- Document Object Model

Содержание
- 2. DOM DOM (от англ. Document Object Model — «объектная модель документа») — это не зависящий от
- 3. DOM Модель DOM не налагает ограничений на структуру документа. Любой документ известной структуры с помощью DOM
- 4. Традиционный DOM JavaScript был выпущен Netscape Communications в 1996 году в рамках Netscape Navigator 2.0. Конкурент
- 5. Традиционный DOM Традиционный DOM был ограничен в типах элементов, к которым можно получить доступ. Такие элементы,
- 6. Промежуточный DOM В 1997 году Netscape и Microsoft выпустили Netscape Navigator и Internet Explorer версии 4.0,
- 7. Промежуточный DOM Промежуточные DOM давали возможность манипуляции свойствами Cascading Style Sheets (CSS), которые воздействуют на отображение
- 8. Стандартизация Организация World Wide Web Consortium (W3C), основанная в 1994 году, чтобы развивать и поддерживать открытые
- 9. Стандартизация DOM уровень 2 был опубликован в конце 2000 года. Он ввел функцию "getElementById", а также
- 10. Обработка XML-данных с использованием модели DOM Модель DOM рассматривает XML-данные как стандартный набор объектов и используется
- 11. Обработка XML-данных с использованием модели DOM Класс XmlDocument представляет XML-документ. Он включает элементы для получения и
- 12. Модель DOM для XML Класс XML DOM является представлением XML-документа в памяти. Модель DOM позволяет читать,
- 13. Модель DOM для XML Carson 31.95 05/01/2001 MSPress WA
- 14. Модель DOM для XML Далее показано, какая структура будет создана в памяти, когда эти XML-данные считываются
- 15. Структура XML-документа
- 16. Модель DOM для XML Каждый круг в данной иллюстрации представляет собой узел в структуре XML-документа, называемый
- 17. Модель DOM для XML Кроме того, XmlDocument предоставляет возможности для просмотра узлов всего XML-документа и выполнения
- 18. Модель DOM для XML Объекты Node обладают набором методов и свойств, а также базовых, хорошо определенных
- 19. Модель DOM для XML Узлы XmlDeclaration, Notation, Entity, CDATASection, Text, Comment, ProcessingInstruction и DocumentType не могут
- 20. Модель DOM для XML Одна из характеристик модели DOM — способ обработки атрибутов.Атрибуты не являются узлами,
- 21. Модель DOM для XML По мере считывания XML-документа в память создаются узлы.Узлы бывают разных типов.Правила и
- 22. Модель DOM для XML Модель DOM чрезвычайно полезна для считывания XML-данных в память, изменения их структуры,
- 23. Типы XML-узлов Когда XML-документ считывается в память в виде дерева узлов, типы для узлов выбираются во
- 24. Типы XML-узлов
- 25. Типы XML-узлов
- 26. Типы XML-узлов В следующей таблице показаны дополнительные типы узлов, которые не определены консорциумом W3C, но доступны
- 27. Типы XML-узлов
- 28. Обработка XML Понятие обработка означает обработку информации, что включает ввод, проверку, организацию, хранение, поиск, преобразование и
- 29. DOM как структура Прежде, чем начинать работу с DOM, стоит получить представление о том, что она
- 30. DOM как структура Для исключительно больших документов разбор и загрузка полного документа может быть медленной и
- 31. Карта DOM
- 32. DOM как структура Работа с DOM затрагивает несколько концепций, которые работают вместе. Вы изучите отношения между
- 33. DOM как API Начиная с DOM Уровня 1, DOM API содержит интерфейсы, которые представляют всевозможные типы
- 34. DOM как API Поддержка пространств была добавлена в DOM Уровня 2. Уровень 2 расширяет Уровень 1,
- 35. Базовый XML-файл Примеры во всем этом учебнике используют XML-файл, который содержит приведенный ниже пример кода, представляющий
