- Хэширование (hashing). Хэш-таблицы (Hash tables).

Содержание
- 2. Хэширование–это преобразование входного массива данных определенного типа и произвольной длины в выходную битовую строку фиксированной длины.
- 3. Хеширование применяется для сравнения данных: если у двух массивов хеш-коды разные, массивы гарантированно различаются; если одинаковые
- 4. Существует множество массивов, дающих одинаковые хеш-коды — так называемые коллизии. Вероятность возникновения коллизий играет немаловажную роль
- 5. Идея хеширования впервые была высказана Г.П. Ланом при создании внутреннего меморандума IBM в январе 1953 г.
- 6. В открытой печати хеширование впервые было описано Арнольдом Думи (1956 год), указавшим, что в качестве хеш-адреса
- 7. Хэш-таблица – это структура данных, реализующая интерфейс ассоциативного массива, то есть она позволяет хранить пары вида
- 8. С точки зрения практического применения, хорошей является такая хэш-функция, которая удовлетворяет следующим условиям: функция должна быть
- 9. Если бы все данные были случайными, то хэш-функции были бы очень простые (например, несколько битов ключа).
- 10. При возникновении коллизий (разным ключам соответствует одно значение хэш-функции) необходимо найти новое место для хранения ключей,
- 11. Хэш-таблицы должны соответствовать следующим свойствам: Выполнение операции в хэш-таблице начинается с вычисления хэш-функции от ключа. Получающееся
- 12. Хэширование полезно, когда широкий диапазон возможных значений должен быть сохранен в малом объеме памяти, и нужен
- 13. Методы разрешения коллизий Коллизии, когда разным ключам соответствует одно значение хэш-функции, осложняют использование хэш-таблиц, т.к. нарушают
- 14. Метод цепочек Технология сцепления элементов состоит в том, что элементы множества, которым соответствует одно и то
- 15. Пример реализации метода цепочек при разрешении коллизий: ? на ключ 002 претендуют два значения, которые организуются
- 16. Операции поиска или удаления данных требуют просмотра всех элементов соответствующей ему цепочки, чтобы найти в ней
- 17. При предположении, что каждый элемент может попасть в любую позицию таблицы с равной вероятностью и независимо
- 18. Метод открытой адресации В отличие от хэширования с цепочками, при открытой адресации никаких списков нет, а
- 19. При любом методе разрешения коллизий необходимо ограничить длину поиска элемента!!!!!!!!. Если для поиска элемента необходимо более
- 20. Алгоритмы хэширования Существует несколько типов функций хеширования, каждая из которых имеет свои преимущества и недостатки и
- 21. Таблица прямого доступа Простейшей организацией таблицы, обеспечивающей идеально быстрый поиск, является таблица прямого доступа. В такой
- 22. Пространство ключей - множество всех теоретически возможных значений ключей записи. Пространство записей - множество тех ячеек
- 23. В большинстве реальных задач размер пространства записей много меньше, чем пространства ключей. Например, если в качестве
- 24. В целях экономии памяти можно назначать размер пространства записей равным размеру фактического множества записей или превосходящим
- 25. Метод остатков от деления Простейшей хэш-функцией является деление по модулю числового значения ключа Key на размер
- 26. Если ключей меньше, чем элементов массива, то в качестве хэш-функции можно использовать деление по модулю, то
- 27. //функция создания хеш-таблицы: //метод деления по модулю (самый //распространённый) int Hash(int Key,int HashTableSize) { return Key
- 28. Функция середины квадрата преобразует значение ключа в число, возводит это число в квадрат, из числа выбирает
- 29. Цифровое представление ключа разбивается на части, каждая из которых имеет длину, равную длине требуемого адреса. Над
- 30. Ключ, записанный как число в некоторой системе счисления P, интерпретируется как число в системе счисления Q>P.
