- Кластеризация данных

Содержание
- 2. 05.10.2006 СПбГУ ИТМО План доклада Основные определения Общая схема кластеризации Популярные алгоритмы Применения кластеризации
- 3. 05.10.2006 СПбГУ ИТМО Что такое кластеризация? Кластеризация – это автоматическое разбиение элементов некоторого множества (объекты, данные,
- 4. 05.10.2006 СПбГУ ИТМО Кластеризация (пример)
- 5. 05.10.2006 СПбГУ ИТМО Разница между кластеризацией и классификацией Кластеризация (unsupervised classification) разбивает множество объектов на группы,
- 6. 05.10.2006 СПбГУ ИТМО Зачем нужна кластеризация? Много практических применений в информатике и других областях: Анализ данных
- 7. 05.10.2006 СПбГУ ИТМО Формальные определения Вектор характеристик (объект) x – единица данных для алгоритма кластеризации. Обычно
- 8. 05.10.2006 СПбГУ ИТМО Формальные определения (продолжение) Множество объектов X = {x1, …, xn} – набор входных
- 9. 05.10.2006 СПбГУ ИТМО Постановка задачи Цель кластеризации – построить оптимальное разбиение объектов на группы: разбить N
- 10. 05.10.2006 СПбГУ ИТМО План доклада Основные определения Общая схема кластеризации Популярные алгоритмы Применения кластеризации
- 11. 05.10.2006 СПбГУ ИТМО Общая схема кластеризации Выделение характеристик Определение метрики Разбиение объектов на группы Представление результатов
- 12. 05.10.2006 СПбГУ ИТМО Выделение характеристик Выбор свойств, характеризующих объекты: количественные характеристики (координаты, интервалы…); качественные характеристики (цвет,
- 13. 05.10.2006 СПбГУ ИТМО Выбор метрики Метрика выбирается в зависимости от: пространства, где расположены объекты; неявных характеристик
- 14. 05.10.2006 СПбГУ ИТМО План доклада Основные определения Общая схема кластеризации Популярные алгоритмы Применения кластеризации
- 15. 05.10.2006 СПбГУ ИТМО Алгоритмы кластеризации Иерархические алгоритмы Минимальное покрывающее дерево k-Means алгоритм (алгоритм k-средних) Метод ближайшего
- 16. 05.10.2006 СПбГУ ИТМО Алгоритмы кластеризации (схема)
- 17. 05.10.2006 СПбГУ ИТМО Классификация алгоритмов Строящие «снизу-вверх» и «сверху-вниз» Монотетические и политетические Непересекающиеся и нечеткие Детерминированные
- 18. 05.10.2006 СПбГУ ИТМО Иерархические алгоритмы Результатом работы является дендограмма (иерархия), позволяющая разбить исходное множество объектов на
- 19. 05.10.2006 СПбГУ ИТМО Single-link (пример)
- 20. 05.10.2006 СПбГУ ИТМО Сравнение Single-link и Complete-link
- 21. 05.10.2006 СПбГУ ИТМО Минимальное покрывающее дерево Позволяет производить иерархическую кластеризацию «сверху-вниз»:
- 22. 05.10.2006 СПбГУ ИТМО k-Means алгоритм Случайно выбрать k точек, являющихся начальными «центрами масс» кластеров (любые k
- 23. 05.10.2006 СПбГУ ИТМО k-Means алгоритм (продолжение) В качестве критерия остановки обычно выбирают один из двух: Отсутствие
- 24. 05.10.2006 СПбГУ ИТМО Метод ближайшего соседа Один из старейших (1978), простейших и наименее оптимальных алгоритмов: Пока
