- SparkML basics

Содержание
- 4. RDD Basics
- 5. RDD Basics
- 6. RDD Basics
- 7. RDD Basics
- 8. DataFrames
- 9. Datasets
- 10. SQL vs. DataFrame vs. Dataset
- 11. Spark ML Pipelines
- 12. Spark ML Pipelines Transformer
- 13. Spark ML Pipelines Transformer Estimator
- 14. Spark ML Pipelines
- 15. Spark ML Pipelines
- 16. Spark ML Pipelines
- 17. Spark ML Core
- 18. Field Metadata and Attributes
- 19. Prediction Model
- 20. “My Spark ML Model”
- 21. Spark ML Features ETL SQLTransformer SqlFilter, ColumnsExtractor Numerization OneHotEncoder StringIndexer MultinomialExtractor Vectorization VectorAssembler FeatureHasher AutoAssembler Feature
- 22. Spark ML Features Feature Engineering DCT ElementwiseProduct Interaction VectorIndexer PolynomialExpansion Feature Selection ChiSqSelector FoldedFeaturesSelector Dimension reduction
- 23. Spark ML Features Texts extraction Tokenizer RegexTokenizer Ngram StopWordsRemover NLP in Pravada-ML LanguageDetectorTransformer LanguageAwareAnalyzer NGramExtractor URLElimminator
- 24. Spark ML Features Regression Classification
- 25. Spark ML Features Recommendations ALS FPGrowth Evaluation BinaryClassificationEvaluator ClusteringEvaluator MulticlassClassificationEvaluator RegressionEvaluator Tuning ParamGridBuilder CrossValidator More from
- 27. Скачать презентацию
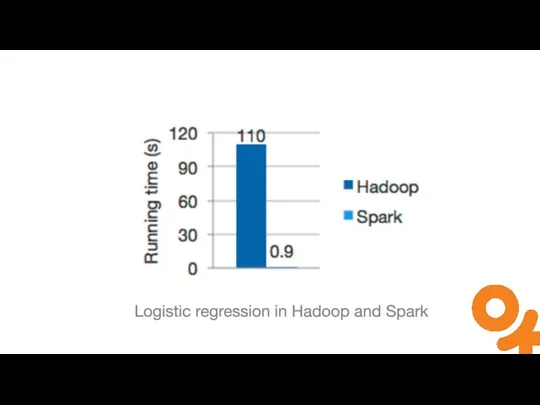
Слайд 4RDD Basics
RDD Basics
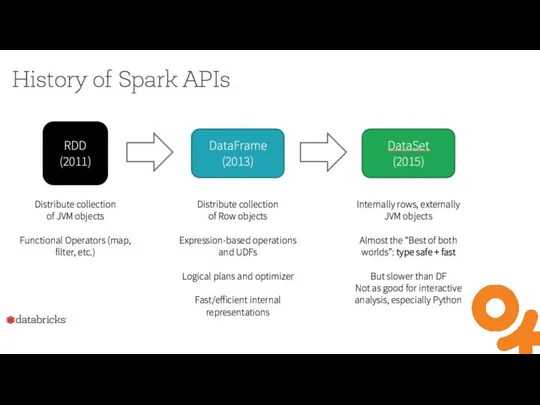
Слайд 5RDD Basics
RDD Basics
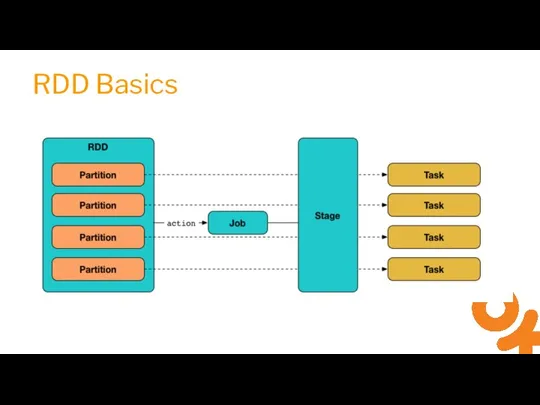
Слайд 6RDD Basics
RDD Basics
