- Data Scientist. Рекомендательные системы

Содержание
- 2. План работы: 1. Постановка задачи, исходные данные и что с ними нужно сделать. 2. Подсчет топ
- 3. Постановка задачи: Нам нужно разработать рекомендательную систему подбора товаров, исходя из индивидуальных особенностей каждого пользователя. Представим
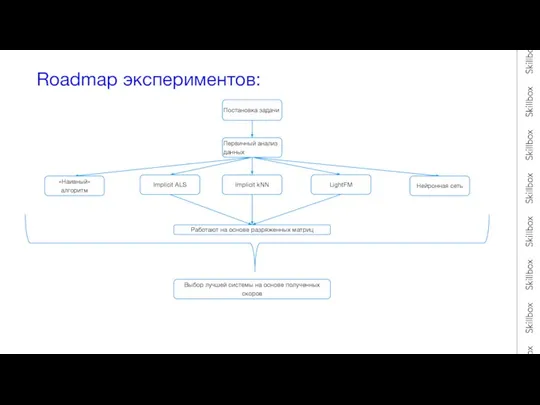
- 4. Roadmap экспериментов: Постановка задачи «Наивный» алгоритм Implicit ALS Implicit kNN LightFM Работают на основе разряженных матриц
- 5. Разбор алгоритмов: 2. Implicit ALS (Alternating Least Squares) Хорошая удобная библиотека, главная фишка заключается в том,
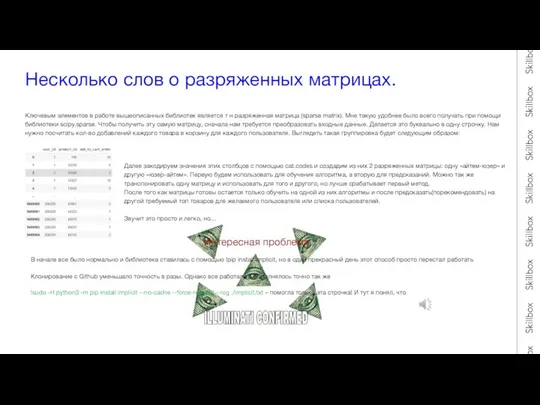
- 6. Несколько слов о разряженных матрицах. Ключевым элементов в работе вышеописанных библиотек является т н разряженная матрица
- 7. Алгоритм на основе нейронной сети. В качестве вишенки на торте и чего-то по-настоящему рабочего было решено
- 8. Архитектура нейросети: 2 входа отдельно для продуктовых и пользовательских признаков Превращаем данные в одномерный тензор Объединение
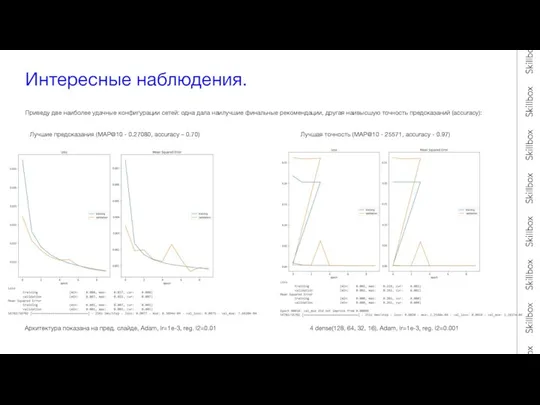
- 9. Интересные наблюдения. Приведу две наиболее удачные конфигурации сетей: одна дала наилучшие финальные рекомендации, другая наивысшую точность
- 10. Некоторые технические моменты. Вид итогового датафрейма, отсортированного по величине выхода сигмоиды: Как дополнялись предсказания: Набор списка
- 12. Скачать презентацию

Слайд 3Постановка задачи:
Нам нужно разработать рекомендательную систему подбора товаров, исходя из индивидуальных особенностей
каждого
Постановка задачи:
Нам нужно разработать рекомендательную систему подбора товаров, исходя из индивидуальных особенностей
каждого

Слайд 4Roadmap экспериментов:
Постановка задачи
«Наивный» алгоритм
Implicit ALS
Implicit kNN
LightFM
Работают на основе разряженных матриц
Первичный анализ данных
Нейронная
Roadmap экспериментов:
Постановка задачи
«Наивный» алгоритм
Implicit ALS
Implicit kNN
LightFM
Работают на основе разряженных матриц
Первичный анализ данных
Нейронная
Слайд 5Разбор алгоритмов:
2. Implicit ALS (Alternating Least Squares)
Хорошая удобная библиотека, главная фишка заключается
Разбор алгоритмов:
2. Implicit ALS (Alternating Least Squares)
Хорошая удобная библиотека, главная фишка заключается

