- Обеспечение непрерывности бизнесаASE 15.5 cluster edition

Содержание
- 2. ПОНЯТИЕ «НЕПРЕРЫВНОСТИ БИЗНЕСА» (BUSINESS CONTINUITY) Кампус-кластер – все сервера находятся в одном ЦОДе Метро-кластер – сервера
- 3. РЕШЕНИЯ ДЛЯ НЕПРЕРЫВНОСТИ БИЗНЕСА Технологии непрерывности бизнеса для создания территориально распределенных DR-решений Технологии непрерывности бизнеса для
- 4. SYBASE REPLICATION SERVER WARM STANDBY РЕШЕНИЕ DISASTER RECOVERY (МЕТРО-КЛАСТЕР) РЕШЕНИЕ Организация «Зеркальной» базы данных, непрерывно реплицируемой
- 5. SYBASE REPLICATION SERVER НЕМНОГО О ПРОДУКТЕ Sybase является Пионером в технологии Репликации. Sybase имеет более чем
- 6. SYBASE REPLICATION SERVER НЕМНОГО О ПРОДУКТЕ Москва, головной офис Система управления заказами ASE Rep Server Rep
- 7. SYBASE MIRROR ACTIVATOR РЕШЕНИЕ DISASTER RECOVERY (МЕТРО-КЛАСТЕР) Sybase Mirror Activator – это DR-решение нового поколения для
- 8. SYBASE MIRROR ACTIVATOR РЕШЕНИЕ DISASTER RECOVERY (МЕТРО-КЛАСТЕР) Sybase ASE Sybase Mirror Activator Агент Sybase Replication Server
- 9. РЕШЕНИЕ HIGH AVAILABILITY (КАМПУС-КЛАСТЕР) SYBASE ASE CLUSTER EDITION
- 10. ASE CLUSTER EDITION - ЧТО ЭТО ТАКОЕ? Специальная кластерная редакция ASE (Shared Disk Cluster) Архитектура поддерживает
- 11. НЕМНОГО ИСТОРИИ Декабрь 2007: ASE CE 15.0.1 первая версия ASE Cluster Edition Solaris & Linux First
- 12. ASE CLUSTER EDITION – ДЛЯ ЧЕГО ОН? Бесперебойность работы критичных систем Защита систем от простоев, вызванных
- 13. СЦЕНАРИЙ ИСПОЛЬЗОВАНИЯ №1: БЕСПЕРЕБОЙНОСТЬ РАБОТЫ ДЛЯ КРИТИЧНЫХ СИСТЕМ Для кого: для тех, кто отвечает за жизненно-важные
- 14. ПРЕИМУЩЕСТВО ASE CLUSTER EDITION ПО СРАВНЕНИЮ С ОБЫЧНЫМ ASE/HA
- 15. ПростаивающиеStand-by сервера Более полное использование имеющего оборудования Слабо загруженные сервера департаментов Мощности Standby-серверов не используются Больше
- 16. СЦЕНАРИЙ ИСПОЛЬЗОВАНИЯ №2 КОНСОЛИДАЦИЯ ПРИЛОЖЕНИЙ Для кого: для тех, у кого в организации есть множество ASE-систем,
- 17. Для кого: для тех, кто использует дорогостоящие Hi-End –сервера для ASE-приложений Что дает вам ASE Cluster
- 18. КЛИЕНТЫ
- 19. ASE 15.5 CLUSTER EDITION УСТРОЙСТВО КЛАСТЕРА
- 20. ASE CE: ВСЕ КОМПОНЕНТЫ Public Network Private Interconnects $SYBASE .cfg CFS (или NFS) Кворум (raw -
- 21. ПОДДЕРЖИВАЕМЫЕ ПЛАТФОРМЫ Поддерживаются только 64-битные платформы RISC UNIX архитектура Solaris SPARC 64-bit Solaris 9 Solaris10 IBM
- 22. ТРЕБОВАНИЯ К H/W Оборудование и ОС Все узлы должны иметь одну платформу и ОС Наполнение может
- 23. СХЕМА ПОДКЛЮЧЕНИЯ Primary Private Secondary Private Public Network Storage Network
- 24. БАЗЫ ДАННЫХ В КЛАСТЕРЕ Системные базы данных Одна(1) совместно используемая копия: master, model, sybsystemprocs, etc Временные
- 25. АРХИТЕКТУРА КЛАСТЕРА ASE CE An Instance Kernel Data Service Cluster Lock Management Buffer Cache Coherency Object
- 26. ASE 15.5 CLUSTER EDITION РАБОТА КЛАСТЕРА
- 27. VIRTUALIZED RESOURCE MANAGEMENT™ Логические кластеры Приложения Физические кластеры Workload Manager
- 28. WORKLOAD MANAGER Workload Manager(менеджер нагрузки) – одна из важнейших подсистем ASE Сluster Edition Позволяет управлять нагрузкой
- 29. ЛОГИЧЕСКИЕ КЛАСТЕРЫ Логические кластеры – это ключевой элемент в системе управления нагрузкой (workload manager subsystem) Служат
- 30. КОМПОНЕНТЫ WORKLOAD MANAGER CUSTSVC SALES SHIPPING Правила перенаправления клиентов (приложение, имя сервера, логин) Профили нагрузки ЛОГИЧЕСКИЕ
- 31. ПРОФИЛИ НАГРУЗКИ Менеджер нагрузки также отвечает за распределение нагрузки по серверам кластера Следит, чтобы не происходил
- 32. ЛОГИЧЕСКИЙ КЛАСТЕР ? ПРОФИЛЬ НАГРУЗКИ: МЕТРИКИ НАГРУЗКИ И ВЕСА
- 33. ЛОГИЧЕСКИЙ КЛАСТЕР ? ПРОФИЛЬ НАГРУЗКИ: ПОРОГОВЫЕ ЗНАЧЕНИЯ
- 34. ЛОГИЧЕСКИЙ КЛАСТЕР & ПРОФИЛЬ НАГРУЗКИ
- 35. МЕТРИКИ ПРОФИЛЯ НАГРУЗКИ В стандартном профиле нагрузки sybase_profile_oltp самый высокий вес имеет метрика Run Queue. В
- 36. МОНИТОРИНГ НАГРУЗКИ Решение о необходимости миграции соединений менеджер нагрузки принимает, основываясь на суммарной оценке (Load Score)Connection,
- 37. ЛОГИЧЕСКИЕ КЛАСТЕРЫ И АВАРИЙНОЕ ПЕРЕКЛЮЧЕНИЕ (FAILOVER) Ресурсы для FAILOVER Список ASE-серверов или групп ASE-серверов, на которые
- 38. ЛОГИЧЕСКИЙ КЛАСТЕР: ОБРАБОТКА АВАРИИ CUSTSVC Базовые ASE-сервера: SYBASE_1 SYBASE_2 Резервные ASE-сервера: SYBASE_3 SYBASE_4 Режим: GROUP SALES
- 39. ЛОГИЧЕСКИЙ КЛАСТЕР. ОБРАБОТКА АВАРИИ: АВАРИЯ СЕРВЕРА #3 CUSTSVC Не затронут SALES Аварийная замена Сервера: Т.к. Failover-режим
- 40. ЛОГИЧЕСКИЙ КЛАСТЕР. ОБРАБОТКА АВАРИИ: АВАРИЯ СЕРВЕРА #4 (СЕРВЕР #4 ОТКЛЮЧЕН) CUSTSVC Не затронут SALES Аварийный перевод
- 41. ЛОГИЧЕСКИЙ КЛАСТЕР. ОБРАБОТКА АВАРИИ: АВАРИЯ СЕРВЕРА #1 (#3 И #4 ОТКЛЮЧЕНЫ) CUSTSVC Аварийный перевод соединений SALES
- 42. НОВЫЕ КЛИЕНТСКИЕ ТЕХНОЛОГИИ Новые клиентские технологии Позволяют клиенту иметь логическое соединение с кластером, оставаясь при этом
- 43. ПЕРЕНАПРАВЛЕНИЕ ЛОГИНОВ Происходит в момент подключения Если данный ASE-сервер перегружен работой, он говорит клиенту подключиться на
- 44. МИГРАЦИЯ СОЕДИНЕНИЙ Перенос существующих клиентских соединения с одного ASE-сервера на другой Позволяет Workload Manager корректно переводить
- 45. ОТЛИЧИЕ МИГРАЦИИ СОЕДИНЕНИЯ ОТ АВАРИЙНОГО ПЕРЕКЛЮЧЕНИЯ СОЕДИНЕНИЯ Миграция или аварийное переключение (Failover) Миграция это плановое контролируемое
- 46. ЗАКЛЮЧЕНИЕ – ASE CLUSTER EDITION … Способен защитить от нескольких одновременных аварий, обеспечивая быстрое переключение клиентов
- 48. Скачать презентацию
Слайд 2ПОНЯТИЕ «НЕПРЕРЫВНОСТИ БИЗНЕСА» (BUSINESS CONTINUITY)
Кампус-кластер – все сервера находятся в одном ЦОДе
Метро-кластер
ПОНЯТИЕ «НЕПРЕРЫВНОСТИ БИЗНЕСА» (BUSINESS CONTINUITY)
Кампус-кластер – все сервера находятся в одном ЦОДе
Метро-кластер