- 36. Базовый XML-файл 12341 pending Silver Show Saddle, 16 inch 825.00 1 Premium Cinch 49.00 1 251222
- 37. Базовый XML-файл Примеры во всем этом учебнике используют XML-файл, который содержит приведенный ниже пример кода, представляющий
- 38. Базовый XML-файл В DOM работа с XML-информацией означает разбиение ее сначала по узлам.
- 39. Различные типы узлов XML Создание иерархии DOM, в сущности, является коллекцией узлов. При том, что в
- 40. Различные типы узлов XML
- 41. Различные типы узлов XML Различие между элементами и узлами Фактически, элементы являются только одним типом узлов,
- 42. Различные типы узлов XML
- 43. Различные типы узлов XML Прямоугольники представляют элементные узлы, а овалы представляют текстовые узлы. Если один узел
- 44. Базовые типы узлов: документ, элемент, атрибут и текст Наиболее распространенными типами узлов в XML являются: Элементы:
- 45. Менее распространенные типы узлов Другие типы узлов используются не так часто, но все равно важны в
- 46. Менее распространенные типы узлов Комментарии: Комментарии включают в себя информацию о данных и обычно игнорируются приложением.
- 47. Менее распространенные типы узлов Фрагменты документа: Чтобы быть правильно форматированным, документ должен иметь только один корневой
- 48. Пространства имен Что такое пространство имен? Одно из главных усовершенствований между DOM Уровня 1 и DOM
- 49. Пространства имен С другой стороны, если я нахожусь вне офиса, и она делает такое же заявление,
- 50. Создание пространства имен Поскольку идентификаторы для пространств имен должны быть уникальными, они обозначаются при помощи Унифицированных
- 51. Создание пространства имен Любые элементы, для которых не указано пространство имен, находятся в пространстве имен по
- 52. Определение пространств имен Для данных могут быть определены также и другие пространства имен. Например, созданием пространства
- 53. Определение пространств имен Рассмотрим код, приведенный ниже. Пространство имен и алиас, rating, использованы для создания элемента
- 54. Разбор файла в документ Трехшаговый процесс Чтобы работать с информацией в XML-файле, файл должен быть разобран
- 55. Базовое приложение Начнем с создания базового приложения, класса с именем OrderProcessor. import javax.xml.parsers.DocumentBuilder; import javax.xml.parsers.DocumentBuilderFactory; import
- 56. Разбор файла в документ Сначала Java-код импортирует необходимые классы, а затем создает приложение OrderProcessor. Примеры в
- 57. Установки парсера Одно из преимуществ создания парсеров при помощи DocumentBuilder состоит в управлении различными установками парсера,
- 58. Разбор файла в документ Java-реализация DOM Уровня 2 обеспечивает управление параметрами парсера через следующие методы: setCoalescing():
- 59. Редактирование документа Просмотр содержимого XML-документ полезен, но когда вы имеете дело с полнофункциональным приложением, вам может
- 60. Редактирование документа Метод changeOrder() вызывается с передачей ему начального узла (root) в качестве параметра, а также
- 61. Редактирование документа В противном случае приложение проверяет каждый потомок так же, как это делалось при прохождении
- 62. Добавление узлов: подготовка данных Иногда необходимо не изменить существующий узел, а добавить узел, и у вас
- 64. Скачать презентацию
Слайд 2DOM
DOM (от англ. Document Object Model — «объектная модель документа») — это не зависящий от платформы и
DOM
DOM (от англ. Document Object Model — «объектная модель документа») — это не зависящий от платформы и

