- Помехоустойчивое кодирование

Содержание
- 2. Для защиты полезной информации необходимо вводить избыточность (смысловая, физическая, статистическая, ) Коды, позволяющие обнаруживать и исправлять
- 3. Надежность обеспечивается тем, что наряду с битами, непосредственно кодирующими сообщение (будем называть их информационными битами), передаются
- 4. Задача обнаружения ошибки может быть решена довольно легко. Достаточно передавать каждую букву сообщения дважды. Например, при
- 5. Например, для информационного байта 01010100 бит четности будет иметь значение 1, а для байта 11011011 бит
- 6. Можно было бы предложить простой способ установления ошибки – передавать каждый символ трижды, например, «гггооорррааа» –
- 7. Приведенную избыточность следует считать минимальной (это указывает ее индекс), поскольку при передаче сообщения по каналу, характеризуемому
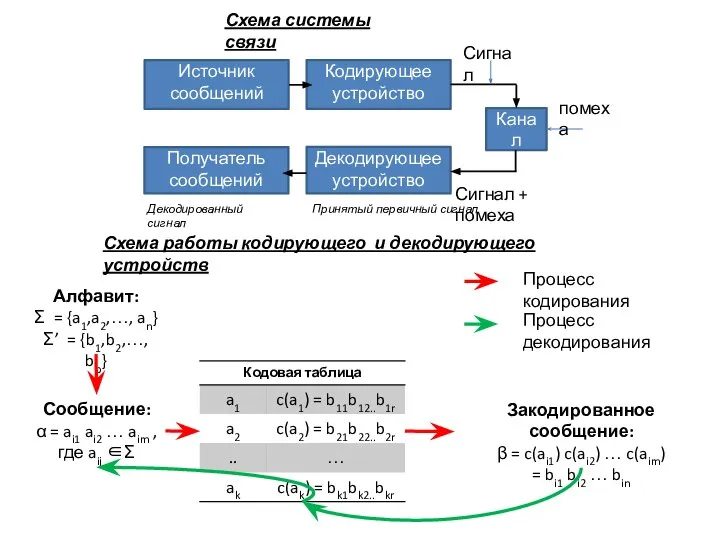
- 8. Источник сообщений Кодирующее устройство Канал Получатель сообщений Декодирующее устройство Сигнал Сигнал + помеха Принятый первичный сигнал
- 9. Геометрическая интерпретация построения кодовых слов Пусть α= 101011 – вектор в пространстве или точка в пространстве
- 11. α1 α2 … αp Канал связи α1 α2 … αp Передача сообщений Существуют следующие способы борьбы
- 12. Код с проверкой на четность m 1 n = m+1 Описание: Код дополняется 1 контрольным разрядом,
- 13. Примеры кодов Замечания. Увеличение избыточности передаваемых кодов приводит к тому, что появляется возможность не только обнаружить,
- 14. Примеры кодов Один заданный информационный символ повторяется n раз. Это (n, 1)-код. Для него минимальное расстояние
- 15. Определение: Минимальное расстояние, взятое по всем парам кодовых разрешенных комбинаций кода, называют (минимальным) кодовым расстоянием (d0min).
- 16. При взаимно независимых ошибках наиболее вероятен переход в кодовую комбинацию, отличающуюся от данной в наименьшем числе
- 17. Кодовое расстояние (d) Если кодовое расстояние d = 1 (избыточность в коде отсутствует), то не могут
- 18. Как видно из рисунка ими являются 110, 011, 101. Для исправления одиночной ошибки расстояние от точки
- 19. Идея исправления ошибки в кодах-спутниках весьма проста. Главное, чтобы при искажении любой комбинации не могла быть
- 20. В общем случае при необходимости обнаруживать ошибки кратности до r включительно минимальное хэммингово расстояние между разрешенными
- 21. Пример. Рассмотрим (2,3)–код с проверкой на четность. Множество кодовых слов есть 000, 101, 011, 110. Минимальное
- 22. Код Хэмминга. Общее описание d0min = 3 Когда при передаче кодового слова возникает одиночная ошибка, окажутся
- 23. Порядок кодирования по методу Хемминга
- 24. и Зависимость между числом информационных и проверочных разрядов Соотношение между количеством информационных и контрольных символов в
- 25. Пример. Матрица кода Хэмминга (15,11) Определение мест расположения и значений контрольных символов Строки матрицы – это
- 26. Целесообразно выбирать такое размещение контрольных символов в кодовой комбинации, при которой каждый из них включается в
- 27. Порядок проведения проверок и декодирования При получении закодированного по методу Хэмминга сообщения необходимо проверить выполнимость соотношений
- 28. Алгоритм декодирования кода Хэмминга: Провести проверку всех битов чётности Если все биты чётности верны, то перейти
- 29. Пример: Закодировать сообщение 1101 кодом Хэмминга. m=4, k=3,n=7 0 0 0 1 1 1 1 H
- 30. Для обнаружения и исправления одиночной ошибки соотношение между числом информационных разрядов m и числом корректирующих разрядов
- 31. Для кодов, обнаруживающих все трехкратные ошибки (d0min = 4) Для кодов длиной в n символов, исправляющих
- 32. Для кодов, исправляющих S ошибок (d0min = 2S + 1), В настоящее время разработаны десятки кодов,
- 34. Скачать презентацию
Слайд 2Для защиты полезной информации необходимо вводить избыточность (смысловая, физическая, статистическая, )
Коды, позволяющие
Для защиты полезной информации необходимо вводить избыточность (смысловая, физическая, статистическая, )
Коды, позволяющие

