- Магистерская программа Моделирование в биотехническом приборостроении

Содержание
- 2. Введение. Методы планирования эксперимента особое значение приобрели в связи с крупными программами проведения и автоматизации научных
- 3. В каждой области существуют специфические ограничения, и только специалисты могут указать группы факторов, которыми можно пренебречь.
- 4. В наших лекциях будут рассматриваться главным образом сравнительные эксперименты. Иначе говоря, они будут относиться скорее к
- 5. Единицу материала, подвергаемую обработке, мы будем называть участком. В соответствии с исходным смыслом участок может быть
- 6. Понятие плана Под планом эксперимента понимают: 1) множество способов обработки, выбираемых для сравнения; 2) спецификацию обрабатываемых
- 7. Рандомизация Необходимым условием для получения несмещенных оценок разностей и их дисперсий является то, что принятое частное
- 8. «Беспорядочное» расположение способов обработки или любое использование личного суждения при построении «случайных на вид» расположений не
- 9. Статистика В математике слово «статистика» имеет два значения. - Во-первых, так называется раздел математики, в котором
- 10. Вероятность события. Случайным событиям можно приписать вероятность – число от нуля до единицы. Понятие вероятности можно
- 11. Распределение случайной величины Пусть X – это случайная величина, множеством возможных значений которой являются действительные числа.
- 12. Рис. 1 плотность вероятности f(x) и ф.р F(x) случайной величины
- 13. Математическое ожидание Пусть X – это случайная величина с плотностью вероятности f(x). Математическим ожиданием X называется
- 14. Основные распределения Нормальное распределение Нормальное (или гауссово) распределение – это, наверное, самое важное распределение в статистике.
- 15. Рис. Функция распределения и плотность вероятности нормального распределения
- 16. Распределение хи-квадрат Рассмотрим N независимых стандартных нормальных случайных величин X1,…, Xn,…, XN с нулевым мат. ожиданием
- 17. Рис. Функция распределения и квантиль распределения хи-квадрат. Квантили распределения χ2(N) обозначаются χ–2(P|N).
- 18. Распределение Стьюдента Рассмотрим две случайные величины: X – распределенную стандартно-нормально X ~ N(0, 1), и Y
- 19. Рис. Функция распределения и квантиль распределения Стьюдента
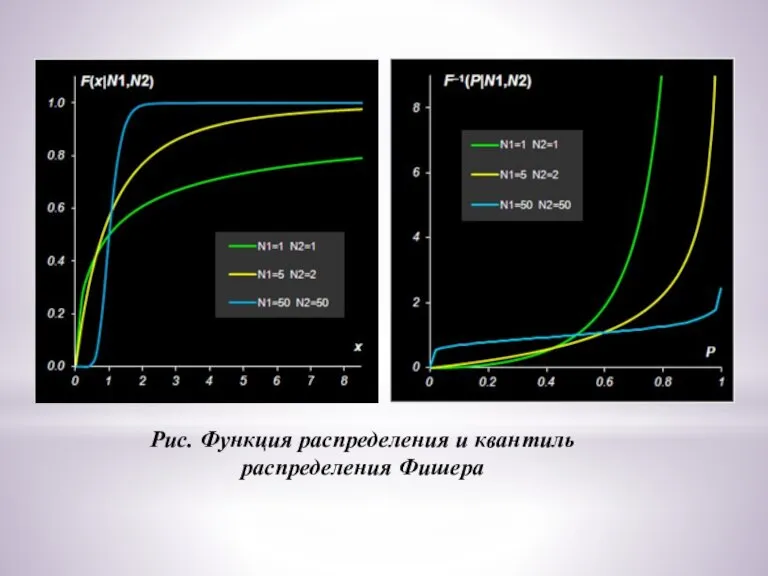
- 20. Распределение Фишера Пусть имеются две независимые случайные величины X1 и X2 , каждая из которых подчиняется
- 21. Рис. Функция распределения и квантиль распределения Фишера
- 22. Генерация случайных чисел Иногда бывает полезно создать искусственную выборку случайных чисел, подчиняющихся заданному распределению. Это можно
- 23. Полностью рандомизованный план Простейшим из всех планов, не представляющим самостоятельного математического интереса, но важным как в
- 24. Дисперсионный анализ в этом случае не представляет никаких трудностей и вытекает непосредственно из разбиения суммы квадратов.
- 25. Модели. Когда речь идет о критериях значимости и оценивании компонент дисперсии, модели важное значение приобретают модели
- 26. В модели нормальных ошибок εj считается нормально распределенной величиной со средним нуль и дисперсией ϭ2, причем
- 27. Компоненты дисперсии. При применении дисперсионного анализа может появиться необходимость вычислить математи-ческие ожидания средних квадратов при использованной
- 29. Скачать презентацию
Слайд 2 Введение.
Методы планирования эксперимента особое значение приобрели в связи с крупными программами
Введение.
Методы планирования эксперимента особое значение приобрели в связи с крупными программами

