- Chapter_2_ooo

Содержание
- 2. Background Required to Understand this Chapter Advanced Computer Architecture. Smruti R. Sarangi http://www.cse.iitd.ac.in/~srsarangi/archbooksoft.html
- 3. Advanced Computer Architecture. Smruti R. Sarangi
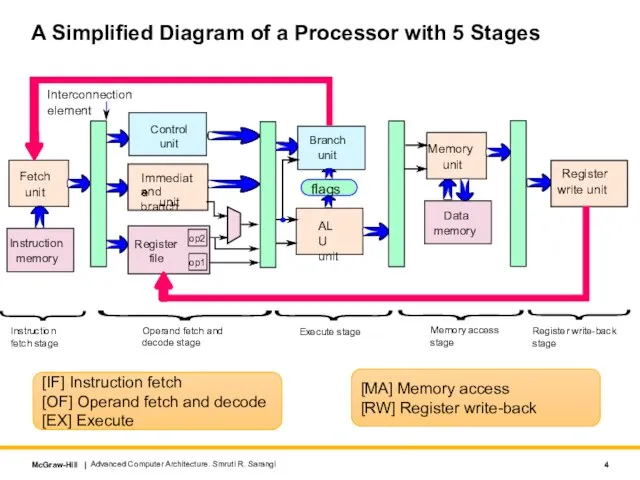
- 4. A Simplified Diagram of a Processor with 5 Stages Advanced Computer Architecture. Smruti R. Sarangi Fetch
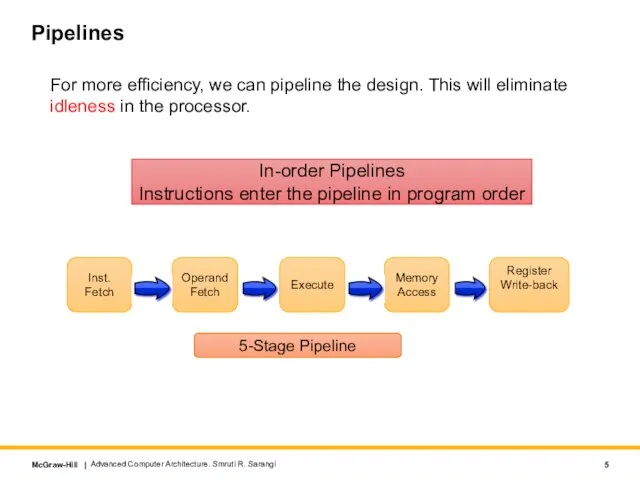
- 5. Pipelines For more efficiency, we can pipeline the design. This will eliminate idleness in the processor.
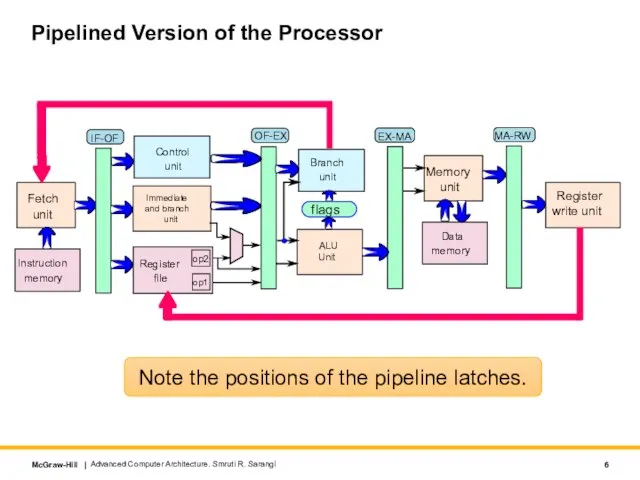
- 6. Pipelined Version of the Processor Advanced Computer Architecture. Smruti R. Sarangi Note the positions of the
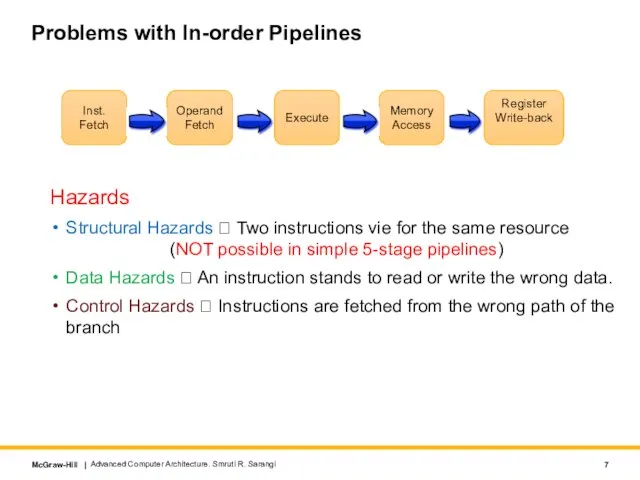
- 7. Problems with In-order Pipelines Hazards Structural Hazards ? Two instructions vie for the same resource (NOT
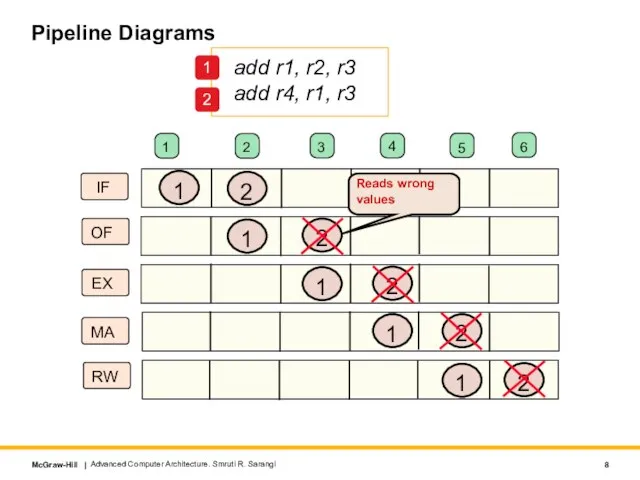
- 8. Pipeline Diagrams Advanced Computer Architecture. Smruti R. Sarangi add r1, r2, r3 add r4, r1, r3
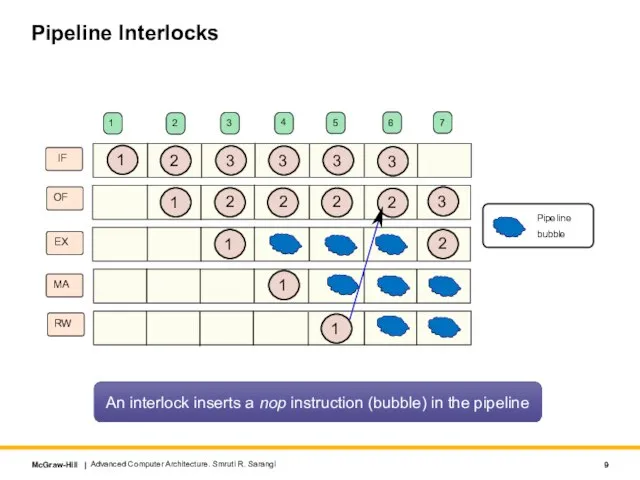
- 9. Pipeline Interlocks Advanced Computer Architecture. Smruti R. Sarangi IF OF EX MA RW 1 1 1
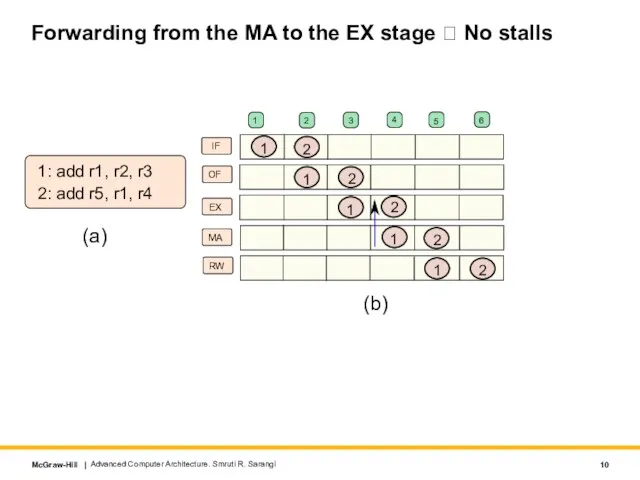
- 10. Forwarding from the MA to the EX stage ? No stalls Advanced Computer Architecture. Smruti R.
- 11. Forwarding Multiplexers Advanced Computer Architecture. Smruti R. Sarangi ALU Latch Memory access unit Forwarded input Input
- 12. We need 4 Forwarding Paths Advanced Computer Architecture. Smruti R. Sarangi Forward as late as possible
- 13. Final View of the Pipelined Processor with Forwarding Multiplexers Advanced Computer Architecture. Smruti R. Sarangi We
- 14. Data Hazards in In-order Pipelines with Forwarding ld r4, 4[r0] add r5, r4, 1 Need the
- 15. Solution: Stall the Pipeline ld r4, 4[r0] add r5, r4, 1 Cycle N Cycle N+1 ld
- 16. Control Hazards beq .label add r1, r2, r3 beq .label sub r5, r6, r7 We know
- 17. Advanced Computer Architecture. Smruti R. Sarangi
- 18. Performance Equation - I Is Computer A faster that Computer B Wrong Answers: More is the
- 19. Performance Equation - II IPC is the number of instructions per cycle Let us loosely refer
- 20. So, what does performance depend on … #instructions in the program Depends on the compiler Frequency
- 21. How to improve performance? There are 3 factors: IPC, #instructions, and frequency #instructions is dependent on
- 22. What about frequency? What is frequency dependent on … Frequency = 1 / clock period Clock
- 23. Limits to Increasing Frequency Assume that we have the fastest possible transistors Can we increase the
- 24. Limits to increasing frequency - II What does it mean to have a very high frequency?
- 25. How many pipeline stages can we have? We are limited by the latch delay Even with
- 26. Pipeline Stages vs IPC CPI = CPIideal + stall_rate * stall_penalty The stall rate will remain
- 27. Summary: Why we cannot increase frequency by increasing the number of pipeline stages? Advanced Computer Architecture.
- 28. Since we cannot increase frequency … Increase IPC Advanced Computer Architecture. Smruti R. Sarangi
- 29. Increase IPC Issue more instructions per cycle 2, 4, or 8 instructions Make it a superscalar
- 30. In-order Superscalar Processor Have multiple in-order pipelines. Inst. Fetch Operand Fetch Execute Memory Access Register Write-back
- 31. In-order Superscalar Processor - II There can be dependences between instructions Have O(n2) forwarding paths for
