- Введение в параллельное программирование в системах с общей памятью

Содержание
- 2. НГУ, «Введение в параллельное программирование в системах с общей памятью» (ММФ, 1 курс, «Программирование») Занятие 1
- 3. НГУ, «Введение в параллельное программирование в системах с общей памятью» (ММФ, 1 курс, «Программирование») Занятие 1
- 4. НГУ, «Введение в параллельное программирование в системах с общей памятью» (ММФ, 1 курс, «Программирование») Занятие 1
- 5. НГУ, «Введение в параллельное программирование в системах с общей памятью» (ММФ, 1 курс, «Программирование») Занятие 1
- 6. НГУ, «Введение в параллельное программирование в системах с общей памятью» (ММФ, 1 курс, «Программирование») Занятие 1
- 7. НГУ, «Введение в параллельное программирование в системах с общей памятью» (ММФ, 1 курс, «Программирование») Занятие 1
- 8. НГУ, «Введение в параллельное программирование в системах с общей памятью» (ММФ, 1 курс, «Программирование») Занятие 1
- 9. НГУ, «Введение в параллельное программирование в системах с общей памятью» (ММФ, 1 курс, «Программирование») Занятие 1
- 10. НГУ, «Введение в параллельное программирование в системах с общей памятью» (ММФ, 1 курс, «Программирование») Занятие 1
- 11. НГУ, «Введение в параллельное программирование в системах с общей памятью» (ММФ, 1 курс, «Программирование») Занятие 1
- 12. НГУ, «Введение в параллельное программирование в системах с общей памятью» (ММФ, 1 курс, «Программирование») Занятие 1
- 13. НГУ, «Введение в параллельное программирование в системах с общей памятью» (ММФ, 1 курс, «Программирование») Занятие 1
- 14. НГУ, «Введение в параллельное программирование в системах с общей памятью» (ММФ, 1 курс, «Программирование») Занятие 1
- 15. НГУ, «Введение в параллельное программирование в системах с общей памятью» (ММФ, 1 курс, «Программирование») Занятие 1
- 16. НГУ, «Введение в параллельное программирование в системах с общей памятью» (ММФ, 1 курс, «Программирование») Занятие 1
- 17. НГУ, «Введение в параллельное программирование в системах с общей памятью» (ММФ, 1 курс, «Программирование») Занятие 1
- 18. НГУ, «Введение в параллельное программирование в системах с общей памятью» (ММФ, 1 курс, «Программирование») Занятие 1
- 19. НГУ, «Введение в параллельное программирование в системах с общей памятью» (ММФ, 1 курс, «Программирование») Занятие 1
- 20. НГУ, «Введение в параллельное программирование в системах с общей памятью» (ММФ, 1 курс, «Программирование») Занятие 1
- 21. НГУ, «Введение в параллельное программирование в системах с общей памятью» (ММФ, 1 курс, «Программирование») Занятие 1
- 22. НГУ, «Введение в параллельное программирование в системах с общей памятью» (ММФ, 1 курс, «Программирование») Занятие 1
- 23. НГУ, «Введение в параллельное программирование в системах с общей памятью» (ММФ, 1 курс, «Программирование») Занятие 1
- 24. НГУ, «Введение в параллельное программирование в системах с общей памятью» (ММФ, 1 курс, «Программирование») Занятие 1
- 25. НГУ, «Введение в параллельное программирование в системах с общей памятью» (ММФ, 1 курс, «Программирование») Занятие 1
- 26. НГУ, «Введение в параллельное программирование в системах с общей памятью» (ММФ, 1 курс, «Программирование») Занятие 1
- 27. НГУ, «Введение в параллельное программирование в системах с общей памятью» (ММФ, 1 курс, «Программирование») Занятие 1
- 28. НГУ, «Введение в параллельное программирование в системах с общей памятью» (ММФ, 1 курс, «Программирование») Занятие 1
- 29. НГУ, «Введение в параллельное программирование в системах с общей памятью» (ММФ, 1 курс, «Программирование») Занятие 1
- 30. НГУ, «Введение в параллельное программирование в системах с общей памятью» (ММФ, 1 курс, «Программирование») Занятие 1
- 31. НГУ, «Введение в параллельное программирование в системах с общей памятью» (ММФ, 1 курс, «Программирование») Занятие 1
- 32. НГУ, «Введение в параллельное программирование в системах с общей памятью» (ММФ, 1 курс, «Программирование») Занятие 1
- 33. НГУ, «Введение в параллельное программирование в системах с общей памятью» (ММФ, 1 курс, «Программирование») Занятие 1
- 34. НГУ, «Введение в параллельное программирование в системах с общей памятью» (ММФ, 1 курс, «Программирование») Занятие 1
- 35. НГУ, «Введение в параллельное программирование в системах с общей памятью» (ММФ, 1 курс, «Программирование») Занятие 1
- 36. НГУ, «Введение в параллельное программирование в системах с общей памятью» (ММФ, 1 курс, «Программирование») Занятие 1
- 37. НГУ, «Введение в параллельное программирование в системах с общей памятью» (ММФ, 1 курс, «Программирование») Занятие 1
- 38. НГУ, «Введение в параллельное программирование в системах с общей памятью» (ММФ, 1 курс, «Программирование») Занятие 1
- 39. НГУ, «Введение в параллельное программирование в системах с общей памятью» (ММФ, 1 курс, «Программирование») Занятие 1
- 40. НГУ, «Введение в параллельное программирование в системах с общей памятью» (ММФ, 1 курс, «Программирование») Занятие 1
- 41. НГУ, «Введение в параллельное программирование в системах с общей памятью» (ММФ, 1 курс, «Программирование») Занятие 1
- 42. НГУ, «Введение в параллельное программирование в системах с общей памятью» (ММФ, 1 курс, «Программирование») Занятие 1
- 43. НГУ, «Введение в параллельное программирование в системах с общей памятью» (ММФ, 1 курс, «Программирование») Занятие 1
- 44. НГУ, «Введение в параллельное программирование в системах с общей памятью» (ММФ, 1 курс, «Программирование») Занятие 1
- 45. НГУ, «Введение в параллельное программирование в системах с общей памятью» (ММФ, 1 курс, «Программирование») Занятие 1
- 46. НГУ, «Введение в параллельное программирование в системах с общей памятью» (ММФ, 1 курс, «Программирование») Занятие 1
- 47. НГУ, «Введение в параллельное программирование в системах с общей памятью» (ММФ, 1 курс, «Программирование») Занятие 1
- 48. НГУ, «Введение в параллельное программирование в системах с общей памятью» (ММФ, 1 курс, «Программирование») Занятие 1
- 50. Скачать презентацию

