Исследование ускорения вычислений параллельных реализаций метода конечных элементов для уравнений мелкой воды
- Исследование ускорения вычислений параллельных реализаций метода конечных элементов для уравнений мелкой воды

Содержание
- 2. Подготовка входных данных о сетках и триангуляции для расчетов на многопроцессорной ВС. Анализ ускорения и эффективности
- 3. В данной работе: было проведено исследование эффективности распараллеливания метода конечных элементов для решения краевой задачи для
- 4. Дифференциальная постановка прямой задачи
- 5. Уравнения (1) – уравнения мелкой воды. Постановка дифференциальной задачи выполнена В.И. Агошковым. Для дискретного аналога задачи
- 6. Векторно-матричная форма дискретного аналога. Потенциальный параллелизм
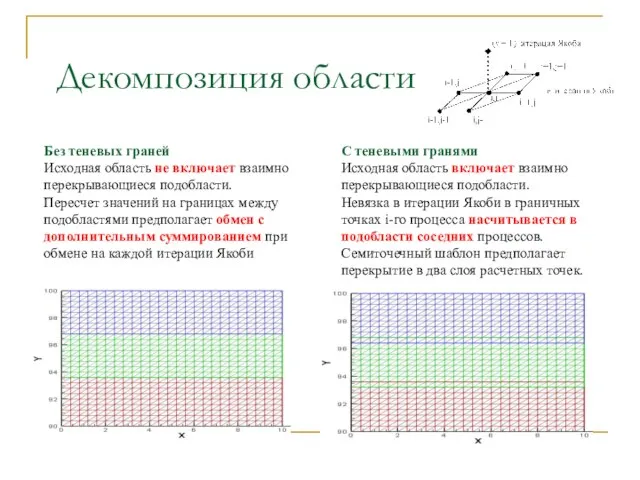
- 7. Декомпозиция области Без теневых граней Исходная область не включает взаимно перекрывающиеся подобласти. Пересчет значений на границах
- 8. Однородное распределение данных по компьютерам Баланса времени затрачиваемого на вычисления затрачиваемого на взаимодействия ветвей параллельной программы
- 9. Программа распределения данных по процессам Написана на языке программирования С На входе файл, описывающий сетку координат
- 10. Отметим, что поскольку декомпозиция с теневыми гранями на P процессов требует дополнительного хранения в каждой граничной
- 11. Типы обменов. Блокирующие передачи Реализации обменов по цепочке процессов с помощью функций совмещенных приема-передачи MPI_Sendrecv(...). Все
- 12. Типы обменов. Неблокирующие передачи Неблокирующие функции подразумевают совмещение операций обмена с другими операциями Время, затрачиваемое на
- 13. Численные эксперименты
- 14. Кластер МВС-1000/ИВМ неоднородной архитектуры (собственная сборка ИВМ СО РАН) 99 вычислительных ядра 23 вычислительных узла AMD
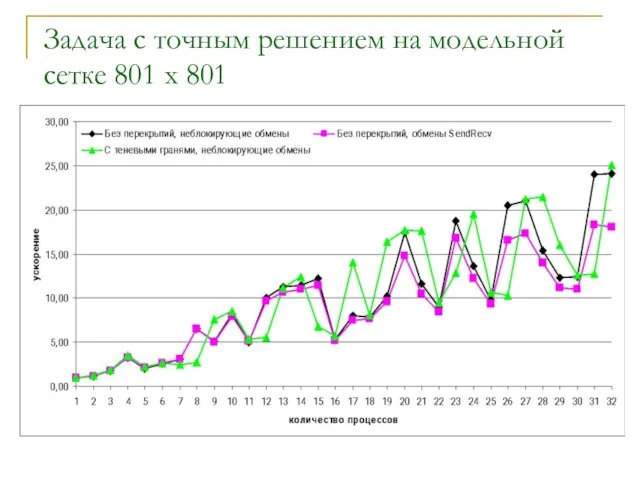
- 15. Задача с точным решением на модельной сетке 801 x 801
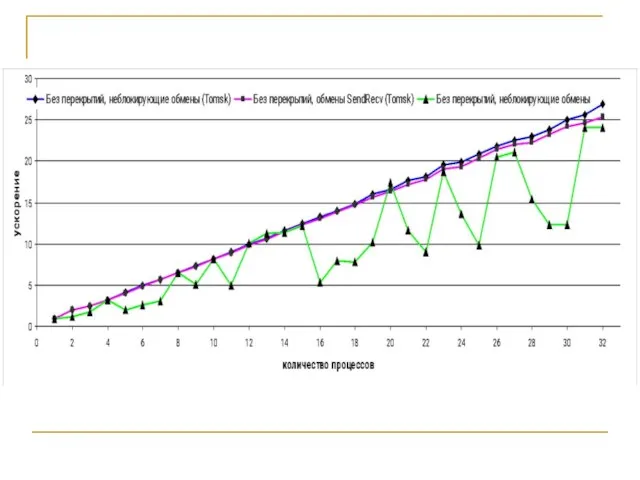
- 16. Кластер Skif Cyberia (ТГУ) Архитектура x86 с поддержкой 64 разрядных расширений. Количество вычислительных узлов/процессоров 283/566 (один
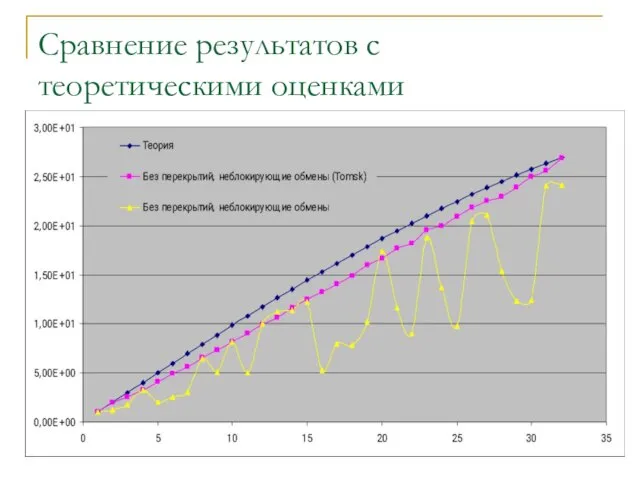
- 18. Сравнение результатов с теоретическими оценками
- 19. Время неблокирующих обменов 801x801 без перекрытий
- 20. Время вычислений 801x801 без перекрытий
- 21. Результаты исследования показали, что ускорение вычислений при увеличении количества процессов для сеток больших размерностей не убывает
- 23. Скачать презентацию
Слайд 2Подготовка входных данных о сетках и триангуляции для расчетов на многопроцессорной ВС.
Анализ
Подготовка входных данных о сетках и триангуляции для расчетов на многопроцессорной ВС.
Анализ