Слайд 3DOM
Модель DOM не налагает ограничений на структуру документа. Любой документ известной структуры
DOM
Модель DOM не налагает ограничений на структуру документа. Любой документ известной структуры

Слайд 4Традиционный DOM
JavaScript был выпущен Netscape Communications в 1996 году в рамках Netscape Navigator 2.0.
Традиционный DOM
JavaScript был выпущен Netscape Communications в 1996 году в рамках Netscape Navigator 2.0.

Слайд 5Традиционный DOM
Традиционный DOM был ограничен в типах элементов, к которым можно получить
Традиционный DOM
Традиционный DOM был ограничен в типах элементов, к которым можно получить

Слайд 6Промежуточный DOM
В 1997 году Netscape и Microsoft выпустили Netscape Navigator и Internet
Промежуточный DOM
В 1997 году Netscape и Microsoft выпустили Netscape Navigator и Internet

Слайд 7Промежуточный DOM
Промежуточные DOM давали возможность манипуляции свойствами Cascading Style Sheets (CSS), которые воздействуют на
Промежуточный DOM
Промежуточные DOM давали возможность манипуляции свойствами Cascading Style Sheets (CSS), которые воздействуют на

Слайд 8Стандартизация
Организация World Wide Web Consortium (W3C), основанная в 1994 году, чтобы развивать и поддерживать
Стандартизация
Организация World Wide Web Consortium (W3C), основанная в 1994 году, чтобы развивать и поддерживать

Слайд 9Стандартизация
DOM уровень 2 был опубликован в конце 2000 года. Он ввел функцию
Стандартизация
DOM уровень 2 был опубликован в конце 2000 года. Он ввел функцию

Слайд 10Обработка XML-данных с использованием модели DOM
Модель DOM рассматривает XML-данные как стандартный набор
Обработка XML-данных с использованием модели DOM
Модель DOM рассматривает XML-данные как стандартный набор

Слайд 11Обработка XML-данных с использованием модели DOM
Класс XmlDocument представляет XML-документ. Он включает элементы для получения и
Обработка XML-данных с использованием модели DOM
Класс XmlDocument представляет XML-документ. Он включает элементы для получения и

Слайд 12Модель DOM для XML
Класс XML DOM является представлением XML-документа в памяти. Модель DOM
Модель DOM для XML
Класс XML DOM является представлением XML-документа в памяти. Модель DOM

Слайд 13Модель DOM для XML
Carson
31.95
05/01/2001
Модель DOM для XML

Слайд 14Модель DOM для XML
Далее показано, какая структура будет создана в памяти, когда
Модель DOM для XML
Далее показано, какая структура будет создана в памяти, когда

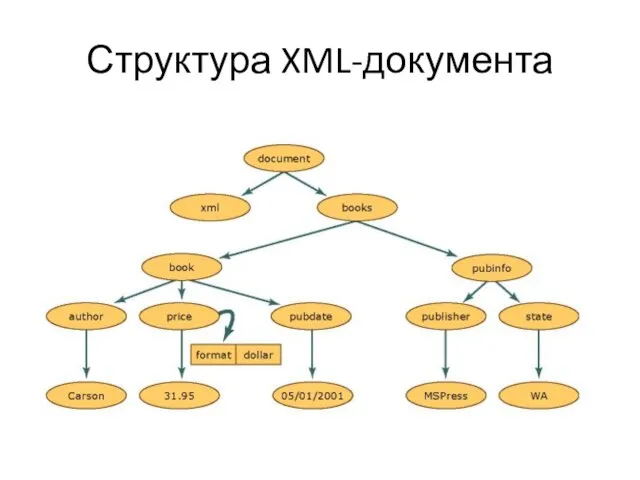
Слайд 15Структура XML-документа
Структура XML-документа
Слайд 16Модель DOM для XML
Каждый круг в данной иллюстрации представляет собой узел в
Модель DOM для XML
Каждый круг в данной иллюстрации представляет собой узел в

Слайд 17Модель DOM для XML
Кроме того, XmlDocument предоставляет возможности для просмотра узлов всего XML-документа и
Модель DOM для XML
Кроме того, XmlDocument предоставляет возможности для просмотра узлов всего XML-документа и

Слайд 18Модель DOM для XML
Объекты Node обладают набором методов и свойств, а также базовых, хорошо
Модель DOM для XML
Объекты Node обладают набором методов и свойств, а также базовых, хорошо

