- Лекции: 60 часов. Лектор: В.П. Ипатов Email: [email protected] Упражнения и демонстрации: 20часов.

Содержание
- 2. Основные положения лекций
- 3. Лекция 1
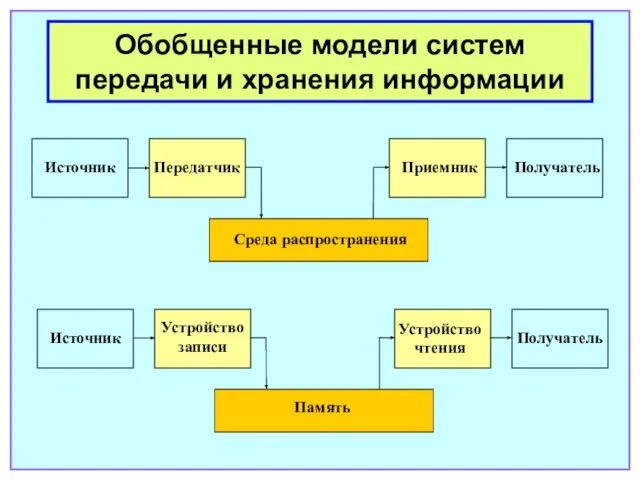
- 4. Источник Обобщенные модели систем передачи и хранения информации Передатчик Приемник Получатель Среда распространения Источник Получатель Память
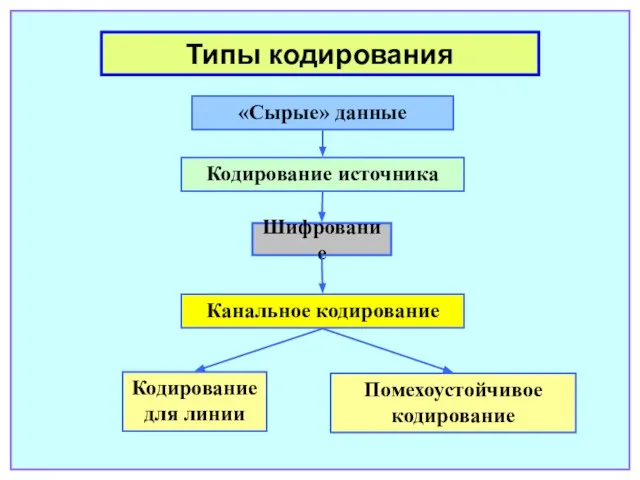
- 5. Типы кодирования «Сырые» данные Кодирование источника Канальное кодирование Шифрование Кодирование для линии Помехоустойчивое кодирование
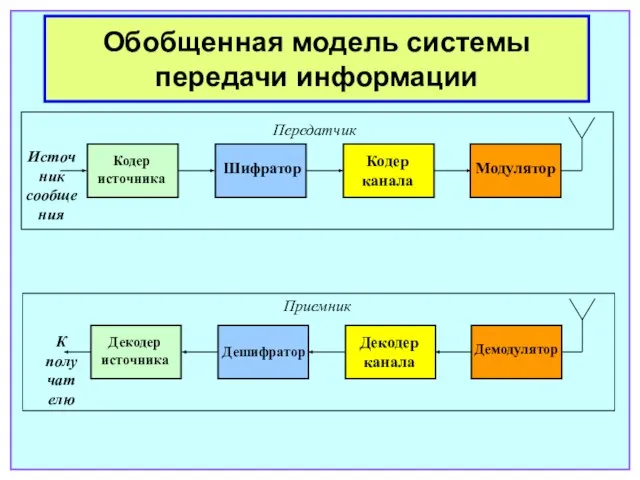
- 6. Обобщенная модель системы передачи информации Декодер источника Дешифратор Декодер канала Демодулятор К получателю Передатчик Приемник
- 7. Исторические вехи в теории и технике кодирования 1837: Электрический телеграф и код Морзе (S. Morse). 1875:
- 8. Некоторые вводные задачи
- 9. Лекция 2
- 10. 1. Источники сообщений, количество информации, энтропия 1.1. Идея определения количества информации С теоретической точки зрения любая
- 11. Рассматривая непрерывные источники, мы ограничимся только теми, несчетный ансамбль которых может быть ассоциирован с непрерывной случайной
- 12. Единственной функцией, удовлетворяющей этим трем аксиомам оказывается логарифм вероятности сообщения: 1.4. Энтропия дискретного источника Энтропия дискретного
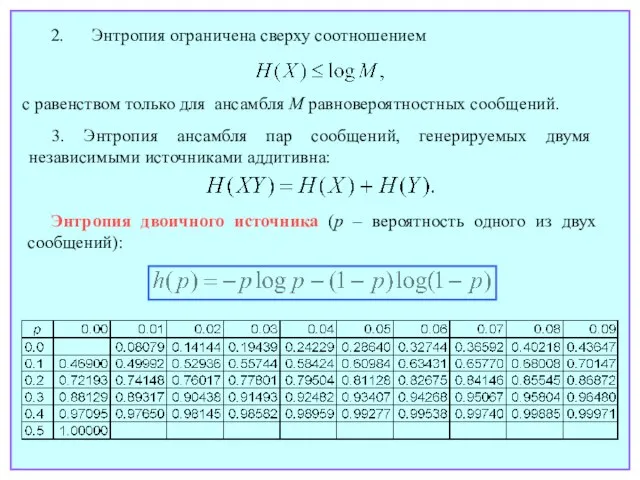
- 13. 2. Энтропия ограничена сверху соотношением 3. Энтропия ансамбля пар сообщений, генерируемых двумя независимыми источниками аддитивна: Энтропия
- 14. Энтропия двоичного источника в зависимости от p
- 15. Лекция 3
- 16. Источник Кодер источника Сообщения (буквы, блоки и т.п.) Кодовые слова 2. Кодирование источника 2.1. Основные определения
- 17. 2.2. Префиксные коды. Неравенство Крафта. Средняя длина кодового слова Идея экономии числа символов при неравномерном кодировании
- 18. x1 ⭢ 0 x2 ⭢ 10 x3 ⭢ 110 x4 ⭢ 111 Так, если последовательность на
- 19. Теорема 2.2.2. Средняя длина лучших префиксных кодов лежит в границах 2.3. Код Шеннона-Фано На первом шаге
- 20. Пример 2.3.1. Закодируем дискретный источник M=8 сообщений, имеющих вероятности, перечисленные в таблице. В данном случае logM
- 21. Лекция 4
- 22. 2.4. Код Хаффмена Этот код оптимален в том смысле, что ни один префиксный код не может
- 23. Пример 2.4.1. Закодируем по Хаффмену ансамбль из Примера 2.3.1: X p(x) x1 0.40 x2 0.20 x3
- 24. На практике источник генерирует сообщения (часто удобно называть их буквами) последовательно одно за другим. Возьмем блок
- 25. 2.6. Равномерное кодирование источника Неравномерное кодирование не всегда удобно. Нередки сценарии (например, цифровое вещание или мобильная
- 26. 2.7. Словарные коды. Алгоритм Лемпеля-Зива Рассмотренные ранее методы кодирования источника опираются на априорное знание вероятностей всех
- 27. своим адресом в словаре (2), и обновляющим символом 0. Все последующие шаги полностью аналогичны и понятны
- 28. Наряду с обновляющим символом 0 это дает новый вход словаря для фразы 10, помещаемой в третьей
- 29. Лекция 5
- 30. 2.8. Резюме. Примеры приложений Из вышесказанного следует, что генерируемые источником данные можно сжать (устранить их избыточность),
- 31. В настоящее время широко применяются как равномерное, так и неравномерное кодирование источника. Коды Хаффмена, например, входят
- 32. Многообразны и поучительны примеры применения методов адаптивного сжатия данных в кодировании речи, цифровом вещании, мобильных телефонах
- 33. В стандартах мобильной связи GSM, IS-95 и 3G используются вокодеры типов VSELP (vector-sum excited linear prediction
- 34. 3. Взаимная информация. Пропускная способность канала. Теоремы кодирования для канала 3.1. Математическое описание канала связи. Дискретный
- 35. Все каналы можно классифицировать на дискретные и непрерывные как по времени, так и по состоянию. Для
- 36. Пример 3.1.1. Двоичный симметричный канал (ДСК): p – вероятность ошибки на символ. Тем самым, ДКБП полностью
- 37. Лекция 6
- 38. 3.2. Взаимная информация, остаточная энтропия, пропускная способность канала Для канала, подверженного влиянию случайных помех, невозможно по
- 39. или, полагая p(y)p(x|y)=p(x,y), Так как до наблюдения неопределенность относительно входного ансамбля равнялась энтропии H(X), снижение неопределенности
- 40. Как видно, I(X;Y) показывает число битов информации о входе канала извлекаемое в среднем из выходного наблюдения,
- 41. Легко доказать симметрию взаимной и средней взаимной информации: I(x;y)=I(y;x); I(X;Y) =I(Y;X). Максимальное количество информации, которое можно
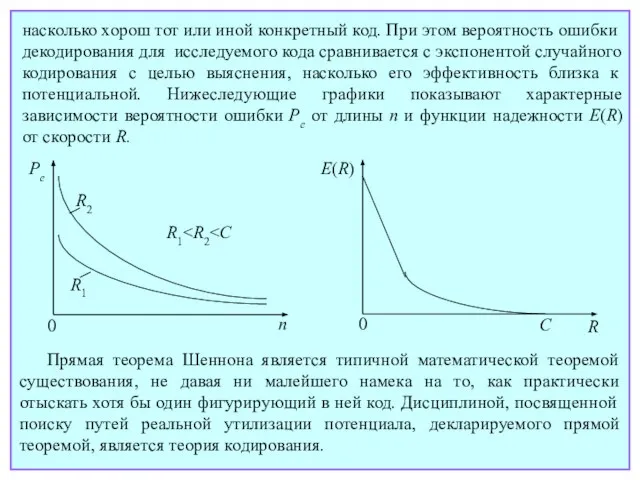
- 42. в каковом случае имеет место ошибка декодирования (ошибочное решение). Вероятность ошибки декодирования Pe и вероятность правильного
- 43. Лекция 7
- 44. 3.4. Теоремы кодирования для канала Пусть одно из M равновероятных сообщений, закодированное некоторым кодовым словом длины
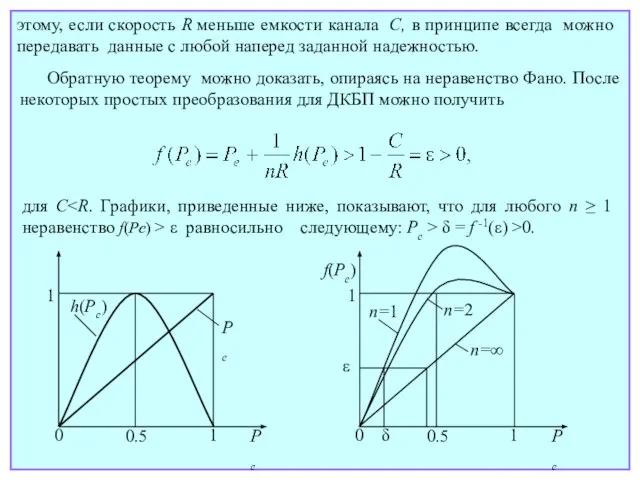
- 45. этому, если скорость R меньше емкости канала C, в принципе всегда можно передавать данные с любой
- 46. В отличие от обратной, доказательство прямой теоремы для общей модели канала без памяти достаточно трудоемко. Оно
- 47. Прямая теорема Шеннона является типичной математической теоремой существования, не давая ни малейшего намека на то, как
- 48. Лекция 8
- 49. 4. Расчет пропускной способности некоторых каналов 4.1. Дискретный канал без памяти Как следует из определения, пропускная
- 50. Для модели произвольного ДКБП подобная оптимизационная задача не имеет замкнутого аналитического решения. В то же время
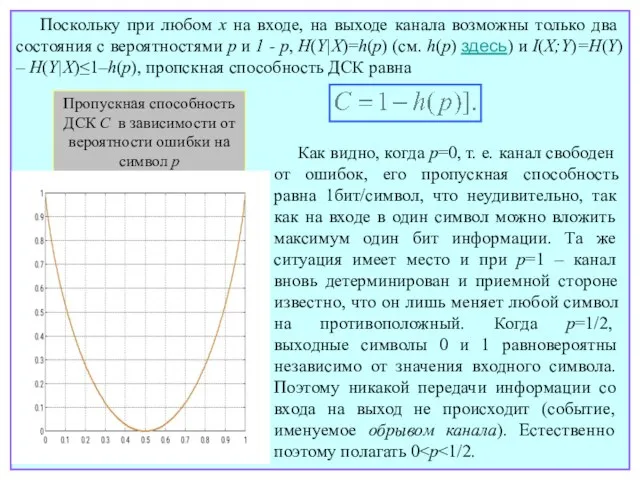
- 51. Поскольку при любом x на входе, на выходе канала возможны только два состояния с вероятностями p
- 52. Лекция 9
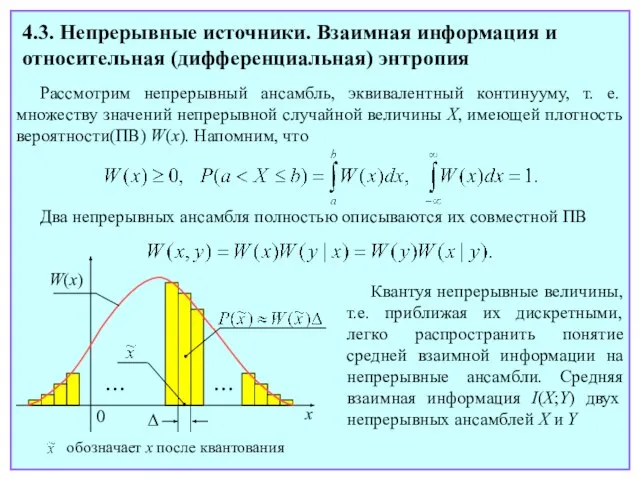
- 53. 4.3. Непрерывные источники. Взаимная информация и относительная (дифференциальная) энтропия Рассмотрим непрерывный ансамбль, эквивалентный континууму, т. е.
- 54. Дифференциальная (относительная) энтропия непрерывной величины X определяется равенством Таким образом, средняя взаимная информация между X и