- 31. Открытое хэширование Основная идея базовой структуры при открытом (внешнем) хэшировании заключается в том, что ✵ потенциальное
- 32. Часто классы называют сегментами, поэтому будем говорить, что элемент х принадлежит сегменту h(x). Массив, называемый таблицей
- 33. //Пример 1. Программная реализация открытого хэширования. #include #include using namespace std; typedef int T; // тип
- 34. //функция поиска местоположения и вставки вершины в таблицу Node *insertNode(T data) { Node *p, *p0; hashTableIndex
- 35. //функция удаления вершины из таблицы void deleteNode(T data) { Node *p0, *p; hashTableIndex bucket; p0 =
- 36. //функция поиска вершины со значением Node *findNode (T data) { Node *p; p = hashTable[myhash(data)]; while
- 37. int main() { int i, *a, maxnum; cout cin >> maxnum; cout cin >> hashTableSize; a
- 38. // вывод эдементов массива в файл List.txt ofstream out("List.txt"); for (i = 0; i { out
- 39. //очистка хэш-таблицы for (i = maxnum-1; i >= 0; i--) deleteNode(a[i]); return 0; } 50 элементов
- 40. Закрытое хеширование При закрытом (внутреннем) хэшировании в хэш-таблице хранятся непосредственно сами элементы, а не заголовки списков
- 41. При поиске элемента х необходимо просмотреть все местоположения h(x),h1(х),h2(х),..., пока не будет найден х или пока
- 42. Если в хэш-таблице допускается удаление элементов, то при достижении пустого сегмента, не найдя элемента х, нельзя
- 43. Важно различать константы DEL и NULL – последняя находится в сегментах, которые никогда не содержали элементов.
- 44. Линейное опробование Это последовательный перебор сегментов таблицы с некоторым фиксированным шагом: адрес=h(x)+ci, где i – номер
- 45. Квадратичное опробование отличается от линейного тем, что шаг перебора сегментов нелинейно зависит от номера попытки найти
- 46. Двойное хэширование Основана на нелинейной адресации, достигаемой за счет суммирования значений основной и дополнительной хэш-функций: адрес=h(x)+ih2(x).
- 47. В случае многократного превышения адресного пространства и, соответственно, многократного циклического перехода к началу будет происходить просмотр
- 48. Например, методика линейного опробования для разрешения коллизий – не самый лучший выбор: Как только несколько последовательных
- 49. //Пример 2. Программная реализация закрытого хеширования. #include #include using namespace std; typedef int T; // тип
- 50. int _tmain(int argc, _TCHAR* argv[]) { int i, *a, maxnum; cout cin >> maxnum; cout cin
- 51. //выделить память used = new bool[hashTableSize]; //выделить память для флажков //заполнение нулями for (i = 0;
- 52. // очистка хеш-таблицы for (i = maxnum-1; i >= 0; i--) { deleteData(a[i]); } system("pause"); return
- 53. // функция поиска величины, равной data bool findData (T data) { hashTableIndex bucket; bucket = myhash(data);
- 54. bucket = (bucket + 1) % hashTableSize; else if(dist(myhash(hashTable[bucket]),bucket) bucket = (bucket + 1) % hashTableSize;
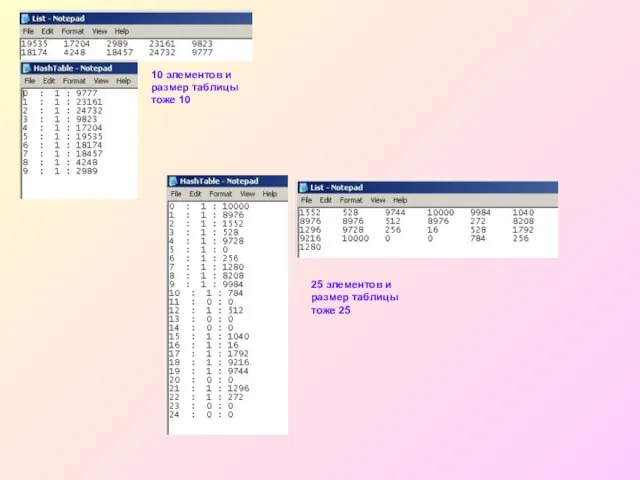
- 55. 25 элементов и размер таблицы тоже 25 10 элементов и размер таблицы тоже 10
- 56. До сих пор рассматривались способы поиска в таблице по ключам, позволяющим однозначно идентифицировать запись. Такие ключи
- 57. Ключевые термины: Вторичные ключи – это ключи, не позволяющие однозначно идентифицировать запись в таблице. Закрытое хэширование
- 58. Пространство записей – это множество тех ячеек памяти, которые выделяются для хранения таблицы. Пространство ключей –
- 59. Контрольные вопросы Каков принцип построения хеш-таблиц? Существуют ли универсальные методы построения хеш-таблиц? Почему возможно возникновение коллизий?
- 61. Скачать презентацию
Слайд 2Хэширование–это преобразование входного массива данных определенного типа и произвольной длины
в
Хэширование–это преобразование входного массива данных определенного типа и произвольной длины
в

