- Основы параллельного программирования с использованием MPI Лекция 4

Содержание
- 2. Лекция 4 2008 Аннотация В лекции описываются средства организации неблокирующих двухточечных обменов. Рассматриваются операции неблокирующих отправки
- 3. План лекции 2008 Пример использования блокирующих двухточечных обменов Общая характеристика неблокирующих обменов. Неблокирующие передача и приём.
- 4. Одномерное уравнение Лапласа. Метод Якоби 2008
- 5. Уравнение Лапласа 2008 В качестве примера использования операций двухточечного обмена рассмотрим численное решение уравнения Лапласа в
- 6. Уравнение Лапласа 2008 Численное решение основано на введении 1- или 2-мерной сетки в области, ограниченной границей
- 7. Уравнение Лапласа 2008 Последовательная программа на языке Fortran 90
- 8. Уравнение Лапласа 2008 program jacobi_serial implicit none real, dimension(0:10001) :: x, newx real :: dx2 integer
- 9. Уравнение Лапласа 2008 x(0) = 0.0 x(n + 1) = 0.0 do k = 1, noiters
- 10. Уравнение Лапласа 2008 Параллельная программа на языке Fortran 90
- 11. Уравнение Лапласа 2008 Параллельный алгоритм Параллельный алгоритм основан на декомпозиции по данным – разбиении одномерной сетки
- 12. Уравнение Лапласа 2008 program jacobi_parallel implicit none include "mpif.h" real, dimension(0:10001) :: x,newx real :: dx2
- 13. Уравнение Лапласа 2008 call MPI_Init(ierr) call MPI_Comm_rank(MPI_COMM_WORLD, me, ierr) call MPI_Comm_size(MPI_COMM_WORLD, p, ierr) tag = 0
- 14. Уравнение Лапласа 2008 do k = 1, noiters ! Пересылки граничных значений if(me - 1 >=
- 15. Уравнение Лапласа 2008 ! Собираем решение if(me = = 0) then do i = 1, ln
- 16. Неблокирующие двухточечные обмены 2008
- 17. Неблокирующие обмены 2008 Вызов подпрограммы неблокирующей передачи инициирует, но не завершает ее. Завершиться выполнение подпрограммы может
- 18. Неблокирующие обмены 2008 Для завершения неблокирующего обмена требуется вызов дополнительной процедуры, которая проверяет, скопированы ли данные
- 19. Неблокирующие обмены 2008 Неблокирующий обмен выполняется в два этапа: инициализация обмена; проверка завершения обмена. Разделение этих
- 20. Неблокирующие обмены 2008 Инициализация неблокирующей стандартной передачи выполняется подпрограммами MPI_I[S, B, R]send. Стандартная неблокирующая передача выполняется
- 21. Неблокирующие обмены 2008 Инициализация неблокирующего приема выполняется при вызове подпрограммы: int MPI_Irecv(void *buf, int count, MPI_Datatype
- 22. Неблокирующие обмены 2008 Вызовы подпрограмм неблокирующего обмена формируют запрос на выполнение операции обмена и связывают его
- 23. Неблокирующие обмены 2008 Проверка выполнения обмена Проверка фактического выполнения передачи или приема в неблокирующем режиме осуществляется
- 24. Неблокирующие обмены 2008 В том случае, когда одновременно несколько процессов обмениваются сообщениями, можно использовать проверки, которые
- 25. Неблокирующие обмены 2008 Блокирующие операции проверки Подпрограмма MPI_Wait блокирует работу процесса до завершения приема или передачи
- 26. Неблокирующие обмены 2008 Успешное выполнение подпрограммы MPI_Wait после вызова MPI_Ibsend подразумевает, что буфер передачи можно использовать
- 27. Неблокирующие обмены 2008 Проверка завершения всех обменов Проверка завершения всех обменов выполняется подпрограммой: int MPI_Waitall(int count,
- 28. Неблокирующие обмены 2008 В результате выполнения подпрограммы MPI_Waitall запросы, сформированные неблокирующими операциями обмена, аннулируются, а соответствующим
- 29. Неблокирующие обмены 2008 Проверка завершения любого числа обменов Проверка завершения любого числа обменов выполняется подпрограммой: int
- 30. Неблокирующие обмены 2008 Если в списке вообще нет активных запросов или он пуст, вызовы завершаются сразу
- 31. Неблокирующие обмены 2008 Неблокирующие процедуры проверки Подпрограмма MPI_Test выполняет неблокирующую проверку завершения приема или передачи сообщения:
- 32. Неблокирующие обмены 2008 Неблокирующая проверка завершения всех обменов Подпрограмма MPI_Testall выполняет неблокирующую проверку завершения приема или
- 33. Неблокирующие обмены 2008 Неблокирующая проверка любого числа обменов Подпрограмма MPI_Testany выполняет неблокирующую проверку завершения приема или
- 34. Неблокирующие обмены 2008 Другие операции проверки Подпрограммы MPI_Waitsome и MPI_Testsome действуют аналогично подпрограммам MPI_Waitany и MPI_Testany,