- 55. 4.4. Пропускная способность непрерывного гауссовского канала Рассмотрим полностью непрерывный (по времени и состоянию) канал. На его
- 56. 0 f W N0 Спектральная плотность мощности шума τ N0W 0 Автокорреляционная функция шума Как теперь
- 57. придем к знаменитой формуле Шеннона для пропускной способности гауссовского канала: Этот результат показывает, что для увеличения
- 58. Вспомнив, что Ct - максимальная теоретически достижимая скорость Rt безошибочной передачи, введем число бит/с, передаваемых в
- 59. Лекция 10
- 60. 5. Введение в блоковые коды 5.1. Общая идея канального кодирования. Классификация кодов Как уже отмечалось, канальное
- 61. было передано, если решение выносится в пользу «ближайшего» (отличающегося в минимальном числе позиций от принятого пятисимвольного
- 62. В последующем тексте используются слегка измененные обозначения: U={u1, u2, … , uM} – канальный код, ui
- 63. Евклидово расстояние играет фундаментальную роль в теории и технике передачи сообщений. Чем дальше сигналы друг от
- 64. канала связи. На выходе канала наблюдается некоторое колебание y(t) (см.рисунок), являющееся переданным сигналом, искаженным канальным шумом.
- 65. кодового слова ui в наблюдаемый вектор y) падает с хэмминговым расстоянием di= dH (y,ui) между ui
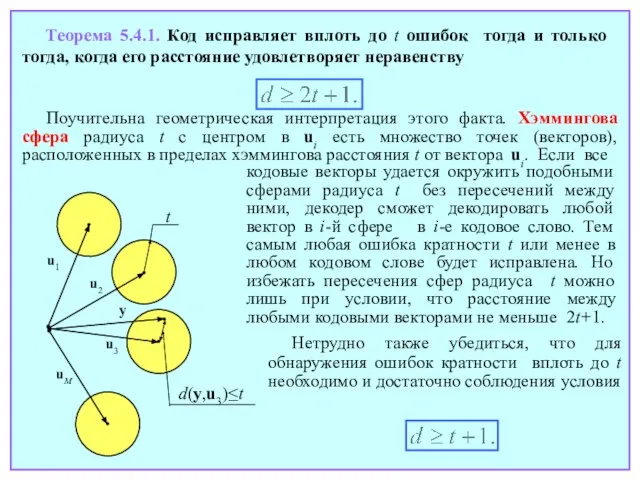
- 66. Теорема 5.4.1. Код исправляет вплоть до t ошибок тогда и только тогда, когда его расстояние удовлетворяет
- 67. Длина кода n вместе с объемом M и расстоянием d составляют тройку ключевых параметров блокового. Вместо
- 68. Лекция 11
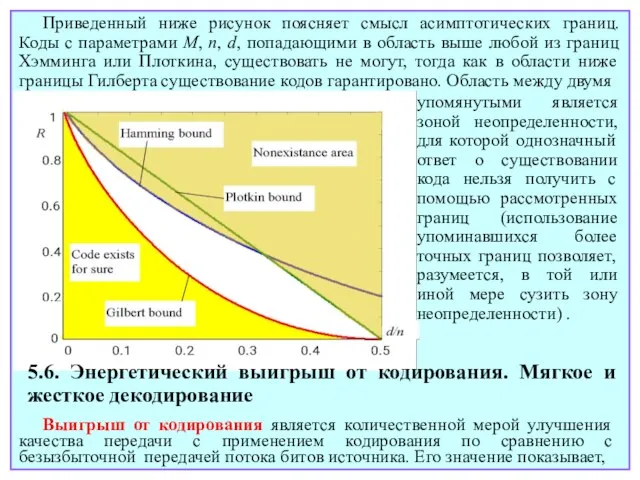
- 69. 5.5. Важнейшие границы теории кодирования Очевидно, особый интерес представляют коды с максимальным расстоянием при заданных длине
- 70. Близкое по смыслу ограничение устанавливается границей Плоткина. Теорема 5.5.2. (Граница Плоткина). Любой двоичный блоковый код подчиняется
- 71. Для больших длин n биномиальные коэффициенты в приведенных неравенствах можно аппроксимировать по Стирлингу, придя к асимптотическим
- 72. упомянутыми является зоной неопределенности, для которой однозначный ответ о существовании кода нельзя получить с помощью рассмотренных
- 73. во сколько раз можно уменьшить энергию сигнала за счет введения канального кодирования. Разумеется, при таком сопоставлении
- 74. квантованием непрерывного выхода демодулятора, после чего следуют те же операции, что и при мягком декодировании. Подобные
- 75. Лекция 12
- 76. 6. Линейные блоковые коды 6.1. Введение в конечные поля Конечным полям принадлежит основополагающая роль в теории
- 77. 3. В F присутствуют два нейтральных элемента – нуль (обозначаемый символом «0») и единица (обозначаемая как
- 78. Простейшие среди полей – числовые (рациональных или действительных чисел), содержащие бесконечно много элементов. Теория кодирования, однако,
- 79. 6.2. Векторные пространства над конечными полями Понятие векторного пространства, традиционно вводимое для случая скаляров в виде
- 80. 4. Умножение вектора на скаляр ассоциативно: 5. Умножение любого вектора на единичный скаляр (обязательно присутствующий в
- 81. Пусть в пространстве S выбраны m ненулевых векторов g1, g2,.., gm. Они называются линейно зависимыми, если
- 82. Лекция 13
- 83. 6.3. Линейные коды и их порождающие матрицы Рассмотрим множество S всех 2n n–компонентных векторов x=(x1, x2,
- 84. Вводя k–компонентный вектор сообщения (данных) a=(a1, a2, … , ak), любое слово u линейного кода U
- 85. 3. Теорема 6.3.1. Минимальное расстояние линейного кода равно наименьшему из весов ненулевых слов кода: Последний результат
- 86. где Ik – k×k единичная матрица, а P – матрица размерности k×(n–k). Порождающая матрица этого вида
- 87. Теорема 6.4.1. Линейный код U имеет минимальное расстояние d, если и только если любые d–1 столбцов
- 88. Лекция 14
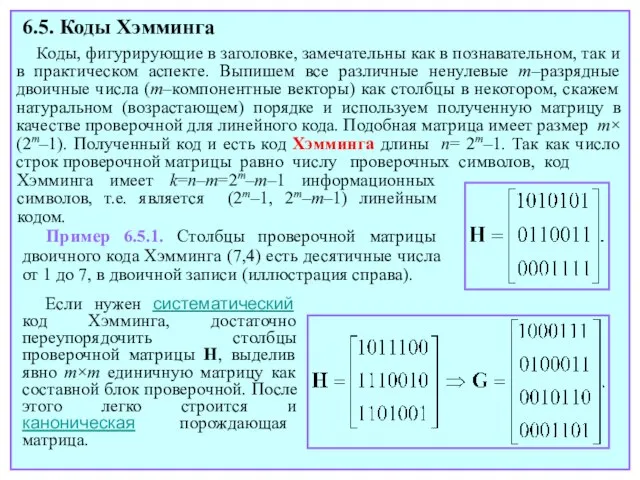
- 89. Коды, фигурирующие в заголовке, замечательны как в познавательном, так и в практическом аспекте. Выпишем все различные
- 90. Так как все столбцы матрицы H кода Хэмминга различны, любая их пара линейно независима, в то
- 91. исправляющий t=(d–1)/2 ошибок, можно трансформировать в расширенный (n+1, k) код, исправляющий ошибки прежней кратности t=(d–1)/2=(d´/2)–1 и,
- 92. уже встречавшегося в параграфе 5.1. Разумеется, этот код – подобно исходному коду Хэмминга – исправляет любую
- 93. Отметим, что коды U и U´ называются дуальными если порождающая матрица одного служит проверочной для другой.
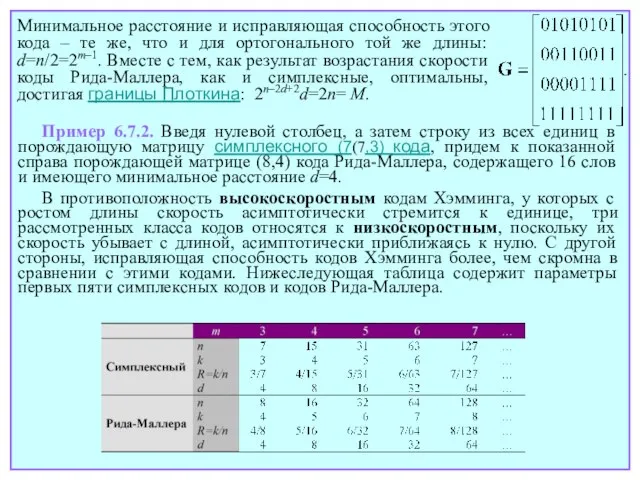
- 94. Минимальное расстояние и исправляющая способность этого кода – те же, что и для ортогонального той же
- 95. Лекция 15
- 96. 6.8. Синдромное декодирование линейных кодов Одним из оснований особой популярности линейных кодов является возможность преобразования для
- 97. Представим вектор наблюдения y как сумму переданного кодового вектора u и вектора ошибки e: В случае
- 98. экономия измерялась бы цифрами порядка 221 раз по обоим ресурсным показателям. В действительности же для декодирования
- 99. Лекция 16
- 100. 7. Циклические коды 7.1. Циклические коды. Кодовые полиномы. Полиномиальная арифметика Линейный блоковый код U длины называется
- 101. Рассмотрим основные правила арифметики формальных полиномов с коэффициентами из GF(q) (полиномов над GF(q)). Сложение двух полиномов
- 102. полиномов можно определить равенством, полностью заимствованным из «школьной» алгебры полиномов с действительными коэффициентами: a(z)=amzm+am-1zm–1 +…+a0, b(z)=blzl+bl-1zl–1+…+b0
- 103. где неотрицательное целое r , меньшее d , называется остатком (от деления a на d), q
- 104. делитель частное делимое остаток В теории циклических кодов важнейшая роль принадлежит остатку. Часто используемая символика означает,
- 105. Лекция 17
- 106. 7.2. Порождающий и проверочный полиномы циклического кода Возьмем кодовое слово u=(u0, u1, … , un–1) некоторого
- 107. Теорема 7.2.2. Порождающий полином циклического кода длины n является делителем бинома zn–1. Пример 7.2.1. Порождающими полиномами
- 108. только эти сомножители либо их произведения могут служить порождающими полиномами (7, k) кода, так что возможными