Слайд 3 В данной работе:
было проведено исследование эффективности распараллеливания метода конечных элементов
В данной работе:
было проведено исследование эффективности распараллеливания метода конечных элементов

Слайд 4 Дифференциальная постановка прямой задачи
Дифференциальная постановка прямой задачи

Слайд 5Уравнения (1) – уравнения мелкой воды.
Постановка дифференциальной задачи выполнена В.И. Агошковым.
Для дискретного
Уравнения (1) – уравнения мелкой воды.
Постановка дифференциальной задачи выполнена В.И. Агошковым.
Для дискретного

Слайд 6Векторно-матричная форма дискретного аналога. Потенциальный параллелизм
Векторно-матричная форма дискретного аналога. Потенциальный параллелизм

Слайд 7 Декомпозиция области
Без теневых граней
Исходная область не включает взаимно перекрывающиеся подобласти.
Пересчет
Декомпозиция области
Без теневых граней
Исходная область не включает взаимно перекрывающиеся подобласти.
Пересчет
Слайд 8Однородное распределение данных по компьютерам
Баланса времени
затрачиваемого на вычисления
затрачиваемого на взаимодействия ветвей
Однородное распределение данных по компьютерам
Баланса времени
затрачиваемого на вычисления
затрачиваемого на взаимодействия ветвей

Слайд 9Программа распределения данных по процессам
Написана на языке программирования С
На входе
файл, описывающий
Программа распределения данных по процессам
Написана на языке программирования С
На входе
файл, описывающий

Слайд 10 Отметим, что поскольку декомпозиция с теневыми гранями на P процессов требует дополнительного
Отметим, что поскольку декомпозиция с теневыми гранями на P процессов требует дополнительного

Слайд 11 Типы обменов. Блокирующие передачи
Реализации обменов по цепочке процессов с помощью
Типы обменов. Блокирующие передачи
Реализации обменов по цепочке процессов с помощью

Слайд 12Типы обменов. Неблокирующие передачи
Неблокирующие функции подразумевают совмещение
операций обмена с другими операциями
Время,
Типы обменов. Неблокирующие передачи
Неблокирующие функции подразумевают совмещение
операций обмена с другими операциями
Время,

Слайд 13Численные эксперименты
Численные эксперименты

Слайд 14Кластер МВС-1000/ИВМ неоднородной архитектуры (собственная сборка ИВМ СО РАН)
99 вычислительных ядра
23 вычислительных
Кластер МВС-1000/ИВМ неоднородной архитектуры (собственная сборка ИВМ СО РАН)
99 вычислительных ядра
23 вычислительных

Слайд 15Задача с точным решением на модельной сетке 801 x 801
Задача с точным решением на модельной сетке 801 x 801
Слайд 16Кластер Skif Cyberia (ТГУ)
Архитектура x86 с поддержкой 64 разрядных расширений. Количество вычислительных
Кластер Skif Cyberia (ТГУ)
Архитектура x86 с поддержкой 64 разрядных расширений. Количество вычислительных

