- Байесова филогенетика

Содержание
- 2. Проблема конкурирующих гипотез и метод проб и ошибок Примеры гипотез: Встречу ли я динозавра, выйдя на
- 3. Проблема конкурирующих гипотез и метод проб и ошибок Примеры гипотез: Встречу ли я динозавра, выйдя на
- 4. Если мы вынули из ящика 21 белый шар, то это точно гипотеза H1 Но не обязательно
- 5. Проблема конкурирующих гипотез и метод проб и ошибок Примеры гипотез: Филогенетическая реконструкция: топология 1, топология 2
- 6. Проблема конкурирующих гипотез Решения: MP: выбираем наиболее простую гипотезу ML: выбираем наиболее правдоподобную гипотезу НО: 1)
- 7. Проблема конкурирующих гипотез А еще лучше иметь совокупность всех гипотез с прямыми оценками их вероятностей Есть
- 8. Метод Байеса (Bayes Inference) Thomas Bayes 1702-1761 England Байесова статистика . Обычная статистика рассматривает вероятности (частоты
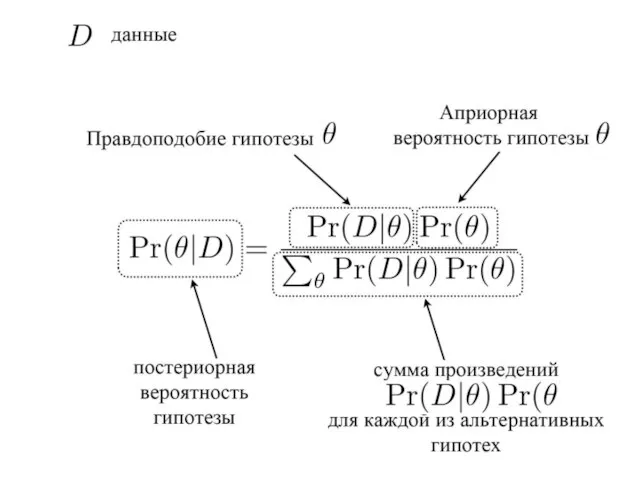
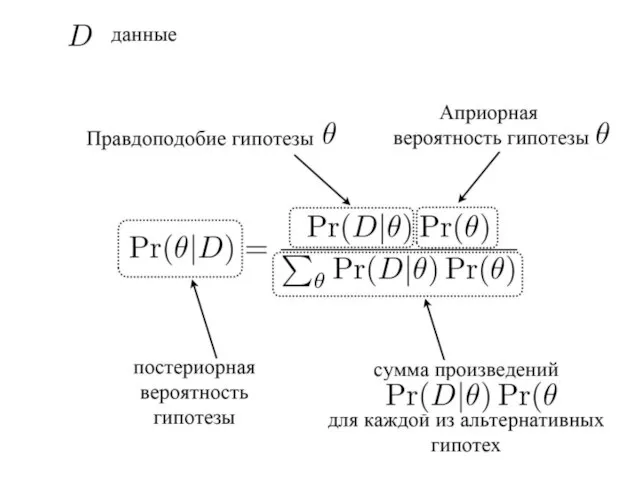
- 9. Метод Байеса (Bayes Inference) основные понятия: Априорная вероятность гипотезы Постериорная вероятность гипотезы правдоподобие гипотезы (вероятность наблюдения
- 10. Априорные и постериорные гипотезы Схема анализа: 1) выбираются (задаются) априорные гипотезы (вероятности) 2) получение данных (эмпирическое
- 11. H1 –гипотеза 1 Н2 – гипотеза 2 E - испытание (P(H1/E) – постериорная вероятность гипотезы H1
- 12. P априорное для H1 = 0.5 P априорное для H2 = 0.5
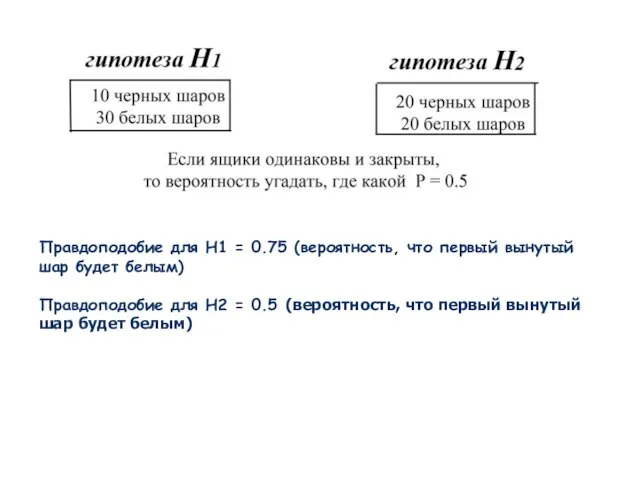
- 13. Правдоподобие для H1 = 0.75 (вероятность, что первый вынутый шар будет белым) Правдоподобие для H2 =
- 14. P(H1) – априорная вероятность гипотезы H1 (P(H1/E) – постериорная вероятность гипотезы H1 P(E/H1) – вероятность наблюдения
- 15. Итеративная процедура – многократное возвращение к тестированию исходной гипотезы, но каждый раз с учетом уже измененной
- 16. Вторая итерация априорные вероятности гипотез уже другие P(H1)=0.6; P(H2)=0.4 Р = (0.6 х 0.75)/(0.6 х 0.75
- 17. Р = (0.69 х 0.75)/(0.69 х 0.75 + 0.31 х 0.5) = 0.5175/(0.5175 + 0.155) =
- 18. Продолжаем процесс до тех пор пока вероятность одной из гипотез не достигнет 100% [P(H1)=1], т.е. гипотеза
- 19. Лодка затонула 21 мая 1968 годаЛодка затонула 21 мая 1968 года в 740 км (400 миль)
- 21. Как все это перенести на реконструкцию филогении? - нужны предварительные гипотезы - нужны значения правдоподобий
- 22. Метод максимального правдоподобия JC model Вероятности всех замен одинаковы, т.е. P(AC)=P(AG)=P(AT)=P(CG)=P(CT)=P(GT)=α частоты нуклеотидов равны, т.е. f(A)=f(C)=f(G)=f(T)=0.25
- 24. Теперь вопрос, как перейти к филогенетическим гипотезам, т.е. деревьям
- 25. • В филогенетике эволюционные модели составляют очень большое число гипотез: (каждая уникальная комбинация дерева [топологии] и
- 26. анализировать не отдельные гипотезы (их может быть неограниченное множество), а статистические распределения этих гипотез
- 31. Униформный (неспецифический прайор), казалось бы, какая от него польза. Но вспомним про итеративность… Итерации постепенно сдвигают
- 33. Еще один прием: расчленить тестируемую гипотезу: представить ее в виде совокупности более простых гипотез
- 34. В случае филогенетической гипотезы вместо дерева можно дать совокупность: 1) топология 2) информация о длине ветвей
- 35. 1) прайор о топологии 2) прайор о длине ветвей 3) прайор о частотах нуклеотидов 4) прайор
- 37. При проведении анализа запускается несколько цепей (обычно 4), каждая из которых ищет оптимальные деревья Цепи могут
