- RuSSIR 2008Russian Summer School in Information Retrieval

Содержание
- 2. Немного истории Идея проведения RuSSIR’ов принадлежит Павлу Браславскому Школы проводятся совместно с РОМИП Школы поддерживаются и
- 3. Немного статистики Таганрогский технологический институт Южного федерального университета 4 полных курса, 1 краткий и 1 лекция
- 4. Курс Text Mining, Information and Fact Extraction Marie-Francine Moens (Katholieke Universiteit Leuven), Belgium
- 5. Text Mining, Information and Fact Extraction Цель: извлечение конкретных фактов из текста на естественном языке Лексическая
- 6. Text Mining, Information and Fact Extraction Методы классификации: SVM, Байес, принцип максимальной энтропии Контекстно-зависимая классификация: Hidden
- 7. Курс Поиск изображений по содержанию Наталья Васильева (HP Labs) Санкт-Петербург, Россия
- 8. Поиск изображений по содержанию Задачи Image Retrieval: поиск изображений, похожих на заданный пример, поиск по заданной
- 9. Поиск изображений по содержанию 3) Уровни свойств изображения Цвет(цветовые пространства, гистограммы) Текстура(статистические свойства, фильтры, вэйвлеты) Форма(методы
- 10. Поиск изображений по содержанию 4) Сегментация 5) Многомерное индексирование Деревья(R, Quad, VP и тд) Locality Sensitive
- 11. Data Structures in IR Максим Губин (Ask.com, США) Курс
- 12. Data Structures in IR Индексация, структуры хранения данных, методы сжатия, распараллеливание Поиск, слияние списков, отсечение, кэширование,
- 13. Курс Hands-on Natural Language Processing for Information Access Applications Horacio Saggion (University of Sheffield)
- 14. Natural Language Processing for Information Access Извлечение информации из текста выявление именованных сущностей поиск связей между
- 15. Natural Language Processing for Information Access Question Answering получение ответа на запрос, сформулированный на естественном языке
- 16. Короткий курс IR in Social Media Alexey Maykov, Microsoft LiveLabs Чем отличается Social Media от обычных
- 17. Лекция. Темы дня в блогах: Как это работает Антон Волнухин Андрей Мищенко Что такое «темы дня»
- 18. Конференция молодых ученых Константин Артемьев Метод вероятностного морфологического анализа для задач полнотекстового индексированного поиска Александр Сибиряков
- 19. Конференция молодых ученых
- 20. Неформальное Welcome Party
- 21. Неформальное Футбольный матч 12 – 0 в пользу студентов!
- 22. Неформальное RuSSIR Party
- 23. Неформальное Мафия по ночам
- 24. Неформальное Последствия мафии
- 25. А на самом деле:
- 27. Скачать презентацию
Слайд 2Немного истории
Идея проведения RuSSIR’ов принадлежит Павлу Браславскому
Школы проводятся совместно с РОМИП
Школы
Немного истории
Идея проведения RuSSIR’ов принадлежит Павлу Браславскому
Школы проводятся совместно с РОМИП
Школы

Слайд 3Немного статистики
Таганрогский технологический институт Южного федерального университета
4 полных курса, 1 краткий
Немного статистики
Таганрогский технологический институт Южного федерального университета
4 полных курса, 1 краткий

Слайд 4Курс
Text Mining, Information and Fact Extraction
Marie-Francine Moens
(Katholieke Universiteit Leuven), Belgium
Курс
Text Mining, Information and Fact Extraction
Marie-Francine Moens
(Katholieke Universiteit Leuven), Belgium

Слайд 5Text Mining, Information and Fact Extraction
Цель: извлечение конкретных фактов из текста на
Text Mining, Information and Fact Extraction
Цель: извлечение конкретных фактов из текста на

Слайд 6Text Mining, Information and Fact Extraction
Методы классификации: SVM, Байес, принцип максимальной энтропии
Контекстно-зависимая
Text Mining, Information and Fact Extraction
Методы классификации: SVM, Байес, принцип максимальной энтропии
Контекстно-зависимая