Слайд 18Сравнение результатов с теоретическими оценками
Сравнение результатов с теоретическими оценками
Слайд 19Время неблокирующих обменов
801x801 без перекрытий
Время неблокирующих обменов
801x801 без перекрытий
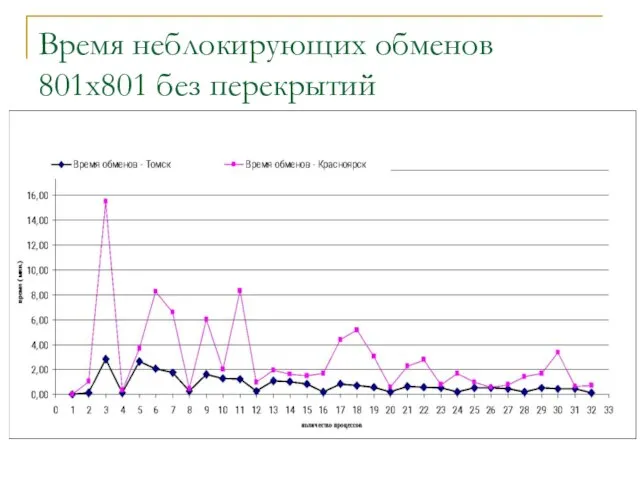
Слайд 20Время вычислений
801x801 без перекрытий
Время вычислений
801x801 без перекрытий
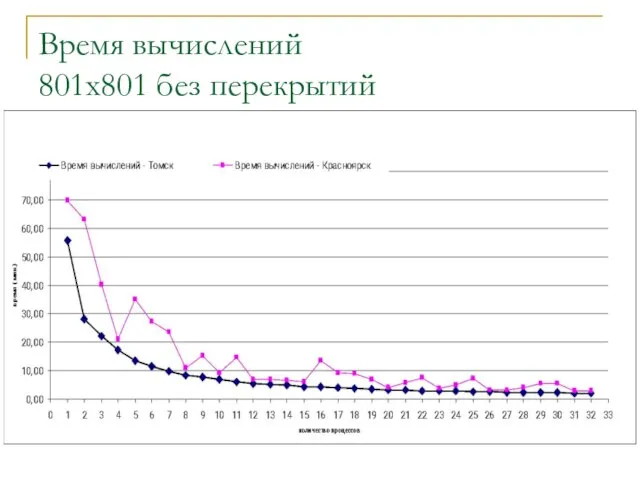
Слайд 21Результаты исследования показали, что
ускорение вычислений при увеличении количества процессов для сеток больших
Результаты исследования показали, что
ускорение вычислений при увеличении количества процессов для сеток больших

 Фонетика русского языка
Фонетика русского языка В мире интересного
В мире интересного Полновесные электронные библиотеки в интернете, источники электронного комплектования
Полновесные электронные библиотеки в интернете, источники электронного комплектования Лексикология и фразеология
Лексикология и фразеология Cream&Chocolate
Cream&Chocolate Чудеса России
Чудеса России Late adulthood
Late adulthood LIETUVOS MENININKU SOCIALINE PADETIS RYTU IR VIDURIO EUROPOS KONTEKSTE
LIETUVOS MENININKU SOCIALINE PADETIS RYTU IR VIDURIO EUROPOS KONTEKSTE Таблицы по Теории организации
Таблицы по Теории организации American holidays
American holidays  Станция «Поморская».
Станция «Поморская». Путь героя к преступлению
Путь героя к преступлению Деепричастие
Деепричастие Электрические машины. ЭДС обмотки якоря, электромагнитный момент, реакция якоря. (Лекция 2)
Электрические машины. ЭДС обмотки якоря, электромагнитный момент, реакция якоря. (Лекция 2) Практикум по методам психологического исследования. Лабораторное занятие № 1
Практикум по методам психологического исследования. Лабораторное занятие № 1 Nicaragua
Nicaragua Восприятие. Психические процессы
Восприятие. Психические процессы Тьюторское сопровождение образовательной программы
Тьюторское сопровождение образовательной программы Книга рекордов Гиннесса
Книга рекордов Гиннесса Презентация на тему Знаки препинания при однородных членах
Презентация на тему Знаки препинания при однородных членах  Конституция Российской Федерации
Конституция Российской Федерации Презентация на тему Проблема терроризма в России. Бесланская трагедия
Презентация на тему Проблема терроризма в России. Бесланская трагедия  Презентация картины Валерия Хованского «Колокольчики звенят» Выполнили ученики: Лесько Караулов Константин
Презентация картины Валерия Хованского «Колокольчики звенят» Выполнили ученики: Лесько Караулов Константин  Тригонометрические функции
Тригонометрические функции  Символизм и его представители
Символизм и его представители Управление рисками
Управление рисками Die BRD (1949 -1990)
Die BRD (1949 -1990) проект по англ яз на тему проблема подростков
проект по англ яз на тему проблема подростков