- Системы распознавания речи

Содержание
- 2. Что такое распознавание речи? Распознавание речи – это многоуровневая задача распознавания образов, в которой акустические сигналы
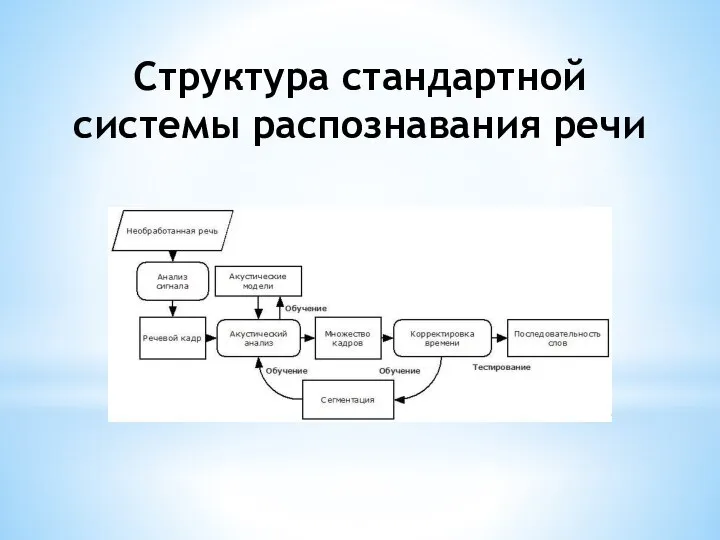
- 3. Структура стандартной системы распознавания речи
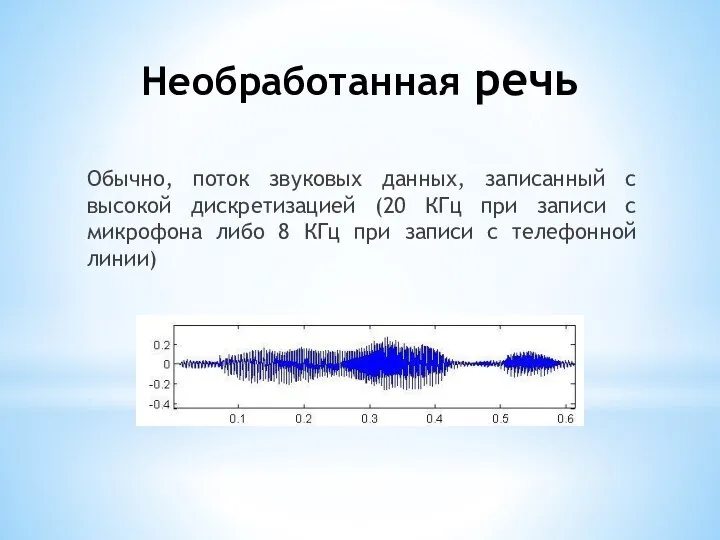
- 4. Необработанная речь Обычно, поток звуковых данных, записанный с высокой дискретизацией (20 КГц при записи с микрофона
- 5. Анализ сигнала Поступающий сигнал должен быть изначально трансформирован и сжат, для облегчения последующей обработки. Есть различные
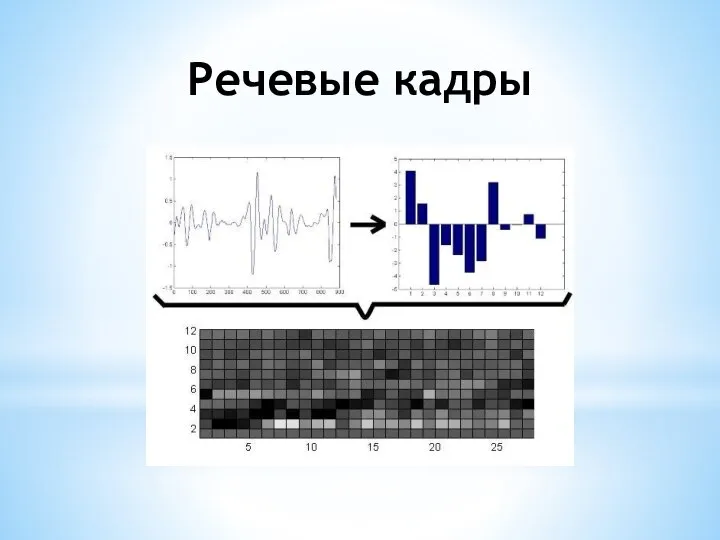
- 6. Речевые кадры Результатом анализа сигнала является последовательность речевых кадров. Обычно, каждый речевой кадр – это результат
- 7. Речевые кадры
- 8. Акустические модели Для анализа состава речевых кадров требуется набор акустических моделей. Рассмотрим две наиболее распространенные из
- 9. Шаблонная модель В качестве акустической модели выступает каким-либо образом сохраненный пример распознаваемой структурной единицы (слова, команды).
- 10. Модель состояний Каждое слово моделируется как последовательность состояний указывающих набор звуков, которые возможно услышать в данном
- 11. Акустический анализ Состоит в сопоставлении различных акустических моделей к каждому кадру речи и выдает матрицу сопоставления
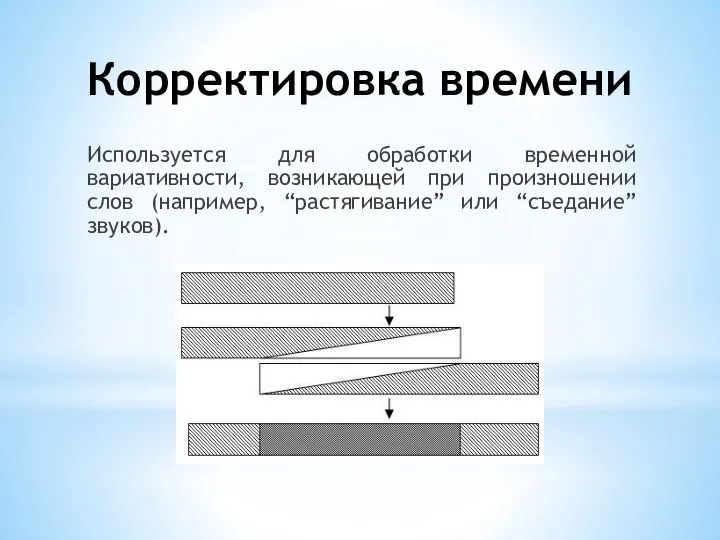
- 12. Корректировка времени Используется для обработки временной вариативности, возникающей при произношении слов (например, “растягивание” или “съедание” звуков).
- 13. Последовательность слов В результате работы, система распознавания речи выдает последовательность (или несколько возможных последовательностей) слов, которая,
- 15. Скачать презентацию
Слайд 2Что такое распознавание речи?
Распознавание речи – это многоуровневая задача распознавания образов, в
Что такое распознавание речи?
Распознавание речи – это многоуровневая задача распознавания образов, в

