- Кластеризация и визуализация экспериментальных данных

Содержание
- 2. План доклада Что такое кластеризация и основные области её применения Этапы кластеризации, основные алгоритмы кластеризации Алгоритм
- 3. Кластеризация (кластерный анализ) “Кластерный анализ – задача разбиения заданной выборки объектов на непересекающиеся подмножества, называемые кластерами
- 4. Дистанционное зондирование Земли “Задачей классификации является перенос нагрузки по анализу и обработки информации с человека на
- 5. Анализ данных Скорой помощи
- 6. Традиционно кластеризация включает в себя следующие шаги: Определить цель исследования. Это может быть или определение кластерной
- 7. Краткий обзор методов кластеризации Классические алгоритмы Алгоритмы, основанные на минимизации функционала Алгоритм К – средних Форель(FOREL),
- 8. Алгоритм К-средних Описание алгоритма: Задание числа кластеров k, на которые надо разбить входные данные. Выбор k
- 9. Алгоритм К-средних Основная трудность, которая возникает при использовании алгоритма к-средних – необходимость задания числа кластеров. Для
- 10. Алгоритм К-средних Основные достоинства алгоритма: простота использовании метода - задание только одного параметра (числа кластеров). один
- 11. Алгоритм К-средних
- 12. Постановка задачи кластеризации Дано Требуется разбить на множество групп (кластеров) чтобы точки из одной группы были
- 13. Алгоритм гравитационной кластеризации Общее описание Шаг 1: построение дерева объединений Шаг 2: построение “естественных” кластеров Шаг
- 14. Алгоритм гравитационной кластеризации: общее описание
- 15. Алгоритм гравитационной кластеризации: построение дерева объединений numpoints=n; t=0; while(numpoints!=1) { объединение “близких” точек движение точек }
- 16. Алгоритм гравитационной кластеризации: построение дерева объединений
- 17. Алгоритм гравитационной кластеризации: построение “естественных” кластеров Упрощение дерева объединений Пусть - дети вершины рассмотрим величины -
- 18. Алгоритм гравитационной кластеризации: построение “естественных” кластеров Определение “естественных” кластеров Вершину будем называть “естественным” кластером, если выполняется
- 19. Алгоритм гравитационной кластеризации: построение кластеризации Если выполнено то говорим, что “естественный” кластер допускает разбиение на более
- 20. Достоинства Автоматическое определение числа кластеров Независимость настроек алгоритма от входных данных Дерево объединения даёт представление о
- 21. Устойчивость алгоритма гравитационной кластеризации Определение Алгоритм кластеризации устойчив на наборе данных если существуют такие что результаты
- 22. Гравитационная кластеризация по m ближайшим точкам Основная идея - учитывать влияние только m “ближайших” точек Пусть
- 23. Гравитационная кластеризация с использованием CF-дерева CF-дерево, построенное по последователь- ности из n точек с параметрами B
- 24. Модификации алгоритма гравитационной кластеризации Предложены следующие модификации алгоритма Алгоритм гравитационной кластеризации по m ближайшим точкам Алгоритм
- 25. Результаты работы гравитационного алгоритма
- 26. Результаты работы гравитационного алгоритма
- 27. Области применения: обработка потоковой информации Рассматривается задача построения иерархии рубрик для системы рубрикации текстов При обучении
- 28. Области применения: обработка потоковой информации Проведенные испытания показывают, что использование дерева повышает точность определения рубрики при
- 29. Области применения: Минимизация вычислений в задаче обтекания
- 30. Минимизация вычислений в задаче обтекания Пример разбиения множества вихрей на группы Цель: разбиение множества вихрей на
- 31. Сопоставление набору точек из многомерного пространства точек на плоскости с качественным отображением: Задача визуализации 1) кластерной
- 32. Требования к алгоритму визуализации 1) интуитивно понятное изображение 2) простота в навигации по данным 3) эффективное
- 33. Существующие подходы 1)Многомерное шкалирование 2) TreeMaps 3) Botanical Tree 4) Star Tree 5) Hyperbolic Display 6)
- 34. Treemaps Botanical Tree Star Tree
- 35. Соответствие предъявленным требованиям существующих методов
- 36. Визуализация многомерных данных Определение Визуализация — множество где Определение Визуализатор — множество визуализаций, т.е. Число s
- 37. Дерево визуализации Каждая визуализация отображается как набор точек. Конкретное состояние визуализатора – некоторая конфигурация точек на
- 38. Составляющие предлагаемого подхода Отображение данных, находящихся в “центре” и группировка данных, находящихся вне “центра”, с использованием
- 39. Построение дерева визуализации (визуализатора) При построении визуализатора на основе дерева объединений выполняются следующие шаги: Сопоставление визуализации
- 40. Обеспечение плавности перехода от одной конфигурации к другой Смещение В любой конфигурации всегда должна быть «точка
- 41. Структура хранения визуализатора Структура хранения визуализации данных – дерево (дерево визуализации), вершины которого содержат следующую информацию:
- 42. Схема взаимодействия элементов системы визуализации Запрос конфигурации точек Клиентское приложение Передача конфигурации точек Обработчик запросов визуализации
- 43. Пример 6 17 1 5 11 16 Раскрытие точки 6
- 45. Скачать презентацию
Слайд 2План доклада
Что такое кластеризация и основные области её применения
Этапы кластеризации, основные алгоритмы
План доклада
Что такое кластеризация и основные области её применения
Этапы кластеризации, основные алгоритмы

