- Стек технологий Apache Hadoop. Распределённая файловая система HDFS

Содержание
- 2. Цели Осветить наиболее значимые технологии стека Apache Hadoop для распределённой обработки данных: MapReduce HDFS Hbase ZooKeeper
- 3. Архитектурные принципы Линейная масштабируемость Надёжность и доступность Ненадёжное (commodity) оборудование Перемещение данных дороже перемещения программ Высокая
- 4. MapReduce Фреймворк для распределённых вычислений MapReduce job – 2 этапа Map: { } -> { }
- 5. MapReduce
- 6. MapReduce
- 7. HDFS Иерархия каталогов и файлов Файлы поделены на блоки (128 MB) Метаданные отделены от данных NameNode
- 8. HBase Распределённое ключ-значение хранилище на базе HDFS Таблицы: Строки с уникальными ключами Произвольное количество колонок Колонки
- 9. ZooKeeper Распределённая служба координации распределённых задач Выборы лидера Распределённые блокировки Координация и уведомления о событиях
- 10. Pig Платформа для анализа больших наборов данных Pig Latin – SQL-подобный язык Простота кодирования Возможности оптимизации
- 11. Hive Служит тем же целям, что и Pig Таблицы Типизированные колонки (int, float, string, date, boolean)
- 12. Avro Система сериализации данных Предоставляет: Компактный бинарный формат Удалённые вызовы процедур (RPC) Простая интеграция с динамическими
- 13. HDFS. Поставленные цели Очень большой объём распределённых данных 10К узлов, 100М файлов, 10ПБ данных Ненадёжное (commodity)
- 14. HDFS. Архитектура
- 15. HDFS. Архитектура Общее пространство имён для всего кластера Согласованность данных Write-once-read-many модель доступа Append-запись всё ещё
- 16. HDFS. Архитектура
- 17. HDFS. NameNode Управляет пространством имён Связывает имя файла с набором блоков Связывает блок с набором DN
- 18. HDFS. NameNode. Метаданные Метаданные для всего кластера хранятся в ОП Типы метаданных Списки файлов Списки блоков
- 19. HDFS. DataNode Сервер блоков Хранит данные в локальной ФС Хранит метаданные блоков (CRC) Предоставляет данные и
- 20. HDFS. CheckpointNode Периодически создаёт новый checkpoint образ из checkpoint и journal, загруженных с NN Загружает новый
- 21. HDFS. Запись Клиент запрашивает у NN список DN-кандидатов на запись Начинает конвейерную запись с ближайшего узла
- 22. HDFS. Чтение Клиент запрашивает местоположение реплик блока у NN Начинает чтение с ближайшего узла, содержащего реплику
- 23. HDFS. Расположение реплик Первая реплика помещается на локальном узле Вторая реплика – на узел удалённой стойки
- 24. HDFS. Balancer Процент используемого дискового пространства на всех DN должен быть одинаков Обычно запускается при добавлении
- 25. HDFS. Block Scanner Каждая DN периодически запускает BS BS проверяет, что контрольные суммы соответствуют блокам данных
- 26. HDFS. Интерфейс пользователя Команды пользователя HDFS hadoop fs –mkdir /foodir hadoop fs –cat /foodir/barfile.txt hadoop fs
- 27. HDFS. Веб-интерфейс
- 28. HDFS. Использование в Yahoo! 3500 узлов 2 процессора [email protected] (по 4 ядра) Red Hat Enterprise Linux
- 29. HDFS. Benchmarks Gray Sort benchmark. Сортировка 1 ТБ и 1 ПБ данных. Записи по 100 байт.
- 31. Скачать презентацию
Слайд 2Цели
Осветить наиболее значимые технологии стека Apache Hadoop для распределённой обработки данных:
MapReduce
HDFS
Hbase
ZooKeeper
Pig
Hive
Avro
Рассмотреть
Цели
Осветить наиболее значимые технологии стека Apache Hadoop для распределённой обработки данных:
MapReduce
HDFS
Hbase
ZooKeeper
Pig
Hive
Avro
Рассмотреть

Слайд 3Архитектурные принципы
Линейная масштабируемость
Надёжность и доступность
Ненадёжное (commodity) оборудование
Перемещение данных дороже перемещения программ
Высокая производительность
Архитектурные принципы
Линейная масштабируемость
Надёжность и доступность
Ненадёжное (commodity) оборудование
Перемещение данных дороже перемещения программ
Высокая производительность