Слайд 3Хеширование применяется для сравнения данных: если у двух массивов хеш-коды разные, массивы
Хеширование применяется для сравнения данных: если у двух массивов хеш-коды разные, массивы

Слайд 4Существует множество массивов, дающих одинаковые хеш-коды — так называемые коллизии. Вероятность возникновения коллизий
Существует множество массивов, дающих одинаковые хеш-коды — так называемые коллизии. Вероятность возникновения коллизий

Слайд 5Идея хеширования впервые была высказана Г.П. Ланом при создании внутреннего меморандума IBM
Идея хеширования впервые была высказана Г.П. Ланом при создании внутреннего меморандума IBM

Слайд 6В открытой печати хеширование впервые было описано Арнольдом Думи (1956 год), указавшим,
В открытой печати хеширование впервые было описано Арнольдом Думи (1956 год), указавшим,

Слайд 7 Хэш-таблица – это структура данных, реализующая интерфейс ассоциативного массива, то есть она
Хэш-таблица – это структура данных, реализующая интерфейс ассоциативного массива, то есть она

Слайд 8С точки зрения практического применения, хорошей является такая хэш-функция, которая удовлетворяет следующим
С точки зрения практического применения, хорошей является такая хэш-функция, которая удовлетворяет следующим

Слайд 9Если бы все данные были случайными, то хэш-функции были бы очень простые
Если бы все данные были случайными, то хэш-функции были бы очень простые

Слайд 10При возникновении коллизий (разным ключам соответствует одно значение хэш-функции) необходимо найти новое
При возникновении коллизий (разным ключам соответствует одно значение хэш-функции) необходимо найти новое

Слайд 11Хэш-таблицы должны соответствовать следующим свойствам:
Выполнение операции в хэш-таблице начинается с вычисления хэш-функции
Хэш-таблицы должны соответствовать следующим свойствам:
Выполнение операции в хэш-таблице начинается с вычисления хэш-функции

Слайд 12Хэширование полезно, когда широкий диапазон возможных значений должен быть сохранен в малом
Хэширование полезно, когда широкий диапазон возможных значений должен быть сохранен в малом

Слайд 13Методы разрешения коллизий
Коллизии, когда разным ключам соответствует одно значение хэш-функции, осложняют использование
Методы разрешения коллизий
Коллизии, когда разным ключам соответствует одно значение хэш-функции, осложняют использование

Слайд 14Метод цепочек
Технология сцепления элементов состоит в том, что элементы множества, которым соответствует
Метод цепочек
Технология сцепления элементов состоит в том, что элементы множества, которым соответствует

