- Очевидное – невероятное(Sphinx tips-n-tricks)

Содержание
- 2. Кто здесь? Слово Sphinx похоже на search Потому что такое же количество букв Бесплатный, открытый поисковой
- 3. Соло на баяне, на тему… Обзор – скучно! Документация – скучно! Внутренняя архитектура – тоже скучно!
- 4. Как забить шуруп микроскопом
- 5. UnFAQ Как иногда можно ускорить индексацию MySQL Как иногда нужно замедлять индексацию Как индексировать результат работы
- 6. 1. Как ускорять индексацию Заставляем протокол сжимать данные mysql_connect_flags=32 До +20% к общему (!) времени на
- 7. 2. Как замедлять индексацию Тормозим выборки Понаехали тут, DB сервер не резиновый! sql_ranged_throttle=100 Тормозим indexer IO
- 8. 3. Как индексировать MySQL SP Опять магические флажки в протоколе: mysql_connect_flags=131074 См. mysql_com.h CLIENT_MULTI_STATEMENT = 65536
- 9. 4. Как бороться с MyISAM locks SELECT * FROM table – это удар в солнечное Понятное
- 10. 5. Как бороться с PgSQL client SELECT * FROM table – это удар в мозг (RAM)
- 11. 6. Как правильно обновляться Sphinx давно и успешно обратно совместим Умеет читать старые конфиги Умеет читать
- 12. 6. Как правильно обновляться Обновить и перезапустить agent searchd(s) Обновить и перезапустить master searchd Обновить indexer
- 13. 7. Как работать со строками… …не имея поддержки строковых атрибутов? А что значит работать? Искать точное
- 14. 7. Как работать со строками… Все, кроме сортировки, можно делать с CRC Коллизии? MD5 + sql_attr_bigint
- 15. 8. Как искать точную форму В случае индексов со стеммингом? 0.9.8 – делаем 2 индекса и…
- 16. 9. Как бустить точное слово В случае prefix/infix индексов? Вариант 1. Магия в запросе highload |
- 17. 10. Как бустить совпадение поля Вариант 1. CRC32 + expr sort $cl->SetSortMode ( SPH_SORT_EXPR, “@weight+IF(fieldcrc=XXX,1,0)” )
- 18. 11. Как эмулировать regex forms Sphinx умеет wordforms Но вы НЕ ХОТИТЕ, чтобы там были regexes
- 19. 11. Как эмулировать regex forms Однако иногда вы таки хотите regexes eeeeeeeek -> eek, hiiiiiiiighload ->
- 20. 12. Как скрещивать ежа и ужа Т.е. одновременно искать по индексам с разными схемами? Минимизация схемы
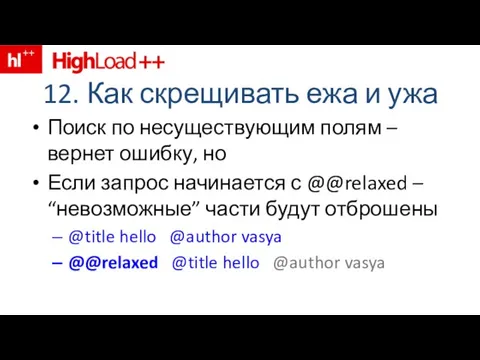
- 21. 12. Как скрещивать ежа и ужа Поиск по несуществующим полям – вернет ошибку, но Если запрос
- 22. 13. Как делать SQL-style запросы А, главное, зачем? Иногда быстрее, чем база (см. селективность) Иногда удобнее
- 23. 13. Как делать SQL-style запросы Когда можно, отключайте ранжирование $client->SetRankingMode ( SPH_RANK_ NONE ); Используйте ключевые
- 24. Disclaimer Пункт 13 – это и было “вкратце про тюнинг”
- 25. 14. Как искать related документы Серебряной пули нет, только мелкая дробь Можно искать title и использовать
- 26. 14. Как искать related документы Интересные слова поможет выбирать BuildKeywords() – вернет статистику Можно анализировать статистику
- 27. 15. Как делать suggestions Или “когда не хватает aspell” Иногда хочется по локальному словарю Что советовать
- 28. 15. Как делать suggestions Построить личный частотный словарь indexer --buildstops dict.txt 1000000 --buildfreqs Затем искать слова
- 29. 16. Как все это не делать Есть секретный код, привожу PHP вариант (*) или http://sphinxsearch.com/contact.html while
- 30. Вопросы?
- 31. А теперь – бонус-трек Как работает поиск? Для каждого локального индекса Строим список кандидатов Фильтруем (аналог
- 32. Цена булева поиска Построение списка кандидатов 1 ключевое слово – 1+ IO (список документов) Булевы операции
- 33. Цена фильтрации Дефолтный режим хранения, docinfo=extern Атрибуты хранятся в отдельном файле (.spa) Загружаются в RAM при
- 34. Цена ранжирования Прямая – зависит от ранкера SPH_RANK_NONE вообще ничего не стоит SPH_RANK_DEFAULT учитывает позиции слов,
- 35. Цена сортировки Стоимость ~ числу результатов Еще зависит от критерия сортировки Документы придут в порядке @id
- 36. Так оптимизировать-то как? Где можно, ранжируйте попроще Сортировка не по весу? Ранжировать не надо Можно вкомпилировать
- 37. А еще как? Вместо высоко-селективных (“редких”) фильтров – делайте ключевые слова Вместо низко-селективных (“частых”) ключевых слов
- 38. Ну а еще как?! Мульти-запросы Всегда экономит round-trip Иногда оптимизируются внутри Особо частый случай – когда
- 39. Надеюсь, все? Конечно Конечно, НЕТ partitioning, cutoff, max_query_time, block level rejects, index level rejects… consulting (да,
- 41. Скачать презентацию
Слайд 2Кто здесь?
Слово Sphinx похоже на search
Потому что такое же количество букв
Бесплатный, открытый
Кто здесь?
Слово Sphinx похоже на search
Потому что такое же количество букв
Бесплатный, открытый