Слайд 6Несколько слов о разряженных матрицах.
Ключевым элементов в работе вышеописанных библиотек является т
Несколько слов о разряженных матрицах.
Ключевым элементов в работе вышеописанных библиотек является т
Слайд 7Алгоритм на основе нейронной сети.
В качестве вишенки на торте и чего-то по-настоящему
Алгоритм на основе нейронной сети.
В качестве вишенки на торте и чего-то по-настоящему

Слайд 8Архитектура нейросети:
2 входа отдельно для продуктовых и пользовательских признаков
Превращаем данные в одномерный
Архитектура нейросети:
2 входа отдельно для продуктовых и пользовательских признаков
Превращаем данные в одномерный

Слайд 9Интересные наблюдения.
Приведу две наиболее удачные конфигурации сетей: одна дала наилучшие финальные рекомендации,
Интересные наблюдения.
Приведу две наиболее удачные конфигурации сетей: одна дала наилучшие финальные рекомендации,
Слайд 10Некоторые технические моменты.
Вид итогового датафрейма, отсортированного по величине выхода сигмоиды:
Как дополнялись предсказания:
Набор
Некоторые технические моменты.
Вид итогового датафрейма, отсортированного по величине выхода сигмоиды:
Как дополнялись предсказания:
Набор

 Русская изба
Русская изба Tema_1_7_Svoboda_i_neobkhodimost_v_chelovecheskoy_deyatelnosti
Tema_1_7_Svoboda_i_neobkhodimost_v_chelovecheskoy_deyatelnosti Сети мелкого и глубокого заложения
Сети мелкого и глубокого заложения WHO and HHS/CDC Prevention of Mother-to-Child Transmission of HIV (PMTCT) Generic Training Package Components Module 8: Safety and Supportive Care in the Work Environment Комплект учебно-методических матер
WHO and HHS/CDC Prevention of Mother-to-Child Transmission of HIV (PMTCT) Generic Training Package Components Module 8: Safety and Supportive Care in the Work Environment Комплект учебно-методических матер Нормативы градостроительного проектирования
Нормативы градостроительного проектирования Презентация на тему Кембриджский университет
Презентация на тему Кембриджский университет Презентация на тему Великие о математике
Презентация на тему Великие о математике  Творческий отчет учителя начальных классов МОУ СОШ № 2 п. Редкино Поляковой Елены Анатольевны
Творческий отчет учителя начальных классов МОУ СОШ № 2 п. Редкино Поляковой Елены Анатольевны Экосистема аквариума
Экосистема аквариума ПРОБЛЕМЫ ВЫБОРА ЛЕКАРСТВЕННЫХ СРЕДСТВ (ОРИГИНАЛЬНЫЕ И ВОСПРОИЗВЕДЕННЫЕ ПРЕПАРАТЫ)
ПРОБЛЕМЫ ВЫБОРА ЛЕКАРСТВЕННЫХ СРЕДСТВ (ОРИГИНАЛЬНЫЕ И ВОСПРОИЗВЕДЕННЫЕ ПРЕПАРАТЫ) Равнобедренный треугольник (готова)
Равнобедренный треугольник (готова) Логистический центр
Логистический центр Воспитание экологической культуры школьников
Воспитание экологической культуры школьников Государственная политика в дополнительном образовании в России и мире
Государственная политика в дополнительном образовании в России и мире Сергей Литовченко Исполнительный директор Ассоциации Менеджеров
Сергей Литовченко Исполнительный директор Ассоциации Менеджеров  Общее определение характера. Биологические предпосылки и формирование характера. Типологии характеров
Общее определение характера. Биологические предпосылки и формирование характера. Типологии характеров Составители: Балдина Ирина Владимировна, заместитель директора Центра дополнительного образования для детей "Юность" г. Бе
Составители: Балдина Ирина Владимировна, заместитель директора Центра дополнительного образования для детей "Юность" г. Бе Взгляд на Великую Отечественную Войну из кино.
Взгляд на Великую Отечественную Войну из кино. Чек-листы для адаптации первокурсников к новой среде
Чек-листы для адаптации первокурсников к новой среде Фантом для занятий.
Фантом для занятий. Детокс. Упражнения и дыхание
Детокс. Упражнения и дыхание Тренажер "Морское путешествие". Правописание префиксов "пре-" и "при-"
Тренажер "Морское путешествие". Правописание префиксов "пре-" и "при-" Грачёв, Штоль, Шульга 41Арх. Экскаваторы радиального копания
Грачёв, Штоль, Шульга 41Арх. Экскаваторы радиального копания Движущие силы эволюции. Борьба за существование
Движущие силы эволюции. Борьба за существование 23 февраля в начальной школе
23 февраля в начальной школе Сервис «Аналитика сделок» Стартап Афиша http://startupafisha.ru
Сервис «Аналитика сделок» Стартап Афиша http://startupafisha.ru Сетевые образовательные программы
Сетевые образовательные программы Презентация на тему Мари-Анри Бейль
Презентация на тему Мари-Анри Бейль