Слайд 3Кластеризация
(кластерный анализ)
“Кластерный анализ – задача разбиения заданной выборки объектов на непересекающиеся
Кластеризация
(кластерный анализ)
“Кластерный анализ – задача разбиения заданной выборки объектов на непересекающиеся

Слайд 4Дистанционное зондирование Земли
“Задачей классификации является перенос нагрузки по анализу и
обработки информации с
Дистанционное зондирование Земли
“Задачей классификации является перенос нагрузки по анализу и
обработки информации с

Слайд 5Анализ данных Скорой помощи
Анализ данных Скорой помощи

Слайд 6Традиционно кластеризация включает в себя следующие шаги:
Определить цель исследования. Это может быть
Традиционно кластеризация включает в себя следующие шаги:
Определить цель исследования. Это может быть

Слайд 7Краткий обзор методов кластеризации
Классические алгоритмы
Алгоритмы, основанные на минимизации функционала
Алгоритм К – средних
Форель(FOREL),
Краткий обзор методов кластеризации
Классические алгоритмы
Алгоритмы, основанные на минимизации функционала
Алгоритм К – средних
Форель(FOREL),

Слайд 8Алгоритм К-средних
Описание алгоритма:
Задание числа кластеров k, на которые надо разбить входные данные.
Выбор
Алгоритм К-средних
Описание алгоритма:
Задание числа кластеров k, на которые надо разбить входные данные.
Выбор

Слайд 9Алгоритм К-средних
Основная трудность, которая возникает при использовании алгоритма к-средних – необходимость задания
Алгоритм К-средних
Основная трудность, которая возникает при использовании алгоритма к-средних – необходимость задания

Слайд 10Алгоритм К-средних
Основные достоинства алгоритма:
простота использовании метода - задание только одного параметра (числа
Алгоритм К-средних
Основные достоинства алгоритма:
простота использовании метода - задание только одного параметра (числа

Слайд 11Алгоритм К-средних
Алгоритм К-средних
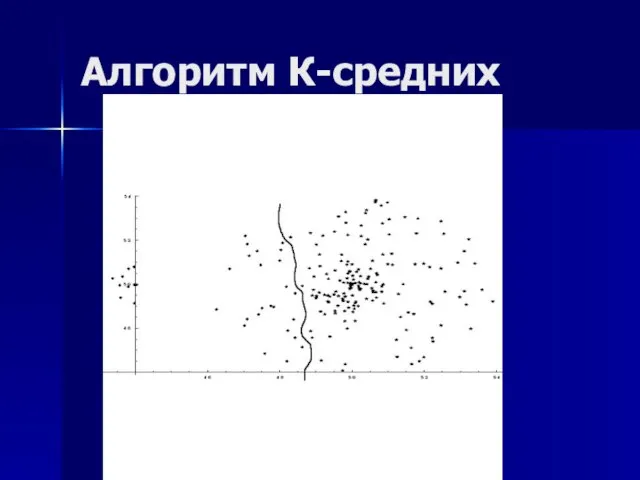
Слайд 12Постановка задачи кластеризации
Дано
Требуется разбить на множество групп (кластеров)
чтобы точки из одной группы
Постановка задачи кластеризации
Дано
Требуется разбить на множество групп (кластеров)
чтобы точки из одной группы