- 109. Сообщению (1110) отвечает информационный полином a(z)=z2+z+1. При этом кодовый полином, получаемый прямым перемножением a(z) и g(z):
- 110. после деления на g(z) дает остаток r(z)=z. В итоге u(z)= z5+z4+z3+z, и соответствующий кодовый вектор U=(0101110)
- 111. Лекция 18
- 112. 7.4. Порождающая и проверочная матрица циклического кода Как и любой линейный, циклический код может быть задан
- 113. Если систематичность кода не является непременным условием, порождающая матрица легко строится непосредственно по порождающему полиному: строки
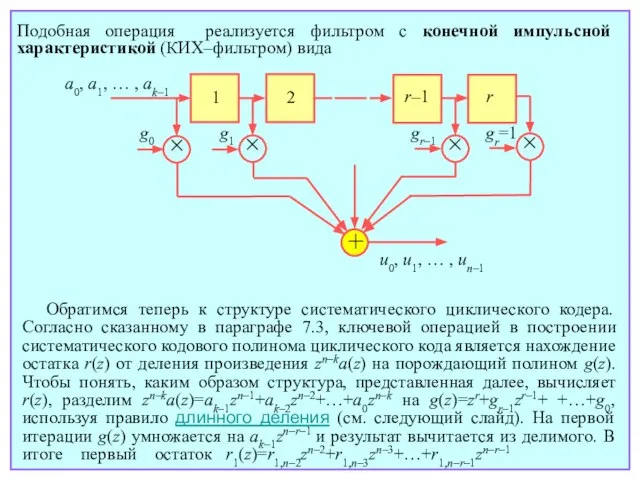
- 114. Обратимся теперь к структуре систематического циклического кодера. Согласно сказанному в параграфе 7.3, ключевой операцией в построении
- 115. имеет степень не более n–1 и после сложения с ak–2zn–2 используется на второй итерации как новое
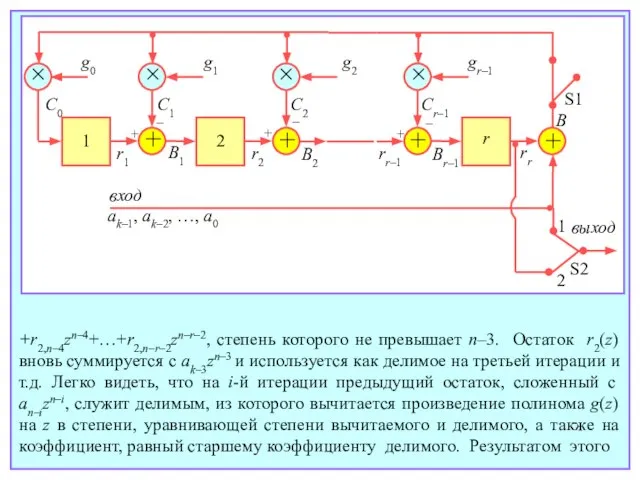
- 116. + + × + + g0 g1 g2 gr–1 1 2 r S1 S2 B 1
- 117. оказывается очередной остаток, с которым производятся те же действия на следующей итерации. После k итераций k-й
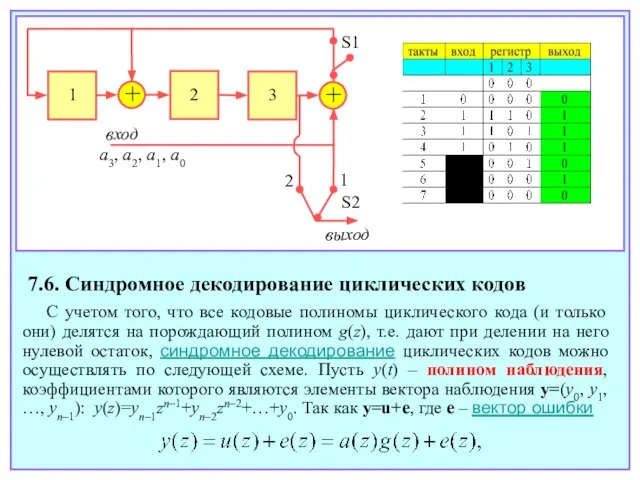
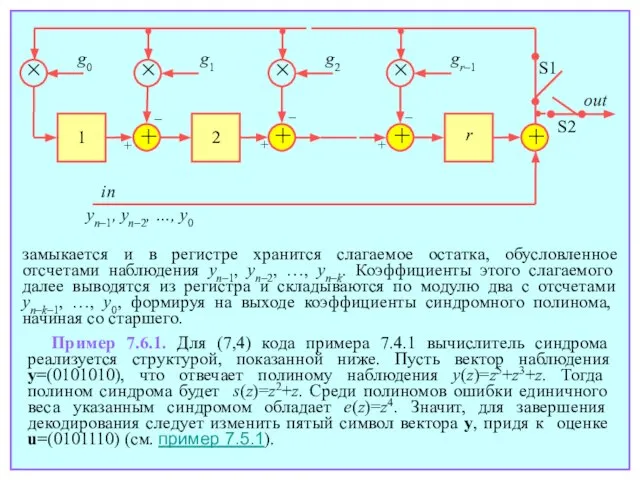
- 118. 7.6. Синдромное декодирование циклических кодов С учетом того, что все кодовые полиномы циклического кода (и только
- 119. где, в свою очередь, e(z)=en–1zn–1+en–2zn–2+…+e0 – полином ошибки. Назовем синдромным полиномом или просто синдромом s(z) остаток
- 120. + + g0 g1 1 2 in yn–1, yn–2, …, y0 + + g2 gr–1 r
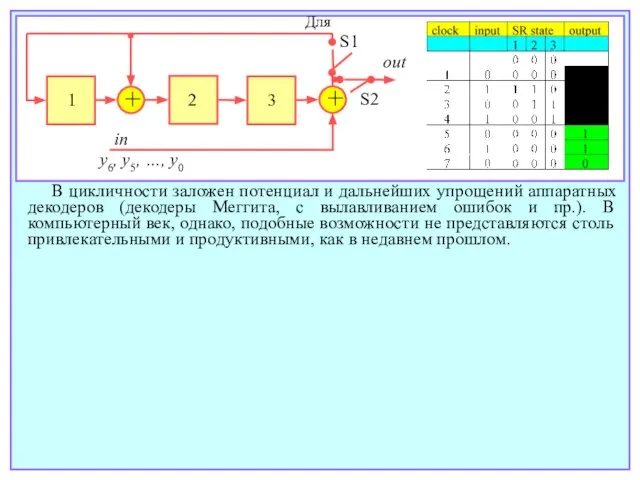
- 121. + + S1 S2 out in y6, y5, …, y0 1 2 3 В цикличности заложен
- 122. Лекция 19
- 123. 8. Коды БЧХ и Рида-Соломона 8.1. Расширенные конечные поля Как уже известно, конечные поля существуют только
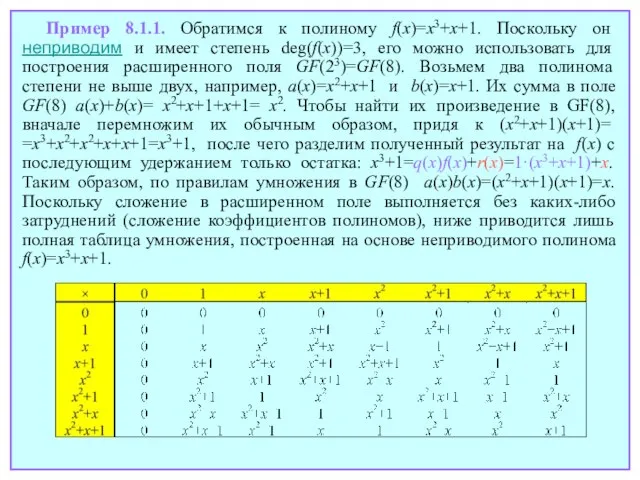
- 124. Пример 8.1.1. Обратимся к полиному f(x)=x3+x+1. Поскольку он неприводим и имеет степень deg(f(x))=3, его можно использовать
- 125. Отметим, что в числе полиномов степени не выше m–1 присутствуют и полиномы нулевой степени, т.е. элементы
- 126. и для любого ненулевого α Таким образом, в конечных полях действуют те же правила обращения с
- 127. Теорема 8.2.1. Мультипликативный порядок любого ненулевого элемента поля GF(q) делит q–1, т.е. число ненулевых элементов GF(q).
- 128. Пример 8.2.4. В поле GF(8) (см. пример 8.2.2) все ненулевые элементы поля за исключением единицы примитивны,
- 129. Отсюда ςm+1= ς·ςm= ς(–fm-1ςm–1–fm–2ςm–2–…–f0)=–fm–1ςm–fm–2ςm–1–…–f0ς. В правой части этого равенства вновь подставим ςm= – fm–1ςm–1– fm-2ςm–2–…–f0, придя
- 130. 8.3. Некоторые свойства расширенных конечных полей Установим в данном параграфе некоторые вспомогательные результаты, которые в дальнейшем
- 131. называются сопряженными с элементом α. Их роль в конечных полях, как вскоре выяснится, весьма близка к
- 132. 8.4. Построение полиномов с заданными корнями Одно из фундаментальных положений классической алгебры утверждает, что любой полином
- 133. g(z) имеет корень α (лежащий) в расширении GF(2m). Пример 8.4.1. Рассмотрим полином g(z)=z3+z2+1. Легко убедиться, что
- 134. где все q–1 ненулевых элементов GF(q) выражены как степени примитивного элемента ς. Теорема 8.4.3. Пусть GF(q)
- 135. Лекция 20
- 136. 8.5. Двоичные БЧХ-коды Накопленные к данному моменту знания открывают путь к ознакомлению с одним из наиболее
- 137. и не может быть вырожденной, если все элементы первой строки различны. Но последнее имеет место всегда,
- 138. корнями порождающего полинома. Любой из них, однако, должен войти в число корней порождающего полинома только вместе
- 139. Гарантией того, что построенный таким образом полином можно использовать как порождающий для циклического кода, служит делимость
- 140. Разумеется, в наши дни системный дизайнер свободен от необходимости поиска порождающих полиномов БЧХ-кодов, поскольку подобная работа
- 141. Пример 8.5.3. Найдем точное число информационных бит БЧХ-кода длины n=31, исправляющего до 5 ошибок. Корнями его
- 142. Лекция 21
- 143. 8.6. Коды Рида-Соломона Если при построении порождающего полинома g(z) согласно теореме БЧХ игнорировать сопряженные циклы элементов
- 144. где свобода выбора числа информационных символов k ограничена лишь одним: с увеличением k на единицу кодовое
- 145. Коды БЧХ и РС находят широкое применение в современных информационных системах. Приведем лишь несколько поучительных примеров.
- 146. укороченных (32,28) и (28,24) кодов РС. Стандарт цифрового телевизионного вещания DVB-T (Digital Video Broadcasting-Terrestrial) включает (204,188)
- 147. 9. Введение в сверточные коды 9.1. Основные определения Наряду с блоковыми кодами, рассмотренными в главах 5–8,
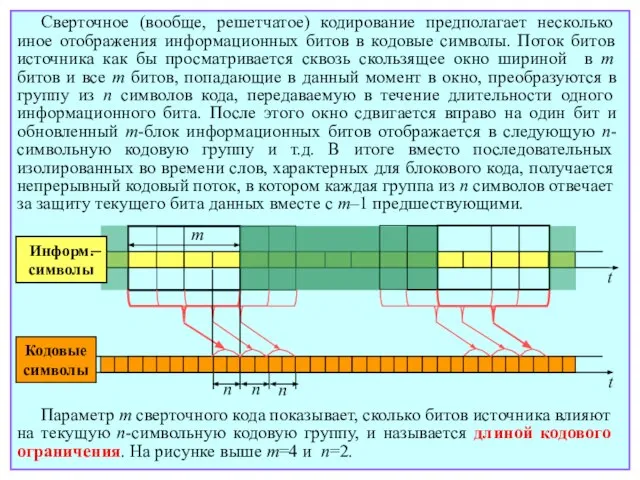
- 148. Сверточное (вообще, решетчатое) кодирование предполагает несколько иное отображения информационных битов в кодовые символы. Поток битов источника
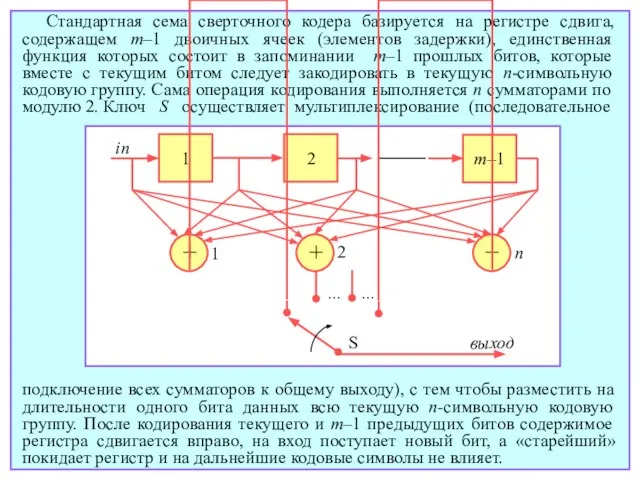
- 149. Стандартная сема сверточного кодера базируется на регистре сдвига, содержащем m–1 двоичных ячеек (элементов задержки), единственная функция
- 150. Если подать на вход этого устройства k информационных битов, на выходе появится последовательность длиной не kn,
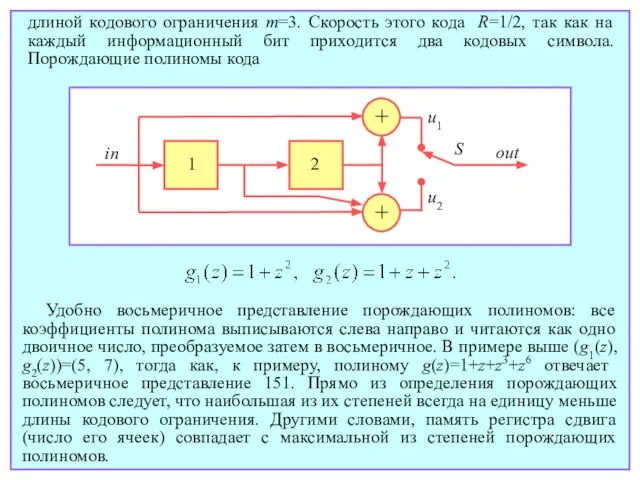
- 151. длиной кодового ограничения m=3. Скорость этого кода R=1/2, так как на каждый информационный бит приходится два
- 152. Нетрудно убедиться в линейности сверточных кодов. Более того, само их название связано с тем, что сверточный
- 153. Лекция 22
- 154. 9.2. Диаграмма состояний и решетчатая диаграмма сверточного кода. Свободное расстояние Любой сверточный кодер можно трактовать как
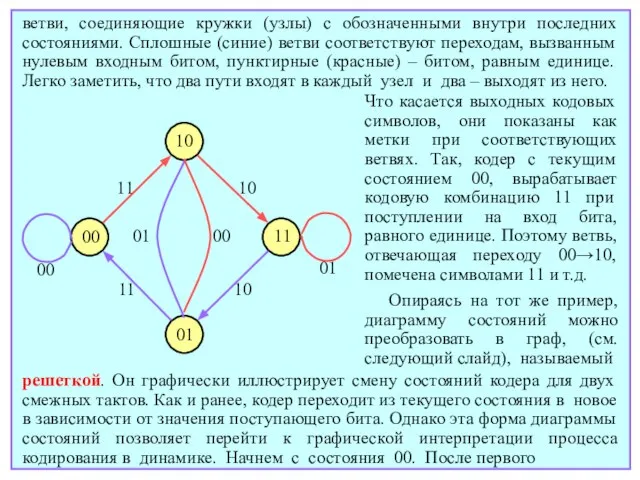
- 155. ветви, соединяющие кружки (узлы) с обозначенными внутри последних состояниями. Сплошные (синие) ветви соответствуют переходам, вызванным нулевым
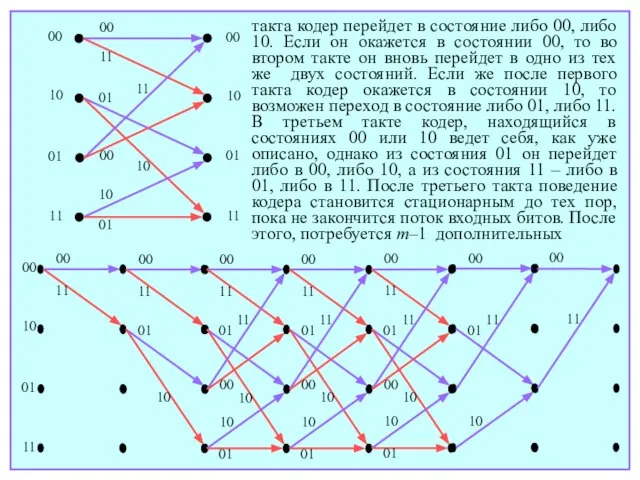
- 156. такта кодер перейдет в состояние либо 00, либо 10. Если он окажется в состоянии 00, то
- 157. тактов для обнуления кодера, в течение которых генерирование кодовых символов будет продолжаться. Построенный таким образом граф
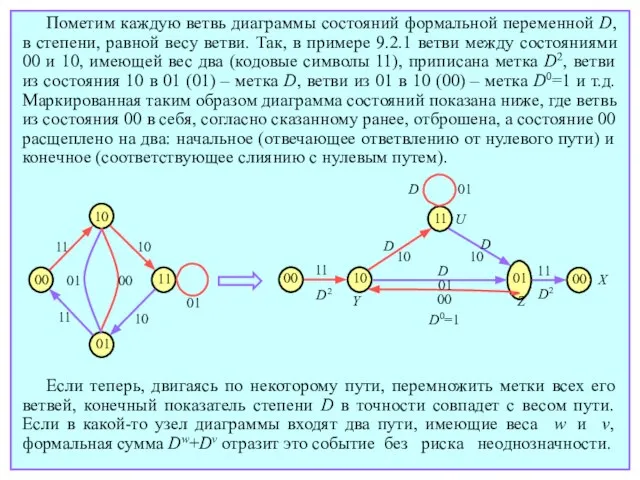