- 25. 05.10.2006 СПбГУ ИТМО Нечеткая кластеризация Непересекающаяся (четкая) кластеризация относит объект только к одному кластеру. Нечеткая кластеризация
- 26. 05.10.2006 СПбГУ ИТМО Схема нечеткой кластеризации Выбрать начальное нечеткое разбиение n объектов на k кластеров путем
- 27. 05.10.2006 СПбГУ ИТМО Применение нейронных сетей Искусственные нейронные сети (ИНС) легко работают в распределенных системах в
- 28. 05.10.2006 СПбГУ ИТМО Генетические алгоритмы Выбрать начальную случайную популяцию для множества решений. Получить оценку качества для
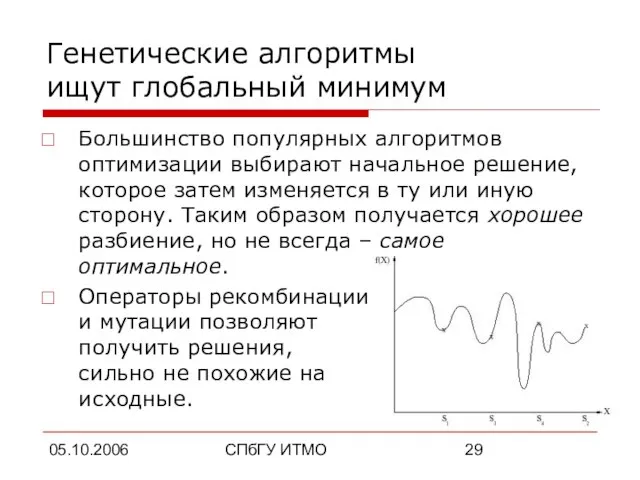
- 29. 05.10.2006 СПбГУ ИТМО Генетические алгоритмы ищут глобальный минимум Большинство популярных алгоритмов оптимизации выбирают начальное решение, которое
- 30. 05.10.2006 СПбГУ ИТМО Метод закалки Пытается найти глобальный оптимум, однако работает только с одним текущим решением.
- 31. 05.10.2006 СПбГУ ИТМО Какой алгоритм выбрать? Генетические алгоритмы и искусственные нейронные сети хорошо распараллеливаются. Генетические алгоритмы
- 32. 05.10.2006 СПбГУ ИТМО Какой алгоритм выбрать? (продолжение) k-Means быстро работает и прост в реализации, но создает
- 33. 05.10.2006 СПбГУ ИТМО Априорное использование природы кластеров в алгоритмах Неявное использование: выбор соответствующих характеристик объектов из
- 34. 05.10.2006 СПбГУ ИТМО Кластеризация больших объемов данных Обычно используют k-Means или его гибридные модификации. Если множество
- 35. 05.10.2006 СПбГУ ИТМО Разделяй и властвуй (пример)
- 36. 05.10.2006 СПбГУ ИТМО Алгоритм Leader (пример)
- 37. 05.10.2006 СПбГУ ИТМО Представление результатов Обычно используется один из следующих способов: представление кластеров центроидами; представление кластеров
- 38. 05.10.2006 СПбГУ ИТМО План доклада Основные определения Общая схема кластеризации Популярные алгоритмы Применения кластеризации
- 39. 05.10.2006 СПбГУ ИТМО Применения кластеризации Анализ данных (Data mining) Упрощение работы с информацией Визуализация данных Группировка
- 40. 05.10.2006 СПбГУ ИТМО Анализ данных (Data mining) Упрощение работы с информацией: достаточно работать только с k
- 41. 05.10.2006 СПбГУ ИТМО http://www.nigma.ru (пример)
- 42. 05.10.2006 СПбГУ ИТМО Группировка и распознавание объектов Распознавание образов (OCR и др.): построение кластеров на основе
- 43. 05.10.2006 СПбГУ ИТМО Сегментация изображений (пример)
- 44. 05.10.2006 СПбГУ ИТМО Извлечение и поиск информации (на примере книг в библиотеке) LCC (Library of Congress
- 45. 05.10.2006 СПбГУ ИТМО Итого Кластеризация – это автоматическое разбиение множества объектов на группы по принципу схожести
- 47. Скачать презентацию
Слайд 205.10.2006
СПбГУ ИТМО
План доклада
Основные определения
Общая схема кластеризации
Популярные алгоритмы
Применения кластеризации
05.10.2006
СПбГУ ИТМО
План доклада
Основные определения
Общая схема кластеризации
Популярные алгоритмы
Применения кластеризации