Слайд 3Надежность обеспечивается тем, что наряду с битами, непосредственно кодирующими сообщение (будем называть
Надежность обеспечивается тем, что наряду с битами, непосредственно кодирующими сообщение (будем называть

Слайд 4Задача обнаружения ошибки может быть решена довольно легко. Достаточно передавать каждую букву
Задача обнаружения ошибки может быть решена довольно легко. Достаточно передавать каждую букву

Слайд 5Например, для информационного байта 01010100 бит четности будет иметь значение 1, а
Например, для информационного байта 01010100 бит четности будет иметь значение 1, а

Слайд 6Можно было бы предложить простой способ установления ошибки – передавать каждый символ
Можно было бы предложить простой способ установления ошибки – передавать каждый символ

Слайд 7Приведенную избыточность следует считать минимальной (это указывает ее индекс), поскольку при передаче
Приведенную избыточность следует считать минимальной (это указывает ее индекс), поскольку при передаче

Слайд 8Источник сообщений
Кодирующее устройство
Канал
Получатель сообщений
Декодирующее устройство
Сигнал
Сигнал + помеха
Принятый первичный сигнал
Декодированный сигнал
помеха
Схема системы
Источник сообщений
Кодирующее устройство
Канал
Получатель сообщений
Декодирующее устройство
Сигнал
Сигнал + помеха
Принятый первичный сигнал
Декодированный сигнал
помеха
Схема системы
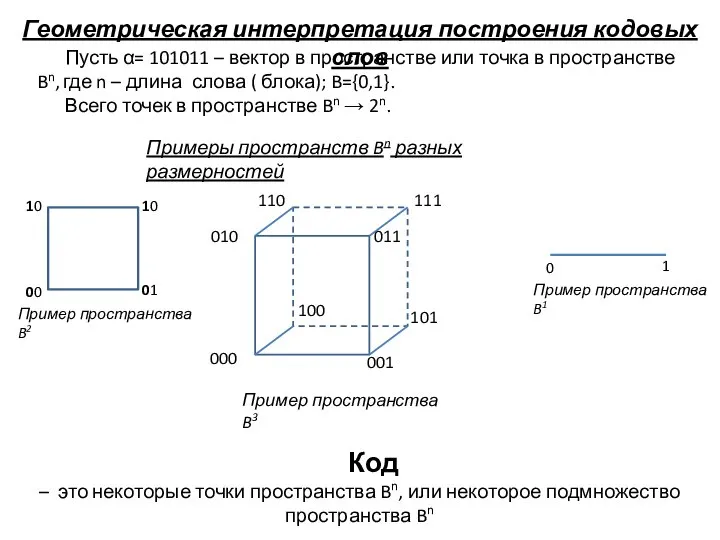
Слайд 9Геометрическая интерпретация построения кодовых слов
Пусть α= 101011 – вектор в пространстве или
Геометрическая интерпретация построения кодовых слов
Пусть α= 101011 – вектор в пространстве или