- 38. Как задать прайоры в Байесовом анализе? Как выбрать модель эволюции в Байесовом анализе? GTR+I+G
- 39. Пример Филогения бабочек рода Parnassius, основанная на анализе гена COI с использованием метода Байеса
- 42. но Основан на другой статистике, которая позволяет, получив вероятность дерева, пересчитать ее с учетом той топологии,
- 43. Получаемые в ходе Байесова анализа деревья образуют распределение, которое позволяет рассчитать так называемую постериорную вероятность отдельных
- 44. Распределение этих деревьев позволяет рассчитать так называемую апостериорную вероятность (PB), которая является прямой оценкой вероятности филогенетической
- 45. Методы максимального правдоподобия и Байеса: сходство и различия, плюсы и минусы ML говорит лишь о степени
- 46. Методы максимального правдоподобия и Байеса применимы для анализа любых структур, закономерности эволюции которых могут быть формализованы
- 47. Не существует никакого теоретического запрета на использование морфологических признаков в рамках метода максимального правдоподобия и Байесова
- 48. Пример Филогения бабочек рода Parnassius, основанная на анализе гена COI с использованием метода Байеса
- 49. Методы реконструкции филогенезов , основанные на анализе генетических дистанций ДНК: 1 5 10 tagcaaaatg
- 50. Суть метода Откуда берутся генетические дистанции? ДНК-ДНК гибридизация, иммунологические реакции, анализ анонимных маркеров – все, что
- 51. Превращение матрицы дискретных данных в матрицу дистанций Превращение матрицы дискретных данных в матрицу дистанций
- 52. Построение дерева на основании матрицы дискретных данных и на основании в матрицы дистанций
- 53. Чем генетические дистанции отличаются от фенетических? Понятия сырой “p” дистанции и скорректированной дистанции модели эволюции
- 54. Методы коррекции генетических дистанций
- 55. Если вероятности нуклеотидных замен (p) и частоты нуклеотидов (f) константны во времени, то суммарная эволюционная дистанция
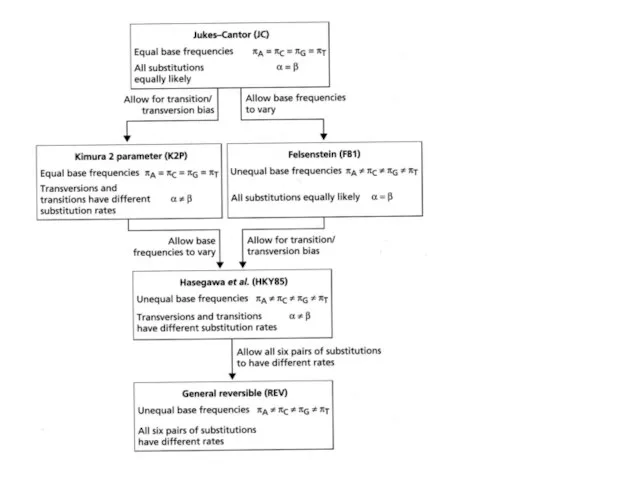
- 56. JC Вероятности всех замен одинаковы, частоты нуклеотидов равны
- 57. K2P Вероятности транзиций и трансверсий разные, частоты нуклеотидов равны α – транзиция β - трансверсия
- 58. F81 Вероятности всех замен одинаковы, но частоты нуклеотидов разные
- 59. K2P Вероятности транзиций и трансверсий разные, частоты нуклеотидов разные
- 60. REV Вероятности ВСЕХ ЗАМЕН разные, частоты нуклеотидов разные
- 62. Методы построения “дистантных” деревьев Методы основанные на использовании критериев оптимальности Методы, основанные на алгоритмах кластеризации
- 63. Методы основанные на использовании критериев оптимальности Метод наименьших квадратов Оптимальным деревом признается то, при котором сумма
- 65. Методы основанные на использовании критериев оптимальности Метод наименьших квадратов Оптимальным деревом признается то, при котором сумма
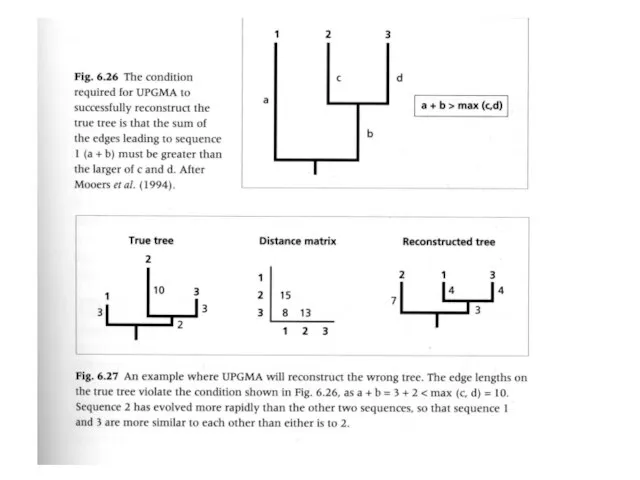
- 66. Методы, основанные на алгоритмах кластеризации Метод ближайшего соседа (Neighbour Joining) Метод UPGMA (unweighted pair group method
- 67. Построение дерева на основании матрицы дискретных данных и на основании в матрицы дистанций
- 68. Методы, основанные на алгоритмах кластеризации Метод ближайшего соседа (Neighbour Joining) Метод UPGMA (unweighted pair group method
- 71. Скачать презентацию
Слайд 2Проблема конкурирующих гипотез
и метод проб и ошибок
Примеры гипотез:
Встречу ли я динозавра, выйдя
Проблема конкурирующих гипотез
и метод проб и ошибок
Примеры гипотез:
Встречу ли я динозавра, выйдя