Слайд 4MapReduce
Фреймворк для распределённых вычислений
MapReduce job – 2 этапа
Map: {} -> {}
Reduce: {}
MapReduce
Фреймворк для распределённых вычислений
MapReduce job – 2 этапа
Map: {
Reduce: {

Слайд 5MapReduce
MapReduce
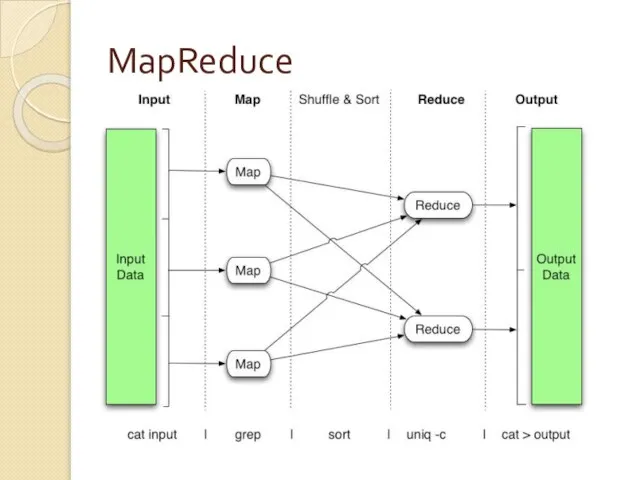
Слайд 6MapReduce
MapReduce
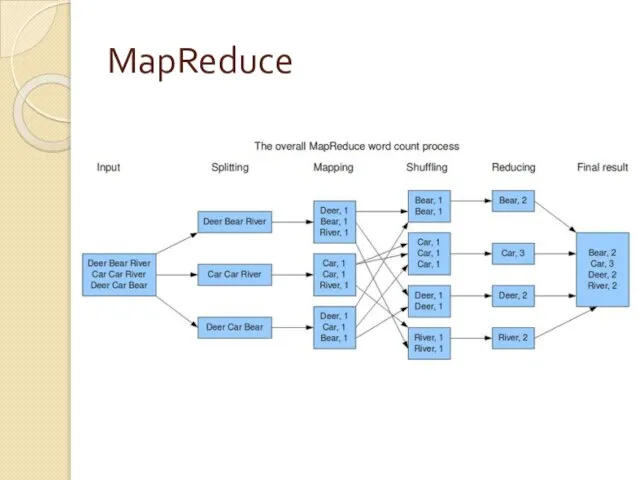
Слайд 7HDFS
Иерархия каталогов и файлов
Файлы поделены на блоки (128 MB)
Метаданные отделены от данных
NameNode
HDFS
Иерархия каталогов и файлов
Файлы поделены на блоки (128 MB)
Метаданные отделены от данных
NameNode

Слайд 8HBase
Распределённое ключ-значение хранилище на базе HDFS
Таблицы:
Строки с уникальными ключами
Произвольное количество колонок
Колонки сгруппированы
HBase
Распределённое ключ-значение хранилище на базе HDFS
Таблицы:
Строки с уникальными ключами
Произвольное количество колонок
Колонки сгруппированы

Слайд 9ZooKeeper
Распределённая служба координации распределённых задач
Выборы лидера
Распределённые блокировки
Координация и уведомления о событиях
ZooKeeper
Распределённая служба координации распределённых задач
Выборы лидера
Распределённые блокировки
Координация и уведомления о событиях

Слайд 10Pig
Платформа для анализа больших наборов данных
Pig Latin – SQL-подобный язык
Простота кодирования
Возможности оптимизации
Расширяемость
Pig-программы
Pig
Платформа для анализа больших наборов данных
Pig Latin – SQL-подобный язык
Простота кодирования
Возможности оптимизации
Расширяемость
Pig-программы

Слайд 11Hive
Служит тем же целям, что и Pig
Таблицы
Типизированные колонки (int, float, string, date,
Hive
Служит тем же целям, что и Pig
Таблицы
Типизированные колонки (int, float, string, date,

Слайд 12Avro
Система сериализации данных
Предоставляет:
Компактный бинарный формат
Удалённые вызовы процедур (RPC)
Простая интеграция с динамическими языками
Чтение/запись
Avro
Система сериализации данных
Предоставляет:
Компактный бинарный формат
Удалённые вызовы процедур (RPC)
Простая интеграция с динамическими языками
Чтение/запись

Слайд 13HDFS. Поставленные цели
Очень большой объём распределённых данных
10К узлов, 100М файлов, 10ПБ
HDFS. Поставленные цели
Очень большой объём распределённых данных
10К узлов, 100М файлов, 10ПБ

