- Тема 2.1.2

Содержание
- 2. Сжатие данных Алгоритмическое преобразование данных, производимое с целью уменьшения занимаемого ими объёма
- 3. КОЭФФИЦИЕНТ СЖАТИЯ СООТНОШЕНИЕ ИСХОДНОГО И СЖАТОГО ФАЙЛА
- 4. АЛГОРИТМ RLE КОДИРОВАНИЕ ЦЕПОЧЕК ОДИНАКОВЫХ СИМВОЛОВ 100 100 200 байтов Файл qq.txt Файл qq.rle (сжатый) 4
- 5. КОДИРОВАНИЕ ШЕННОНА — ФАНО АЛГОРИТМ ПРЕФИКСНОГО НЕОДНОРОДНОГО КОДИРОВАНИЯ. ОТНОСИТСЯ К ВЕРОЯТНОСТНЫМ МЕТОДАМ СЖАТИЯ. ИСПОЛЬЗУЕТ ИЗБЫТОЧНОСТЬ СООБЩЕНИЯ,
- 6. ОСНОВНЫЕ ЭТАПЫ АЛГОРИТМА ШЕННОНА — ФАНО СИМВОЛЫ ПЕРВИЧНОГО АЛФАВИТА M1 ВЫПИСЫВАЮТ ПО УБЫВАНИЮ ВЕРОЯТНОСТЕЙ. СИМВОЛЫ ПОЛУЧЕННОГО
- 7. ПРИМЕР КОДОВОГО ДЕРЕВА ИСХОДНЫЕ СИМВОЛЫ: A (ЧАСТОТА ВСТРЕЧАЕМОСТИ 50) B (ЧАСТОТА ВСТРЕЧАЕМОСТИ 39) C (ЧАСТОТА ВСТРЕЧАЕМОСТИ
- 8. КОД ШЕННОНА-ФАНО ДОСТОИНСТВА И НЕДОСТАТКИ учитывается частота символов не нужен символ-разделитель код префиксный – можно декодировать
- 9. АЛГОРИТМ ХАФФМАНА АЛГОРИТМ ОПТИМАЛЬНОГО ПРЕФИКСНОГО КОДИРОВАНИЯ АЛФАВИТА С МИНИМАЛЬНОЙ ИЗБЫТОЧНОСТЬЮ ЭТОТ МЕТОД КОДИРОВАНИЯ СОСТОИТ ИЗ ДВУХ
- 10. КЛАССИЧЕСКИЙ АЛГОРИТМ ХАФФМАНА НА ВХОДЕ ПОЛУЧАЕТ ТАБЛИЦУ ЧАСТОТ ВСТРЕЧАЕМОСТИ СИМВОЛОВ В СООБЩЕНИИ. ДАЛЕЕ НА ОСНОВАНИИ ЭТОЙ
- 11. ПРИМЕР ИСХОДНЫЕ СИМВОЛЫ: Полученный код:
- 12. АЛГОРИТМ ХАФФМАНА ДОСТОИНСТВА И НЕДОСТАТКИ код оптимальный среди алфавитных кодов нужно заранее знать частоты символов при
- 13. АЛГОРИТМ LZW Этот метод позволяет достичь одну из наилучших степеней сжатия среди других существующих методов сжатия
- 14. КОДИРОВАНИЕ Начало. Шаг 1. Все возможные символы заносятся в словарь. Во входную фразу X заносится первый
- 15. ПРИМЕР Пусть мы сжимаем последовательность: abacabadabacabae. Ответ: 01025039864
- 16. ДЕКОДИРОВАНИЕ Начало. Шаг 1. Все возможные символы заносятся в словарь. Во входную фразу X заносится первый
- 17. ПРИМЕР Пусть мы декодируем последовательность: 01025039864.
- 19. Скачать презентацию
Слайд 2Сжатие данных
Алгоритмическое преобразование данных, производимое с целью уменьшения занимаемого ими объёма
Сжатие данных
Алгоритмическое преобразование данных, производимое с целью уменьшения занимаемого ими объёма

Слайд 3КОЭФФИЦИЕНТ СЖАТИЯ
СООТНОШЕНИЕ ИСХОДНОГО И СЖАТОГО ФАЙЛА
КОЭФФИЦИЕНТ СЖАТИЯ
СООТНОШЕНИЕ ИСХОДНОГО И СЖАТОГО ФАЙЛА

Слайд 4АЛГОРИТМ RLE
КОДИРОВАНИЕ ЦЕПОЧЕК ОДИНАКОВЫХ СИМВОЛОВ
100
100
200 байтов
Файл qq.txt
Файл qq.rle (сжатый)
4 байта
АЛГОРИТМ RLE
КОДИРОВАНИЕ ЦЕПОЧЕК ОДИНАКОВЫХ СИМВОЛОВ
100
100
200 байтов
Файл qq.txt
Файл qq.rle (сжатый)
4 байта

