- СТАТИСТИЧЕСКИЕ МЕТОДЫ АНАЛИЗА СВЯЗИ

Содержание
- 2. Признаки, которыми характеризуются единицы совокупности, могут быть взаимосвязанными. Взаимосвязанные признаки могут выступать в одной из ролей:
- 3. По степени тесноты связи делят на статистические и функциональные. Статистическая (стохастическая) связь – это такая связь
- 4. Корреляционная связь частный случай стохастической связи. При корреляционной связи с изменением значения признака Х среднее значение
- 5. Функциональная связь – такая связь, при которой для каждого значения признака-фактора признак-результат принимает одно (иногда несколько)
- 6. По направлению связи делят на прямые и обратные связи. При прямой связи направление изменения результата совпадает
- 7. По форме связи (виду функции f) связи делят на линейные (прямолинейные) и нелинейные (криволинейные) связи. Линейная
- 8. По количеству факторов, действующих на результат, связи подразделяют на однофакторные (парные) и многофакторные связи.
- 9. Порядок изучения парной статистической связи: 1. Качественный (содержательный) анализ связи. На этом этапе производят предварительный анализ
- 10. 3 этап – эмпирический анализ связи состоит в построении группировок (аналитической или комбинационной) и графиков. Для
- 11. Эмпирическая линия регрессия - ломанная линия, построенная по данным аналитической группировки. Число точек ломанной равно числу
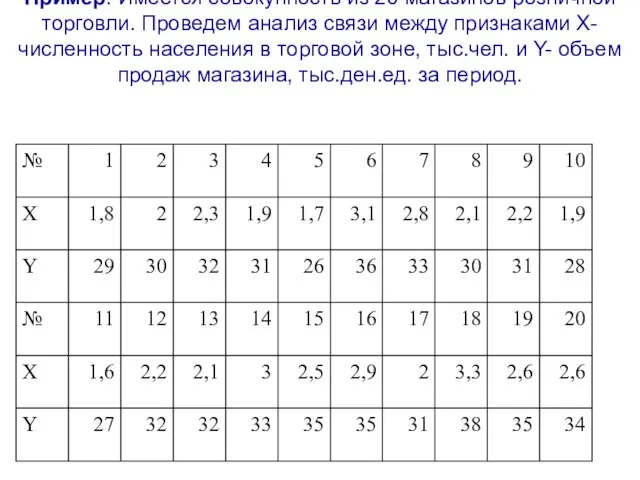
- 12. Пример: Имеется совокупность из 20 магазинов розничной торговли. Проведем анализ связи между признаками Х- численность населения
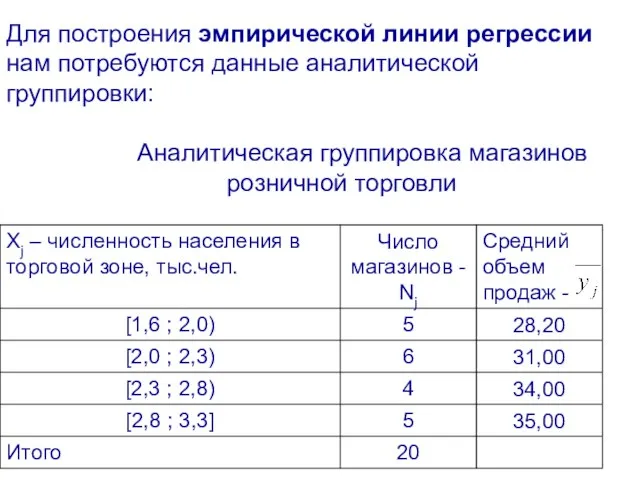
- 13. Для построения эмпирической линии регрессии нам потребуются данные аналитической группировки: Аналитическая группировка магазинов розничной торговли
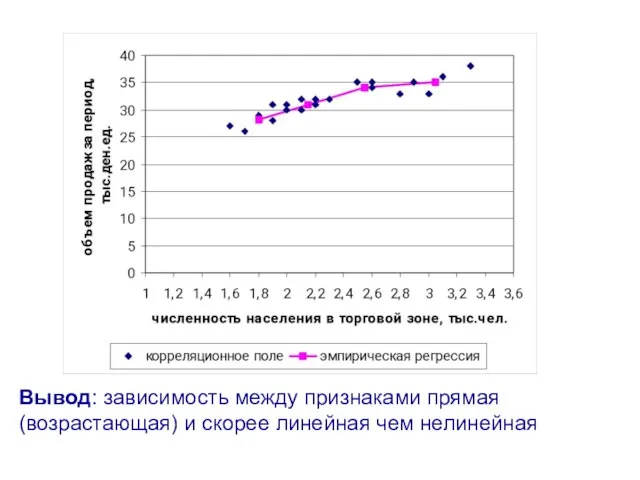
- 14. Вывод: зависимость между признаками прямая (возрастающая) и скорее линейная чем нелинейная
- 15. 4 этап – количественная оценка тесноты связи (корреляционный анализ) состоит в расчете показателей тесноты связи: эмпирического
- 16. Эмпирический коэффициент детерминации (эмпирическое дисперсионное отношение) - ρ2. Данный показатель рассчитывается по данным аналитической группировки, как
- 17. Межгрупповая дисперсия рассчитывается по формуле : Остаточная дисперсия рассчитывается по формуле: Где σ2j – дисперсия признака
