- Регулярные выражения

Содержание
- 2. Регулярные выражения https://ru.wikipedia.org/wiki/Регулярные_выражения В компьютерной терминологии «регулярное выражение» (его еще называют regexp или regex, сокр. «регулярка»)
- 3. Регулярные выражения Умный подход к анализу и сопоставлению строк, основанный на использовании метасимволов https://ru.wikipedia.org/wiki/Регулярные_выражения
- 4. О регулярных выражениях Очень мощные Регулярные выражения сами по себе напоминают язык программирования Пишутся с помощью
- 5. Регулярные выражения: краткое руководство ^ Начало всего текста или начало строки текста $ Конец всего текста
- 6. Модуль регулярных выражений Прежде чем вы сможете использовать в своей программе регулярные выражения, необходимо импортировать библиотеку,
- 7. Использование re.search(), как find() import re hand = open('mbox-short.txt') for line in hand: line = line.rstrip()
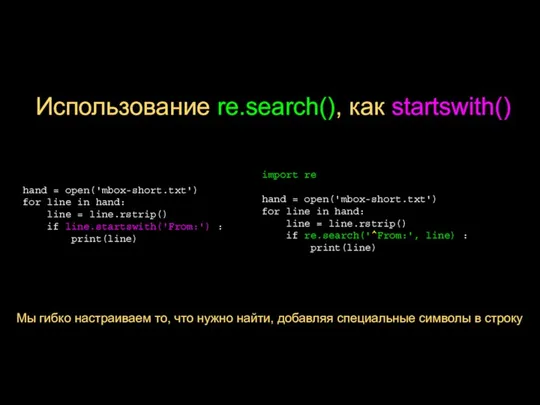
- 8. Использование re.search(), как startswith() import re hand = open('mbox-short.txt') for line in hand: line = line.rstrip()
- 9. Метасимволы Символ . (точка) означает один любой символ Символ * (звездочка) означает «ноль или более повторений»
- 10. Тонкая настройка соответствия В зависимости от «чистоты» данных и целей вашего приложения, вам может понадобиться немного
- 11. Тонкая настройка соответствия В зависимости от «чистоты» данных и целей вашего приложения, вам может понадобиться немного
- 12. Сопоставление и извлечение данных re.search() возвращает значение True/False в зависимости от того, соответствует ли строка регулярному
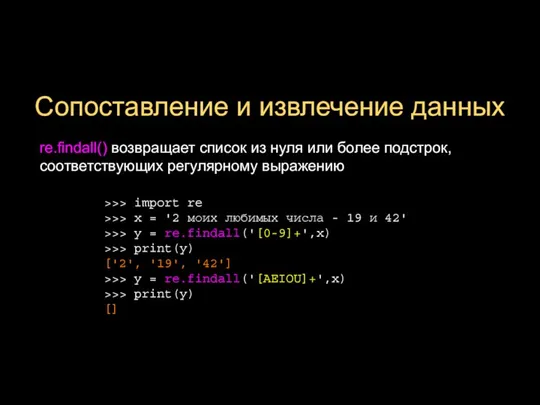
- 13. Сопоставление и извлечение данных re.findall() возвращает список из нуля или более подстрок, соответствующих регулярному выражению >>>
- 14. Жадные квантификаторы Квантификаторы (* и +) называют «жадными», так как в некоторых реализациях регулярным выражениям с
- 15. Ленивые квантификаторы Но не все квантификаторы регулярных выражений жадные! Добавьте символ ?, это немного охладит пыл
- 16. Тонкая настройка извлечения строк Вы можете точнее настроить поиск совпадения для re.findall() и отдельно указать, какая
- 17. Тонкая настройка извлечения строк Круглые скобки не являются частью совпадения, они лишь сообщают, где начинается и
- 18. Примеры анализа строк
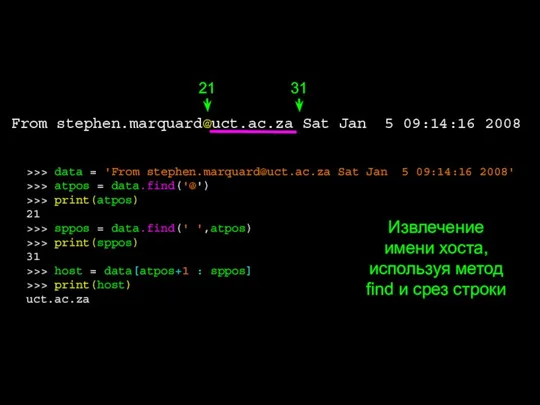
- 19. >>> data = 'From [email protected] Sat Jan 5 09:14:16 2008' >>> atpos = data.find('@') >>> print(atpos)
- 20. Шаблон двойного разделения Иногда бывает необходимо сначала разделить строку одним образом, а затем взять один из
- 21. '@([^ ]*)' Просматривать строку пока не встретится символ @ From [email protected] Sat Jan 5 09:14:16 2008
- 22. Версия с регулярным выражением '@([^ ]*)' Захватить непробельные символы Ноль или более символов import re lin
- 23. Версия с регулярным выражением '@([^ ]*)' Извлечь непробельные символы From [email protected] Sat Jan 5 09:14:16 2008
- 24. Или так… '^From .*@([^ ]*)' Начиная с начала строки, ищем подстроку 'From ' From [email protected] Sat
- 25. Или так… '^From .*@([^ ]*)' Пропустим часть символов, пока не встретим символ @ import re lin
- 26. Или так… '^From .*@([^ ]*)' Начало извлечения From [email protected] Sat Jan 5 09:14:16 2008 import re
- 27. Или так… '^From .*@([^ ]+)' Захватить непробельные символы Захватить их как можно больше import re lin
- 28. Или так… '^From .*@([^ ]+)' Конец извлечения import re lin = 'From [email protected] Sat Jan 5
- 30. Скачать презентацию
Слайд 2Регулярные выражения
https://ru.wikipedia.org/wiki/Регулярные_выражения
В компьютерной терминологии «регулярное выражение» (его еще называют regexp или regex,
Регулярные выражения
https://ru.wikipedia.org/wiki/Регулярные_выражения
В компьютерной терминологии «регулярное выражение» (его еще называют regexp или regex,