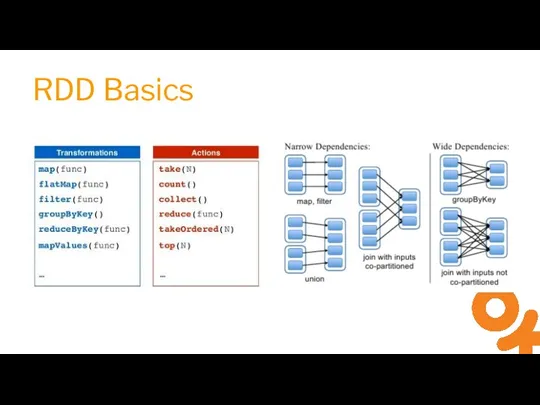
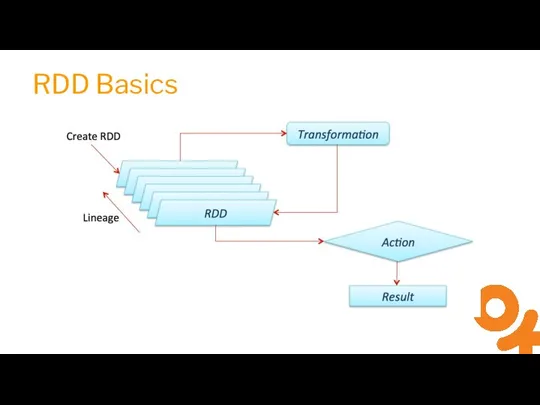
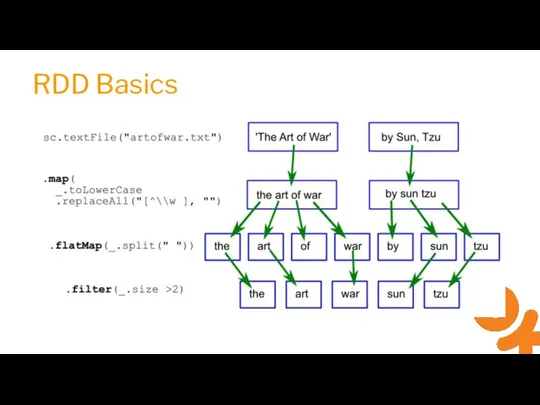
Слайд 7RDD Basics
RDD Basics
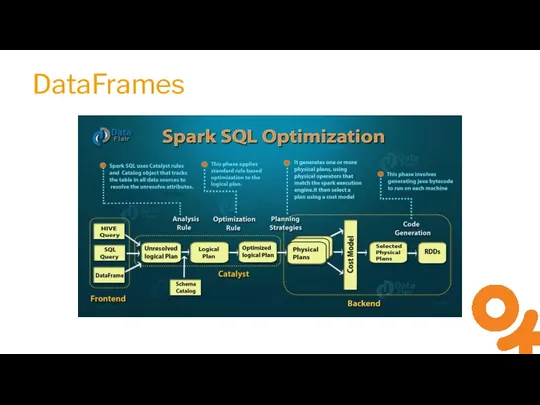
Слайд 8DataFrames
DataFrames
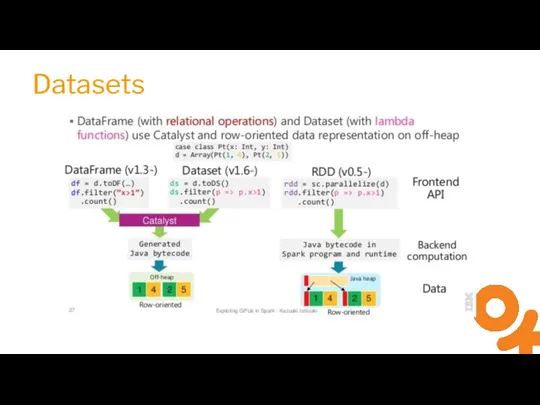
Слайд 9Datasets
Datasets
Слайд 10SQL vs. DataFrame vs. Dataset
SQL vs. DataFrame vs. Dataset

Слайд 11Spark ML Pipelines
Spark ML Pipelines

Слайд 12Spark ML Pipelines
Transformer
Spark ML Pipelines
Transformer
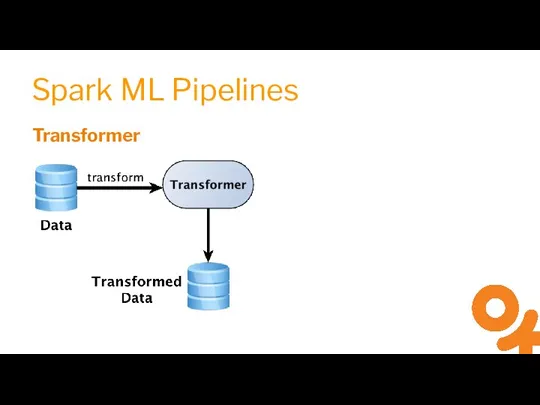
Слайд 13Spark ML Pipelines
Transformer
Estimator
Spark ML Pipelines
Transformer
Estimator
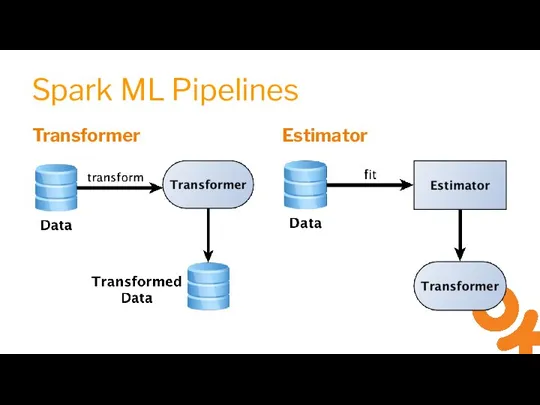
Слайд 14Spark ML Pipelines
Spark ML Pipelines
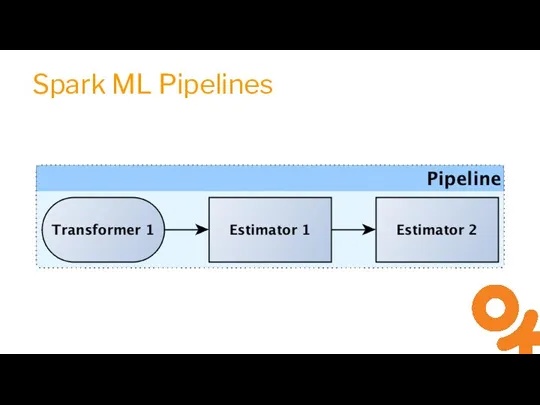
Слайд 15Spark ML Pipelines
Spark ML Pipelines
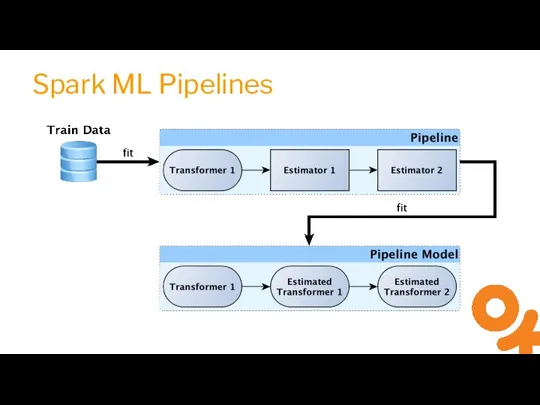
Слайд 16Spark ML Pipelines
Spark ML Pipelines
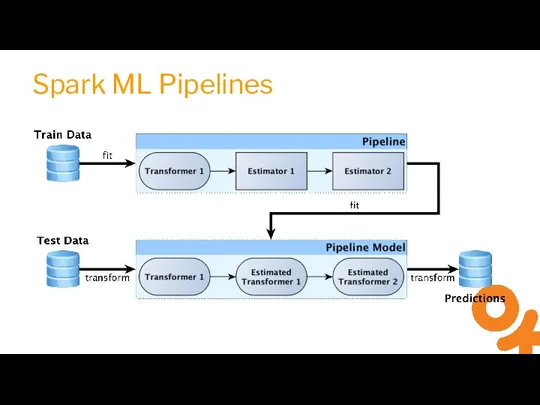
Слайд 17Spark ML Core
Spark ML Core
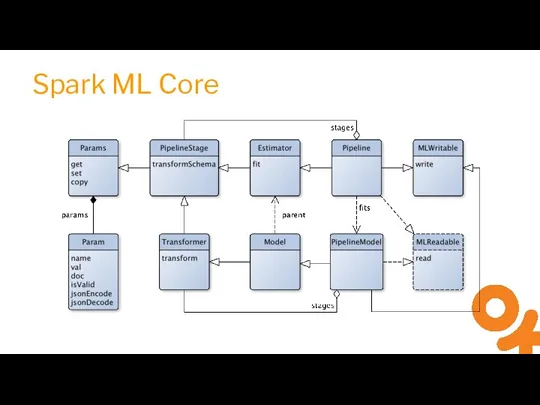
Слайд 18Field Metadata and Attributes
Field Metadata and Attributes
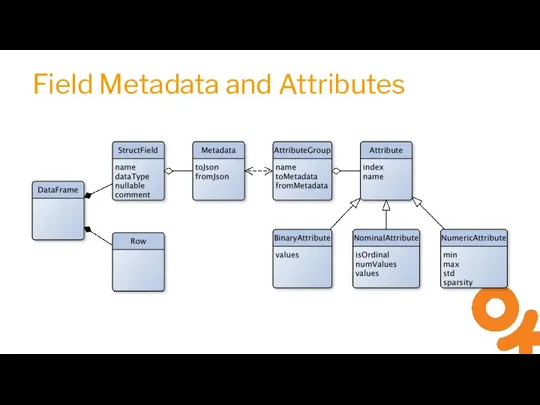
Слайд 19Prediction Model
Prediction Model
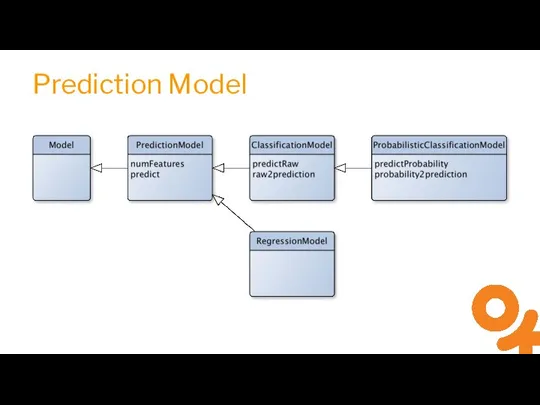
Слайд 20“My Spark ML Model”
“My Spark ML Model”
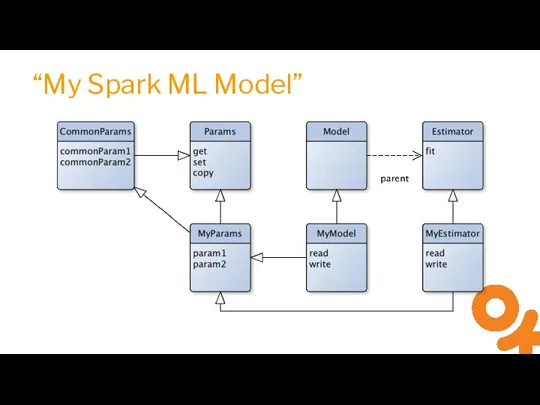
Слайд 21Spark ML Features
ETL
SQLTransformer
SqlFilter, ColumnsExtractor
Numerization
OneHotEncoder
StringIndexer
MultinomialExtractor
Vectorization
VectorAssembler
FeatureHasher
AutoAssembler
Feature Normalization
MaxAbsScaler
MinMaxScaler
Normalizer
QuantileDiscretizer