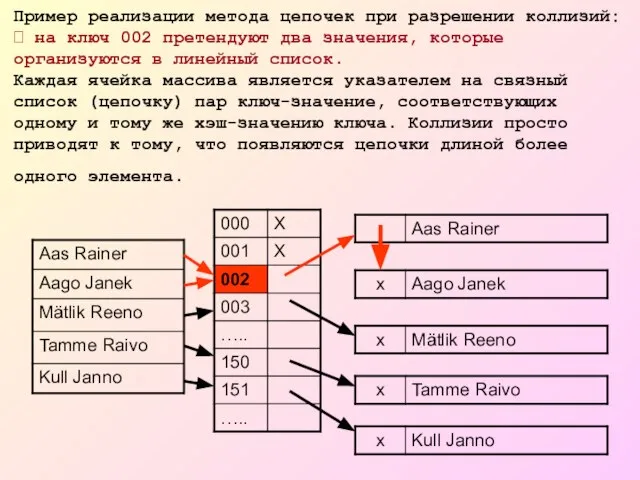
Слайд 15Пример реализации метода цепочек при разрешении коллизий: ? на ключ 002 претендуют
Пример реализации метода цепочек при разрешении коллизий: ? на ключ 002 претендуют
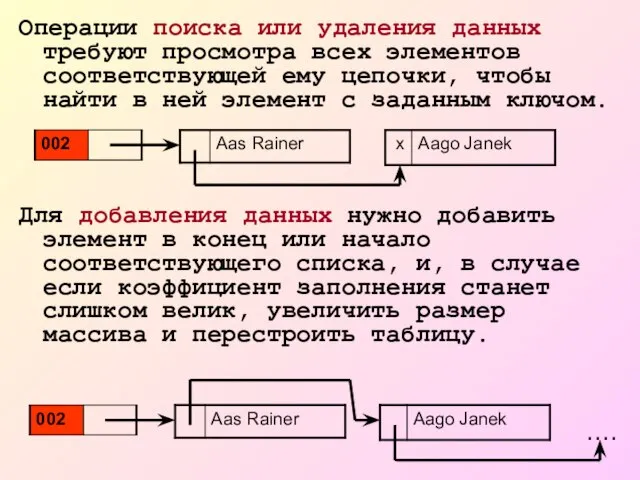
Слайд 16Операции поиска или удаления данных требуют просмотра всех элементов соответствующей ему цепочки,
Операции поиска или удаления данных требуют просмотра всех элементов соответствующей ему цепочки,
Слайд 17При предположении, что каждый элемент может попасть в любую позицию таблицы с
При предположении, что каждый элемент может попасть в любую позицию таблицы с

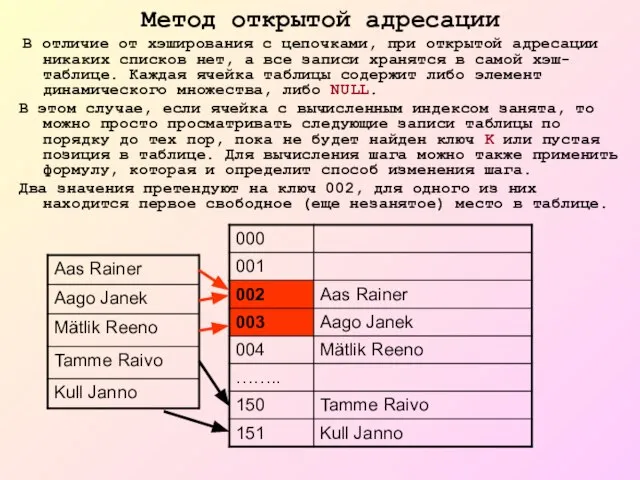
Слайд 18Метод открытой адресации
В отличие от хэширования с цепочками, при открытой адресации
Метод открытой адресации
В отличие от хэширования с цепочками, при открытой адресации
Слайд 19При любом методе разрешения коллизий необходимо ограничить длину поиска элемента!!!!!!!!.
Если для
При любом методе разрешения коллизий необходимо ограничить длину поиска элемента!!!!!!!!.
Если для

Слайд 20Алгоритмы хэширования
Существует несколько типов функций хеширования, каждая из которых имеет свои преимущества
Алгоритмы хэширования Существует несколько типов функций хеширования, каждая из которых имеет свои преимущества

Слайд 21Таблица прямого доступа
Простейшей организацией таблицы, обеспечивающей идеально быстрый поиск, является таблица прямого
Таблица прямого доступа
Простейшей организацией таблицы, обеспечивающей идеально быстрый поиск, является таблица прямого