Слайд 14HDFS. Архитектура
HDFS. Архитектура
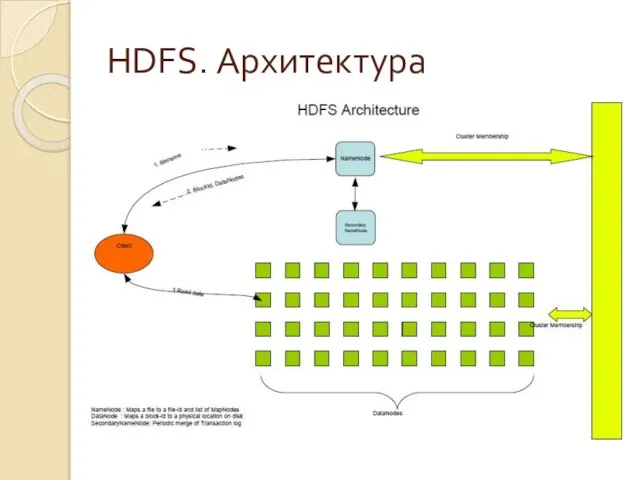
Слайд 15HDFS. Архитектура
Общее пространство имён для всего кластера
Согласованность данных
Write-once-read-many модель доступа
Append-запись всё ещё
HDFS. Архитектура
Общее пространство имён для всего кластера
Согласованность данных
Write-once-read-many модель доступа
Append-запись всё ещё

Слайд 16HDFS. Архитектура
HDFS. Архитектура
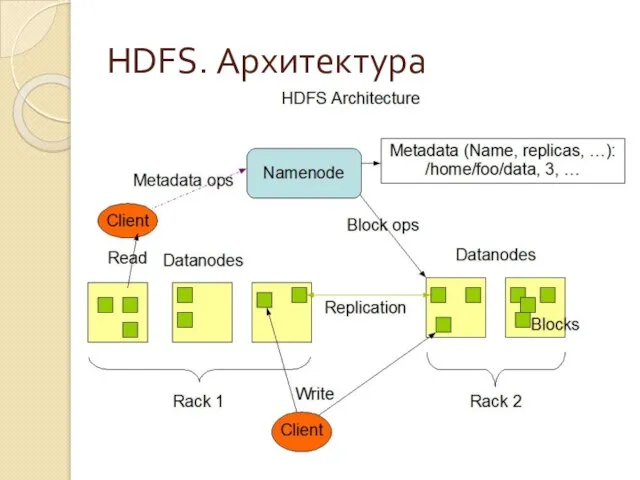
Слайд 17HDFS. NameNode
Управляет пространством имён
Связывает имя файла с набором блоков
Связывает блок с набором
HDFS. NameNode
Управляет пространством имён
Связывает имя файла с набором блоков
Связывает блок с набором

Слайд 18HDFS. NameNode. Метаданные
Метаданные для всего кластера хранятся в ОП
Типы метаданных
Списки файлов
Списки блоков
HDFS. NameNode. Метаданные
Метаданные для всего кластера хранятся в ОП
Типы метаданных
Списки файлов
Списки блоков

Слайд 19HDFS. DataNode
Сервер блоков
Хранит данные в локальной ФС
Хранит метаданные блоков (CRC)
Предоставляет данные и
HDFS. DataNode
Сервер блоков
Хранит данные в локальной ФС
Хранит метаданные блоков (CRC)
Предоставляет данные и

Слайд 20HDFS. CheckpointNode
Периодически создаёт новый checkpoint образ из checkpoint и journal, загруженных с
HDFS. CheckpointNode
Периодически создаёт новый checkpoint образ из checkpoint и journal, загруженных с