Слайд 3Проблема конкурирующих гипотез
и метод проб и ошибок
Примеры гипотез:
Встречу ли я динозавра, выйдя
Проблема конкурирующих гипотез
и метод проб и ошибок
Примеры гипотез:
Встречу ли я динозавра, выйдя

Слайд 4Если мы вынули из ящика 21 белый шар, то это точно
гипотеза
Если мы вынули из ящика 21 белый шар, то это точно
гипотеза

Слайд 5Проблема конкурирующих гипотез
и метод проб и ошибок
Примеры гипотез:
Филогенетическая реконструкция: топология 1, топология
Проблема конкурирующих гипотез
и метод проб и ошибок
Примеры гипотез:
Филогенетическая реконструкция: топология 1, топология

Слайд 6Проблема конкурирующих гипотез
Решения:
MP: выбираем наиболее простую гипотезу
ML: выбираем наиболее правдоподобную гипотезу
НО:
1)
Проблема конкурирующих гипотез
Решения:
MP: выбираем наиболее простую гипотезу
ML: выбираем наиболее правдоподобную гипотезу
НО:
1)

Слайд 7Проблема конкурирующих гипотез
А еще лучше иметь совокупность всех гипотез с прямыми оценками
Проблема конкурирующих гипотез
А еще лучше иметь совокупность всех гипотез с прямыми оценками

