- Методы поиска в структурированных файлах функции ранжирования

Содержание
- 2. Содержание Векторная модель TF-IDF Косинусная мера Структурированный файл на примере XML Лексические поддеревья Структурные термы Расширение
- 3. Векторная модель Векторная модель (англ. vector space model) — представление коллекции документов векторами из одного общего
- 4. Векторная модель Более формально dj = (w1j, w2j, …, wnj), где dj — векторное представление j-го
- 5. TF-IDF TF-IDF (от англ. TF — term frequency, IDF — inverse document frequency) — статистическая мера,
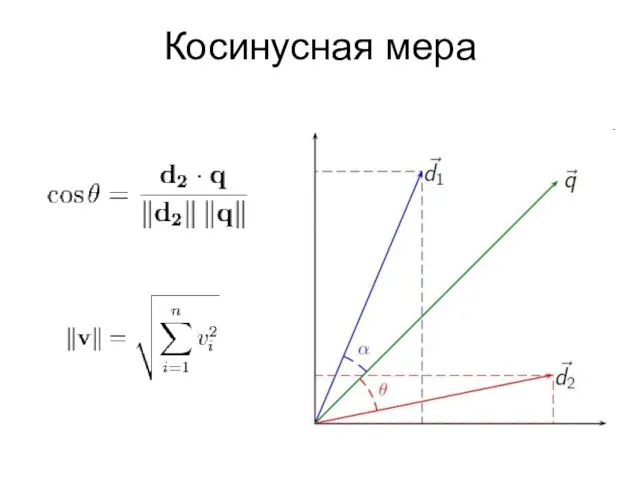
- 6. Косинусная мера
- 7. Косинусная мера ρ(Q,D) – соответствие запроса Q документу D ti – терм (измерение) wQ(ti) – вес
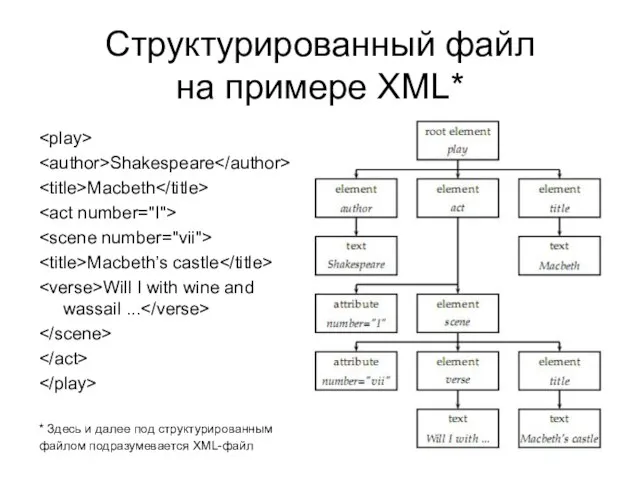
- 8. Структурированный файл на примере XML* Shakespeare Macbeth Macbeth’s castle Will I with wine and wassail ...
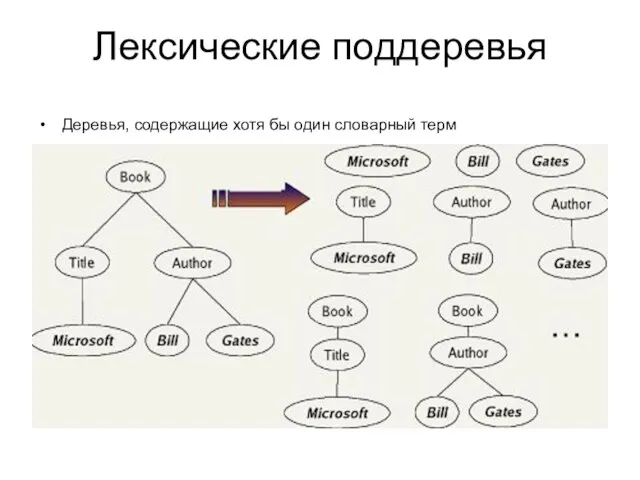
- 9. Лексические поддеревья Деревья, содержащие хотя бы один словарный терм
- 10. Лексические поддеревья С увеличением количества узлов в дереве растет число лексических поддеревьев.
- 11. Структурные термы Будем рассматривать только такие лексические поддеревья, которые оканчиваются единственным словарным термом Такие поддеревья называются
- 12. Расширение векторной модели на случай структурированных файлов ρ(Q,D) – соответствие запроса Q документу D (ti,c i)
- 13. Схожесть контекстов 1 способ |cq| - число узлов в контексте, соответствующем терму из запроса |cd| -
- 14. Схожесть контекстов 2 способ Рассмотрим запрос в форме T Q = q1q2q3 – контекст появления Т
- 15. Схожесть контекстов LCS(Q,A) Longest Common Subsequence LCS(Q,A) = lcs(Q,A)/|Q|, где lcs(Q,A) – длина наибольшей общей подпоследовательности
- 16. Критерии оценки Контекст А включает больше элементов qi в правильном порядке. (В примере - 3) Элементы
- 17. Схожесть контекстов POS(Q,A) POS(Q,A) = 1-((AP-AverOptimalPosition)/(|A|-2*AverOptimalPosition+1)) AverOptimalPosition - среднее положение оптимального совпадения Q и А (если
