- Работа_с_текстом_Python_MFypnq

Содержание
- 2. Текстовые литералы Текстовый литерал представляет собой последовательность символов, заключенную в одинарные или двойные кавычки. Это самое
- 3. На заметку По умолчанию при отображении текстовых значений в области вывода обычно используются одинарные кавычки (если
- 4. Текстовые литералы Первый вопрос, который возникает, связан тем, как в самом текстовом литерале использовать двойные или
- 5. Текстовые литералы Если же текст содержит одинарные кавычки, то весь литерал можно заключить в двойные кавычки.
- 6. Текстовые литералы Сама по себе обратная косая черта \ используется для разбивки литерала на несколько строк
- 7. На заметку Просто так разбить значение текстового литерала на несколько строк не получится — возникнет ошибка.
- 8. Текстовые литералы Также обратная косая черта используется в управляющих инструкциях. Управляющая инструкция состоит из обратной косой
- 9. Подробности Область вывода условно разбивается на последовательность позиций, в которых отображаются символы. Позиции табуляции — это
- 10. На заметку Кроме инструкции перехода к новой строке \n и инструкции табуляции \t, есть и другие
- 11. Текстовые литералы Если нам нужно в самом литерале использовать обратную косую черту (не как часть управляющей
- 12. Текстовые литералы Достаточно удобный способ задавать текстовые литералы базируется на использовании трех пар двойных или одинарных
- 13. Текстовые литералы
- 14. Текстовые литералы
- 15. Текстовые литералы В этой программе создается несколько текстовых значений, и затем эти значения отображаются в области
- 16. Текстовые литералы В команде print("\\ Омар Хайям \\") мы использовали текстовый литерал, содержащий двойную обратную косую
- 17. Текстовые литералы Текстовые литералы можно создавать с использованием специальных префиксов. Префикс — это специальный символ (или
- 18. Текстовые литералы Эта инструкция интерпретируется как один символ. А вот выражение r"\n" представляет собой литерал, который
- 19. Текстовые литералы С использованием префикса f или F создаются форматированные литералы. Главное преимущество форматированных литералов состоит
- 20. Текстовые литералы Внутри этих скобок указывается название переменной, значение которой вставляется в соответствующем месте в текстовом
- 21. Текстовые литералы
- 22. Текстовые литералы Сначала в программе переменной A в качестве значения присваивается текстовый литерал "\"Java\"\n\"Python\"". Он содержит
- 23. Текстовые литералы Еще один пример литерала с префиксом (на этот раз использован префикс f) дается командой
- 24. Подробности Вместо инструкции {name} вставляется то значение переменной name, которое она имеет на момент присваивания значения
- 25. Текстовые литералы Это самый простой способ инкапсулировать (вставить) в текстовый литерал значение переменной. В общем случае,
- 26. Подробности Практически для каждого объекта предусмотрено или может быть предусмотрено текстовое представление, применимое для отображения в
- 28. Скачать презентацию
Слайд 2Текстовые литералы
Текстовый литерал представляет собой последовательность символов, заключенную в одинарные или двойные
Текстовые литералы
Текстовый литерал представляет собой последовательность символов, заключенную в одинарные или двойные

Слайд 3На заметку
По умолчанию при отображении текстовых значений в области вывода обычно используются
На заметку
По умолчанию при отображении текстовых значений в области вывода обычно используются

Слайд 4Текстовые литералы
Первый вопрос, который возникает, связан тем, как в самом текстовом литерале
Текстовые литералы
Первый вопрос, который возникает, связан тем, как в самом текстовом литерале

Слайд 5Текстовые литералы
Если же текст содержит одинарные кавычки, то весь литерал можно заключить
Текстовые литералы
Если же текст содержит одинарные кавычки, то весь литерал можно заключить

Слайд 6Текстовые литералы
Сама по себе обратная косая черта \ используется для разбивки литерала
Текстовые литералы
Сама по себе обратная косая черта \ используется для разбивки литерала

Слайд 7На заметку
Просто так разбить значение текстового литерала на несколько строк не получится
На заметку
Просто так разбить значение текстового литерала на несколько строк не получится