Слайд 305.10.2006
СПбГУ ИТМО
Что такое кластеризация?
Кластеризация – это автоматическое разбиение элементов некоторого множества (объекты,
05.10.2006
СПбГУ ИТМО
Что такое кластеризация?
Кластеризация – это автоматическое разбиение элементов некоторого множества (объекты,

Слайд 405.10.2006
СПбГУ ИТМО
Кластеризация (пример)
05.10.2006
СПбГУ ИТМО
Кластеризация (пример)
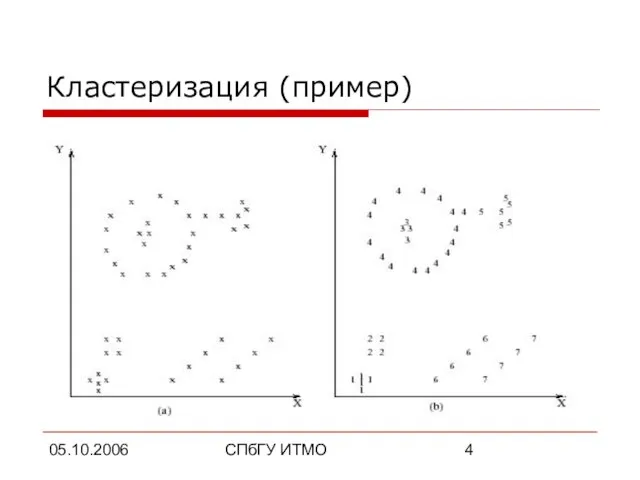
Слайд 505.10.2006
СПбГУ ИТМО
Разница между
кластеризацией и классификацией
Кластеризация (unsupervised classification) разбивает множество объектов на группы,
05.10.2006
СПбГУ ИТМО
Разница между
кластеризацией и классификацией
Кластеризация (unsupervised classification) разбивает множество объектов на группы,

Слайд 605.10.2006
СПбГУ ИТМО
Зачем нужна кластеризация?
Много практических применений в информатике и других областях:
Анализ данных
05.10.2006
СПбГУ ИТМО
Зачем нужна кластеризация?
Много практических применений в информатике и других областях:
Анализ данных

Слайд 705.10.2006
СПбГУ ИТМО
Формальные определения
Вектор характеристик (объект) x – единица данных для алгоритма кластеризации.
05.10.2006
СПбГУ ИТМО
Формальные определения
Вектор характеристик (объект) x – единица данных для алгоритма кластеризации.

Слайд 805.10.2006
СПбГУ ИТМО
Формальные определения (продолжение)
Множество объектов X = {x1, …, xn} – набор
05.10.2006
СПбГУ ИТМО
Формальные определения (продолжение)
Множество объектов X = {x1, …, xn} – набор

Слайд 905.10.2006
СПбГУ ИТМО
Постановка задачи
Цель кластеризации – построить оптимальное разбиение объектов на группы:
разбить N
05.10.2006
СПбГУ ИТМО
Постановка задачи
Цель кластеризации – построить оптимальное разбиение объектов на группы:
разбить N

Слайд 1005.10.2006
СПбГУ ИТМО
План доклада
Основные определения
Общая схема кластеризации
Популярные алгоритмы
Применения кластеризации
05.10.2006
СПбГУ ИТМО
План доклада
Основные определения
Общая схема кластеризации
Популярные алгоритмы
Применения кластеризации

Слайд 1105.10.2006
СПбГУ ИТМО
Общая схема кластеризации
Выделение характеристик
Определение метрики
Разбиение объектов на группы
Представление результатов
05.10.2006
СПбГУ ИТМО
Общая схема кластеризации
Выделение характеристик
Определение метрики
Разбиение объектов на группы
Представление результатов
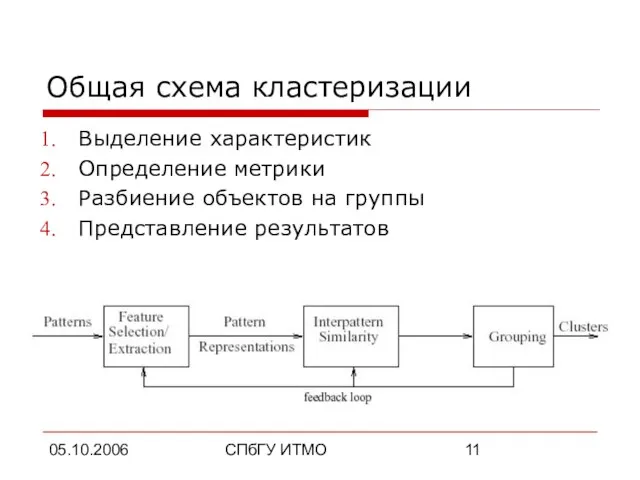
Слайд 1205.10.2006
СПбГУ ИТМО
Выделение характеристик
Выбор свойств, характеризующих объекты:
количественные характеристики (координаты, интервалы…);
качественные характеристики (цвет, статус,
05.10.2006
СПбГУ ИТМО
Выделение характеристик
Выбор свойств, характеризующих объекты:
количественные характеристики (координаты, интервалы…);
качественные характеристики (цвет, статус,

Слайд 1305.10.2006
СПбГУ ИТМО
Выбор метрики
Метрика выбирается в зависимости от:
пространства, где расположены объекты;
неявных характеристик кластеров.
Если
05.10.2006
СПбГУ ИТМО
Выбор метрики
Метрика выбирается в зависимости от:
пространства, где расположены объекты;
неявных характеристик кластеров.
Если