Слайд 8Метод Байеса (Bayes Inference)
Thomas Bayes
1702-1761 England
Байесова статистика .
Обычная статистика рассматривает вероятности (частоты
Метод Байеса (Bayes Inference)
Thomas Bayes
1702-1761 England
Байесова статистика .
Обычная статистика рассматривает вероятности (частоты

Слайд 9Метод Байеса (Bayes Inference)
основные понятия:
Априорная вероятность гипотезы
Постериорная вероятность гипотезы
правдоподобие гипотезы (вероятность
Метод Байеса (Bayes Inference)
основные понятия:
Априорная вероятность гипотезы
Постериорная вероятность гипотезы
правдоподобие гипотезы (вероятность

Слайд 10Априорные и постериорные гипотезы
Схема анализа:
1) выбираются (задаются) априорные гипотезы (вероятности)
2) получение данных
Априорные и постериорные гипотезы
Схема анализа:
1) выбираются (задаются) априорные гипотезы (вероятности)
2) получение данных

Слайд 11H1 –гипотеза 1
Н2 – гипотеза 2
E - испытание
(P(H1/E) – постериорная вероятность гипотезы
H1 –гипотеза 1
Н2 – гипотеза 2
E - испытание
(P(H1/E) – постериорная вероятность гипотезы

Слайд 12P априорное для H1 = 0.5
P априорное для H2 = 0.5
P априорное для H1 = 0.5
P априорное для H2 = 0.5

Слайд 13Правдоподобие для H1 = 0.75 (вероятность, что первый вынутый шар будет белым)
Правдоподобие
Правдоподобие для H1 = 0.75 (вероятность, что первый вынутый шар будет белым)
Правдоподобие
Слайд 14P(H1) – априорная вероятность гипотезы H1
(P(H1/E) – постериорная вероятность гипотезы H1
P(E/H1) –
P(H1) – априорная вероятность гипотезы H1
(P(H1/E) – постериорная вероятность гипотезы H1
P(E/H1) –

Слайд 15Итеративная процедура – многократное возвращение к тестированию исходной гипотезы, но каждый раз
Итеративная процедура – многократное возвращение к тестированию исходной гипотезы, но каждый раз

Слайд 16Вторая итерация
априорные вероятности гипотез уже другие
P(H1)=0.6; P(H2)=0.4
Р = (0.6 х 0.75)/(0.6 х
Вторая итерация
априорные вероятности гипотез уже другие
P(H1)=0.6; P(H2)=0.4
Р = (0.6 х 0.75)/(0.6 х

Слайд 17Р = (0.69 х 0.75)/(0.69 х 0.75 + 0.31 х 0.5) =
Р = (0.69 х 0.75)/(0.69 х 0.75 + 0.31 х 0.5) =

Слайд 18Продолжаем процесс до тех пор пока вероятность одной из гипотез не достигнет
Продолжаем процесс до тех пор пока вероятность одной из гипотез не достигнет

Слайд 19Лодка затонула 21 мая 1968 годаЛодка затонула 21 мая 1968 года в 740 км (400
Лодка затонула 21 мая 1968 годаЛодка затонула 21 мая 1968 года в 740 км (400

Слайд 21Как все это перенести на реконструкцию филогении?
- нужны предварительные гипотезы
- нужны значения
Как все это перенести на реконструкцию филогении?
- нужны предварительные гипотезы
- нужны значения

Слайд 22Метод максимального
правдоподобия
JC model
Вероятности всех замен одинаковы,
т.е. P(AC)=P(AG)=P(AT)=P(CG)=P(CT)=P(GT)=α
частоты нуклеотидов равны,
т.е. f(A)=f(C)=f(G)=f(T)=0.25
Pxy
Метод максимального
правдоподобия
JC model
Вероятности всех замен одинаковы,
т.е. P(AC)=P(AG)=P(AT)=P(CG)=P(CT)=P(GT)=α
частоты нуклеотидов равны,
т.е. f(A)=f(C)=f(G)=f(T)=0.25
Pxy

Слайд 24Теперь вопрос, как перейти к филогенетическим гипотезам, т.е. деревьям
Теперь вопрос, как перейти к филогенетическим гипотезам, т.е. деревьям

Слайд 25• В филогенетике эволюционные модели составляют очень большое число гипотез: (каждая уникальная
• В филогенетике эволюционные модели составляют очень большое число гипотез: (каждая уникальная

Слайд 26анализировать не отдельные гипотезы (их может быть неограниченное множество), а статистические распределения