- 35. Неблокирующие обмены 2008 Интерфейс этих подпрограмм: int MPI_Waitsome(int incount, MPI_Request requests[], int *outcount, int indices[], MPI_Status
- 36. Неблокирующие обмены 2008 Неблокирующая проверка выполнения обменов int MPI_Testsome(int incount, MPI_Request requests[], int *outcount, int indices[],
- 37. Примеры использования неблокирующих двухточечных обменов 2008
- 38. Неблокирующие обмены 2008 Пример 1 program main_mpi include 'mpif.h' integer rank, tag, cnt, ierr, status(MPI_STATUS_SIZE) integer
- 39. Неблокирующие обмены 2008 if(rank.eq.0) then call MPI_Isend(sndbuf(1), cnt, MPI_REAL, 1, tag, MPI_COMM_WORLD, request, ierr) print *,
- 40. Неблокирующие обмены 2008 Результат выполнения:
- 41. Неблокирующие обмены 2008 Пример 2 program main_mpi include 'mpif.h' integer rank, tag1, tag2, cnt, ierr, status(MPI_STATUS_SIZE)
- 42. Неблокирующие обмены 2008 if (rank.eq.0) then call MPI_Ssend(sndbuf1, cnt, MPI_REAL, 1, tag1, MPI_COMM_WORLD, ierr) print *,
- 43. Неблокирующие обмены 2008 Результат выполнения:
- 44. Подпрограммы-пробники 2008
- 45. Неблокирующие обмены 2008 Неблокирующая проверка сообщения Неблокирующая проверка сообщения выполняется подпрограммой: int MPI_Iprobe(int source, int tag,
- 46. Неблокирующие обмены 2008 Размер полученного сообщения (count) можно определить с помощью вызова подпрограммы int MPI_Get_count(MPI_Status *status,
- 47. Неблокирующие обмены 2008 Пример 3 program main_mpi include 'mpif.h' integer rank, i, k, ierr, tag, dest,
- 48. Неблокирующие обмены 2008 do k = 1, 2 call MPI_Probe(MPI_any_source, tag, MPI_COMM_WORLD, status, ierr) if (status(MPI_source).eq.0)
- 49. Неблокирующие обмены 2008 Результат выполнения:
- 50. Отложенные обмены 2008
- 51. Неблокирующие обмены 2008 Достаточно часто приходится сталкиваться с ситуацией, когда обмены с одинаковыми параметрами выполняются повторно,
- 52. Неблокирующие обмены 2008 Запрос для стандартной передачи создается при вызове подпрограммы MPI_Send_init: int MPI_Send_init(void *buf, int
- 53. Неблокирующие обмены 2008 Отложенный запрос может быть сформирован для всех режимов обмена. Для этого используются подпрограммы
- 54. Неблокирующие обмены 2008 Подпрограмма MPI_Startall: int MPI_Startall(int count, MPI_request *requests) MPI_Startall(count, requests, ierr) инициирует все обмены,
- 55. 2008 В этой лекции мы рассмотрели: примеры использования двухточечных обменов; особенности двухточечных неблокирующих обменов; реализацию неблокирующих
- 56. 2008 Задания для самостоятельной работы Решения следует высылать по электронной почте: [email protected]
- 57. 2008 Задания для самостоятельной работы Задание 1 Разберите работу следующей программы. Запустите ее на выполнение.
- 58. 2008 #include "mpi.h" #include int main(int argc,char *argv[]) { int myid, numprocs, **buf, source, i; int
- 59. 2008 else { MPI_Probe(MPI_ANY_SOURCE, 0, MPI_COMM_WORLD, &status); source = status.MPI_SOURCE; MPI_Get_count(&status, MPI_INT, &count); for (i =
- 60. 2008 Задания для самостоятельной работы Задание 2 Два вектора a и b размерности N представлены двумя
- 61. 2008 Задания для самостоятельной работы Задание 3 Имеется последовательная программа на языке Fortran 90 решения двумерного
- 62. Задания для самостоятельной работы 2008 Двумерное уравнение Лапласа. Последовательная программа на языке Fortran 90
- 63. Задания для самостоятельной работы 2008 program laplace implicit none integer :: nx, ny, i, j, iter
- 64. Задания для самостоятельной работы 2008 change = change / 100 ! ! Boundary potential ! boundary_potential_x
- 65. Задания для самостоятельной работы 2008 subroutine relax(v, nx, ny, change, iter) implicit none integer :: nx,
- 66. Задания для самостоятельной работы 2008 ! Update potential of each cell x_loop : do i =
- 67. Задания для самостоятельной работы 2008 subroutine output(v, nx, ny, iter) implicit none integer :: nx, ny,
- 68. 2008 0x2dab 57 653 291 vaverage(i, j) = v(i + 1, j) + v(i - 1,
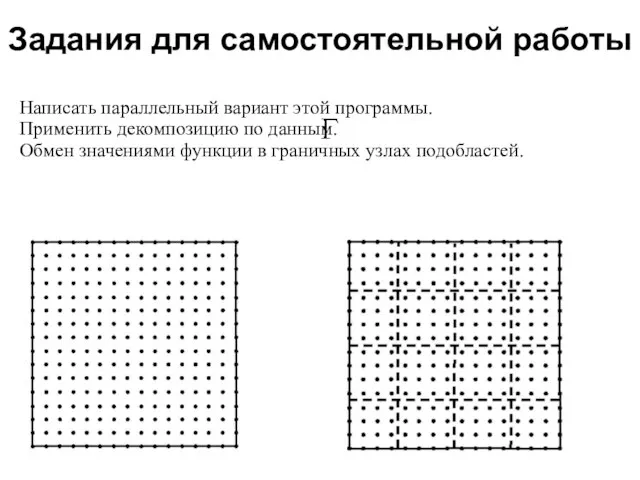
- 69. Задания для самостоятельной работы 2008 Написать параллельный вариант этой программы. Применить декомпозицию по данным. Обмен значениями
- 71. Скачать презентацию
Слайд 2Лекция 4
2008
Аннотация
В лекции описываются средства организации неблокирующих двухточечных обменов. Рассматриваются операции неблокирующих
Лекция 4
2008
Аннотация
В лекции описываются средства организации неблокирующих двухточечных обменов. Рассматриваются операции неблокирующих