Слайд 13Алгоритм гравитационной кластеризации
Общее описание
Шаг 1: построение дерева объединений
Шаг 2: построение “естественных” кластеров
Шаг
Алгоритм гравитационной кластеризации
Общее описание
Шаг 1: построение дерева объединений
Шаг 2: построение “естественных” кластеров
Шаг

Слайд 14Алгоритм гравитационной кластеризации: общее описание
Алгоритм гравитационной кластеризации: общее описание
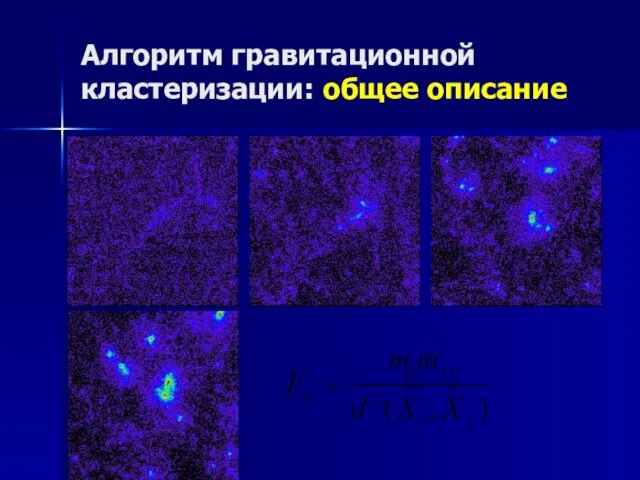
Слайд 15Алгоритм гравитационной кластеризации: построение дерева объединений
numpoints=n;
t=0;
while(numpoints!=1)
{
объединение “близких” точек
движение точек
}
Объединение “близких”
Две
Алгоритм гравитационной кластеризации: построение дерева объединений
numpoints=n;
t=0;
while(numpoints!=1)
{
объединение “близких” точек
движение точек
}
Объединение “близких”
Две