Слайд 3НГУ, «Введение в параллельное программирование в системах с общей памятью»
(ММФ, 1
НГУ, «Введение в параллельное программирование в системах с общей памятью» (ММФ, 1

Слайд 4НГУ, «Введение в параллельное программирование в системах с общей памятью»
(ММФ, 1
НГУ, «Введение в параллельное программирование в системах с общей памятью» (ММФ, 1

Слайд 5НГУ, «Введение в параллельное программирование в системах с общей памятью»
(ММФ, 1
НГУ, «Введение в параллельное программирование в системах с общей памятью» (ММФ, 1

Слайд 6НГУ, «Введение в параллельное программирование в системах с общей памятью»
(ММФ, 1
НГУ, «Введение в параллельное программирование в системах с общей памятью» (ММФ, 1

Слайд 7НГУ, «Введение в параллельное программирование в системах с общей памятью»
(ММФ, 1
НГУ, «Введение в параллельное программирование в системах с общей памятью» (ММФ, 1

Слайд 8НГУ, «Введение в параллельное программирование в системах с общей памятью»
(ММФ, 1
НГУ, «Введение в параллельное программирование в системах с общей памятью» (ММФ, 1

Слайд 9НГУ, «Введение в параллельное программирование в системах с общей памятью»
(ММФ, 1
НГУ, «Введение в параллельное программирование в системах с общей памятью» (ММФ, 1

Слайд 10НГУ, «Введение в параллельное программирование в системах с общей памятью»
(ММФ, 1
НГУ, «Введение в параллельное программирование в системах с общей памятью» (ММФ, 1

Слайд 11НГУ, «Введение в параллельное программирование в системах с общей памятью»
(ММФ, 1
НГУ, «Введение в параллельное программирование в системах с общей памятью» (ММФ, 1