Слайд 3В каждой области существуют специфические ограничения, и только специалисты могут указать группы

Слайд 4В наших лекциях будут рассматриваться главным образом сравнительные эксперименты. Иначе говоря, они

Слайд 5Единицу материала, подвергаемую обработке, мы будем называть участком. В соответствии с исходным
Единицу материала, подвергаемую обработке, мы будем называть участком. В соответствии с исходным

Слайд 6Понятие плана
Под планом эксперимента понимают:
1) множество способов обработки, выбираемых для сравнения;
2) спецификацию
Понятие плана
Под планом эксперимента понимают:
1) множество способов обработки, выбираемых для сравнения;
2) спецификацию

Слайд 7Рандомизация
Необходимым условием для получения несмещенных оценок разностей и их дисперсий является то,
Рандомизация
Необходимым условием для получения несмещенных оценок разностей и их дисперсий является то,

Слайд 8«Беспорядочное» расположение способов обработки или любое использование личного суждения при построении «случайных
«Беспорядочное» расположение способов обработки или любое использование личного суждения при построении «случайных

Слайд 9Статистика
В математике слово «статистика» имеет два значения.
- Во-первых, так называется раздел
Статистика
В математике слово «статистика» имеет два значения.
- Во-первых, так называется раздел

Слайд 10Вероятность события. Случайным событиям можно приписать вероятность – число от нуля до
Вероятность события. Случайным событиям можно приписать вероятность – число от нуля до

Слайд 11Распределение случайной величины
Пусть X – это случайная величина, множеством возможных значений которой
Распределение случайной величины
Пусть X – это случайная величина, множеством возможных значений которой

Слайд 12
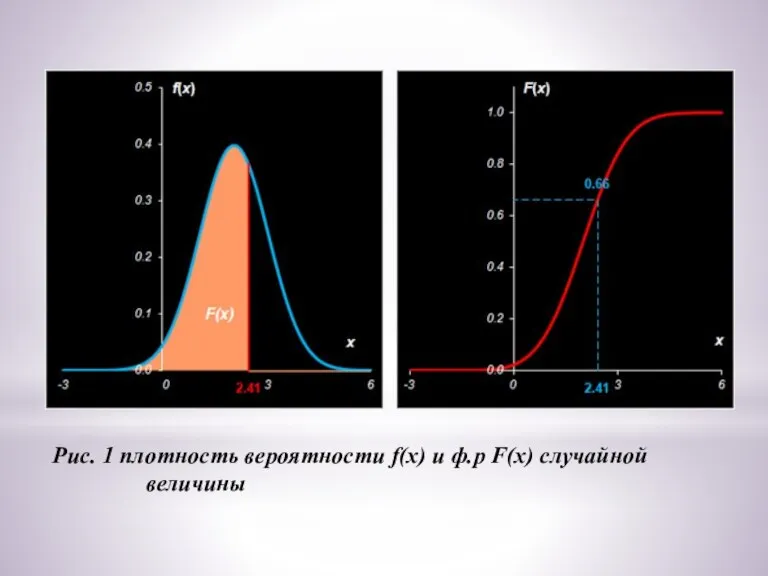
Рис. 1 плотность вероятности f(x) и ф.р F(x) случайной
величины
Рис. 1 плотность вероятности f(x) и ф.р F(x) случайной
величины
Слайд 13 Математическое ожидание
Пусть X – это случайная величина с плотностью вероятности f(x).
Математическое ожидание
Пусть X – это случайная величина с плотностью вероятности f(x).