Слайд 22Пространство ключей - множество всех теоретически возможных значений ключей записи.
Пространство записей
Пространство ключей - множество всех теоретически возможных значений ключей записи.
Пространство записей

Слайд 23В большинстве реальных задач размер пространства записей много меньше, чем пространства ключей.
Например,
В большинстве реальных задач размер пространства записей много меньше, чем пространства ключей.
Например,

Слайд 24В целях экономии памяти можно назначать размер пространства записей равным размеру фактического
В целях экономии памяти можно назначать размер пространства записей равным размеру фактического

Слайд 25Метод остатков от деления
Простейшей хэш-функцией является деление по модулю числового значения ключа
Метод остатков от деления
Простейшей хэш-функцией является деление по модулю числового значения ключа

Слайд 26Если ключей меньше, чем элементов массива, то в качестве хэш-функции можно использовать
Если ключей меньше, чем элементов массива, то в качестве хэш-функции можно использовать

Слайд 27 //функция создания хеш-таблицы: //метод деления по модулю (самый //распространённый)
int Hash(int Key,int
//функция создания хеш-таблицы: //метод деления по модулю (самый //распространённый)
int Hash(int Key,int

Слайд 28Функция середины квадрата
преобразует значение ключа в число,
возводит это число в квадрат,
Функция середины квадрата
преобразует значение ключа в число,
возводит это число в квадрат,

Слайд 29Цифровое представление ключа разбивается на части, каждая из которых имеет длину, равную
Цифровое представление ключа разбивается на части, каждая из которых имеет длину, равную

Слайд 30Ключ, записанный как число в некоторой системе счисления P, интерпретируется как число
Ключ, записанный как число в некоторой системе счисления P, интерпретируется как число

Слайд 31Открытое хэширование
Основная идея базовой структуры при открытом (внешнем) хэшировании заключается в том,
Открытое хэширование
Основная идея базовой структуры при открытом (внешнем) хэшировании заключается в том,

Слайд 32Часто классы называют сегментами, поэтому будем говорить, что элемент х принадлежит сегменту
Часто классы называют сегментами, поэтому будем говорить, что элемент х принадлежит сегменту

Слайд 33//Пример 1. Программная реализация открытого хэширования.
#include
#include
using namespace std;
typedef int T;
//Пример 1. Программная реализация открытого хэширования.
#include
#include
using namespace std;
typedef int T;

Слайд 34//функция поиска местоположения и вставки вершины в таблицу
Node *insertNode(T data)
{
Node
//функция поиска местоположения и вставки вершины в таблицу
Node *insertNode(T data)
{
Node
Слайд 35//функция удаления вершины из таблицы
void deleteNode(T data)
{
Node *p0, *p;
hashTableIndex
//функция удаления вершины из таблицы
void deleteNode(T data)
{
Node *p0, *p;
hashTableIndex

Слайд 36//функция поиска вершины со значением
Node *findNode (T data)
{
Node *p;
p
//функция поиска вершины со значением
Node *findNode (T data)
{
Node *p;
p

Слайд 37int main()
{
int i, *a, maxnum;
cout << "Введите количество элементов maxnum
int main()
{
int i, *a, maxnum;
cout << "Введите количество элементов maxnum

Слайд 38// вывод эдементов массива в файл List.txt
ofstream out("List.txt");
for (i =
// вывод эдементов массива в файл List.txt
ofstream out("List.txt");
for (i =

Слайд 39//очистка хэш-таблицы
for (i = maxnum-1; i >= 0; i--) deleteNode(a[i]);
return 0;
}
50
//очистка хэш-таблицы
for (i = maxnum-1; i >= 0; i--) deleteNode(a[i]);
return 0;
}
50
![//очистка хэш-таблицы for (i = maxnum-1; i >= 0; i--) deleteNode(a[i]); return](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/420329/slide-38.jpg)
Слайд 40Закрытое хеширование
При закрытом (внутреннем) хэшировании в хэш-таблице хранятся непосредственно сами элементы, а
Закрытое хеширование
При закрытом (внутреннем) хэшировании в хэш-таблице хранятся непосредственно сами элементы, а