- 32. Contents Advanced Computer Architecture. Smruti R. Sarangi
- 33. What to do ... Don’t follow program order Too many dependences mov r1, 1 add r3,
- 34. Execute out of order mov r1, 1 add r3, r1, r2 add r4, r3, r2 mov
- 35. Continuation ... mov r1, 1 add r3, r1, r2 add r4, r3, r2 mov r5, 1
- 36. Basic Principle of OOO Processors Advanced Computer Architecture. Smruti R. Sarangi ILP Instruction level parallelism The
- 37. Revisit the Example mov r1, 1 add r3, r1, r2 add r4, r3, r2 mov r5,
- 38. Pool of Instructions: Instruction Window Needs to be large enough such that the requisite number of
- 39. Problems with creating an Instruction Pool Typically 1 in 5 instructions is a branch Predict the
- 40. Advanced Computer Architecture. Smruti R. Sarangi Motivation for Branch Prediction 1 2 3 4 We need
- 41. The Maths of Branch Prediction Advanced Computer Architecture. Smruti R. Sarangi
- 42. Advanced Computer Architecture. Smruti R. Sarangi For (n=100) : A plot of Pn vs p If
- 43. Advanced Computer Architecture. Smruti R. Sarangi If we need a large instruction window, we need a
- 44. Advanced Computer Architecture. Smruti R. Sarangi Nature of Dependences
- 45. Dependences between Instructions Program Order Dependence mov r1, 1 mov r2, 2 One instruction appears after
- 46. Data Dependences RAW ? Read after Write Dependence (True dependence) mov r1, 1 add r3, r1,
- 47. Data Dependences - II WAW ? Write after Write Dependence (Output dependence) mov r1, 1 add
- 48. Data Dependences - III WAR ? Write after Read Dependence (Anti dependence) add r1, r2, r3
- 49. Control Dependences The add instruction is control dependent on the branch(beq) instruction If the branch is
- 50. Basic Results In-order processors respect all program order dependences. Thus, they automatically respect all data and
- 51. Can output and anti dependences be removed? Don’t you think that these dependences are there because
- 52. Solution: Assume infinite number of physical registers mov r1, 1 add r1, r2, r3 add r4,
- 53. Renaming Program with real (architectural) registers Program with physical registers RAW dependences WAR dependences WAW dependences
- 54. Where are we now ... Fetch + Decode + Rename Instruction Memory Pool of Instructions Execution
- 55. Issue with Write-back To an outsider should it matter if the processor is in-order or OOO
- 56. Assume that there is an exception or interrupt Languages like C or Java have dedicated functions
- 57. Precise Exceptions Assume that the exception handler decides to do nothing and return back After this
- 58. Precise Exceptions - II To an external observer The execution should always be correct and as
- 59. Precise Exceptions - III We thus need precise exceptions Assume that the dynamic instructions in a
- 60. Precise Exceptions in an OOO Processor Processor (Out-of-order execution) Register File Memory Update State In program
- 61. Advanced Computer Architecture. Smruti R. Sarangi In-order pipelines have a limited IPC because of hazards and
- 63. Скачать презентацию
Слайд 2Background Required to Understand this Chapter
Advanced Computer Architecture. Smruti R. Sarangi
http://www.cse.iitd.ac.in/~srsarangi/archbooksoft.html
Background Required to Understand this Chapter
Advanced Computer Architecture. Smruti R. Sarangi
http://www.cse.iitd.ac.in/~srsarangi/archbooksoft.html