- 158. Пометим каждую ветвь диаграммы состояний формальной переменной D, в степени, равной весу ветви. Так, в примере
- 159. Так как движение по ветвям диаграммы есть рекуррентный, пошаговый процесс, вес пути на данном шаге можно
- 160. показывающей, что рассматриваемый код имеет свободное расстояние df=5: из нулевого состояния выходит единственный путь веса пять,
- 161. откуда видно, что в рассматриваемом коде присутствуют один путь длины 3 и веса 5, кодирующий блок
- 162. Лекция 23
- 163. 9.4. Алгоритм декодирования Витерби Рекурсивная природа сверточного кодирования лежит в основе также рекурсивного и ресурсно-экономного алгоритма
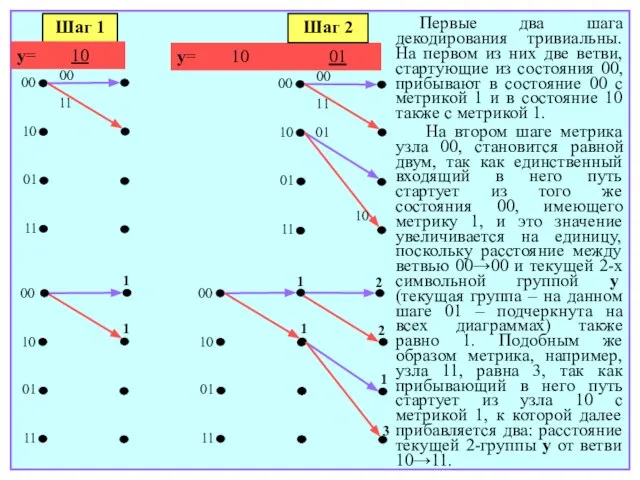
- 164. 1. Вычисляются хэмминговы расстояния от принятой n-символьной группы до каждой из ветвей решетчатой диаграммы. Так как
- 165. 00 10 01 11 00 11 Шаг 1 y= 10 00 10 01 11 1 1
- 166. 00 10 01 11 2 2 1 3 00 10 01 11 00 01 00 01
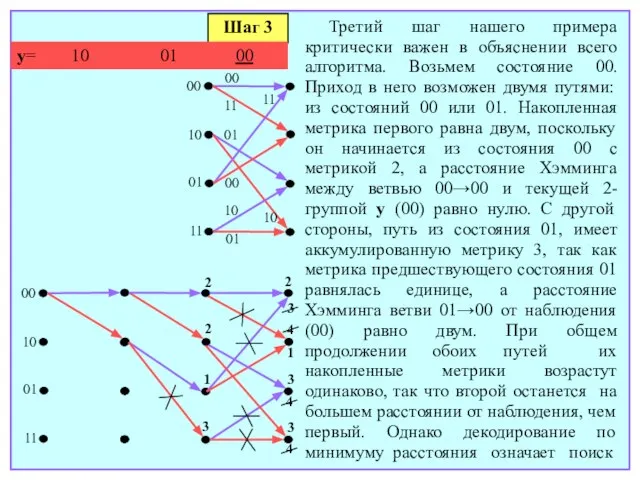
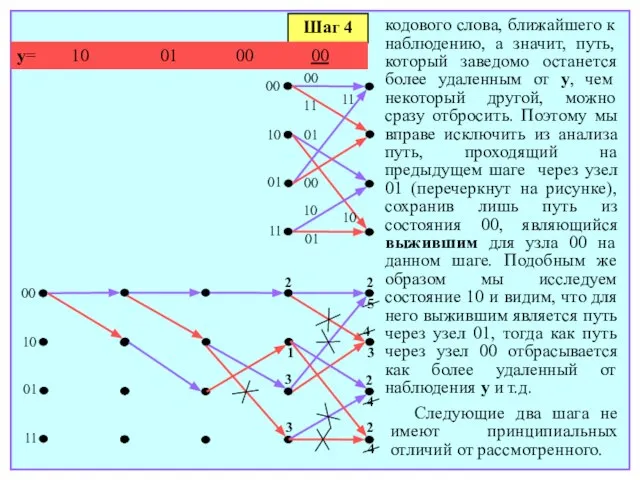
- 167. кодового слова, ближайшего к наблюдению, а значит, путь, который заведомо останется более удаленным от y, чем
- 168. Шаг 5 y= 10 01 00 00 00 00 10 01 11 00 10 01 11
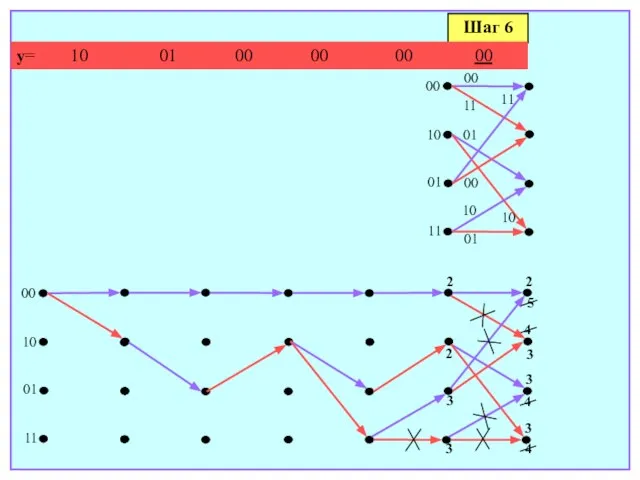
- 169. Шаг 6 y= 10 01 00 00 00 00 00 10 01 11 00 10 01
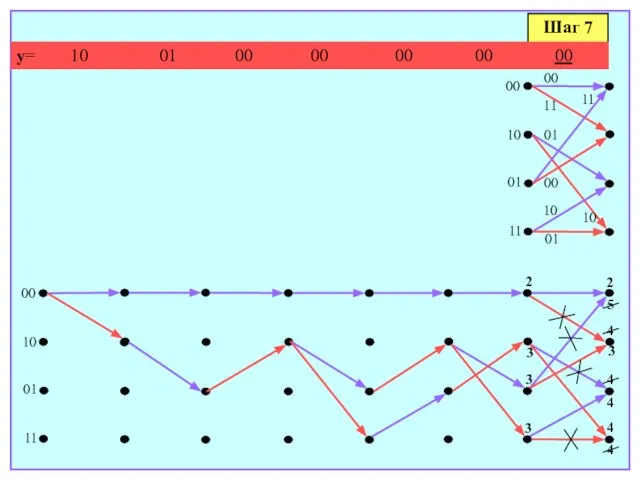
- 170. Шаг 7 y= 10 01 00 00 00 00 00 00 10 01 11 00 10
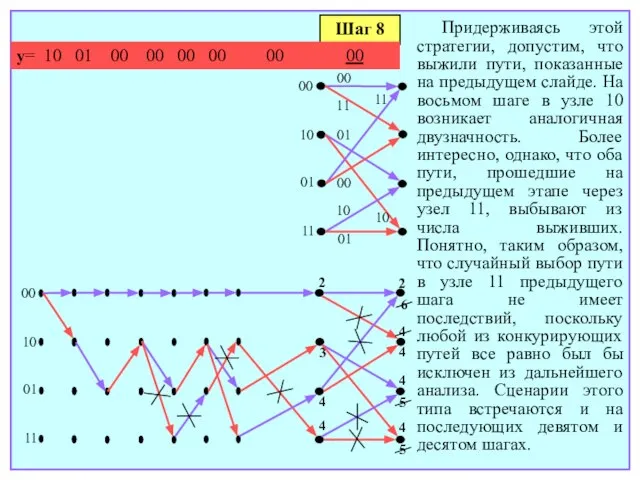
- 171. Шаг 8 y= 10 01 00 00 00 00 00 00 00 10 01 11 00
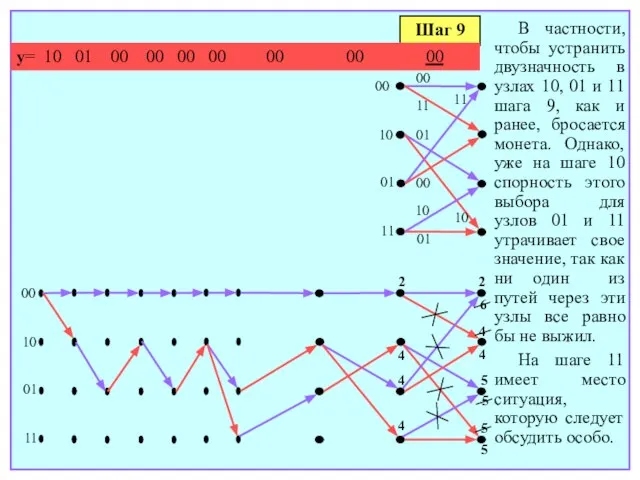
- 172. Шаг 9 y= 10 01 00 00 00 00 00 00 00 00 10 01 11
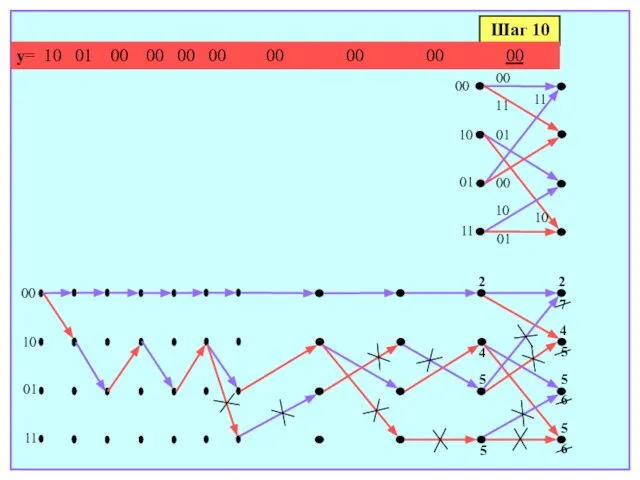
- 173. Шаг 10 y= 10 01 00 00 00 00 00 00 00 00 00 10 01
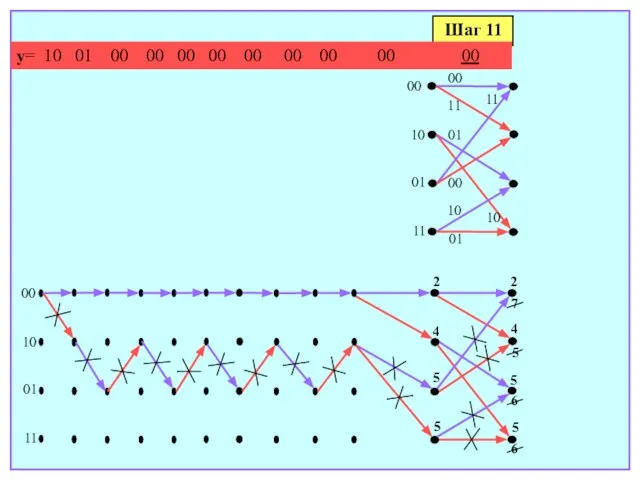
- 174. Шаг 11 y= 10 01 00 00 00 00 00 00 00 00 00 00 10
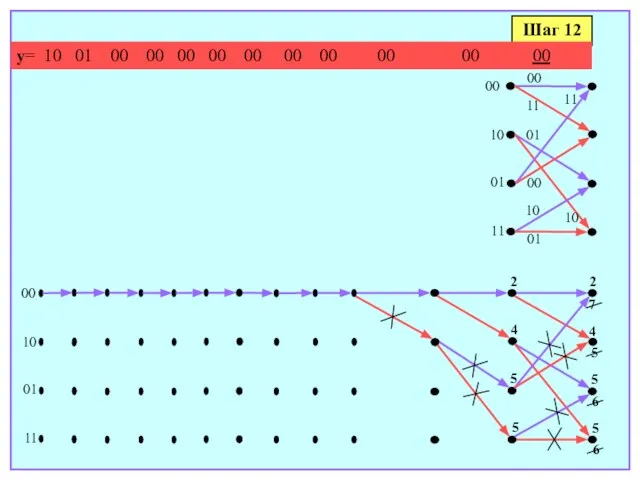
- 175. Шаг 12 y= 10 01 00 00 00 00 00 00 00 00 00 00 00
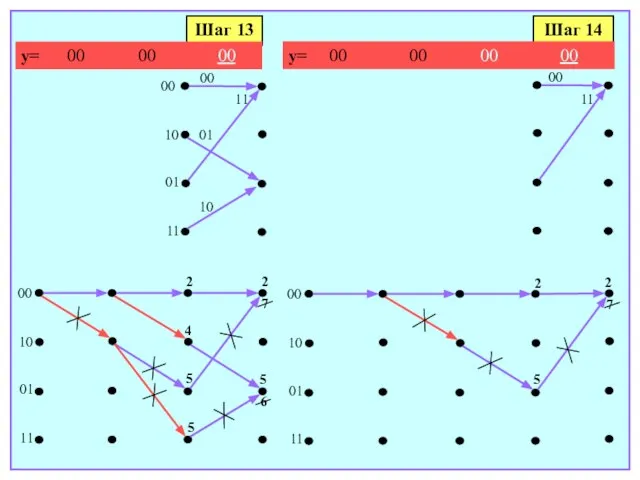
- 176. Шаг 14 00 11 Шаг 13 2 5 4 5 00 10 01 11 y= 00
- 177. Во-первых, ни один из путей, для которых ранее приходилось разрешать неоднозначность, не выжил, а значит, какие-либо
- 178. На финальном, 14-м шаге осуществляется выбор между двумя путями, сходящимися в состоянии 00, что завершает декодирование:
- 179. Лекция 24
- 180. 9.5. Мягкое декодирование сверточных кодов Наилучшая (максимально правдоподобная) стратегия принятия решений на выходе гауссовского канала состоит
- 181. того из двух путей, который приходит в узел, накопив бóльшее евклидово расстояние. Отметим, что среди 2m
- 182. в каждом блоке, длина которого после выкалывания g символов составит ln–g. В итоге скорость выколотого кода
- 183. Подбором l и g при заданном n можно варьировать скорость в широком диапазоне, добиваясь ее желаемого
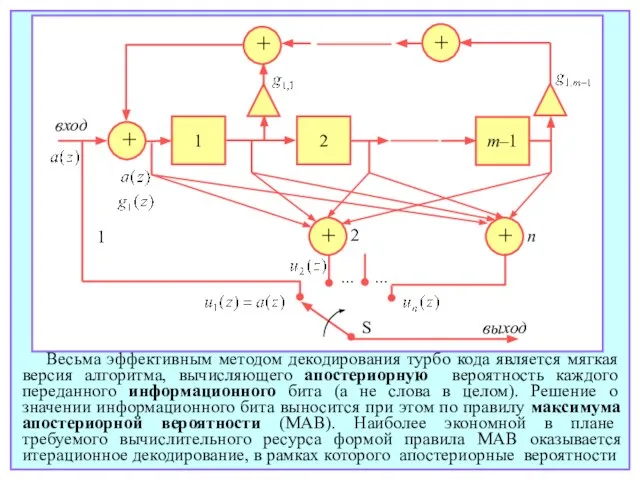
- 184. при построении турбо кода систематичность критически важна, компонентный кодер приходится модифицировать, применяя рекурсивный фильтр с бесконечной
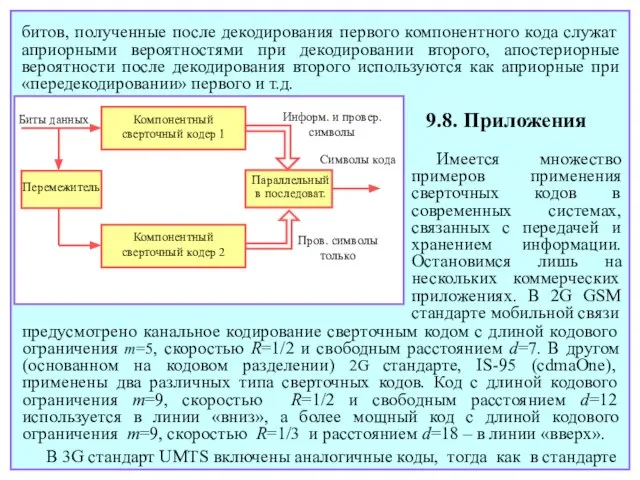
- 185. + + 1 2 m–1 1 2 n S выход вход ... ... + + +
- 186. битов, полученные после декодирования первого компонентного кода служат априорными вероятностями при декодировании второго, апостериорные вероятности после
- 187. Использование турбо кодов наряду со сверточными характерно для 3G стандартов UMTS, cdma2000, etc., а также для
- 188. Лекция 25
- 189. До этого момента (кроме краткого экскурса в двоичное представление кодов РСДо этого момента (кроме краткого экскурса
- 190. эксплуатируя особенности пакетной конфигурации. Краткое обсуждение этого вопроса составляет предмет двух следующих параграфов. 10.2. Коды, исправляющие
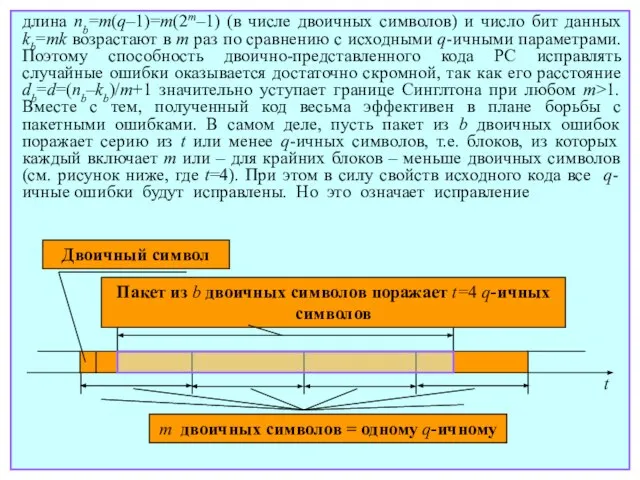
- 191. длина nb=m(q–1)=m(2m–1) (в числе двоичных символов) и число бит данных kb=mk возрастают в m раз по
- 192. любого пакета двоичных ошибок длины b=m(t–1)+1=m[(nb–kb)/2m–1]+1 и менее. Когда число проверочных символов РС кода достаточно велико
- 193. равномерно распределятся между B кодовыми словами, и если на каждое слово придется не более t ошибок,
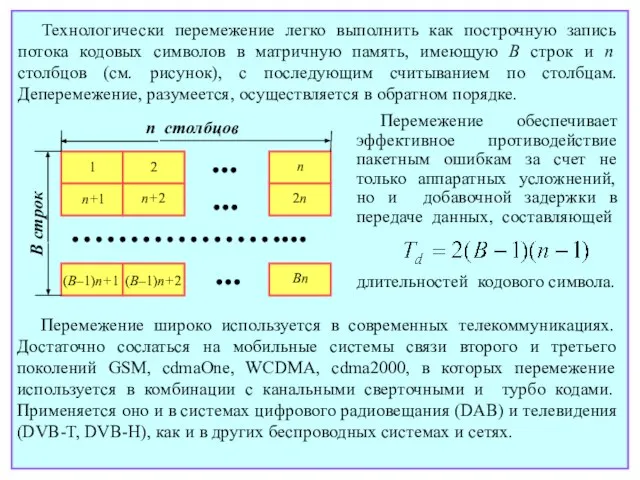
- 194. Технологически перемежение легко выполнить как построчную запись потока кодовых символов в матричную память, имеющую B строк
- 195. Лекция 26
- 196. 11. Элементы криптографии 11.1. Основные определения Термин криптография происходит от греческого kryptos (скрытый) и относится к
- 197. z. Для облегчения понимания задачи полезно представить все множество возможных шифров как некий гигантский справочник, в
- 198. Как можно видеть, основная идея любой криптосистемы – доступность ключа только отправителю и получателю. Как, однако,
- 199. Другими словами, шифрование должно обеспечивать статистическую независимость открытых текстов и криптограмм. При выполнении этого условия криптосистема
- 200. статистически независим с входным Ux, означая соблюдение достаточных условий совершенной стойкости. В действительности, однако, абсолютная случайность
- 201. проблемы в управлении ключами. По этой причине в практических криптосистемах повсеместно применяется дробление потока данных на
- 202. помощью простейшего шифра подстановки, т.е. заменяет каждую букву (восьмибитовый блок ASCII кода) некоторой другой, например, A→U,
- 203. Предшествующее шифрованию устранение избыточности, как следует из сказанного, потенциально повышает стойкость криптосистемы и потому широко используется
- 204. Лекция 27
- 205. Ранее неоднократно отмечалось, что управление ключами является серьезнейшей проблемой в криптографии с секретным ключом. Это явилось
- 206. ключ определяет некоторую одностороннюю функцию Fe(x), которая используется для шифрования открытого текста x. Тем самым, каждому
- 207. где dA - секретный ключ Алисы (известный только ей!). KAB и есть номер того шифра в
- 208. При типичном для практики гигантском p (сотни и более десятичных цифр), подобная задача, решаемая методом проб
- 209. Функция Эйлера (тотиент-функция) ϕ(n) в теории чисел есть число положительных целых, меньших n и взаимно простых
- 210. По получении криптограммы y Боб выполняет еще одно возведение в степень, определяемую его секретным ключом dB,
- 212. Скачать презентацию