Слайд 41При поиске элемента х необходимо просмотреть все местоположения h(x),h1(х),h2(х),..., пока не будет
При поиске элемента х необходимо просмотреть все местоположения h(x),h1(х),h2(х),..., пока не будет

Слайд 42Если в хэш-таблице допускается удаление элементов, то при достижении пустого сегмента, не
Если в хэш-таблице допускается удаление элементов, то при достижении пустого сегмента, не

Слайд 43Важно различать константы DEL и NULL – последняя находится в сегментах, которые
Важно различать константы DEL и NULL – последняя находится в сегментах, которые

Слайд 44Линейное опробование
Это последовательный перебор сегментов таблицы с некоторым фиксированным шагом:
адрес=h(x)+ci, где i –
Линейное опробование
Это последовательный перебор сегментов таблицы с некоторым фиксированным шагом:
адрес=h(x)+ci, где i –

Слайд 45Квадратичное опробование
отличается от линейного тем, что шаг перебора сегментов нелинейно зависит от
Квадратичное опробование
отличается от линейного тем, что шаг перебора сегментов нелинейно зависит от

Слайд 46Двойное хэширование
Основана на нелинейной адресации, достигаемой за счет суммирования значений основной и
Двойное хэширование
Основана на нелинейной адресации, достигаемой за счет суммирования значений основной и

Слайд 47В случае многократного превышения адресного пространства и, соответственно, многократного циклического перехода к
В случае многократного превышения адресного пространства и, соответственно, многократного циклического перехода к

Слайд 48Например, методика линейного опробования для разрешения коллизий – не самый лучший выбор:
Как
Например, методика линейного опробования для разрешения коллизий – не самый лучший выбор:
Как

Слайд 49//Пример 2. Программная реализация закрытого хеширования.
#include
#include
using namespace std;
typedef int T;
//Пример 2. Программная реализация закрытого хеширования.
#include
#include
using namespace std;
typedef int T;

Слайд 50int _tmain(int argc, _TCHAR* argv[])
{
int i, *a, maxnum;
cout << "Введите
int _tmain(int argc, _TCHAR* argv[])
{
int i, *a, maxnum;
cout << "Введите
![int _tmain(int argc, _TCHAR* argv[]) { int i, *a, maxnum; cout cin](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/420329/slide-49.jpg)
Слайд 51//выделить память
used = new bool[hashTableSize];
//выделить память для флажков
//заполнение нулями
//выделить память
used = new bool[hashTableSize];
//выделить память для флажков
//заполнение нулями
![//выделить память used = new bool[hashTableSize]; //выделить память для флажков //заполнение нулями](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/420329/slide-50.jpg)
Слайд 52// очистка хеш-таблицы
for (i = maxnum-1; i >= 0; i--)
{
// очистка хеш-таблицы
for (i = maxnum-1; i >= 0; i--)
{

Слайд 53// функция поиска величины, равной data
bool findData (T data)
{ hashTableIndex bucket;
// функция поиска величины, равной data
bool findData (T data)
{ hashTableIndex bucket;

Слайд 54bucket = (bucket + 1) % hashTableSize;
else
if(dist(myhash(hashTable[bucket]),bucket) < dist(gap,bucket) )
bucket = (bucket + 1) % hashTableSize;
else
if(dist(myhash(hashTable[bucket]),bucket) < dist(gap,bucket) )
![bucket = (bucket + 1) % hashTableSize; else if(dist(myhash(hashTable[bucket]),bucket) bucket = (bucket](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/420329/slide-53.jpg)
Слайд 5525 элементов и размер таблицы тоже 25
10 элементов и размер таблицы тоже
25 элементов и размер таблицы тоже 25
10 элементов и размер таблицы тоже
Слайд 56До сих пор рассматривались способы поиска в таблице по ключам, позволяющим однозначно
До сих пор рассматривались способы поиска в таблице по ключам, позволяющим однозначно