Слайд 3РЕШЕНИЯ ДЛЯ НЕПРЕРЫВНОСТИ БИЗНЕСА
Технологии непрерывности бизнеса для создания
территориально распределенных DR-решений
Технологии непрерывности
РЕШЕНИЯ ДЛЯ НЕПРЕРЫВНОСТИ БИЗНЕСА
Технологии непрерывности бизнеса для создания
территориально распределенных DR-решений
Технологии непрерывности
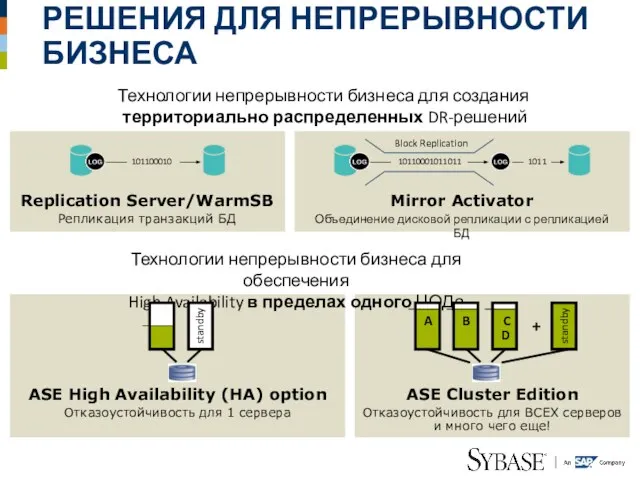
Слайд 4SYBASE REPLICATION SERVER WARM STANDBY
РЕШЕНИЕ DISASTER RECOVERY (МЕТРО-КЛАСТЕР)
РЕШЕНИЕ
Организация «Зеркальной» базы данных,
SYBASE REPLICATION SERVER WARM STANDBY
РЕШЕНИЕ DISASTER RECOVERY (МЕТРО-КЛАСТЕР)
РЕШЕНИЕ
Организация «Зеркальной» базы данных,
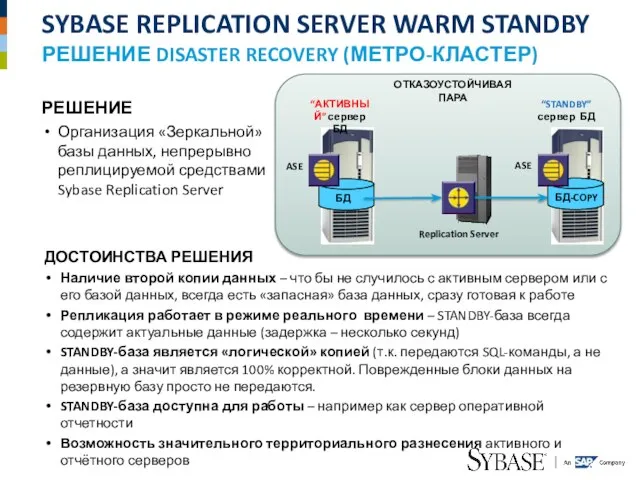
Слайд 5SYBASE REPLICATION SERVER
НЕМНОГО О ПРОДУКТЕ
Sybase является Пионером в технологии Репликации.
Sybase имеет
SYBASE REPLICATION SERVER
НЕМНОГО О ПРОДУКТЕ
Sybase является Пионером в технологии Репликации.
Sybase имеет