- 18. Схожесть контекстов GAPS(Q,A) GAPS(Q,A) = gaps/(gaps + lcs(Q,A)) gaps - число «пробелов» (в примере gaps =
- 19. Схожесть контекстов LD(Q,A) LD(Q,A)= (|A|- lcs(Q,A))/|A| 0 ≤ LD ≤ 1 ( 0 – полное совпадение)
- 20. Схожесть контекстов cr(Q,A) = αLCS(Q,A) + βPOS(Q,A) – γGAPS(Q,A) – δLD(Q,A) 0 ≤ α ≤ 1,
- 21. Примеры Показывают, как влияют оценки LCS(Q,A) , POS(Q,A), GAPS(Q,A), LD(Q,A) на cr(Q,A) Q = q1q2q3 =
- 22. Пример A1. Влияние lcs(Q,A) на cr(Q,A) Пример A2. Влияние AP(Q,A) на cr(Q,A)
- 23. Пример A3. Влияние gaps(Q,A) на cr(Q,A) Пример A4. Влияние ld(Q,A) на cr(Q,A)
- 24. Пример B1. Влияние AP(Q,A) на cr(Q,A) при меньшем lcs (Q,A)
- 25. Okapi BM25 d - документ C – коллекция документов W(d,q,C) – релевантность документа d из коллекции
- 26. Okapi BM25 d - документ C – коллекция документов wj(d,C) – вес j-го терма в документе
- 27. BM25F модификация BM25, в которой документ рассматривается как совокупность нескольких полей (таких как, например, заголовки, основной
- 28. BM25F Пусть имеется nF полей f = 1, …, nF В данном поле f документа d
- 29. BM25F Пусть имеется nF полей f = 1, …, nF В данном поле f документа d
- 30. BM25F Если считать, что полю f присвоен вес wf , получим: N – мощность коллекции atf
- 31. BM25E В BM25F вместо частоты терма в документе используется линейная комбинация взвешенных частот терма в полях
- 32. BM25E Пусть имеется nЕ элементов е = 1, …, nЕ в коллекции С В элементе е
- 33. ВМ25Е Соответственно, функция ВМ25Е: tf’e,j – взвешенная частота j-го терма в элементе е еl’ – взвешенная
- 34. BM25E Соответственно, M – мощность коллекции atf – средняя частота терма
- 35. Литература Christopher D. Manning, Prabhakar Raghavan and Hinrich Schütze, Introduction to Information Retrieval, Cambridge University Press.
- 37. Скачать презентацию
Слайд 2Содержание
Векторная модель
TF-IDF
Косинусная мера
Структурированный файл
на примере XML
Лексические поддеревья
Структурные термы
Расширение векторной модели на случай
Содержание
Векторная модель
TF-IDF
Косинусная мера
Структурированный файл
на примере XML
Лексические поддеревья
Структурные термы
Расширение векторной модели на случай