Слайд 57Ключевые термины:
Вторичные ключи – это ключи, не позволяющие однозначно идентифицировать запись в
Ключевые термины:
Вторичные ключи – это ключи, не позволяющие однозначно идентифицировать запись в

Слайд 58Пространство записей – это множество тех ячеек памяти, которые выделяются для хранения
Пространство записей – это множество тех ячеек памяти, которые выделяются для хранения

Слайд 59Контрольные вопросы
Каков принцип построения хеш-таблиц?
Существуют ли универсальные методы построения хеш-таблиц?
Почему возможно
Контрольные вопросы
Каков принцип построения хеш-таблиц?
Существуют ли универсальные методы построения хеш-таблиц?
Почему возможно

 Постоянная Комиссия по вопросам материнства, детства и защиты прав женщин Общественного Совета Центрального федерального округа
Постоянная Комиссия по вопросам материнства, детства и защиты прав женщин Общественного Совета Центрального федерального округа  Организация работы конфликтной комиссии при проведении аттестации по образовательным программам среднего образования в 2016 году
Организация работы конфликтной комиссии при проведении аттестации по образовательным программам среднего образования в 2016 году Культура Древнего Китая
Культура Древнего Китая Правила подготовки изделий под сварку
Правила подготовки изделий под сварку Изменения внесенные в образовательные программы по технологии
Изменения внесенные в образовательные программы по технологии Концепция сайта ДОУМуниципальное бюджетное дошкольное образовательное учреждение города Костромы «Детский сад №36»
Концепция сайта ДОУМуниципальное бюджетное дошкольное образовательное учреждение города Костромы «Детский сад №36» Наша профессия - реклама
Наша профессия - реклама Модели экономического развития стран Азии
Модели экономического развития стран Азии Александр Николаевич Радищев. Настоящий сын Отечества
Александр Николаевич Радищев. Настоящий сын Отечества Организация дистанционного обучения
Организация дистанционного обучения Презентация &amp;#39;&amp;#39;Я то, что я ем&amp;#39;&amp;#39;
Презентация &amp;#39;&amp;#39;Я то, что я ем&amp;#39;&amp;#39; ОБЖ 9 класс
ОБЖ 9 класс Szkoa Podstawowa nr 389
Szkoa Podstawowa nr 389 Технология как часть общечеловеческой культуры. 10 класс
Технология как часть общечеловеческой культуры. 10 класс Mamba
Mamba Об организации межведомственного взаимодействия при предоставлении государственных и муниципальных услуг
Об организации межведомственного взаимодействия при предоставлении государственных и муниципальных услуг Повторение изученного о фонетике и орфоэпии
Повторение изученного о фонетике и орфоэпии Орфоэпическое упражнение
Орфоэпическое упражнение ПРИВОЛЖСКИЙ ФЕДЕРАЛЬНЫЙ ОКРУГ БАЗОВЫЕ ЭЛЕМЕНТЫ ИННОВАЦИОННОЙ СИСТЕМЫ
ПРИВОЛЖСКИЙ ФЕДЕРАЛЬНЫЙ ОКРУГ БАЗОВЫЕ ЭЛЕМЕНТЫ ИННОВАЦИОННОЙ СИСТЕМЫ ДЕТСКОЕ ПИТАНИЕ
ДЕТСКОЕ ПИТАНИЕ SQLite менеджер Создание БД и таблиц DDL
SQLite менеджер Создание БД и таблиц DDL Проблема создания космического комплекса для исследования КОРОНЫ СОЛНЦА
Проблема создания космического комплекса для исследования КОРОНЫ СОЛНЦА Отмена крепостного права в России
Отмена крепостного права в России Электроскоп. Делимость электрического заряда
Электроскоп. Делимость электрического заряда Краевой конкурс профессионального мастерства
Краевой конкурс профессионального мастерства lang United Kingdom
lang United Kingdom Составить баланс земель для заданной территории
Составить баланс земель для заданной территории