Слайд 8Текстовые литералы
Также обратная косая черта используется в управляющих инструкциях. Управляющая инструкция состоит
Текстовые литералы
Также обратная косая черта используется в управляющих инструкциях. Управляющая инструкция состоит

Слайд 9Подробности
Область вывода условно разбивается на последовательность позиций, в которых отображаются символы. Позиции
Подробности
Область вывода условно разбивается на последовательность позиций, в которых отображаются символы. Позиции

Слайд 10На заметку
Кроме инструкции перехода к новой строке \n и инструкции табуляции \t,
На заметку
Кроме инструкции перехода к новой строке \n и инструкции табуляции \t,

Слайд 11Текстовые литералы
Если нам нужно в самом литерале использовать обратную косую черту (не
Текстовые литералы
Если нам нужно в самом литерале использовать обратную косую черту (не

Слайд 12Текстовые литералы
Достаточно удобный способ задавать текстовые литералы базируется на использовании трех пар
Текстовые литералы
Достаточно удобный способ задавать текстовые литералы базируется на использовании трех пар

Слайд 13Текстовые литералы
Текстовые литералы

Слайд 14Текстовые литералы
Текстовые литералы
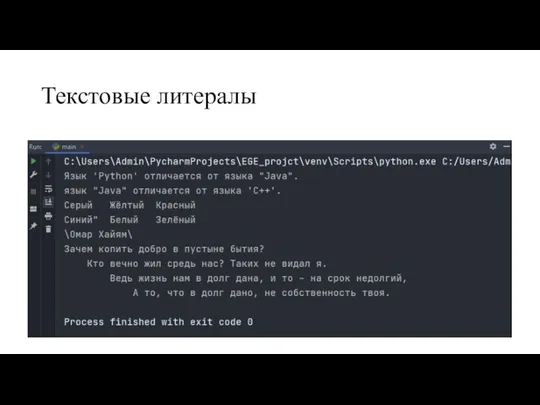
Слайд 15Текстовые литералы
В этой программе создается несколько текстовых значений, и затем эти значения
Текстовые литералы
В этой программе создается несколько текстовых значений, и затем эти значения

Слайд 16Текстовые литералы
В команде print("\\ Омар Хайям \\") мы использовали текстовый литерал, содержащий
Текстовые литералы
В команде print("\\ Омар Хайям \\") мы использовали текстовый литерал, содержащий

Слайд 17Текстовые литералы
Текстовые литералы можно создавать с использованием специальных префиксов. Префикс — это
Текстовые литералы
Текстовые литералы можно создавать с использованием специальных префиксов. Префикс — это

Слайд 18Текстовые литералы
Эта инструкция интерпретируется как один символ. А вот выражение r"\n" представляет
Текстовые литералы
Эта инструкция интерпретируется как один символ. А вот выражение r"\n" представляет

Слайд 19Текстовые литералы
С использованием префикса f или F создаются форматированные литералы. Главное преимущество
Текстовые литералы
С использованием префикса f или F создаются форматированные литералы. Главное преимущество

Слайд 20Текстовые литералы
Внутри этих скобок указывается название переменной, значение которой вставляется в соответствующем
Текстовые литералы
Внутри этих скобок указывается название переменной, значение которой вставляется в соответствующем

Слайд 21Текстовые литералы
Текстовые литералы

Слайд 22Текстовые литералы
Сначала в программе переменной A в качестве значения присваивается текстовый литерал
Текстовые литералы
Сначала в программе переменной A в качестве значения присваивается текстовый литерал

Слайд 23Текстовые литералы
Еще один пример литерала с префиксом (на этот раз использован префикс
Текстовые литералы
Еще один пример литерала с префиксом (на этот раз использован префикс

Слайд 24Подробности
Вместо инструкции {name} вставляется то значение переменной name, которое она имеет на
Подробности
Вместо инструкции {name} вставляется то значение переменной name, которое она имеет на

Слайд 25Текстовые литералы
Это самый простой способ инкапсулировать (вставить) в текстовый литерал значение переменной.
Текстовые литералы
Это самый простой способ инкапсулировать (вставить) в текстовый литерал значение переменной.

