Итак, что
23 апреля 2010 г.
Корпоративные базы данных 2010
ETL с использованием MapReduce (3)
Итак, что

Слайд 12823 апреля 2010 г.
Корпоративные базы данных 2010
ETL с использованием MapReduce (4)
MapReduce и
23 апреля 2010 г.
Корпоративные базы данных 2010
ETL с использованием MapReduce (4) MapReduce и

Слайд 12923 апреля 2010 г.
Корпоративные базы данных 2010
ETL с использованием MapReduce (5)
MapReduce и
23 апреля 2010 г.
Корпоративные базы данных 2010
ETL с использованием MapReduce (5) MapReduce и

Слайд 13023 апреля 2010 г.
Корпоративные базы данных 2010
ETL с использованием MapReduce (6)
MapReduce и
23 апреля 2010 г.
Корпоративные базы данных 2010
ETL с использованием MapReduce (6) MapReduce и

Слайд 13123 апреля 2010 г.
Корпоративные базы данных 2010
ETL с использованием MapReduce (7)
Hadoop и
23 апреля 2010 г.
Корпоративные базы данных 2010
ETL с использованием MapReduce (7) Hadoop и

Слайд 13223 апреля 2010 г.
Корпоративные базы данных 2010
ETL с использованием MapReduce (8)
Hadoop и
23 апреля 2010 г.
Корпоративные базы данных 2010
ETL с использованием MapReduce (8) Hadoop и

Слайд 13323 апреля 2010 г.
Корпоративные базы данных 2010
ETL с использованием MapReduce (9)
Скорее всего,
23 апреля 2010 г.
Корпоративные базы данных 2010
ETL с использованием MapReduce (9)
Скорее всего,

Слайд 13423 апреля 2010 г.
Корпоративные базы данных 2010
Заключение (1)
Еще пару лет назад было
23 апреля 2010 г.
Корпоративные базы данных 2010
Заключение (1)
Еще пару лет назад было

Слайд 13523 апреля 2010 г.
Корпоративные базы данных 2010
Заключение (2)
Однако вскоре стало понятно, что
23 апреля 2010 г.
Корпоративные базы данных 2010
Заключение (2)
Однако вскоре стало понятно, что

Слайд 13623 апреля 2010 г.
Корпоративные базы данных 2010
Заключение (3)
На сегодняшний день уже понятно,
23 апреля 2010 г.
Корпоративные базы данных 2010
Заключение (3)
На сегодняшний день уже понятно,

Слайд 13723 апреля 2010 г.
Корпоративные базы данных 2010
Заключение (4)
Интересные работы ведутся и в
23 апреля 2010 г.
Корпоративные базы данных 2010
Заключение (4)
Интересные работы ведутся и в

Слайд 13823 апреля 2010 г.
Корпоративные базы данных 2010
Заключение (5)
Полный текст:
Сергей Кузнецов. MapReduce: внутри,
23 апреля 2010 г.
Корпоративные базы данных 2010
Заключение (5)
Полный текст:
Сергей Кузнецов. MapReduce: внутри,

 Судебный этикет как составляющая культуры уголовно-процессуальной деятельности. Нормативные основы судебного этикета
Судебный этикет как составляющая культуры уголовно-процессуальной деятельности. Нормативные основы судебного этикета Оружие массового поражения
Оружие массового поражения Модельный ряд грузовых автомобилей Mercedes-Benz
Модельный ряд грузовых автомобилей Mercedes-Benz Энергетика: вчера, сегодня, завтра
Энергетика: вчера, сегодня, завтра ГИИС ЭБ. Запрос на аннулирование
ГИИС ЭБ. Запрос на аннулирование Элементы интернет-маркетинга и их взаимодействие
Элементы интернет-маркетинга и их взаимодействие 1. ОСНОВНЫЕ ПОНЯТИЯ Компьютерный исполнитель – это виртуальный объект, действующий в виртуальной среде обитания. Примеры: –Чертеж
1. ОСНОВНЫЕ ПОНЯТИЯ Компьютерный исполнитель – это виртуальный объект, действующий в виртуальной среде обитания. Примеры: –Чертеж Beerfest
Beerfest Красота осени
Красота осени Социально-психологическая служба в школе
Социально-психологическая служба в школе Как принимать управленческие решения
Как принимать управленческие решения Денежные переводы в Республике Таджикистан
Денежные переводы в Республике Таджикистан Темы в Drupal 6 Что нового, и чем оно грозит
Темы в Drupal 6 Что нового, и чем оно грозит Память в камне
Память в камне Помещение для открытия магазина Белорусская косметика
Помещение для открытия магазина Белорусская косметика Огневая подготовка. Версия 3
Огневая подготовка. Версия 3 Горный Дагестан
Горный Дагестан Методические рекомендации по введению модульной системы и системы зачетных единиц Методические рекомендации по разработке рабо
Методические рекомендации по введению модульной системы и системы зачетных единиц Методические рекомендации по разработке рабо Внутренний мир болезни
Внутренний мир болезни Техническое обслуживание и ремонт трансформатора ТДТНГ 40500\115\38,5\6,6 кВ Смоленск – 1
Техническое обслуживание и ремонт трансформатора ТДТНГ 40500\115\38,5\6,6 кВ Смоленск – 1 Кинестетик
Кинестетик Илья Ефимович Репин –великий русский художник
Илья Ефимович Репин –великий русский художник Václavské náměstí
Václavské náměstí Презентация на тему Иван третий (4 класс)
Презентация на тему Иван третий (4 класс) 11 причин инвестировать в Свердловскую область
11 причин инвестировать в Свердловскую область Технология установки врезного замка
Технология установки врезного замка Религия и мораль
Религия и мораль Караевское сельское поселение. Золотые руки мастера по бисероплетению
Караевское сельское поселение. Золотые руки мастера по бисероплетению