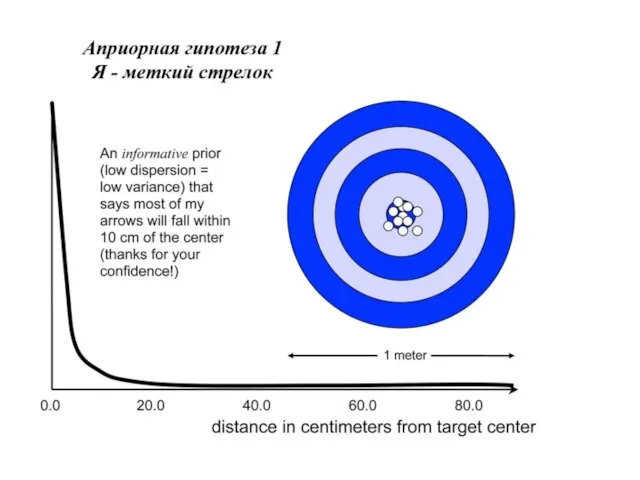
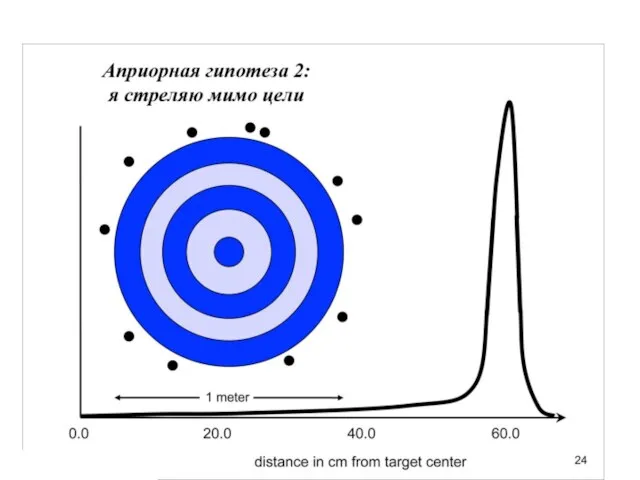
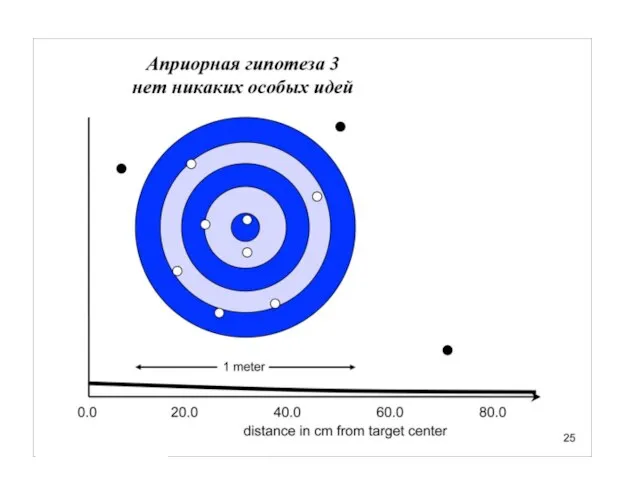
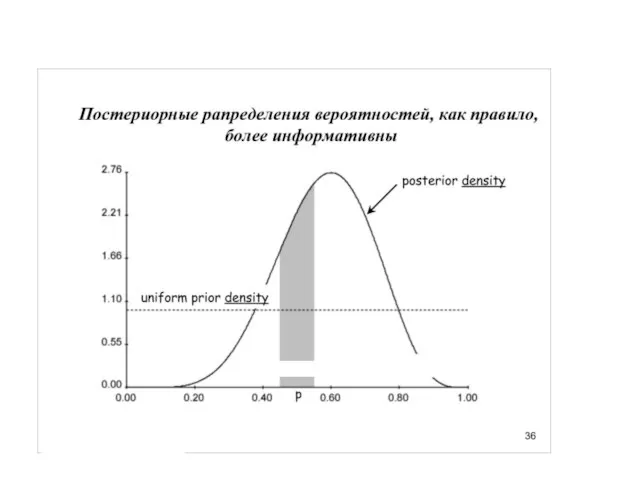
Слайд 31Униформный (неспецифический прайор), казалось бы, какая от него польза.
Но вспомним про итеративность…
Униформный (неспецифический прайор), казалось бы, какая от него польза.
Но вспомним про итеративность…

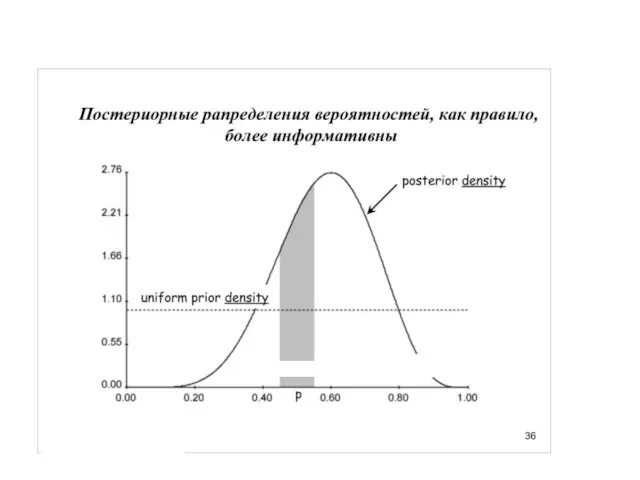
Слайд 33Еще один прием: расчленить тестируемую гипотезу: представить ее в виде совокупности более
Еще один прием: расчленить тестируемую гипотезу: представить ее в виде совокупности более