Слайд 3Advanced Computer Architecture. Smruti R. Sarangi
Advanced Computer Architecture. Smruti R. Sarangi
Слайд 4A Simplified Diagram of a Processor with 5 Stages
Advanced Computer Architecture. Smruti
A Simplified Diagram of a Processor with 5 Stages
Advanced Computer Architecture. Smruti
Слайд 5Pipelines
For more efficiency, we can pipeline the design. This will eliminate idleness
Pipelines
For more efficiency, we can pipeline the design. This will eliminate idleness
Слайд 6Pipelined Version of the Processor
Advanced Computer Architecture. Smruti R. Sarangi
Note the positions
Pipelined Version of the Processor
Advanced Computer Architecture. Smruti R. Sarangi
Note the positions
Слайд 7Problems with In-order Pipelines
Hazards
Structural Hazards ? Two instructions vie for the same
Problems with In-order Pipelines
Hazards
Structural Hazards ? Two instructions vie for the same
Слайд 8Pipeline Diagrams
Advanced Computer Architecture. Smruti R. Sarangi
add r1, r2, r3
add r4,
Pipeline Diagrams
Advanced Computer Architecture. Smruti R. Sarangi
add r1, r2, r3
add r4,
Слайд 9Pipeline Interlocks
Advanced Computer Architecture. Smruti R. Sarangi
IF
OF
EX
MA
RW
1
1
1
1
1
2
2
2
3
3
1
2
3
4
5
6
Pipeline
bubble
3
2
2
3
2
3
7
An interlock inserts a nop
Pipeline Interlocks
Advanced Computer Architecture. Smruti R. Sarangi
IF
OF
EX
MA
RW
1
1
1
1
1
2
2
2
3
3
1
2
3
4
5
6
Pipeline
bubble
3
2
2
3
2
3
7
An interlock inserts a nop
Слайд 10Forwarding from the MA to the EX stage ? No stalls
Advanced Computer
Forwarding from the MA to the EX stage ? No stalls
Advanced Computer
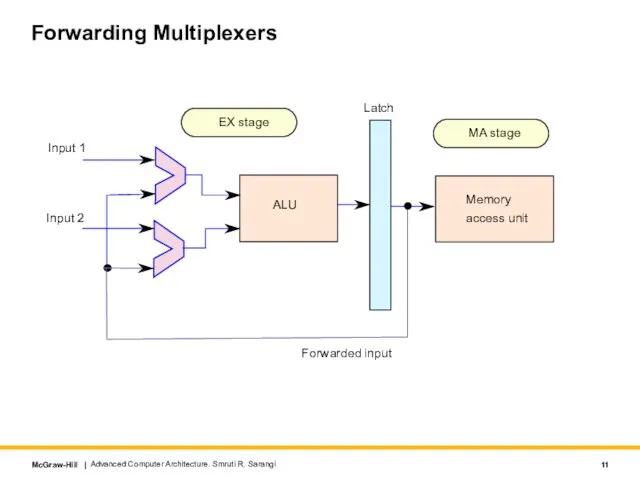
Слайд 11Forwarding Multiplexers
Advanced Computer Architecture. Smruti R. Sarangi
ALU
Latch
Memory
access unit
Forwarded input
Input 1
Input 2
EX
Forwarding Multiplexers
Advanced Computer Architecture. Smruti R. Sarangi
ALU
Latch
Memory
access unit
Forwarded input
Input 1
Input 2
EX
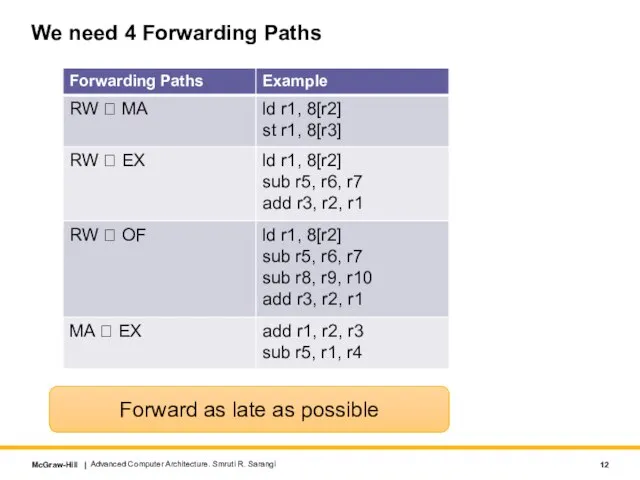
Слайд 12We need 4 Forwarding Paths
Advanced Computer Architecture. Smruti R. Sarangi
Forward as late
We need 4 Forwarding Paths
Advanced Computer Architecture. Smruti R. Sarangi
Forward as late
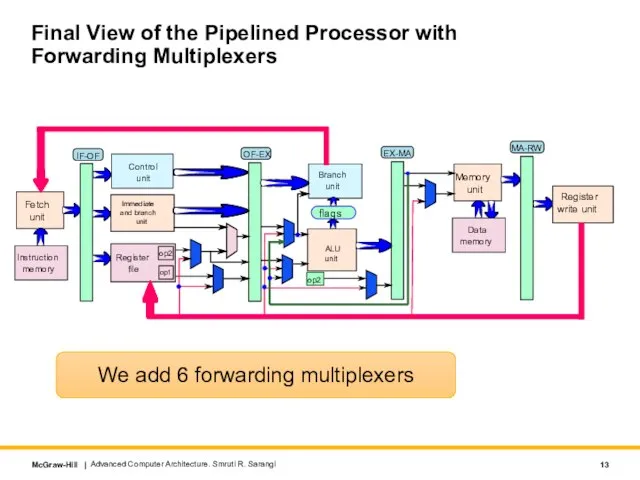
Слайд 13Final View of the Pipelined Processor with Forwarding Multiplexers
Advanced Computer Architecture. Smruti
Final View of the Pipelined Processor with Forwarding Multiplexers
Advanced Computer Architecture. Smruti
Слайд 14Data Hazards in In-order Pipelines with Forwarding
ld r4, 4[r0]
add r5, r4,
Data Hazards in In-order Pipelines with Forwarding
ld r4, 4[r0]
add r5, r4,
![Data Hazards in In-order Pipelines with Forwarding ld r4, 4[r0] add r5,](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/901210/slide-13.jpg)
Слайд 15Solution: Stall the Pipeline
ld r4, 4[r0]
add r5, r4, 1
Cycle N
Cycle N+1
ld
Solution: Stall the Pipeline
ld r4, 4[r0]
add r5, r4, 1
Cycle N
Cycle N+1
ld
![Solution: Stall the Pipeline ld r4, 4[r0] add r5, r4, 1 Cycle](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/901210/slide-14.jpg)
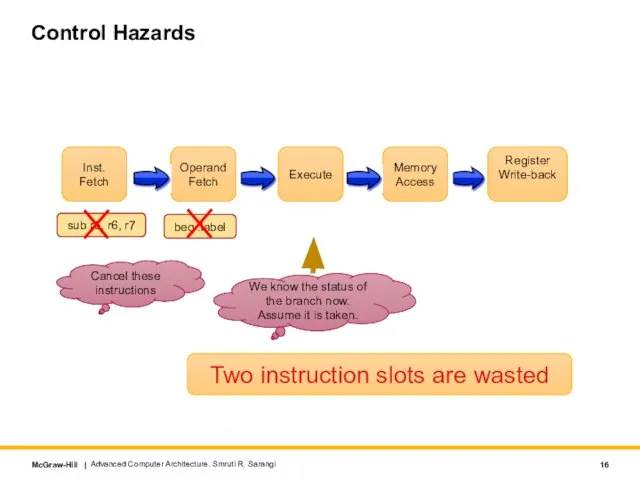
Слайд 16Control Hazards
beq .label
add r1, r2, r3
beq .label
sub r5, r6, r7
We know the
Control Hazards
beq .label
add r1, r2, r3
beq .label
sub r5, r6, r7
We know the
Слайд 17Advanced Computer Architecture. Smruti R. Sarangi
Advanced Computer Architecture. Smruti R. Sarangi