Слайд 3Структура стандартной системы распознавания речи
Структура стандартной системы распознавания речи
Слайд 4Необработанная речь
Обычно, поток звуковых данных, записанный с высокой дискретизацией (20 КГц при
Необработанная речь
Обычно, поток звуковых данных, записанный с высокой дискретизацией (20 КГц при
Слайд 5Анализ сигнала
Поступающий сигнал должен быть изначально трансформирован и сжат, для облегчения последующей
Анализ сигнала
Поступающий сигнал должен быть изначально трансформирован и сжат, для облегчения последующей

Слайд 6Речевые кадры
Результатом анализа сигнала является последовательность речевых кадров. Обычно, каждый речевой кадр
Речевые кадры
Результатом анализа сигнала является последовательность речевых кадров. Обычно, каждый речевой кадр

Слайд 7Речевые кадры
Речевые кадры
Слайд 8Акустические модели
Для анализа состава речевых кадров требуется набор акустических моделей. Рассмотрим две
Акустические модели
Для анализа состава речевых кадров требуется набор акустических моделей. Рассмотрим две

Слайд 9Шаблонная модель
В качестве акустической модели выступает каким-либо образом сохраненный пример распознаваемой структурной
Шаблонная модель
В качестве акустической модели выступает каким-либо образом сохраненный пример распознаваемой структурной

Слайд 10Модель состояний
Каждое слово моделируется как последовательность состояний указывающих набор звуков, которые возможно
Модель состояний
Каждое слово моделируется как последовательность состояний указывающих набор звуков, которые возможно

Слайд 11Акустический анализ
Состоит в сопоставлении различных акустических моделей к каждому кадру речи и
Акустический анализ
Состоит в сопоставлении различных акустических моделей к каждому кадру речи и