Слайд 34В случае филогенетической гипотезы вместо дерева можно дать совокупность:
1) топология
2) информация о
В случае филогенетической гипотезы вместо дерева можно дать совокупность:
1) топология
2) информация о

Слайд 351) прайор о топологии
2) прайор о длине ветвей
3) прайор о частотах нуклеотидов
4)
1) прайор о топологии
2) прайор о длине ветвей
3) прайор о частотах нуклеотидов
4)

Слайд 37При проведении анализа запускается несколько цепей (обычно 4), каждая из которых ищет
При проведении анализа запускается несколько цепей (обычно 4), каждая из которых ищет

Слайд 38Как задать прайоры в Байесовом анализе?
Как выбрать модель эволюции в Байесовом
Как задать прайоры в Байесовом анализе?
Как выбрать модель эволюции в Байесовом

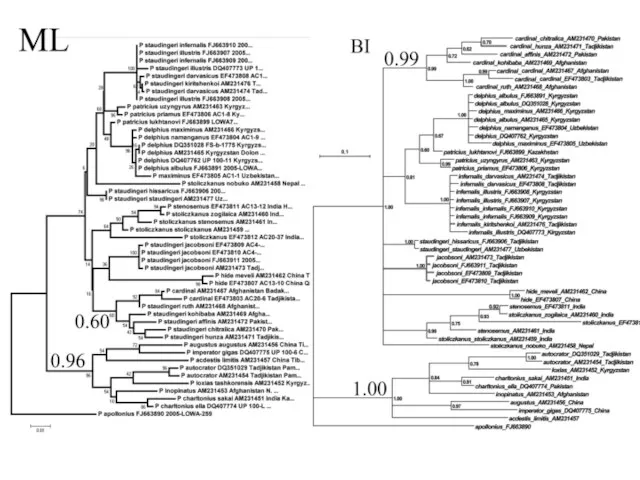
Слайд 39Пример
Филогения бабочек рода Parnassius, основанная на анализе гена COI с использованием метода
Пример Филогения бабочек рода Parnassius, основанная на анализе гена COI с использованием метода


Слайд 42
но
Основан на другой статистике, которая позволяет, получив вероятность дерева, пересчитать ее с
но
Основан на другой статистике, которая позволяет, получив вероятность дерева, пересчитать ее с

Слайд 43Получаемые в ходе Байесова анализа деревья образуют распределение, которое позволяет рассчитать так
Получаемые в ходе Байесова анализа деревья образуют распределение, которое позволяет рассчитать так

Слайд 44Распределение этих деревьев позволяет рассчитать так называемую апостериорную вероятность (PB), которая является
Распределение этих деревьев позволяет рассчитать так называемую апостериорную вероятность (PB), которая является

Слайд 45Методы максимального правдоподобия и Байеса: сходство и различия, плюсы и минусы
ML говорит
Методы максимального правдоподобия и Байеса: сходство и различия, плюсы и минусы
ML говорит

Слайд 46Методы максимального правдоподобия и Байеса применимы для анализа любых структур, закономерности эволюции
Методы максимального правдоподобия и Байеса применимы для анализа любых структур, закономерности эволюции
Слайд 47Не существует никакого теоретического запрета на использование морфологических признаков в рамках метода
Не существует никакого теоретического запрета на использование морфологических признаков в рамках метода

Слайд 48Пример
Филогения бабочек рода Parnassius, основанная на анализе гена COI с использованием метода
Пример Филогения бабочек рода Parnassius, основанная на анализе гена COI с использованием метода

Слайд 49Методы реконструкции филогенезов , основанные на анализе генетических дистанций
ДНК:
1 5 10
tagcaaaatg
Методы реконструкции филогенезов , основанные на анализе генетических дистанций
ДНК:
1 5 10
tagcaaaatg

Слайд 50Суть метода
Откуда берутся генетические дистанции?
ДНК-ДНК гибридизация, иммунологические реакции, анализ анонимных маркеров –
Суть метода
Откуда берутся генетические дистанции?
ДНК-ДНК гибридизация, иммунологические реакции, анализ анонимных маркеров –

Слайд 51Превращение матрицы дискретных данных в матрицу дистанций
Превращение матрицы дискретных данных в матрицу
Превращение матрицы дискретных данных в матрицу дистанций
Превращение матрицы дискретных данных в матрицу