Слайд 3Соло на баяне, на тему…
Обзор – скучно!
Документация – скучно!
Внутренняя архитектура – тоже
Соло на баяне, на тему…
Обзор – скучно!
Документация – скучно!
Внутренняя архитектура – тоже
Слайд 4Как забить шуруп микроскопом
Как забить шуруп микроскопом

Слайд 5UnFAQ
Как иногда можно ускорить индексацию MySQL
Как иногда нужно замедлять индексацию
Как индексировать результат
UnFAQ
Как иногда можно ускорить индексацию MySQL
Как иногда нужно замедлять индексацию
Как индексировать результат

Слайд 61. Как ускорять индексацию
Заставляем протокол сжимать данные
mysql_connect_flags=32
До +20% к общему (!) времени
1. Как ускорять индексацию
Заставляем протокол сжимать данные
mysql_connect_flags=32
До +20% к общему (!) времени

Слайд 72. Как замедлять индексацию
Тормозим выборки
Понаехали тут, DB сервер не резиновый!
sql_ranged_throttle=100
Тормозим indexer IO
max_iops=40
2. Как замедлять индексацию
Тормозим выборки
Понаехали тут, DB сервер не резиновый!
sql_ranged_throttle=100
Тормозим indexer IO
max_iops=40

Слайд 83. Как индексировать MySQL SP
Опять магические флажки в протоколе:
mysql_connect_flags=131074
См. mysql_com.h
CLIENT_MULTI_STATEMENT = 65536
CLIENT_MULTI_RESULTS
3. Как индексировать MySQL SP
Опять магические флажки в протоколе:
mysql_connect_flags=131074
См. mysql_com.h
CLIENT_MULTI_STATEMENT = 65536
CLIENT_MULTI_RESULTS

Слайд 94. Как бороться с MyISAM locks
SELECT * FROM table – это удар
4. Как бороться с MyISAM locks
SELECT * FROM table – это удар

Слайд 105. Как бороться с PgSQL client
SELECT * FROM table – это удар
5. Как бороться с PgSQL client
SELECT * FROM table – это удар

Слайд 116. Как правильно обновляться
Sphinx давно и успешно обратно совместим
Умеет читать старые конфиги
Умеет
6. Как правильно обновляться
Sphinx давно и успешно обратно совместим
Умеет читать старые конфиги
Умеет

Слайд 126. Как правильно обновляться
Обновить и перезапустить agent searchd(s)
Обновить и перезапустить master searchd
Обновить
6. Как правильно обновляться
Обновить и перезапустить agent searchd(s)
Обновить и перезапустить master searchd
Обновить

Слайд 137. Как работать со строками…
…не имея поддержки строковых атрибутов?
А что значит работать?
Искать
7. Как работать со строками…
…не имея поддержки строковых атрибутов?
А что значит работать?
Искать

Слайд 147. Как работать со строками…
Все, кроме сортировки, можно делать с CRC
Коллизии? MD5
7. Как работать со строками…
Все, кроме сортировки, можно делать с CRC
Коллизии? MD5

