- OpenMP

Содержание
- 2. Различие между тредами и процессами Процессы Треды
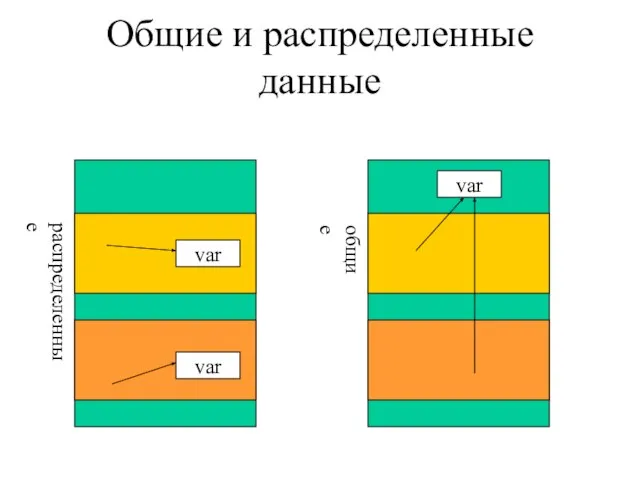
- 3. Общие и распределенные данные var var var распределенные общие
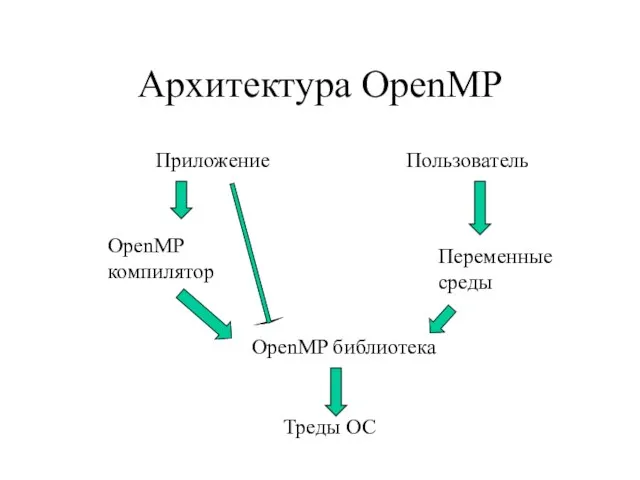
- 4. Архитектура OpenMP Приложение OpenMP компилятор OpenMP библиотека Треды ОС Пользователь Переменные среды
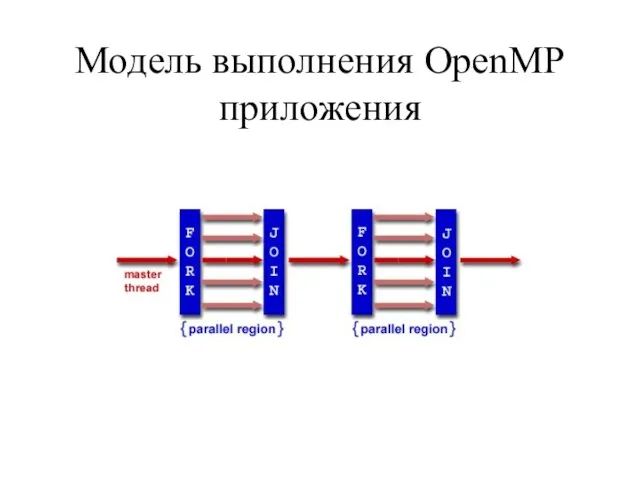
- 5. Модель выполнения OpenMP приложения
- 6. Работа с вычислительным пространством – число тредов Мастер-тред имеет номер 0 Число тредов, выполняющих работу определяется:
- 7. Работа с вычислительным пространством – динамическое определение числа тредов В некоторых случаях целесообразно устанавливать число тредов
- 8. Определение числа процессоров, тредов и своих координат в системе int omp_get_num_procs() возвращает количество процессоров в системе;
- 9. #include #include #include main(int argc, char* argv[]) { omp_set_num_threads(atoi(argv[1])); printf("Total number of processors is %d\n", omp_get_num_procs());
- 10. Общий синтаксис директив OpenMP #pragma omp directive_name [clause[clause ...]] newline Действия, соответствующие директиве применяются непосредственно к
- 11. Директива parallel Данная директива – единственный способ инициировать параллельное выполнение программы. #pragma omp parallel [clause ...]
- 12. #include main () { int nthreads, tid; #pragma omp parallel private(nthreads, tid) { tid = omp_get_thread_num();
- 13. Опции для данных Данные, видимые в области, объемлющей блок параллельного исполнения, являются общими (shared). Переменные, объявленные
- 14. Опция firstprivate обладает той же семантикой, что и опция private. При этом, все копии переменной инициализируются
- 15. Опция default Опция default задает опцию по-умолчанию для переменных. Пример: #pragma omp parallel default(private) Опция shared
- 16. опция reduction Опция reduction определяет что на выходе из параллельного блока переменная получит комбинированное значение. Пример:
- 17. Глобальные общие данные Проблема: опция private «работает» только для статически-видимых ссылок в пределах параллельного участка: static
- 18. Директива threadprivate #omp threadprivate (список глобальных переменных) переменные становятся общими для всех тредов: static int a;
- 19. Опция copyin Опция copyin директивы parallel определяет порядок инициализации threadprivate-переменных: эти переменные инициализируются значением на master-треде
- 20. Управление распределением вычислений Для распределения вычислений применяются конструкции: for sections single