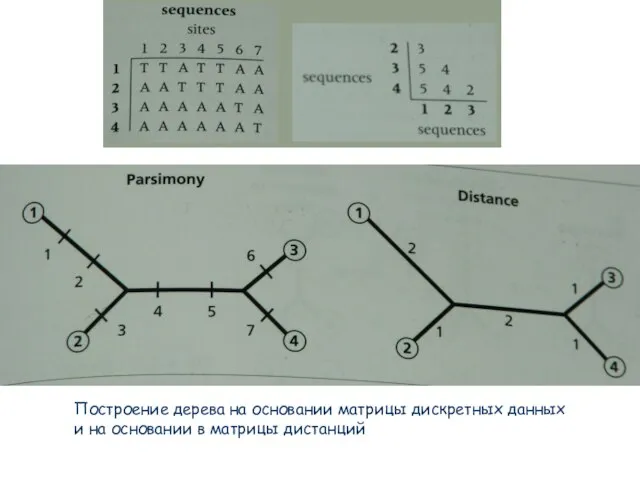
Слайд 52Построение дерева на основании матрицы дискретных данных
и на основании в матрицы
Построение дерева на основании матрицы дискретных данных
и на основании в матрицы
Слайд 53Чем генетические дистанции отличаются от фенетических?
Понятия сырой “p” дистанции и скорректированной дистанции
модели
Чем генетические дистанции отличаются от фенетических?
Понятия сырой “p” дистанции и скорректированной дистанции
модели

Слайд 54Методы коррекции генетических дистанций
Методы коррекции генетических дистанций

Слайд 55Если вероятности нуклеотидных замен (p) и частоты нуклеотидов (f) константны во времени,
Если вероятности нуклеотидных замен (p) и частоты нуклеотидов (f) константны во времени,

Слайд 56JC
Вероятности всех замен одинаковы, частоты нуклеотидов равны
JC
Вероятности всех замен одинаковы, частоты нуклеотидов равны

Слайд 57K2P
Вероятности транзиций и трансверсий разные,
частоты нуклеотидов равны
α – транзиция
β - трансверсия
K2P
Вероятности транзиций и трансверсий разные,
частоты нуклеотидов равны
α – транзиция
β - трансверсия

Слайд 58 F81
Вероятности всех замен одинаковы, но частоты нуклеотидов разные
F81
Вероятности всех замен одинаковы, но частоты нуклеотидов разные

Слайд 59K2P
Вероятности транзиций и трансверсий разные,
частоты нуклеотидов разные
K2P
Вероятности транзиций и трансверсий разные,
частоты нуклеотидов разные

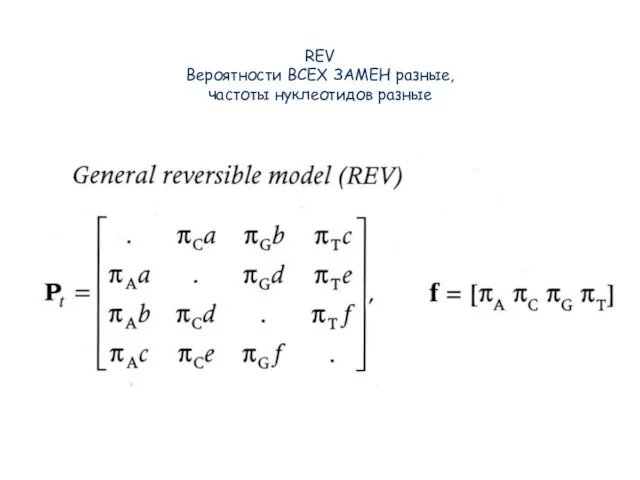
Слайд 60REV
Вероятности ВСЕХ ЗАМЕН разные,
частоты нуклеотидов разные
REV
Вероятности ВСЕХ ЗАМЕН разные,
частоты нуклеотидов разные
Слайд 62Методы построения “дистантных” деревьев
Методы основанные на использовании критериев оптимальности
Методы, основанные на
Методы построения “дистантных” деревьев
Методы основанные на использовании критериев оптимальности
Методы, основанные на

Слайд 63Методы основанные на использовании критериев оптимальности
Метод наименьших квадратов
Оптимальным деревом признается то, при
Метод наименьших квадратов
Оптимальным деревом признается то, при

Слайд 65Методы основанные на использовании критериев оптимальности
Метод наименьших квадратов
Оптимальным деревом признается то, при
Метод наименьших квадратов
Оптимальным деревом признается то, при

Слайд 66Методы, основанные на алгоритмах кластеризации
Метод ближайшего соседа (Neighbour Joining)
Метод UPGMA (unweighted pair
Методы, основанные на алгоритмах кластеризации
Метод ближайшего соседа (Neighbour Joining)
Метод UPGMA (unweighted pair