Слайд 16Алгоритм гравитационной кластеризации: построение дерева объединений
Алгоритм гравитационной кластеризации: построение дерева объединений
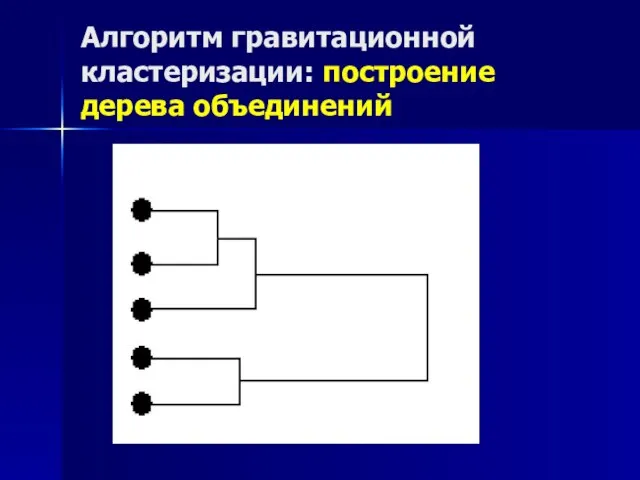
Слайд 17Алгоритм гравитационной кластеризации: построение “естественных” кластеров
Упрощение дерева объединений
Пусть - дети вершины
рассмотрим
Алгоритм гравитационной кластеризации: построение “естественных” кластеров
Упрощение дерева объединений Пусть - дети вершины рассмотрим
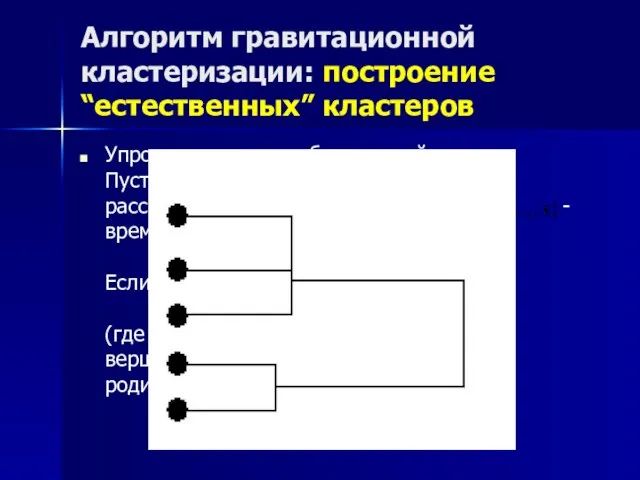
Слайд 18Алгоритм гравитационной кластеризации: построение “естественных” кластеров
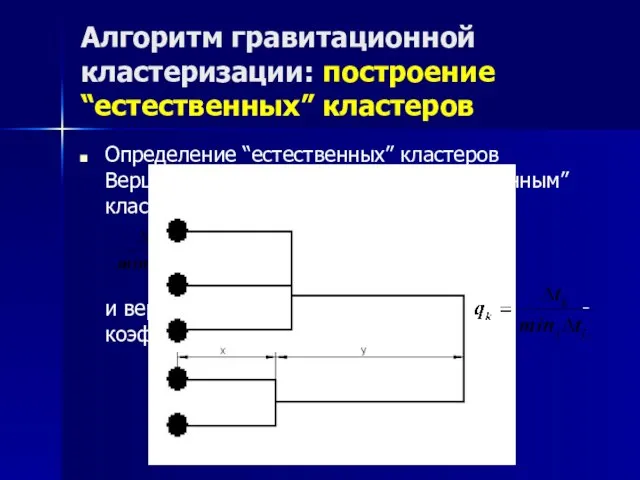
Определение “естественных” кластеров
Вершину будем называть “естественным” кластером,
Алгоритм гравитационной кластеризации: построение “естественных” кластеров
Определение “естественных” кластеров Вершину будем называть “естественным” кластером,
Слайд 19Алгоритм гравитационной кластеризации: построение кластеризации
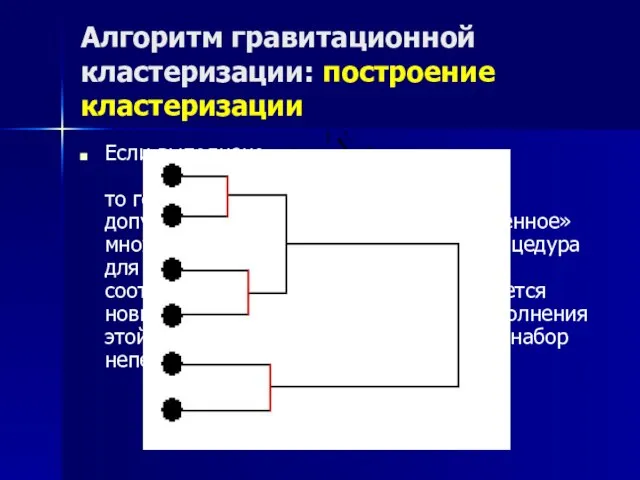
Если выполнено
то говорим, что “естественный” кластер допускает
Алгоритм гравитационной кластеризации: построение кластеризации
Если выполнено то говорим, что “естественный” кластер допускает
Слайд 20Достоинства
Автоматическое определение числа кластеров
Независимость настроек алгоритма от входных данных
Дерево объединения даёт представление
Достоинства
Автоматическое определение числа кластеров
Независимость настроек алгоритма от входных данных
Дерево объединения даёт представление

Слайд 21Устойчивость алгоритма гравитационной кластеризации
Определение Алгоритм кластеризации устойчив на наборе данных
если существуют
Устойчивость алгоритма гравитационной кластеризации
Определение Алгоритм кластеризации устойчив на наборе данных
если существуют

Слайд 22Гравитационная кластеризация по m ближайшим точкам
Основная идея - учитывать влияние только m
Гравитационная кластеризация по m ближайшим точкам
Основная идея - учитывать влияние только m

Слайд 23Гравитационная кластеризация с использованием CF-дерева
CF-дерево, построенное по последователь- ности из n точек
Гравитационная кластеризация с использованием CF-дерева
CF-дерево, построенное по последователь- ности из n точек