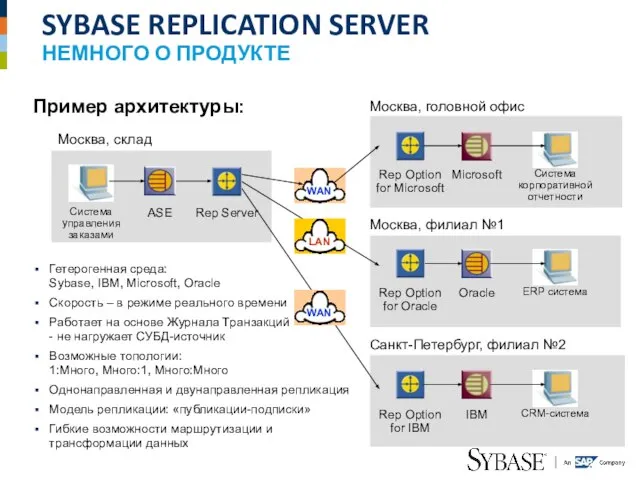
Слайд 6SYBASE REPLICATION SERVER
НЕМНОГО О ПРОДУКТЕ
Москва, головной офис
Система
управления
заказами
ASE
Rep Server
Rep Option
for Microsoft
Microsoft
Система
SYBASE REPLICATION SERVER
НЕМНОГО О ПРОДУКТЕ
Москва, головной офис
Система
управления
заказами
ASE
Rep Server
Rep Option
for Microsoft
Microsoft
Система
Слайд 7SYBASE MIRROR ACTIVATOR
РЕШЕНИЕ DISASTER RECOVERY (МЕТРО-КЛАСТЕР)
Sybase Mirror Activator – это DR-решение нового
SYBASE MIRROR ACTIVATOR
РЕШЕНИЕ DISASTER RECOVERY (МЕТРО-КЛАСТЕР)
Sybase Mirror Activator – это DR-решение нового

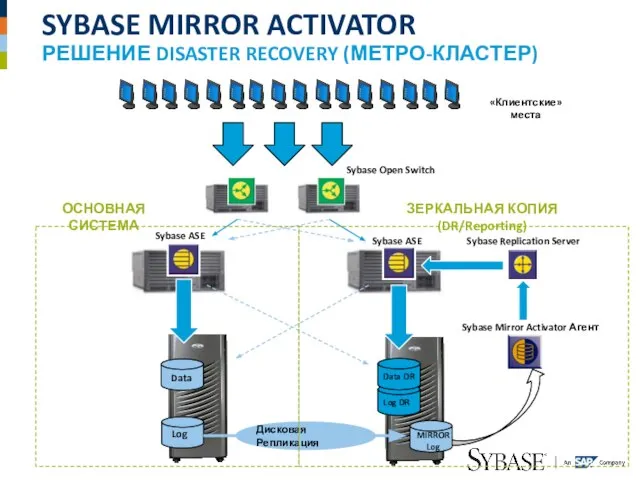
Слайд 8SYBASE MIRROR ACTIVATOR
РЕШЕНИЕ DISASTER RECOVERY (МЕТРО-КЛАСТЕР)
Sybase ASE
Sybase Mirror Activator Агент
Sybase Replication Server
Sybase
SYBASE MIRROR ACTIVATOR
РЕШЕНИЕ DISASTER RECOVERY (МЕТРО-КЛАСТЕР)
Sybase ASE
Sybase Mirror Activator Агент
Sybase Replication Server
Sybase
Слайд 9РЕШЕНИЕ HIGH AVAILABILITY (КАМПУС-КЛАСТЕР)
SYBASE ASE CLUSTER EDITION
РЕШЕНИЕ HIGH AVAILABILITY (КАМПУС-КЛАСТЕР)
SYBASE ASE CLUSTER EDITION

Слайд 10ASE CLUSTER EDITION - ЧТО ЭТО ТАКОЕ?
Специальная кластерная редакция ASE (Shared Disk
ASE CLUSTER EDITION - ЧТО ЭТО ТАКОЕ?
Специальная кластерная редакция ASE (Shared Disk

Слайд 11НЕМНОГО ИСТОРИИ
Декабрь 2007: ASE CE 15.0.1
первая версия ASE Cluster Edition
Solaris &
НЕМНОГО ИСТОРИИ
Декабрь 2007: ASE CE 15.0.1
первая версия ASE Cluster Edition
Solaris &

Слайд 12ASE CLUSTER EDITION – ДЛЯ ЧЕГО ОН?
Бесперебойность работы критичных систем
Защита систем от
ASE CLUSTER EDITION – ДЛЯ ЧЕГО ОН?
Бесперебойность работы критичных систем
Защита систем от

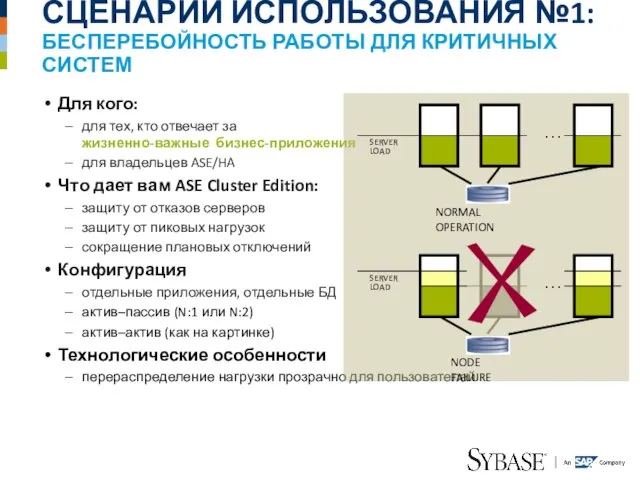
Слайд 13СЦЕНАРИЙ ИСПОЛЬЗОВАНИЯ №1:
БЕСПЕРЕБОЙНОСТЬ РАБОТЫ ДЛЯ КРИТИЧНЫХ СИСТЕМ
Для кого:
для тех, кто отвечает за
СЦЕНАРИЙ ИСПОЛЬЗОВАНИЯ №1:
БЕСПЕРЕБОЙНОСТЬ РАБОТЫ ДЛЯ КРИТИЧНЫХ СИСТЕМ
Для кого:
для тех, кто отвечает за
Слайд 14ПРЕИМУЩЕСТВО ASE CLUSTER EDITION ПО СРАВНЕНИЮ С ОБЫЧНЫМ ASE/HA
ПРЕИМУЩЕСТВО ASE CLUSTER EDITION ПО СРАВНЕНИЮ С ОБЫЧНЫМ ASE/HA

Слайд 15ПростаивающиеStand-by
сервера
Более полное использование имеющего оборудования
Слабо загруженные сервера департаментов
Мощности Standby-серверов не используются
Больше
ПростаивающиеStand-by
сервера
Более полное использование имеющего оборудования
Слабо загруженные сервера департаментов
Мощности Standby-серверов не используются
Больше