- 18. Пример: Рассчитаем эмпирический коэффициент детерминации ρ2=δ2y/σ2y для измерения тесноты связи между численностью населения в торговой зоне
- 19. Общая дисперсия признака Y для нашего примера будет равна: Тогда эмпирический коэффициент детерминации ρ2=6,95 / 9,09=
- 20. Эмпирическое корреляционное отношение - ρ. Данный показатель представляет собой корень из эмпирического коэффициента детерминации. Он измеряет
- 21. В нашем примере: Следовательно, связь между численностью населения в торговой зоне и объемом продаж достаточно тесная.
- 22. Коэффициент Фехнера - Кф служит для измерения тесноты линейной связи. Изменяется в пределах от -1 до
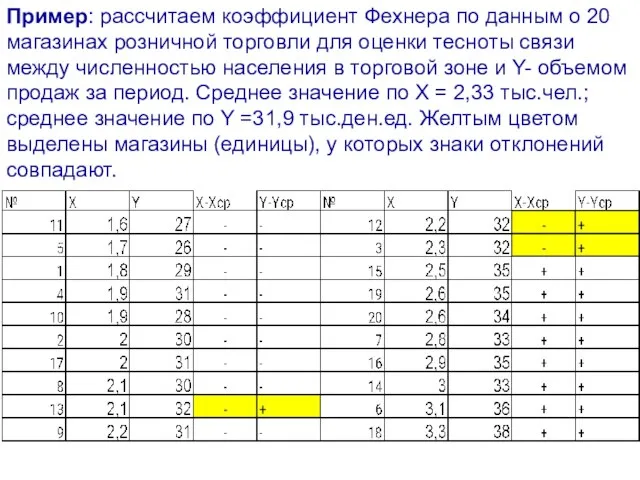
- 23. Пример: рассчитаем коэффициент Фехнера по данным о 20 магазинах розничной торговли для оценки тесноты связи между
- 24. Таким образом число совпадений С=17, число несовпадений равно Н=3. Следовательно, Кф= (17 - 3) / (17
- 25. Коэффициент линейной парной корреляции используется для оценки степени тесноты линейной связи: σх, σy - среднее квадратические
- 26. Область допустимых значений линейного коэффициента корреляции от -1 до +1. Если | rx,y |→1 , то
- 27. Пример: рассчитаем коэффициент линейной парной корреляции между численностью населения в торговой зоне и Y- объемом продаж
- 28. Если сравнить значения эмпирического корреляционного отношения (ρ) с линейным парным коэффициентом корреляции ( r ), то
- 29. 5 этап - установление аналитической зависимости между признаками (регрессионный анализ) Регрессия – зависимость среднего значения какой-либо
- 30. Линейное парное (однофакторное) уравнение регрессии имеет вид: M(yi│x=xi)= f(xi) = а + b·xi , где M(yi│x=xi)
- 31. При построении уравнения регрессии f(x) мы должны: 1) определить вид уравнения (линейное или нелинейное и какое
- 32. 5.1. Выбор формы связи (вида аналитической зависимости). Наиболее часто для описания статистической связи признаков используется линейное
- 33. Методы выявления формы связи: - графический (вид корреляционного поля и эмпирической линии регрессии); - теоретический анализ
- 34. 5.2. Оценки параметров линейной регрессии (а и b) могут быть найдены разными методами: методом наименьших квадратов;
- 35. Суть МНК: Пусть имеются n наблюдений признаков х и y. Причем известен вид уравнения регрессии -
- 36. Проиллюстрируем суть данного метода графически. Попытаемся подобрать прямую линию, которая ближе всего расположена к точкам корреляционного
