- Технология извлечения знаний из использования Интернет

Содержание
- 2. Определение Извлечение знаний – поиск нетривиальных потенциально полезных знаний в больших объёмах данных.
- 3. Основные области применения Финансы Страхование Медицина Биология Интернет
- 4. OLAP/Data mining
- 5. Структура web mining
- 6. Структура web content mining
- 7. Web usage mining Извлечение знаний из использования Интернет – поиск нетривиальных потенциально полезных знаний в деятельности
- 8. Применения Web usage mining Персонификация контента Улучшение работы сети Модификация сайтов Исследования сети
- 9. Этапы Web usage mining Сбор данных Обработка данных Применение методов Data mining Кластеризация Поиск ассоциативных правил
- 10. Сбор информации
- 11. Обработка данных Очистка данных Заполнение пути Выделение пользовательских сессий
- 12. Ассоциативные правила Правила вида: A=>b. Где А - ДНФ Поддержка – отношение тех элементов где A
- 13. Цель кластеризации Уменьшение размерности (выбор представителей) Генерация гипотез Проверка гипотез Прогнозные модели
- 14. Методы кластеризации Иерархические Алгоритмы оптимизации Основанные на плотности Нечёткие методы
- 15. Иерархические методы N кластеров На каждом шаге объединение двух самых «близких» кластеров Расстояние: по наиболее близкими
- 16. Нечёткий c-medoids метод Jm(V;X) = Минимизируется это значение Только 30 элементов с наибольшей вероятностью используются для
- 17. Верификация кластеризации
- 18. Методы верификации Сопоставление эталонного разбиения и кластеров Статистические Связанные с нечётким разбиением Комбинированные методы
- 19. Предлагаемый метод Сессии представлены как численные векторы Используюется расстояние редактирования Расстояние модифицируется с учётом положения страниц
- 20. Данные Sigla.ru 70000 посещений в день 1300 сессий в день 50 страниц Данные за три дня
- 21. Расстояние Евклида Каждая сессия это вектор vi = {x1,..xn} xj = 1 если страница j входит
- 22. Расстояние редактирования Примеры строк: ‘cat’, ‘cash’ CAT -> CAS -> CASH Общее расстояние 3.
- 23. Модификация расстояния dir11/dir12/pagename1 dir21/dir22/pagename2 Если совпадают dir 11 и dir 21 то уменьшается стоимость замены Если
- 24. Индекс Беждека
- 25. Энтропия разбиения
- 26. Предлагаемая верификация Подсчёт уникальных ассоциативных правил Индекс = количество уникальных правил/количество кластеров
- 27. Предлагаемый метод
- 29. Скачать презентацию
Слайд 2Определение
Извлечение знаний – поиск нетривиальных потенциально полезных знаний в больших объёмах данных.
Определение
Извлечение знаний – поиск нетривиальных потенциально полезных знаний в больших объёмах данных.

Слайд 3Основные области применения
Финансы
Страхование
Медицина
Биология
Интернет
Основные области применения
Финансы
Страхование
Медицина
Биология
Интернет