StandardScaler
Missing values
Imputer
NullToDefaultReplacer
NaNToMeanReplacer
Spark ML Features
ETL
SQLTransformer
SqlFilter, ColumnsExtractor
Numerization
OneHotEncoder
StringIndexer
MultinomialExtractor
Vectorization
VectorAssembler
FeatureHasher
AutoAssembler
Feature Normalization
MaxAbsScaler
MinMaxScaler
Normalizer
QuantileDiscretizer
StandardScaler
Missing values
Imputer
NullToDefaultReplacer
NaNToMeanReplacer

Слайд 22Spark ML Features
Feature Engineering
DCT
ElementwiseProduct
Interaction
VectorIndexer
PolynomialExpansion
Feature Selection
ChiSqSelector
FoldedFeaturesSelector
Dimension reduction
PCA
MinHashLSHModel
BucketedRandomProjectionLSH
RandomProjectionsHasher
Spark ML Features
Feature Engineering
DCT
ElementwiseProduct
Interaction
VectorIndexer
PolynomialExpansion
Feature Selection
ChiSqSelector
FoldedFeaturesSelector
Dimension reduction
PCA
MinHashLSHModel
BucketedRandomProjectionLSH
RandomProjectionsHasher

Слайд 23Spark ML Features
Texts extraction
Tokenizer
RegexTokenizer
Ngram
StopWordsRemover
NLP in Pravada-ML
LanguageDetectorTransformer
LanguageAwareAnalyzer
NGramExtractor
URLElimminator
Texts vecotization
CountVectorizer
HashingTF
IDF
Text embedding
Word2Vec
Clustering
LDA
KMeans/BisectingKMeans
GaussianMixture
Spark ML Features
Texts extraction
Tokenizer
RegexTokenizer
Ngram
StopWordsRemover
NLP in Pravada-ML
LanguageDetectorTransformer
LanguageAwareAnalyzer
NGramExtractor
URLElimminator
Texts vecotization
CountVectorizer
HashingTF
IDF
Text embedding
Word2Vec
Clustering
LDA