Слайд 3Векторная модель
Векторная модель (англ. vector space model) — представление коллекции документов векторами
Векторная модель
Векторная модель (англ. vector space model) — представление коллекции документов векторами

Слайд 4Векторная модель
Более формально
dj = (w1j, w2j, …, wnj), где
dj — векторное
Векторная модель
Более формально
dj = (w1j, w2j, …, wnj), где
dj — векторное

Слайд 5TF-IDF
TF-IDF (от англ. TF — term frequency, IDF — inverse document frequency)
TF-IDF
TF-IDF (от англ. TF — term frequency, IDF — inverse document frequency)

Слайд 6Косинусная мера
Косинусная мера
Слайд 7Косинусная мера
ρ(Q,D) – соответствие запроса Q документу D
ti – терм (измерение)
wQ(ti)
Косинусная мера
ρ(Q,D) – соответствие запроса Q документу D
ti – терм (измерение)
wQ(ti)

Слайд 8Структурированный файл
на примере XML*
Shakespeare
Macbeth
Macbeth’s castle
Will I with wine and wassail
Структурированный файл
на примере XML*
Слайд 9Лексические поддеревья
Деревья, содержащие хотя бы один словарный терм
Лексические поддеревья
Деревья, содержащие хотя бы один словарный терм
Слайд 10Лексические поддеревья
С увеличением количества узлов в дереве
растет число лексических поддеревьев.
Лексические поддеревья
С увеличением количества узлов в дереве
растет число лексических поддеревьев.

Слайд 11Структурные термы
Будем рассматривать только такие лексические поддеревья, которые оканчиваются единственным словарным термом
Такие
Структурные термы
Будем рассматривать только такие лексические поддеревья, которые оканчиваются единственным словарным термом
Такие

Слайд 12Расширение векторной модели на случай структурированных файлов
ρ(Q,D) – соответствие запроса Q документу
Расширение векторной модели на случай структурированных файлов
ρ(Q,D) – соответствие запроса Q документу

Слайд 13Схожесть контекстов
1 способ
|cq| - число узлов в контексте, соответствующем терму из
Схожесть контекстов
1 способ
|cq| - число узлов в контексте, соответствующем терму из

Слайд 14Схожесть контекстов
2 способ
Рассмотрим запрос в форме T
Q = q1q2q3 – контекст появления
Схожесть контекстов
2 способ
Рассмотрим запрос в форме
Q = q1q2q3 – контекст появления

Слайд 15Схожесть контекстов
LCS(Q,A)
Longest Common Subsequence
LCS(Q,A) = lcs(Q,A)/|Q|, где
lcs(Q,A) – длина наибольшей общей подпоследовательности
Схожесть контекстов
LCS(Q,A)
Longest Common Subsequence
LCS(Q,A) = lcs(Q,A)/|Q|, где
lcs(Q,A) – длина наибольшей общей подпоследовательности

Слайд 16Критерии оценки
Контекст А включает больше элементов qi в правильном порядке. (В примере
Критерии оценки
Контекст А включает больше элементов qi в правильном порядке. (В примере

Слайд 17Схожесть контекстов
POS(Q,A)
POS(Q,A) = 1-((AP-AverOptimalPosition)/(|A|-2*AverOptimalPosition+1))
AverOptimalPosition - среднее положение оптимального совпадения Q и
Схожесть контекстов
POS(Q,A)
POS(Q,A) = 1-((AP-AverOptimalPosition)/(|A|-2*AverOptimalPosition+1))
AverOptimalPosition - среднее положение оптимального совпадения Q и

Слайд 18Схожесть контекстов
GAPS(Q,A)
GAPS(Q,A) = gaps/(gaps + lcs(Q,A))
gaps - число «пробелов» (в примере gaps
Схожесть контекстов
GAPS(Q,A)
GAPS(Q,A) = gaps/(gaps + lcs(Q,A))
gaps - число «пробелов» (в примере gaps

Слайд 19Схожесть контекстов
LD(Q,A)
LD(Q,A)= (|A|- lcs(Q,A))/|A|
0 ≤ LD ≤ 1
( 0 – полное
Схожесть контекстов
LD(Q,A)
LD(Q,A)= (|A|- lcs(Q,A))/|A|
0 ≤ LD ≤ 1
( 0 – полное

Слайд 20Схожесть контекстов
cr(Q,A) = αLCS(Q,A) + βPOS(Q,A) – γGAPS(Q,A) – δLD(Q,A)
0 ≤
Схожесть контекстов
cr(Q,A) = αLCS(Q,A) + βPOS(Q,A) – γGAPS(Q,A) – δLD(Q,A)
0 ≤

Слайд 21Примеры
Показывают, как влияют оценки LCS(Q,A) , POS(Q,A), GAPS(Q,A), LD(Q,A) на cr(Q,A)
Q
Примеры
Показывают, как влияют оценки LCS(Q,A) , POS(Q,A), GAPS(Q,A), LD(Q,A) на cr(Q,A)
Q