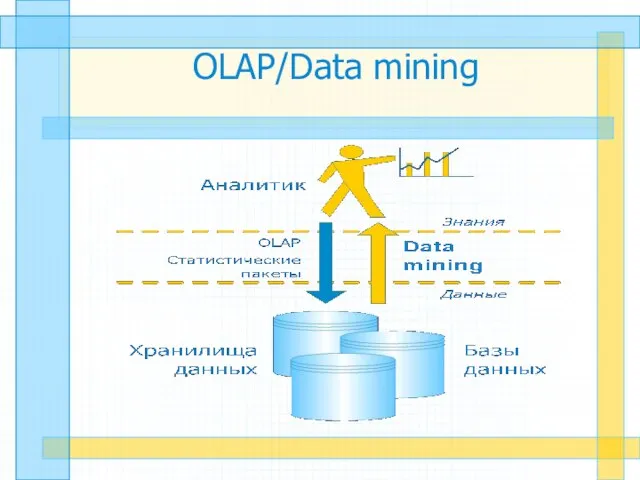
Слайд 4OLAP/Data mining
OLAP/Data mining
Слайд 5Структура web mining
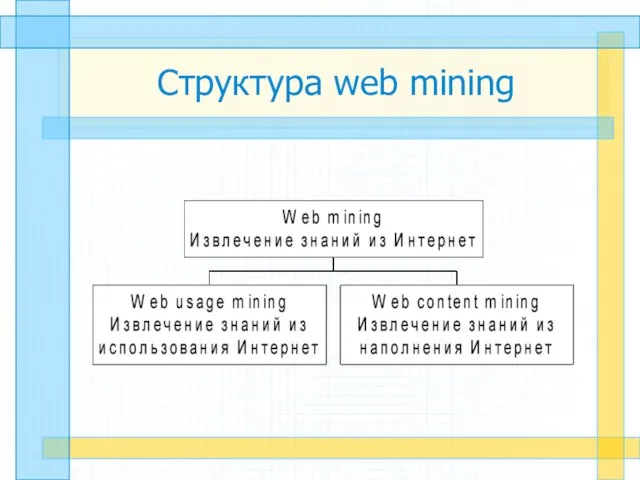
Структура web mining
Слайд 6Структура web content mining
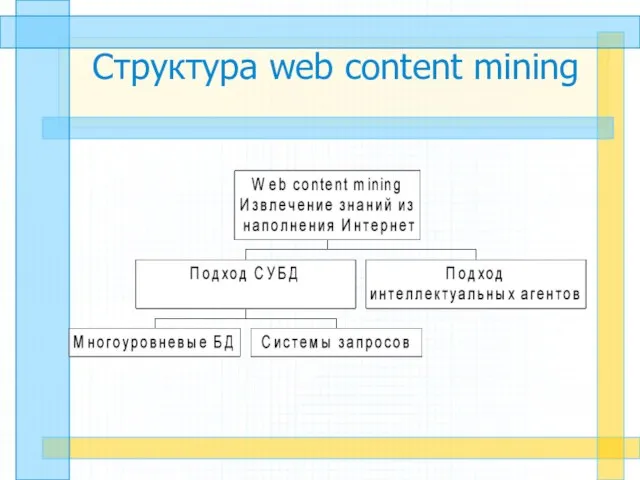
Структура web content mining
Слайд 7Web usage mining
Извлечение знаний из использования Интернет – поиск нетривиальных потенциально
Web usage mining
Извлечение знаний из использования Интернет – поиск нетривиальных потенциально

Слайд 8Применения Web usage mining
Персонификация контента
Улучшение работы сети
Модификация сайтов
Исследования сети
Применения Web usage mining
Персонификация контента
Улучшение работы сети
Модификация сайтов
Исследования сети

Слайд 9Этапы Web usage mining
Сбор данных
Обработка данных
Применение методов Data mining
Кластеризация
Поиск ассоциативных правил
Поиск наиболее
Этапы Web usage mining
Сбор данных
Обработка данных
Применение методов Data mining
Кластеризация
Поиск ассоциативных правил
Поиск наиболее

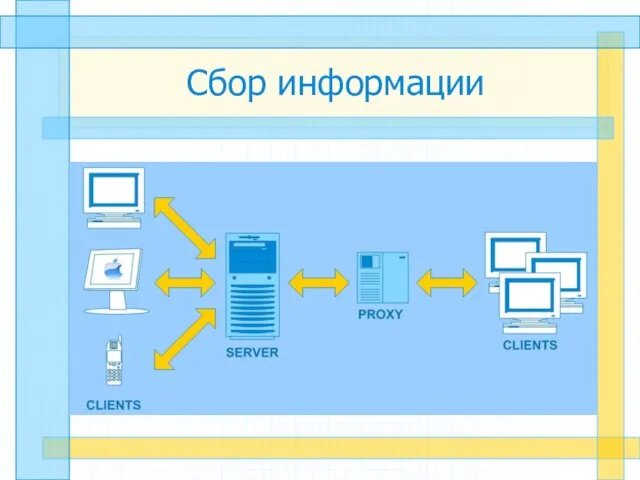
Слайд 10Сбор информации
Сбор информации
Слайд 11Обработка данных
Очистка данных
Заполнение пути
Выделение пользовательских сессий
Обработка данных
Очистка данных
Заполнение пути
Выделение пользовательских сессий

Слайд 12Ассоциативные правила
Правила вида:
A=>b. Где А - ДНФ
Поддержка – отношение тех элементов где
Ассоциативные правила
Правила вида:
A=>b. Где А - ДНФ
Поддержка – отношение тех элементов где

Слайд 13Цель кластеризации
Уменьшение размерности (выбор представителей)
Генерация гипотез
Проверка гипотез
Прогнозные модели
Цель кластеризации
Уменьшение размерности (выбор представителей)
Генерация гипотез
Проверка гипотез
Прогнозные модели

Слайд 14Методы кластеризации
Иерархические
Алгоритмы оптимизации
Основанные на плотности
Нечёткие методы
Методы кластеризации
Иерархические
Алгоритмы оптимизации
Основанные на плотности
Нечёткие методы

Слайд 15Иерархические методы
N кластеров
На каждом шаге объединение двух самых «близких» кластеров
Расстояние: по наиболее
Иерархические методы
N кластеров
На каждом шаге объединение двух самых «близких» кластеров
Расстояние: по наиболее