- 21. Директива for #pragma omp for [clause ...] clause: schedule (type [,chunk]) ordered private (list) firstprivate (list)
- 22. Директива предшествует циклу for канонического типа: for(init-expr, var logical_op b, incr_expr) init_expr ::= var = expr
- 23. incr_expr ::= var ++ ++ var var -- -- var var += incr var -= incr
- 24. Опция shedule директивы for Опция shedule допускает следующие аргументы: static - распределение осуществляется статически; dynamic -
- 25. Особенности опции schedule директивы for аргумент chunk можноиспользовать только вместе с типами static, dynamic, guided по
- 26. #include #include #include main(int argc, char* argv[]) { int n, iters, t, i, j; double *a,
- 27. #include #include #include #include main(int argc, char* argv[]) { int n, iters, t, i, j; double
- 28. Результаты эксперимента Компьютер: 2 x 64-разрядный процессор Intel® Itanium-2® 1.6 ГГц.
- 29. Директива sections #pragma omp sections [clause ...] structured_block clause: private (list) firstprivate (list) lastprivate (list) reduction
- 30. Опция lastprivate обладает той же семантикой, что и опция private. При этом, значение переменной после завершения
- 31. Директива single #pragma omp single [clause ...] structured_block Директива single определяет что последующий блок будет выполняться
- 32. Директивы синхронизации master critical barrier atomic flush ordered
- 33. #pragma omp master определяет секцию кода, выполняемого только master-тредом #pragma omp critical [(name)] определяет секцию кода,
- 34. #pragma omp atomic ::== x binop = expr x ++ ++ x x -- -- x
- 35. #paragma omp flush [var-list] ::== x binop = expr x ++ ++ x x -- --
- 36. Решение уравнения Пуассона методом верхней релаксации d2u/dx2 + d2u/dy2 – a * u = f 1
- 37. Разностная схема uijnew = uij – w /b *((ui-1,j + ui+1,j)/dx2 + (ui,j-1 + +ui,j+1)/dy2 +
- 39. Скачать презентацию
Слайд 3Общие и распределенные данные
var
var
var
распределенные
общие
Общие и распределенные данные
var
var
var
распределенные
общие
Слайд 4Архитектура OpenMP
Приложение
OpenMP
компилятор
OpenMP библиотека
Треды ОС
Пользователь
Переменные
среды
Архитектура OpenMP
Приложение
OpenMP
компилятор
OpenMP библиотека
Треды ОС
Пользователь
Переменные
среды
Слайд 5Модель выполнения OpenMP приложения
Модель выполнения OpenMP приложения
Слайд 6Работа с вычислительным пространством – число тредов
Мастер-тред имеет номер 0
Число
Работа с вычислительным пространством – число тредов
Мастер-тред имеет номер 0
Число