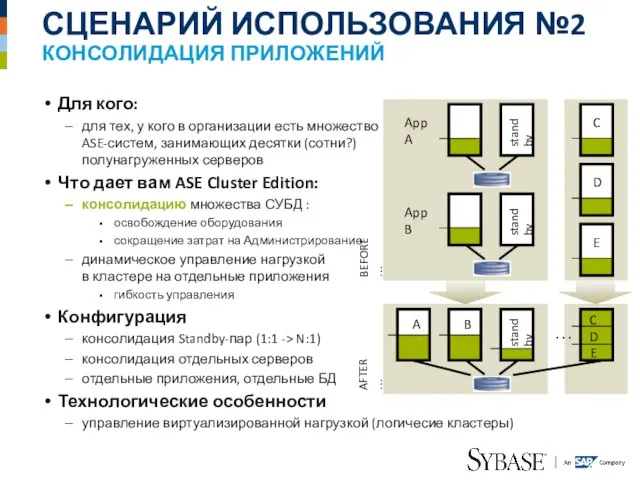
Слайд 16СЦЕНАРИЙ ИСПОЛЬЗОВАНИЯ №2
КОНСОЛИДАЦИЯ ПРИЛОЖЕНИЙ
Для кого:
для тех, у кого в организации есть множество
СЦЕНАРИЙ ИСПОЛЬЗОВАНИЯ №2
КОНСОЛИДАЦИЯ ПРИЛОЖЕНИЙ
Для кого:
для тех, у кого в организации есть множество
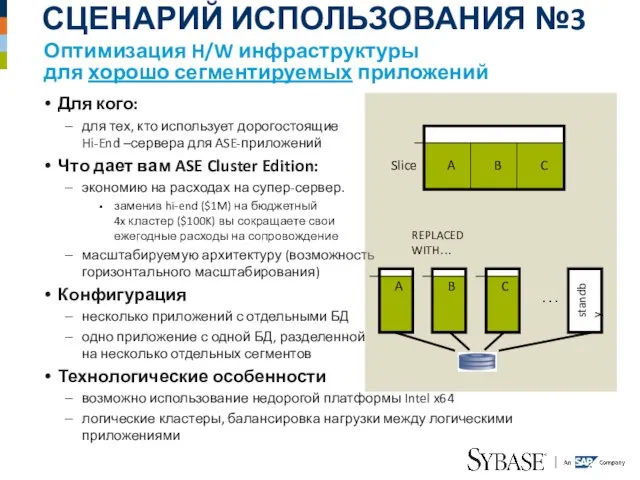
Слайд 17Для кого:
для тех, кто использует дорогостоящие
Hi-End –сервера для ASE-приложений
Что дает вам
Для кого:
для тех, кто использует дорогостоящие
Hi-End –сервера для ASE-приложений
Что дает вам
Слайд 18КЛИЕНТЫ
КЛИЕНТЫ

Слайд 19ASE 15.5 CLUSTER EDITION
УСТРОЙСТВО КЛАСТЕРА
ASE 15.5 CLUSTER EDITION
УСТРОЙСТВО КЛАСТЕРА

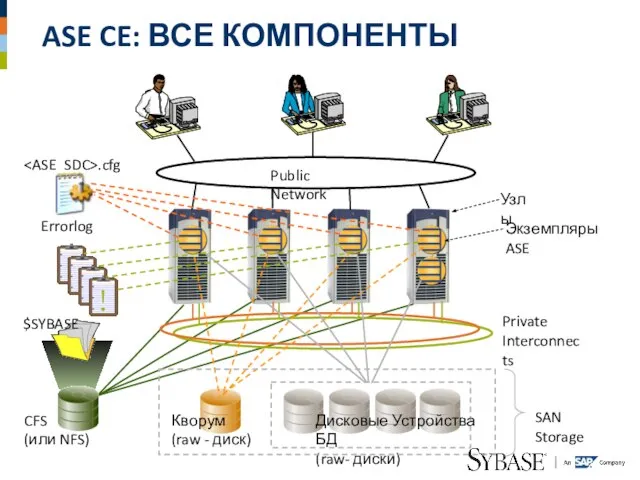
Слайд 20ASE CE: ВСЕ КОМПОНЕНТЫ
Public Network
Private
Interconnects
$SYBASE
.cfg
CFS
(или NFS)
Кворум
(raw - диск)
Дисковые Устройства БД
(raw-
ASE CE: ВСЕ КОМПОНЕНТЫ
Public Network
Private
Interconnects
$SYBASE
CFS Кворум Дисковые Устройства БД
(или NFS)
(raw - диск)
(raw-
Слайд 21ПОДДЕРЖИВАЕМЫЕ ПЛАТФОРМЫ
Поддерживаются только 64-битные платформы
RISC UNIX архитектура
Solaris SPARC 64-bit
Solaris 9
Solaris10
IBM AIX (pSeries)
AIX
ПОДДЕРЖИВАЕМЫЕ ПЛАТФОРМЫ
Поддерживаются только 64-битные платформы
RISC UNIX архитектура
Solaris SPARC 64-bit
Solaris 9
Solaris10
IBM AIX (pSeries)
AIX

Слайд 22ТРЕБОВАНИЯ К H/W
Оборудование и ОС
Все узлы должны иметь одну платформу и ОС
Наполнение
ТРЕБОВАНИЯ К H/W
Оборудование и ОС
Все узлы должны иметь одну платформу и ОС
Наполнение

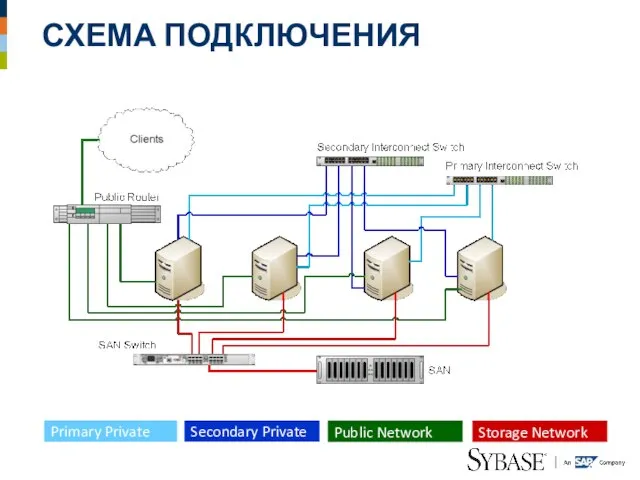
Слайд 23СХЕМА ПОДКЛЮЧЕНИЯ
Primary Private
Secondary Private
Public Network
Storage Network
СХЕМА ПОДКЛЮЧЕНИЯ
Primary Private
Secondary Private
Public Network
Storage Network
Слайд 24БАЗЫ ДАННЫХ В КЛАСТЕРЕ
Системные базы данных
Одна(1) совместно используемая копия: master, model, sybsystemprocs,
БАЗЫ ДАННЫХ В КЛАСТЕРЕ
Системные базы данных
Одна(1) совместно используемая копия: master, model, sybsystemprocs,