Слайд 67Построение дерева на основании матрицы дискретных данных
и на основании в матрицы
Построение дерева на основании матрицы дискретных данных
и на основании в матрицы
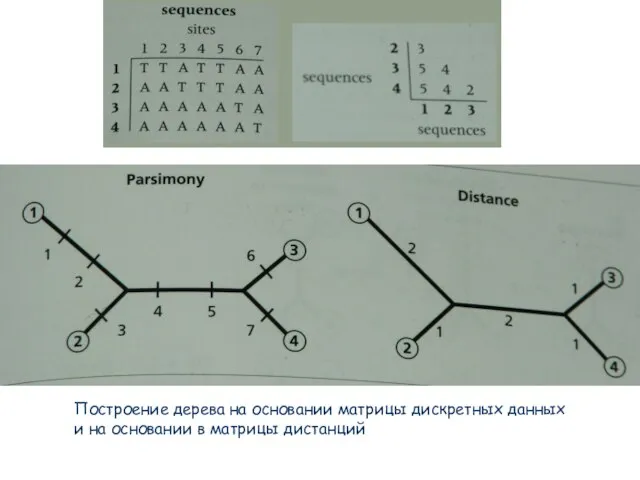
Слайд 68Методы, основанные на алгоритмах кластеризации
Метод ближайшего соседа (Neighbour Joining)
Метод UPGMA (unweighted pair
Методы, основанные на алгоритмах кластеризации
Метод ближайшего соседа (Neighbour Joining)
Метод UPGMA (unweighted pair

Похожие презентации
 Уголовное право. Право в системе социальных норм
Уголовное право. Право в системе социальных норм Что это? Социальная сеть Коллективный блог Сервис вопросов и ответов.
Что это? Социальная сеть Коллективный блог Сервис вопросов и ответов. Felting exhibition(выставка из фетровых изделий)
Felting exhibition(выставка из фетровых изделий)
 Презентация на тему Маленькие открытия в моей большой семье
Презентация на тему Маленькие открытия в моей большой семье Аудит бренда. Шаблон
Аудит бренда. Шаблон Архитектура и основные функции протоколов сети UMTS (часть 10)
Архитектура и основные функции протоколов сети UMTS (часть 10) «Дороги, которые мы выбираем» "ВЫБОР ПРОФЕССИИ МОЖНО СРАВНИТЬ С РЕШЕНИЕМ СЛОЖНОЙ ТВОРЧЕСКОЙ ЗАДАЧИ, ПРИЧЕМ ЗАДАЧИ СО МНОГИМИ НЕИЗВ
«Дороги, которые мы выбираем» "ВЫБОР ПРОФЕССИИ МОЖНО СРАВНИТЬ С РЕШЕНИЕМ СЛОЖНОЙ ТВОРЧЕСКОЙ ЗАДАЧИ, ПРИЧЕМ ЗАДАЧИ СО МНОГИМИ НЕИЗВ Урок _ 5_6
Урок _ 5_6 Ионная связь. Вещества ионного немолекулярного строения
Ионная связь. Вещества ионного немолекулярного строения Берегите здоровье смолоду
Берегите здоровье смолоду Почему протекают химические реакции
Почему протекают химические реакции 7-а вопросы к пар.8 (1)
7-а вопросы к пар.8 (1) Производная и её геометрический смысл
Производная и её геометрический смысл Презентация на тему Предлоги
Презентация на тему Предлоги Электроприборы в быту. Расчёт стоимости электроэнергии.Техника электробезопасности.
Электроприборы в быту. Расчёт стоимости электроэнергии.Техника электробезопасности. Подарок детям
Подарок детям Поиск информации в Интернет (web)
Поиск информации в Интернет (web) NATIONAL TRADITIONS AND CUSTOMS OF MY REGION
NATIONAL TRADITIONS AND CUSTOMS OF MY REGION Создание комфортной среды среди малых городов и исторических поселений. Череповец
Создание комфортной среды среди малых городов и исторических поселений. Череповец Омбудсмен, или уполномоченный по правам ребенка
Омбудсмен, или уполномоченный по правам ребенка Комплексное предложение по видеонаблюдению
Комплексное предложение по видеонаблюдению Management stratуgique
Management stratуgique  Аборты в православии
Аборты в православии Пульты управления. Особенности проектирования и конструирования
Пульты управления. Особенности проектирования и конструирования Презентация на тему "Использование технологии проблемного обучения в процессе преподавания географии" - скачать презентации
Презентация на тему "Использование технологии проблемного обучения в процессе преподавания географии" - скачать презентации Презентация вебинар 2017-04-05
Презентация вебинар 2017-04-05 Фантазия как психиологический термин - продукт воображения
Фантазия как психиологический термин - продукт воображения