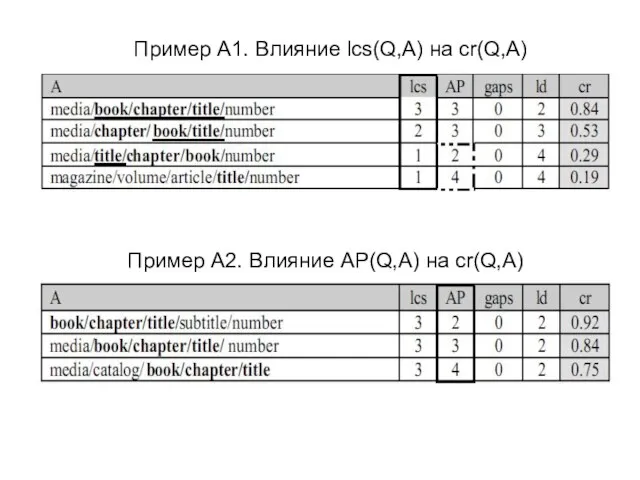
Слайд 22Пример A1. Влияние lcs(Q,A) на cr(Q,A)
Пример A2. Влияние AP(Q,A) на cr(Q,A)
Пример A1. Влияние lcs(Q,A) на cr(Q,A)
Пример A2. Влияние AP(Q,A) на cr(Q,A)
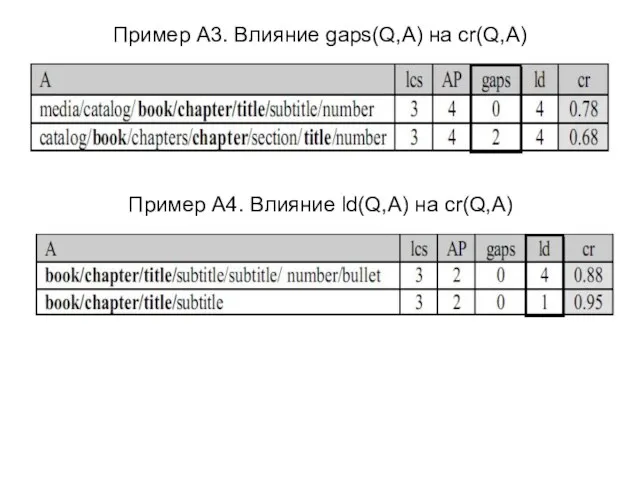
Слайд 23Пример A3. Влияние gaps(Q,A) на cr(Q,A)
Пример A4. Влияние ld(Q,A) на cr(Q,A)
Пример A3. Влияние gaps(Q,A) на cr(Q,A)
Пример A4. Влияние ld(Q,A) на cr(Q,A)
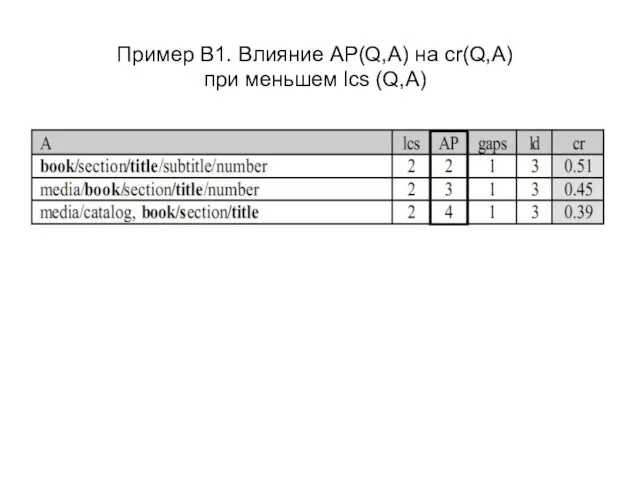
Слайд 24Пример B1. Влияние AP(Q,A) на cr(Q,A)
при меньшем lcs (Q,A)
Пример B1. Влияние AP(Q,A) на cr(Q,A)
при меньшем lcs (Q,A)
Слайд 25Okapi BM25
d - документ
C – коллекция документов
W(d,q,C) – релевантность документа d из
Okapi BM25
d - документ
C – коллекция документов
W(d,q,C) – релевантность документа d из

Слайд 26Okapi BM25
d - документ
C – коллекция документов
wj(d,C) – вес j-го терма в
Okapi BM25
d - документ
C – коллекция документов
wj(d,C) – вес j-го терма в

Слайд 27BM25F
модификация BM25, в которой документ рассматривается как совокупность нескольких полей (таких как,
BM25F
модификация BM25, в которой документ рассматривается как совокупность нескольких полей (таких как,

Слайд 28BM25F
Пусть имеется nF полей f = 1, …, nF
В данном поле f
BM25F
Пусть имеется nF полей f = 1, …, nF
В данном поле f