Слайд 5КОДИРОВАНИЕ ШЕННОНА — ФАНО
АЛГОРИТМ ПРЕФИКСНОГО НЕОДНОРОДНОГО КОДИРОВАНИЯ. ОТНОСИТСЯ К ВЕРОЯТНОСТНЫМ МЕТОДАМ СЖАТИЯ.
ИСПОЛЬЗУЕТ ИЗБЫТОЧНОСТЬ
КОДИРОВАНИЕ ШЕННОНА — ФАНО
АЛГОРИТМ ПРЕФИКСНОГО НЕОДНОРОДНОГО КОДИРОВАНИЯ. ОТНОСИТСЯ К ВЕРОЯТНОСТНЫМ МЕТОДАМ СЖАТИЯ.
ИСПОЛЬЗУЕТ ИЗБЫТОЧНОСТЬ

Слайд 6ОСНОВНЫЕ ЭТАПЫ АЛГОРИТМА ШЕННОНА — ФАНО
СИМВОЛЫ ПЕРВИЧНОГО АЛФАВИТА M1 ВЫПИСЫВАЮТ ПО УБЫВАНИЮ ВЕРОЯТНОСТЕЙ.
СИМВОЛЫ
ОСНОВНЫЕ ЭТАПЫ АЛГОРИТМА ШЕННОНА — ФАНО
СИМВОЛЫ ПЕРВИЧНОГО АЛФАВИТА M1 ВЫПИСЫВАЮТ ПО УБЫВАНИЮ ВЕРОЯТНОСТЕЙ.
СИМВОЛЫ

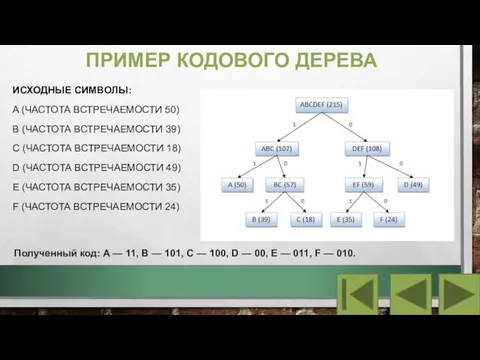
Слайд 7ПРИМЕР КОДОВОГО ДЕРЕВА
ИСХОДНЫЕ СИМВОЛЫ:
A (ЧАСТОТА ВСТРЕЧАЕМОСТИ 50)
B (ЧАСТОТА ВСТРЕЧАЕМОСТИ 39)
C (ЧАСТОТА ВСТРЕЧАЕМОСТИ
ПРИМЕР КОДОВОГО ДЕРЕВА
ИСХОДНЫЕ СИМВОЛЫ:
A (ЧАСТОТА ВСТРЕЧАЕМОСТИ 50)
B (ЧАСТОТА ВСТРЕЧАЕМОСТИ 39)
C (ЧАСТОТА ВСТРЕЧАЕМОСТИ
Слайд 8КОД ШЕННОНА-ФАНО
ДОСТОИНСТВА И НЕДОСТАТКИ
учитывается частота символов
не нужен символ-разделитель
код префиксный – можно декодировать
КОД ШЕННОНА-ФАНО
ДОСТОИНСТВА И НЕДОСТАТКИ
учитывается частота символов
не нужен символ-разделитель
код префиксный – можно декодировать

Слайд 9АЛГОРИТМ ХАФФМАНА
АЛГОРИТМ ОПТИМАЛЬНОГО ПРЕФИКСНОГО КОДИРОВАНИЯ АЛФАВИТА С МИНИМАЛЬНОЙ ИЗБЫТОЧНОСТЬЮ
ЭТОТ МЕТОД КОДИРОВАНИЯ СОСТОИТ
АЛГОРИТМ ХАФФМАНА
АЛГОРИТМ ОПТИМАЛЬНОГО ПРЕФИКСНОГО КОДИРОВАНИЯ АЛФАВИТА С МИНИМАЛЬНОЙ ИЗБЫТОЧНОСТЬЮ
ЭТОТ МЕТОД КОДИРОВАНИЯ СОСТОИТ

Слайд 10КЛАССИЧЕСКИЙ АЛГОРИТМ ХАФФМАНА НА ВХОДЕ ПОЛУЧАЕТ ТАБЛИЦУ ЧАСТОТ ВСТРЕЧАЕМОСТИ СИМВОЛОВ В СООБЩЕНИИ.
КЛАССИЧЕСКИЙ АЛГОРИТМ ХАФФМАНА НА ВХОДЕ ПОЛУЧАЕТ ТАБЛИЦУ ЧАСТОТ ВСТРЕЧАЕМОСТИ СИМВОЛОВ В СООБЩЕНИИ.