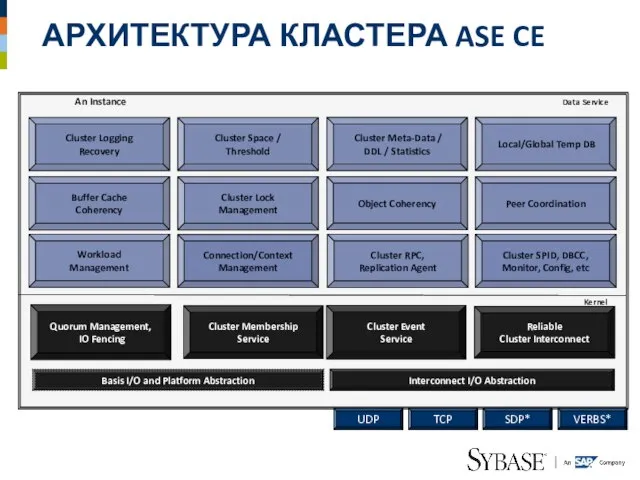
Слайд 25АРХИТЕКТУРА КЛАСТЕРА ASE CE
An Instance
Kernel
Data Service
Cluster Lock
Management
Buffer Cache
Coherency
Object Coherency
Cluster Space
АРХИТЕКТУРА КЛАСТЕРА ASE CE
An Instance
Kernel
Data Service
Cluster Lock
Management
Buffer Cache
Coherency
Object Coherency
Cluster Space
Слайд 26ASE 15.5 CLUSTER EDITION
РАБОТА КЛАСТЕРА
ASE 15.5 CLUSTER EDITION
РАБОТА КЛАСТЕРА

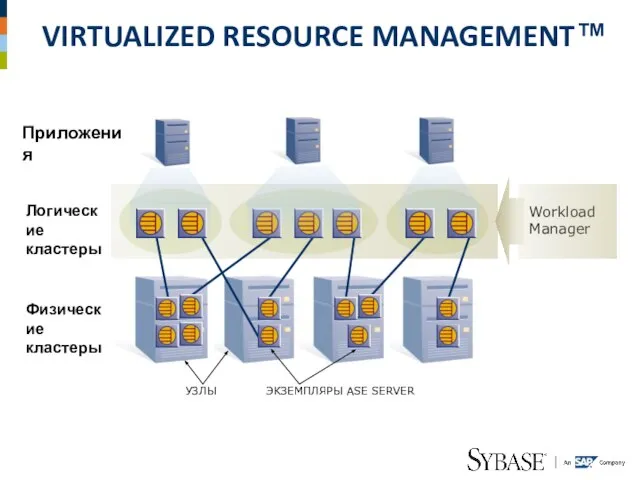
Слайд 27VIRTUALIZED RESOURCE MANAGEMENT™
Логические
кластеры
Приложения
Физические
кластеры
Workload
Manager
VIRTUALIZED RESOURCE MANAGEMENT™
Логические
кластеры
Приложения
Физические
кластеры
Workload
Manager
Слайд 28WORKLOAD MANAGER
Workload Manager(менеджер нагрузки) – одна из важнейших подсистем ASE Сluster Edition
Позволяет
WORKLOAD MANAGER
Workload Manager(менеджер нагрузки) – одна из важнейших подсистем ASE Сluster Edition
Позволяет

Слайд 29ЛОГИЧЕСКИЕ КЛАСТЕРЫ
Логические кластеры – это ключевой элемент в системе управления нагрузкой (workload
ЛОГИЧЕСКИЕ КЛАСТЕРЫ
Логические кластеры – это ключевой элемент в системе управления нагрузкой (workload

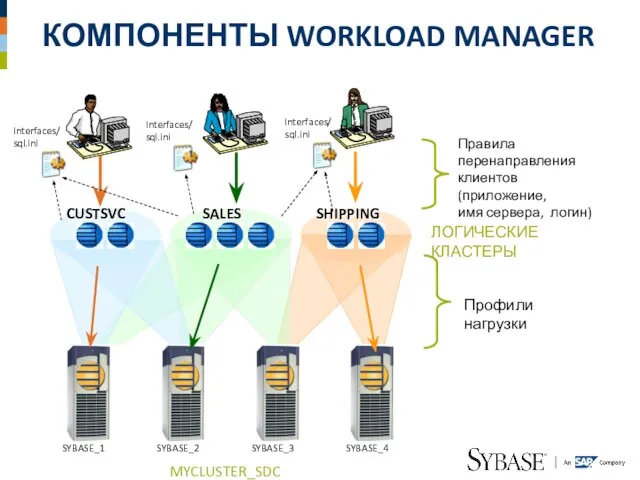
Слайд 30КОМПОНЕНТЫ WORKLOAD MANAGER
CUSTSVC
SALES
SHIPPING
Правила перенаправления клиентов
(приложение,
имя сервера, логин)
Профили нагрузки
ЛОГИЧЕСКИЕ КЛАСТЕРЫ
Interfaces/
sql.ini
Interfaces/
sql.ini
Interfaces/
sql.ini
MYCLUSTER_SDC
КОМПОНЕНТЫ WORKLOAD MANAGER
CUSTSVC
SALES
SHIPPING
Правила перенаправления клиентов
(приложение,
имя сервера, логин)
Профили нагрузки
ЛОГИЧЕСКИЕ КЛАСТЕРЫ
Interfaces/
sql.ini
Interfaces/
sql.ini
Interfaces/
sql.ini
MYCLUSTER_SDC
Слайд 31ПРОФИЛИ НАГРУЗКИ
Менеджер нагрузки также отвечает за распределение нагрузки по серверам кластера
Следит, чтобы
ПРОФИЛИ НАГРУЗКИ
Менеджер нагрузки также отвечает за распределение нагрузки по серверам кластера
Следит, чтобы