Слайд 3Лекция 1
Лекция 1

Слайд 4Источник
Обобщенные модели систем передачи и хранения информации
Передатчик
Приемник
Получатель
Среда распространения
Источник
Получатель
Память
Устройство записи
Устройство чтения
Источник
Обобщенные модели систем передачи и хранения информации
Передатчик
Приемник
Получатель
Среда распространения
Источник
Получатель
Память
Устройство записи
Устройство чтения
Слайд 5Типы кодирования
«Сырые» данные
Кодирование источника
Канальное кодирование
Шифрование
Кодирование для линии
Помехоустойчивое кодирование
Типы кодирования
«Сырые» данные
Кодирование источника
Канальное кодирование
Шифрование
Кодирование для линии
Помехоустойчивое кодирование
Слайд 6Обобщенная модель системы передачи информации
Декодер источника
Дешифратор
Декодер канала
Демодулятор
К получателю
Передатчик
Приемник
Обобщенная модель системы передачи информации
Декодер источника
Дешифратор
Декодер канала
Демодулятор
К получателю
Передатчик
Приемник
Слайд 7Исторические вехи в теории и технике кодирования
1837: Электрический телеграф и код Морзе
Исторические вехи в теории и технике кодирования
1837: Электрический телеграф и код Морзе

Слайд 8Некоторые вводные задачи
Некоторые вводные задачи

Слайд 9Лекция 2
Лекция 2

Слайд 101. Источники сообщений, количество информации, энтропия
1.1. Идея определения количества информации
С теоретической точки
1. Источники сообщений, количество информации, энтропия
1.1. Идея определения количества информации
С теоретической точки

Слайд 11Рассматривая непрерывные источники, мы ограничимся только теми, несчетный ансамбль которых может быть
Рассматривая непрерывные источники, мы ограничимся только теми, несчетный ансамбль которых может быть

Слайд 12Единственной функцией, удовлетворяющей этим трем аксиомам оказывается логарифм вероятности сообщения:
1.4. Энтропия дискретного
Единственной функцией, удовлетворяющей этим трем аксиомам оказывается логарифм вероятности сообщения:
1.4. Энтропия дискретного

Слайд 132. Энтропия ограничена сверху соотношением
3. Энтропия ансамбля пар сообщений, генерируемых двумя независимыми
2. Энтропия ограничена сверху соотношением
3. Энтропия ансамбля пар сообщений, генерируемых двумя независимыми
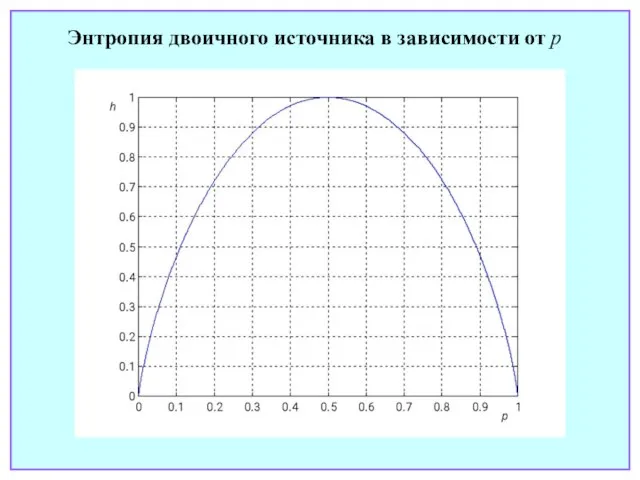
Слайд 14Энтропия двоичного источника в зависимости от p
Энтропия двоичного источника в зависимости от p
Слайд 15Лекция 3
Лекция 3

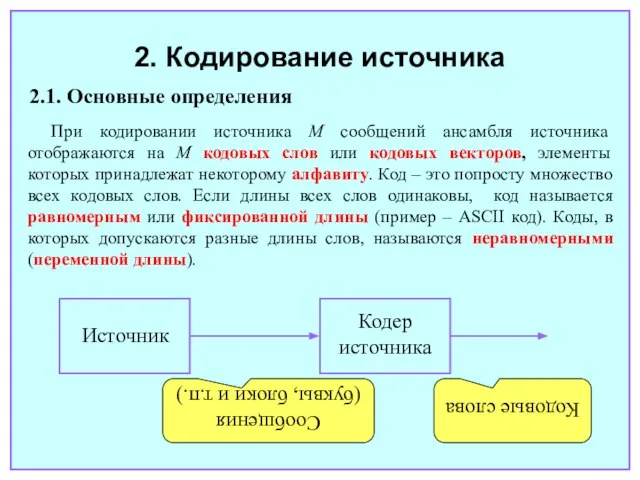
Слайд 16Источник
Кодер источника
Сообщения
(буквы, блоки и т.п.)
Кодовые слова
2. Кодирование источника
2.1. Основные определения
При
Источник
Кодер источника
Сообщения
(буквы, блоки и т.п.)
Кодовые слова
2. Кодирование источника
2.1. Основные определения
При
Слайд 172.2. Префиксные коды. Неравенство Крафта. Средняя длина кодового слова
Идея экономии числа символов
2.2. Префиксные коды. Неравенство Крафта. Средняя длина кодового слова
Идея экономии числа символов

Слайд 18x1 ⭢ 0
x2 ⭢ 10
x3 ⭢ 110
x4 ⭢ 111
Так, если последовательность на выходе
x1 ⭢ 0
x2 ⭢ 10
x3 ⭢ 110
x4 ⭢ 111
Так, если последовательность на выходе

Слайд 19Теорема 2.2.2. Средняя длина лучших префиксных кодов лежит в границах
2.3. Код Шеннона-Фано
На
Теорема 2.2.2. Средняя длина лучших префиксных кодов лежит в границах
2.3. Код Шеннона-Фано
На

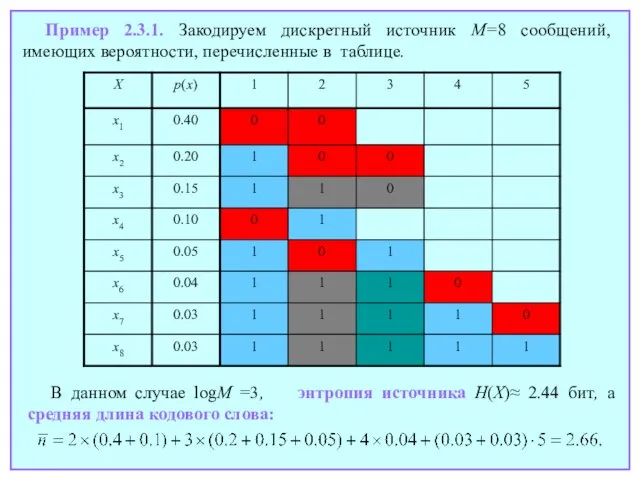
Слайд 20Пример 2.3.1. Закодируем дискретный источник M=8 сообщений, имеющих вероятности, перечисленные в таблице.
В
Пример 2.3.1. Закодируем дискретный источник M=8 сообщений, имеющих вероятности, перечисленные в таблице.
В
Слайд 21Лекция 4
Лекция 4

Слайд 222.4. Код Хаффмена
Этот код оптимален в том смысле, что ни один префиксный
2.4. Код Хаффмена
Этот код оптимален в том смысле, что ни один префиксный

Слайд 23Пример 2.4.1. Закодируем по Хаффмену ансамбль из Примера 2.3.1:
X p(x)
x1 0.40
x2 0.20
x3 0.15
x4 0.10
x5 0.05
x6 0.04
x7 0.03
x8 0.03
0
1
0
0
1
0
1
0
1
0
1
1.00
0.06
0.09
0.35
Средняя длина:
0
1
0.15
0.25
1
0.60
Кодовые слова
0
110
100
101
11100
11101
11110
11111
Пример 2.4.1. Закодируем по Хаффмену ансамбль из Примера 2.3.1:
X p(x)
x1 0.40
x2 0.20
x3 0.15
x4 0.10
x5 0.05
x6 0.04
x7 0.03
x8 0.03
0
1
0
0
1
0
1
0
1
0
1
1.00
0.06
0.09
0.35
Средняя длина:
0
1
0.15
0.25
1
0.60
Кодовые слова
0
110
100
101
11100
11101
11110
11111

Слайд 24На практике источник генерирует сообщения (часто удобно называть их буквами) последовательно одно
На практике источник генерирует сообщения (часто удобно называть их буквами) последовательно одно

Слайд 252.6. Равномерное кодирование источника
Неравномерное кодирование не всегда удобно. Нередки сценарии (например, цифровое
2.6. Равномерное кодирование источника
Неравномерное кодирование не всегда удобно. Нередки сценарии (например, цифровое

Слайд 262.7. Словарные коды. Алгоритм Лемпеля-Зива
Рассмотренные ранее методы кодирования источника опираются на априорное
2.7. Словарные коды. Алгоритм Лемпеля-Зива
Рассмотренные ранее методы кодирования источника опираются на априорное

Слайд 27своим адресом в словаре (2), и обновляющим символом 0. Все последующие шаги
своим адресом в словаре (2), и обновляющим символом 0. Все последующие шаги

Слайд 28Наряду с обновляющим символом 0 это дает новый вход словаря для фразы
Наряду с обновляющим символом 0 это дает новый вход словаря для фразы

Слайд 29Лекция 5
Лекция 5

Слайд 302.8. Резюме. Примеры приложений
Из вышесказанного следует, что генерируемые источником данные можно сжать
2.8. Резюме. Примеры приложений
Из вышесказанного следует, что генерируемые источником данные можно сжать

Слайд 31В настоящее время широко применяются как равномерное, так и неравномерное кодирование источника.
В настоящее время широко применяются как равномерное, так и неравномерное кодирование источника.