Слайд 1405.10.2006
СПбГУ ИТМО
План доклада
Основные определения
Общая схема кластеризации
Популярные алгоритмы
Применения кластеризации
05.10.2006
СПбГУ ИТМО
План доклада
Основные определения
Общая схема кластеризации
Популярные алгоритмы
Применения кластеризации

Слайд 1505.10.2006
СПбГУ ИТМО
Алгоритмы кластеризации
Иерархические алгоритмы
Минимальное покрывающее дерево
k-Means алгоритм (алгоритм k-средних)
Метод ближайшего соседа
Алгоритмы нечеткой
05.10.2006
СПбГУ ИТМО
Алгоритмы кластеризации
Иерархические алгоритмы
Минимальное покрывающее дерево
k-Means алгоритм (алгоритм k-средних)
Метод ближайшего соседа
Алгоритмы нечеткой

Слайд 1605.10.2006
СПбГУ ИТМО
Алгоритмы кластеризации (схема)
05.10.2006
СПбГУ ИТМО
Алгоритмы кластеризации (схема)
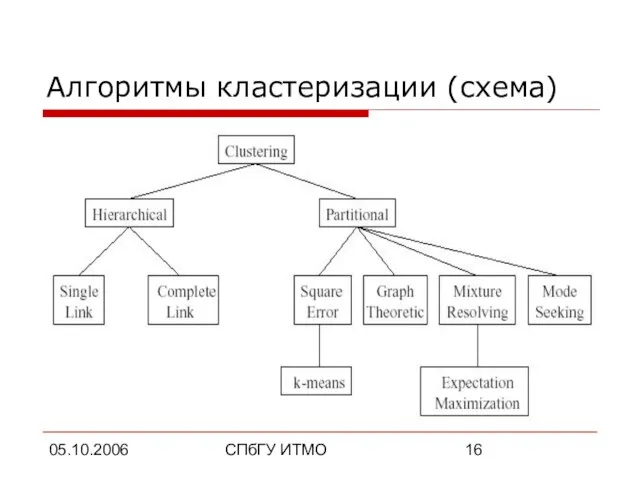
Слайд 1705.10.2006
СПбГУ ИТМО
Классификация алгоритмов
Строящие «снизу-вверх» и «сверху-вниз»
Монотетические и политетические
Непересекающиеся и нечеткие
Детерминированные и стохастические
Потоковые
05.10.2006
СПбГУ ИТМО
Классификация алгоритмов
Строящие «снизу-вверх» и «сверху-вниз»
Монотетические и политетические
Непересекающиеся и нечеткие
Детерминированные и стохастические
Потоковые

Слайд 1805.10.2006
СПбГУ ИТМО
Иерархические алгоритмы
Результатом работы является дендограмма (иерархия), позволяющая разбить исходное множество объектов
05.10.2006
СПбГУ ИТМО
Иерархические алгоритмы
Результатом работы является дендограмма (иерархия), позволяющая разбить исходное множество объектов