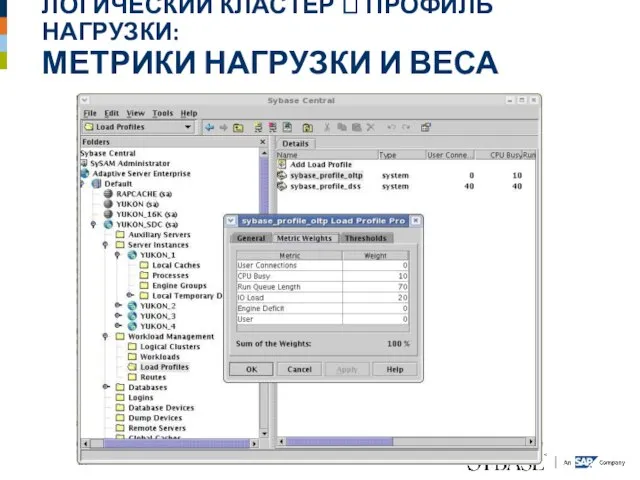
Слайд 32ЛОГИЧЕСКИЙ КЛАСТЕР ? ПРОФИЛЬ НАГРУЗКИ:
МЕТРИКИ НАГРУЗКИ И ВЕСА
ЛОГИЧЕСКИЙ КЛАСТЕР ? ПРОФИЛЬ НАГРУЗКИ:
МЕТРИКИ НАГРУЗКИ И ВЕСА
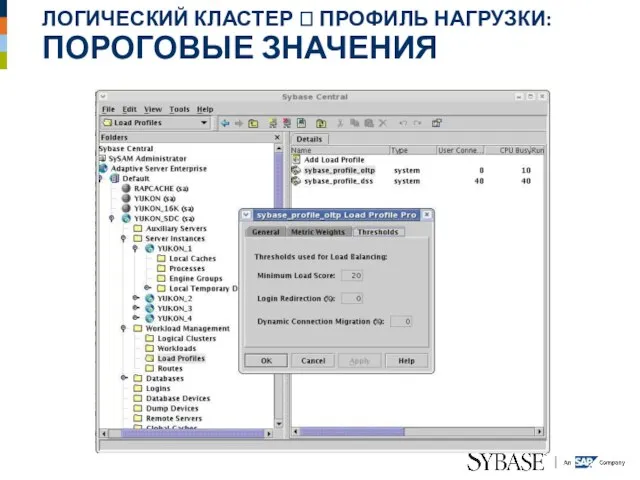
Слайд 33ЛОГИЧЕСКИЙ КЛАСТЕР ? ПРОФИЛЬ НАГРУЗКИ:
ПОРОГОВЫЕ ЗНАЧЕНИЯ
ЛОГИЧЕСКИЙ КЛАСТЕР ? ПРОФИЛЬ НАГРУЗКИ:
ПОРОГОВЫЕ ЗНАЧЕНИЯ
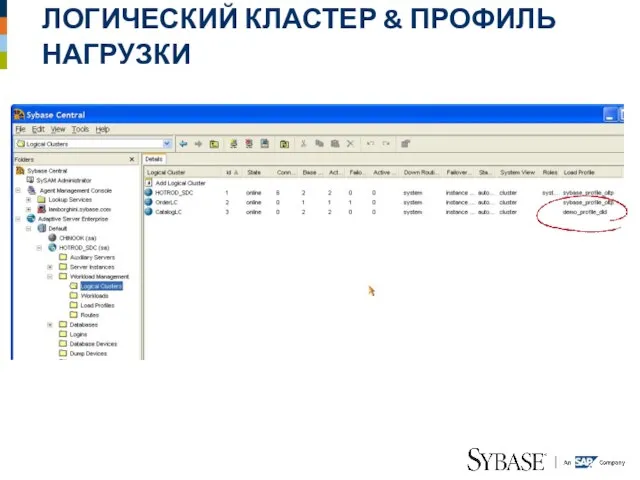
Слайд 34ЛОГИЧЕСКИЙ КЛАСТЕР & ПРОФИЛЬ НАГРУЗКИ
ЛОГИЧЕСКИЙ КЛАСТЕР & ПРОФИЛЬ НАГРУЗКИ
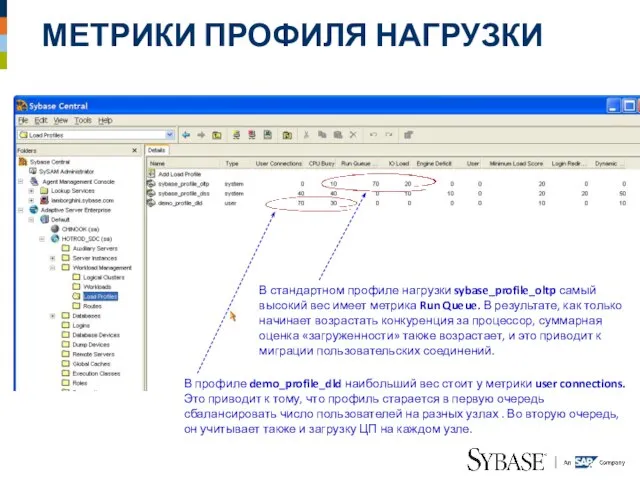
Слайд 35МЕТРИКИ ПРОФИЛЯ НАГРУЗКИ
В стандартном профиле нагрузки sybase_profile_oltp самый высокий вес имеет метрика
МЕТРИКИ ПРОФИЛЯ НАГРУЗКИ
В стандартном профиле нагрузки sybase_profile_oltp самый высокий вес имеет метрика
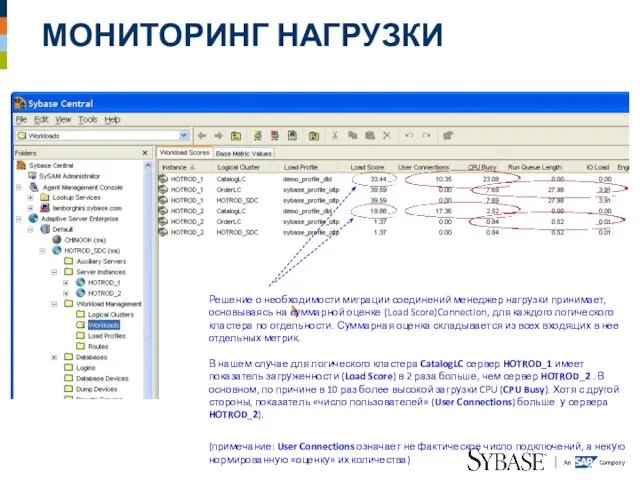
Слайд 36МОНИТОРИНГ НАГРУЗКИ
Решение о необходимости миграции соединений менеджер нагрузки принимает, основываясь на суммарной
МОНИТОРИНГ НАГРУЗКИ
Решение о необходимости миграции соединений менеджер нагрузки принимает, основываясь на суммарной
Слайд 37ЛОГИЧЕСКИЕ КЛАСТЕРЫ
И АВАРИЙНОЕ ПЕРЕКЛЮЧЕНИЕ (FAILOVER)
Ресурсы для FAILOVER
Список ASE-серверов или групп ASE-серверов,
ЛОГИЧЕСКИЕ КЛАСТЕРЫ
И АВАРИЙНОЕ ПЕРЕКЛЮЧЕНИЕ (FAILOVER)
Ресурсы для FAILOVER
Список ASE-серверов или групп ASE-серверов,