Слайд 7Работа с вычислительным пространством – динамическое определение числа тредов
В некоторых случаях целесообразно
Работа с вычислительным пространством – динамическое определение числа тредов
В некоторых случаях целесообразно

Слайд 8Определение числа процессоров, тредов и своих координат в системе
int omp_get_num_procs() возвращает количество
Определение числа процессоров, тредов и своих координат в системе
int omp_get_num_procs() возвращает количество

Слайд 9#include
#include
#include
main(int argc, char* argv[])
{
omp_set_num_threads(atoi(argv[1]));
printf("Total number of processors
#include
main(int argc, char* argv[])
{
omp_set_num_threads(atoi(argv[1]));
printf("Total number of processors
![#include #include #include main(int argc, char* argv[]) { omp_set_num_threads(atoi(argv[1])); printf("Total number of](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/420390/slide-8.jpg)
Слайд 10Общий синтаксис директив OpenMP
#pragma omp directive_name [clause[clause ...]] newline
Действия, соответствующие директиве применяются
Общий синтаксис директив OpenMP
#pragma omp directive_name [clause[clause ...]] newline
Действия, соответствующие директиве применяются
![Общий синтаксис директив OpenMP #pragma omp directive_name [clause[clause ...]] newline Действия, соответствующие](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/420390/slide-9.jpg)
Слайд 11Директива parallel
Данная директива – единственный способ инициировать
параллельное выполнение программы.
#pragma omp parallel [clause
Директива parallel
Данная директива – единственный способ инициировать
параллельное выполнение программы.
#pragma omp parallel [clause

Слайд 12#include
main () {
int nthreads, tid;
#pragma omp parallel private(nthreads, tid)
{
tid
#include
main () {
int nthreads, tid;
#pragma omp parallel private(nthreads, tid)
{
tid

Слайд 13Опции для данных
Данные, видимые в области, объемлющей блок параллельного
исполнения, являются общими (shared).
Опции для данных
Данные, видимые в области, объемлющей блок параллельного
исполнения, являются общими (shared).

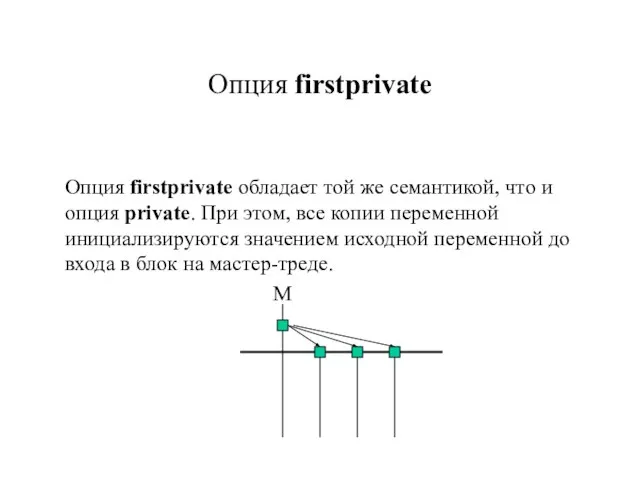
Слайд 14Опция firstprivate обладает той же семантикой, что и
опция private. При этом,
Опция firstprivate обладает той же семантикой, что и
опция private. При этом,
Слайд 15Опция default
Опция default задает опцию по-умолчанию для
переменных. Пример:
#pragma omp parallel default(private)
Опция shared
Опция
Опция default
Опция default задает опцию по-умолчанию для
переменных. Пример:
#pragma omp parallel default(private)
Опция shared
Опция

Слайд 16опция reduction
Опция reduction определяет что на выходе из параллельного блока переменная получит
опция reduction
Опция reduction определяет что на выходе из параллельного блока переменная получит

Слайд 17Глобальные общие данные
Проблема: опция private «работает» только для статически-видимых ссылок в пределах
Глобальные общие данные
Проблема: опция private «работает» только для статически-видимых ссылок в пределах

Слайд 18Директива threadprivate
#omp threadprivate (список глобальных переменных)
переменные становятся общими для всех тредов:
static int
Директива threadprivate
#omp threadprivate (список глобальных переменных)
переменные становятся общими для всех тредов:
static int

Слайд 19Опция copyin
Опция copyin директивы parallel определяет порядок инициализации threadprivate-переменных: эти переменные
Опция copyin
Опция copyin директивы parallel определяет порядок инициализации threadprivate-переменных: эти переменные

Слайд 20Управление распределением
вычислений
Для распределения вычислений применяются
конструкции:
for
sections
single
Управление распределением
вычислений
Для распределения вычислений применяются
конструкции:
for
sections
single