Слайд 24Модификации алгоритма гравитационной кластеризации
Предложены следующие модификации алгоритма
Алгоритм гравитационной кластеризации по m ближайшим
Модификации алгоритма гравитационной кластеризации
Предложены следующие модификации алгоритма
Алгоритм гравитационной кластеризации по m ближайшим

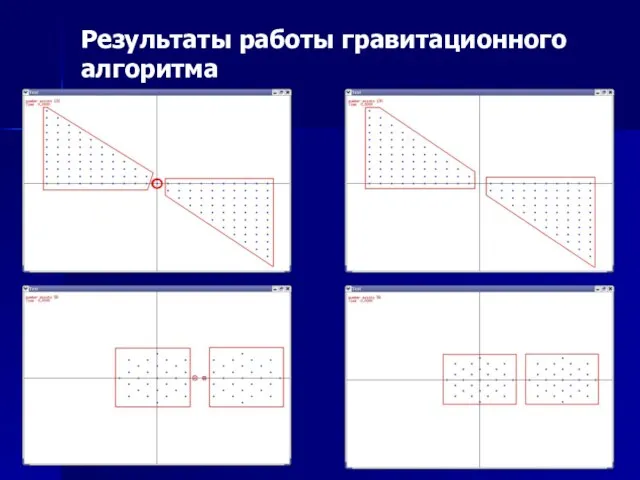
Слайд 25Результаты работы гравитационного алгоритма
Результаты работы гравитационного алгоритма
Слайд 26Результаты работы гравитационного алгоритма
Результаты работы гравитационного алгоритма

Слайд 27Области применения: обработка потоковой информации
Рассматривается задача построения иерархии рубрик для системы рубрикации
Области применения: обработка потоковой информации
Рассматривается задача построения иерархии рубрик для системы рубрикации

Слайд 28Области применения: обработка потоковой информации
Проведенные испытания показывают, что использование дерева повышает
точность
Области применения: обработка потоковой информации
Проведенные испытания показывают, что использование дерева повышает
точность

Слайд 29Области применения: Минимизация вычислений в задаче обтекания
Области применения: Минимизация вычислений в задаче обтекания

Слайд 30Минимизация вычислений в задаче обтекания
Пример разбиения множества вихрей на группы
Цель: разбиение множества
Минимизация вычислений в задаче обтекания
Пример разбиения множества вихрей на группы
Цель: разбиение множества

Слайд 31Сопоставление набору точек из многомерного пространства точек на плоскости с качественным отображением:
Задача
Сопоставление набору точек из многомерного пространства точек на плоскости с качественным отображением:
Задача

Слайд 32Требования к алгоритму визуализации
1) интуитивно понятное изображение
2) простота в навигации по данным
3)
Требования к алгоритму визуализации
1) интуитивно понятное изображение 2) простота в навигации по данным 3)

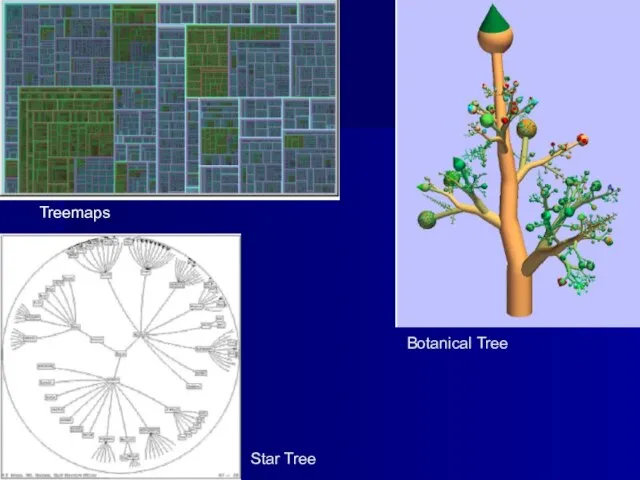
Слайд 33Существующие подходы
1)Многомерное шкалирование
2) TreeMaps
3) Botanical Tree
4) Star Tree
5) Hyperbolic Display
6) Визуализация
Существующие подходы
1)Многомерное шкалирование 2) TreeMaps 3) Botanical Tree 4) Star Tree 5) Hyperbolic Display 6) Визуализация