Слайд 3План лекции
2008
Пример использования блокирующих двухточечных
обменов
Общая характеристика неблокирующих обменов.
План лекции
2008
Пример использования блокирующих двухточечных
обменов
Общая характеристика неблокирующих обменов.

Слайд 4Одномерное уравнение Лапласа. Метод Якоби
2008
Одномерное уравнение Лапласа. Метод Якоби
2008

Слайд 5Уравнение Лапласа
2008
В качестве примера использования операций двухточечного обмена рассмотрим численное решение уравнения
Уравнение Лапласа
2008
В качестве примера использования операций двухточечного обмена рассмотрим численное решение уравнения

Слайд 6Уравнение Лапласа
2008
Численное решение основано на введении 1- или 2-мерной сетки в области,
Уравнение Лапласа
2008
Численное решение основано на введении 1- или 2-мерной сетки в области,

Слайд 7Уравнение Лапласа
2008
Последовательная программа на языке Fortran 90
Уравнение Лапласа
2008
Последовательная программа на языке Fortran 90

Слайд 8Уравнение Лапласа
2008
program jacobi_serial
implicit none
real, dimension(0:10001) :: x, newx
real :: dx2
integer :: n,
Уравнение Лапласа
2008
program jacobi_serial
implicit none
real, dimension(0:10001) :: x, newx
real :: dx2
integer :: n,

Слайд 9Уравнение Лапласа
2008
x(0) = 0.0
x(n + 1) = 0.0
do k = 1, noiters
Уравнение Лапласа
2008
x(0) = 0.0
x(n + 1) = 0.0
do k = 1, noiters

Слайд 10Уравнение Лапласа
2008
Параллельная программа на языке Fortran 90
Уравнение Лапласа
2008
Параллельная программа на языке Fortran 90

Слайд 11Уравнение Лапласа
2008
Параллельный алгоритм
Параллельный алгоритм основан на декомпозиции по данным – разбиении одномерной
Уравнение Лапласа
2008
Параллельный алгоритм
Параллельный алгоритм основан на декомпозиции по данным – разбиении одномерной

Слайд 12Уравнение Лапласа
2008
program jacobi_parallel
implicit none
include "mpif.h"
real, dimension(0:10001) :: x,newx
real :: dx2
integer :: n,
Уравнение Лапласа
2008
program jacobi_parallel
implicit none
include "mpif.h"
real, dimension(0:10001) :: x,newx
real :: dx2
integer :: n,

Слайд 13Уравнение Лапласа
2008
call MPI_Init(ierr)
call MPI_Comm_rank(MPI_COMM_WORLD, me, ierr)
call MPI_Comm_size(MPI_COMM_WORLD, p, ierr)
tag = 0
ln =
Уравнение Лапласа
2008
call MPI_Init(ierr)
call MPI_Comm_rank(MPI_COMM_WORLD, me, ierr)
call MPI_Comm_size(MPI_COMM_WORLD, p, ierr)
tag = 0
ln =