Слайд 32Многообразны и поучительны примеры применения методов адаптивного сжатия данных в кодировании речи,
Многообразны и поучительны примеры применения методов адаптивного сжатия данных в кодировании речи,

Слайд 33В стандартах мобильной связи GSM, IS-95 и 3G используются вокодеры типов VSELP
В стандартах мобильной связи GSM, IS-95 и 3G используются вокодеры типов VSELP

Слайд 343. Взаимная информация. Пропускная способность канала. Теоремы кодирования для канала
3.1. Математическое описание
3. Взаимная информация. Пропускная способность канала. Теоремы кодирования для канала
3.1. Математическое описание

Слайд 35Все каналы можно классифицировать на дискретные и непрерывные как по времени, так
Все каналы можно классифицировать на дискретные и непрерывные как по времени, так

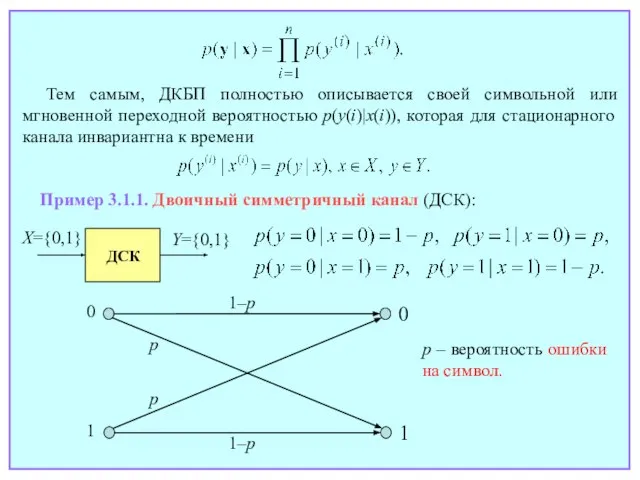
Слайд 36Пример 3.1.1. Двоичный симметричный канал (ДСК):
p – вероятность ошибки на символ.
Тем самым,
Пример 3.1.1. Двоичный симметричный канал (ДСК):
p – вероятность ошибки на символ.
Тем самым,
Слайд 37Лекция 6
Лекция 6

Слайд 383.2. Взаимная информация, остаточная энтропия, пропускная способность канала
Для канала, подверженного влиянию случайных
3.2. Взаимная информация, остаточная энтропия, пропускная способность канала
Для канала, подверженного влиянию случайных

Слайд 39или, полагая p(y)p(x|y)=p(x,y),
Так как до наблюдения неопределенность относительно входного ансамбля равнялась энтропии
или, полагая p(y)p(x|y)=p(x,y),
Так как до наблюдения неопределенность относительно входного ансамбля равнялась энтропии

Слайд 40Как видно, I(X;Y) показывает число битов информации о входе канала извлекаемое в
Как видно, I(X;Y) показывает число битов информации о входе канала извлекаемое в

Слайд 41Легко доказать симметрию взаимной и средней взаимной информации: I(x;y)=I(y;x); I(X;Y) =I(Y;X).
Максимальное количество
Легко доказать симметрию взаимной и средней взаимной информации: I(x;y)=I(y;x); I(X;Y) =I(Y;X).
Максимальное количество

Слайд 42в каковом случае имеет место ошибка декодирования (ошибочное решение). Вероятность ошибки декодирования
в каковом случае имеет место ошибка декодирования (ошибочное решение). Вероятность ошибки декодирования

Слайд 43Лекция 7
Лекция 7

Слайд 443.4. Теоремы кодирования для канала
Пусть одно из M равновероятных сообщений, закодированное
3.4. Теоремы кодирования для канала
Пусть одно из M равновероятных сообщений, закодированное

Слайд 45этому, если скорость R меньше емкости канала C, в принципе всегда можно
этому, если скорость R меньше емкости канала C, в принципе всегда можно
Слайд 46В отличие от обратной, доказательство прямой теоремы для общей модели канала без
В отличие от обратной, доказательство прямой теоремы для общей модели канала без

Слайд 47Прямая теорема Шеннона является типичной математической теоремой существования, не давая ни малейшего
Прямая теорема Шеннона является типичной математической теоремой существования, не давая ни малейшего
Слайд 48Лекция 8
Лекция 8

Слайд 494. Расчет пропускной способности некоторых каналов
4.1. Дискретный канал без памяти
Как следует из
4. Расчет пропускной способности некоторых каналов
4.1. Дискретный канал без памяти
Как следует из

Слайд 50 Для модели произвольного ДКБП подобная оптимизационная задача не имеет замкнутого аналитического решения.
Для модели произвольного ДКБП подобная оптимизационная задача не имеет замкнутого аналитического решения.

Слайд 51Поскольку при любом x на входе, на выходе канала возможны только два
Поскольку при любом x на входе, на выходе канала возможны только два
Слайд 52Лекция 9
Лекция 9

Слайд 534.3. Непрерывные источники. Взаимная информация и относительная (дифференциальная) энтропия
Рассмотрим непрерывный ансамбль, эквивалентный
4.3. Непрерывные источники. Взаимная информация и относительная (дифференциальная) энтропия
Рассмотрим непрерывный ансамбль, эквивалентный
Слайд 54Дифференциальная (относительная) энтропия непрерывной величины X определяется равенством
Таким образом, средняя взаимная информация
Дифференциальная (относительная) энтропия непрерывной величины X определяется равенством
Таким образом, средняя взаимная информация

Слайд 554.4. Пропускная способность непрерывного гауссовского канала
Рассмотрим полностью непрерывный (по времени и состоянию)
4.4. Пропускная способность непрерывного гауссовского канала
Рассмотрим полностью непрерывный (по времени и состоянию)

Слайд 560
f
W
N0
Спектральная плотность мощности шума
τ
N0W
0
Автокорреляционная функция шума
Как теперь видно, отсчеты с частотой Найквиста-Котельникова
0
f
W
N0
Спектральная плотность мощности шума
τ
N0W
0
Автокорреляционная функция шума
Как теперь видно, отсчеты с частотой Найквиста-Котельникова

Слайд 57придем к знаменитой формуле Шеннона для пропускной способности гауссовского канала:
Этот результат показывает,
придем к знаменитой формуле Шеннона для пропускной способности гауссовского канала:
Этот результат показывает,

Слайд 58Вспомнив, что Ct - максимальная теоретически достижимая скорость Rt безошибочной передачи, введем
Вспомнив, что Ct - максимальная теоретически достижимая скорость Rt безошибочной передачи, введем

Слайд 59Лекция 10
Лекция 10

Слайд 605. Введение в блоковые коды
5.1. Общая идея канального кодирования. Классификация кодов
Как уже
5. Введение в блоковые коды
5.1. Общая идея канального кодирования. Классификация кодов
Как уже

Слайд 61было передано, если решение выносится в пользу «ближайшего» (отличающегося в минимальном числе
было передано, если решение выносится в пользу «ближайшего» (отличающегося в минимальном числе

Слайд 62В последующем тексте используются слегка измененные обозначения:
U={u1, u2, … , uM} –
В последующем тексте используются слегка измененные обозначения:
U={u1, u2, … , uM} –

Слайд 63Евклидово расстояние играет фундаментальную роль в теории и технике передачи сообщений. Чем
Евклидово расстояние играет фундаментальную роль в теории и технике передачи сообщений. Чем

Слайд 64канала связи. На выходе канала наблюдается некоторое колебание y(t) (см.рисунок), являющееся переданным
канала связи. На выходе канала наблюдается некоторое колебание y(t) (см.рисунок), являющееся переданным

Слайд 65кодового слова ui в наблюдаемый вектор y)
падает с хэмминговым расстоянием di= dH
кодового слова ui в наблюдаемый вектор y)
падает с хэмминговым расстоянием di= dH

Слайд 66Теорема 5.4.1. Код исправляет вплоть до t ошибок тогда и только тогда,
Теорема 5.4.1. Код исправляет вплоть до t ошибок тогда и только тогда,
Слайд 67Длина кода n вместе с объемом M и расстоянием d составляют тройку
Длина кода n вместе с объемом M и расстоянием d составляют тройку

Слайд 68Лекция 11
Лекция 11

Слайд 695.5. Важнейшие границы теории кодирования
Очевидно, особый интерес представляют коды с максимальным расстоянием
5.5. Важнейшие границы теории кодирования
Очевидно, особый интерес представляют коды с максимальным расстоянием

Слайд 70Близкое по смыслу ограничение устанавливается границей Плоткина.
Теорема 5.5.2. (Граница Плоткина). Любой двоичный
Близкое по смыслу ограничение устанавливается границей Плоткина.
Теорема 5.5.2. (Граница Плоткина). Любой двоичный

Слайд 71Для больших длин n биномиальные коэффициенты в приведенных неравенствах можно аппроксимировать по
Для больших длин n биномиальные коэффициенты в приведенных неравенствах можно аппроксимировать по

Слайд 72упомянутыми является зоной неопределенности, для которой однозначный ответ о существовании кода нельзя
упомянутыми является зоной неопределенности, для которой однозначный ответ о существовании кода нельзя
Слайд 73во сколько раз можно уменьшить энергию сигнала за счет введения канального кодирования.
во сколько раз можно уменьшить энергию сигнала за счет введения канального кодирования.

Слайд 74квантованием непрерывного выхода демодулятора, после чего следуют те же операции, что и
квантованием непрерывного выхода демодулятора, после чего следуют те же операции, что и

Слайд 75Лекция 12
Лекция 12

Слайд 766. Линейные блоковые коды
6.1. Введение в конечные поля
Конечным полям принадлежит основополагающая роль
6. Линейные блоковые коды
6.1. Введение в конечные поля
Конечным полям принадлежит основополагающая роль

Слайд 773. В F присутствуют два нейтральных элемента – нуль (обозначаемый символом «0») и
3. В F присутствуют два нейтральных элемента – нуль (обозначаемый символом «0») и

Слайд 78Простейшие среди полей – числовые (рациональных или действительных чисел), содержащие бесконечно много
Простейшие среди полей – числовые (рациональных или действительных чисел), содержащие бесконечно много

Слайд 796.2. Векторные пространства над конечными полями
Понятие векторного пространства, традиционно вводимое для случая
6.2. Векторные пространства над конечными полями
Понятие векторного пространства, традиционно вводимое для случая

Слайд 804. Умножение вектора на скаляр ассоциативно:
5. Умножение любого вектора на единичный скаляр (обязательно
4. Умножение вектора на скаляр ассоциативно:
5. Умножение любого вектора на единичный скаляр (обязательно

Слайд 81Пусть в пространстве S выбраны m ненулевых векторов g1, g2,.., gm.
Они называются
Пусть в пространстве S выбраны m ненулевых векторов g1, g2,.., gm.
Они называются

Слайд 82Лекция 13
Лекция 13

Слайд 836.3. Линейные коды и их порождающие матрицы
Рассмотрим множество S всех 2n n–компонентных
6.3. Линейные коды и их порождающие матрицы
Рассмотрим множество S всех 2n n–компонентных

Слайд 84Вводя k–компонентный вектор сообщения (данных) a=(a1, a2, … , ak), любое слово
Вводя k–компонентный вектор сообщения (данных) a=(a1, a2, … , ak), любое слово

Слайд 853. Теорема 6.3.1. Минимальное расстояние линейного кода равно наименьшему из весов ненулевых слов
3. Теорема 6.3.1. Минимальное расстояние линейного кода равно наименьшему из весов ненулевых слов

Слайд 86где Ik – k×k единичная матрица, а P – матрица размерности k×(n–k).
где Ik – k×k единичная матрица, а P – матрица размерности k×(n–k).