Слайд 12НГУ, «Введение в параллельное программирование в системах с общей памятью»
(ММФ, 1
НГУ, «Введение в параллельное программирование в системах с общей памятью» (ММФ, 1

Слайд 13НГУ, «Введение в параллельное программирование в системах с общей памятью»
(ММФ, 1
НГУ, «Введение в параллельное программирование в системах с общей памятью» (ММФ, 1

Слайд 14НГУ, «Введение в параллельное программирование в системах с общей памятью»
(ММФ, 1
НГУ, «Введение в параллельное программирование в системах с общей памятью» (ММФ, 1

Слайд 15НГУ, «Введение в параллельное программирование в системах с общей памятью»
(ММФ, 1
НГУ, «Введение в параллельное программирование в системах с общей памятью» (ММФ, 1

Слайд 16НГУ, «Введение в параллельное программирование в системах с общей памятью»
(ММФ, 1
НГУ, «Введение в параллельное программирование в системах с общей памятью» (ММФ, 1

Слайд 17НГУ, «Введение в параллельное программирование в системах с общей памятью»
(ММФ, 1
НГУ, «Введение в параллельное программирование в системах с общей памятью» (ММФ, 1

Слайд 18НГУ, «Введение в параллельное программирование в системах с общей памятью»
(ММФ, 1
НГУ, «Введение в параллельное программирование в системах с общей памятью» (ММФ, 1

Слайд 19НГУ, «Введение в параллельное программирование в системах с общей памятью»
(ММФ, 1
НГУ, «Введение в параллельное программирование в системах с общей памятью» (ММФ, 1

Слайд 20НГУ, «Введение в параллельное программирование в системах с общей памятью»
(ММФ, 1
НГУ, «Введение в параллельное программирование в системах с общей памятью» (ММФ, 1

Слайд 21НГУ, «Введение в параллельное программирование в системах с общей памятью»
(ММФ, 1
НГУ, «Введение в параллельное программирование в системах с общей памятью» (ММФ, 1

Слайд 22НГУ, «Введение в параллельное программирование в системах с общей памятью»
(ММФ, 1
НГУ, «Введение в параллельное программирование в системах с общей памятью» (ММФ, 1

Слайд 23НГУ, «Введение в параллельное программирование в системах с общей памятью»
(ММФ, 1
НГУ, «Введение в параллельное программирование в системах с общей памятью» (ММФ, 1

Слайд 24НГУ, «Введение в параллельное программирование в системах с общей памятью»
(ММФ, 1
НГУ, «Введение в параллельное программирование в системах с общей памятью» (ММФ, 1

Слайд 25НГУ, «Введение в параллельное программирование в системах с общей памятью»
(ММФ, 1
НГУ, «Введение в параллельное программирование в системах с общей памятью» (ММФ, 1

Слайд 26НГУ, «Введение в параллельное программирование в системах с общей памятью»
(ММФ, 1
НГУ, «Введение в параллельное программирование в системах с общей памятью» (ММФ, 1

Слайд 27НГУ, «Введение в параллельное программирование в системах с общей памятью»
(ММФ, 1
НГУ, «Введение в параллельное программирование в системах с общей памятью» (ММФ, 1

Слайд 28НГУ, «Введение в параллельное программирование в системах с общей памятью»
(ММФ, 1
НГУ, «Введение в параллельное программирование в системах с общей памятью» (ММФ, 1

Слайд 29НГУ, «Введение в параллельное программирование в системах с общей памятью»
(ММФ, 1
НГУ, «Введение в параллельное программирование в системах с общей памятью» (ММФ, 1

Слайд 30НГУ, «Введение в параллельное программирование в системах с общей памятью»
(ММФ, 1
НГУ, «Введение в параллельное программирование в системах с общей памятью» (ММФ, 1