Слайд 18Performance Equation - I
Is Computer A faster that Computer B
Wrong Answers:
More
Performance Equation - I
Is Computer A faster that Computer B
Wrong Answers:
More

Слайд 19Performance Equation - II
IPC is the number of instructions per cycle
Let us
Performance Equation - II
IPC is the number of instructions per cycle
Let us

Слайд 20So, what does performance depend on …
#instructions in the program
Depends on the
So, what does performance depend on …
#instructions in the program
Depends on the
Слайд 21How to improve performance?
There are 3 factors:
IPC, #instructions, and frequency
#instructions
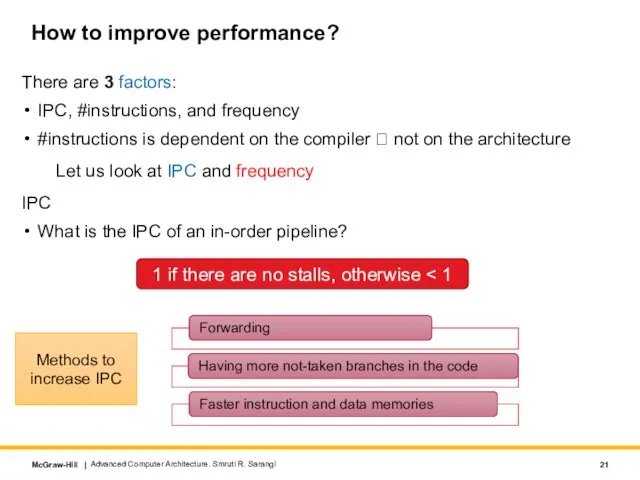
How to improve performance?
There are 3 factors:
IPC, #instructions, and frequency
#instructions
Слайд 22What about frequency?
What is frequency dependent on …
Frequency = 1
What about frequency?
What is frequency dependent on …
Frequency = 1

Слайд 23Limits to Increasing Frequency
Assume that we have the fastest possible transistors
Can we
Limits to Increasing Frequency
Assume that we have the fastest possible transistors
Can we