Слайд 14 Основные распределения
Нормальное распределение
Нормальное (или гауссово) распределение – это, наверное, самое важное
Основные распределения
Нормальное распределение
Нормальное (или гауссово) распределение – это, наверное, самое важное

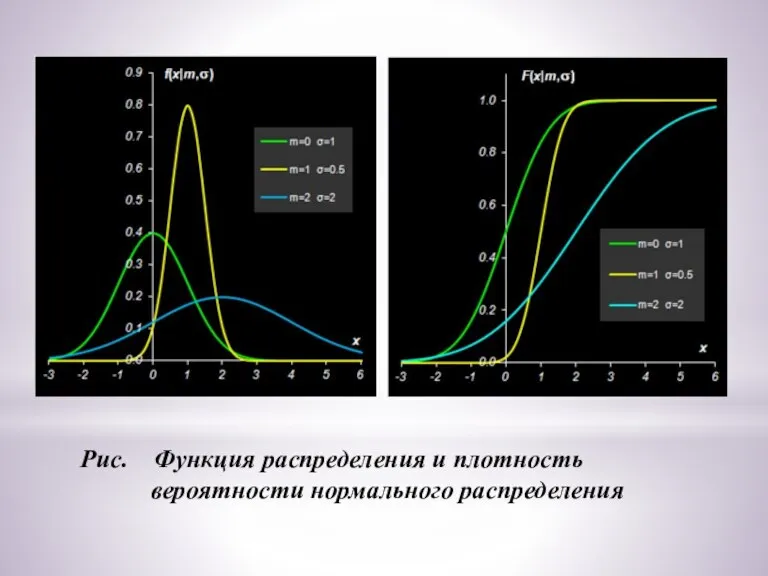
Слайд 15Рис. Функция распределения и плотность
вероятности нормального распределения
Рис. Функция распределения и плотность
вероятности нормального распределения
Слайд 16 Распределение хи-квадрат
Рассмотрим N независимых стандартных нормальных случайных величин X1,…, Xn,…, XN
с нулевым мат. ожиданием и единичной дисперсией, т.е.
Xn ~
Распределение хи-квадрат
Рассмотрим N независимых стандартных нормальных случайных величин X1,…, Xn,…, XN
с нулевым мат. ожиданием и единичной дисперсией, т.е.
Xn ~

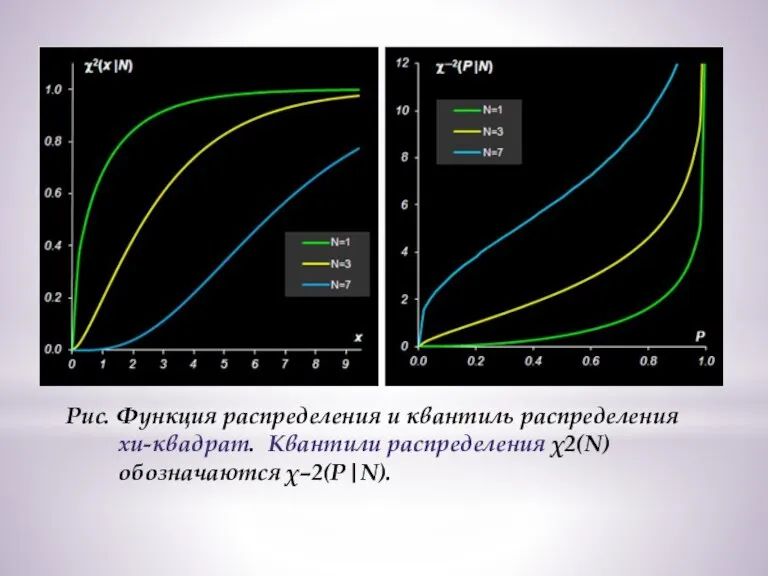
Слайд 17Рис. Функция распределения и квантиль распределения
хи-квадрат. Квантили распределения χ2(N)
обозначаются
Рис. Функция распределения и квантиль распределения
хи-квадрат. Квантили распределения χ2(N)
обозначаются
Слайд 18Распределение Стьюдента
Рассмотрим две случайные величины: X – распределенную стандартно-нормально X ~ N(0,
Распределение Стьюдента
Рассмотрим две случайные величины: X – распределенную стандартно-нормально X ~ N(0,