Слайд 19Модель DOM для XML
Узлы XmlDeclaration, Notation, Entity, CDATASection, Text, Comment, ProcessingInstruction и DocumentType не могут иметь дочерних узлов.
Узлы, находящиеся на одном уровне,
Модель DOM для XML
Узлы XmlDeclaration, Notation, Entity, CDATASection, Text, Comment, ProcessingInstruction и DocumentType не могут иметь дочерних узлов.
Узлы, находящиеся на одном уровне,

Слайд 20Модель DOM для XML
Одна из характеристик модели DOM — способ обработки атрибутов.Атрибуты
Модель DOM для XML
Одна из характеристик модели DOM — способ обработки атрибутов.Атрибуты

Слайд 21Модель DOM для XML
По мере считывания XML-документа в память создаются узлы.Узлы бывают
Модель DOM для XML
По мере считывания XML-документа в память создаются узлы.Узлы бывают

Слайд 22Модель DOM для XML
Модель DOM чрезвычайно полезна для считывания XML-данных в память,
Модель DOM для XML
Модель DOM чрезвычайно полезна для считывания XML-данных в память,

Слайд 23Типы XML-узлов
Когда XML-документ считывается в память в виде дерева узлов, типы для
Типы XML-узлов
Когда XML-документ считывается в память в виде дерева узлов, типы для

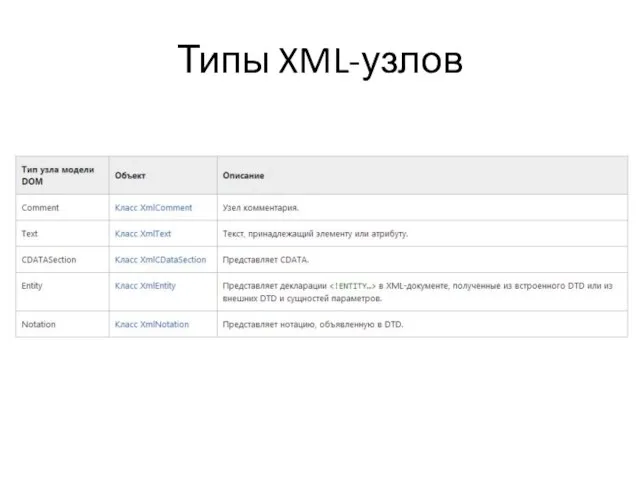
Слайд 24Типы XML-узлов
Типы XML-узлов

Слайд 25Типы XML-узлов
Типы XML-узлов
Слайд 26Типы XML-узлов
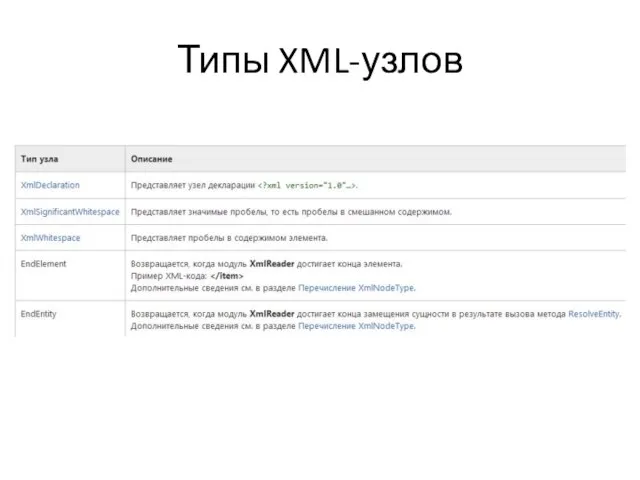
В следующей таблице показаны дополнительные типы узлов, которые не определены консорциумом
Типы XML-узлов
В следующей таблице показаны дополнительные типы узлов, которые не определены консорциумом

Слайд 27Типы XML-узлов
Типы XML-узлов
Слайд 28Обработка XML
Понятие обработка означает обработку информации, что включает ввод, проверку, организацию, хранение, поиск, преобразование и извлечение
Обработка XML
Понятие обработка означает обработку информации, что включает ввод, проверку, организацию, хранение, поиск, преобразование и извлечение