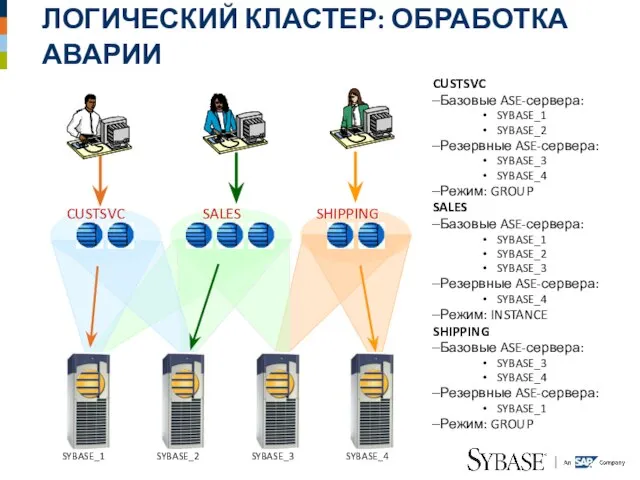
Слайд 38ЛОГИЧЕСКИЙ КЛАСТЕР: ОБРАБОТКА АВАРИИ
CUSTSVC
Базовые ASE-сервера:
SYBASE_1
SYBASE_2
Резервные ASE-сервера:
SYBASE_3
SYBASE_4
Режим: GROUP
SALES
Базовые ASE-сервера:
SYBASE_1
SYBASE_2
SYBASE_3
Резервные ASE-сервера:
SYBASE_4
Режим: INSTANCE
SHIPPING
Базовые ASE-сервера:
SYBASE_3
SYBASE_4
Резервные ASE-сервера:
SYBASE_1
Режим:
ЛОГИЧЕСКИЙ КЛАСТЕР: ОБРАБОТКА АВАРИИ
CUSTSVC
Базовые ASE-сервера:
SYBASE_1
SYBASE_2
Резервные ASE-сервера:
SYBASE_3
SYBASE_4
Режим: GROUP
SALES
Базовые ASE-сервера:
SYBASE_1
SYBASE_2
SYBASE_3
Резервные ASE-сервера:
SYBASE_4
Режим: INSTANCE
SHIPPING
Базовые ASE-сервера:
SYBASE_3
SYBASE_4
Резервные ASE-сервера:
SYBASE_1
Режим:
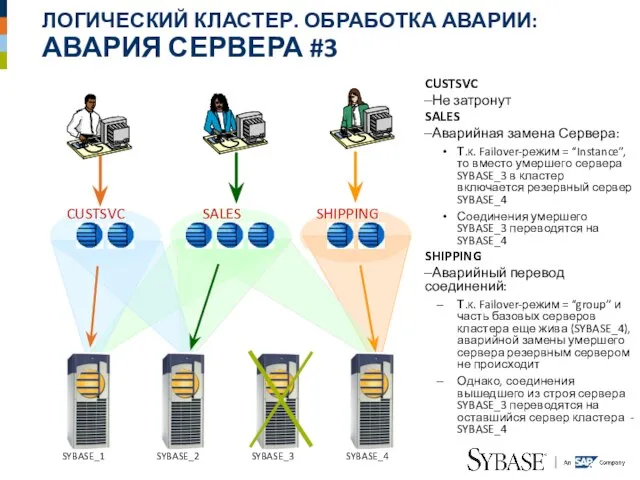
Слайд 39ЛОГИЧЕСКИЙ КЛАСТЕР. ОБРАБОТКА АВАРИИ:
АВАРИЯ СЕРВЕРА #3
CUSTSVC
Не затронут
SALES
Аварийная замена Сервера:
Т.к. Failover-режим = “Instance”,
ЛОГИЧЕСКИЙ КЛАСТЕР. ОБРАБОТКА АВАРИИ:
АВАРИЯ СЕРВЕРА #3
CUSTSVC
Не затронут
SALES
Аварийная замена Сервера:
Т.к. Failover-режим = “Instance”,
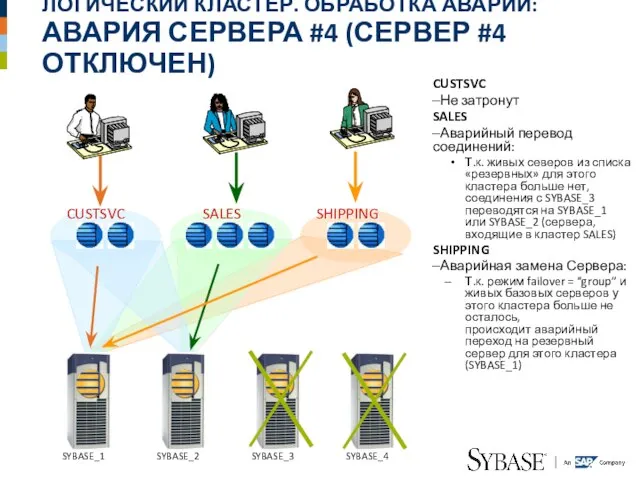
Слайд 40ЛОГИЧЕСКИЙ КЛАСТЕР. ОБРАБОТКА АВАРИИ:
АВАРИЯ СЕРВЕРА #4 (СЕРВЕР #4 ОТКЛЮЧЕН)
CUSTSVC
Не затронут
SALES
Аварийный перевод соединений:
Т.к.
ЛОГИЧЕСКИЙ КЛАСТЕР. ОБРАБОТКА АВАРИИ:
АВАРИЯ СЕРВЕРА #4 (СЕРВЕР #4 ОТКЛЮЧЕН)
CUSTSVC
Не затронут
SALES
Аварийный перевод соединений:
Т.к.
Слайд 41ЛОГИЧЕСКИЙ КЛАСТЕР. ОБРАБОТКА АВАРИИ:
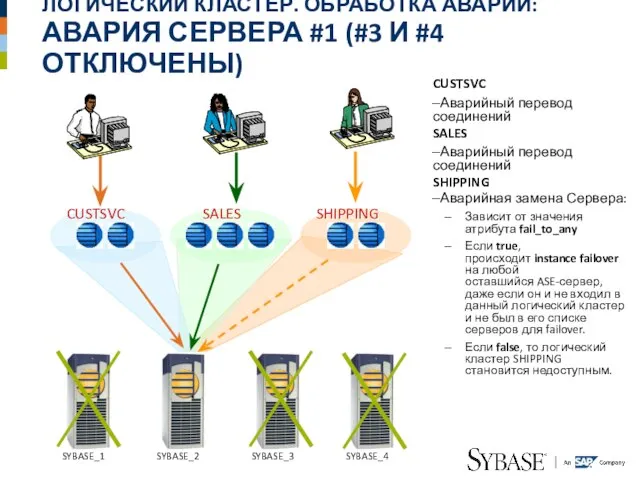
АВАРИЯ СЕРВЕРА #1 (#3 И #4 ОТКЛЮЧЕНЫ)
CUSTSVC
Аварийный перевод соединений
SALES
Аварийный
ЛОГИЧЕСКИЙ КЛАСТЕР. ОБРАБОТКА АВАРИИ:
АВАРИЯ СЕРВЕРА #1 (#3 И #4 ОТКЛЮЧЕНЫ)
CUSTSVC
Аварийный перевод соединений
SALES
Аварийный
Слайд 42НОВЫЕ КЛИЕНТСКИЕ ТЕХНОЛОГИИ
Новые клиентские технологии
Позволяют клиенту иметь логическое соединение с кластером,
НОВЫЕ КЛИЕНТСКИЕ ТЕХНОЛОГИИ
Новые клиентские технологии
Позволяют клиенту иметь логическое соединение с кластером,