Слайд 158. Как искать точную форму
В случае индексов со стеммингом?
0.9.8 – делаем 2
8. Как искать точную форму
В случае индексов со стеммингом?
0.9.8 – делаем 2

Слайд 169. Как бустить точное слово
В случае prefix/infix индексов?
Вариант 1. Магия в запросе
highload
9. Как бустить точное слово
В случае prefix/infix индексов?
Вариант 1. Магия в запросе
highload

Слайд 1710. Как бустить совпадение поля
Вариант 1. CRC32 + expr sort
$cl->SetSortMode ( SPH_SORT_EXPR,
10. Как бустить совпадение поля
Вариант 1. CRC32 + expr sort
$cl->SetSortMode ( SPH_SORT_EXPR,

Слайд 1811. Как эмулировать regex forms
Sphinx умеет wordforms
Но вы НЕ ХОТИТЕ, чтобы там
11. Как эмулировать regex forms
Sphinx умеет wordforms
Но вы НЕ ХОТИТЕ, чтобы там

Слайд 1911. Как эмулировать regex forms
Однако иногда вы таки хотите regexes
eeeeeeeek -> eek,
11. Как эмулировать regex forms
Однако иногда вы таки хотите regexes
eeeeeeeek -> eek,

Слайд 2012. Как скрещивать ежа и ужа
Т.е. одновременно искать по индексам с разными
12. Как скрещивать ежа и ужа
Т.е. одновременно искать по индексам с разными

Слайд 2112. Как скрещивать ежа и ужа
Поиск по несуществующим полям – вернет ошибку,
12. Как скрещивать ежа и ужа
Поиск по несуществующим полям – вернет ошибку,
Слайд 2213. Как делать SQL-style запросы
А, главное, зачем?
Иногда быстрее, чем база (см. селективность)
Иногда
13. Как делать SQL-style запросы
А, главное, зачем?
Иногда быстрее, чем база (см. селективность)
Иногда

Слайд 2313. Как делать SQL-style запросы
Когда можно, отключайте ранжирование
$client->SetRankingMode ( SPH_RANK_ NONE );
Используйте
13. Как делать SQL-style запросы
Когда можно, отключайте ранжирование
$client->SetRankingMode ( SPH_RANK_ NONE );
Используйте

Слайд 24Disclaimer
Пункт 13 – это и было “вкратце про тюнинг”
Disclaimer
Пункт 13 – это и было “вкратце про тюнинг”

Слайд 2514. Как искать related документы
Серебряной пули нет, только мелкая дробь
Можно искать title
14. Как искать related документы
Серебряной пули нет, только мелкая дробь
Можно искать title

Слайд 2614. Как искать related документы
Интересные слова поможет выбирать BuildKeywords() – вернет статистику
Можно
14. Как искать related документы
Интересные слова поможет выбирать BuildKeywords() – вернет статистику
Можно

Слайд 2715. Как делать suggestions
Или “когда не хватает aspell”
Иногда хочется по локальному словарю
Что
15. Как делать suggestions
Или “когда не хватает aspell”
Иногда хочется по локальному словарю
Что

Слайд 2815. Как делать suggestions
Построить личный частотный словарь
indexer --buildstops dict.txt 1000000 --buildfreqs
Затем искать
15. Как делать suggestions
Построить личный частотный словарь
indexer --buildstops dict.txt 1000000 --buildfreqs
Затем искать

Слайд 2916. Как все это не делать
Есть секретный код, привожу PHP вариант
(*) или
16. Как все это не делать
Есть секретный код, привожу PHP вариант
(*) или

Слайд 30Вопросы?
Вопросы?

Слайд 31А теперь – бонус-трек
Как работает поиск?
Для каждого локального индекса
Строим список кандидатов
Фильтруем (аналог
А теперь – бонус-трек
Как работает поиск?
Для каждого локального индекса
Строим список кандидатов
Фильтруем (аналог

Слайд 32Цена булева поиска
Построение списка кандидатов
1 ключевое слово – 1+ IO (список документов)
Булевы
Цена булева поиска
Построение списка кандидатов
1 ключевое слово – 1+ IO (список документов)
Булевы

Слайд 33Цена фильтрации
Дефолтный режим хранения, docinfo=extern
Атрибуты хранятся в отдельном файле (.spa)
Загружаются в RAM
Цена фильтрации
Дефолтный режим хранения, docinfo=extern
Атрибуты хранятся в отдельном файле (.spa)
Загружаются в RAM