Слайд 26Подробности
Практически для каждого объекта предусмотрено или может быть предусмотрено текстовое представление, применимое
Подробности
Практически для каждого объекта предусмотрено или может быть предусмотрено текстовое представление, применимое

 Создание игр
Создание игр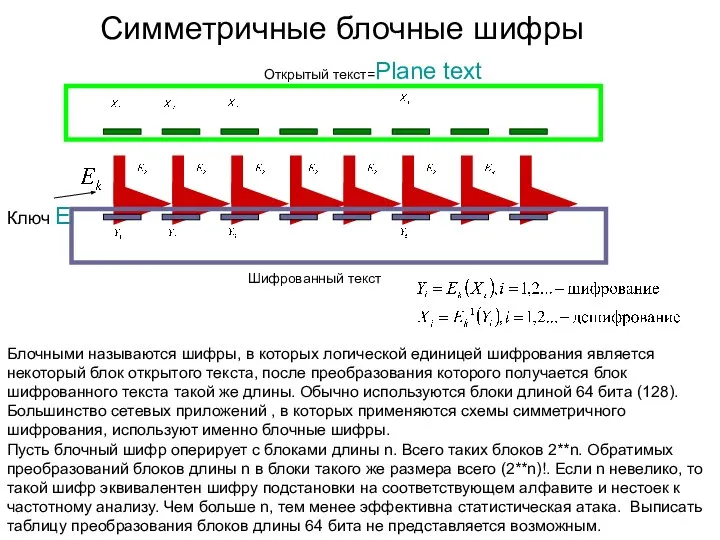 Часть 3 SDES DES ГОСТ IDEA
Часть 3 SDES DES ГОСТ IDEA Презентация на тему Программа Проводник
Презентация на тему Программа Проводник  Booking.com
Booking.com Алгоритм. Циклический алгоритм. While, for. Range. Random
Алгоритм. Циклический алгоритм. While, for. Range. Random Распространение информации
Распространение информации Курсовая работа
Курсовая работа Методические приёмы обучения информатике
Методические приёмы обучения информатике Выпускная квалификационная работа: Сравнительный анализ систем связи 4G и 5G
Выпускная квалификационная работа: Сравнительный анализ систем связи 4G и 5G Презентация. Основные компоненты мультимедиа
Презентация. Основные компоненты мультимедиа Применение формул для вычисления в таблицах, созданных в Microsoft Word 2007
Применение формул для вычисления в таблицах, созданных в Microsoft Word 2007 Чек-листы и тест-кейсы
Чек-листы и тест-кейсы Открытка. Поздравляю
Открытка. Поздравляю Искусственный интеллек ( лекция 1)
Искусственный интеллек ( лекция 1) Сокращатель ссылок с авторизацией пользователя для использования дополнительного функционала. Проект
Сокращатель ссылок с авторизацией пользователя для использования дополнительного функционала. Проект Готэм. Версия 1.2.3
Готэм. Версия 1.2.3 Санау системасы. БДЭ информатика
Санау системасы. БДЭ информатика Интерфейс
Интерфейс Комитет Развитие общественных инноваций
Комитет Развитие общественных инноваций Процедуры и функции в Паскале. Рекурсия
Процедуры и функции в Паскале. Рекурсия Rukki. Проект для строителей
Rukki. Проект для строителей Разработка предложений по внедрению системы управления событиями информационной безопасности в систему безопасности организации
Разработка предложений по внедрению системы управления событиями информационной безопасности в систему безопасности организации Модульная сетка. Современные компьютерные дизайн-программы
Модульная сетка. Современные компьютерные дизайн-программы Разработка автоматизированной системы управления технологическими процессами ООО Связьторг
Разработка автоматизированной системы управления технологическими процессами ООО Связьторг Растровая и векторная графика
Растровая и векторная графика Компьютерные технологии в подготовке спортсменов
Компьютерные технологии в подготовке спортсменов Стриминг через ключ трансляции
Стриминг через ключ трансляции Решение задач на измерение информации (7 класс) (1)
Решение задач на измерение информации (7 класс) (1)