Слайд 24Limits to increasing frequency - II
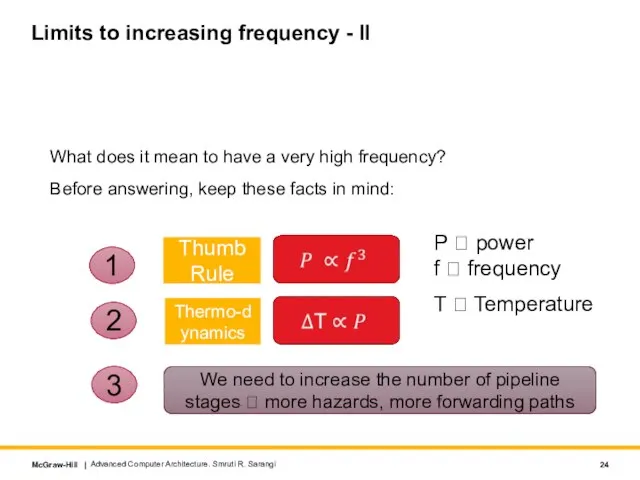
What does it mean to have a
Limits to increasing frequency - II
What does it mean to have a
Слайд 25How many pipeline stages can we have?
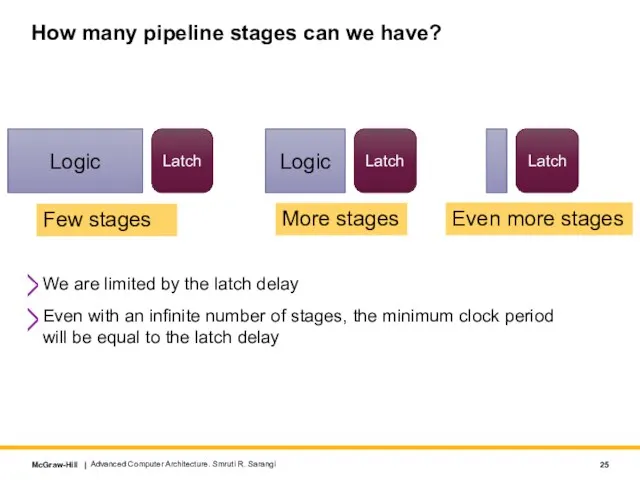
We are limited by the latch
How many pipeline stages can we have?
We are limited by the latch
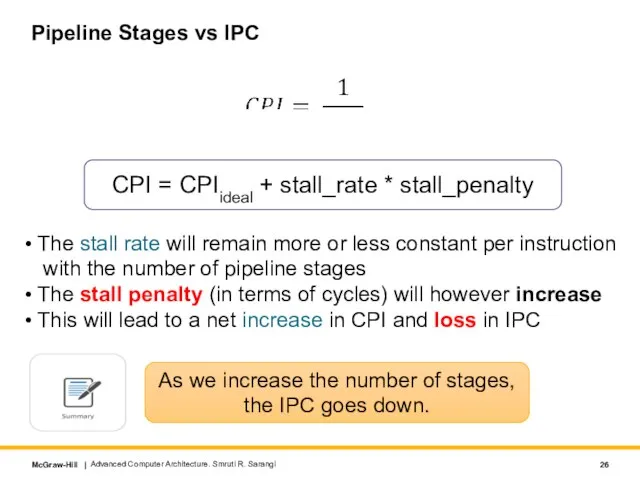
Слайд 26Pipeline Stages vs IPC
CPI = CPIideal + stall_rate * stall_penalty
The stall rate
Pipeline Stages vs IPC
CPI = CPIideal + stall_rate * stall_penalty
The stall rate
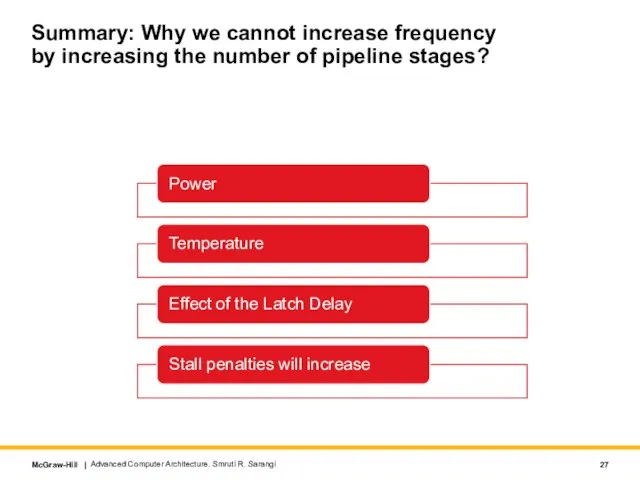
Слайд 27Summary: Why we cannot increase frequency by increasing the number of pipeline
Summary: Why we cannot increase frequency by increasing the number of pipeline
Слайд 28Since we cannot increase frequency …
Increase IPC
Advanced Computer Architecture. Smruti R. Sarangi
Since we cannot increase frequency …
Increase IPC
Advanced Computer Architecture. Smruti R. Sarangi

Слайд 29Increase IPC
Issue more instructions per cycle
2, 4, or 8 instructions
Make it a
Increase IPC
Issue more instructions per cycle
2, 4, or 8 instructions
Make it a

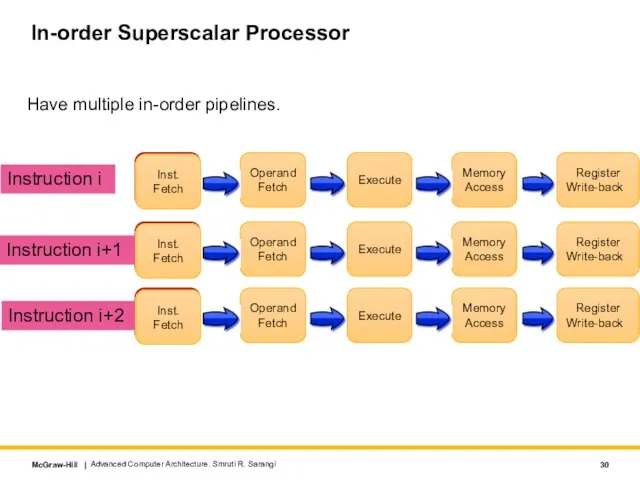
Слайд 30In-order Superscalar Processor
Have multiple in-order pipelines.
Inst. Fetch
Operand Fetch
Execute
Memory
Access
Register
Write-back
Inst. Fetch
Operand Fetch
Execute
Memory
Access
Register
Write-back
Inst. Fetch
Operand
In-order Superscalar Processor
Have multiple in-order pipelines.
Inst. Fetch
Operand Fetch
Execute
Memory
Access
Register
Write-back
Inst. Fetch
Operand Fetch
Execute
Memory
Access
Register
Write-back
Inst. Fetch
Operand
Слайд 31In-order Superscalar Processor - II
There can be dependences between instructions
Have O(n2)
In-order Superscalar Processor - II
There can be dependences between instructions
Have O(n2)