Слайд 21Директива for
#pragma omp for [clause ...]
clause:
schedule (type [,chunk])
ordered
Директива for
#pragma omp for [clause ...]
clause:
schedule (type [,chunk])
ordered
![Директива for #pragma omp for [clause ...] clause: schedule (type [,chunk]) ordered](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/420390/slide-20.jpg)
Слайд 22Директива предшествует циклу for канонического типа:
for(init-expr, var logical_op b, incr_expr)
init_expr ::=
for(init-expr, var logical_op b, incr_expr)
init_expr ::=

Слайд 23incr_expr ::= var ++
++ var
var --
-- var
var += incr
var -= incr
var
incr_expr ::= var ++
++ var
var --
-- var
var += incr
var -= incr
var

Слайд 24Опция shedule директивы for
Опция shedule допускает следующие аргументы:
static - распределение осуществляется статически;
dynamic
Опция shedule директивы for
Опция shedule допускает следующие аргументы:
static - распределение осуществляется статически;
dynamic

Слайд 25Особенности опции schedule директивы for
аргумент chunk можноиспользовать только вместе с типами
Особенности опции schedule директивы for
аргумент chunk можноиспользовать только вместе с типами

Слайд 26#include
#include
#include
main(int argc, char* argv[])
{
int n, iters, t, i,
#include
![#include #include #include main(int argc, char* argv[]) { int n, iters, t,](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/420390/slide-25.jpg)
Слайд 27#include
#include
#include
#include
main(int argc, char* argv[])
{
int n, iters, t,
#include
main(int argc, char* argv[])
{
int n, iters, t,
![#include #include #include #include main(int argc, char* argv[]) { int n, iters,](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/420390/slide-26.jpg)
Слайд 28Результаты эксперимента
Компьютер: 2 x 64-разрядный процессор Intel® Itanium-2® 1.6 ГГц.
Результаты эксперимента
Компьютер: 2 x 64-разрядный процессор Intel® Itanium-2® 1.6 ГГц.

Слайд 29Директива sections
#pragma omp sections [clause ...]
structured_block
clause: private (list)
firstprivate (list)
Директива sections
#pragma omp sections [clause ...]
structured_block
clause: private (list)
firstprivate (list)
![Директива sections #pragma omp sections [clause ...] structured_block clause: private (list) firstprivate](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/420390/slide-28.jpg)
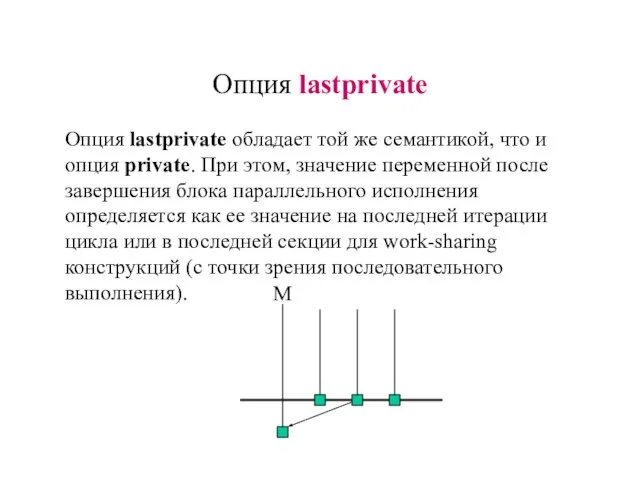
Слайд 30Опция lastprivate обладает той же семантикой, что и
опция private. При этом,
Опция lastprivate обладает той же семантикой, что и
опция private. При этом,
Слайд 31Директива single
#pragma omp single [clause ...]
structured_block
Директива single определяет что последующий
блок будет
Директива single
#pragma omp single [clause ...]
structured_block
Директива single определяет что последующий
блок будет
![Директива single #pragma omp single [clause ...] structured_block Директива single определяет что](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/420390/slide-30.jpg)
Слайд 32Директивы синхронизации
master
critical
barrier
atomic
flush
ordered
Директивы синхронизации
master
critical
barrier
atomic
flush
ordered

Слайд 33#pragma omp master
определяет секцию кода, выполняемого только master-тредом
#pragma omp critical [(name)]
определяет секцию
#pragma omp master
определяет секцию кода, выполняемого только master-тредом
#pragma omp critical [(name)]
определяет секцию

