ПРОБЛЕМЫ КЛАСТЕРИЗАЦИИ НОВОСТНОГО ПОТОКА Петр Воляк [email protected] NLPseminar, Санкт-Петербург 8 октября 2011 года
- ПРОБЛЕМЫ КЛАСТЕРИЗАЦИИ НОВОСТНОГО ПОТОКА Петр Воляк [email protected] NLPseminar, Санкт-Петербург 8 октября 2011 года

Содержание
- 2. О КОМПАНИИ И ТЕХНОЛОГИЯХ
- 3. О компании «Медиалогия» специализируется на технологиях лингвистического анализа текстовой информации российский лидер в области разработки онлайн-решений
- 4. Что такое система «Медиалогия» БАЗА СМИ ТЕХНОЛОГИИ ОБРАБОТКИ И ИЗВЛЕЧЕНИЯ ДАННЫХ СИСТЕМА ОНЛАЙН АНАЛИЗА СМИ +
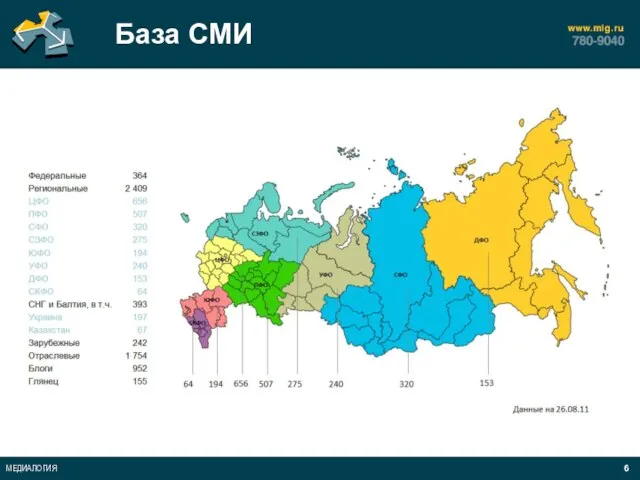
- 5. База СМИ
- 6. База СМИ
- 7. Основные технологии Агрегация онлайн- и оффлайн-СМИ, а также соцмедиа (блоги, форумы, соц.сети) в режиме реального времени
- 8. Named Entity Recognition Выделение позиций Соотнесение с базой объектов (персоны, организации, бренды, геопонятия) Работа правил Ранжирование
- 9. На том же этапе Выделение прямой и косвенной речи Жанровая классификация Рубрикация Выделение фактов и связей
- 10. Продукты Мониторинг упоминаний объектов в СМИ Генерация периодических отчетов Различные продукты с новостной картиной дня Мониторинг
- 11. КЛАСТЕРИЗАЦИЯ
- 12. Гравитационная кластеризация Нормализуем лексику в документе, выкидываем стоп-слова В каждом документе выделяем топ по TF-IDF Подсвечиваем
- 13. Обработка новостей Непрерывная кластеризация: анализ вновь поступивших документов и включение их в уже имеющиеся кластера, проверка
- 14. Главная статья кластера Влиятельность источника Свежесть Максимальная связанность с другими документами кластера Заголовок выбирается из документов,
- 15. Основные проблемы Большие кластера, собирающиеся вокруг похожих событий (стихийные бедствия, происшествия, биржевые котировки) Плохое деление на
- 16. Способы решения Отдельный вектор с биграммами Учет биграмм в лексических векторах Точное определение географии Подключение тезауруса
- 17. Учет географии Сбор данных о географии: Объекты Прилагательные Онтологические связи Определение локации с помощью геобазы: Иерархия
- 18. Выбор заголовка (задача) лексика – отсутствие оценочной, жаргонной, ненормативной лексики Например: (хорошо) 1 января для водителей
- 19. Выбор заголовка (критерии) Длина - в районе 50-70 символов Наличие ключевых слов и объектов а) из
- 21. Скачать презентацию

Слайд 3О компании «Медиалогия»
специализируется на технологиях лингвистического анализа текстовой информации
российский лидер в области
О компании «Медиалогия»
специализируется на технологиях лингвистического анализа текстовой информации
российский лидер в области

Слайд 4Что такое система «Медиалогия»
БАЗА СМИ
ТЕХНОЛОГИИ
ОБРАБОТКИ И
ИЗВЛЕЧЕНИЯ ДАННЫХ
СИСТЕМА ОНЛАЙН
АНАЛИЗА СМИ
+
=
Что такое система «Медиалогия»
БАЗА СМИ
ТЕХНОЛОГИИ
ОБРАБОТКИ И
ИЗВЛЕЧЕНИЯ ДАННЫХ
СИСТЕМА ОНЛАЙН
АНАЛИЗА СМИ
+
=

Слайд 5База СМИ
База СМИ

Слайд 6База СМИ
База СМИ
Слайд 7Основные технологии
Агрегация онлайн- и оффлайн-СМИ, а также соцмедиа (блоги, форумы, соц.сети) в
Основные технологии
Агрегация онлайн- и оффлайн-СМИ, а также соцмедиа (блоги, форумы, соц.сети) в

Слайд 8Named Entity Recognition
Выделение позиций
Соотнесение с базой объектов (персоны, организации, бренды, геопонятия)
Работа правил
Named Entity Recognition
Выделение позиций
Соотнесение с базой объектов (персоны, организации, бренды, геопонятия)
Работа правил