Слайд 31НГУ, «Введение в параллельное программирование в системах с общей памятью»
(ММФ, 1
НГУ, «Введение в параллельное программирование в системах с общей памятью» (ММФ, 1
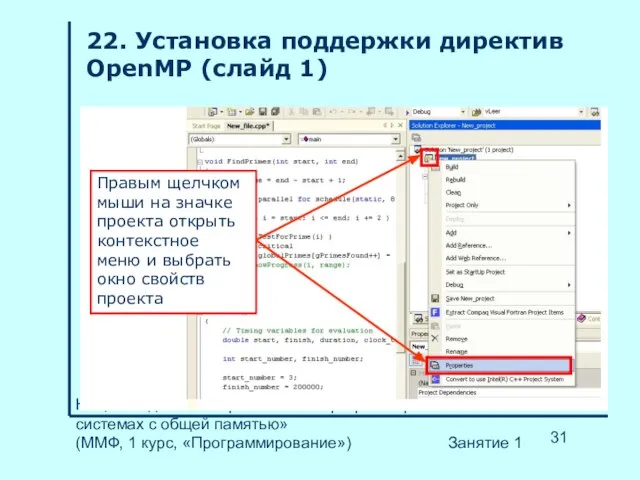
Слайд 32НГУ, «Введение в параллельное программирование в системах с общей памятью»
(ММФ, 1
НГУ, «Введение в параллельное программирование в системах с общей памятью» (ММФ, 1
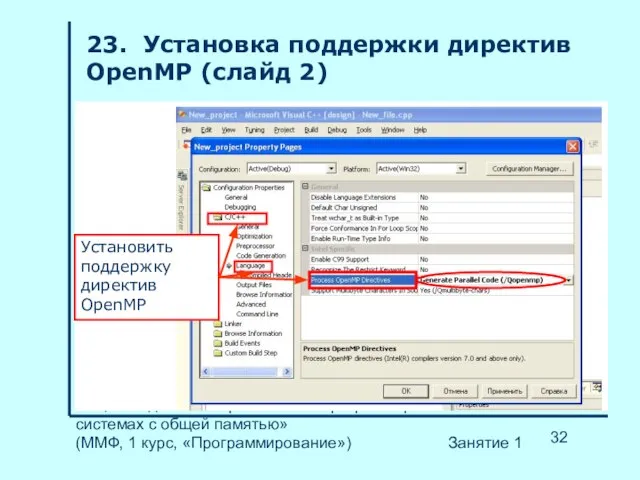
Слайд 33НГУ, «Введение в параллельное программирование в системах с общей памятью»
(ММФ, 1
НГУ, «Введение в параллельное программирование в системах с общей памятью» (ММФ, 1
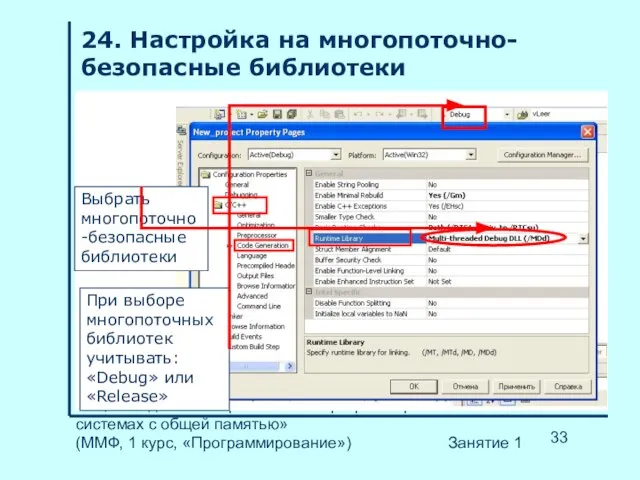
Слайд 34НГУ, «Введение в параллельное программирование в системах с общей памятью»
(ММФ, 1
НГУ, «Введение в параллельное программирование в системах с общей памятью» (ММФ, 1

Слайд 35НГУ, «Введение в параллельное программирование в системах с общей памятью»
(ММФ, 1
НГУ, «Введение в параллельное программирование в системах с общей памятью» (ММФ, 1

Слайд 36НГУ, «Введение в параллельное программирование в системах с общей памятью»
(ММФ, 1
НГУ, «Введение в параллельное программирование в системах с общей памятью» (ММФ, 1

Слайд 37НГУ, «Введение в параллельное программирование в системах с общей памятью»
(ММФ, 1
НГУ, «Введение в параллельное программирование в системах с общей памятью» (ММФ, 1

Слайд 38НГУ, «Введение в параллельное программирование в системах с общей памятью»
(ММФ, 1
НГУ, «Введение в параллельное программирование в системах с общей памятью» (ММФ, 1

