- Автоматическое определение авторства

Содержание
- 2. Введение Определение авторства – определение одного автора из нескольких возможных Верификация автора – установление, принадлежит ли
- 3. Содержание Определение автора как задача классификации Методы атрибуции
- 4. Определение авторства как задача классификации Дано: текст неизвестного автора набор возможных авторов примеры текстов для каждого
- 5. Стилистические свойства Символьные Лексические Синтаксические Семантические Тематические
- 6. Лексические свойства текстов Словарный запас – зависит от объема текста, не может использоваться в одиночку Частотные
- 7. Символьные свойства текста Частотные распределения букв, цифр, верхнего и нижнего регистра, знаков препинания N-граммы – сочетания
- 8. Синтаксические свойства Автор использует набор синтаксических паттернов, которые хуже осознаются, чем лексика Требуется синтаксический разбор текста
- 9. Семантические свойства Семантический анализ сам по себе менее развит, семантическая разметка дает большее число ошибок –
- 10. Тематические свойства Если тематика сообщений заранее известна (например, речь идет об анонимном сообщении на тематическом интернет-форуме),
- 11. Выбор свойств В определении авторства лучше всего работает не одно какое-то свойство, а их сочетание Обычно
- 12. Содержание Определение автора как задача классификации Методы атрибуции
- 13. Ориентированные на автора
- 14. Ориентированные на текст
- 16. Скачать презентацию
Слайд 2Введение
Определение авторства – определение одного автора из нескольких возможных
Верификация автора – установление,
Введение
Определение авторства – определение одного автора из нескольких возможных
Верификация автора – установление,

Слайд 3Содержание
Определение автора как задача классификации
Методы атрибуции
Содержание
Определение автора как задача классификации
Методы атрибуции

Слайд 4Определение авторства как задача классификации
Дано:
текст неизвестного автора
набор возможных авторов
примеры текстов для
Определение авторства как задача классификации
Дано:
текст неизвестного автора
набор возможных авторов
примеры текстов для

Слайд 5Стилистические свойства
Символьные
Лексические
Синтаксические
Семантические
Тематические
Стилистические свойства
Символьные
Лексические
Синтаксические
Семантические
Тематические

Слайд 6Лексические свойства текстов
Словарный запас
– зависит от объема текста, не может использоваться
Лексические свойства текстов
Словарный запас
– зависит от объема текста, не может использоваться

Слайд 7Символьные свойства текста
Частотные распределения букв, цифр, верхнего и нижнего регистра, знаков препинания
N-граммы
Символьные свойства текста
Частотные распределения букв, цифр, верхнего и нижнего регистра, знаков препинания
N-граммы

Слайд 8Синтаксические свойства
Автор использует набор синтаксических паттернов, которые хуже осознаются, чем лексика
Требуется синтаксический
Синтаксические свойства
Автор использует набор синтаксических паттернов, которые хуже осознаются, чем лексика
Требуется синтаксический

Слайд 9Семантические свойства
Семантический анализ сам по себе менее развит, семантическая разметка дает большее
Семантические свойства
Семантический анализ сам по себе менее развит, семантическая разметка дает большее

Слайд 10Тематические свойства
Если тематика сообщений заранее известна (например, речь идет об анонимном сообщении
Тематические свойства
Если тематика сообщений заранее известна (например, речь идет об анонимном сообщении

Слайд 11Выбор свойств
В определении авторства лучше всего работает не одно какое-то свойство, а
Выбор свойств
В определении авторства лучше всего работает не одно какое-то свойство, а

Слайд 12Содержание
Определение автора как задача классификации
Методы атрибуции
Содержание
Определение автора как задача классификации
Методы атрибуции