Слайд 3Регулярные выражения
Умный подход к анализу и сопоставлению строк, основанный на использовании метасимволов
https://ru.wikipedia.org/wiki/Регулярные_выражения
Регулярные выражения
Умный подход к анализу и сопоставлению строк, основанный на использовании метасимволов
https://ru.wikipedia.org/wiki/Регулярные_выражения

Слайд 4О регулярных выражениях
Очень мощные
Регулярные выражения сами по себе напоминают язык программирования
Пишутся с
О регулярных выражениях
Очень мощные
Регулярные выражения сами по себе напоминают язык программирования
Пишутся с

Слайд 5Регулярные выражения: краткое руководство
^ Начало всего текста или начало строки текста
$ Конец
Регулярные выражения: краткое руководство
^ Начало всего текста или начало строки текста
$ Конец

Слайд 6Модуль регулярных выражений
Прежде чем вы сможете использовать в своей программе регулярные выражения,
Модуль регулярных выражений
Прежде чем вы сможете использовать в своей программе регулярные выражения,

Слайд 7Использование re.search(), как find()
import re
hand = open('mbox-short.txt')
for line in hand:
line =
Использование re.search(), как find()
import re
hand = open('mbox-short.txt')
for line in hand:
line =

Слайд 8Использование re.search(), как startswith()
import re
hand = open('mbox-short.txt')
for line in hand:
line =
Использование re.search(), как startswith()
import re
hand = open('mbox-short.txt')
for line in hand:
line =
Слайд 9Метасимволы
Символ . (точка) означает один любой символ
Символ * (звездочка) означает «ноль или
Метасимволы
Символ . (точка) означает один любой символ
Символ * (звездочка) означает «ноль или

Слайд 10Тонкая настройка соответствия
В зависимости от «чистоты» данных и целей вашего приложения, вам
Тонкая настройка соответствия
В зависимости от «чистоты» данных и целей вашего приложения, вам

Слайд 11Тонкая настройка соответствия
В зависимости от «чистоты» данных и целей вашего приложения, вам
Тонкая настройка соответствия
В зависимости от «чистоты» данных и целей вашего приложения, вам

Слайд 12Сопоставление и извлечение данных
re.search() возвращает значение True/False в зависимости от того, соответствует
Сопоставление и извлечение данных
re.search() возвращает значение True/False в зависимости от того, соответствует

Слайд 13Сопоставление и извлечение данных
re.findall() возвращает список из нуля или более подстрок, соответствующих
Сопоставление и извлечение данных
re.findall() возвращает список из нуля или более подстрок, соответствующих
Слайд 14Жадные квантификаторы
Квантификаторы (* и +) называют «жадными», так как в некоторых реализациях
Жадные квантификаторы
Квантификаторы (* и +) называют «жадными», так как в некоторых реализациях

Слайд 15Ленивые квантификаторы
Но не все квантификаторы регулярных выражений жадные!
Добавьте символ ?, это немного
Ленивые квантификаторы
Но не все квантификаторы регулярных выражений жадные!
Добавьте символ ?, это немного

Слайд 16Тонкая настройка извлечения строк
Вы можете точнее настроить поиск совпадения для re.findall() и
Тонкая настройка извлечения строк
Вы можете точнее настроить поиск совпадения для re.findall() и

Слайд 17Тонкая настройка извлечения строк
Круглые скобки не являются частью совпадения, они лишь сообщают,
Тонкая настройка извлечения строк
Круглые скобки не являются частью совпадения, они лишь сообщают,