Слайд 1905.10.2006
СПбГУ ИТМО
Single-link (пример)
05.10.2006
СПбГУ ИТМО
Single-link (пример)
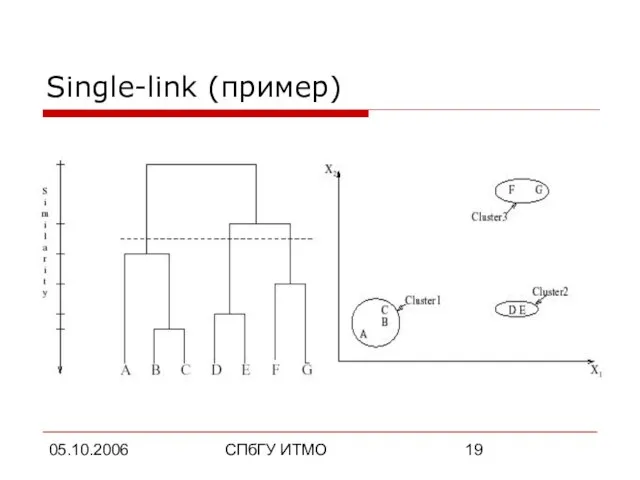
Слайд 2005.10.2006
СПбГУ ИТМО
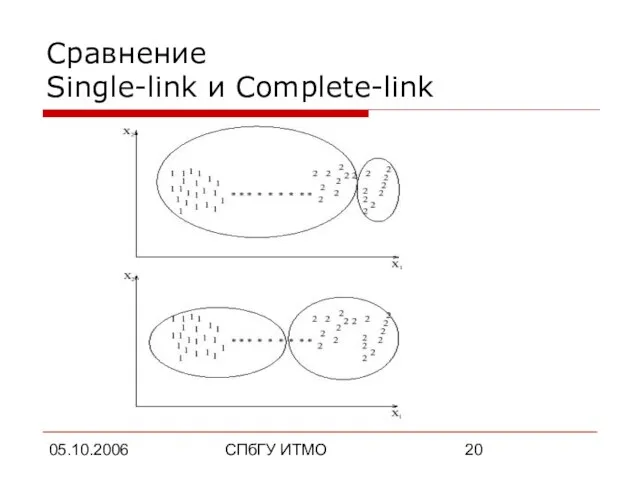
Сравнение
Single-link и Complete-link
05.10.2006
СПбГУ ИТМО
Сравнение
Single-link и Complete-link
Слайд 2105.10.2006
СПбГУ ИТМО
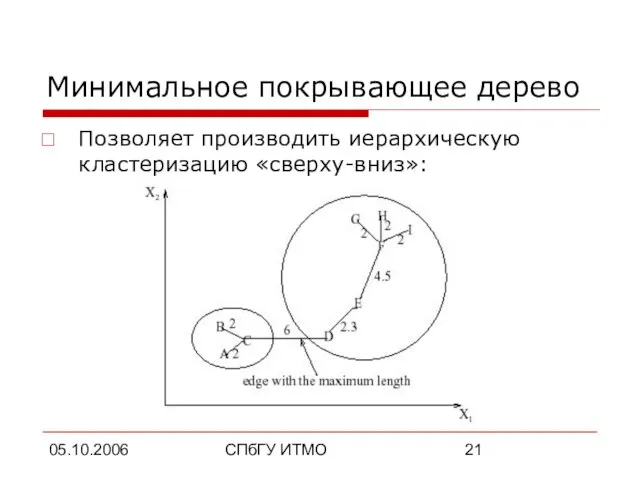
Минимальное покрывающее дерево
Позволяет производить иерархическую кластеризацию «сверху-вниз»:
05.10.2006
СПбГУ ИТМО
Минимальное покрывающее дерево
Позволяет производить иерархическую кластеризацию «сверху-вниз»:
Слайд 2205.10.2006
СПбГУ ИТМО
k-Means алгоритм
Случайно выбрать k точек, являющихся начальными «центрами масс» кластеров (любые
05.10.2006
СПбГУ ИТМО
k-Means алгоритм
Случайно выбрать k точек, являющихся начальными «центрами масс» кластеров (любые

Слайд 2305.10.2006
СПбГУ ИТМО
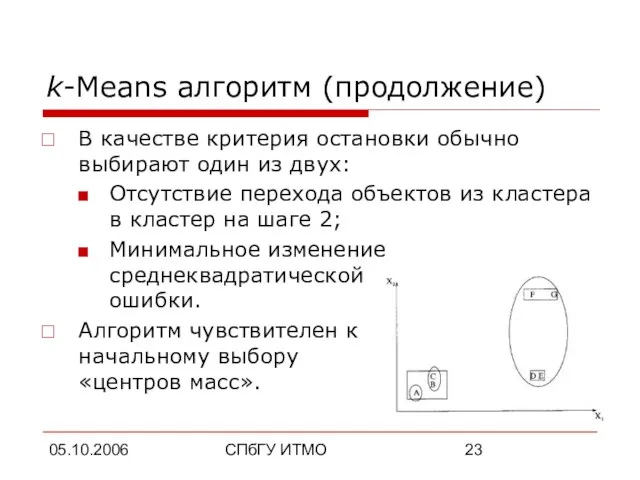
k-Means алгоритм (продолжение)
В качестве критерия остановки обычно выбирают один из двух:
Отсутствие
05.10.2006
СПбГУ ИТМО
k-Means алгоритм (продолжение)
В качестве критерия остановки обычно выбирают один из двух:
Отсутствие
Слайд 2405.10.2006
СПбГУ ИТМО
Метод ближайшего соседа
Один из старейших (1978), простейших и наименее оптимальных алгоритмов:
Пока
05.10.2006
СПбГУ ИТМО
Метод ближайшего соседа
Один из старейших (1978), простейших и наименее оптимальных алгоритмов:
Пока