Слайд 9На том же этапе
Выделение прямой и косвенной речи
Жанровая классификация
Рубрикация
Выделение фактов и связей
Далее
На том же этапе
Выделение прямой и косвенной речи
Жанровая классификация
Рубрикация
Выделение фактов и связей
Далее

Слайд 10Продукты
Мониторинг упоминаний объектов в СМИ
Генерация периодических отчетов
Различные продукты с новостной картиной дня
Мониторинг
Продукты
Мониторинг упоминаний объектов в СМИ
Генерация периодических отчетов
Различные продукты с новостной картиной дня
Мониторинг

Слайд 11КЛАСТЕРИЗАЦИЯ
КЛАСТЕРИЗАЦИЯ

Слайд 12Гравитационная кластеризация
Нормализуем лексику в документе, выкидываем стоп-слова
В каждом документе выделяем топ по
Гравитационная кластеризация
Нормализуем лексику в документе, выкидываем стоп-слова
В каждом документе выделяем топ по

Слайд 13Обработка новостей
Непрерывная кластеризация: анализ вновь поступивших документов и включение их в уже
Обработка новостей
Непрерывная кластеризация: анализ вновь поступивших документов и включение их в уже

Слайд 14Главная статья кластера
Влиятельность источника
Свежесть
Максимальная связанность с другими документами кластера
Заголовок выбирается из документов,
Главная статья кластера
Влиятельность источника
Свежесть
Максимальная связанность с другими документами кластера
Заголовок выбирается из документов,

Слайд 15Основные проблемы
Большие кластера, собирающиеся вокруг похожих событий (стихийные бедствия, происшествия, биржевые котировки)
Плохое
Основные проблемы
Большие кластера, собирающиеся вокруг похожих событий (стихийные бедствия, происшествия, биржевые котировки)
Плохое

Слайд 16Способы решения
Отдельный вектор с биграммами
Учет биграмм в лексических векторах
Точное определение географии
Подключение тезауруса
Способы решения
Отдельный вектор с биграммами
Учет биграмм в лексических векторах
Точное определение географии
Подключение тезауруса

Слайд 17Учет географии
Сбор данных о географии:
Объекты
Прилагательные
Онтологические связи
Определение локации с помощью геобазы:
Иерархия
Система координат
Учет географии
Сбор данных о географии:
Объекты
Прилагательные
Онтологические связи
Определение локации с помощью геобазы:
Иерархия
Система координат

Слайд 18Выбор заголовка (задача)
лексика – отсутствие оценочной, жаргонной, ненормативной лексики
Например:
(хорошо) 1 января
Выбор заголовка (задача)
лексика – отсутствие оценочной, жаргонной, ненормативной лексики
Например:
(хорошо) 1 января

Слайд 19Выбор заголовка (критерии)
Длина - в районе 50-70 символов
Наличие ключевых слов и объектов
а)
Выбор заголовка (критерии)
Длина - в районе 50-70 символов
Наличие ключевых слов и объектов
а)

 психол культура
психол культура Всероссийская перепись населения
Всероссийская перепись населения Человек в экономических отношениях 7 класс
Человек в экономических отношениях 7 класс Образцы гистологических препаратов
Образцы гистологических препаратов Организация опытно-экспериментальной и инновационной деятельности в образовательных учреждениях Прохоровского районав 2011-2012 у
Организация опытно-экспериментальной и инновационной деятельности в образовательных учреждениях Прохоровского районав 2011-2012 у Тренажёр
Тренажёр Система (гр. Systema — целое, составленное из частей; соединение) — множество закономерно связанных друг с другом элементов
Система (гр. Systema — целое, составленное из частей; соединение) — множество закономерно связанных друг с другом элементов Фотошкола Пикча. Профессия - фотограф
Фотошкола Пикча. Профессия - фотограф Коучинг Катализирующая роль коучинга в становлении и развитии бизнес-объединений и усовершенствовании образовательных програ
Коучинг Катализирующая роль коучинга в становлении и развитии бизнес-объединений и усовершенствовании образовательных програ Читаешь книги – хорошо. Не читаешь - плохо
Читаешь книги – хорошо. Не читаешь - плохо Кейс. Таргетированная реклама ВК. СК-Моторс (автосалон)
Кейс. Таргетированная реклама ВК. СК-Моторс (автосалон) баннер
баннер Управленческий учет и его место в информационной и учетной системах организации
Управленческий учет и его место в информационной и учетной системах организации Презентация на тему Китай в средние века (6 класс)
Презентация на тему Китай в средние века (6 класс) Костюм древнего египтянина
Костюм древнего египтянина Дизайн гостиничного домика (фотографии)
Дизайн гостиничного домика (фотографии) ...В слове МЫ сто тысяч Я.
...В слове МЫ сто тысяч Я. Презентация на тему Диагностика готовности к школе как условие успешной адаптации первоклассников
Презентация на тему Диагностика готовности к школе как условие успешной адаптации первоклассников Презентация о себе
Презентация о себе Закуски из овощей
Закуски из овощей Уголовное право
Уголовное право Правописание НН-Н в полных прилагательных и причастиях
Правописание НН-Н в полных прилагательных и причастиях От сердца к сердцу
От сердца к сердцу Ориентирование на местности (2 класс)
Ориентирование на местности (2 класс) Кожевенное сырье
Кожевенное сырье Лесопарк – территория здоровья
Лесопарк – территория здоровья Предметно-развивающая среда
Предметно-развивающая среда Color chart and structure chart
Color chart and structure chart