- Лекция №14

Содержание
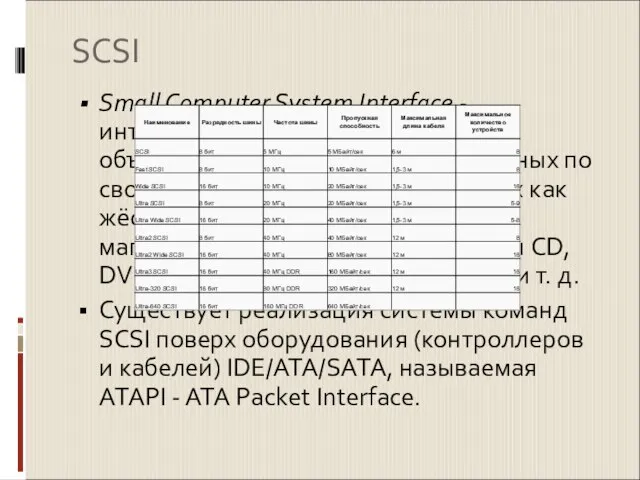
- 2. SCSI Small Computer System Interface - интерфейс, разработанный для объединения на одной шине различных по своему
- 3. SAS (Serial Attached SCSI) компьютерный интерфейс, разработанный для обмена данными с такими устройствами, как жёсткие диски,
- 4. SCSI vs SAS SAS использует последовательный протокол передачи данных между несколькими устройствами, и, таким образом, использует
- 5. NAS (Network Attached Storage) сетевая система хранения данных, сетевое хранилище. представляет собой одно устройство с некоторым
- 6. SAN (Storage Area Network) представляет собой архитектурное решение для подключения внешних устройств хранения данных, таких как
- 7. SAN vs NAS Кто обслуживает файловую систему? NAS – клиент оперирует понятием файл SAN – блочное
- 8. SAN Используются протоколы SCSI и SAS, iSCSI (tcp транспорт), FCP (Fiber Channel Protocol)
- 9. SAN
- 10. Switch SAN
- 11. DFS (Distributed File System) Распределённая файловая система - используется для упрощения доступа и управления файлами, физически
- 12. GFS (Google File System) Система строится из большого количества обыкновенного недорого оборудования, которое часто дает сбои.
- 13. GFS устройство Chunk (Чанк сервера) – сервера с самостоятельной операционной системой сохраняющие данные на установленные локально
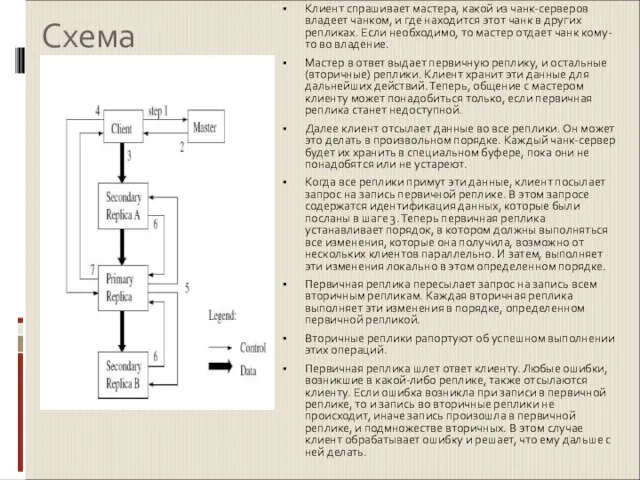
- 14. Схема Клиент спрашивает мастера, какой из чанк-серверов владеет чанком, и где находится этот чанк в других
- 16. Скачать презентацию
Слайд 3SAS (Serial Attached SCSI)
компьютерный интерфейс, разработанный для обмена данными с такими устройствами,
SAS (Serial Attached SCSI)
компьютерный интерфейс, разработанный для обмена данными с такими устройствами,

Слайд 4SCSI vs SAS
SAS использует последовательный протокол передачи данных между несколькими устройствами, и,
SCSI vs SAS
SAS использует последовательный протокол передачи данных между несколькими устройствами, и,

Слайд 5NAS (Network Attached Storage)
сетевая система хранения данных, сетевое хранилище.
представляет собой одно устройство с некоторым
NAS (Network Attached Storage)
сетевая система хранения данных, сетевое хранилище.
представляет собой одно устройство с некоторым