Слайд 14Уравнение Лапласа
2008
do k = 1, noiters
! Пересылки граничных значений
if(me - 1
Уравнение Лапласа
2008
do k = 1, noiters
! Пересылки граничных значений
if(me - 1

Слайд 15Уравнение Лапласа
2008
! Собираем решение
if(me = = 0) then
do i = 1,
Уравнение Лапласа
2008
! Собираем решение
if(me = = 0) then
do i = 1,

Слайд 16Неблокирующие двухточечные обмены
2008
Неблокирующие двухточечные обмены
2008

Слайд 17Неблокирующие обмены
2008
Вызов подпрограммы неблокирующей передачи инициирует, но не завершает ее. Завершиться выполнение
Неблокирующие обмены
2008
Вызов подпрограммы неблокирующей передачи инициирует, но не завершает ее. Завершиться выполнение

Слайд 18Неблокирующие обмены
2008
Для завершения неблокирующего обмена требуется вызов дополнительной процедуры, которая проверяет, скопированы
Неблокирующие обмены
2008
Для завершения неблокирующего обмена требуется вызов дополнительной процедуры, которая проверяет, скопированы

Слайд 19Неблокирующие обмены
2008
Неблокирующий обмен выполняется в два этапа:
инициализация обмена;
проверка завершения обмена.
Разделение
Неблокирующие обмены
2008
Неблокирующий обмен выполняется в два этапа:
инициализация обмена;
проверка завершения обмена.
Разделение

Слайд 20Неблокирующие обмены
2008
Инициализация неблокирующей стандартной передачи выполняется подпрограммами MPI_I[S, B, R]send. Стандартная неблокирующая
Неблокирующие обмены
2008
Инициализация неблокирующей стандартной передачи выполняется подпрограммами MPI_I[S, B, R]send. Стандартная неблокирующая
![Неблокирующие обмены 2008 Инициализация неблокирующей стандартной передачи выполняется подпрограммами MPI_I[S, B, R]send.](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/461334/slide-19.jpg)
Слайд 21Неблокирующие обмены
2008
Инициализация неблокирующего приема выполняется при вызове подпрограммы:
int MPI_Irecv(void *buf, int count,
Неблокирующие обмены
2008
Инициализация неблокирующего приема выполняется при вызове подпрограммы:
int MPI_Irecv(void *buf, int count,

Слайд 22Неблокирующие обмены
2008
Вызовы подпрограмм неблокирующего обмена формируют
запрос на выполнение операции обмена и
Неблокирующие обмены
2008
Вызовы подпрограмм неблокирующего обмена формируют
запрос на выполнение операции обмена и

Слайд 23Неблокирующие обмены
2008
Проверка выполнения обмена
Проверка фактического выполнения передачи или приема в неблокирующем режиме
Неблокирующие обмены
2008
Проверка выполнения обмена
Проверка фактического выполнения передачи или приема в неблокирующем режиме

Слайд 24Неблокирующие обмены
2008
В том случае, когда одновременно несколько процессов
обмениваются сообщениями, можно использовать
Неблокирующие обмены
2008
В том случае, когда одновременно несколько процессов
обмениваются сообщениями, можно использовать

Слайд 25Неблокирующие обмены
2008
Блокирующие операции проверки
Подпрограмма MPI_Wait блокирует работу процесса до завершения приема или
Неблокирующие обмены
2008
Блокирующие операции проверки
Подпрограмма MPI_Wait блокирует работу процесса до завершения приема или

Слайд 26Неблокирующие обмены
2008
Успешное выполнение подпрограммы MPI_Wait после вызова MPI_Ibsend подразумевает, что буфер передачи
Неблокирующие обмены
2008
Успешное выполнение подпрограммы MPI_Wait после вызова MPI_Ibsend подразумевает, что буфер передачи

Слайд 27Неблокирующие обмены
2008
Проверка завершения всех обменов
Проверка завершения всех обменов выполняется подпрограммой:
int MPI_Waitall(int count,
Неблокирующие обмены
2008
Проверка завершения всех обменов
Проверка завершения всех обменов выполняется подпрограммой:
int MPI_Waitall(int count,

Слайд 28Неблокирующие обмены
2008
В результате выполнения подпрограммы MPI_Waitall запросы, сформированные неблокирующими операциями обмена, аннулируются,
Неблокирующие обмены
2008
В результате выполнения подпрограммы MPI_Waitall запросы, сформированные неблокирующими операциями обмена, аннулируются,