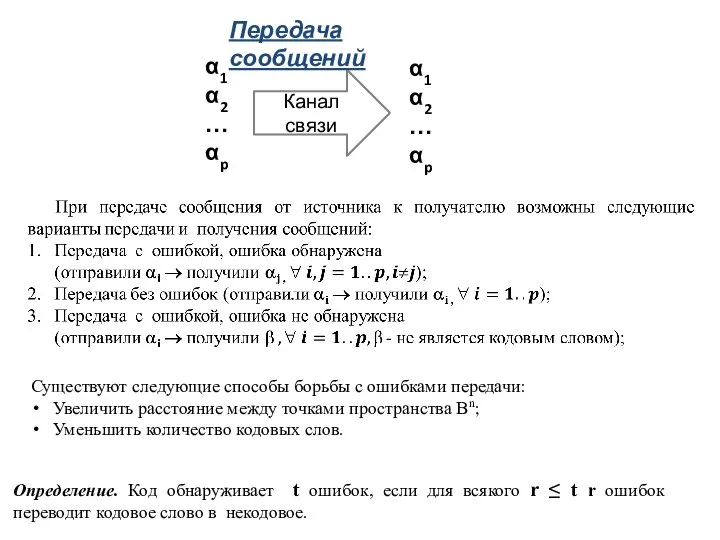
Слайд 11
α1
α2
…
αp
Канал связи
α1
α2
…
αp
Передача сообщений
Существуют следующие способы борьбы с ошибками передачи:
Увеличить расстояние между точками
α1
α2
…
αp
Канал связи
α1
α2
…
αp
Передача сообщений
Существуют следующие способы борьбы с ошибками передачи:
Увеличить расстояние между точками
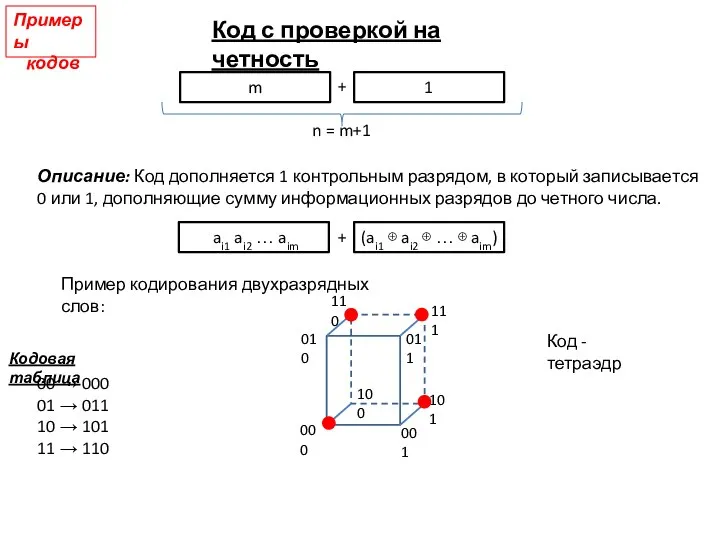
Слайд 12Код с проверкой на четность
m
1
n = m+1
Описание: Код дополняется 1 контрольным разрядом,
Код с проверкой на четность
m
1
n = m+1
Описание: Код дополняется 1 контрольным разрядом,
Слайд 13Примеры
кодов
Замечания.
Увеличение избыточности передаваемых кодов приводит к тому, что появляется возможность
Примеры
кодов
Замечания.
Увеличение избыточности передаваемых кодов приводит к тому, что появляется возможность
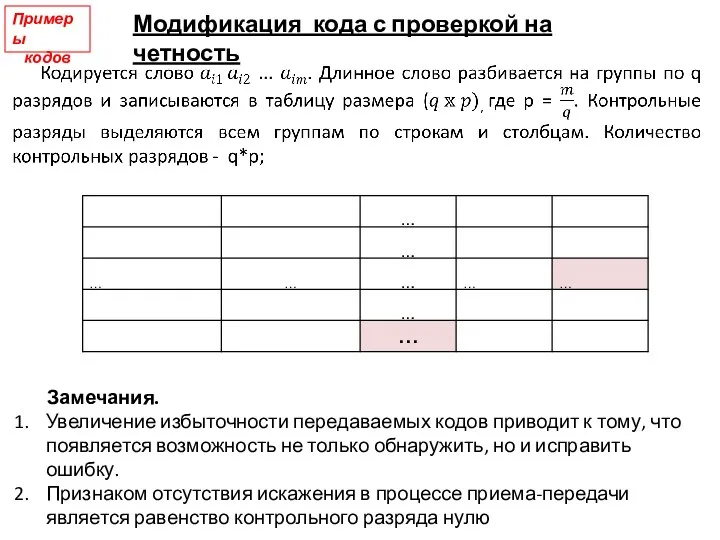
Слайд 14Примеры кодов
Один заданный информационный символ повторяется n раз. Это (n, 1)-код. Для
Примеры кодов
Один заданный информационный символ повторяется n раз. Это (n, 1)-код. Для