Слайд 32Contents
Advanced Computer Architecture. Smruti R. Sarangi
Contents
Advanced Computer Architecture. Smruti R. Sarangi
Слайд 33What to do ...
Don’t follow program order
Too many dependences
mov r1,
What to do ...
Don’t follow program order
Too many dependences
mov r1,

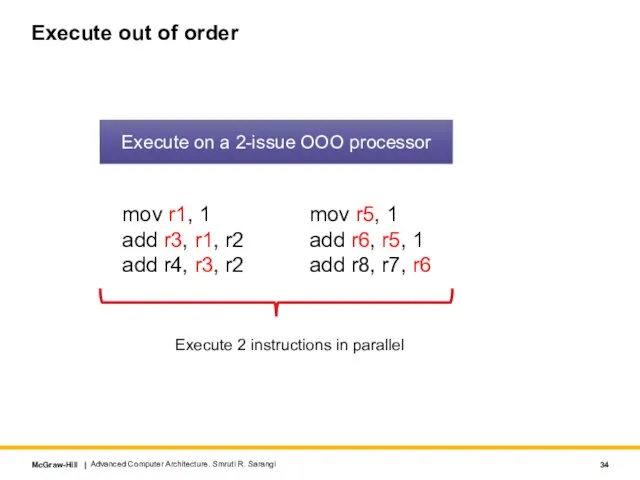
Слайд 34Execute out of order
mov r1, 1
add r3, r1, r2
add r4, r3, r2
mov
Execute out of order
mov r1, 1
add r3, r1, r2
add r4, r3, r2
mov
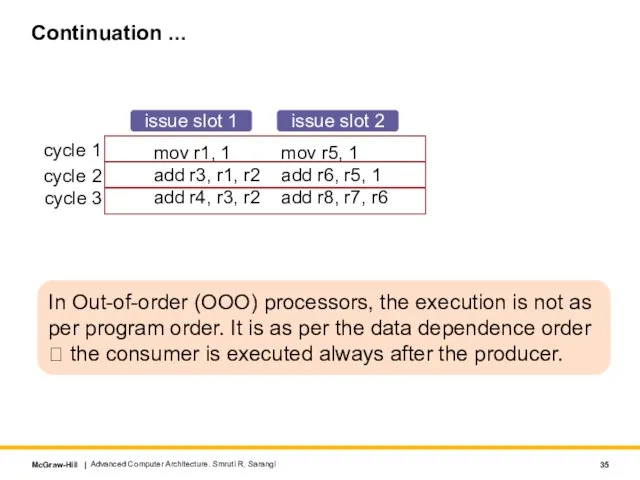
Слайд 35Continuation ...
mov r1, 1
add r3, r1, r2
add r4, r3, r2
mov r5,
Continuation ...
mov r1, 1
add r3, r1, r2
add r4, r3, r2
mov r5,
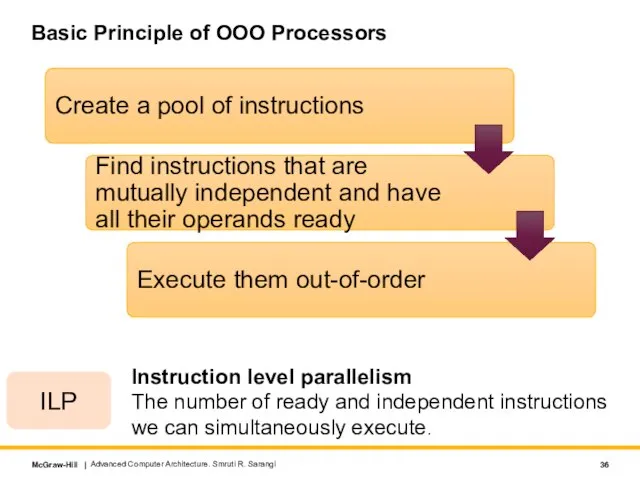
Слайд 36Basic Principle of OOO Processors
Advanced Computer Architecture. Smruti R. Sarangi
ILP
Instruction level parallelism
The
Basic Principle of OOO Processors
Advanced Computer Architecture. Smruti R. Sarangi
ILP
Instruction level parallelism
The
Слайд 37Revisit the Example
mov r1, 1
add r3, r1, r2
add r4, r3, r2
mov r5,
Revisit the Example
mov r1, 1
add r3, r1, r2
add r4, r3, r2
mov r5,

Слайд 38Pool of Instructions: Instruction Window
Needs to be large enough such that the
Pool of Instructions: Instruction Window
Needs to be large enough such that the

Слайд 39Problems with creating an Instruction Pool
Typically 1 in 5 instructions is
Problems with creating an Instruction Pool
Typically 1 in 5 instructions is
Слайд 40Advanced Computer Architecture. Smruti R. Sarangi
Motivation for Branch Prediction
1
2
3
4
We need
high IPC
This
Advanced Computer Architecture. Smruti R. Sarangi
Motivation for Branch Prediction
1
2
3
4
We need
high IPC
This
Слайд 41The Maths of Branch Prediction
Advanced Computer Architecture. Smruti R. Sarangi
The Maths of Branch Prediction
Advanced Computer Architecture. Smruti R. Sarangi