Слайд 29Неблокирующие обмены
2008
Проверка завершения любого числа обменов
Проверка завершения любого числа обменов выполняется подпрограммой:
int
Неблокирующие обмены
2008
Проверка завершения любого числа обменов
Проверка завершения любого числа обменов выполняется подпрограммой:
int

Слайд 30Неблокирующие обмены
2008
Если в списке вообще нет активных запросов или он пуст, вызовы
Неблокирующие обмены
2008
Если в списке вообще нет активных запросов или он пуст, вызовы

Слайд 31Неблокирующие обмены
2008
Неблокирующие процедуры проверки
Подпрограмма MPI_Test выполняет неблокирующую проверку
завершения приема или передачи
Неблокирующие обмены
2008
Неблокирующие процедуры проверки
Подпрограмма MPI_Test выполняет неблокирующую проверку
завершения приема или передачи

Слайд 32Неблокирующие обмены
2008
Неблокирующая проверка завершения всех обменов
Подпрограмма MPI_Testall выполняет неблокирующую проверку
завершения приема
Неблокирующие обмены
2008
Неблокирующая проверка завершения всех обменов
Подпрограмма MPI_Testall выполняет неблокирующую проверку
завершения приема

Слайд 33Неблокирующие обмены
2008
Неблокирующая проверка любого числа обменов
Подпрограмма MPI_Testany выполняет неблокирующую проверку
завершения приема
Неблокирующие обмены
2008
Неблокирующая проверка любого числа обменов
Подпрограмма MPI_Testany выполняет неблокирующую проверку
завершения приема

Слайд 34Неблокирующие обмены
2008
Другие операции проверки
Подпрограммы MPI_Waitsome и MPI_Testsome действуют аналогично подпрограммам MPI_Waitany и
Неблокирующие обмены
2008
Другие операции проверки
Подпрограммы MPI_Waitsome и MPI_Testsome действуют аналогично подпрограммам MPI_Waitany и

Слайд 35Неблокирующие обмены
2008
Интерфейс этих подпрограмм:
int MPI_Waitsome(int incount, MPI_Request requests[], int *outcount, int indices[],
Неблокирующие обмены
2008
Интерфейс этих подпрограмм:
int MPI_Waitsome(int incount, MPI_Request requests[], int *outcount, int indices[],
![Неблокирующие обмены 2008 Интерфейс этих подпрограмм: int MPI_Waitsome(int incount, MPI_Request requests[], int](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/461334/slide-34.jpg)
Слайд 36Неблокирующие обмены
2008
Неблокирующая проверка выполнения обменов
int MPI_Testsome(int incount, MPI_Request requests[], int *outcount, int
Неблокирующие обмены
2008
Неблокирующая проверка выполнения обменов
int MPI_Testsome(int incount, MPI_Request requests[], int *outcount, int
![Неблокирующие обмены 2008 Неблокирующая проверка выполнения обменов int MPI_Testsome(int incount, MPI_Request requests[],](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/461334/slide-35.jpg)
Слайд 37Примеры использования неблокирующих двухточечных обменов
2008
Примеры использования неблокирующих двухточечных обменов
2008

Слайд 38Неблокирующие обмены
2008
Пример 1
program main_mpi
include 'mpif.h'
integer rank, tag, cnt, ierr, status(MPI_STATUS_SIZE)
integer request
real sndbuf(5)
Неблокирующие обмены
2008
Пример 1
program main_mpi
include 'mpif.h'
integer rank, tag, cnt, ierr, status(MPI_STATUS_SIZE)
integer request
real sndbuf(5)

Слайд 39Неблокирующие обмены
2008
if(rank.eq.0) then
call MPI_Isend(sndbuf(1), cnt, MPI_REAL, 1, tag, MPI_COMM_WORLD, request, ierr)
print *,
Неблокирующие обмены
2008
if(rank.eq.0) then
call MPI_Isend(sndbuf(1), cnt, MPI_REAL, 1, tag, MPI_COMM_WORLD, request, ierr)
print *,