Слайд 2505.10.2006
СПбГУ ИТМО
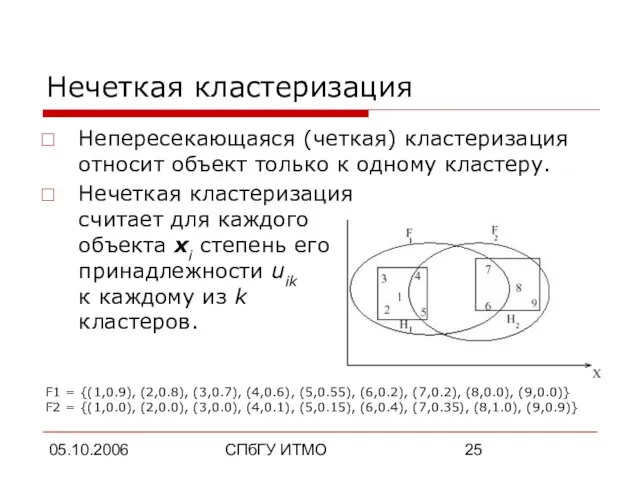
Нечеткая кластеризация
Непересекающаяся (четкая) кластеризация относит объект только к одному кластеру.
Нечеткая кластеризация
считает
05.10.2006
СПбГУ ИТМО
Нечеткая кластеризация
Непересекающаяся (четкая) кластеризация относит объект только к одному кластеру.
Нечеткая кластеризация
считает
Слайд 2605.10.2006
СПбГУ ИТМО
Схема нечеткой кластеризации
Выбрать начальное нечеткое разбиение n объектов на k кластеров
05.10.2006
СПбГУ ИТМО
Схема нечеткой кластеризации
Выбрать начальное нечеткое разбиение n объектов на k кластеров

Слайд 2705.10.2006
СПбГУ ИТМО
Применение нейронных сетей
Искусственные нейронные сети (ИНС) легко работают в распределенных системах
05.10.2006
СПбГУ ИТМО
Применение нейронных сетей
Искусственные нейронные сети (ИНС) легко работают в распределенных системах

Слайд 2805.10.2006
СПбГУ ИТМО
Генетические алгоритмы
Выбрать начальную случайную популяцию для множества решений. Получить оценку качества
05.10.2006
СПбГУ ИТМО
Генетические алгоритмы
Выбрать начальную случайную популяцию для множества решений. Получить оценку качества

Слайд 2905.10.2006
СПбГУ ИТМО
Генетические алгоритмы
ищут глобальный минимум
Большинство популярных алгоритмов оптимизации выбирают начальное решение, которое
05.10.2006
СПбГУ ИТМО
Генетические алгоритмы
ищут глобальный минимум
Большинство популярных алгоритмов оптимизации выбирают начальное решение, которое
Слайд 3005.10.2006
СПбГУ ИТМО
Метод закалки
Пытается найти глобальный оптимум, однако работает только с одним текущим
05.10.2006
СПбГУ ИТМО
Метод закалки
Пытается найти глобальный оптимум, однако работает только с одним текущим

Слайд 3105.10.2006
СПбГУ ИТМО
Какой алгоритм выбрать?
Генетические алгоритмы и искусственные нейронные сети хорошо распараллеливаются.
Генетические алгоритмы
05.10.2006
СПбГУ ИТМО
Какой алгоритм выбрать?
Генетические алгоритмы и искусственные нейронные сети хорошо распараллеливаются.
Генетические алгоритмы

Слайд 3205.10.2006
СПбГУ ИТМО
Какой алгоритм выбрать? (продолжение)
k-Means быстро работает и прост в реализации, но
05.10.2006
СПбГУ ИТМО
Какой алгоритм выбрать? (продолжение)
k-Means быстро работает и прост в реализации, но

Слайд 3305.10.2006
СПбГУ ИТМО
Априорное использование
природы кластеров в алгоритмах
Неявное использование:
выбор соответствующих характеристик объектов из всех
05.10.2006
СПбГУ ИТМО
Априорное использование
природы кластеров в алгоритмах
Неявное использование:
выбор соответствующих характеристик объектов из всех

Слайд 3405.10.2006
СПбГУ ИТМО
Кластеризация
больших объемов данных
Обычно используют k-Means или его гибридные модификации.
Если множество объектов
05.10.2006
СПбГУ ИТМО
Кластеризация
больших объемов данных
Обычно используют k-Means или его гибридные модификации.
Если множество объектов