Слайд 21HDFS. Запись
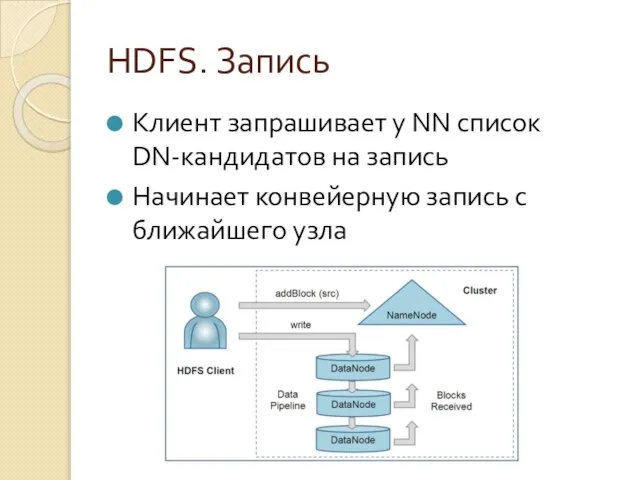
Клиент запрашивает у NN список DN-кандидатов на запись
Начинает конвейерную запись с
HDFS. Запись
Клиент запрашивает у NN список DN-кандидатов на запись
Начинает конвейерную запись с
Слайд 22HDFS. Чтение
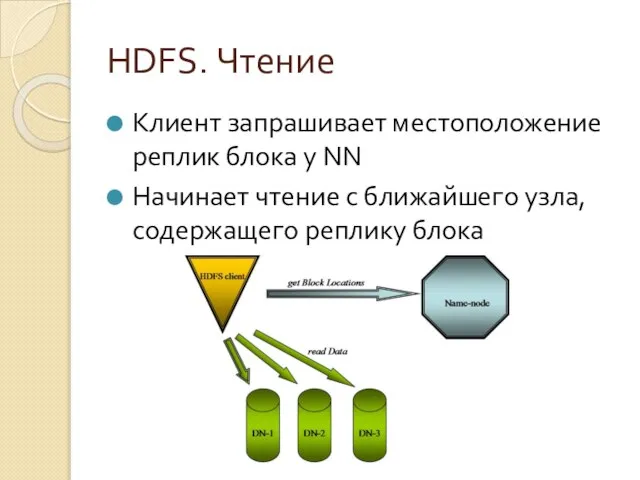
Клиент запрашивает местоположение реплик блока у NN
Начинает чтение с ближайшего узла,
HDFS. Чтение
Клиент запрашивает местоположение реплик блока у NN
Начинает чтение с ближайшего узла,
Слайд 23HDFS. Расположение реплик
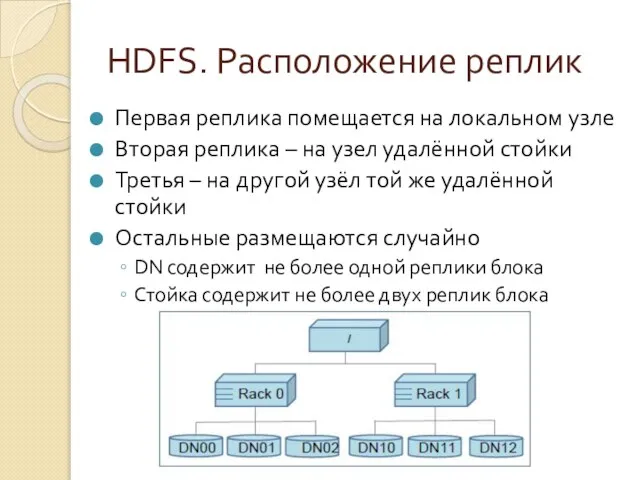
Первая реплика помещается на локальном узле
Вторая реплика – на узел
HDFS. Расположение реплик
Первая реплика помещается на локальном узле
Вторая реплика – на узел
Слайд 24HDFS. Balancer
Процент используемого дискового пространства на всех DN должен быть одинаков
Обычно запускается
HDFS. Balancer
Процент используемого дискового пространства на всех DN должен быть одинаков
Обычно запускается

Слайд 25HDFS. Block Scanner
Каждая DN периодически запускает BS
BS проверяет, что контрольные суммы соответствуют
HDFS. Block Scanner
Каждая DN периодически запускает BS
BS проверяет, что контрольные суммы соответствуют

Слайд 26HDFS. Интерфейс пользователя
Команды пользователя HDFS
hadoop fs –mkdir /foodir
hadoop fs –cat /foodir/barfile.txt
hadoop fs
HDFS. Интерфейс пользователя
Команды пользователя HDFS
hadoop fs –mkdir /foodir
hadoop fs –cat /foodir/barfile.txt
hadoop fs