Слайд 11ПРИМЕР
ИСХОДНЫЕ СИМВОЛЫ:
Полученный код:
ПРИМЕР
ИСХОДНЫЕ СИМВОЛЫ:
Полученный код:

Слайд 12АЛГОРИТМ ХАФФМАНА
ДОСТОИНСТВА И НЕДОСТАТКИ
код оптимальный среди алфавитных кодов
нужно заранее знать частоты символов
при
АЛГОРИТМ ХАФФМАНА
ДОСТОИНСТВА И НЕДОСТАТКИ
код оптимальный среди алфавитных кодов
нужно заранее знать частоты символов
при

Слайд 13АЛГОРИТМ LZW
Этот метод позволяет достичь одну из наилучших степеней сжатия среди других
АЛГОРИТМ LZW
Этот метод позволяет достичь одну из наилучших степеней сжатия среди других

Слайд 14КОДИРОВАНИЕ
Начало.
Шаг 1. Все возможные символы заносятся в словарь. Во входную фразу X заносится первый символ
КОДИРОВАНИЕ
Начало.
Шаг 1. Все возможные символы заносятся в словарь. Во входную фразу X заносится первый символ

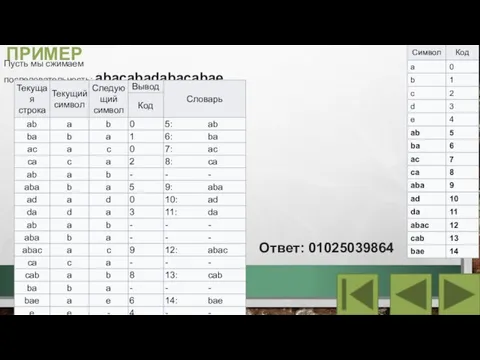
Слайд 15ПРИМЕР
Пусть мы сжимаем последовательность: abacabadabacabae.
Ответ: 01025039864
ПРИМЕР
Пусть мы сжимаем последовательность: abacabadabacabae.
Ответ: 01025039864
Слайд 16ДЕКОДИРОВАНИЕ
Начало.
Шаг 1. Все возможные символы заносятся в словарь. Во входную фразу X заносится первый код
ДЕКОДИРОВАНИЕ
Начало.
Шаг 1. Все возможные символы заносятся в словарь. Во входную фразу X заносится первый код

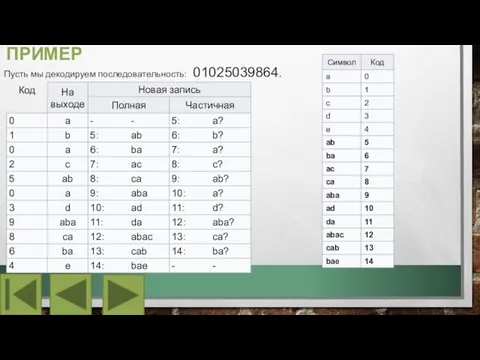
Слайд 17ПРИМЕР
Пусть мы декодируем последовательность: 01025039864.
ПРИМЕР
Пусть мы декодируем последовательность: 01025039864.
 Способы представления информации. Носители информации. Урок 4
Способы представления информации. Носители информации. Урок 4 Ключевые вопросы для обсуждения на текущий период
Ключевые вопросы для обсуждения на текущий период Продвижение через социальные сети
Продвижение через социальные сети Алгоритм: добыча клада
Алгоритм: добыча клада Инвентаризация ОС по шагам
Инвентаризация ОС по шагам Организация ввода и вывода данных. Начала программирования
Организация ввода и вывода данных. Начала программирования Программное обеспечение для расчета стоимости грузоперевозок ООО НПЗ-Транс
Программное обеспечение для расчета стоимости грузоперевозок ООО НПЗ-Транс Использование связей
Использование связей Занятие Школы Медиа
Занятие Школы Медиа Flipping through channels
Flipping through channels БД_л3_Типы_данных_констрейны
БД_л3_Типы_данных_констрейны Структура LTE
Структура LTE Системы распознавания речи
Системы распознавания речи Пистолет с Touch ID
Пистолет с Touch ID Бесплатное обучение торговле на рынке Форекс
Бесплатное обучение торговле на рынке Форекс Республиканский конкурс ИТ-Чемпион
Республиканский конкурс ИТ-Чемпион 4. Измерение информации. Содержательный подход
4. Измерение информации. Содержательный подход Test questions
Test questions Архитектура информационных систем. Лекция 1
Архитектура информационных систем. Лекция 1 Виды и техника правки текстов
Виды и техника правки текстов Windows 7. Операционная система
Windows 7. Операционная система Стриминг в игровой сфере
Стриминг в игровой сфере Языки программирования. Эволюция языков программирования. Методы программирования. Тема 1
Языки программирования. Эволюция языков программирования. Методы программирования. Тема 1 Отчёт о прохождении практики в коммуникационном агентстве полного цикла Redline PR
Отчёт о прохождении практики в коммуникационном агентстве полного цикла Redline PR Вход в оборот
Вход в оборот Основы проектирования баз данных (лекция 6)
Основы проектирования баз данных (лекция 6) Создание векторного рисунка в Microsoft Word
Создание векторного рисунка в Microsoft Word Особенности продвижения корпоративного бренда в Интернет – пространстве
Особенности продвижения корпоративного бренда в Интернет – пространстве