Слайд 16Нечёткий c-medoids метод
Jm(V;X) =
Минимизируется это значение
Только 30 элементов с наибольшей вероятностью используются
Нечёткий c-medoids метод
Jm(V;X) =
Минимизируется это значение
Только 30 элементов с наибольшей вероятностью используются

Слайд 17Верификация кластеризации
Верификация кластеризации
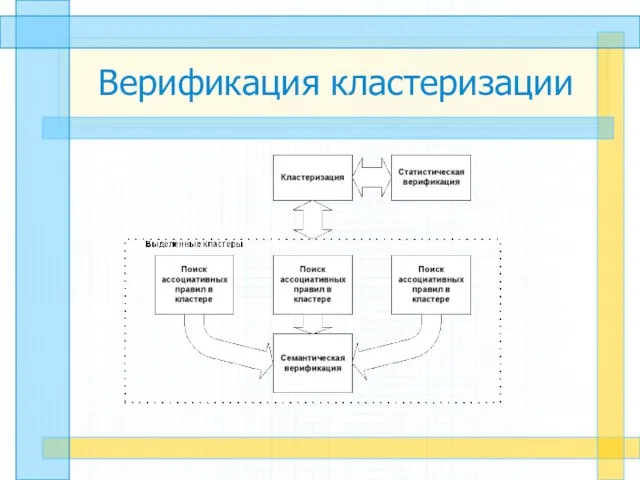
Слайд 18Методы верификации
Сопоставление эталонного разбиения и кластеров
Статистические
Связанные с нечётким разбиением
Комбинированные методы
Методы верификации
Сопоставление эталонного разбиения и кластеров
Статистические
Связанные с нечётким разбиением
Комбинированные методы

Слайд 19Предлагаемый метод
Сессии представлены как численные векторы
Используюется расстояние редактирования
Расстояние модифицируется с учётом
Предлагаемый метод
Сессии представлены как численные векторы
Используюется расстояние редактирования
Расстояние модифицируется с учётом

Слайд 20Данные Sigla.ru
70000 посещений в день
1300 сессий в день
50 страниц
Данные за три дня
Сессии
Данные Sigla.ru
70000 посещений в день
1300 сессий в день
50 страниц
Данные за три дня
Сессии

Слайд 21Расстояние Евклида
Каждая сессия это вектор
vi = {x1,..xn}
xj = 1 если страница
Расстояние Евклида
Каждая сессия это вектор
vi = {x1,..xn}
xj = 1 если страница

Слайд 22Расстояние редактирования
Примеры строк: ‘cat’, ‘cash’
CAT -> CAS -> CASH
Общее расстояние 3.
Расстояние редактирования
Примеры строк: ‘cat’, ‘cash’
CAT -> CAS -> CASH
Общее расстояние 3.

Слайд 23Модификация расстояния
dir11/dir12/pagename1
dir21/dir22/pagename2
Если совпадают dir 11 и dir 21 то уменьшается стоимость замены
Если
Модификация расстояния
dir11/dir12/pagename1
dir21/dir22/pagename2
Если совпадают dir 11 и dir 21 то уменьшается стоимость замены
Если

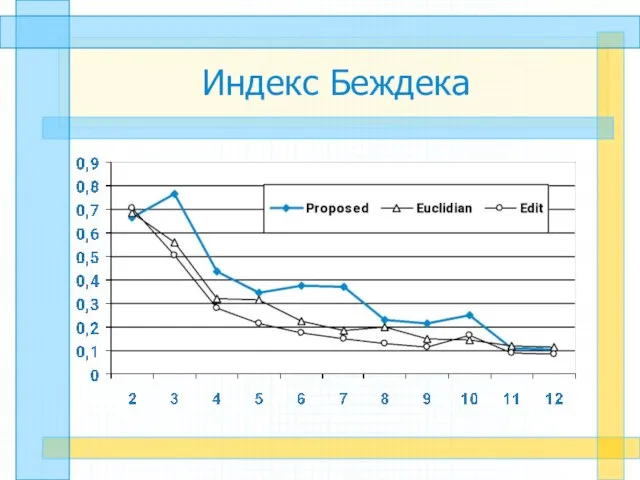
Слайд 24Индекс Беждека
Индекс Беждека
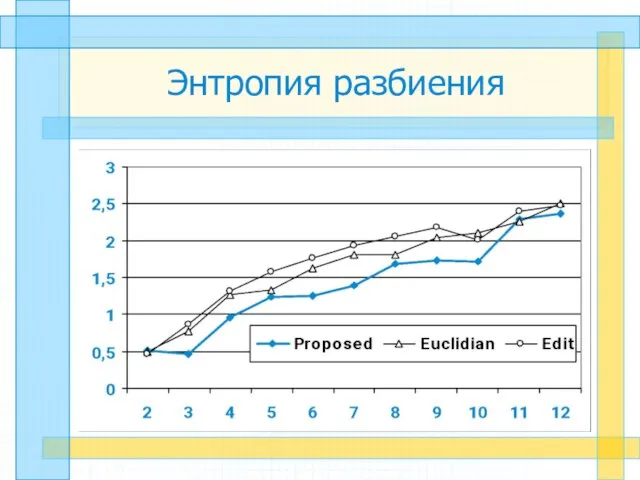
Слайд 25Энтропия разбиения
Энтропия разбиения
Слайд 26Предлагаемая верификация
Подсчёт уникальных ассоциативных правил
Индекс = количество уникальных правил/количество кластеров
Предлагаемая верификация
Подсчёт уникальных ассоциативных правил
Индекс = количество уникальных правил/количество кластеров