Слайд 18Примеры анализа строк
Примеры анализа строк

Слайд 19>>> data = 'From [email protected] Sat Jan 5 09:14:16 2008'
>>> atpos =
>>> data = 'From [email protected] Sat Jan 5 09:14:16 2008'
>>> atpos =
Слайд 20Шаблон двойного разделения
Иногда бывает необходимо сначала разделить строку одним образом, а затем
Шаблон двойного разделения
Иногда бывает необходимо сначала разделить строку одним образом, а затем

!['@([^ ]*)' Просматривать строку пока не встретится символ @ From stephen.marquard@uct.ac.za Sat](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/967346/slide-20.jpg)
Слайд 22Версия с регулярным выражением
'@([^ ]*)'
Захватить непробельные символы
Ноль или более символов
import re
Версия с регулярным выражением
'@([^ ]*)'
Захватить непробельные символы
Ноль или более символов
import re
![Версия с регулярным выражением '@([^ ]*)' Захватить непробельные символы Ноль или более](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/967346/slide-21.jpg)
Слайд 23Версия с регулярным выражением
'@([^ ]*)'
Извлечь непробельные символы
From [email protected] Sat Jan 5
Версия с регулярным выражением
'@([^ ]*)'
Извлечь непробельные символы
From [email protected] Sat Jan 5
![Версия с регулярным выражением '@([^ ]*)' Извлечь непробельные символы From stephen.marquard@uct.ac.za Sat](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/967346/slide-22.jpg)
Слайд 24Или так…
'^From .*@([^ ]*)'
Начиная с начала строки, ищем подстроку 'From '
From
Или так…
'^From .*@([^ ]*)'
Начиная с начала строки, ищем подстроку 'From '
From
![Или так… '^From .*@([^ ]*)' Начиная с начала строки, ищем подстроку 'From](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/967346/slide-23.jpg)
Слайд 25Или так…
'^From .*@([^ ]*)'
Пропустим часть символов, пока не встретим символ @
import re
Или так…
'^From .*@([^ ]*)'
Пропустим часть символов, пока не встретим символ @
import re
![Или так… '^From .*@([^ ]*)' Пропустим часть символов, пока не встретим символ](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/967346/slide-24.jpg)
![Или так… '^From .*@([^ ]*)' Начало извлечения From stephen.marquard@uct.ac.za Sat Jan 5](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/967346/slide-25.jpg)
Слайд 27Или так…
'^From .*@([^ ]+)'
Захватить непробельные символы
Захватить их как можно больше
import re
lin
Или так…
'^From .*@([^ ]+)'
Захватить непробельные символы
Захватить их как можно больше
import re
lin
![Или так… '^From .*@([^ ]+)' Захватить непробельные символы Захватить их как можно](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/967346/slide-26.jpg)
![Или так… '^From .*@([^ ]+)' Конец извлечения import re lin = 'From](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/967346/slide-27.jpg)
 10 сайтов, полезных для школьников
10 сайтов, полезных для школьников Экспертные системы
Экспертные системы Файловые системы. Жесткие диски. FAT, EXT. Особенности ФС. LVM в Linux
Файловые системы. Жесткие диски. FAT, EXT. Особенности ФС. LVM в Linux Информационная система соревнований (CIS)
Информационная система соревнований (CIS) Рекурсия
Рекурсия Покажи свои эмоджи. Раунд 2
Покажи свои эмоджи. Раунд 2 HackerSchool
HackerSchool Предоставление доступа к документам компьютера локальной сети
Предоставление доступа к документам компьютера локальной сети Тестирование программного обеспечения
Тестирование программного обеспечения Мининский университет
Мининский университет Оформление групп. Общее положение
Оформление групп. Общее положение Ядро операционной системы
Ядро операционной системы Ресурсные записи
Ресурсные записи Logicheskoe_proektirvoanie_fizicheskaya_model_BD
Logicheskoe_proektirvoanie_fizicheskaya_model_BD Правила ввода и решения задач с одномерными массивами. Часть 1
Правила ввода и решения задач с одномерными массивами. Часть 1 Единая мультисервисная платформа
Единая мультисервисная платформа Презентация1-D
Презентация1-D Мультипликация. Урок 1
Мультипликация. Урок 1 Виртуальная модель АЦП последовательного приближения
Виртуальная модель АЦП последовательного приближения Тестовая программа по информатике
Тестовая программа по информатике Геймификация. Активируй. Вовлекай. Получай
Геймификация. Активируй. Вовлекай. Получай Определение видов визуализации 3D моделей
Определение видов визуализации 3D моделей Введение в информатику. Информация
Введение в информатику. Информация Наследование классов. Пример лабораторной 2
Наследование классов. Пример лабораторной 2 Оценка достоверности интернет-источников
Оценка достоверности интернет-источников Формирование библиографической записи на картографическое издание
Формирование библиографической записи на картографическое издание Базовые алгоритмические конструкции. Лекция 5
Базовые алгоритмические конструкции. Лекция 5 Поняття документу. Призначення та класифікація документів. Документообіг
Поняття документу. Призначення та класифікація документів. Документообіг