Слайд 12Корректировка времени
Используется для обработки временной вариативности, возникающей при произношении слов (например, “растягивание”
Корректировка времени
Используется для обработки временной вариативности, возникающей при произношении слов (например, “растягивание”
Слайд 13Последовательность слов
В результате работы, система распознавания речи выдает последовательность (или несколько возможных
Последовательность слов
В результате работы, система распознавания речи выдает последовательность (или несколько возможных

 Табличный процессор Microsoft Excel
Табличный процессор Microsoft Excel Файл. Полное и имя файла
Файл. Полное и имя файла Файлы. Элементы файлов
Файлы. Элементы файлов cybersport
cybersport Вредоносное программное обеспечение и методы борьбы с ним
Вредоносное программное обеспечение и методы борьбы с ним 6. Bloklar 1
6. Bloklar 1 Интерфейс Sound Forge 9.0 (часть 2)
Интерфейс Sound Forge 9.0 (часть 2) 5-6-1-peredacha-informacii (1)
5-6-1-peredacha-informacii (1) Способы создания и продвижения новостей в медиа
Способы создания и продвижения новостей в медиа Data centre services in Estonia
Data centre services in Estonia Программы краткосрочных курсов
Программы краткосрочных курсов Функциональная схема взаимодействия участников симметричного криптографического обмена. Недостатки симметричных криптосистем
Функциональная схема взаимодействия участников симметричного криптографического обмена. Недостатки симметричных криптосистем Основы научных исследований. Представление научного доклада в форме презентации. Тема 9
Основы научных исследований. Представление научного доклада в форме презентации. Тема 9 Компьютерная графика. Растровая и векторная графика
Компьютерная графика. Растровая и векторная графика Как продвигаться юристу в Instagram
Как продвигаться юристу в Instagram Занимательная информатика. 5 класс
Занимательная информатика. 5 класс Пример оформления итоговых заданий в формате ЕГЭ
Пример оформления итоговых заданий в формате ЕГЭ Администрирование информационных систем. Администрирование БД
Администрирование информационных систем. Администрирование БД Лекция 7_Технические каналы утечки акустической информации
Лекция 7_Технические каналы утечки акустической информации E-learning infographics
E-learning infographics Особенности организации бухгалтерского финансового учета в условиях применения компьютерных технологий
Особенности организации бухгалтерского финансового учета в условиях применения компьютерных технологий Растровая и векторная графика
Растровая и векторная графика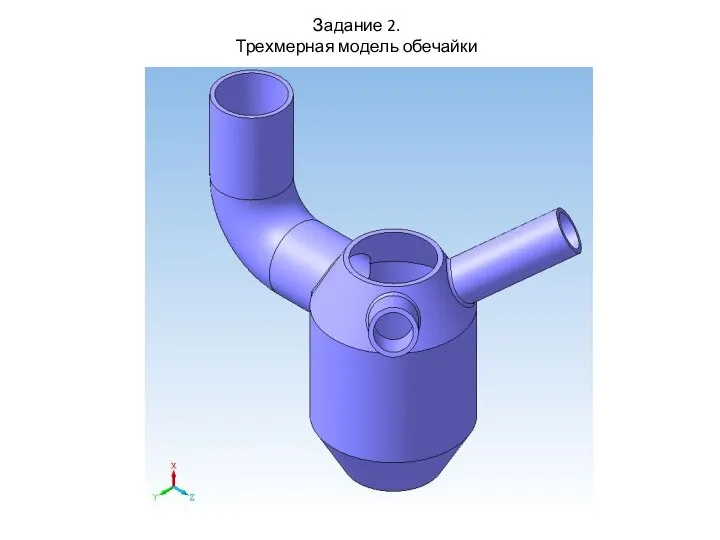 Трехмерная модель обечайки. Задание 2
Трехмерная модель обечайки. Задание 2 Главные ресурсы молодежной политики
Главные ресурсы молодежной политики Разграничение прав доступа в локальной сети сети
Разграничение прав доступа в локальной сети сети Использование ИКТ в обучении английскому языку на примере компьютерных обучающих программ и ролевых игр
Использование ИКТ в обучении английскому языку на примере компьютерных обучающих программ и ролевых игр Управление компьютером. Программы и документы
Управление компьютером. Программы и документы Классификация шрифтов
Классификация шрифтов