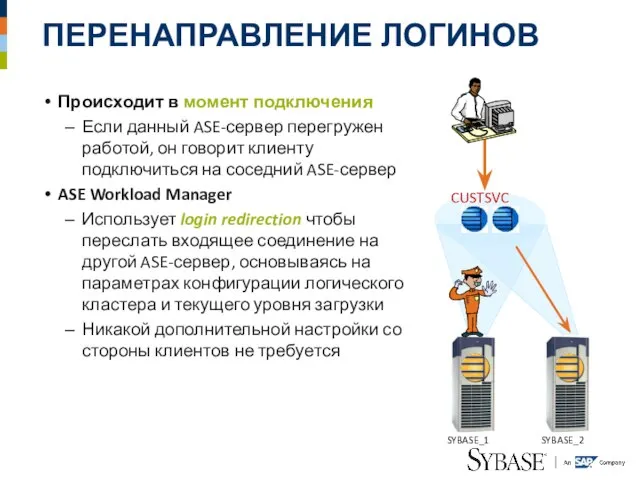
Слайд 43ПЕРЕНАПРАВЛЕНИЕ ЛОГИНОВ
Происходит в момент подключения
Если данный ASE-сервер перегружен работой, он говорит клиенту
ПЕРЕНАПРАВЛЕНИЕ ЛОГИНОВ
Происходит в момент подключения
Если данный ASE-сервер перегружен работой, он говорит клиенту
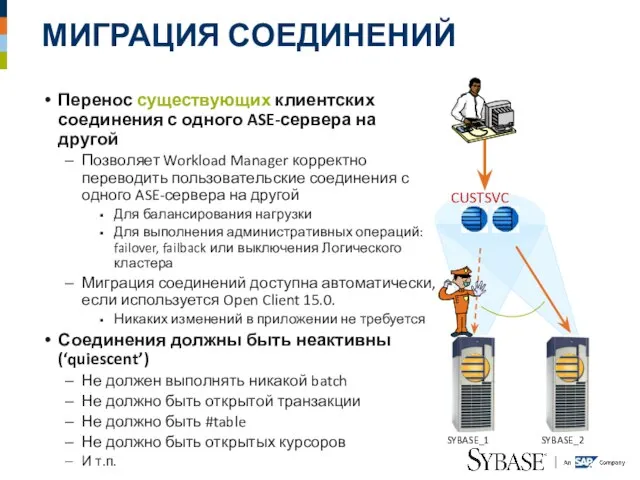
Слайд 44МИГРАЦИЯ СОЕДИНЕНИЙ
Перенос существующих клиентских соединения с одного ASE-сервера на другой
Позволяет Workload Manager
МИГРАЦИЯ СОЕДИНЕНИЙ
Перенос существующих клиентских соединения с одного ASE-сервера на другой
Позволяет Workload Manager
Слайд 45ОТЛИЧИЕ МИГРАЦИИ СОЕДИНЕНИЯ ОТ
АВАРИЙНОГО ПЕРЕКЛЮЧЕНИЯ СОЕДИНЕНИЯ
Миграция или аварийное переключение (Failover)
Миграция это
ОТЛИЧИЕ МИГРАЦИИ СОЕДИНЕНИЯ ОТ
АВАРИЙНОГО ПЕРЕКЛЮЧЕНИЯ СОЕДИНЕНИЯ
Миграция или аварийное переключение (Failover)
Миграция это

Слайд 46ЗАКЛЮЧЕНИЕ – ASE CLUSTER EDITION …
Способен защитить от нескольких одновременных аварий, обеспечивая
ЗАКЛЮЧЕНИЕ – ASE CLUSTER EDITION …
Способен защитить от нескольких одновременных аварий, обеспечивая

 Реклама - двигатель торговли
Реклама - двигатель торговли ИНТЕЛЛЕКТУАЛЬНАЯ ИГРА«АШКИ ИЛИ ГЭШКИ?»
ИНТЕЛЛЕКТУАЛЬНАЯ ИГРА«АШКИ ИЛИ ГЭШКИ?» Забастовка. Право на забастовку
Забастовка. Право на забастовку Какой бывает транспорт
Какой бывает транспорт Построение осей складок
Построение осей складок Kimono shop
Kimono shop Открытие Show-room РуДа в ТРЦ
Открытие Show-room РуДа в ТРЦ Решение задач на сложение и вычитание смешанных чисел
Решение задач на сложение и вычитание смешанных чисел Критерии деятельности классных руководителей начального звена за 2 полугодие
Критерии деятельности классных руководителей начального звена за 2 полугодие Презентация на тему Решение логарифмических уравнений
Презентация на тему Решение логарифмических уравнений Преподаватель: Жирнова Н.Ю. ОБ УЧАСТИИ ВО ВСЕРОССИЙСКИХ ПЕДАГОГИЧЕСКИХ КОНКУРСАХ.
Преподаватель: Жирнова Н.Ю. ОБ УЧАСТИИ ВО ВСЕРОССИЙСКИХ ПЕДАГОГИЧЕСКИХ КОНКУРСАХ. Яңы йыл байрамы
Яңы йыл байрамы Осциллограф H3015
Осциллограф H3015 Хранение и распределение нефти, нефтепродуктов и газа
Хранение и распределение нефти, нефтепродуктов и газа Кузмицкий Василий Федорович
Кузмицкий Василий Федорович Интересная физика
Интересная физика Как древние люди представляли себе Вселенную
Как древние люди представляли себе Вселенную Школа творческих открытий Русский авангард для детей. Контраст Встреча противоположностей
Школа творческих открытий Русский авангард для детей. Контраст Встреча противоположностей Вознекновение театрв 18 веке
Вознекновение театрв 18 веке История российского парламентаризма
История российского парламентаризма Группа в VKontakte Сообщество инфобизнесменов, проект ИнфоХит
Группа в VKontakte Сообщество инфобизнесменов, проект ИнфоХит Концепция «Единого окна»: ключевой инструмент упрощения процедур торговли и надлежащего управления Марио Апостолов, Р
Концепция «Единого окна»: ключевой инструмент упрощения процедур торговли и надлежащего управления Марио Апостолов, Р Романтизм 11 класс
Романтизм 11 класс Тест на тему: Сила упругости. Закон Гука
Тест на тему: Сила упругости. Закон Гука Manhattan
Manhattan Différenciation sociale du lexique
Différenciation sociale du lexique Samp Stories Epesode one(1)
Samp Stories Epesode one(1) Регрессивный анализ для выявления лучших агентов. Росгосстрах
Регрессивный анализ для выявления лучших агентов. Росгосстрах