Слайд 29DOM как структура
Прежде, чем начинать работу с DOM, стоит получить представление о
DOM как структура
Прежде, чем начинать работу с DOM, стоит получить представление о

Слайд 30DOM как структура
Для исключительно больших документов разбор и загрузка полного документа может
DOM как структура
Для исключительно больших документов разбор и загрузка полного документа может

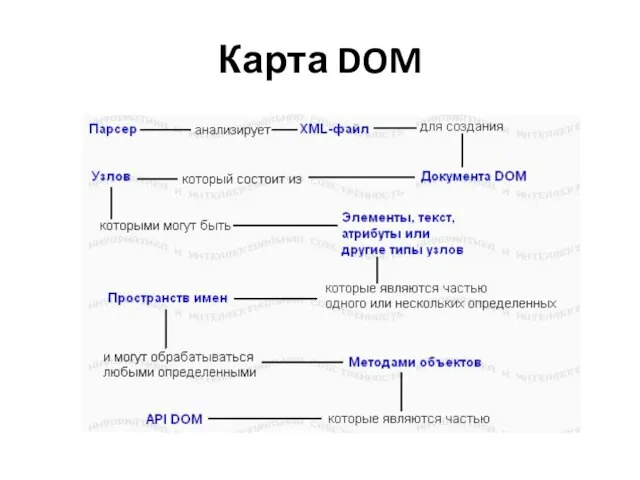
Слайд 31Карта DOM
Карта DOM
Слайд 32DOM как структура
Работа с DOM затрагивает несколько концепций, которые работают вместе. Вы
DOM как структура
Работа с DOM затрагивает несколько концепций, которые работают вместе. Вы

Слайд 33DOM как API
Начиная с DOM Уровня 1, DOM API содержит интерфейсы, которые
DOM как API
Начиная с DOM Уровня 1, DOM API содержит интерфейсы, которые

Слайд 34DOM как API
Поддержка пространств была добавлена в DOM Уровня 2. Уровень 2
DOM как API
Поддержка пространств была добавлена в DOM Уровня 2. Уровень 2

Слайд 35Базовый XML-файл
Примеры во всем этом учебнике используют XML-файл, который содержит приведенный ниже
Базовый XML-файл
Примеры во всем этом учебнике используют XML-файл, который содержит приведенный ниже

Слайд 36Базовый XML-файл
12341
Базовый XML-файл

Слайд 37Базовый XML-файл
Примеры во всем этом учебнике используют XML-файл, который содержит приведенный ниже
Базовый XML-файл
Примеры во всем этом учебнике используют XML-файл, который содержит приведенный ниже

Слайд 38Базовый XML-файл
В DOM работа с XML-информацией означает разбиение ее сначала по узлам.
Базовый XML-файл
В DOM работа с XML-информацией означает разбиение ее сначала по узлам.

Слайд 39Различные типы узлов XML
Создание иерархии
DOM, в сущности, является коллекцией узлов. При том,
Различные типы узлов XML
Создание иерархии
DOM, в сущности, является коллекцией узлов. При том,

Слайд 40Различные типы узлов XML
Различные типы узлов XML
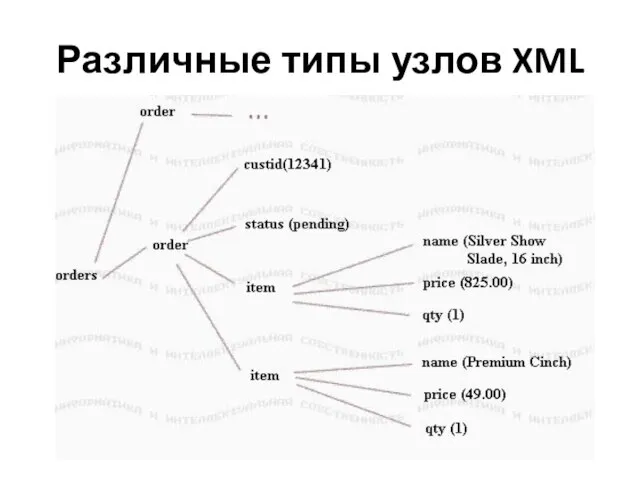
Слайд 41Различные типы узлов XML
Различие между элементами и узлами
Фактически, элементы являются только одним
Различные типы узлов XML
Различие между элементами и узлами
Фактически, элементы являются только одним