Слайд 40Неблокирующие обмены
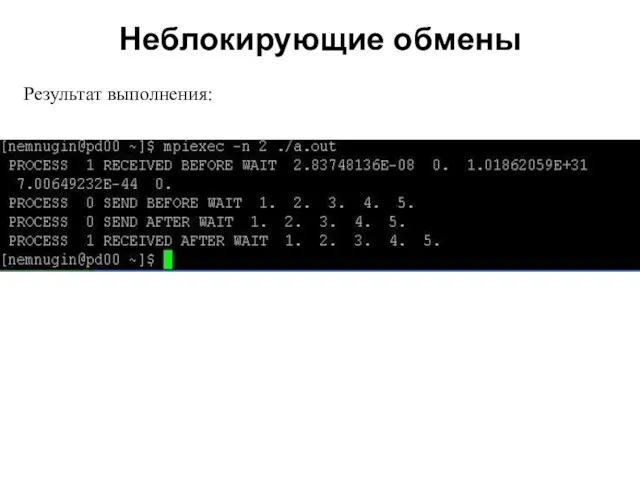
2008
Результат выполнения:
Неблокирующие обмены
2008
Результат выполнения:
Слайд 41Неблокирующие обмены
2008
Пример 2
program main_mpi
include 'mpif.h'
integer rank, tag1, tag2, cnt, ierr, status(MPI_STATUS_SIZE)
integer request
real
Неблокирующие обмены
2008
Пример 2
program main_mpi
include 'mpif.h'
integer rank, tag1, tag2, cnt, ierr, status(MPI_STATUS_SIZE)
integer request
real

Слайд 42Неблокирующие обмены
2008
if (rank.eq.0) then
call MPI_Ssend(sndbuf1, cnt, MPI_REAL, 1, tag1, MPI_COMM_WORLD, ierr)
print *,
Неблокирующие обмены
2008
if (rank.eq.0) then
call MPI_Ssend(sndbuf1, cnt, MPI_REAL, 1, tag1, MPI_COMM_WORLD, ierr)
print *,

Слайд 43Неблокирующие обмены
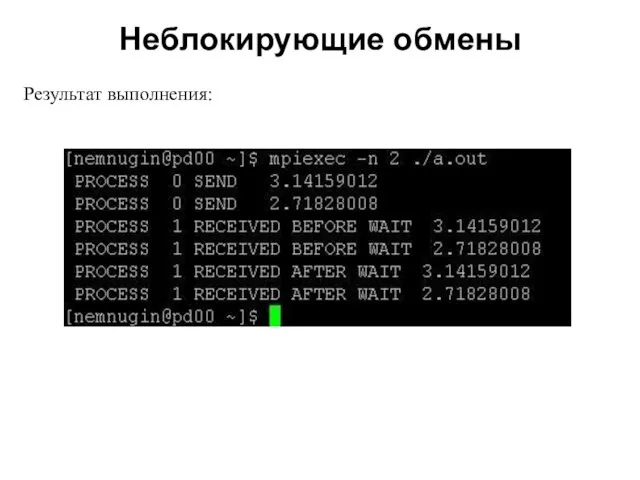
2008
Результат выполнения:
Неблокирующие обмены
2008
Результат выполнения:
Слайд 44Подпрограммы-пробники
2008
Подпрограммы-пробники
2008

Слайд 45Неблокирующие обмены
2008
Неблокирующая проверка сообщения
Неблокирующая проверка сообщения выполняется подпрограммой:
int MPI_Iprobe(int source, int tag,
Неблокирующие обмены
2008
Неблокирующая проверка сообщения
Неблокирующая проверка сообщения выполняется подпрограммой:
int MPI_Iprobe(int source, int tag,

Слайд 46Неблокирующие обмены
2008
Размер полученного сообщения (count) можно определить с помощью вызова подпрограммы
int
Неблокирующие обмены
2008
Размер полученного сообщения (count) можно определить с помощью вызова подпрограммы
int

Слайд 47Неблокирующие обмены
2008
Пример 3
program main_mpi
include 'mpif.h'
integer rank, i, k, ierr, tag, dest, status(MPI_status_size)
real
Неблокирующие обмены
2008
Пример 3
program main_mpi
include 'mpif.h'
integer rank, i, k, ierr, tag, dest, status(MPI_status_size)
real

Слайд 48Неблокирующие обмены
2008
do k = 1, 2
call MPI_Probe(MPI_any_source, tag, MPI_COMM_WORLD, status, ierr)
Неблокирующие обмены
2008
do k = 1, 2
call MPI_Probe(MPI_any_source, tag, MPI_COMM_WORLD, status, ierr)

Слайд 49Неблокирующие обмены
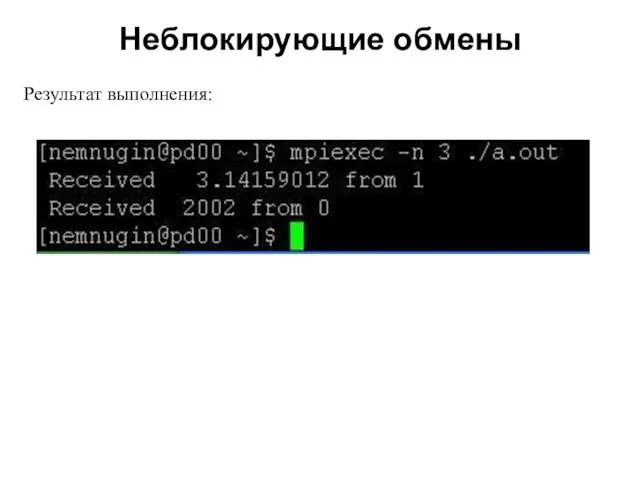
2008
Результат выполнения:
Неблокирующие обмены
2008
Результат выполнения:
Слайд 50Отложенные обмены
2008
Отложенные обмены
2008