Слайд 7Курс
Поиск изображений
по содержанию
Наталья Васильева
(HP Labs)
Санкт-Петербург, Россия
Курс
Поиск изображений
по содержанию
Наталья Васильева
(HP Labs)
Санкт-Петербург, Россия

Слайд 8Поиск изображений по содержанию
Задачи Image Retrieval: поиск изображений, похожих на заданный пример,
Поиск изображений по содержанию
Задачи Image Retrieval: поиск изображений, похожих на заданный пример,

Слайд 9Поиск изображений по содержанию
3) Уровни свойств изображения
Цвет(цветовые пространства, гистограммы)
Текстура(статистические свойства, фильтры, вэйвлеты)
Форма(методы
Поиск изображений по содержанию
3) Уровни свойств изображения
Цвет(цветовые пространства, гистограммы)
Текстура(статистические свойства, фильтры, вэйвлеты)
Форма(методы

Слайд 10Поиск изображений по содержанию
4) Сегментация
5) Многомерное индексирование
Деревья(R, Quad, VP и тд)
Поиск изображений по содержанию
4) Сегментация
5) Многомерное индексирование
Деревья(R, Quad, VP и тд)

Слайд 11Data Structures in IR
Максим Губин (Ask.com, США)
Курс
Data Structures in IR
Максим Губин (Ask.com, США)
Курс

Слайд 12Data Structures in IR
Индексация, структуры хранения данных, методы сжатия, распараллеливание
Поиск, слияние списков,
Data Structures in IR
Индексация, структуры хранения данных, методы сжатия, распараллеливание
Поиск, слияние списков,

Слайд 13Курс
Hands-on Natural Language Processing for Information Access Applications
Horacio Saggion
(University of Sheffield)
Курс
Hands-on Natural Language Processing for Information Access Applications
Horacio Saggion
(University of Sheffield)

Слайд 14Natural Language Processing for Information Access
Извлечение информации из текста
выявление именованных сущностей
поиск связей
Natural Language Processing for Information Access
Извлечение информации из текста
выявление именованных сущностей
поиск связей

Слайд 15Natural Language Processing for Information Access
Question Answering
получение ответа на запрос, сформулированный на
Natural Language Processing for Information Access
Question Answering
получение ответа на запрос, сформулированный на

Слайд 16Короткий курс
IR in Social Media
Alexey Maykov, Microsoft LiveLabs
Чем отличается Social Media от
Короткий курс
IR in Social Media
Alexey Maykov, Microsoft LiveLabs
Чем отличается Social Media от

Слайд 17Лекция. Темы дня в блогах:
Как это работает
Антон Волнухин
Андрей Мищенко
Что такое «темы
Лекция. Темы дня в блогах:
Как это работает
Антон Волнухин
Андрей Мищенко
Что такое «темы

Слайд 18Конференция
молодых ученых
Константин Артемьев
Метод вероятностного морфологического анализа для задач полнотекстового индексированного поиска
Александр
Конференция
молодых ученых
Константин Артемьев
Метод вероятностного морфологического анализа для задач полнотекстового индексированного поиска
Александр

Слайд 19Конференция
молодых ученых
Конференция
молодых ученых

Слайд 20Неформальное
Welcome Party
Неформальное
Welcome Party

Слайд 21Неформальное
Футбольный матч
12 – 0
в пользу студентов!
Неформальное
Футбольный матч
12 – 0
в пользу студентов!