Слайд 6SAN (Storage Area Network)
представляет собой архитектурное решение для подключения внешних устройств
SAN (Storage Area Network)
представляет собой архитектурное решение для подключения внешних устройств

Слайд 7SAN vs NAS
Кто обслуживает файловую систему?
NAS – клиент оперирует понятием файл
SAN –
SAN vs NAS
Кто обслуживает файловую систему?
NAS – клиент оперирует понятием файл
SAN –

Слайд 8SAN
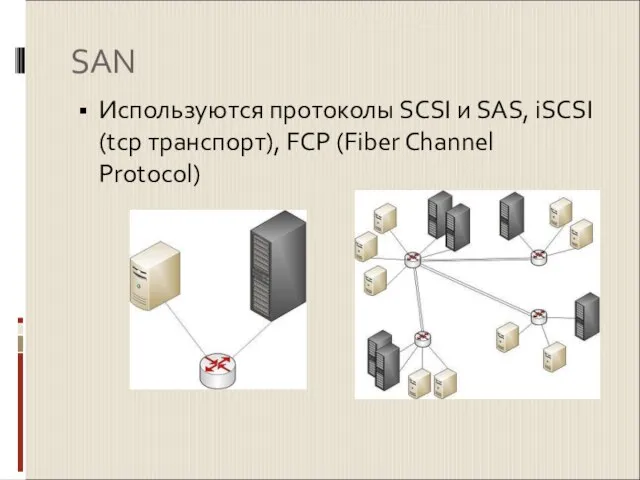
Используются протоколы SCSI и SAS, iSCSI (tcp транспорт), FCP (Fiber Channel Protocol)
SAN
Используются протоколы SCSI и SAS, iSCSI (tcp транспорт), FCP (Fiber Channel Protocol)
Слайд 9SAN
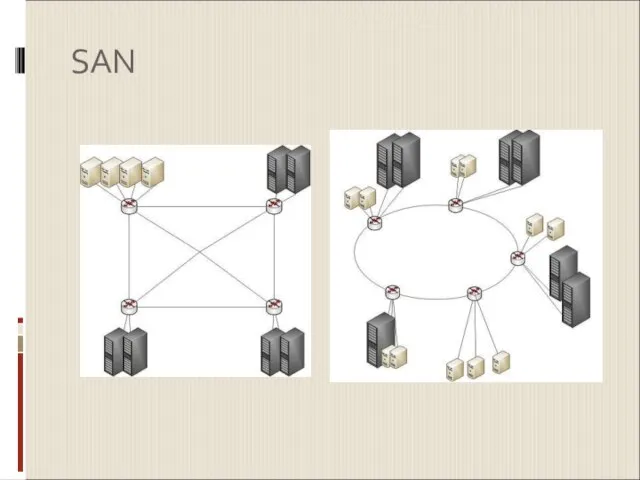
SAN
Слайд 10Switch SAN
Switch SAN

Слайд 11DFS (Distributed File System)
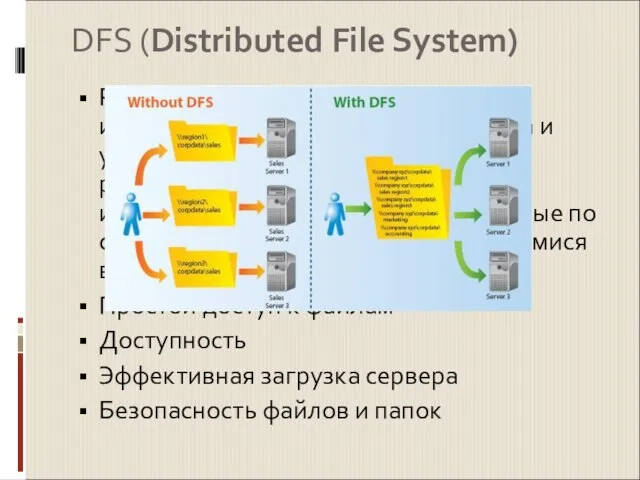
Распределённая файловая система - используется для упрощения доступа и
DFS (Distributed File System)
Распределённая файловая система - используется для упрощения доступа и
Слайд 12GFS (Google File System)
Система строится из большого количества обыкновенного недорого оборудования, которое
GFS (Google File System)
Система строится из большого количества обыкновенного недорого оборудования, которое