Слайд 34Treemaps
Botanical Tree
Star Tree
Treemaps
Botanical Tree
Star Tree
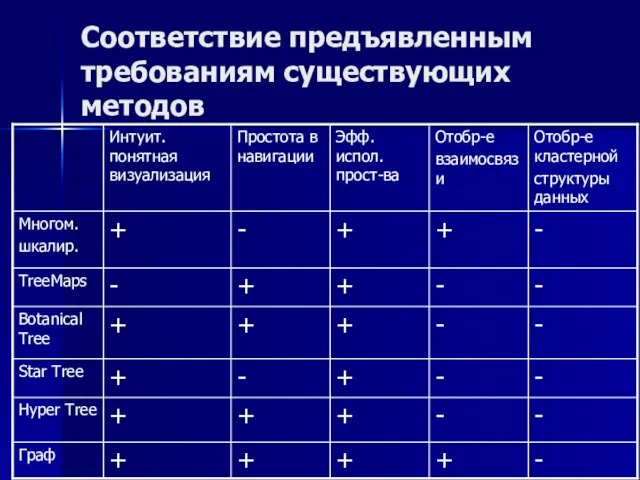
Слайд 35Соответствие предъявленным требованиям существующих методов
Соответствие предъявленным требованиям существующих методов
Слайд 36Визуализация многомерных данных
Определение Визуализация — множество
где
Определение Визуализатор — множество визуализаций, т.е. Число s
Визуализация многомерных данных
Определение Визуализация — множество
где
Определение Визуализатор — множество визуализаций, т.е. Число s

Слайд 37Дерево визуализации
Каждая визуализация отображается как набор точек.
Конкретное состояние визуализатора – некоторая конфигурация
Дерево визуализации
Каждая визуализация отображается как набор точек.
Конкретное состояние визуализатора – некоторая конфигурация

Слайд 38Составляющие предлагаемого подхода
Отображение данных, находящихся в “центре” и группировка данных, находящихся вне
Составляющие предлагаемого подхода
Отображение данных, находящихся в “центре” и группировка данных, находящихся вне

Слайд 39Построение дерева визуализации (визуализатора)
При построении визуализатора на основе дерева объединений выполняются следующие
Построение дерева визуализации (визуализатора)
При построении визуализатора на основе дерева объединений выполняются следующие

Слайд 40Обеспечение плавности перехода от одной конфигурации к другой
Смещение
В любой конфигурации всегда должна
Обеспечение плавности перехода от одной конфигурации к другой
Смещение
В любой конфигурации всегда должна

Слайд 41Структура хранения визуализатора
Структура хранения визуализации данных – дерево (дерево визуализации), вершины которого
Структура хранения визуализатора
Структура хранения визуализации данных – дерево (дерево визуализации), вершины которого