Слайд 22Неформальное
RuSSIR Party
Неформальное
RuSSIR Party

Слайд 23Неформальное
Мафия по ночам
Неформальное
Мафия по ночам

Слайд 24Неформальное
Последствия мафии
Неформальное
Последствия мафии

Слайд 25А на самом деле:
А на самом деле:

 DVIZH_Spotlight_11_mod_2a
DVIZH_Spotlight_11_mod_2a Основные закономерности развития науки Подготовили: студентки 1 курса РТА Группа : 1409ФТД Ломовцева Екатерина и Кройтор Татьяна
Основные закономерности развития науки Подготовили: студентки 1 курса РТА Группа : 1409ФТД Ломовцева Екатерина и Кройтор Татьяна Права і свободи людини три теми
Права і свободи людини три теми Организационно-техническое обеспечение конкурсного отбора программ развития деятельности студенческих объединений вузов 22
Организационно-техническое обеспечение конкурсного отбора программ развития деятельности студенческих объединений вузов 22  Проект идея 2021
Проект идея 2021 Отчетная выставка работ учащихся художественного отделения
Отчетная выставка работ учащихся художественного отделения Эрмитаж (8 класс)
Эрмитаж (8 класс) Презентация на тему Региональный экзамен по математике в 7 классе
Презентация на тему Региональный экзамен по математике в 7 классе Творческий проект
Творческий проект Интеллектуализация процессов обработки потоков данных, лекция 6
Интеллектуализация процессов обработки потоков данных, лекция 6 Презентация на тему Демографическая проблема
Презентация на тему Демографическая проблема  Требования к исследовательским работам учащихся
Требования к исследовательским работам учащихся VELES GROUP. Проблемы и браки традиционной офсетной печати
VELES GROUP. Проблемы и браки традиционной офсетной печати Презентация на тему Письменность Древнего Египта
Презентация на тему Письменность Древнего Египта Комитет Тульской области по предпринимательству и потребительскому рынку Тульский областной фонд поддержки малого предпринимат
Комитет Тульской области по предпринимательству и потребительскому рынку Тульский областной фонд поддержки малого предпринимат Коллективные и индивидуальные средства защиты
Коллективные и индивидуальные средства защиты СТРАТЕГИЧЕСКОЕ ПЛАНИРОВАНИЕ
СТРАТЕГИЧЕСКОЕ ПЛАНИРОВАНИЕ Методические рекомендации по работе с автоматизированной информационно-библиотечной системой «Mark-SQL. Версия для школьных библиот
Методические рекомендации по работе с автоматизированной информационно-библиотечной системой «Mark-SQL. Версия для школьных библиот Способы выделения композиционного центра
Способы выделения композиционного центра Чёваш прозин ёсти
Чёваш прозин ёсти Обучение в ИФНиТ
Обучение в ИФНиТ Интеллектуальные права на правила
Интеллектуальные права на правила Как понять другого человека через познание самого себя?
Как понять другого человека через познание самого себя? Колониальные империи
Колониальные империи Логарифмы. Логарифмическая функция
Логарифмы. Логарифмическая функция Насекомые Урок окружающего мира 2 класс
Насекомые Урок окружающего мира 2 класс О готовности вновь построенного здания школы в с. Фролы Пермского района для приобретения в собственность Пермского района
О готовности вновь построенного здания школы в с. Фролы Пермского района для приобретения в собственность Пермского района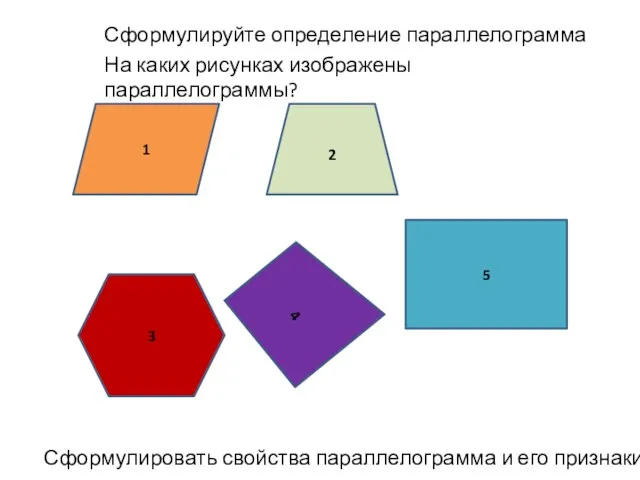 Параллелограмм и трапеция (8 класс)
Параллелограмм и трапеция (8 класс)