Слайд 29BM25F
Пусть имеется nF полей f = 1, …, nF
В данном поле f
BM25F
Пусть имеется nF полей f = 1, …, nF
В данном поле f

Слайд 30BM25F
Если считать, что полю f присвоен вес wf , получим:
N – мощность
BM25F
Если считать, что полю f присвоен вес wf , получим:
N – мощность

Слайд 31BM25E
В BM25F вместо частоты терма в документе используется линейная комбинация взвешенных частот
BM25E
В BM25F вместо частоты терма в документе используется линейная комбинация взвешенных частот

Слайд 32BM25E
Пусть имеется nЕ элементов е = 1, …, nЕ в коллекции С
В
BM25E
Пусть имеется nЕ элементов е = 1, …, nЕ в коллекции С
В

Слайд 33ВМ25Е
Соответственно, функция ВМ25Е:
tf’e,j – взвешенная частота j-го терма в элементе е
еl’ –
ВМ25Е
Соответственно, функция ВМ25Е:
tf’e,j – взвешенная частота j-го терма в элементе е
еl’ –

Слайд 34BM25E
Соответственно,
M – мощность коллекции
atf – средняя частота терма
BM25E
Соответственно,
M – мощность коллекции
atf – средняя частота терма

Слайд 35Литература
Christopher D. Manning, Prabhakar Raghavan and Hinrich Schütze, Introduction to Information Retrieval,
Литература
Christopher D. Manning, Prabhakar Raghavan and Hinrich Schütze, Introduction to Information Retrieval,

 Интересные факты из жизни великого учёного Д. И. Менделеева
Интересные факты из жизни великого учёного Д. И. Менделеева Основной альбом - 2019 год. Репертуар театра Улыбка
Основной альбом - 2019 год. Репертуар театра Улыбка ВИМІРЮВАННЯ ТИСКУ
ВИМІРЮВАННЯ ТИСКУ Рыбоперерабатывающийкомплекс наКольском полуострове
Рыбоперерабатывающийкомплекс наКольском полуострове Дон Аминадо. (Шполянский Аминад Петрович)
Дон Аминадо. (Шполянский Аминад Петрович) РЕШЕНИЕ ОСНОВНЫХЗАДАЧ НА ПРОЦЕНТЫ
РЕШЕНИЕ ОСНОВНЫХЗАДАЧ НА ПРОЦЕНТЫ Клей
Клей Быть гражданином!
Быть гражданином! Такие знакомые и неизвестные нам пчелы
Такие знакомые и неизвестные нам пчелы Обзор аналитических продуктоврынка опционов
Обзор аналитических продуктоврынка опционов Реєстр депонованої заробітної плати. Зразок
Реєстр депонованої заробітної плати. Зразок Евгения Громова Управление по ценностям. Изучение персонала.
Евгения Громова Управление по ценностям. Изучение персонала. Шкалы оценки состояния и прогноза больных: возможности и ограничения
Шкалы оценки состояния и прогноза больных: возможности и ограничения Системный анализ семьи по Б. Хеллингеру
Системный анализ семьи по Б. Хеллингеру Механика проведения аудита выкладки продукции. Arla foods \ starbucks
Механика проведения аудита выкладки продукции. Arla foods \ starbucks Определение компетенций
Определение компетенций Рождественский кролик
Рождественский кролик Формирование ключевых (метапредметных) компетенций как основа учебно-воспитательного процесса в образовательном учреждении
Формирование ключевых (метапредметных) компетенций как основа учебно-воспитательного процесса в образовательном учреждении Диета
Диета Презентация на тему Первые советские награды
Презентация на тему Первые советские награды СОЛОВЬЕВА ЕЛЕНА АНАТОЛЬЕВНА 575-05-05, комн. 450 (гл. корпус),
СОЛОВЬЕВА ЕЛЕНА АНАТОЛЬЕВНА 575-05-05, комн. 450 (гл. корпус),  День письменности
День письменности Person with disability act
Person with disability act Влияние физических упражнений на мышцы
Влияние физических упражнений на мышцы Люди теряют воображение
Люди теряют воображение Бирка на лестницы-стремянки fin
Бирка на лестницы-стремянки fin Простейший ремонт сантехнического оборудования
Простейший ремонт сантехнического оборудования Возрастные психологические особенности занимающихся и их учет в процессе занятий спортом
Возрастные психологические особенности занимающихся и их учет в процессе занятий спортом