Слайд 87Теорема 6.4.1. Линейный код U имеет минимальное расстояние d, если и только
Теорема 6.4.1. Линейный код U имеет минимальное расстояние d, если и только

Слайд 88Лекция 14
Лекция 14

Слайд 89Коды, фигурирующие в заголовке, замечательны как в познавательном, так и в практическом
Коды, фигурирующие в заголовке, замечательны как в познавательном, так и в практическом
Слайд 90Так как все столбцы матрицы H кода Хэмминга различны, любая их пара
Так как все столбцы матрицы H кода Хэмминга различны, любая их пара

Слайд 91исправляющий t=(d–1)/2 ошибок, можно трансформировать в расширенный (n+1, k) код, исправляющий ошибки
исправляющий t=(d–1)/2 ошибок, можно трансформировать в расширенный (n+1, k) код, исправляющий ошибки

Слайд 92уже встречавшегося в параграфе 5.1. Разумеется, этот код – подобно исходному коду
уже встречавшегося в параграфе 5.1. Разумеется, этот код – подобно исходному коду

Слайд 93Отметим, что коды U и U´ называются дуальными если порождающая матрица одного
Отметим, что коды U и U´ называются дуальными если порождающая матрица одного

Слайд 94Минимальное расстояние и исправляющая способность этого кода – те же, что и
Минимальное расстояние и исправляющая способность этого кода – те же, что и
Слайд 95Лекция 15
Лекция 15

Слайд 966.8. Синдромное декодирование линейных кодов
Одним из оснований особой популярности линейных кодов
6.8. Синдромное декодирование линейных кодов
Одним из оснований особой популярности линейных кодов

Слайд 97Представим вектор наблюдения y как сумму переданного кодового вектора u и вектора
Представим вектор наблюдения y как сумму переданного кодового вектора u и вектора

Слайд 98экономия измерялась бы цифрами порядка 221 раз по обоим ресурсным показателям. В
экономия измерялась бы цифрами порядка 221 раз по обоим ресурсным показателям. В

Слайд 99Лекция 16
Лекция 16

Слайд 1007. Циклические коды
7.1. Циклические коды. Кодовые полиномы. Полиномиальная арифметика
Линейный блоковый код U
7. Циклические коды
7.1. Циклические коды. Кодовые полиномы. Полиномиальная арифметика
Линейный блоковый код U

Слайд 101Рассмотрим основные правила арифметики формальных полиномов с коэффициентами из GF(q) (полиномов над
Рассмотрим основные правила арифметики формальных полиномов с коэффициентами из GF(q) (полиномов над

Слайд 102полиномов можно определить равенством, полностью заимствованным из «школьной» алгебры полиномов с действительными
полиномов можно определить равенством, полностью заимствованным из «школьной» алгебры полиномов с действительными

Слайд 103где неотрицательное целое r , меньшее d , называется остатком (от деления
где неотрицательное целое r , меньшее d , называется остатком (от деления

Слайд 104делитель
частное
делимое
остаток
В теории циклических кодов важнейшая роль принадлежит остатку.
Часто используемая символика
означает, что
делитель
частное
делимое
остаток
В теории циклических кодов важнейшая роль принадлежит остатку.
Часто используемая символика
означает, что

Слайд 105Лекция 17
Лекция 17

Слайд 1067.2. Порождающий и проверочный полиномы циклического кода
Возьмем кодовое слово u=(u0, u1, …
7.2. Порождающий и проверочный полиномы циклического кода
Возьмем кодовое слово u=(u0, u1, …

Слайд 107Теорема 7.2.2. Порождающий полином циклического кода длины n является делителем бинома zn–1.
Теорема 7.2.2. Порождающий полином циклического кода длины n является делителем бинома zn–1.

Слайд 108только эти сомножители либо их произведения могут служить порождающими полиномами (7, k)
только эти сомножители либо их произведения могут служить порождающими полиномами (7, k)

Слайд 109Сообщению (1110) отвечает информационный полином a(z)=z2+z+1. При этом кодовый полином, получаемый прямым
Сообщению (1110) отвечает информационный полином a(z)=z2+z+1. При этом кодовый полином, получаемый прямым

Слайд 110после деления на g(z) дает остаток r(z)=z. В итоге u(z)= z5+z4+z3+z, и
после деления на g(z) дает остаток r(z)=z. В итоге u(z)= z5+z4+z3+z, и

Слайд 111Лекция 18
Лекция 18

Слайд 1127.4. Порождающая и проверочная матрица циклического кода
Как и любой линейный, циклический код
7.4. Порождающая и проверочная матрица циклического кода
Как и любой линейный, циклический код

Слайд 113Если систематичность кода не является непременным условием, порождающая матрица легко строится непосредственно
Если систематичность кода не является непременным условием, порождающая матрица легко строится непосредственно

Слайд 114Обратимся теперь к структуре систематического циклического кодера. Согласно сказанному в параграфе 7.3,
Обратимся теперь к структуре систематического циклического кодера. Согласно сказанному в параграфе 7.3,
Слайд 115имеет степень не более n–1 и после сложения с ak–2zn–2 используется на
имеет степень не более n–1 и после сложения с ak–2zn–2 используется на

Слайд 116+
+
×
+
+
g0
g1
g2
gr–1
1
2
r
S1
S2
B
1
2
вход
выход
ak–1, ak–2, …, a0
C0
C1
C2
Cr–1
r1
r2
rr–1
rr
B1
B2
Br–1
+r2,n–4zn–4+…+r2,n–r–2zn–r–2, степень которого не превышает n–3. Остаток r2(z) вновь
+
+
×
+
+
g0
g1
g2
gr–1
1
2
r
S1
S2
B
1
2
вход
выход
ak–1, ak–2, …, a0
C0
C1
C2
Cr–1
r1
r2
rr–1
rr
B1
B2
Br–1
+r2,n–4zn–4+…+r2,n–r–2zn–r–2, степень которого не превышает n–3. Остаток r2(z) вновь
Слайд 117оказывается очередной остаток, с которым производятся те же действия на следующей итерации.
оказывается очередной остаток, с которым производятся те же действия на следующей итерации.

Слайд 1187.6. Синдромное декодирование циклических кодов
С учетом того, что все кодовые полиномы циклического
7.6. Синдромное декодирование циклических кодов
С учетом того, что все кодовые полиномы циклического
Слайд 119где, в свою очередь, e(z)=en–1zn–1+en–2zn–2+…+e0 – полином ошибки. Назовем синдромным полиномом или
где, в свою очередь, e(z)=en–1zn–1+en–2zn–2+…+e0 – полином ошибки. Назовем синдромным полиномом или

Слайд 120+
+
g0
g1
1
2
in
yn–1, yn–2, …, y0
+
+
g2
gr–1
r
S1
S2
out
×
×
×
×
+
+
+
–
–
–
замыкается и в регистре хранится слагаемое остатка, обусловленное отсчетами
+
+
g0
g1
1
2
in
yn–1, yn–2, …, y0
+
+
g2
gr–1
r
S1
S2
out
×
×
×
×
+
+
+
–
–
–
замыкается и в регистре хранится слагаемое остатка, обусловленное отсчетами
Слайд 121+
+
S1
S2
out
in
y6, y5, …, y0
1
2
3
В цикличности заложен потенциал и дальнейших упрощений аппаратных декодеров
+
+
S1
S2
out
in
y6, y5, …, y0
1
2
3
В цикличности заложен потенциал и дальнейших упрощений аппаратных декодеров
Слайд 122Лекция 19
Лекция 19

Слайд 1238. Коды БЧХ и Рида-Соломона
8.1. Расширенные конечные поля
Как уже известно, конечные
8. Коды БЧХ и Рида-Соломона
8.1. Расширенные конечные поля
Как уже известно, конечные

Слайд 124Пример 8.1.1. Обратимся к полиному f(x)=x3+x+1. Поскольку он неприводим и имеет степень
Пример 8.1.1. Обратимся к полиному f(x)=x3+x+1. Поскольку он неприводим и имеет степень
Слайд 125Отметим, что в числе полиномов степени не выше m–1 присутствуют и полиномы
Отметим, что в числе полиномов степени не выше m–1 присутствуют и полиномы

Слайд 126и для любого ненулевого α
Таким образом, в конечных полях действуют те же
и для любого ненулевого α
Таким образом, в конечных полях действуют те же

Слайд 127Теорема 8.2.1. Мультипликативный порядок любого ненулевого элемента поля GF(q) делит q–1, т.е.
Теорема 8.2.1. Мультипликативный порядок любого ненулевого элемента поля GF(q) делит q–1, т.е.

Слайд 128Пример 8.2.4. В поле GF(8) (см. пример 8.2.2) все ненулевые элементы поля
Пример 8.2.4. В поле GF(8) (см. пример 8.2.2) все ненулевые элементы поля

Слайд 129Отсюда ςm+1= ς·ςm= ς(–fm-1ςm–1–fm–2ςm–2–…–f0)=–fm–1ςm–fm–2ςm–1–…–f0ς. В правой части этого равенства вновь подставим ςm=
Отсюда ςm+1= ς·ςm= ς(–fm-1ςm–1–fm–2ςm–2–…–f0)=–fm–1ςm–fm–2ςm–1–…–f0ς. В правой части этого равенства вновь подставим ςm=

Слайд 1308.3. Некоторые свойства расширенных конечных полей
Установим в данном параграфе некоторые вспомогательные
8.3. Некоторые свойства расширенных конечных полей
Установим в данном параграфе некоторые вспомогательные

Слайд 131называются сопряженными с элементом α. Их роль в конечных полях, как вскоре
называются сопряженными с элементом α. Их роль в конечных полях, как вскоре

Слайд 1328.4. Построение полиномов с заданными корнями
Одно из фундаментальных положений классической алгебры
8.4. Построение полиномов с заданными корнями
Одно из фундаментальных положений классической алгебры

Слайд 133g(z) имеет корень α (лежащий) в расширении GF(2m).
Пример 8.4.1. Рассмотрим полином g(z)=z3+z2+1.
g(z) имеет корень α (лежащий) в расширении GF(2m).
Пример 8.4.1. Рассмотрим полином g(z)=z3+z2+1.

Слайд 134где все q–1 ненулевых элементов GF(q) выражены как степени примитивного элемента ς.
Теорема
где все q–1 ненулевых элементов GF(q) выражены как степени примитивного элемента ς.
Теорема

Слайд 135Лекция 20
Лекция 20

Слайд 1368.5. Двоичные БЧХ-коды
Накопленные к данному моменту знания открывают путь к ознакомлению с
8.5. Двоичные БЧХ-коды
Накопленные к данному моменту знания открывают путь к ознакомлению с

Слайд 137и не может быть вырожденной, если все элементы первой строки различны. Но
и не может быть вырожденной, если все элементы первой строки различны. Но

Слайд 138корнями порождающего полинома. Любой из них, однако, должен войти в число корней
корнями порождающего полинома. Любой из них, однако, должен войти в число корней

Слайд 139Гарантией того, что построенный таким образом полином можно использовать как порождающий для
Гарантией того, что построенный таким образом полином можно использовать как порождающий для

Слайд 140Разумеется, в наши дни системный дизайнер свободен от необходимости поиска порождающих полиномов
Разумеется, в наши дни системный дизайнер свободен от необходимости поиска порождающих полиномов

Слайд 141Пример 8.5.3. Найдем точное число информационных бит БЧХ-кода длины n=31, исправляющего до
Пример 8.5.3. Найдем точное число информационных бит БЧХ-кода длины n=31, исправляющего до

Слайд 142Лекция 21
Лекция 21

Слайд 1438.6. Коды Рида-Соломона
Если при построении порождающего полинома g(z) согласно теореме БЧХ игнорировать
8.6. Коды Рида-Соломона
Если при построении порождающего полинома g(z) согласно теореме БЧХ игнорировать

Слайд 144где свобода выбора числа информационных символов k ограничена лишь одним: с увеличением
где свобода выбора числа информационных символов k ограничена лишь одним: с увеличением

Слайд 145Коды БЧХ и РС находят широкое применение в современных информационных системах. Приведем
Коды БЧХ и РС находят широкое применение в современных информационных системах. Приведем

Слайд 146укороченных (32,28) и (28,24) кодов РС. Стандарт цифрового телевизионного вещания DVB-T (Digital
укороченных (32,28) и (28,24) кодов РС. Стандарт цифрового телевизионного вещания DVB-T (Digital

Слайд 1479. Введение в сверточные коды
9.1. Основные определения
Наряду с блоковыми кодами, рассмотренными в
9. Введение в сверточные коды
9.1. Основные определения
Наряду с блоковыми кодами, рассмотренными в

Слайд 148Сверточное (вообще, решетчатое) кодирование предполагает несколько иное отображения информационных битов в кодовые
Сверточное (вообще, решетчатое) кодирование предполагает несколько иное отображения информационных битов в кодовые
Слайд 149Стандартная сема сверточного кодера базируется на регистре сдвига, содержащем m–1 двоичных ячеек
Стандартная сема сверточного кодера базируется на регистре сдвига, содержащем m–1 двоичных ячеек
Слайд 150Если подать на вход этого устройства k информационных битов, на выходе появится
Если подать на вход этого устройства k информационных битов, на выходе появится

Слайд 151длиной кодового ограничения m=3. Скорость этого кода R=1/2, так как на каждый
длиной кодового ограничения m=3. Скорость этого кода R=1/2, так как на каждый
Слайд 152Нетрудно убедиться в линейности сверточных кодов. Более того, само их название связано
Нетрудно убедиться в линейности сверточных кодов. Более того, само их название связано

Слайд 153Лекция 22
Лекция 22

Слайд 1549.2. Диаграмма состояний и решетчатая диаграмма сверточного кода. Свободное расстояние
Любой сверточный кодер
9.2. Диаграмма состояний и решетчатая диаграмма сверточного кода. Свободное расстояние
Любой сверточный кодер

Слайд 155ветви, соединяющие кружки (узлы) с обозначенными внутри последних состояниями. Сплошные (синие) ветви
ветви, соединяющие кружки (узлы) с обозначенными внутри последних состояниями. Сплошные (синие) ветви
Слайд 156такта кодер перейдет в состояние либо 00, либо 10. Если он окажется
такта кодер перейдет в состояние либо 00, либо 10. Если он окажется
Слайд 157тактов для обнуления кодера, в течение которых генерирование кодовых символов будет продолжаться.
тактов для обнуления кодера, в течение которых генерирование кодовых символов будет продолжаться.