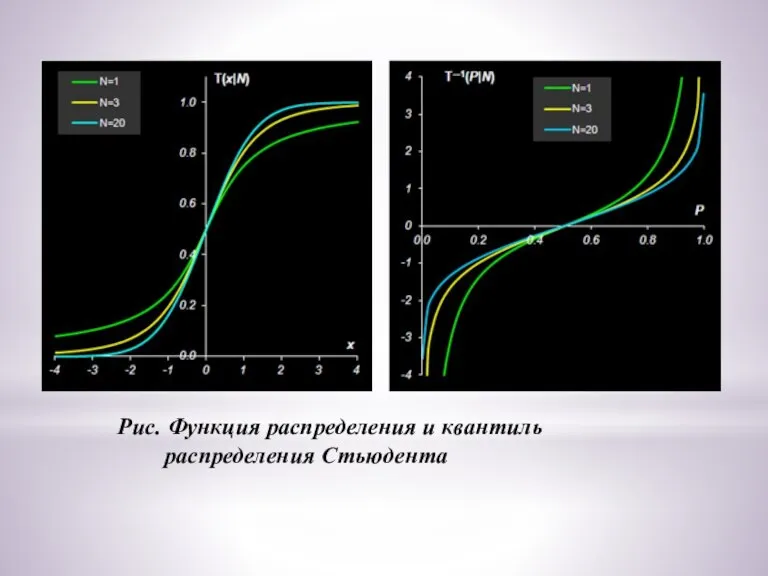
Слайд 19Рис. Функция распределения и квантиль
распределения Стьюдента
Рис. Функция распределения и квантиль
распределения Стьюдента
Слайд 20Распределение Фишера
Пусть имеются две независимые случайные величины X1 и X2 , каждая из которых подчиняется распределению
Распределение Фишера
Пусть имеются две независимые случайные величины X1 и X2 , каждая из которых подчиняется распределению

Слайд 21Рис. Функция распределения и квантиль распределения Фишера
Рис. Функция распределения и квантиль распределения Фишера
Слайд 22Генерация случайных чисел
Иногда бывает полезно создать искусственную выборку случайных чисел, подчиняющихся заданному
Генерация случайных чисел
Иногда бывает полезно создать искусственную выборку случайных чисел, подчиняющихся заданному

Слайд 23 Полностью рандомизованный план
Простейшим из всех планов, не представляющим самостоятельного математического интереса,
Полностью рандомизованный план
Простейшим из всех планов, не представляющим самостоятельного математического интереса,

Слайд 24Дисперсионный анализ в этом случае не представляет никаких трудностей и вытекает непосредственно
Дисперсионный анализ в этом случае не представляет никаких трудностей и вытекает непосредственно

Слайд 25Модели. Когда речь идет о критериях значимости и оценивании компонент дисперсии, модели
Модели. Когда речь идет о критериях значимости и оценивании компонент дисперсии, модели

Слайд 26
В модели нормальных ошибок εj считается нормально распределенной величиной со
В модели нормальных ошибок εj считается нормально распределенной величиной со

Слайд 27Компоненты дисперсии. При применении дисперсионного анализа может появиться необходимость вычислить математи-ческие ожидания
Компоненты дисперсии. При применении дисперсионного анализа может появиться необходимость вычислить математи-ческие ожидания

 Виды информационных моделей и их назначение
Виды информационных моделей и их назначение Разработка раздела, посвященного ТЭО дипломного проекта
Разработка раздела, посвященного ТЭО дипломного проекта Актуализация и диагностика знаний
Актуализация и диагностика знаний Комплектование, конфигурирование и настройка средств вычислительной техники
Комплектование, конфигурирование и настройка средств вычислительной техники Управляющие процессы и их формализованное описание
Управляющие процессы и их формализованное описание Создание новостного текста
Создание новостного текста Как записывать числа в двоичной системе счисления
Как записывать числа в двоичной системе счисления Безопасность детей в Интернете
Безопасность детей в Интернете Фото/история персонажа из игры Warcraft III
Фото/история персонажа из игры Warcraft III 1С-разработчик с 0 до PRO
1С-разработчик с 0 до PRO Понятие операционного окружения, состав, назначение
Понятие операционного окружения, состав, назначение Как подать обращение через сайт ГИС ЖКХ
Как подать обращение через сайт ГИС ЖКХ Информационные ресурсы
Информационные ресурсы Разработка баз данных
Разработка баз данных Анализ данных. Подготовка данных
Анализ данных. Подготовка данных Unit 2. Computer essentials
Unit 2. Computer essentials Машинное обучение в управлении БПЛА
Машинное обучение в управлении БПЛА Интернет технологии в образовании
Интернет технологии в образовании Франчайзинговый ассортимент 1С
Франчайзинговый ассортимент 1С Цикл с переменной
Цикл с переменной Анализ программ
Анализ программ Вирусы и антивирусные программы
Вирусы и антивирусные программы Библиотека в социальных сетях
Библиотека в социальных сетях 7_Obzor_tehnologiy_H25_FR_ATM
7_Obzor_tehnologiy_H25_FR_ATM История развития вычислительной техники
История развития вычислительной техники Подходы к интеграции программных модулей
Подходы к интеграции программных модулей Понятие алгоритмов, свойства алгоритма
Понятие алгоритмов, свойства алгоритма Антивирусные программы
Антивирусные программы