Слайд 13GFS устройство
Chunk (Чанк сервера) – сервера с самостоятельной операционной системой сохраняющие данные
GFS устройство
Chunk (Чанк сервера) – сервера с самостоятельной операционной системой сохраняющие данные

Слайд 14Схема
Клиент спрашивает мастера, какой из чанк-серверов владеет чанком, и где находится этот
Схема
Клиент спрашивает мастера, какой из чанк-серверов владеет чанком, и где находится этот
 Использование ИКТ в образовательном процессе как способ оптимизации деятельности учителя
Использование ИКТ в образовательном процессе как способ оптимизации деятельности учителя Психология зависимого поведения
Психология зависимого поведения ПРЕЗЕНТАЦИЯ МОИХ РАБОТ«ВРЕМЕНА ГОДА»
ПРЕЗЕНТАЦИЯ МОИХ РАБОТ«ВРЕМЕНА ГОДА» Рак почки. Эпидемиология, классификация, этиология, патогенез, клиническая картина
Рак почки. Эпидемиология, классификация, этиология, патогенез, клиническая картина Dmitry Sergeyevich Likhachov
Dmitry Sergeyevich Likhachov Вопрос о правде в драме М.Горького «На дне».
Вопрос о правде в драме М.Горького «На дне». Информационно-справочная система Предприятие средств диспетчерского и технологического управления РУП Гродноэнерго
Информационно-справочная система Предприятие средств диспетчерского и технологического управления РУП Гродноэнерго Презентация на тему Албания
Презентация на тему Албания  Мониторинг и оценкав деятельности НКО
Мониторинг и оценкав деятельности НКО Научно-методические основы корректировочного курса по русскому языку как неродному(глагольное предложное управление в азербай
Научно-методические основы корректировочного курса по русскому языку как неродному(глагольное предложное управление в азербай Педагогический meet-up Начать легко
Педагогический meet-up Начать легко Наше Сердце.
Наше Сердце. Презентация на тему ОЛИМПИАДА 2014 г. СОЧИ
Презентация на тему ОЛИМПИАДА 2014 г. СОЧИ  Соединение деталей шурупами
Соединение деталей шурупами Подготовка документов для создания организации
Подготовка документов для создания организации Фундаментальные и прикладные вопросы нейробиологии
Фундаментальные и прикладные вопросы нейробиологии Литература Древнего Египта
Литература Древнего Египта ТЕХНИЧЕСКОЕ ЗАДАНИЕ
ТЕХНИЧЕСКОЕ ЗАДАНИЕ Презентация на тему Жизненный цикл клетки. Митоз. Амитоз
Презентация на тему Жизненный цикл клетки. Митоз. Амитоз Мир художественной культуры эпохи Возрождения
Мир художественной культуры эпохи Возрождения Сервис 1С-Товары
Сервис 1С-Товары House
House Этиология и распространенность наркологических заболеваний
Этиология и распространенность наркологических заболеваний Ноябрь 18 - соок-ирей кырган-ачавыстыӊ төрүттүнген хүнү болур, уруглар
Ноябрь 18 - соок-ирей кырган-ачавыстыӊ төрүттүнген хүнү болур, уруглар Экипаж. Отечественное кино
Экипаж. Отечественное кино Л.С. Выготский о законах личностного развития
Л.С. Выготский о законах личностного развития Find 1 word for 3 pictures
Find 1 word for 3 pictures 01.09.20121 3 «ПОСЛЕДНИЙ ДЕНЬ ПЕРЕД РОЖДЕСТВОМ ПРОШЁЛ.ЗИМНЯЯ, ЯСНАЯ НОЧЬ НАСТУПИЛА. ГЛЯНУЛИ ЗВЁЗДЫ.»
01.09.20121 3 «ПОСЛЕДНИЙ ДЕНЬ ПЕРЕД РОЖДЕСТВОМ ПРОШЁЛ.ЗИМНЯЯ, ЯСНАЯ НОЧЬ НАСТУПИЛА. ГЛЯНУЛИ ЗВЁЗДЫ.»