- 37. Значения yi и xi i=1;n нам известны, это данные наблюдений. В функции S они представляют собой
- 38. В результате получим систему из 2-ух нормальных линейных уравнений:
- 39. Решая данную систему, найдем искомые оценки параметров. Оценка параметра b может быть рассчитана также через коэффициент
- 40. Знак коэффициента регрессии b указывает направление связи (если b>0, связь прямая, если b Величина b показывает
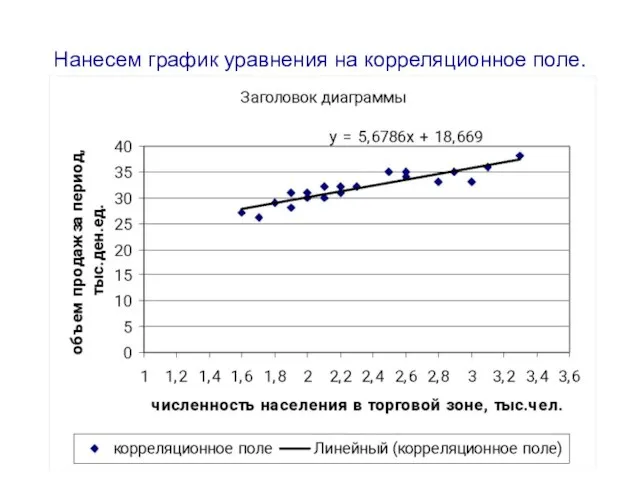
- 41. Пример: построим линейное уравнение регрессии объема продаж магазина (y) от значений фактора x– численности населения в
- 42. Нанесем график уравнения на корреляционное поле.
- 43. 5.3. - Оценка качества уравнения регрессии. Под качеством (адекватностью) уравнения регрессии понимается степень близости (соответствия) рассчитанных
- 44. Наиболее широкое применение из них получил теоретический коэффициент детерминации – R2. Данный показатель рассчитывается, как отношение
- 45. В регрессионном анализе также действует теорема о сложении дисперсий, согласно которой общая дисперсия признака-результата равна сумме
- 46. Данный показатель (R2) характеризует долю вариации (дисперсии) признака-результата y, объясняемую уравнением регрессии (а, следовательно, и фактором
- 47. 2. Средняя квадратическая ошибка уравнения регрессии представляет собой среднее квадратическое отклонение наблюдаемых значений признака - результата
- 48. Показатели качества (адекватности) используют также для решения задачи выбора вида функциональной зависимости. Выбор может быть осуществлен
- 49. Пример: рассчитаем показатель качества - коэффициент детерминации для уравнения: f(xi)=18,67 + 5,68∙хi R2=r2yx=0,9072=0,82. То есть 82
- 50. Прогнозирование по уравнению регрессии означает построение доверительного интервала для ожидаемого (прогнозируемого) значения признака-результата Y при заданном
- 51. μпрогноза – средняя ошибка прогноза определяется в случае линейной парной регрессии по формуле: где s2u –
- 52. Пример: требуется построитьдоверительный интервал для ожидаемого (прогнозируемого) значения Y, если Х примет значение равное 105% от
- 54. Скачать презентацию
Слайд 2Признаки, которыми характеризуются единицы совокупности, могут быть взаимосвязанными. Взаимосвязанные признаки могут выступать
Признаки, которыми характеризуются единицы совокупности, могут быть взаимосвязанными. Взаимосвязанные признаки могут выступать