Слайд 3505.10.2006
СПбГУ ИТМО
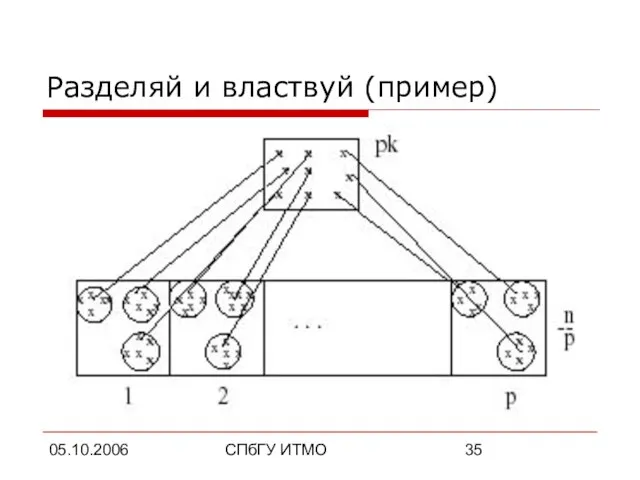
Разделяй и властвуй (пример)
05.10.2006
СПбГУ ИТМО
Разделяй и властвуй (пример)
Слайд 3605.10.2006
СПбГУ ИТМО
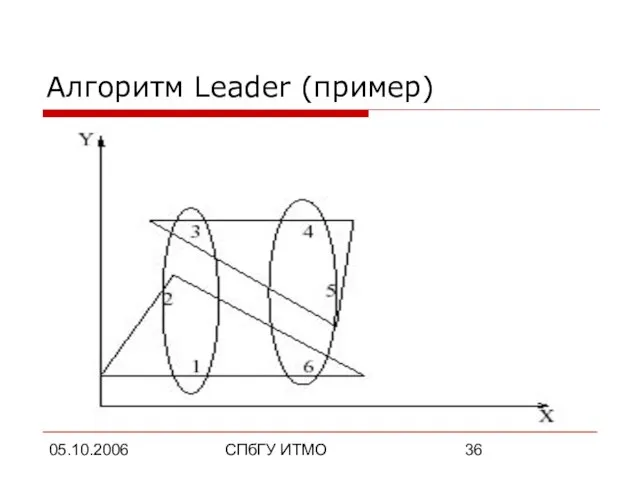
Алгоритм Leader (пример)
05.10.2006
СПбГУ ИТМО
Алгоритм Leader (пример)
Слайд 3705.10.2006
СПбГУ ИТМО
Представление результатов
Обычно используется один из следующих способов:
представление кластеров центроидами;
представление кластеров набором
05.10.2006
СПбГУ ИТМО
Представление результатов
Обычно используется один из следующих способов:
представление кластеров центроидами;
представление кластеров набором

Слайд 3805.10.2006
СПбГУ ИТМО
План доклада
Основные определения
Общая схема кластеризации
Популярные алгоритмы
Применения кластеризации
05.10.2006
СПбГУ ИТМО
План доклада
Основные определения
Общая схема кластеризации
Популярные алгоритмы
Применения кластеризации

Слайд 3905.10.2006
СПбГУ ИТМО
Применения кластеризации
Анализ данных (Data mining)
Упрощение работы с информацией
Визуализация данных
Группировка и распознавание
05.10.2006
СПбГУ ИТМО
Применения кластеризации
Анализ данных (Data mining)
Упрощение работы с информацией
Визуализация данных
Группировка и распознавание

Слайд 4005.10.2006
СПбГУ ИТМО
Анализ данных (Data mining)
Упрощение работы с информацией:
достаточно работать только с k
05.10.2006
СПбГУ ИТМО
Анализ данных (Data mining)
Упрощение работы с информацией:
достаточно работать только с k

Слайд 4105.10.2006
СПбГУ ИТМО
http://www.nigma.ru (пример)
05.10.2006
СПбГУ ИТМО
http://www.nigma.ru (пример)

Слайд 4205.10.2006
СПбГУ ИТМО
Группировка и распознавание объектов
Распознавание образов (OCR и др.):
построение кластеров на основе
05.10.2006
СПбГУ ИТМО
Группировка и распознавание объектов
Распознавание образов (OCR и др.):
построение кластеров на основе