Слайд 34Цена ранжирования
Прямая – зависит от ранкера
SPH_RANK_NONE вообще ничего не стоит
SPH_RANK_DEFAULT учитывает позиции
Цена ранжирования
Прямая – зависит от ранкера
SPH_RANK_NONE вообще ничего не стоит
SPH_RANK_DEFAULT учитывает позиции

Слайд 35Цена сортировки
Стоимость ~ числу результатов
Еще зависит от критерия сортировки
Документы придут в порядке
Цена сортировки
Стоимость ~ числу результатов
Еще зависит от критерия сортировки
Документы придут в порядке

Слайд 36Так оптимизировать-то как?
Где можно, ранжируйте попроще
Сортировка не по весу? Ранжировать не надо
Можно
Так оптимизировать-то как?
Где можно, ранжируйте попроще
Сортировка не по весу? Ранжировать не надо
Можно

Слайд 37А еще как?
Вместо высоко-селективных (“редких”) фильтров – делайте ключевые слова
Вместо низко-селективных (“частых”)
А еще как?
Вместо высоко-селективных (“редких”) фильтров – делайте ключевые слова
Вместо низко-селективных (“частых”)

Слайд 38Ну а еще как?!
Мульти-запросы
Всегда экономит round-trip
Иногда оптимизируются внутри
Особо частый случай – когда
Ну а еще как?!
Мульти-запросы
Всегда экономит round-trip
Иногда оптимизируются внутри
Особо частый случай – когда

Слайд 39Надеюсь, все?
Конечно
Конечно, НЕТ
partitioning, cutoff, max_query_time, block level rejects, index level rejects…
consulting (да,
Надеюсь, все?
Конечно
Конечно, НЕТ
partitioning, cutoff, max_query_time, block level rejects, index level rejects…
consulting (да,

 Интерактивный квест Спасение эйленов
Интерактивный квест Спасение эйленов ОФБУ как форма управления активами
ОФБУ как форма управления активами Педагогические колледжи Красноярского края
Педагогические колледжи Красноярского края Осторожно огонь
Осторожно огонь Требования, предъявляемые к лицам, назначаемым на должности прокуроров
Требования, предъявляемые к лицам, назначаемым на должности прокуроров А. Куприн «Слон»
А. Куприн «Слон» Что изменилось в отчетности за 9 месяцев: Декларация по НДС и прослеживаемость товаров
Что изменилось в отчетности за 9 месяцев: Декларация по НДС и прослеживаемость товаров Презентация на тему Вред здоровью человека от сотового телефона
Презентация на тему Вред здоровью человека от сотового телефона  «Роль игры в развитии речи дошкольника»
«Роль игры в развитии речи дошкольника» Спорт среди молодежи в Красноярске
Спорт среди молодежи в Красноярске Лувр
Лувр Государственная поддержка субъектов предпринимательства в Республике Казахстан со стороны АО «Фонд «Даму»
Государственная поддержка субъектов предпринимательства в Республике Казахстан со стороны АО «Фонд «Даму» Моделирование при разработке управленческих решений. Разработка управленческого решения
Моделирование при разработке управленческих решений. Разработка управленческого решения Как на самом деле любить детей. «Именно любовь делает человека таким, каким он должен быть.» Подготовила воспитатель Кори
Как на самом деле любить детей. «Именно любовь делает человека таким, каким он должен быть.» Подготовила воспитатель Кори Страницы истории
Страницы истории  Презентация на тему Петр 1
Презентация на тему Петр 1  5S: Сортировка. Систематизация. Сияние. Стандартизация. Самосовершенствование
5S: Сортировка. Систематизация. Сияние. Стандартизация. Самосовершенствование Использование современных образовательных технологий в процессе обучения русскому языку
Использование современных образовательных технологий в процессе обучения русскому языку Медведев Егор Бийск ОПШ 2022 (1) (1)
Медведев Егор Бийск ОПШ 2022 (1) (1) Россия выбирает президента
Россия выбирает президента Изображение головы человека в пространстве
Изображение головы человека в пространстве Искусство раннего Возрождения
Искусство раннего Возрождения Проверка домашнего задания
Проверка домашнего задания Новая сказка про Красную Шапочку
Новая сказка про Красную Шапочку Танковая навигационная аппаратура
Танковая навигационная аппаратура Social and personality development and types of play pre-school years
Social and personality development and types of play pre-school years  Презентация на тему ЗУНР Западно-Украинская Народная Республика
Презентация на тему ЗУНР Западно-Украинская Народная Республика  Спин - HIV
Спин - HIV