Слайд 15
Определение: Минимальное расстояние, взятое по всем парам кодовых разрешенных комбинаций кода, называют
Определение: Минимальное расстояние, взятое по всем парам кодовых разрешенных комбинаций кода, называют

Слайд 16При взаимно независимых ошибках наиболее вероятен переход в кодовую комбинацию, отличающуюся от
При взаимно независимых ошибках наиболее вероятен переход в кодовую комбинацию, отличающуюся от

Слайд 17Кодовое расстояние (d)
Если кодовое расстояние d = 1 (избыточность в коде отсутствует),
Кодовое расстояние (d)
Если кодовое расстояние d = 1 (избыточность в коде отсутствует),
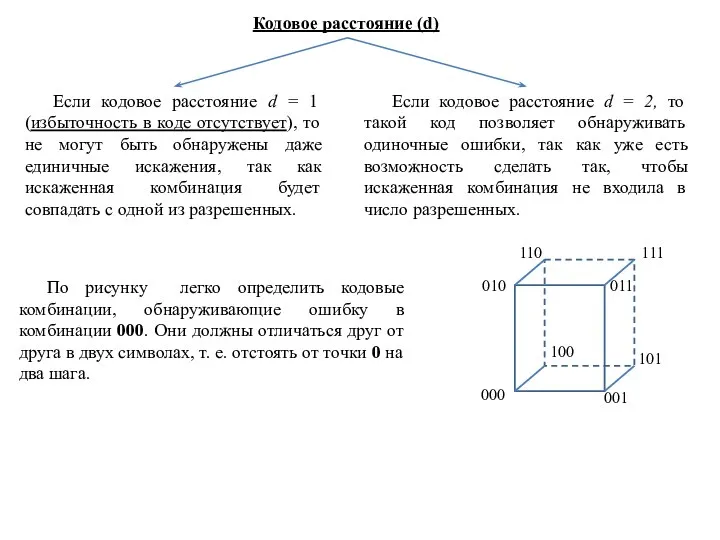
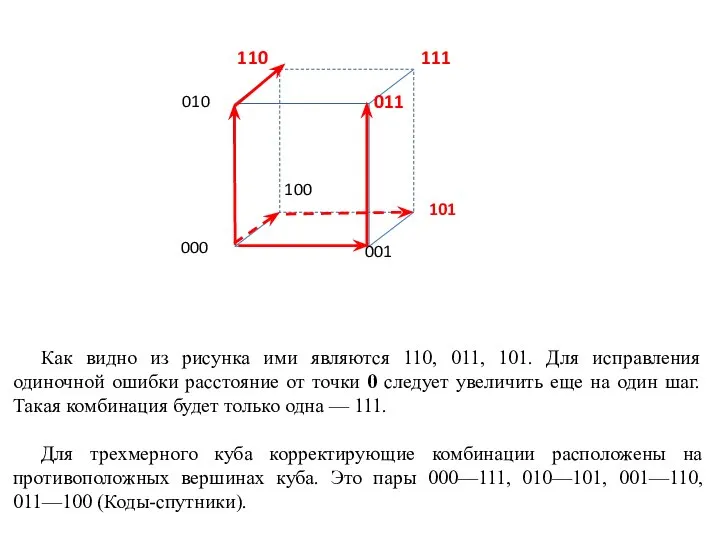
Слайд 18Как видно из рисунка ими являются 110, 011, 101. Для исправления одиночной
Как видно из рисунка ими являются 110, 011, 101. Для исправления одиночной
Слайд 19Идея исправления ошибки в кодах-спутниках весьма проста. Главное, чтобы при искажении любой
Идея исправления ошибки в кодах-спутниках весьма проста. Главное, чтобы при искажении любой