KMeans/BisectingKMeans
GaussianMixture

Слайд 24Spark ML Features
Regression
Classification
Spark ML Features
Regression
Classification

Слайд 25Spark ML Features
Recommendations
ALS
FPGrowth
Evaluation
BinaryClassificationEvaluator
ClusteringEvaluator
MulticlassClassificationEvaluator
RegressionEvaluator
Tuning
ParamGridBuilder
CrossValidator
More from Pravda-ML
CombinedModel
PartitionedRankingEvaluator
CRRSampler
XGBoost
StochasticHyperopt
Spark ML Features
Recommendations
ALS
FPGrowth
Evaluation
BinaryClassificationEvaluator
ClusteringEvaluator
MulticlassClassificationEvaluator
RegressionEvaluator
Tuning
ParamGridBuilder
CrossValidator
More from Pravda-ML
CombinedModel
PartitionedRankingEvaluator
CRRSampler
XGBoost
StochasticHyperopt

 IoC Inversion of Control инверсия управления. Dependency Injection (внедрение зависимостей)
IoC Inversion of Control инверсия управления. Dependency Injection (внедрение зависимостей) логика
логика Особенности материалов для соцсетей: пост, лонгрид подкаст
Особенности материалов для соцсетей: пост, лонгрид подкаст 1_количество_инф
1_количество_инф Использование свободного программного обеспечения для обучения графике
Использование свободного программного обеспечения для обучения графике Информация
Информация Разработка автоматизированной информационной системы учета материальных и иных активов в ЦЦОД IT-Куб г. Княгинино
Разработка автоматизированной информационной системы учета материальных и иных активов в ЦЦОД IT-Куб г. Княгинино Создание кроссворда в текстовом процессоре Word. 8 класс