Слайд 3По степени тесноты связи делят на статистические и функциональные.
Статистическая (стохастическая) связь –
По степени тесноты связи делят на статистические и функциональные.
Статистическая (стохастическая) связь –

Слайд 4Корреляционная связь частный случай стохастической связи. При корреляционной связи с изменением значения
Корреляционная связь частный случай стохастической связи. При корреляционной связи с изменением значения

Слайд 5Функциональная связь – такая связь, при которой для каждого значения признака-фактора
признак-результат
Функциональная связь – такая связь, при которой для каждого значения признака-фактора
признак-результат

Слайд 6По направлению связи делят на прямые и обратные связи.
При прямой связи
По направлению связи делят на прямые и обратные связи.
При прямой связи

Слайд 7По форме связи (виду функции f) связи делят на линейные (прямолинейные) и
По форме связи (виду функции f) связи делят на линейные (прямолинейные) и

Слайд 8По количеству факторов, действующих на результат, связи подразделяют на однофакторные (парные) и
По количеству факторов, действующих на результат, связи подразделяют на однофакторные (парные) и

Слайд 9Порядок изучения парной статистической связи:
1. Качественный (содержательный) анализ связи. На этом этапе
Порядок изучения парной статистической связи:
1. Качественный (содержательный) анализ связи. На этом этапе

Слайд 103 этап – эмпирический анализ связи
состоит в построении группировок (аналитической или комбинационной)
3 этап – эмпирический анализ связи состоит в построении группировок (аналитической или комбинационной)

Слайд 11Эмпирическая линия регрессия - ломанная линия, построенная по данным аналитической группировки. Число
Эмпирическая линия регрессия - ломанная линия, построенная по данным аналитической группировки. Число

Слайд 12Пример: Имеется совокупность из 20 магазинов розничной торговли. Проведем анализ связи между
Пример: Имеется совокупность из 20 магазинов розничной торговли. Проведем анализ связи между
Слайд 13Для построения эмпирической линии регрессии нам потребуются данные аналитической группировки: Аналитическая группировка
Для построения эмпирической линии регрессии нам потребуются данные аналитической группировки: Аналитическая группировка
Слайд 14Вывод: зависимость между признаками прямая (возрастающая) и скорее линейная чем нелинейная
Вывод: зависимость между признаками прямая (возрастающая) и скорее линейная чем нелинейная
Слайд 154 этап – количественная оценка тесноты связи (корреляционный анализ) состоит в расчете
4 этап – количественная оценка тесноты связи (корреляционный анализ) состоит в расчете

Слайд 16Эмпирический коэффициент детерминации (эмпирическое дисперсионное отношение) - ρ2.
Данный показатель рассчитывается по
Эмпирический коэффициент детерминации (эмпирическое дисперсионное отношение) - ρ2. Данный показатель рассчитывается по

Слайд 17Межгрупповая дисперсия рассчитывается по формуле :
Остаточная дисперсия рассчитывается по формуле:
Где σ2j
Межгрупповая дисперсия рассчитывается по формуле :
Остаточная дисперсия рассчитывается по формуле:
Где σ2j

Слайд 18Пример: Рассчитаем эмпирический коэффициент детерминации ρ2=δ2y/σ2y для измерения тесноты связи между численностью
Пример: Рассчитаем эмпирический коэффициент детерминации ρ2=δ2y/σ2y для измерения тесноты связи между численностью

Слайд 19Общая дисперсия признака Y для нашего примера будет равна:
Тогда эмпирический коэффициент детерминации
Общая дисперсия признака Y для нашего примера будет равна:
Тогда эмпирический коэффициент детерминации

Слайд 20Эмпирическое корреляционное отношение - ρ.
Данный показатель представляет собой корень из эмпирического
Эмпирическое корреляционное отношение - ρ. Данный показатель представляет собой корень из эмпирического

Слайд 21В нашем примере:
Следовательно, связь между численностью населения в торговой зоне и объемом
В нашем примере:
Следовательно, связь между численностью населения в торговой зоне и объемом

Слайд 22Коэффициент Фехнера - Кф служит для измерения тесноты линейной связи. Изменяется в
Коэффициент Фехнера - Кф служит для измерения тесноты линейной связи. Изменяется в

Слайд 23Пример: рассчитаем коэффициент Фехнера по данным о 20 магазинах розничной торговли для
Пример: рассчитаем коэффициент Фехнера по данным о 20 магазинах розничной торговли для
Слайд 24Таким образом число совпадений С=17, число несовпадений равно Н=3.
Следовательно, Кф= (17
Таким образом число совпадений С=17, число несовпадений равно Н=3. Следовательно, Кф= (17

Слайд 25Коэффициент линейной парной корреляции используется для оценки степени тесноты линейной связи:
σх, σy
Коэффициент линейной парной корреляции используется для оценки степени тесноты линейной связи:
σх, σy

Слайд 26Область допустимых значений линейного коэффициента корреляции от -1 до +1.
Если |
Область допустимых значений линейного коэффициента корреляции от -1 до +1. Если |

Слайд 27Пример: рассчитаем коэффициент линейной парной корреляции между численностью населения в торговой зоне
Пример: рассчитаем коэффициент линейной парной корреляции между численностью населения в торговой зоне

Слайд 28Если сравнить значения эмпирического корреляционного отношения (ρ) с линейным парным коэффициентом корреляции
Если сравнить значения эмпирического корреляционного отношения (ρ) с линейным парным коэффициентом корреляции