Слайд 20В общем случае при необходимости обнаруживать ошибки кратности до r включительно минимальное
В общем случае при необходимости обнаруживать ошибки кратности до r включительно минимальное

Слайд 21Пример. Рассмотрим (2,3)–код с проверкой на четность. Множество кодовых слов есть 000,
Пример. Рассмотрим (2,3)–код с проверкой на четность. Множество кодовых слов есть 000,

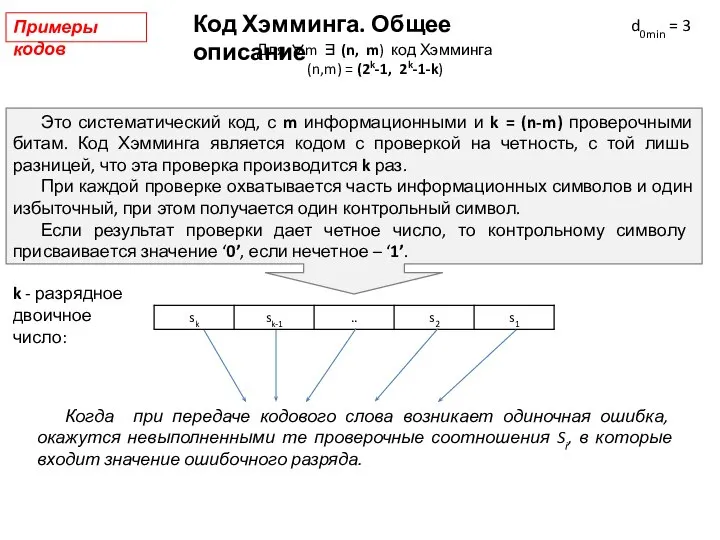
Слайд 22Код Хэмминга. Общее описание
d0min = 3
Когда при передаче кодового слова возникает одиночная
Код Хэмминга. Общее описание
d0min = 3
Когда при передаче кодового слова возникает одиночная
Слайд 23
Порядок кодирования по методу Хемминга
Порядок кодирования по методу Хемминга

Слайд 24
и
Зависимость между числом информационных и проверочных разрядов
Соотношение между количеством информационных и контрольных
и
Зависимость между числом информационных и проверочных разрядов
Соотношение между количеством информационных и контрольных

Слайд 25Пример. Матрица кода Хэмминга (15,11)
Определение мест расположения и значений контрольных символов
Строки матрицы
Пример. Матрица кода Хэмминга (15,11)
Определение мест расположения и значений контрольных символов
Строки матрицы

Слайд 26Целесообразно выбирать такое размещение контрольных символов в кодовой комбинации, при которой каждый
Целесообразно выбирать такое размещение контрольных символов в кодовой комбинации, при которой каждый

Слайд 27Порядок проведения проверок и декодирования
При получении закодированного по методу Хэмминга сообщения необходимо
Порядок проведения проверок и декодирования
При получении закодированного по методу Хэмминга сообщения необходимо

Слайд 28Алгоритм декодирования кода Хэмминга:
Провести проверку всех битов чётности
Если все биты чётности верны,
Алгоритм декодирования кода Хэмминга:
Провести проверку всех битов чётности
Если все биты чётности верны,

Слайд 29Пример: Закодировать сообщение 1101 кодом Хэмминга.
m=4, k=3,n=7
0 0 0 1
Пример: Закодировать сообщение 1101 кодом Хэмминга.
m=4, k=3,n=7
0 0 0 1