Слайд 42Advanced Computer Architecture. Smruti R. Sarangi
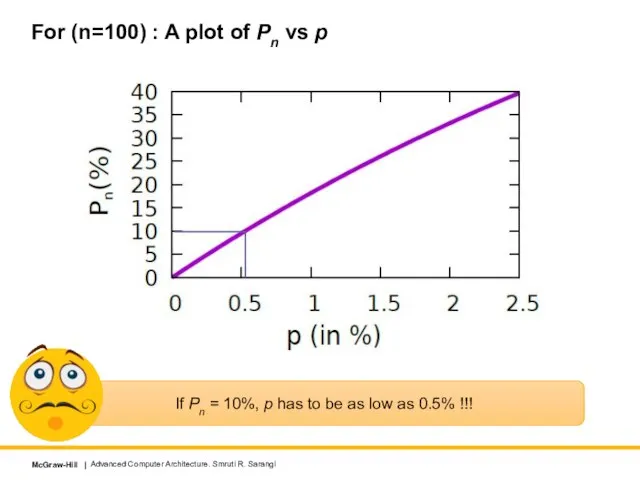
For (n=100) : A plot of Pn
Advanced Computer Architecture. Smruti R. Sarangi
For (n=100) : A plot of Pn
Слайд 43Advanced Computer Architecture. Smruti R. Sarangi
If we need a large instruction window,
Advanced Computer Architecture. Smruti R. Sarangi
If we need a large instruction window,

Слайд 44Advanced Computer Architecture. Smruti R. Sarangi
Nature of Dependences
Advanced Computer Architecture. Smruti R. Sarangi
Nature of Dependences

Слайд 45Dependences between Instructions
Program Order Dependence
mov r1, 1
mov r2, 2
One instruction appears after
Dependences between Instructions
Program Order Dependence
mov r1, 1
mov r2, 2
One instruction appears after

Слайд 46Data Dependences
RAW ? Read after Write Dependence (True dependence)
mov r1, 1
add
Data Dependences
RAW ? Read after Write Dependence (True dependence)
mov r1, 1
add

Слайд 47Data Dependences - II
WAW ? Write after Write Dependence (Output dependence)
mov r1,
Data Dependences - II
WAW ? Write after Write Dependence (Output dependence)
mov r1,

Слайд 48Data Dependences - III
WAR ? Write after Read Dependence (Anti dependence)
add r1,
Data Dependences - III
WAR ? Write after Read Dependence (Anti dependence)
add r1,

Слайд 49Control Dependences
The add instruction is control dependent on the branch(beq) instruction
If the
Control Dependences
The add instruction is control dependent on the branch(beq) instruction
If the

Слайд 50Basic Results
In-order processors respect all program order dependences. Thus, they automatically respect
Basic Results
In-order processors respect all program order dependences. Thus, they automatically respect

Слайд 51Can output and anti dependences be removed?
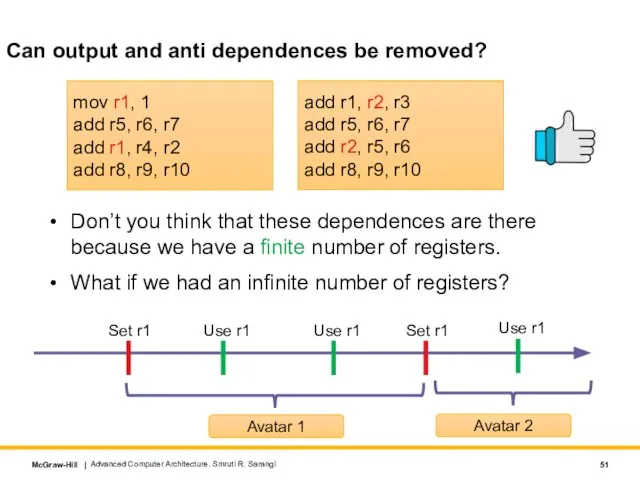
Don’t you think that these dependences
Can output and anti dependences be removed?
Don’t you think that these dependences
Слайд 52Solution: Assume infinite number of physical registers
mov r1, 1
add r1, r2, r3
add
Solution: Assume infinite number of physical registers
mov r1, 1
add r1, r2, r3
add

Слайд 53Renaming
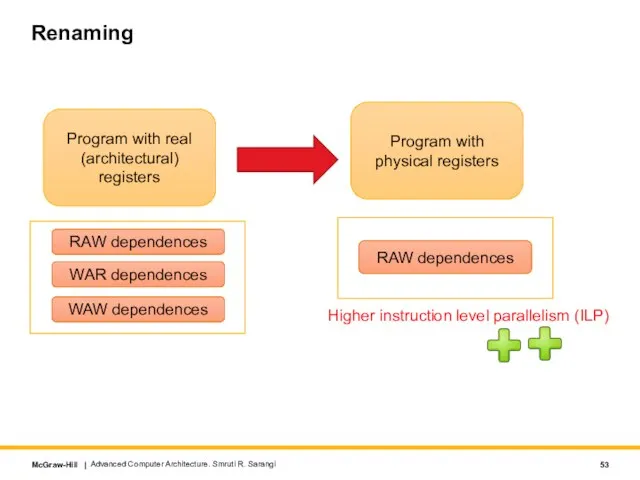
Program with real (architectural) registers
Program with physical registers
RAW dependences
WAR dependences
WAW dependences
RAW dependences
Higher
Renaming
Program with real (architectural) registers
Program with physical registers
RAW dependences
WAR dependences
WAW dependences
RAW dependences
Higher
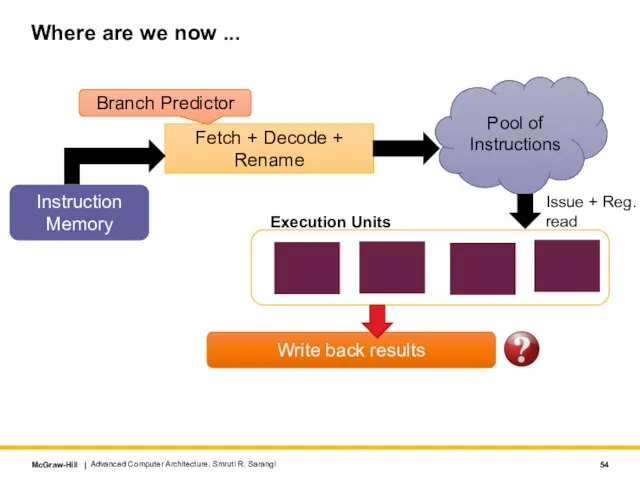
Слайд 54Where are we now ...
Fetch + Decode + Rename
Instruction
Memory
Pool of Instructions
Execution Units
Issue
Where are we now ...
Fetch + Decode + Rename
Instruction
Memory
Pool of Instructions
Execution Units
Issue
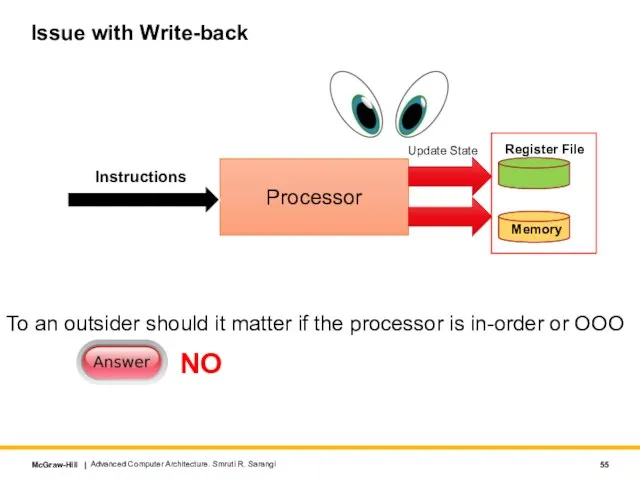
Слайд 55Issue with Write-back
To an outsider should it matter if the processor is
Issue with Write-back
To an outsider should it matter if the processor is
Слайд 56Assume that there is an exception or interrupt
Languages like C or Java
Assume that there is an exception or interrupt
Languages like C or Java