Создание кроссворда в текстовом процессоре Word. 8 класс Анализ неструктурированных данных и оптимизация их хранения
Анализ неструктурированных данных и оптимизация их хранения ВКР: Разработка агрегатора сервисных центров по ремонту электроники
ВКР: Разработка агрегатора сервисных центров по ремонту электроники Настройка Vlan
Настройка Vlan Составление комбинированных алгоритмов для графических исполнителей
Составление комбинированных алгоритмов для графических исполнителей Макросы MoveHim и MoveTo
Макросы MoveHim и MoveTo Дистанционная подготовка
Дистанционная подготовка Отношения между объектами
Отношения между объектами Библиотечный урок В гостях у книжки о структуре книги
Библиотечный урок В гостях у книжки о структуре книги Интересные факты
Интересные факты Створюємо блог
Створюємо блог Школа “Успех в Internet PRO100”
Школа “Успех в Internet PRO100” Мемы
Мемы Самоаудит отделений boxberry через мобильное приложение Checkpoint
Самоаудит отделений boxberry через мобильное приложение Checkpoint Работа редактора с композицией медиатекста
Работа редактора с композицией медиатекста Jobs Guessing Game
Jobs Guessing Game App that change adventures
App that change adventures Основные логические операции
Основные логические операции Улучшаем монетизацию c РСЯ
Улучшаем монетизацию c РСЯ Представление данных в текстовом формате. Информационные технологии
Представление данных в текстовом формате. Информационные технологии Триггеры в презентации. Применение
Триггеры в презентации. Применение