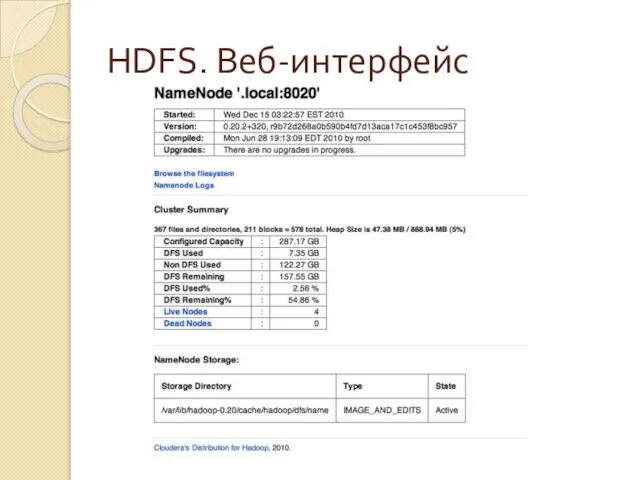
Слайд 27HDFS. Веб-интерфейс
HDFS. Веб-интерфейс
Слайд 28HDFS. Использование в Yahoo!
3500 узлов
2 процессора [email protected] (по 4 ядра)
Red Hat Enterprise
HDFS. Использование в Yahoo!
3500 узлов
2 процессора [email protected] (по 4 ядра)
Red Hat Enterprise

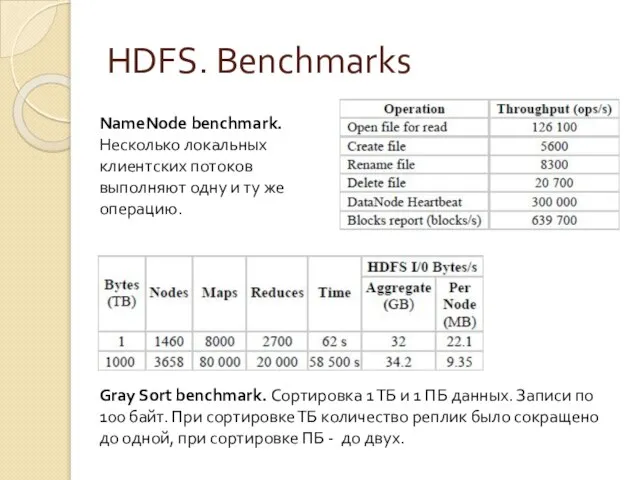
Слайд 29HDFS. Benchmarks
Gray Sort benchmark. Сортировка 1 ТБ и 1 ПБ данных. Записи
HDFS. Benchmarks
Gray Sort benchmark. Сортировка 1 ТБ и 1 ПБ данных. Записи
 От мечты к открытию. Женщины в науке
От мечты к открытию. Женщины в науке Электронный документооборотПрактика внедрения
Электронный документооборотПрактика внедрения Встреча участников сети практиков в области миграции и денежных переводов ( МИРПАЛ)
Встреча участников сети практиков в области миграции и денежных переводов ( МИРПАЛ) ПРАВО КАК ПРОЦЕДУРА
ПРАВО КАК ПРОЦЕДУРА Новое поколение тракторов КИРОВЕЦ К-7М
Новое поколение тракторов КИРОВЕЦ К-7М Презентация на тему Серебряный век русской литературы
Презентация на тему Серебряный век русской литературы Строение земного шара
Строение земного шара "ВНИМАНИЕ!
"ВНИМАНИЕ! Психологические особенности адаптации младших школьников к условиям и требованиям школы
Психологические особенности адаптации младших школьников к условиям и требованиям школы Теоретические подходы к консультированию
Теоретические подходы к консультированию Создавать видимость активной работы Минимизировать ответственность и риски Сохранить хорошую мину Получать большую зарплату КАК
Создавать видимость активной работы Минимизировать ответственность и риски Сохранить хорошую мину Получать большую зарплату КАК Отряд Вши
Отряд Вши Слова с сочетаниями чк, чн
Слова с сочетаниями чк, чн Парк культуры и отдыха Заельцовский
Парк культуры и отдыха Заельцовский Программирование
Программирование Социальная психология. Практическое занятие №1
Социальная психология. Практическое занятие №1 Перегонка и ректификация
Перегонка и ректификация D3_Hum_2_Greece_2022
D3_Hum_2_Greece_2022 Творожная запеканка
Творожная запеканка Стандартизация. История развития
Стандартизация. История развития Презентация на тему Времена года
Презентация на тему Времена года INVITE
INVITE Буддизм: учение о преодолении зла
Буддизм: учение о преодолении зла Организация и порядок проведения учений, тренировок по ГО и защите от чрезвычайных ситуаций
Организация и порядок проведения учений, тренировок по ГО и защите от чрезвычайных ситуаций  Курс молодого консультанта
Курс молодого консультанта Чарльз Дарвин биография
Чарльз Дарвин биография ВИЗИТНАЯ КАРТОЧКА БИБЛИОТЕКИ
ВИЗИТНАЯ КАРТОЧКА БИБЛИОТЕКИ УЧИМ БУКВЫ
УЧИМ БУКВЫ