Слайд 34#pragma omp atomic
::==
x binop = expr
x ++
++ x
x --
-- x
#pragma omp atomic
x binop = expr
x ++
++ x
x --
-- x

Слайд 35#paragma omp flush [var-list]
::==
x binop = expr
x ++
++ x
x --
--
#paragma omp flush [var-list]
x binop = expr
x ++
++ x
x --
--
![#paragma omp flush [var-list] ::== x binop = expr x ++ ++](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/420390/slide-34.jpg)
Слайд 36Решение уравнения Пуассона
методом верхней релаксации
d2u/dx2 + d2u/dy2 – a * u =
Решение уравнения Пуассона
методом верхней релаксации
d2u/dx2 + d2u/dy2 – a * u =

Слайд 37Разностная схема
uijnew = uij – w /b *((ui-1,j + ui+1,j)/dx2 + (ui,j-1
Разностная схема
uijnew = uij – w /b *((ui-1,j + ui+1,j)/dx2 + (ui,j-1

 МЕХАНИЗМ СТИМУЛИРОВАНИЯ НАКОПЛЕНИЯ И СОФИНАНСИРОВАНИЯ РЕМОНТА И ВОССТАНОВЛЕНИЯ ОБЩЕГО ИМУЩЕСТВА ОБЪЕКТА КОНДОМИНИУМА
МЕХАНИЗМ СТИМУЛИРОВАНИЯ НАКОПЛЕНИЯ И СОФИНАНСИРОВАНИЯ РЕМОНТА И ВОССТАНОВЛЕНИЯ ОБЩЕГО ИМУЩЕСТВА ОБЪЕКТА КОНДОМИНИУМА Love Rules the World
Love Rules the World Здоровый образ жизни. Культура и общение
Здоровый образ жизни. Культура и общение Строение и функции белков
Строение и функции белков Основные этапы и элементы организации маршрутных перевозок
Основные этапы и элементы организации маршрутных перевозок АУДИТ САЙТА
АУДИТ САЙТА  Взаимосвязь фискальной политики и экономического роста
Взаимосвязь фискальной политики и экономического роста Шепеленко Татьяна Анатольевна, учитель русского языка и литературы, классный руководитель Персональный сайт: http://shepelenko.ukoz.ru
Шепеленко Татьяна Анатольевна, учитель русского языка и литературы, классный руководитель Персональный сайт: http://shepelenko.ukoz.ru Экскурсионные заметки
Экскурсионные заметки ДОБРО ПОЖАЛОВАТЬ В ИГХТУ!
ДОБРО ПОЖАЛОВАТЬ В ИГХТУ! Почему летают самолёты?
Почему летают самолёты? Дизайн тренажёра
Дизайн тренажёра Эффект волшебного стекла
Эффект волшебного стекла Хокку - чудо Японской поэзии
Хокку - чудо Японской поэзии Селекция, её задачи и основные направления
Селекция, её задачи и основные направления  ГИС АО Навигатор дополнительного образования детей
ГИС АО Навигатор дополнительного образования детей Константин Дмитриевич Ушинский. Аннотированный список главных трудов
Константин Дмитриевич Ушинский. Аннотированный список главных трудов Famous British writers
Famous British writers  ПУБЛИЧНАЯ ПРЕЗЕНТАЦИЯ СИБАТРОВ ВАСИЛИЙ ПАВЛОВИЧ,
ПУБЛИЧНАЯ ПРЕЗЕНТАЦИЯ СИБАТРОВ ВАСИЛИЙ ПАВЛОВИЧ, Моё имя Алина
Моё имя Алина Металлы. Общая характеристика металлов (нахождение в природе и физические свойства)
Металлы. Общая характеристика металлов (нахождение в природе и физические свойства) Diletantof.net. Выполнение студенческих работ на заказ
Diletantof.net. Выполнение студенческих работ на заказ Реклама на мобильных платформах, видео реклама
Реклама на мобильных платформах, видео реклама Сетевой подход в маркетинге как основа коммерциализации инноваций
Сетевой подход в маркетинге как основа коммерциализации инноваций Презентация на тему Пушные звери
Презентация на тему Пушные звери Новые аккумуляторы
Новые аккумуляторы Искусствознание и культура
Искусствознание и культура Традиции - ключ к патриотическому самосознанию
Традиции - ключ к патриотическому самосознанию