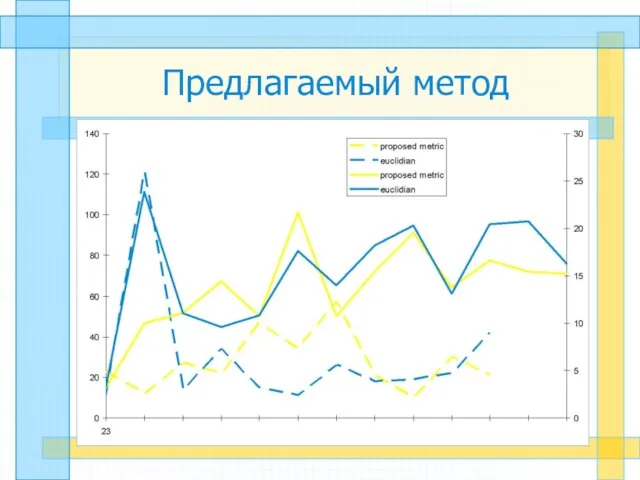
Слайд 27Предлагаемый метод
Предлагаемый метод
 Традиционные праздники Японии. День Совершеннолетия. Выполнила ученица 10 класса Василенко ЕкатеринаМАОУ «СОШ №31» Ве
Традиционные праздники Японии. День Совершеннолетия. Выполнила ученица 10 класса Василенко ЕкатеринаМАОУ «СОШ №31» Ве «СОЛНЫШКО» ЛЕТНИЙОЗДОРОВИТЕЛЬНЫЙ ЛАГЕРЬ
«СОЛНЫШКО» ЛЕТНИЙОЗДОРОВИТЕЛЬНЫЙ ЛАГЕРЬ Теплица ЦДОД г. Полярный
Теплица ЦДОД г. Полярный Лесная аптека
Лесная аптека 2 часть
2 часть Создание специальных образовательных условий в образовательной организации
Создание специальных образовательных условий в образовательной организации Консорциум «ЭНЕРГОКОМИНТЕХ»
Консорциум «ЭНЕРГОКОМИНТЕХ» Нормы трудового права. Тест
Нормы трудового права. Тест Российский парламентаризм
Российский парламентаризм Защита курсовой работы
Защита курсовой работы Девиантное поведение: причины, сущность, профилактика
Девиантное поведение: причины, сущность, профилактика МПСУ управляемыми выпрямителями
МПСУ управляемыми выпрямителями Психическое здоровье
Психическое здоровье Презентация на тему Способы установления невербального общения во время консультирования
Презентация на тему Способы установления невербального общения во время консультирования Формула Ньютона-Лейбница
Формула Ньютона-Лейбница Военные корабли времен первой и второй Мировой войны
Военные корабли времен первой и второй Мировой войны Statisticheskaya_obrabotka_dannykh_fizicheskogo_experimenta
Statisticheskaya_obrabotka_dannykh_fizicheskogo_experimenta «На крыльях творчества»
«На крыльях творчества»  Презентация на тему Музей Шерлока Холмса (Sherlock Holmes museum)
Презентация на тему Музей Шерлока Холмса (Sherlock Holmes museum) Что такое экономика?
Что такое экономика? Роль воды в жизнедеятельности растений
Роль воды в жизнедеятельности растений Русская национальная культура в хаосе масскульта и маргинальных форм культуры
Русская национальная культура в хаосе масскульта и маргинальных форм культуры «Национальный институт сертифицированных консультантов по управлению(Россия) XIII летняя конференция
«Национальный институт сертифицированных консультантов по управлению(Россия) XIII летняя конференция Оформление пояснительной записки выпускной квалификационной работы
Оформление пояснительной записки выпускной квалификационной работы Повторение. Предложение
Повторение. Предложение Ручная аргонодуговая сварка
Ручная аргонодуговая сварка Structural Analysis of Trusses – Method of Joints
Structural Analysis of Trusses – Method of Joints Договор страхования
Договор страхования