Слайд 51Неблокирующие обмены
2008
Достаточно часто приходится сталкиваться с ситуацией, когда обмены с одинаковыми параметрами
Неблокирующие обмены
2008
Достаточно часто приходится сталкиваться с ситуацией, когда обмены с одинаковыми параметрами

Слайд 52Неблокирующие обмены
2008
Запрос для стандартной передачи создается при вызове подпрограммы MPI_Send_init:
int MPI_Send_init(void *buf,
Неблокирующие обмены
2008
Запрос для стандартной передачи создается при вызове подпрограммы MPI_Send_init:
int MPI_Send_init(void *buf,

Слайд 53Неблокирующие обмены
2008
Отложенный запрос может быть сформирован для всех режимов обмена. Для этого
Неблокирующие обмены
2008
Отложенный запрос может быть сформирован для всех режимов обмена. Для этого

Слайд 54Неблокирующие обмены
2008
Подпрограмма MPI_Startall:
int MPI_Startall(int count, MPI_request *requests)
MPI_Startall(count, requests, ierr)
инициирует все обмены, связанные
Неблокирующие обмены
2008
Подпрограмма MPI_Startall:
int MPI_Startall(int count, MPI_request *requests)
MPI_Startall(count, requests, ierr)
инициирует все обмены, связанные

Слайд 552008
В этой лекции мы рассмотрели:
примеры использования двухточечных обменов;
особенности двухточечных
2008
В этой лекции мы рассмотрели:
примеры использования двухточечных обменов;
особенности двухточечных

Слайд 562008
Задания для самостоятельной работы
Решения следует высылать по электронной почте:
[email protected]
2008
Задания для самостоятельной работы
Решения следует высылать по электронной почте:
[email protected]

Слайд 572008
Задания для самостоятельной работы
Задание 1
Разберите работу следующей программы. Запустите ее на выполнение.
2008
Задания для самостоятельной работы
Задание 1
Разберите работу следующей программы. Запустите ее на выполнение.

Слайд 582008
#include "mpi.h"
#include
int main(int argc,char *argv[])
{
int myid, numprocs, **buf, source, i;
2008
#include "mpi.h"
#include
int main(int argc,char *argv[])
{
int myid, numprocs, **buf, source, i;
![2008 #include "mpi.h" #include int main(int argc,char *argv[]) { int myid, numprocs,](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/461334/slide-57.jpg)
Слайд 592008
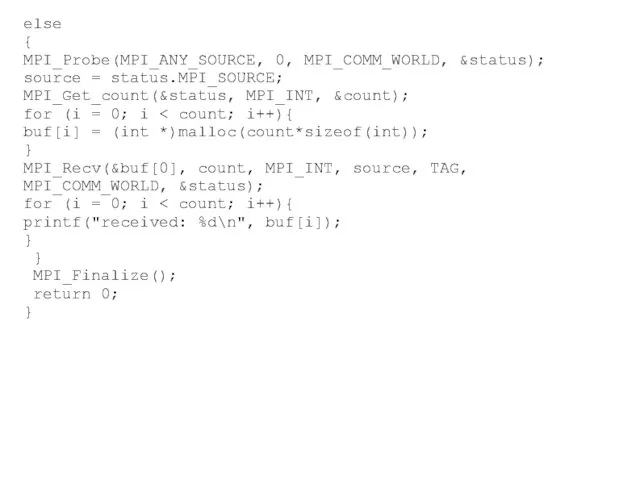
else
{
MPI_Probe(MPI_ANY_SOURCE, 0, MPI_COMM_WORLD, &status);
source = status.MPI_SOURCE;
MPI_Get_count(&status, MPI_INT, &count);
for (i = 0; i
2008
else
{
MPI_Probe(MPI_ANY_SOURCE, 0, MPI_COMM_WORLD, &status);
source = status.MPI_SOURCE;
MPI_Get_count(&status, MPI_INT, &count);
for (i = 0; i
Слайд 602008
Задания для самостоятельной работы
Задание 2
Два вектора a и b размерности N представлены
2008
Задания для самостоятельной работы
Задание 2
Два вектора a и b размерности N представлены

Слайд 612008
Задания для самостоятельной работы
Задание 3
Имеется последовательная программа на языке Fortran 90 решения
2008
Задания для самостоятельной работы
Задание 3
Имеется последовательная программа на языке Fortran 90 решения