Слайд 42Различные типы узлов XML
Различные типы узлов XML
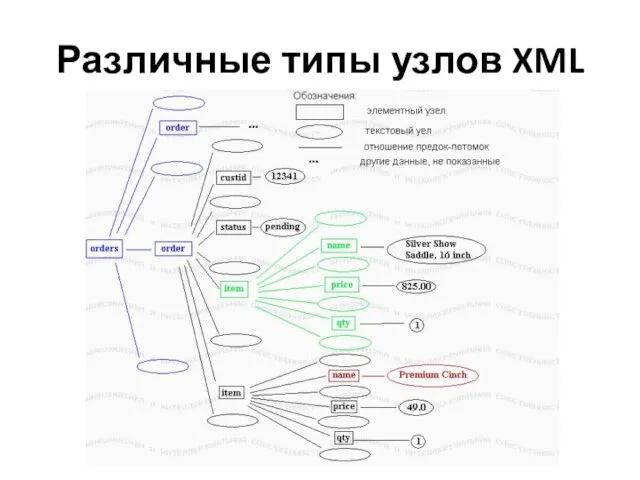
Слайд 43Различные типы узлов XML
Прямоугольники представляют элементные узлы, а овалы представляют текстовые узлы. Если
Различные типы узлов XML
Прямоугольники представляют элементные узлы, а овалы представляют текстовые узлы. Если

Слайд 44Базовые типы узлов: документ, элемент, атрибут и текст
Наиболее распространенными типами узлов в
Базовые типы узлов: документ, элемент, атрибут и текст
Наиболее распространенными типами узлов в

Слайд 45Менее распространенные типы узлов
Другие типы узлов используются не так часто, но все
Менее распространенные типы узлов
Другие типы узлов используются не так часто, но все

Слайд 46Менее распространенные типы узлов
Комментарии: Комментарии включают в себя информацию о данных и
Менее распространенные типы узлов
Комментарии: Комментарии включают в себя информацию о данных и

Слайд 47Менее распространенные типы узлов
Фрагменты документа: Чтобы быть правильно форматированным, документ должен иметь только
Менее распространенные типы узлов
Фрагменты документа: Чтобы быть правильно форматированным, документ должен иметь только

Слайд 48Пространства имен
Что такое пространство имен?
Одно из главных усовершенствований между DOM Уровня 1
Пространства имен
Что такое пространство имен?
Одно из главных усовершенствований между DOM Уровня 1

Слайд 49Пространства имен
С другой стороны, если я нахожусь вне офиса, и она делает
Пространства имен
С другой стороны, если я нахожусь вне офиса, и она делает

Слайд 50Создание пространства имен
Поскольку идентификаторы для пространств имен должны быть уникальными, они обозначаются
Создание пространства имен
Поскольку идентификаторы для пространств имен должны быть уникальными, они обозначаются

Слайд 51Создание пространства имен
Любые элементы, для которых не указано пространство имен, находятся в
Создание пространства имен
Любые элементы, для которых не указано пространство имен, находятся в

Слайд 52Определение пространств имен
Для данных могут быть определены также и другие пространства имен.
Определение пространств имен
Для данных могут быть определены также и другие пространства имен.