Слайд 295 этап - установление аналитической зависимости между признаками (регрессионный анализ)
Регрессия – зависимость
5 этап - установление аналитической зависимости между признаками (регрессионный анализ)
Регрессия – зависимость

Слайд 30Линейное парное (однофакторное) уравнение регрессии имеет вид:
M(yi│x=xi)= f(xi) = а +
Линейное парное (однофакторное) уравнение регрессии имеет вид:
M(yi│x=xi)= f(xi) = а +

Слайд 31При построении уравнения регрессии f(x) мы должны:
1) определить вид уравнения (линейное
При построении уравнения регрессии f(x) мы должны: 1) определить вид уравнения (линейное

Слайд 325.1. Выбор формы связи (вида аналитической зависимости).
Наиболее часто для описания статистической
5.1. Выбор формы связи (вида аналитической зависимости). Наиболее часто для описания статистической

Слайд 33Методы выявления формы связи:
- графический (вид корреляционного поля и эмпирической линии регрессии);
-
Методы выявления формы связи: - графический (вид корреляционного поля и эмпирической линии регрессии); -

Слайд 345.2. Оценки параметров линейной регрессии (а и b) могут быть найдены разными
5.2. Оценки параметров линейной регрессии (а и b) могут быть найдены разными

Слайд 35Суть МНК:
Пусть имеются n наблюдений признаков х и y. Причем известен вид
Суть МНК: Пусть имеются n наблюдений признаков х и y. Причем известен вид

Слайд 36Проиллюстрируем суть данного метода графически. Попытаемся подобрать прямую линию, которая ближе всего
Проиллюстрируем суть данного метода графически. Попытаемся подобрать прямую линию, которая ближе всего
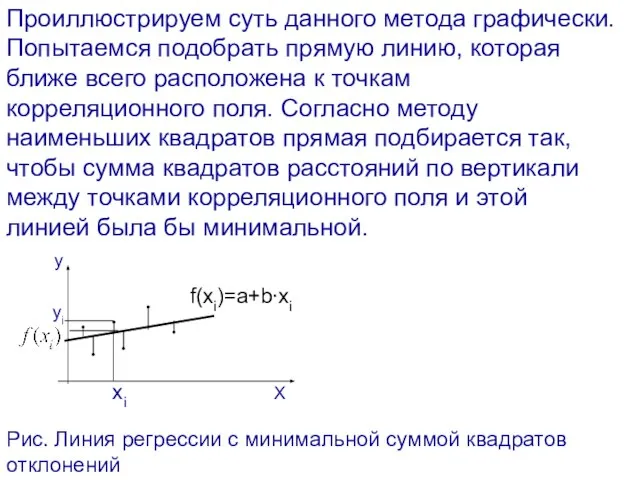
Слайд 37Значения yi и xi i=1;n нам известны, это данные наблюдений. В функции
Значения yi и xi i=1;n нам известны, это данные наблюдений. В функции

Слайд 38В результате получим систему из 2-ух нормальных линейных уравнений:
В результате получим систему из 2-ух нормальных линейных уравнений:

Слайд 39Решая данную систему, найдем искомые оценки параметров.
Оценка параметра b может быть рассчитана
Решая данную систему, найдем искомые оценки параметров.
Оценка параметра b может быть рассчитана

Слайд 40Знак коэффициента регрессии b указывает направление связи (если b>0, связь прямая, если
Знак коэффициента регрессии b указывает направление связи (если b>0, связь прямая, если

Слайд 41Пример: построим линейное уравнение регрессии объема продаж магазина (y) от значений фактора
Пример: построим линейное уравнение регрессии объема продаж магазина (y) от значений фактора

Слайд 42Нанесем график уравнения на корреляционное поле.
Нанесем график уравнения на корреляционное поле.
Слайд 435.3. - Оценка качества уравнения регрессии.
Под качеством (адекватностью) уравнения регрессии понимается степень
5.3. - Оценка качества уравнения регрессии.
Под качеством (адекватностью) уравнения регрессии понимается степень

Слайд 44Наиболее широкое применение из них получил теоретический коэффициент детерминации – R2.
Данный
Наиболее широкое применение из них получил теоретический коэффициент детерминации – R2. Данный

Слайд 45В регрессионном анализе также действует теорема о сложении дисперсий, согласно которой общая
В регрессионном анализе также действует теорема о сложении дисперсий, согласно которой общая