Слайд 62Задания для самостоятельной работы
2008
Двумерное уравнение Лапласа. Последовательная программа на языке Fortran 90
Задания для самостоятельной работы
2008
Двумерное уравнение Лапласа. Последовательная программа на языке Fortran 90

Слайд 63Задания для самостоятельной работы
2008
program laplace
implicit none
integer :: nx, ny, i,
Задания для самостоятельной работы
2008
program laplace
implicit none
integer :: nx, ny, i,

Слайд 64Задания для самостоятельной работы
2008
change = change / 100
!
! Boundary potential
!
boundary_potential_x
Задания для самостоятельной работы
2008
change = change / 100
!
! Boundary potential
!
boundary_potential_x

Слайд 65Задания для самостоятельной работы
2008
subroutine relax(v, nx, ny, change, iter)
implicit none
Задания для самостоятельной работы
2008
subroutine relax(v, nx, ny, change, iter)
implicit none

Слайд 66Задания для самостоятельной работы
2008
! Update potential of each cell
x_loop : do
Задания для самостоятельной работы
2008
! Update potential of each cell
x_loop : do

Слайд 67Задания для самостоятельной работы
2008
subroutine output(v, nx, ny, iter)
implicit none
integer
Задания для самостоятельной работы
2008
subroutine output(v, nx, ny, iter)
implicit none
integer

Слайд 682008
0x2dab 57 653 291 vaverage(i, j) = v(i + 1, j) +
2008
0x2dab 57 653 291 vaverage(i, j) = v(i + 1, j) +

Слайд 69Задания для самостоятельной работы
2008
Написать параллельный вариант этой программы.
Применить декомпозицию по данным.
Обмен значениями
Задания для самостоятельной работы
2008
Написать параллельный вариант этой программы.
Применить декомпозицию по данным.
Обмен значениями
 Число 0. Цифра 0
Число 0. Цифра 0 Цветочные мотивы в китайской живописи
Цветочные мотивы в китайской живописи Академика Сахарова пр-т, участок «А» (ЦАО)
Академика Сахарова пр-т, участок «А» (ЦАО) Иуда Искариот
Иуда Искариот УЧИМСЯ ПО-НОВОМУ
УЧИМСЯ ПО-НОВОМУ 3 Уважаемые господа! Представляем вашему вниманию инвестиционный паспорт Кашинского района. Кашинский район находится в самом цен
3 Уважаемые господа! Представляем вашему вниманию инвестиционный паспорт Кашинского района. Кашинский район находится в самом цен Конференция по литературе
Конференция по литературе Кабели автоматики, телемеханики и связи Классификация
Кабели автоматики, телемеханики и связи Классификация Птица года-варакушка
Птица года-варакушка Желтый блокнот. Этапы работы
Желтый блокнот. Этапы работы Дорога на выборы
Дорога на выборы Отрасли фундаментальной психологии
Отрасли фундаментальной психологии Представление о сетях
Представление о сетях Особенности правопри-менения в МЧП
Особенности правопри-менения в МЧП Constructions impersonnelles
Constructions impersonnelles Инклюзивное образование. Принципы, перспективы развития
Инклюзивное образование. Принципы, перспективы развития Типы маркетинга в зависимости от типа спроса
Типы маркетинга в зависимости от типа спроса Лекция 4. Строительство дорожных оснований и покрытий из каменных материалов
Лекция 4. Строительство дорожных оснований и покрытий из каменных материалов Сделано в Китае: особенности национального бизнеса
Сделано в Китае: особенности национального бизнеса Виды корней. Типы корневых систем
Виды корней. Типы корневых систем Административные правоотношения
Административные правоотношения Альберт Эйнштейн
Альберт Эйнштейн СТУДЕНЧЕСКАЯ ЮРИДИЧЕСКАЯ КОНСУЛЬТАЦИЯ ДЛЯ МАЛОИМУЩИХ
СТУДЕНЧЕСКАЯ ЮРИДИЧЕСКАЯ КОНСУЛЬТАЦИЯ ДЛЯ МАЛОИМУЩИХ Сказочный образ в картинах В.Васнецова.
Сказочный образ в картинах В.Васнецова. Лекция ПТМ - 2
Лекция ПТМ - 2 Презентация на тему Русская икона. Древнерусская живопись
Презентация на тему Русская икона. Древнерусская живопись вода и её свойства
вода и её свойства Особенности покупки Поставщиками электрической энергии для покрытия собственных нужд в условиях НОРЭМ Новый порядок учета собст
Особенности покупки Поставщиками электрической энергии для покрытия собственных нужд в условиях НОРЭМ Новый порядок учета собст