Слайд 57Precise Exceptions
Assume that the exception handler decides to do nothing and return
Precise Exceptions
Assume that the exception handler decides to do nothing and return

Слайд 58Precise Exceptions - II
To an external observer
The execution should always be correct
Precise Exceptions - II
To an external observer
The execution should always be correct

Слайд 59Precise Exceptions - III
We thus need precise exceptions
Assume that the dynamic instructions
Precise Exceptions - III
We thus need precise exceptions
Assume that the dynamic instructions

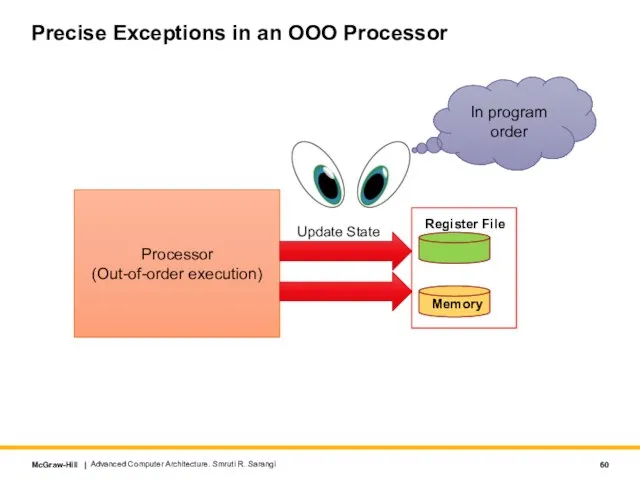
Слайд 60Precise Exceptions in an OOO Processor
Processor
(Out-of-order execution)
Register File
Memory
Update State
In program order
Advanced Computer
Precise Exceptions in an OOO Processor
Processor
(Out-of-order execution)
Register File
Memory
Update State
In program order
Advanced Computer
Слайд 61Advanced Computer Architecture. Smruti R. Sarangi
In-order pipelines have a limited IPC because
of
Advanced Computer Architecture. Smruti R. Sarangi
In-order pipelines have a limited IPC because
of

 Технологии и продукты Microsoft в обеспечении ИБ
Технологии и продукты Microsoft в обеспечении ИБ Как избежать соблазнов
Как избежать соблазнов Использование исследовательской деятельности в начальных классах
Использование исследовательской деятельности в начальных классах По рассказу Александра Грина «Зеленая лампа»
По рассказу Александра Грина «Зеленая лампа» ЗАСТАВКА (1)
ЗАСТАВКА (1) Презентация на тему Гулькевичи - мой родной город
Презентация на тему Гулькевичи - мой родной город Спешите делать добро
Спешите делать добро Психологическое занятие в детском саду с использованием песочной арт-терапии
Психологическое занятие в детском саду с использованием песочной арт-терапии Управлениепроектной деятельностью учащихся(ключевые аспекты)
Управлениепроектной деятельностью учащихся(ключевые аспекты) Харизма в менеджменте
Харизма в менеджменте {
{ Один день из жизни моей мамы
Один день из жизни моей мамы Инвестиционная политика в развитии железнодорожного транспорта в России в различные исторические периоды
Инвестиционная политика в развитии железнодорожного транспорта в России в различные исторические периоды ТИПЫ РЕЧИ
ТИПЫ РЕЧИ ОС Windows Пакет FAR
ОС Windows Пакет FAR Основные результаты исследования влияния антикоррозионных покрытий на несущую способность свайных фундаментов в мерзлых грунтах
Основные результаты исследования влияния антикоррозионных покрытий на несущую способность свайных фундаментов в мерзлых грунтах Формулы сокращенного умножения
Формулы сокращенного умножения Операционные системы
Операционные системы Осенний сюрприз
Осенний сюрприз УСТАНОВКА УПАКОВОЧНАЯ ПОЛУАВТОМАТИЧЕСКАЯ
УСТАНОВКА УПАКОВОЧНАЯ ПОЛУАВТОМАТИЧЕСКАЯ Электродвигатели для горных работ
Электродвигатели для горных работ The Migration Of Russian Scientists
The Migration Of Russian Scientists  Поведение и поступок. 6 класс
Поведение и поступок. 6 класс Презентация на тему Противоположные числа Какие числа называют противоположными? Как на координатной прямой располагаются точк
Презентация на тему Противоположные числа Какие числа называют противоположными? Как на координатной прямой располагаются точк Презентация программы МВА ЛИНК «Стратегия»2009 год
Презентация программы МВА ЛИНК «Стратегия»2009 год муниципальное казённое общеобразовательное учреждение средняя общеобразовательная школа №9 г. Канска
муниципальное казённое общеобразовательное учреждение средняя общеобразовательная школа №9 г. Канска Средневековая наука
Средневековая наука Международное сотрудничество в области управления природоохранной деятельностью
Международное сотрудничество в области управления природоохранной деятельностью