Слайд 4305.10.2006
СПбГУ ИТМО
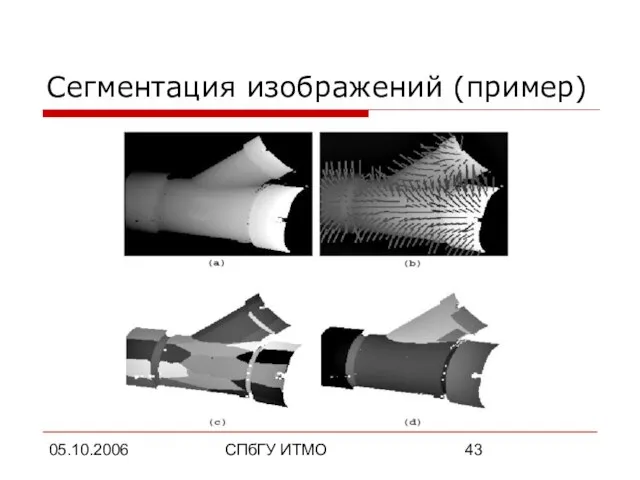
Сегментация изображений (пример)
05.10.2006
СПбГУ ИТМО
Сегментация изображений (пример)
Слайд 4405.10.2006
СПбГУ ИТМО
Извлечение и поиск информации
(на примере книг в библиотеке)
LCC (Library of Congress
05.10.2006
СПбГУ ИТМО
Извлечение и поиск информации
(на примере книг в библиотеке)
LCC (Library of Congress

Слайд 4505.10.2006
СПбГУ ИТМО
Итого
Кластеризация – это автоматическое разбиение множества объектов на группы по принципу
05.10.2006
СПбГУ ИТМО
Итого
Кластеризация – это автоматическое разбиение множества объектов на группы по принципу

 Особенности костюма жителей Дона» (на материале романа М. А. Шолохова «Тихий Дон»)
Особенности костюма жителей Дона» (на материале романа М. А. Шолохова «Тихий Дон») Витамины, БАД
Витамины, БАД Многообразие художественных культур в мире. Обобщение темы III четверти
Многообразие художественных культур в мире. Обобщение темы III четверти Работа школы по привитию навыков здорового образа жизни
Работа школы по привитию навыков здорового образа жизни КПД тепловых двигателей (10 класс)
КПД тепловых двигателей (10 класс) Конспект занятия по развитию речив подготовительной группе детского сада на тему: «Музей почтовых принадлежностей» (с использов
Конспект занятия по развитию речив подготовительной группе детского сада на тему: «Музей почтовых принадлежностей» (с использов Пугачевщина
Пугачевщина Основы фотографии. Главные фотографические термины и понятия
Основы фотографии. Главные фотографические термины и понятия Четыре среды жизни на Земле
Четыре среды жизни на Земле Загрязнение воздуха
Загрязнение воздуха Общество с ограниченной ответственностью «СОЮЗСТРОЙКОМПЛЕКС»
Общество с ограниченной ответственностью «СОЮЗСТРОЙКОМПЛЕКС» Презентация на тему ГЕНЕТИЧЕСКИЕ ОСНОВЫ СЕЛЕКЦИИ ОРГАНИЗМОВ
Презентация на тему ГЕНЕТИЧЕСКИЕ ОСНОВЫ СЕЛЕКЦИИ ОРГАНИЗМОВ  Объекты авторских прав
Объекты авторских прав У А Слог. Слоговой состав слова. ЯБЛОКО СКАКАЛКА.
У А Слог. Слоговой состав слова. ЯБЛОКО СКАКАЛКА. Уроки доброты по произведению В.Распутина «Уроки Французского»
Уроки доброты по произведению В.Распутина «Уроки Французского» Вопрос телесности в современном православном богословии
Вопрос телесности в современном православном богословии Интеллектуальная игра
Интеллектуальная игра Галерея изобретений В.Г. Шухова
Галерея изобретений В.Г. Шухова Алюминий
Алюминий 莎士比亚 大脑溜号的产物 弗洛依德 我们压抑的潜意识的反映
莎士比亚 大脑溜号的产物 弗洛依德 我们压抑的潜意识的反映 Материалы для дистанционной поддержки учащихся по дополнительной программе Шахматы для начинающих
Материалы для дистанционной поддержки учащихся по дополнительной программе Шахматы для начинающих Моя Родина - Россия
Моя Родина - Россия Organic Cocoon от компании Kitfort
Organic Cocoon от компании Kitfort Механические волны
Механические волны Организация документооборота в бухгалтерском учете
Организация документооборота в бухгалтерском учете ВОЗРОЖДЕНИЕ (Ренессанс) Торговая площадь (Гроте-маркт) и ратуша —
ВОЗРОЖДЕНИЕ (Ренессанс) Торговая площадь (Гроте-маркт) и ратуша —  Каша из топора.
Каша из топора. Имидж школы – ресурс устойчивого развития
Имидж школы – ресурс устойчивого развития