Слайд 158Пометим каждую ветвь диаграммы состояний формальной переменной D, в степени, равной весу
Пометим каждую ветвь диаграммы состояний формальной переменной D, в степени, равной весу
Слайд 159Так как движение по ветвям диаграммы есть рекуррентный, пошаговый процесс, вес пути
Так как движение по ветвям диаграммы есть рекуррентный, пошаговый процесс, вес пути

Слайд 160показывающей, что рассматриваемый код имеет свободное расстояние df=5: из нулевого состояния выходит
показывающей, что рассматриваемый код имеет свободное расстояние df=5: из нулевого состояния выходит

Слайд 161откуда видно, что в рассматриваемом коде присутствуют один путь длины 3 и
откуда видно, что в рассматриваемом коде присутствуют один путь длины 3 и

Слайд 162Лекция 23
Лекция 23

Слайд 1639.4. Алгоритм декодирования Витерби
Рекурсивная природа сверточного кодирования лежит в основе также рекурсивного
9.4. Алгоритм декодирования Витерби
Рекурсивная природа сверточного кодирования лежит в основе также рекурсивного

Слайд 1641. Вычисляются хэмминговы расстояния от принятой n-символьной группы до каждой из ветвей
1. Вычисляются хэмминговы расстояния от принятой n-символьной группы до каждой из ветвей

Слайд 16500
10
01
11
00
11
Шаг 1
y= 10
00
10
01
11
1
1
00
10
01
11
1
1
2
2
00
10
01
11
00
01
11
10
y= 10 01
1
3
Первые два шага декодирования тривиальны. На первом из
00
10
01
11
00
11
Шаг 1
y= 10
00
10
01
11
1
1
00
10
01
11
1
1
2
2
00
10
01
11
00
01
11
10
y= 10 01
1
3
Первые два шага декодирования тривиальны. На первом из
Слайд 16600
10
01
11
2
2
1
3
00
10
01
11
00
01
00
01
11
10
11
10
Шаг 3
y= 10 01 00
Третий шаг нашего примера критически важен в объяснении
00
10
01
11
2
2
1
3
00
10
01
11
00
01
00
01
11
10
11
10
Шаг 3
y= 10 01 00
Третий шаг нашего примера критически важен в объяснении
Слайд 167кодового слова, ближайшего к наблюдению, а значит, путь, который заведомо останется более
кодового слова, ближайшего к наблюдению, а значит, путь, который заведомо останется более
Слайд 168Шаг 5
y= 10 01 00 00 00
00
10
01
11
00
10
01
11
00
01
00
01
11
10
11
10
2
3
2
2
2
4
4
2
4
3
4
3
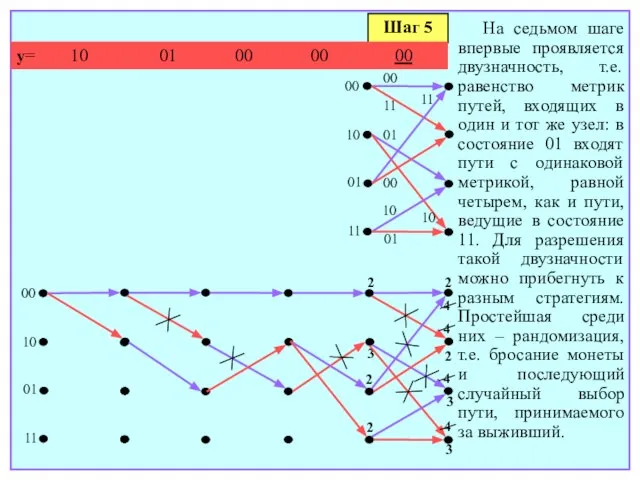
На седьмом шаге впервые проявляется двузначность,
Шаг 5
y= 10 01 00 00 00
00
10
01
11
00
10
01
11
00
01
00
01
11
10
11
10
2
3
2
2
2
4
4
2
4
3
4
3
На седьмом шаге впервые проявляется двузначность,
Слайд 169Шаг 6
y= 10 01 00 00 00 00
00
10
01
11
00
10
01
11
00
01
00
01
11
10
11
10
2
2
3
3
5
4
3
3
4
3
4
2
Шаг 6
y= 10 01 00 00 00 00
00
10
01
11
00
10
01
11
00
01
00
01
11
10
11
10
2
2
3
3
5
4
3
3
4
3
4
2
Слайд 170Шаг 7
y= 10 01 00 00 00 00 00
00
10
01
11
00
10
01
11
00
01
00
01
11
10
11
10
2
3
3
3
2
5
4
3
4
4
4
4
Шаг 7
y= 10 01 00 00 00 00 00
00
10
01
11
00
10
01
11
00
01
00
01
11
10
11
10
2
3
3
3
2
5
4
3
4
4
4
4
Слайд 171Шаг 8
y= 10 01 00 00 00 00 00 00
00
10
01
11
00
01
00
01
11
10
11
10
00
10
01
11
2
3
4
4
2
6
4
4
4
5
4
5
Придерживаясь этой стратегии,
Шаг 8
y= 10 01 00 00 00 00 00 00
00
10
01
11
00
01
00
01
11
10
11
10
00
10
01
11
2
3
4
4
2
6
4
4
4
5
4
5
Придерживаясь этой стратегии,
Слайд 172Шаг 9
y= 10 01 00 00 00 00 00 00 00
00
10
01
11
00
01
00
01
11
10
11
10
00
10
01
11
2
4
4
4
2
6
4
4
5
5
5
5
В частности,
Шаг 9
y= 10 01 00 00 00 00 00 00 00
00
10
01
11
00
01
00
01
11
10
11
10
00
10
01
11
2
4
4
4
2
6
4
4
5
5
5
5
В частности,
Слайд 173Шаг 10
y= 10 01 00 00 00 00 00 00 00 00
00
10
01
11
00
01
00
01
11
10
11
10
00
10
01
11
2
4
5
5
2
7
4
5
5
6
5
6
Шаг 10
y= 10 01 00 00 00 00 00 00 00 00
00
10
01
11
00
01
00
01
11
10
11
10
00
10
01
11
2
4
5
5
2
7
4
5
5
6
5
6
Слайд 174Шаг 11
y= 10 01 00 00 00 00 00 00 00 00
Шаг 11
y= 10 01 00 00 00 00 00 00 00 00
Слайд 175Шаг 12
y= 10 01 00 00 00 00 00 00 00 00
Шаг 12
y= 10 01 00 00 00 00 00 00 00 00
Слайд 176Шаг 14
00
11
Шаг 13
2
5
4
5
00
10
01
11
y= 00 00 00
00
10
01
11
00
01
10
11
2
7
5
6
7
00
10
01
11
2
5
y= 00 00 00 00
2
Шаг 14
00
11
Шаг 13
2
5
4
5
00
10
01
11
y= 00 00 00
00
10
01
11
00
01
10
11
2
7
5
6
7
00
10
01
11
2
5
y= 00 00 00 00
2
Слайд 177Во-первых, ни один из путей, для которых ранее приходилось разрешать неоднозначность, не
Во-первых, ни один из путей, для которых ранее приходилось разрешать неоднозначность, не

Слайд 178На финальном, 14-м шаге осуществляется выбор между двумя путями, сходящимися в состоянии
На финальном, 14-м шаге осуществляется выбор между двумя путями, сходящимися в состоянии

Слайд 179Лекция 24
Лекция 24

Слайд 1809.5. Мягкое декодирование сверточных кодов
Наилучшая (максимально правдоподобная) стратегия принятия решений на
9.5. Мягкое декодирование сверточных кодов
Наилучшая (максимально правдоподобная) стратегия принятия решений на

Слайд 181того из двух путей, который приходит в узел, накопив бóльшее евклидово расстояние.
того из двух путей, который приходит в узел, накопив бóльшее евклидово расстояние.

Слайд 182в каждом блоке, длина которого после выкалывания g символов составит ln–g. В
в каждом блоке, длина которого после выкалывания g символов составит ln–g. В

Слайд 183Подбором l и g при заданном n можно варьировать скорость в широком
Подбором l и g при заданном n можно варьировать скорость в широком

Слайд 184при построении турбо кода систематичность критически важна, компонентный кодер приходится модифицировать, применяя
при построении турбо кода систематичность критически важна, компонентный кодер приходится модифицировать, применяя

Слайд 185+
+
1
2
m–1
1
2
n
S
выход
вход
...
...
+
+
+
Весьма эффективным методом декодирования турбо кода является мягкая версия алгоритма, вычисляющего апостериорную
+
+
1
2
m–1
1
2
n
S
выход
вход
...
...
+
+
+
Весьма эффективным методом декодирования турбо кода является мягкая версия алгоритма, вычисляющего апостериорную
Слайд 186битов, полученные после декодирования первого компонентного кода служат априорными вероятностями при декодировании
битов, полученные после декодирования первого компонентного кода служат априорными вероятностями при декодировании
Слайд 187Использование турбо кодов наряду со сверточными характерно для 3G стандартов UMTS, cdma2000,
Использование турбо кодов наряду со сверточными характерно для 3G стандартов UMTS, cdma2000,

Слайд 188 Лекция 25
Лекция 25

Слайд 189До этого момента (кроме краткого экскурса в двоичное представление кодов РСДо этого
До этого момента (кроме краткого экскурса в двоичное представление кодов РСДо этого

Слайд 190эксплуатируя особенности пакетной конфигурации. Краткое обсуждение этого вопроса составляет предмет двух следующих
эксплуатируя особенности пакетной конфигурации. Краткое обсуждение этого вопроса составляет предмет двух следующих

Слайд 191длина nb=m(q–1)=m(2m–1) (в числе двоичных символов) и число бит данных kb=mk возрастают
длина nb=m(q–1)=m(2m–1) (в числе двоичных символов) и число бит данных kb=mk возрастают
Слайд 192любого пакета двоичных ошибок длины b=m(t–1)+1=m[(nb–kb)/2m–1]+1 и менее. Когда число проверочных символов
любого пакета двоичных ошибок длины b=m(t–1)+1=m[(nb–kb)/2m–1]+1 и менее. Когда число проверочных символов
![любого пакета двоичных ошибок длины b=m(t–1)+1=m[(nb–kb)/2m–1]+1 и менее. Когда число проверочных символов](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/410073/slide-191.jpg)
Слайд 193равномерно распределятся между B кодовыми словами, и если на каждое слово придется
равномерно распределятся между B кодовыми словами, и если на каждое слово придется

Слайд 194Технологически перемежение легко выполнить как построчную запись потока кодовых символов в матричную
Технологически перемежение легко выполнить как построчную запись потока кодовых символов в матричную
Слайд 195Лекция 26
Лекция 26

Слайд 19611. Элементы криптографии
11.1. Основные определения
Термин криптография происходит от греческого kryptos (скрытый) и
11. Элементы криптографии
11.1. Основные определения
Термин криптография происходит от греческого kryptos (скрытый) и

Слайд 197z. Для облегчения понимания задачи полезно представить все множество возможных шифров как
z. Для облегчения понимания задачи полезно представить все множество возможных шифров как

Слайд 198Как можно видеть, основная идея любой криптосистемы – доступность ключа только отправителю
Как можно видеть, основная идея любой криптосистемы – доступность ключа только отправителю

Слайд 199Другими словами, шифрование должно обеспечивать статистическую независимость открытых текстов и криптограмм. При
Другими словами, шифрование должно обеспечивать статистическую независимость открытых текстов и криптограмм. При

Слайд 200статистически независим с входным Ux, означая соблюдение достаточных условий совершенной стойкости. В
статистически независим с входным Ux, означая соблюдение достаточных условий совершенной стойкости. В

Слайд 201проблемы в управлении ключами. По этой причине в практических криптосистемах повсеместно применяется
проблемы в управлении ключами. По этой причине в практических криптосистемах повсеместно применяется

Слайд 202помощью простейшего шифра подстановки, т.е. заменяет каждую букву (восьмибитовый блок ASCII кода)
помощью простейшего шифра подстановки, т.е. заменяет каждую букву (восьмибитовый блок ASCII кода)

Слайд 203Предшествующее шифрованию устранение избыточности, как следует из сказанного, потенциально повышает стойкость криптосистемы
Предшествующее шифрованию устранение избыточности, как следует из сказанного, потенциально повышает стойкость криптосистемы

Слайд 204Лекция 27
Лекция 27

Слайд 205Ранее неоднократно отмечалось, что управление ключами является серьезнейшей проблемой в криптографии с
Ранее неоднократно отмечалось, что управление ключами является серьезнейшей проблемой в криптографии с

Слайд 206ключ определяет некоторую одностороннюю функцию Fe(x), которая используется для шифрования открытого текста
ключ определяет некоторую одностороннюю функцию Fe(x), которая используется для шифрования открытого текста

Слайд 207где dA - секретный ключ Алисы (известный только ей!). KAB и есть
где dA - секретный ключ Алисы (известный только ей!). KAB и есть

Слайд 208При типичном для практики гигантском p (сотни и более десятичных цифр), подобная
При типичном для практики гигантском p (сотни и более десятичных цифр), подобная

Слайд 209 Функция Эйлера (тотиент-функция) ϕ(n) в теории чисел есть число положительных целых,
Функция Эйлера (тотиент-функция) ϕ(n) в теории чисел есть число положительных целых,

Слайд 210По получении криптограммы y Боб выполняет еще одно возведение в степень, определяемую
По получении криптограммы y Боб выполняет еще одно возведение в степень, определяемую

 Способы реализации деятельностного подхода на занятиях модульного курса «ОРКиСЭ»
Способы реализации деятельностного подхода на занятиях модульного курса «ОРКиСЭ» 127417
127417 Эпоха Петра Великого 1672-1725
Эпоха Петра Великого 1672-1725 Сетевой проект от хобби-гипермаркета Леонардо – 2019г
Сетевой проект от хобби-гипермаркета Леонардо – 2019г Структурный подход к анализу семьи С. Минухина
Структурный подход к анализу семьи С. Минухина ОПОВЕЩЕНИЕ И ЭВАКУАЦИЯ НАСЕЛЕНИЯ
ОПОВЕЩЕНИЕ И ЭВАКУАЦИЯ НАСЕЛЕНИЯ Презентация на тему Андрей Платонович Платонов (1899-1951)
Презентация на тему Андрей Платонович Платонов (1899-1951)  Jesteśmy dla siebie darem i zadaniem
Jesteśmy dla siebie darem i zadaniem Электрические линии напряжением выше 1000 в. Воздушные и кабельные линии
Электрические линии напряжением выше 1000 в. Воздушные и кабельные линии Исследовательская работа
Исследовательская работа Число и цифра 4
Число и цифра 4 A c a d e m y
A c a d e m y изучаем цифры How many
изучаем цифры How many МДОУ «Детский сад №146 «Петушок»
МДОУ «Детский сад №146 «Петушок» Психокоррекционная работа с детьми. Областной семинар учителей-логопедов. Фестиваль психического здоровья школьников
Психокоррекционная работа с детьми. Областной семинар учителей-логопедов. Фестиваль психического здоровья школьников Второстепенные члены Дополнение
Второстепенные члены Дополнение Жанры изобразительного искусства (6 класс)
Жанры изобразительного искусства (6 класс) Классный час. «300 лет М.В.Ломоносову»
Классный час. «300 лет М.В.Ломоносову» БИОЦЕНОЗ И АГРОЦЕНОЗ
БИОЦЕНОЗ И АГРОЦЕНОЗ «Вредные привычки»
«Вредные привычки» Юрий Визбор
Юрий Визбор Уравнение дальности радиолокационного обнаружения
Уравнение дальности радиолокационного обнаружения Математические софизмы
Математические софизмы Презентация на тему ЧИСТАЯ ВОДА
Презентация на тему ЧИСТАЯ ВОДА Генерация объектной модели для DocsVision и использование ее при синхронизации сервисов
Генерация объектной модели для DocsVision и использование ее при синхронизации сервисов Создание домашней акустики из устаревших материалов
Создание домашней акустики из устаревших материалов Презентация на тему Мусульманское искусство
Презентация на тему Мусульманское искусство Орында?ан: ??рман?али А.Б. Тескерген: Нуркеева Б.А.
Орында?ан: ??рман?али А.Б. Тескерген: Нуркеева Б.А.