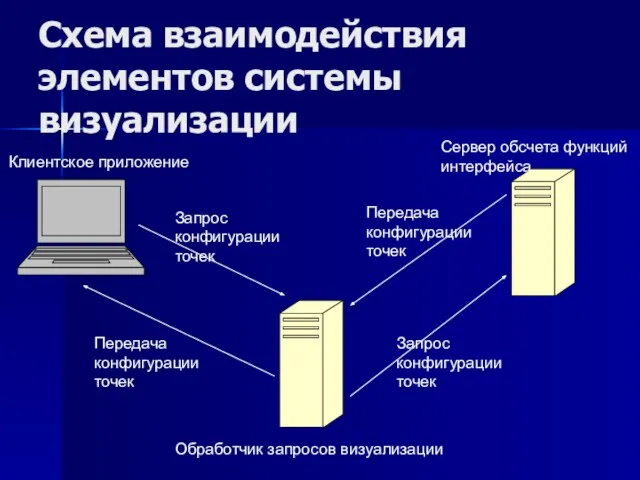
Слайд 42Схема взаимодействия элементов системы визуализации
Запрос
конфигурации
точек
Клиентское приложение
Передача
конфигурации
точек
Обработчик запросов визуализации
Запрос
конфигурации
Схема взаимодействия элементов системы визуализации
Запрос
конфигурации
точек
Клиентское приложение
Передача
конфигурации
точек
Обработчик запросов визуализации
Запрос
конфигурации
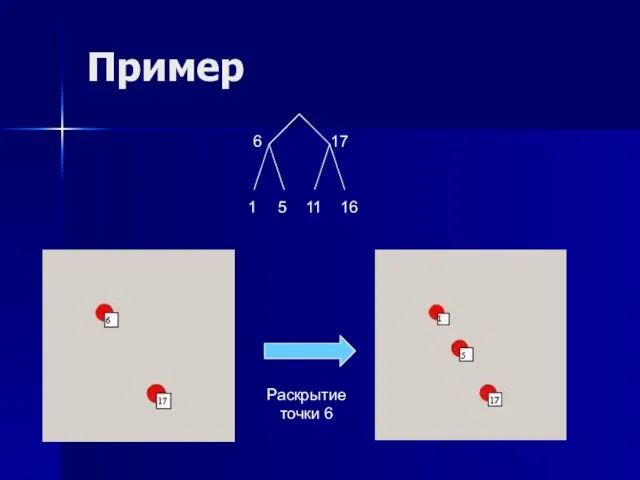
Слайд 43Пример
6
17
1
5
11
16
Раскрытие
точки 6
Пример
6
17
1
5
11
16
Раскрытие
точки 6
 Изоморфизм
Изоморфизм  Типовое решение для энергопредприятий в области финансового управления на базе 1С:Предприятие
Типовое решение для энергопредприятий в области финансового управления на базе 1С:Предприятие Дада. Дадаизм
Дада. Дадаизм 2011-2012 год
2011-2012 год Проект компоновки механического цеха с подробной разработкой участка механической обработки по изготовлению детали Ползун
Проект компоновки механического цеха с подробной разработкой участка механической обработки по изготовлению детали Ползун Формирование ключевых компетентностей у учащихся в процессе преподавания математики с использованием И К Т
Формирование ключевых компетентностей у учащихся в процессе преподавания математики с использованием И К Т CIVIL LAW Subjects of civil
CIVIL LAW Subjects of civil Кафедра английского языкаГОУ Гимназия 171
Кафедра английского языкаГОУ Гимназия 171 Советский период. СССР
Советский период. СССР Биоэквивалентность – как регуляторный механизм на фармрынках государств СНГ
Биоэквивалентность – как регуляторный механизм на фармрынках государств СНГ WFM МТС
WFM МТС Профессиограмма директора школы
Профессиограмма директора школы Устные приемы сложения и вычитания
Устные приемы сложения и вычитания Анализ внедрения системы управления качеством в медицинской организации на примере деятельности ЦКБ РАН
Анализ внедрения системы управления качеством в медицинской организации на примере деятельности ЦКБ РАН Цена, рынок, конкуренция
Цена, рынок, конкуренция Силлогические выводы
Силлогические выводы Об организации подготовки в муниципальных образованиях жилищного фонда к осенне-зимнему периоду 2011-2012 гг.
Об организации подготовки в муниципальных образованиях жилищного фонда к осенне-зимнему периоду 2011-2012 гг. Операционные системы, среды и оболочки
Операционные системы, среды и оболочки ЯРМАРКА НА РУСИ
ЯРМАРКА НА РУСИ Русский классицизм в архитектуре. История классицизма в России
Русский классицизм в архитектуре. История классицизма в России Презентация на тему Русская народная вышивка
Презентация на тему Русская народная вышивка Лекция 2СОЦИАЛИЗАЦИЯ ЛИЧНОСТИ: НОРМЫ И ОТКЛОНЕНИЯ
Лекция 2СОЦИАЛИЗАЦИЯ ЛИЧНОСТИ: НОРМЫ И ОТКЛОНЕНИЯ Пошив детского платья
Пошив детского платья Исполнитель: студентка 5 курса 1 группы Е.Г.Лозюк Руководитель: профессор, д.э.н., профессор С.А.Толкачев
Исполнитель: студентка 5 курса 1 группы Е.Г.Лозюк Руководитель: профессор, д.э.н., профессор С.А.Толкачев Презентация на тему: Повседневная жизнь земледельцев и горожан
Презентация на тему: Повседневная жизнь земледельцев и горожан ГБОУ детский сад № 184
ГБОУ детский сад № 184 Социальное проектирование как технология развития ключевых компетентностей школьника
Социальное проектирование как технология развития ключевых компетентностей школьника Обучение грамоте(дидактический материал)
Обучение грамоте(дидактический материал)