Слайд 30Для обнаружения и исправления одиночной ошибки соотношение между числом информационных разрядов m
Для обнаружения и исправления одиночной ошибки соотношение между числом информационных разрядов m

Слайд 31Для кодов, обнаруживающих все трехкратные ошибки (d0min = 4)
Для кодов длиной в
Для кодов, обнаруживающих все трехкратные ошибки (d0min = 4)
Для кодов длиной в

Слайд 32Для кодов, исправляющих S ошибок (d0min = 2S + 1),
В настоящее время
Для кодов, исправляющих S ошибок (d0min = 2S + 1),
В настоящее время

 Информационные технологии в электротехнике
Информационные технологии в электротехнике ПАКЕТ
ПАКЕТ Электрическая схема
Электрическая схема Пропорции и особенности изображения животных
Пропорции и особенности изображения животных Методическая служба МБОУ Большесундырская СОШ им.В.А.Верендеева Моргаушского района Чувашской Республики
Методическая служба МБОУ Большесундырская СОШ им.В.А.Верендеева Моргаушского района Чувашской Республики Why We All Need to Get A Girlfriend
Why We All Need to Get A Girlfriend Расписание занятий по пинг - понгу
Расписание занятий по пинг - понгу тема 1.2 Суповое отд
тема 1.2 Суповое отд Путешествие по осеннему лесу
Путешествие по осеннему лесу Управление качеством
Управление качеством tls2
tls2 План реализации мероприятий Технологической платформы «Медицина будущего» по направлению «Многокомпонентные биокомпозиционн
План реализации мероприятий Технологической платформы «Медицина будущего» по направлению «Многокомпонентные биокомпозиционн Ланцетники
Ланцетники Атеизм как религия
Атеизм как религия Автопортрет Т.Г. Шевченко
Автопортрет Т.Г. Шевченко Социальные пособия. 6 классы
Социальные пособия. 6 классы Бриф 05.02.2019 для раздела Правильное питание
Бриф 05.02.2019 для раздела Правильное питание Исковое производство
Исковое производство Тоталитарные интернет-сообщества: как избежать, победить и выжить в мире ловцов виртуальных душ
Тоталитарные интернет-сообщества: как избежать, победить и выжить в мире ловцов виртуальных душ Донской А.Г. 26.01._Об особенностях реализации НПП
Донской А.Г. 26.01._Об особенностях реализации НПП Презентация на тему Становление новой России
Презентация на тему Становление новой России Влияние рок- музыки на здоровье подростка
Влияние рок- музыки на здоровье подростка Valuation exercise,или почем сегодня Yandex
Valuation exercise,или почем сегодня Yandex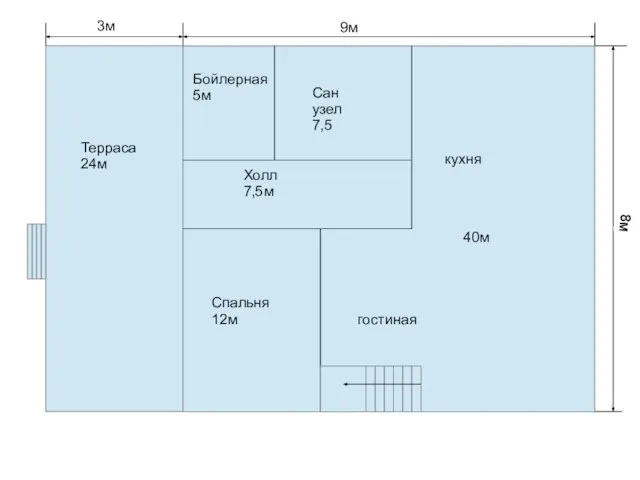 Дом. Планировка
Дом. Планировка Классификация видов термической обработки стали. Отжиг. (Лекция 6)
Классификация видов термической обработки стали. Отжиг. (Лекция 6) Rytsarskaya_kultura_v_Evrope (1)
Rytsarskaya_kultura_v_Evrope (1) Права инвалидов
Права инвалидов Влияние вредных привычек на сердечно-сосудистую и дыхательную системы
Влияние вредных привычек на сердечно-сосудистую и дыхательную системы