Слайд 46Данный показатель (R2) характеризует долю вариации (дисперсии) признака-результата y, объясняемую уравнением регрессии
Данный показатель (R2) характеризует долю вариации (дисперсии) признака-результата y, объясняемую уравнением регрессии

Слайд 472. Средняя квадратическая ошибка уравнения регрессии представляет собой среднее квадратическое отклонение наблюдаемых
2. Средняя квадратическая ошибка уравнения регрессии представляет собой среднее квадратическое отклонение наблюдаемых

Слайд 48Показатели качества (адекватности) используют также для решения задачи выбора вида функциональной зависимости.
Показатели качества (адекватности) используют также для решения задачи выбора вида функциональной зависимости.

Слайд 49Пример: рассчитаем показатель качества - коэффициент детерминации для уравнения:
f(xi)=18,67 + 5,68∙хi
R2=r2yx=0,9072=0,82.
Пример: рассчитаем показатель качества - коэффициент детерминации для уравнения:
f(xi)=18,67 + 5,68∙хi
R2=r2yx=0,9072=0,82.

Слайд 50Прогнозирование по уравнению регрессии
означает построение доверительного интервала для ожидаемого (прогнозируемого) значения признака-результата
Прогнозирование по уравнению регрессии означает построение доверительного интервала для ожидаемого (прогнозируемого) значения признака-результата

Слайд 51μпрогноза – средняя ошибка прогноза определяется в случае линейной парной регрессии по
μпрогноза – средняя ошибка прогноза определяется в случае линейной парной регрессии по

Слайд 52Пример: требуется построитьдоверительный интервал для ожидаемого (прогнозируемого) значения Y, если Х примет
Пример: требуется построитьдоверительный интервал для ожидаемого (прогнозируемого) значения Y, если Х примет

 See on taime organ See voib olla soodav voi mittesoodav See tekib uhel taime eluperioodil Selle abil taim voib paljuneda kogu maailmas
See on taime organ See voib olla soodav voi mittesoodav See tekib uhel taime eluperioodil Selle abil taim voib paljuneda kogu maailmas Из чего состоит системный блок компьютера
Из чего состоит системный блок компьютера Обеспечение информационного взаимодействия программных средств декларанта – АПС «ЭПС» при декларировании товаров в электронной
Обеспечение информационного взаимодействия программных средств декларанта – АПС «ЭПС» при декларировании товаров в электронной О вреде курения.
О вреде курения. Женский костюм Белгородского края
Женский костюм Белгородского края Организация месячника военнопатриотической и оборонно-массовой работы в ОО
Организация месячника военнопатриотической и оборонно-массовой работы в ОО ребусы РС 2022г
ребусы РС 2022г ЮРИЙ ДОЛГОРУКИЙ Памятники Юрию Долгорукому в Москве.
ЮРИЙ ДОЛГОРУКИЙ Памятники Юрию Долгорукому в Москве. Аптраковский селский дом культуры
Аптраковский селский дом культуры Презентация на тему Движения земной коры
Презентация на тему Движения земной коры Презентация 12 декабря
Презентация 12 декабря Обзор продуктовой линейки МРТ 2019
Обзор продуктовой линейки МРТ 2019 Моль
Моль Декоративно-прикладное искусство Западной Европы XVII в. 5 класс
Декоративно-прикладное искусство Западной Европы XVII в. 5 класс horse
horse Многогранники в архитектуре
Многогранники в архитектуре Изучение административного устройства Ростовской области
Изучение административного устройства Ростовской области Виды соединений материалов. Резьбовые соединения
Виды соединений материалов. Резьбовые соединения Microsoft Dynamics Axapta
Microsoft Dynamics Axapta Физиология выделения
Физиология выделения Анна Анастази (1908–2001)
Анна Анастази (1908–2001) Сердечно-легочнаяреанимация.
Сердечно-легочнаяреанимация. Мультимедиа.Аналоговой и цифровой звук
Мультимедиа.Аналоговой и цифровой звук CARCINOMA OF GALLBLADDER AND CHOLICYSTITIS
CARCINOMA OF GALLBLADDER AND CHOLICYSTITIS Коренной перелом в Великой Отечественной войне
Коренной перелом в Великой Отечественной войне Основы теории построения чертежа
Основы теории построения чертежа Мотивирование топ-менеджеров
Мотивирование топ-менеджеров Презентация на тему Типы химической связи
Презентация на тему Типы химической связи