Слайд 39НГУ, «Введение в параллельное программирование в системах с общей памятью»
(ММФ, 1
НГУ, «Введение в параллельное программирование в системах с общей памятью» (ММФ, 1

Слайд 40НГУ, «Введение в параллельное программирование в системах с общей памятью»
(ММФ, 1
НГУ, «Введение в параллельное программирование в системах с общей памятью» (ММФ, 1

Слайд 41НГУ, «Введение в параллельное программирование в системах с общей памятью»
(ММФ, 1
НГУ, «Введение в параллельное программирование в системах с общей памятью» (ММФ, 1

Слайд 42НГУ, «Введение в параллельное программирование в системах с общей памятью»
(ММФ, 1
НГУ, «Введение в параллельное программирование в системах с общей памятью» (ММФ, 1

Слайд 43НГУ, «Введение в параллельное программирование в системах с общей памятью»
(ММФ, 1
НГУ, «Введение в параллельное программирование в системах с общей памятью» (ММФ, 1

Слайд 44НГУ, «Введение в параллельное программирование в системах с общей памятью»
(ММФ, 1
НГУ, «Введение в параллельное программирование в системах с общей памятью» (ММФ, 1

Слайд 45НГУ, «Введение в параллельное программирование в системах с общей памятью»
(ММФ, 1
НГУ, «Введение в параллельное программирование в системах с общей памятью» (ММФ, 1

Слайд 46НГУ, «Введение в параллельное программирование в системах с общей памятью»
(ММФ, 1
НГУ, «Введение в параллельное программирование в системах с общей памятью» (ММФ, 1

Слайд 47НГУ, «Введение в параллельное программирование в системах с общей памятью»
(ММФ, 1
НГУ, «Введение в параллельное программирование в системах с общей памятью» (ММФ, 1

Слайд 48НГУ, «Введение в параллельное программирование в системах с общей памятью»
(ММФ, 1
НГУ, «Введение в параллельное программирование в системах с общей памятью» (ММФ, 1

 Forses and Motion
Forses and Motion  Легкая атлетика.Техника бега на короткие дистанции
Легкая атлетика.Техника бега на короткие дистанции The Sources of Philosophy (India, China)
The Sources of Philosophy (India, China) Вопросы по инвестициям
Вопросы по инвестициям 1
1 Областная экспедиция Музейная коллекция, посвящённая 75-летию образования Костромской области
Областная экспедиция Музейная коллекция, посвящённая 75-летию образования Костромской области Презентация на тему Зачем люди осваивают космос
Презентация на тему Зачем люди осваивают космос  Уголовная ответственность несовершеннолетних
Уголовная ответственность несовершеннолетних Культура и образование в информационный век: направления сотрудничества
Культура и образование в информационный век: направления сотрудничества Севастопольская городская молодежная организация
Севастопольская городская молодежная организация SRO #3. SmartCat (2)
SRO #3. SmartCat (2) Университетский округ инновационных образовательных учреждений при ПГПУ
Университетский округ инновационных образовательных учреждений при ПГПУ Вот и кончилось лето
Вот и кончилось лето Наши клиенты
Наши клиенты Сегментация изображений
Сегментация изображений Доли. Обыкновенные дроби
Доли. Обыкновенные дроби Внедрение информационных технологийв образовательный процесс начальной школы.
Внедрение информационных технологийв образовательный процесс начальной школы. Всемирный день качества
Всемирный день качества Клиентоориентированность. Рыбный мир 55
Клиентоориентированность. Рыбный мир 55 Факультет экономики и права ФГБОУ ВО Оренбургский ГАУ
Факультет экономики и права ФГБОУ ВО Оренбургский ГАУ ИЗО
ИЗО Влияет ли одежда на здоровье подростка ?
Влияет ли одежда на здоровье подростка ? QNX Software Systems
QNX Software Systems поликарбонатные профили +система монтажа сотового поликарбоната
поликарбонатные профили +система монтажа сотового поликарбоната 03 - System Specifications Rev B
03 - System Specifications Rev B Презентация на тему Иммунная система организма
Презентация на тему Иммунная система организма  South Korea (фотографии)
South Korea (фотографии) Виды воды
Виды воды