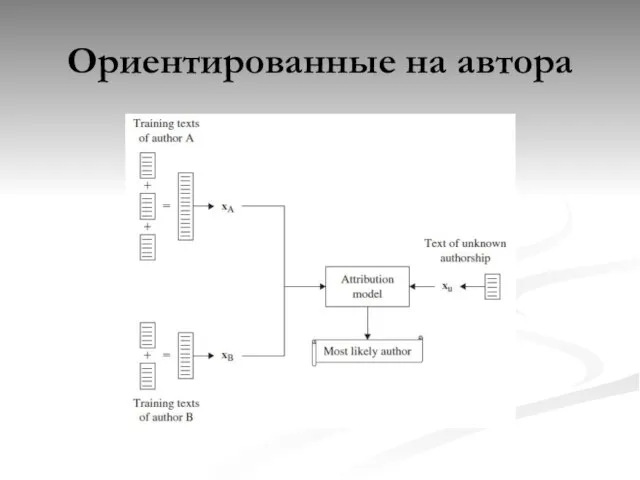
Слайд 13Ориентированные на автора
Ориентированные на автора
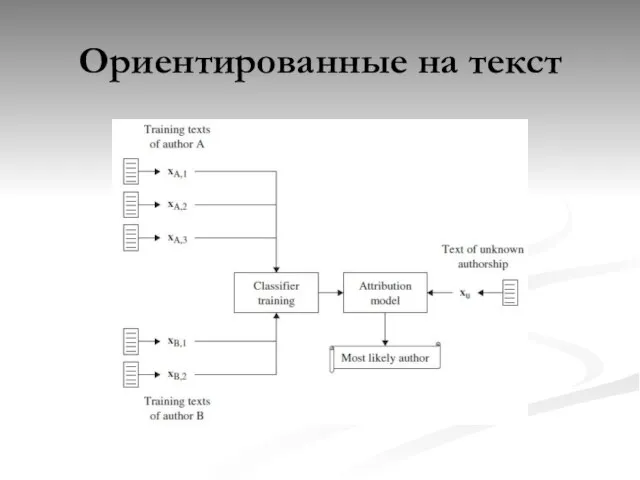
Слайд 14Ориентированные на текст
Ориентированные на текст
 К вопросу о цикличности развития диатомовых водорослей Байкала
К вопросу о цикличности развития диатомовых водорослей Байкала Вариации на тему …. организационной структуры
Вариации на тему …. организационной структуры Звездный час
Звездный час Храмовое зодчество Византии
Храмовое зодчество Византии Опыт реализации программы психолого-педагогического сопровождения развития личности в условиях МОУ СОШ №9
Опыт реализации программы психолого-педагогического сопровождения развития личности в условиях МОУ СОШ №9 Конструктор цветной прозрачный блок 2. 4 уровень сложности
Конструктор цветной прозрачный блок 2. 4 уровень сложности Искусство витража
Искусство витража Психология групп С.А. Володина. Малые группы
Психология групп С.А. Володина. Малые группы Измерение эффективности Rich-Media Полевой эксперимент
Измерение эффективности Rich-Media Полевой эксперимент MENDELEEV DIMITRIT IVANOVICH
MENDELEEV DIMITRIT IVANOVICH Стили родительского воспитания
Стили родительского воспитания ОБЪЕДИНЕННАЯ ДВИГАТЕЛЕСТРОИТЕЛЬНАЯ КОРПОРАЦИЯ ОАО”Пермский моторный завод”
ОБЪЕДИНЕННАЯ ДВИГАТЕЛЕСТРОИТЕЛЬНАЯ КОРПОРАЦИЯ ОАО”Пермский моторный завод” Строение цветка
Строение цветка Гимнастика
Гимнастика Мобильные приложения
Мобильные приложения НОВЫЕ ТЕХНОЛОГИИ КИНЕЗОТЕРАПИИ В САНАТОРНО-КУРОРТНОМ ЛЕЧЕНИИ
НОВЫЕ ТЕХНОЛОГИИ КИНЕЗОТЕРАПИИ В САНАТОРНО-КУРОРТНОМ ЛЕЧЕНИИ Олимпийские игры в Греции
Олимпийские игры в Греции Презентация на тему Загрязнение воды и последствия
Презентация на тему Загрязнение воды и последствия  Готов к труду и обороне (ГТО)
Готов к труду и обороне (ГТО) R – X
R – X Соглашение о встречной закупке Выполнили УЛАН КЫЗЫ АЙГЕРИМ, РАДЖАБИЕН САРВАРИ
Соглашение о встречной закупке Выполнили УЛАН КЫЗЫ АЙГЕРИМ, РАДЖАБИЕН САРВАРИ Презентация на тему Изобретения 19 века
Презентация на тему Изобретения 19 века Заработная плата. Тема 24
Заработная плата. Тема 24 Творчество А.Блока
Творчество А.Блока Вакуумный выключатель среднего напряжения VD4
Вакуумный выключатель среднего напряжения VD4 Коллективные знаки, охраняемые в Российской Федерации
Коллективные знаки, охраняемые в Российской Федерации Презентация на тему Дневник Печорина как самохарактеристика героя
Презентация на тему Дневник Печорина как самохарактеристика героя Проект: робо-рука
Проект: робо-рука