Слайд 53Определение пространств имен
Рассмотрим код, приведенный ниже. Пространство имен и алиас, rating, использованы для
Определение пространств имен
Рассмотрим код, приведенный ниже. Пространство имен и алиас, rating, использованы для

Слайд 54Разбор файла в документ
Трехшаговый процесс
Чтобы работать с информацией в XML-файле, файл должен
Разбор файла в документ
Трехшаговый процесс
Чтобы работать с информацией в XML-файле, файл должен

Слайд 55Базовое приложение
Начнем с создания базового приложения, класса с именем OrderProcessor.
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import
Базовое приложение
Начнем с создания базового приложения, класса с именем OrderProcessor.
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import

Слайд 56Разбор файла в документ
Сначала Java-код импортирует необходимые классы, а затем создает приложение OrderProcessor.
Разбор файла в документ
Сначала Java-код импортирует необходимые классы, а затем создает приложение OrderProcessor.

Слайд 57Установки парсера
Одно из преимуществ создания парсеров при помощи DocumentBuilder состоит в управлении различными установками
Установки парсера
Одно из преимуществ создания парсеров при помощи DocumentBuilder состоит в управлении различными установками

Слайд 58Разбор файла в документ
Java-реализация DOM Уровня 2 обеспечивает управление параметрами парсера через
Разбор файла в документ
Java-реализация DOM Уровня 2 обеспечивает управление параметрами парсера через

Слайд 59Редактирование документа
Просмотр содержимого XML-документ полезен, но когда вы имеете дело с полнофункциональным
Редактирование документа
Просмотр содержимого XML-документ полезен, но когда вы имеете дело с полнофункциональным

Слайд 60Редактирование документа
Метод changeOrder() вызывается с передачей ему начального узла (root) в качестве параметра, а
Редактирование документа
Метод changeOrder() вызывается с передачей ему начального узла (root) в качестве параметра, а

Слайд 61Редактирование документа
В противном случае приложение проверяет каждый потомок так же, как это
Редактирование документа
В противном случае приложение проверяет каждый потомок так же, как это

Слайд 62Добавление узлов: подготовка данных
Иногда необходимо не изменить существующий узел, а добавить узел,
Добавление узлов: подготовка данных
Иногда необходимо не изменить существующий узел, а добавить узел,

 9
9 Презентация на тему Коллективный субъект преступления
Презентация на тему Коллективный субъект преступления  Famous people
Famous people Talking About Writing
Talking About Writing Бенчмаркинг в инновационной деятельности
Бенчмаркинг в инновационной деятельности Ландшафтный дизайн пришкольных клумб «Цветочная фантазия»
Ландшафтный дизайн пришкольных клумб «Цветочная фантазия» «Космические» загадки
«Космические» загадки Пирамида (10 класс)
Пирамида (10 класс) Процессуальное право: гражданский и арбитражный процесс
Процессуальное право: гражданский и арбитражный процесс Технология педагогического общения
Технология педагогического общения Налог на имущество физических лиц
Налог на имущество физических лиц Операционная система
Операционная система слюнные
слюнные Презентация к уроку
Презентация к уроку Оперный театр (урок музыки, 2 класс)
Оперный театр (урок музыки, 2 класс) Знакомство с Тильдой
Знакомство с Тильдой Административно - жилой комплекс «СОВРЕМЕННИК»
Административно - жилой комплекс «СОВРЕМЕННИК» Многогранники в архитектуре
Многогранники в архитектуре „SAM“ Well Manager-Управляющее устройство- “SAM”
„SAM“ Well Manager-Управляющее устройство- “SAM” Уголовное право. Уголовный процесс
Уголовное право. Уголовный процесс Урок литературы в 7 классе
Урок литературы в 7 классе Брифинг подрядчиков. ТНТ на VK Fest 2018 Санкт-Петербург
Брифинг подрядчиков. ТНТ на VK Fest 2018 Санкт-Петербург Презентация на тему Путешествие по странам Северной Африк
Презентация на тему Путешествие по странам Северной Африк Буквенные выражения 2 класс
Буквенные выражения 2 класс Разработка концепции виртуальной выставки
Разработка концепции виртуальной выставки Один день в жизни моей мамы
Один день в жизни моей мамы Битва на Чудском озере
Битва на Чудском озере Победа хлебопекарня
Победа хлебопекарня